Dify-LLM大模型平台无缝集成第三方系统 --知识铺
Dify简介
1.1 功能特点
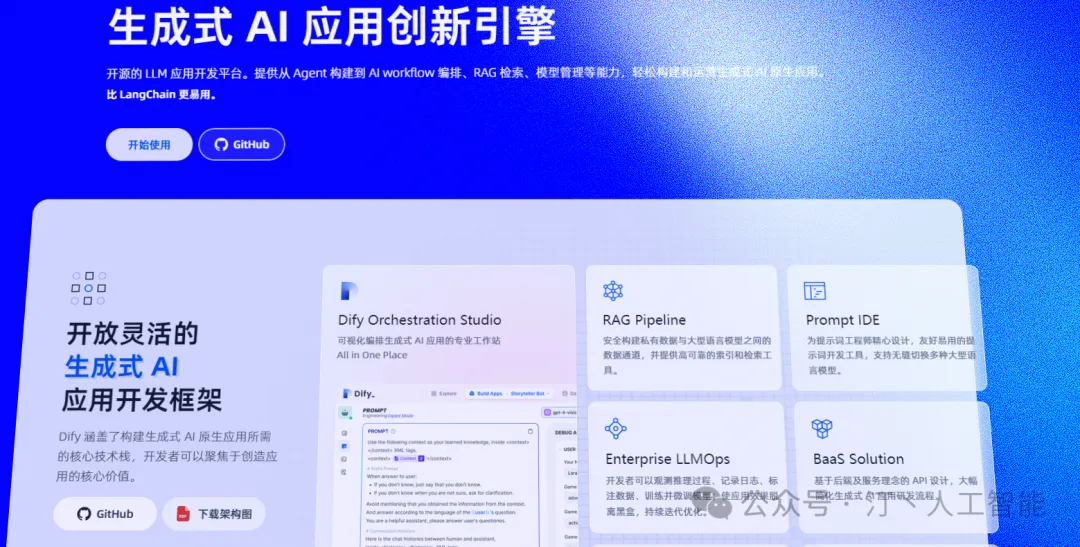
Dify是一款前沿的开源大语言模型(LLM)应用开发平台,它创新性地结合了后端即服务(Backend as a Service, BaaS)和LLMOps的核心理念。该平台旨在为开发者提供一个从创意原型到高效生产的快速通道,打破技术障碍,使非技术背景的用户也能轻松参与AI应用的开发和数据运营,共同推动智能技术的发展。
Dify: 全方位LLM应用构建平台
Dify是一个集成了全方位技术的LLM应用构建平台,它提供了从模型选择到应用开发的一站式服务。以下是Dify的核心功能和特点:
技术基石
-
模型库: 提供数百种模型选择
-
Prompt编排: 高效直观的界面
-
RAG引擎: 检索增强生成引擎
-
Agent框架: 稳固可靠的框架
开发者体验
-
简化开发流程: 减少开发复杂性
-
灵活性与创意空间: 提供更大的自由度
-
流程编排: 灵活的流程设计
-
用户界面: 友好的界面设计
-
API接口: 用户友好的API接口
核心价值
-
避免重复劳动: 提高开发效率
-
专注创新: 让开发者集中精力于创新
-
业务需求挖掘: 深入理解业务需求
Dify的含义
-
Define + Modify: 定义并持续改进AI应用
-
Do it for you: 为你而做



-
后端即服务: 所有 Dify 的功能都带有相应的 API,因此您可以轻松地将 Dify 集成到自己的业务逻辑中。 -
Agent 智能体: 您可以基于 LLM 函数调用或 ReAct 定义 Agent,并为 Agent 添加预构建或自定义工具。Dify 为 AI Agent 提供了50多种内置工具,如谷歌搜索、DALL·E、Stable Diffusion 和 WolframAlpha 等。
-
LLMOps: 提供随时间监视和分析应用程序日志和性能的功能。用户可以根据生产数据和标注持续改进提示、数据集和模型。
-
Prompt IDE: 一个直观的界面,用于制作提示、比较模型性能以及向基于聊天的应用程序添加其他功能(如文本转语音)。
-
RAG Pipeline: 广泛的 RAG 功能,涵盖从文档摄入到检索的所有内容,支持从 PDF、PPT 和其他常见文档格式中提取文本的开箱即用的支持。
-
全面的模型支持: 与数百种专有/开源 LLMs 以及数十种推理提供商和自托管解决方案无缝集成,涵盖 GPT、Mistral、Llama3 以及任何与 OpenAI API 兼容的模型。
-
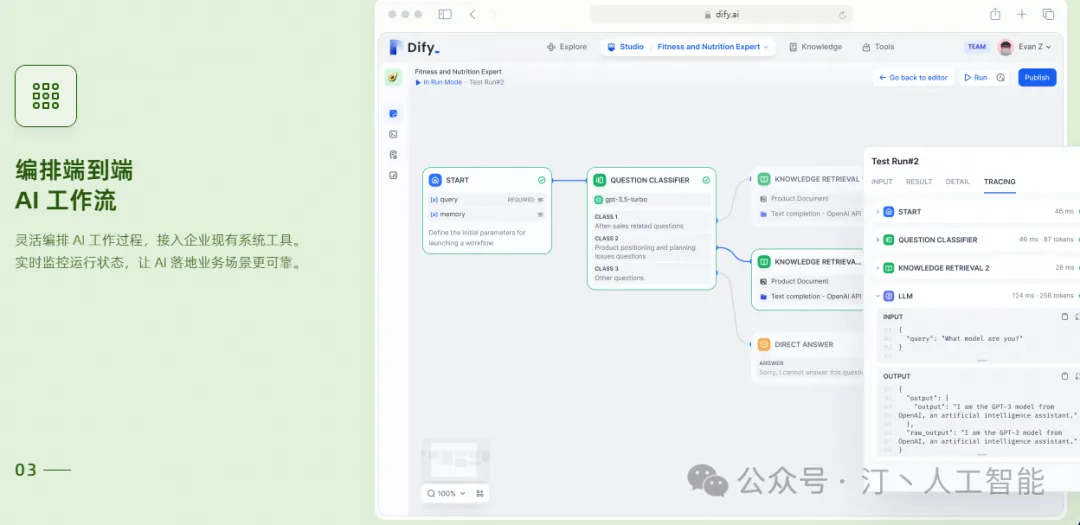
工作流: 在画布上构建和测试功能强大的 AI 工作流程,利用以上所有功能以及更多功能。

-
功能对比
-
框架原理图


Dify 平台关键技术特性与部署指南
1.2 关键技术特性Dify 平台集成了多种关键技术特性,以支持高效的本地模型推理和复杂的工作流程管理。以下是一些核心特性:
- 本地模型推理 Runtime 支持: 包括 Xinference(推荐)、OpenLLM、LocalAI、ChatGLM、Ollama 和 NVIDIA TIS。
- Agentic Workflow 特性: 支持节点操作,使工作流程更加灵活和可定制。
- LLM(大型语言模型): 提供强大的自然语言处理能力。
- 知识库检索: 允许从大量数据中快速检索信息。
- 问题分类: 自动将问题分配到适当的处理流程。
- 条件分支: 根据特定条件执行不同的代码路径。
- 代码执行: 在平台上直接运行代码段。
- 模板转换: 使用预定义的模板来格式化输出。
- HTTP 请求: 支持通过 HTTP 进行外部通信。
- 工具集成: 提供多种工具以扩展平台功能。
RAG(Retrieval-Augmented Generation)特性Dify 支持以下 RAG 特性:
- 使用 ReRank 模型: 提高检索结果的相关性和准确性。
- 关键词高亮: 突出显示关键信息。
- 文本相似度匹配: 确保检索内容的相关性。
- 混合检索: 结合不同类型的数据源进行搜索。
- 多路召回: 同时检索多个信息源。
- 索引方式: 优化数据的组织和访问速度。
- 检索方式: 提供多种检索策略。
- 召回优化技术: 提升检索效率和质量。
向量数据库支持Dify 支持多种向量数据库,包括但不限于 Qdrant、Weaviate、Zilliz/Milvus、Pgvector、Pgvector-rs、Chroma、OpenSearch、TiDB、Tencent Vector 和 Oracle。
1.3 云服务Dify 提供便捷的云服务,用户无需自行部署即可使用完整功能。要开始使用 Dify 云服务,只需拥有一个 GitHub 或 Google 账号:
- 登录 Dify 云服务并创建或加入一个 Workspace。2. 配置你的模型供应商,或选择我们提供的托管模型供应商。3. 开始创建应用。
1.4 更多 LLM 平台参考有关 LLM 框架的选择和比较,可以参考以下资源:
