JD-hotkey:京东开源的利器 --知识铺
项目介绍
京东 App 后台中间件,毫秒级探测热点数据,毫秒级推送至服务器集群内存,大幅降低热 key 对数据层查询压力。
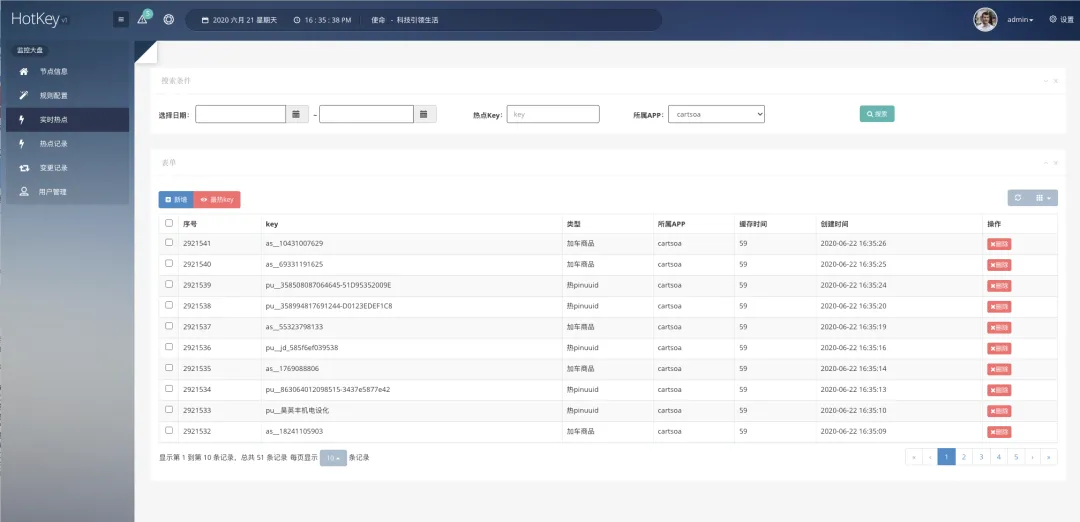
对于任何突发的、无法预测的高需求请求,例如大量对同一商品的请求(热点数据)、爬虫或刷子(热用户)、或对同一接口的大量请求(热接口),本框架能够毫秒级精确探测。这些热点信息会被推送到部署应用的每一台机器的JVM内存中,显著减轻后端数据存储层的负载。客户端可以决定如何使用这些热点key,如本地缓存热门商品、拒绝访问某些用户或对某些接口进行熔断或返回默认值,确保整个应用集群内热点数据的一致性。
核心功能:
- 热点数据探测并推送至集群各服务器
适用场景:
- MySQL 热数据本地缓存
- Redis 热数据本地缓存
- 黑名单用户本地缓存
- 爬虫用户限流
- 接口、用户维度限流
- 单机接口、用户维度限流
- 集群用户维度限流
- 集群接口维度限流
性能指标:
- 探测性能:8核单机worker端每秒可处理16万个key探测任务,16核单机至少每秒平稳处理30万以上,实际压测达到37万,CPU运行稳定,框架无异常。
- 推送性能:在高并发写入的同时,对外推送性能约为每秒10-12万次。例如,若有1千台server,一台worker上每秒产生100个热key,则这1秒会平稳推送10万次。如果主要是推送操作,该框架每秒可稳定推送40-60万次,极限可达80万次,并能维持几秒。
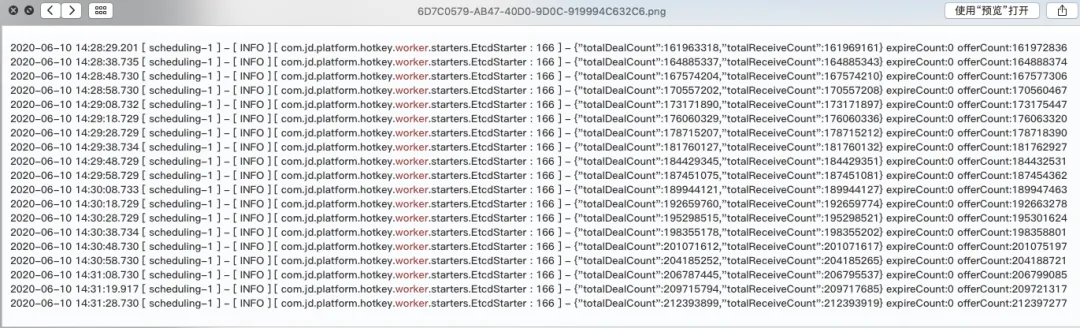

实战检验
京东APP后台热数据探测框架,在经过多次高压压测以及2020年京东618和双11大促的考验后,表现出色。
-
性能表现:每天探测数十亿个key,有效识别爬虫和刷单用户。
-
实时推送:毫秒级将热门商品推送至服务端内存,减少数据层查询压力,提升应用性能。
-
大促期间表现:hotkey worker集群的秒级吞吐量达到1500万级别,本地缓存占总访问量的50%以上,显著减轻了redis层的负担。
架构设计
该框架具有以下特点:
-
无依赖:不依赖任何定制化组件,与redis无关。
-