- RAG+AI工作流+Agent:LLM框架该如何选择,全面对比 MaxKB、Dify、FastGPT、RagFlow 等
- 智胜未来:国内大模型+Agent应用案例精选,以及主流 Agent 框架开源项目推荐
社区版部署#### 2.1 Docker Compose 部署(推荐)注意:请根据上述内容进行操作。

Docker 安装向量数据库 Milvus 指南
概述
本指南将详细介绍如何使用 Docker 安装和使用向量数据库 Milvus,包括安装 Docker、Docker Compose,克隆 Dify 代码仓库,以及如何启动 Milvus 进行向量相似度搜索。
步骤 1: 安装 Docker
-
安装 Docker: 请根据你的操作系统选择合适的安装方法。
-
Docker Hub 加速: 为了加速 Docker 镜像下载,可以配置 Docker Hub 加速器。
步骤 2: 安装 Docker Compose
- 安装 Docker Compose: Docker Compose 用于定义和运行多容器 Docker 应用程序。
步骤 3: 克隆 Dify 代码仓库
- 克隆代码仓库: 克隆 Dify 代码仓库以获取 Milvus 的相关代码和配置文件。
步骤 4: 启动 Milvus
-
启动 Milvus: 使用 Docker Compose 启动 Milvus 服务。
-
向量相似度搜索: 启动后,你可以进行向量相似度搜索。
推荐阅读
-
一文带你入门向量数据库 Milvus: 这篇文章详细介绍了 Milvus 的安装和使用,包括 Docker 安装、Milvus 安装使用、以及使用 Attu 进行可视化。
-
告别 DockerHub 镜像下载难题: 这篇文章提供了一些策略来高效下载 Docker 镜像,以提升开发体验。
注意事项
- 请确保在安装过程中遵循正确的步骤,以避免潜在的问题。
git clone https://github.com/langgenius/dify.git
- 启动 Dify
#进入 Dify 源代码的 docker 目录,执行一键启动命令:
cd dify/docker
cp .env.example .env
docker compose up -d
Docker Compose 使用指南
检查 Docker Compose 版本
如果您的系统安装了 Docker Compose V2 而不是 V1,请使用 docker compose 而不是 docker-compose。您可以通过以下命令检查版本:
|
|
更多信息请参考官方文档。
解决 pulling 失败问题
如果您遇到 pulling 镜像失败的问题,请尝试添加镜像源。解决方案可参考以下推荐文章:
部署结果展示
请确保您的部署结果符合预期。如果遇到问题,请按照上述指南进行操作。
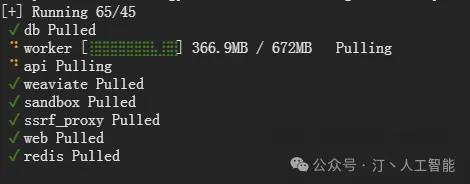
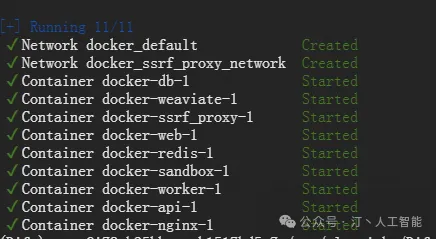
最后检查是否所有容器都正常运行:
docker compose ps
包括 3 个业务服务 api / worker / web,以及 6 个基础组件 weaviate / db / redis / nginx / ssrf_proxy / sandbox 。

NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
docker-api-1 langgenius/dify-api:0.6.16 "/bin/bash /entrypoi…" api 15 minutes ago Up 15 minutes 5001/tcp
docker-db-1 postgres:15-alpine "docker-entrypoint.s…" db 15 minutes ago Up 15 minutes (healthy) 5432/tcp
docker-nginx-1 nginx:latest "sh -c 'cp /docker-e…" nginx 15 minutes ago Up 15 minutes 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp
docker-redis-1 redis:6-alpine "docker-entrypoint.s…" redis 15 minutes ago Up 15 minutes (healthy) 6379/tcp
docker-sandbox-1 langgenius/dify-sandbox:0.2.1 "/main" sandbox 15 minutes ago Up 15 minutes
docker-ssrf_proxy-1 ubuntu/squid:latest "sh -c 'cp /docker-e…" ssrf_proxy 15 minutes ago Up 15 minutes 3128/tcp
docker-weaviate-1 semitechnologies/weaviate:1.19.0 "/bin/weaviate --hos…" weaviate 15 minutes ago Up 15 minutes
docker-web-1 langgenius/dify-web:0.6.16 "/bin/sh ./entrypoin…" web 15 minutes ago Up 15 minutes 3000/tcp
docker-worker-1 langgenius/dify-api:0.6.16 "/bin/bash /entrypoi…" worker 15 minutes ago Up 15 minutes 5001/tcp
- 更新 Dify
进入 dify 源代码的 docker 目录,按顺序执行以下命令:
cd dify/docker
docker compose down
git pull origin main
docker compose pull
docker compose up -d
同步环境变量配置指南
1. 更新 .env 文件
-
同步更新:如果
.env.example文件有更新,请确保同步修改您本地的.env文件。 -
检查配置:检查
.env文件中的所有配置项,确保它们与您的实际运行环境相匹配。 -
添加新变量:可能需要将
.env.example中的新变量添加到.env文件中。 -
更新变量值:更新
.env文件中已更改的任何值。
2. 访问 Dify
-
访问方式:访问 Dify 的方法有两种。
-
浏览器访问:在浏览器中输入
http://localhost访问 Dify。 -
本地端口访问:访问
http://127.0.0.1:80即可使用本地部署的 Dify。
3. Docker 部署运行
-
查看容器:Docker 部署运行完成后,输入指令
sudo docker ps即可看到运行的容器。 -
识别 Nginx 容器:在运行的容器列表中找到 Nginx 容器,它对外访问的是 80 端口。
-
外部访问端口:这个端口(80)是外部访问的端口。
4. 注意事项
-
访问地址:注意,您可以通过
10.80.2.195:80访问 Dify。 -
环境匹配:请确保您的环境配置与
.env文件中的设置相匹配。

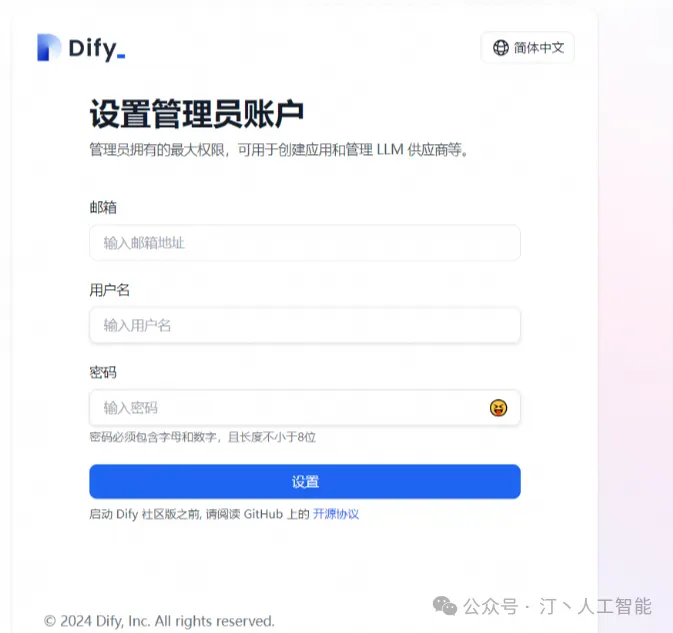
随便填写,进入界面
- 自定义配置
编辑 .env 文件中的环境变量值。然后,重新启动 Dify:
docker compose down
docker compose up -d
完整的环境变量集合可以在 docker/.env.example 中找到。
2.2 本地码源部署
- 前置条件

Clone Dify 代码:
git clone https://github.com/langgenius/dify.git
在启用业务服务之前,需要先部署 PostgresSQL / Redis / Weaviate(如果本地没有的话),可以通过以下命令启动:
cd docker
cp middleware.env.example middleware.env
docker compose -f docker-compose.middleware.yaml up -d
服务端部署步骤
安装基础环境
服务器启动需要 Python 3.10.x。推荐使用 Anaconda 进行安装。参考文章:
- Linux和Windows系统下: 安装Anaconda
- Anaconda安装超简洁教程
也可以使用 pyenv,执行以下命令安装 Python 3.10 并切换到该环境:
bashpyenv install 3.10pyenv global 3.10
进入 API 目录
- 首先,确保已经安装了所需的依赖包。可以使用
pip或conda来安装。2. 然后,进入 api 目录,开始配置和启动服务。
cd api
- 复制环境变量配置文件.
cp .env.example .env
- 生成随机密钥,并替换 .env 中 SECRET_KEY 的值
openssl rand -base64 42
sed -i 's/SECRET_KEY=.*/SECRET_KEY=<your_value>/' .env
- 安装依赖包
Dify API 服务使用 Poetry 来管理依赖。您可以执行 poetry shell 来激活环境。
poetry env use 3.10
poetry install
- 执行数据库迁移,将数据库结构迁移至最新版本。
poetry shell
flask db upgrade
- 启动 API 服务
flask run --host 0.0.0.0 --port=5001 --debug
正确输出:
* Debug mode: on
INFO:werkzeug:WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5001
INFO:werkzeug:Press CTRL+C to quit
INFO:werkzeug: * Restarting with stat
WARNING:werkzeug: * Debugger is active!