核心机制:利用netty连接,client端发送待测key,由worker完成分布式计算。
-
轻量级:计算出热key后,直接推送至client端。
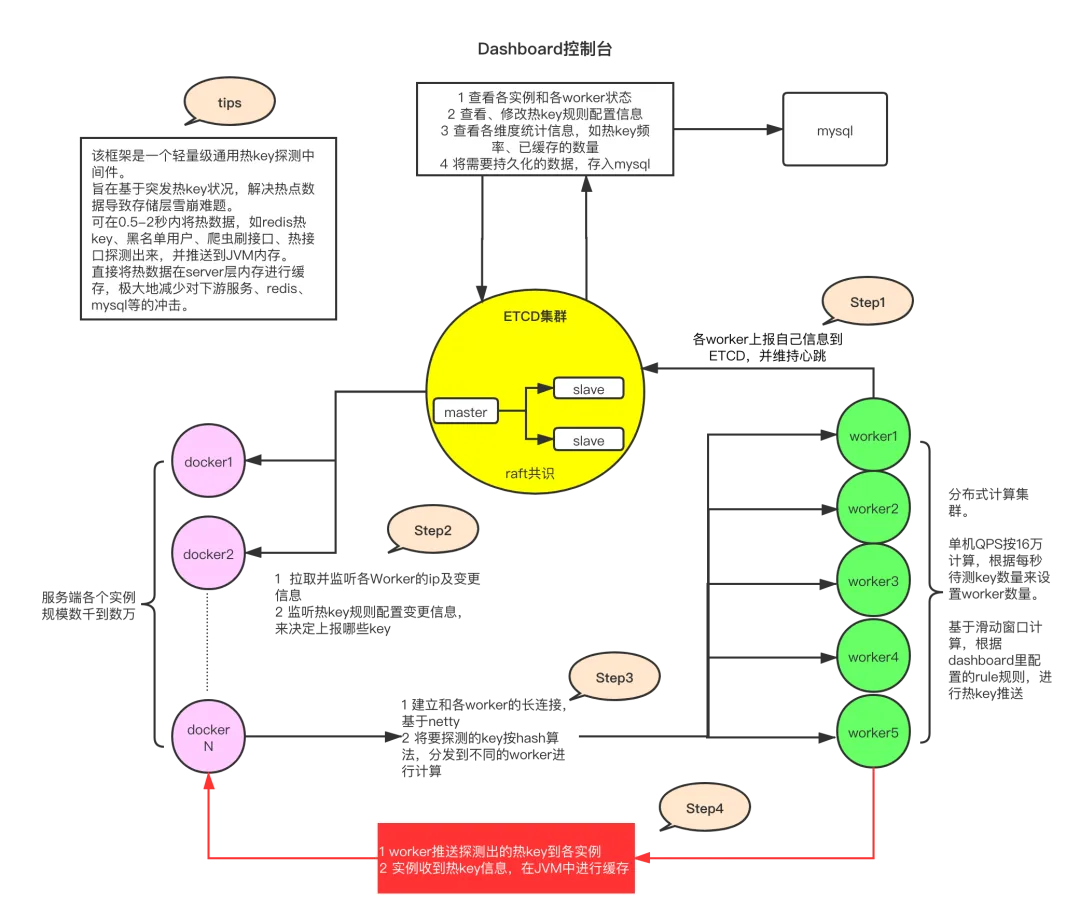
该框架主要由 4 个部分组成:
etcd 集群: etcd 是一个高性能的分布式键值存储系统,它作为配置中心,能够以极小的资源消耗提供高效的监听和订阅服务。在本框架中,etcd 主要用于存储规则配置、worker 节点的 IP 地址以及探测到的热 key 或者手动添加的热 key。 client 端 JAR 包: 客户端通过引入特定的 JAR 包来集成热 key 检测功能。这个 JAR 包提供了简便的方法来判断某个 key 是否为热 key,并且负责 key 的上报、监听 etcd 中的规则变化、worker 信息变化以及热 key 的更新。此外,它还使用本地 Caffeine 缓存对热 key 进行缓存处理。 worker 端集群: worker 是独立部署的 Java 应用程序,它们启动后会连接到 etcd 并定期报告自己的 IP 地址,以便客户端获取并建立长连接。worker 的主要任务是收集来自各个 client 的待检测 key,并对其进行累加计数。一旦某个 key 达到了 etcd 中设定的阈值,该 key 就会被标记为热 key,并推送到所有客户端。 dashboard 控制台: 控制台提供了一个可视化的界面,同样连接至 etcd。用户可以通过控制台设置针对不同应用的 key 规则,例如定义多长时间内出现多少次算作热 key。当 worker 发现热 key 后,会将其发送到 etcd,同时 dashboard 也会监听这些热 key 信息,并记录入库。此外,还可以通过控制台手工添加或移除热 key,这些更改会被客户端实时监听到。
项目地址
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek002/post/20240918/JD-hotkey%E4%BA%AC%E4%B8%9C%E5%BC%80%E6%BA%90%E7%9A%84%E5%88%A9%E5%99%A8--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com