INFO:werkzeug: * Debugger PIN: 695-801-919
- 启动 Worker 服务
用于消费异步队列任务,如数据集文件导入、更新数据集文档等异步操作。Linux / MacOS 启动:
celery -A app.celery worker -P gevent -c 1 -Q dataset,generation,mail,ops_trace --loglevel INFO
如果使用 Windows 系统启动,请替换为该命令:
celery -A app.celery worker -P solo --without-gossip --without-mingle -Q dataset,generation,mail,ops_trace --loglevel INFO
-------------- celery@TAKATOST.lan v5.2.7 (dawn-chorus)
--- ***** -----
-- ******* ---- macOS-10.16-x86_64-i386-64bit 2023-07-31 12:58:08
- *** --- * ---
- ** ---------- [config]
- ** ---------- .> app: app:0x7fb568572a10
- ** ---------- .> transport: redis://:**@localhost:6379/1
- ** ---------- .> results: postgresql://postgres:**@localhost:5432/dify
- *** --- * --- .> concurrency: 1 (gevent)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> dataset exchange=dataset(direct) key=dataset
.> generation exchange=generation(direct) key=generation
.> mail exchange=mail(direct) key=mail
[tasks]
. tasks.add_document_to_index_task.add_document_to_index_task
. tasks.clean_dataset_task.clean_dataset_task
. tasks.clean_document_task.clean_document_task
. tasks.clean_notion_document_task.clean_notion_document_task
. tasks.create_segment_to_index_task.create_segment_to_index_task
. tasks.deal_dataset_vector_index_task.deal_dataset_vector_index_task
. tasks.document_indexing_sync_task.document_indexing_sync_task
. tasks.document_indexing_task.document_indexing_task
. tasks.document_indexing_update_task.document_indexing_update_task
. tasks.enable_segment_to_index_task.enable_segment_to_index_task
. tasks.generate_conversation_summary_task.generate_conversation_summary_task
. tasks.mail_invite_member_task.send_invite_member_mail_task
. tasks.remove_document_from_index_task.remove_document_from_index_task
. tasks.remove_segment_from_index_task.remove_segment_from_index_task
. tasks.update_segment_index_task.update_segment_index_task
. tasks.update_segment_keyword_index_task.update_segment_keyword_index_task
[2024-07-31 13:58:08,831: INFO/MainProcess] Connected to redis://:**@localhost:6379/1
[2024-07-31 13:58:08,840: INFO/MainProcess] mingle: searching for neighbors
[2024-07-31 13:58:09,873: INFO/MainProcess] mingle: all alone
[2024-07-31 13:58:09,886: INFO/MainProcess] pidbox: Connected to redis://:**@localhost:6379/1.
[2024-07-31 13:58:09,890: INFO/MainProcess] celery@TAKATOST.lan ready.
Node.js 安装指南
1. 安装 Node.js
-
下载 Node.js: 访问 Node.js 官网 下载页面。
-
选择版本: 选择适合您操作系统的 Node.js v18.x (LTS) 版本。
-
安装: 下载后,根据操作系统的提示完成安装。
2. 安装 NPM
-
版本要求: 需要 NPM 版本为 8.x.x。
-
安装: Node.js 安装包中已包含 NPM,无需单独安装。
3. 使用 Web 前端服务
- 启动服务: 安装完成后,您可以启动您的 Web 前端服务。
4. 验证安装
-
验证 Node.js: 在命令行中输入
node -v,应显示版本号v18.x.x。 -
验证 NPM: 在命令行中输入
npm -v,应显示版本号8.x.x。
5. 使用 Yarn 作为替代
- 安装 Yarn: 如果您选择使用 Yarn 作为包管理器,可以访问 Yarn 官网 下载并安装。
注意事项
-
环境配置: 安装完成后,请确保环境变量配置正确。
-
版本问题: 如果遇到版本兼容性问题,请参考 Node.js 官网的文档或联系技术支持。 附加信息:
-
阅读更新日志: 了解 Node.js 的更新内容。
-
阅读博客: 获取 Node.js 的最新动态。
-
验证 SHASUMS: 学习如何验证下载文件的签名。
-
社区支持: 探索其他社区支持的包管理器。
cd web
npm install
```
#For production release, change this to PRODUCTION
NEXT_PUBLIC_DEPLOY_ENV=DEVELOPMENT
#The deployment edition, SELF_HOSTED
NEXT_PUBLIC_EDITION=SELF_HOSTED
#The base URL of console application, refers to the Console base URL of WEB service if console domain is
#different from api or web app domain.
#example: http://cloud.dify.ai/console/api
NEXT_PUBLIC_API_PREFIX=http://localhost:5001/console/api
#The URL for Web APP, refers to the Web App base URL of WEB service if web app domain is different from
#console or api domain.
#example: http://udify.app/api
NEXT_PUBLIC_PUBLIC_API_PREFIX=http://localhost:5001/api
#SENTRY
NEXT_PUBLIC_SENTRY_DSN=
NEXT_PUBLIC_SENTRY_ORG=
NEXT_PUBLIC_SENTRY_PROJECT=
```
npm run build
npm run start
#or
yarn start
#or
pnpm start
```
ready - started server on 0.0.0.0:3000, url: http://localhost:3000
warn - You have enabled experimental feature (appDir) in next.config.js.
warn - Experimental features are not covered by semver, and may cause unexpected or broken application behavior. Use at your own risk.
info - Thank you for testing appDir please leave your feedback at https://nextjs.link/app-feedback
```
Dify 部署指南
2.2 启动 Web 服务
- 构建代码并启动 web 服务。
- 配置环境变量。在当前目录下创建文件
.env.local,并将.env.example文件中的内容复制到.env.local中。根据实际需求修改这些环境变量的值。 - 进入
web目录,并安装依赖包。 - 在浏览器中输入
http://localhost或者http://127.0.0.1:3000来访问本地部署的 Dify 应用。
2.3 单独启动前端 Docker 容器
当单独开发后端时,如果不需要本地构建前端代码并启动,可以使用以下步骤直接通过 Docker 镜像来启动前端服务:
- 从 DockerHub 拉取前端镜像,并运行容器以启动前端服务。 aaaaaaa注意:确保按照上述步骤正确配置和启动服务。
docker run -it -p 3000:3000 -e CONSOLE_API_URL=http://127.0.0.1:5001 -e APP_API_URL=http://127.0.0.1:5001 langgenius/dify-web:latest
- 源码构建 Docker 镜像
cd web && docker build . -t dify-web
```
docker run -it -p 3000:3000 -e CONSOLE_API_URL=http://127.0.0.1:5001 -e APP_API_URL=http://127.0.0.1:5001 dify-web
```
-
当控制台域名和 Web APP 域名不一致时,可单独设置 CONSOLE_URL 和 APP_URL
本地访问 http://127.0.0.1:3000 -
启动前端镜像
-
构建前端镜像
3. Ollama 部署的本地模型
Ollama 是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。,这是 Ollama 的官网地址:https://ollama.com/
- 以下是其主要特点和功能概述:
-
简化部署:Ollama 目标在于简化在 Docker 容器中部署大型语言模型的过程,使得非专业用户也能方便地管理和运行这些复杂的模型。
-
轻量级与可扩展:作为轻量级框架,Ollama 保持了较小的资源占用,同时具备良好的可扩展性,允许用户根据需要调整配置以适应不同规模的项目和硬件条件。
-
API支持:提供了一个简洁的 API,使得开发者能够轻松创建、运行和管理大型语言模型实例,降低了与模型交互的技术门槛。
-
预构建模型库:包含一系列预先训练好的大型语言模型,用户可以直接选用这些模型应用于自己的应用程序,无需从头训练或自行寻找模型源
3.1 一键安装
curl: (77) error setting certificate verify locations:CAfile: /data/usr/local/anaconda/ssl/cacert.pemCApath: none 报错原因:cacert.pem 的寻址路径 CAfile 不对,也就是在该路径下找不到文件。
- 解决方法:
-
找到你的 cacert.pem 文件所在位置 /path/to/cacert.pem。如果你没有该证书,可以先在 https://curl.se/ca/cacert.pem 下载,保存在某个目录中。
-
设置环境变量
export CURL_CA_BUNDLE=/path/to/cacert.pem
#将"/path/to/cacert.pem"替换为你的证书文件的实际路径。
export CURL_CA_BUNDLE=/www/anaconda3/anaconda3/ssl/cacert.pem
- 执行下载
curl -fsSL https://ollama.com/install.sh | sh
3.2 手动安装
ollama中文网:https://ollama.fan/getting-started/linux/
- 下载 ollama 二进制文件:Ollama 以自包含的二进制文件形式分发。将其下载到您的 PATH 中的目录:
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
- 将 Ollama 添加为启动服务(推荐):为 Ollama 创建一个用户:
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama
3.在 /etc/systemd/system/ollama.service 中创建一个服务文件:
#vim ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
[Install]
WantedBy=default.target
- 然后启动服务:
sudo systemctl enable ollama
- 启动 Ollama¶ 使用 systemd 启动 Ollama:
sudo systemctl start ollama
- 更新,查看日志
#再次运行
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
#要查看作为启动服务运行的 Ollama 的日志,请运行:
journalctl -u ollama
- 步骤7:关闭 Ollama 服务
#关闭ollama服务
service ollama stop
3.3 Linux内网离线安装Ollama
- 查看服务器CPU的型号
##查看Linux系统CPU型号命令,我的服务器cpu型号是x86_64
lscpu
- 步骤2:根据CPU型号下载Ollama安装包,并保存到目录
下载地址:https://github.com/ollama/ollama/releases/
#x86_64 CPU选择下载ollama-linux-amd64
#aarch64|arm64 CPU选择下载ollama-linux-arm64
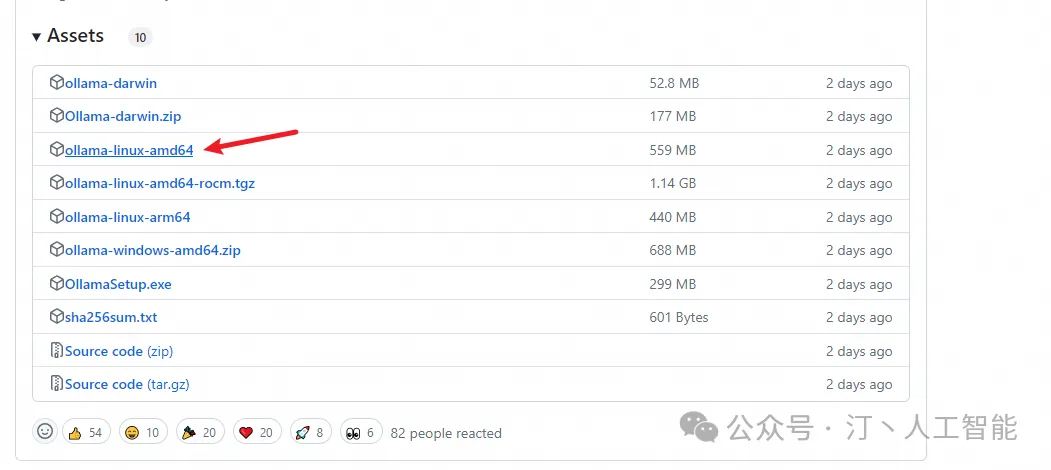
#有网机器下载过来也一样
wget https://ollama.com/download/ollama-linux-amd64
3.4 修改存储路径
Ollama模型默认存储在不同的操作系统路径下:
-
macOS:
~/.ollama/models -
Linux:
/usr/share/ollama/.ollama/models -
Windows:
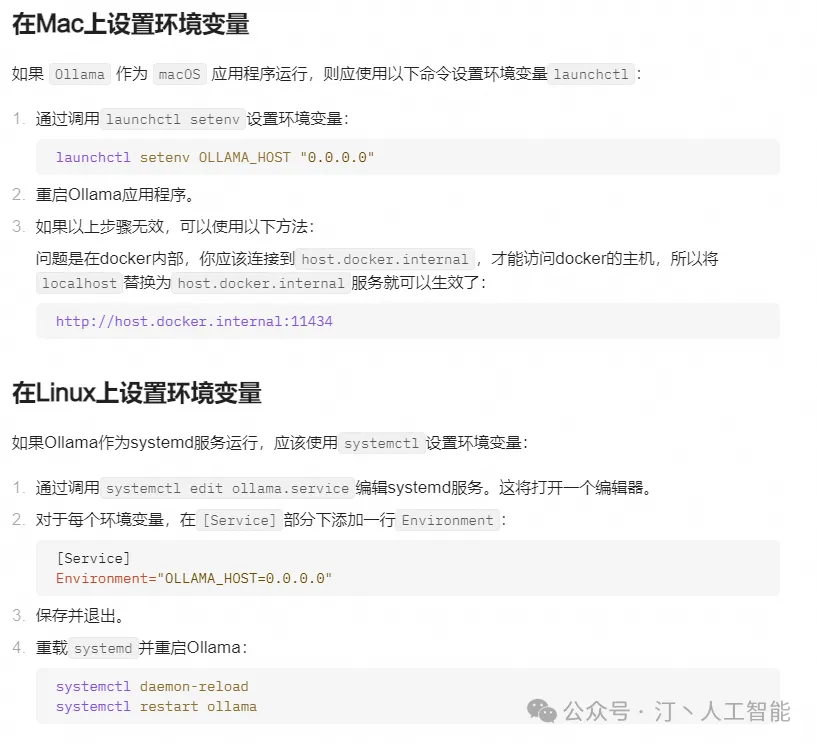
C:\Users\<username>\.ollama\models如果Ollama作为systemd服务运行,您可以通过以下步骤设置环境变量:
-
编辑Systemd服务: 通过调用
systemctl edit ollama.service来编辑Ollama的systemd服务。这将打开一个编辑器。 -
设置环境变量: 对于每个需要设置的环境变量,在
[Service]部分下添加一行。例如:
[Service]
Environment="VARIABLE_NAME=VALUE"
注意: 直接在/etc/systemd/system/ollama.service文件中添加如下两行:
[Service]
Environment="MODEL_PATH=/usr/bin/ollama"
请根据您的实际路径调整MODEL_PATH的值。
[Service]
Environment="OLLAMA_HOST=0.0.0.0:7861"
Environment="OLLAMA_MODELS=/www/algorithm/LLM_model/models"
-
保存并退出。
-
重新加载systemd并重新启动 Ollama:
systemctl restart ollama
参考链接:https://github.com/ollama/ollama/blob/main/docs/faq.md
- 使用 systemd 启动 Ollama:
sudo systemctl start ollama
- 终止
终止(ollama加载的大模型将会停止占用显存,此时ollama属于失联状态,部署和运行操作失效,会报错:
Error: could not connect to ollama app, is it running?需要启动后,才可以进行部署和运行操作
systemctl stop ollama.service
- 终止后启动(启动后,可以接着使用ollama 部署和运行大模型)
systemctl start ollama.service
3.5 启动LLM
- 下载模型
ollama pull llama3.1
ollama pull qwen2
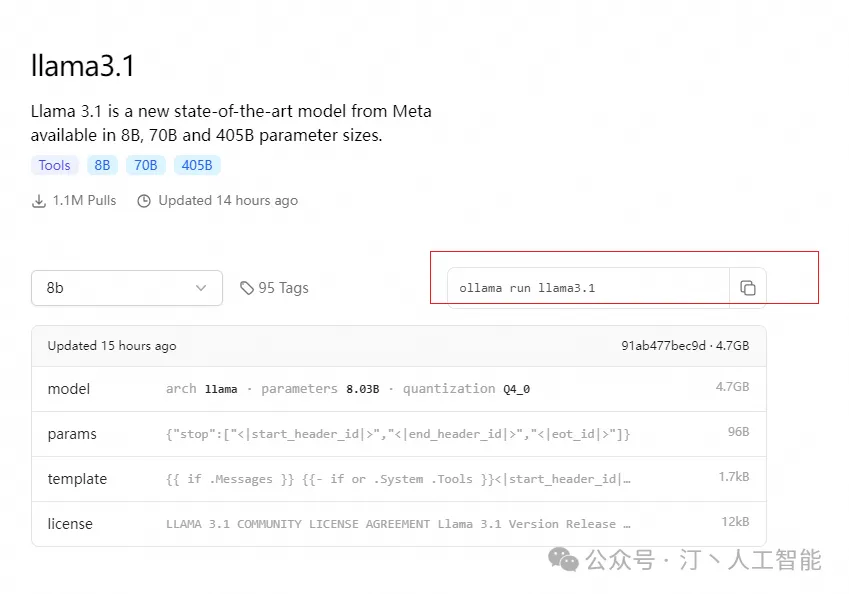
- 运行大模型
ollama run llama3.1
ollama run qwen2

- 查看是否识别到大模型:
ollama list, 如果成功, 则会看到大模型
ollama list
NAME ID SIZE MODIFIED
qwen2:latest e0d4e1163c58 4.4 GB 3 hours ago
- 使用该
ollama ps命令查看当前已加载到内存中的模型。
NAME ID SIZE PROCESSOR UNTIL
qwen2:latest e0d4e1163c58 5.7 GB 100% GPU 3 minutes from now
- nvidia-smi查看
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.86.10 Driver Version: 535.86.10 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla V100-SXM2-32GB On | 00000000:00:08.0 Off | 0 |
| N/A 35C P0 56W / 300W | 5404MiB / 32768MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 3062036 C ...unners/cuda_v11/ollama_llama_server 5402MiB |
+---------------------------------------------------------------------------------------+
- 启动后,我们可验证是否可用:
curl http://10.80.2.195:7861/api/chat -d '{
"model": "llama3.1",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
3.6 更多其他配置
Ollama 可以设置的环境变量:
-
OLLAMA_HOST:定义了Ollama监听的网络接口。通过设置OLLAMA_HOST=0.0.0.0,可以让Ollama监听所有可用的网络接口,允许外部访问。 -
OLLAMA_MODELS:指定了模型镜像的存储路径。如OLLAMA_MODELS=F:\OllamaCache,可以将模型文件存储在指定位置,解决C盘空间不足问题。 -
OLLAMA_KEEP_ALIVE:控制模型在内存中的存活时间。例如,OLLAMA_KEEP_ALIVE=24h表示模型保持加载状态24小时,提高响应速度。 -
OLLAMA_PORT:更改Ollama的服务端口。比如OLLAMA_PORT=8080将默认端口11434改为8080。 -
OLLAMA_NUM_PARALLEL:决定Ollama同时处理的并发请求量。设定OLLAMA_NUM_PARALLEL=4允许同时处理四个并发请求。 -
OLLAMA_MAX_LOADED_MODELS:限制同时加载的模型数量。设置为OLLAMA_MAX_LOADED_MODELS=4有助于合理分配系统资源。
注意: 使用
Environment="OLLAMA_PORT=9380"这样的方式无效。 正确的做法是直接指定主机和端口,例如:
Environment="OLLAMA_HOST=0.0.0.0:7861"
指定 GPU 运行 Ollam
a若您的系统中安装有多张GPU,并希望Ollama运行在特定的GPU上,在Linux环境下可以通过创建一个配置文件并设置CUDA_VISIBLE_DEVICES环境变量来实现。该变量用于控制哪些GPU对应用程序可见。假设要使用第一张GPU(索引从0开始),您可以在启动Ollama前设置如下环境变量:
|
|
之后重启Ollama服务即可生效。
vim /etc/systemd/system/ollama.service
[Service]
Environment="CUDA_VISIBLE_DEVICES=0,1"
3.7 Ollama常见命令
- 重启 ollama
systemctl daemon-reload
systemctl restart ollama
- 重启 ollama 服务
ubuntu/debian
sudo apt update
sudo apt install lsof
stop ollama
lsof -i :11434
kill <PID>
ollama serve
- Ubuntu
sudo apt update
sudo apt install lsof
stop ollama
lsof -i :11434
kill <PID>
ollama serve
- 确认服务端口状态:
netstat -tulpn | grep 11434
- 配置服务
为使外网环境能够访问到服务,需要对 HOST 进行配置。
打开配置文件:
vim /etc/systemd/system/ollama.service
根据情况修改变量 Environment:
服务器环境下:
Environment="OLLAMA_HOST=0.0.0.0:11434"
虚拟机环境下:
Environment="OLLAMA_HOST=服务器内网IP地址:11434"
3.8 卸载Ollama
如果决定不再使用Ollama,可以通过以下步骤将其完全从系统中移除:
(1)停止并禁用服务:
sudo systemctl stop ollama
sudo systemctl disable ollama
(2)删除服务文件和Ollama二进制文件:
sudo rm /etc/systemd/system/ollama.service
sudo rm $(which ollama)
(3)清理Ollama用户和组:
sudo rm -r /usr/share/ollama
sudo userdel ollama
sudo groupdel ollama
通过以上步骤,不仅能够在Linux平台上成功安装和配置Ollama,还能够灵活地进行更新和卸载。
4.配置LLM+Dify
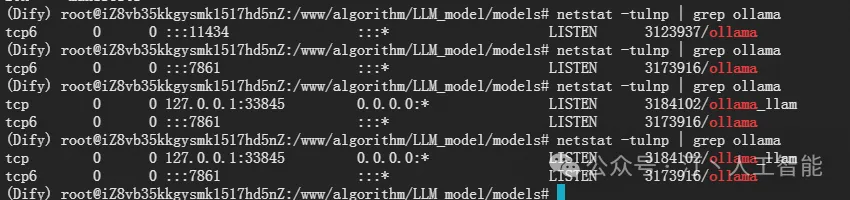
- 确认服务端口状态:
netstat -tulnp | grep ollama
#netstat -tulpn | grep 11434
- 报错:“Error: could not connect to ollama app, is it running?”
参考链接:https://stackoverflow.com/questions/78437376/run-ollama-run-llama3-in-colab-raise-err-error-could-not-connect-to-ollama
/etc/systemd/system/ollama.service文件是:
[Service]
ExecStart=/usr/local/bin/ollama serve
Environment="OLLAMA_HOST=0.0.0.0:7861"
Environment="OLLAMA_KEEP_ALIVE=-1"
- 运行指令
export OLLAMA_HOST=0.0.0.0:7861
ollama list
ollama run llama3.1
#直接添加到环境变量也可以
vim ~/.bashrc
source ~/.bashrc
在 设置 > 模型供应商 > Ollama 中填入:
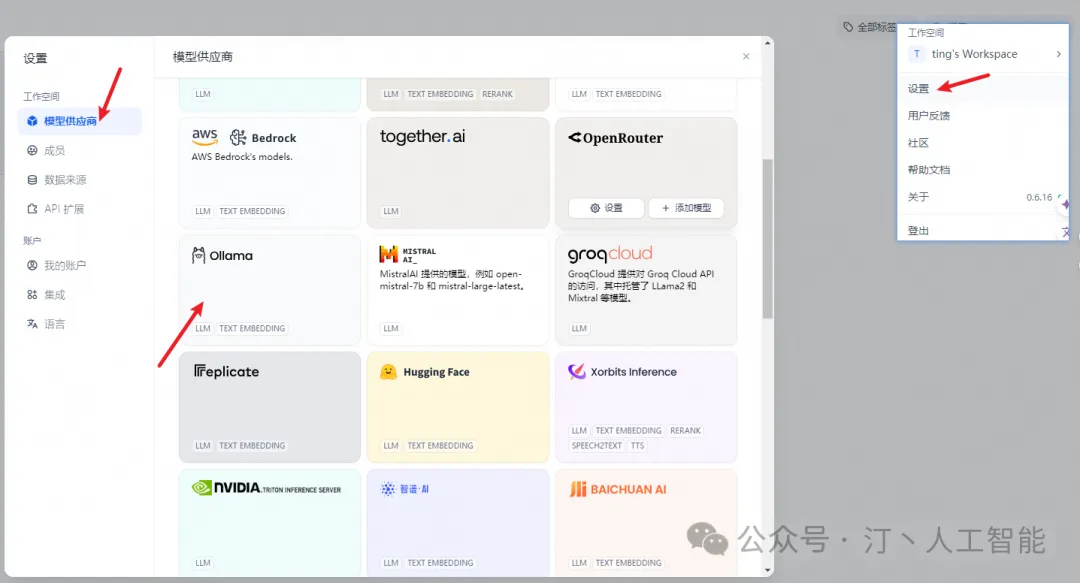
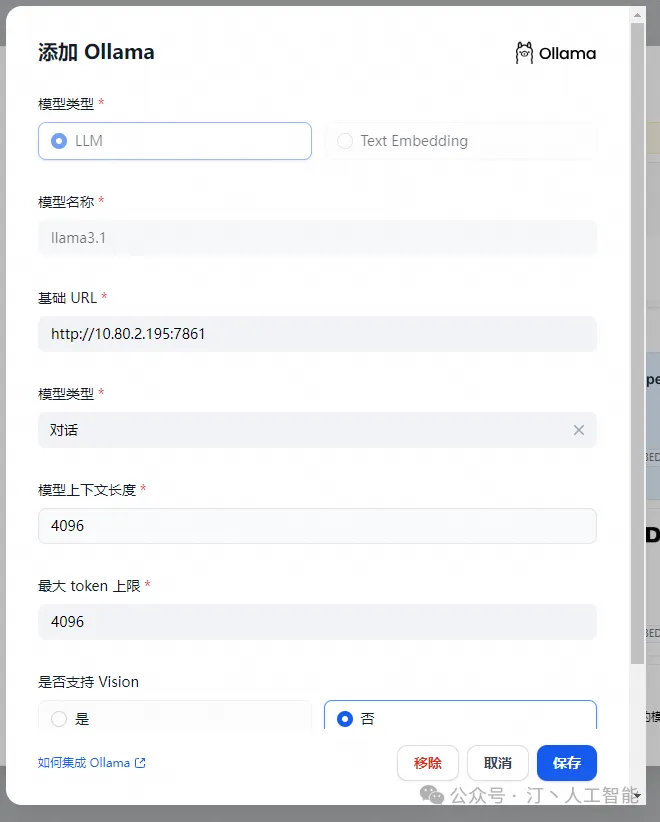
-
模型名称:llama3.1
-
基础 URL:
http://<your-ollama-endpoint-domain>:11434 -
此处需填写可访问到的 Ollama 服务地址。
-
若 Dify 为 docker 部署,建议填写局域网 IP 地址,如:
http://10.80.2.195:11434或 docker 宿主机 IP 地址,如:http://172.17.0.1:11434。 -
若为本地源码部署,可填写
http://localhost:11434。 -
模型类型:对话
-
模型上下文长度:4096
-
模型的最大上下文长度,若不清楚可填写默认值 4096。
-
最大 token 上限:4096
-
模型返回内容的最大 token 数量,若模型无特别说明,则可与模型上下文长度保持一致。
-
是否支持 Vision:是
-
当模型支持图片理解(多模态)勾选此项,如 llava。
-
点击 “保存” 校验无误后即可在应用中使用该模型。
-
Embedding 模型接入方式与 LLM 类似,只需将模型类型改为 Text Embedding 即可。
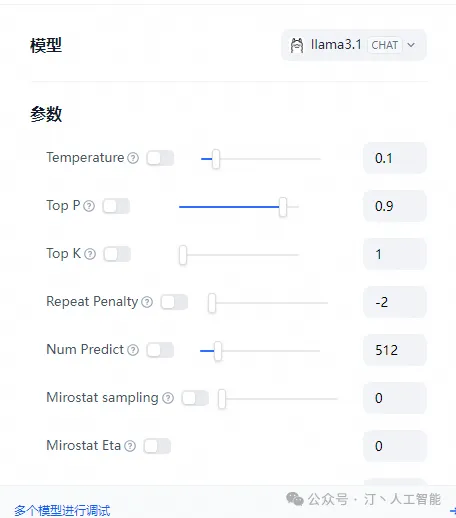
- 如果您使用Docker部署Dify和Ollama,您可能会遇到以下错误:
httpconnectionpool(host=127.0.0.1, port=11434): max retries exceeded with url:/cpi/chat (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>: fail to establish a new connection:[Errno 111] Connection refused'))
httpconnectionpool(host=localhost, port=11434): max retries exceeded with url:/cpi/chat (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>: fail to establish a new connection:[Errno 111] Connection refused'))
这个错误是因为 Docker 容器无法访问 Ollama 服务。localhost 通常指的是容器本身,而不是主机或其他容器。要解决此问题,您需要将 Ollama 服务暴露给网络。
4.1.多模型对比
参考单个模型部署一样,进行再一次配置添加即可
- 需要注意的是添加完新的模型配置后,需要刷新dify网页,直接网页端刷新就好,新添加的模型就会加载进来
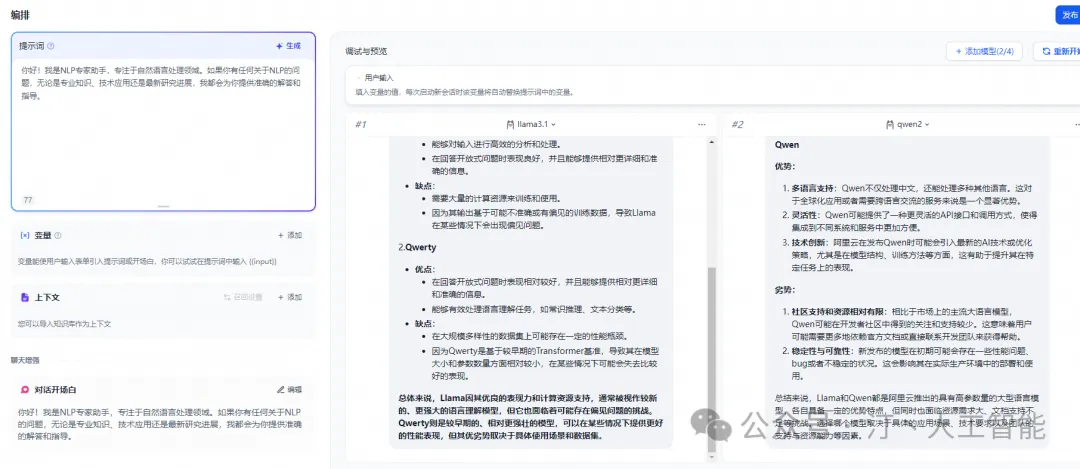
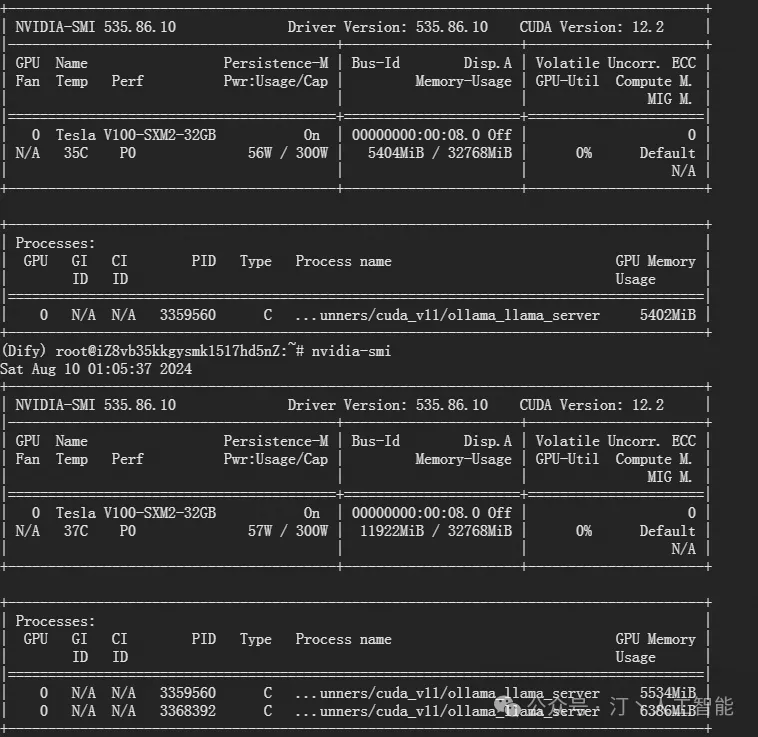
- 可以看到调用后模型资源消耗情况

AI技术资源推荐
探索人工智能技术,尤其是大型语言模型(LLM)的众多应用和开发框架。以下是一些精选的资源和工具,可以帮助您深入了解并应用这些强大的技术。
LLM框架对比
-
MaxKB、Dify、FastGPT、RagFlow等框架的全面对比分析,帮助您选择最适合的AI工作流和Agent解决方案。
国内大模型+Agent应用案例
-
精选案例展示了国内大模型和Agent框架的应用实例,以及主流Agent框架的开源项目推荐。
开发平台
LLM模型资源
技术文章与资源
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek002/post/20240918/Dify-LLM%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%B9%B3%E5%8F%B0%E6%97%A0%E7%BC%9D%E9%9B%86%E6%88%90%E7%AC%AC%E4%B8%89%E6%96%B9%E7%B3%BB%E7%BB%9F--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com