构建Agentic RAG AI Agent智能体教程 --知识铺
什么是Agentic RAG
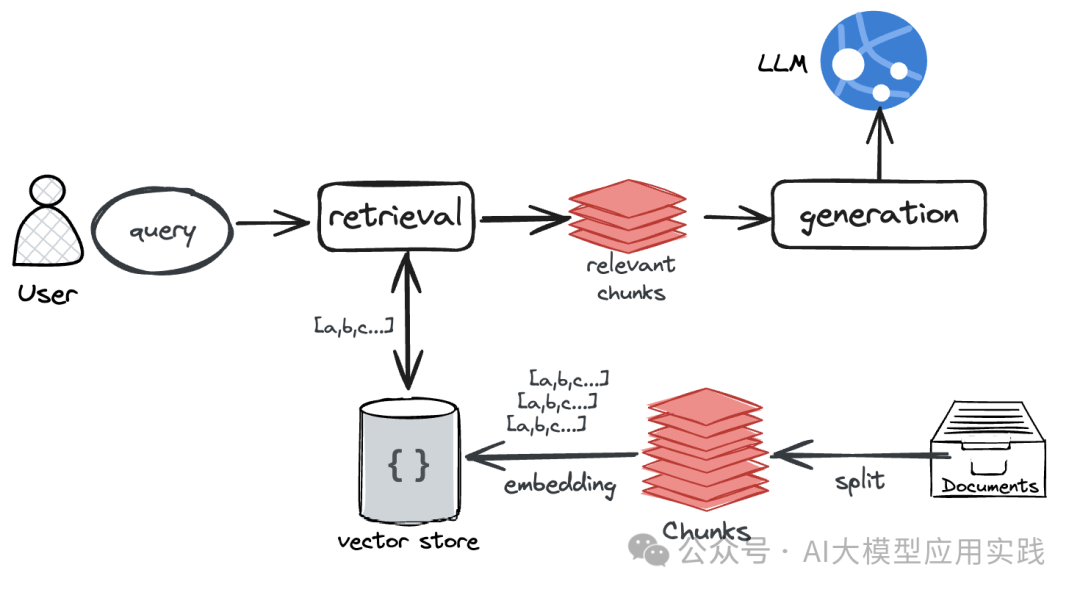
RAG (Retrieval-Augmented Generation) 是一种结合了信息检索和生成模型的技术,旨在通过从大量文档中检索相关信息来增强大语言模型(LLM)的回答质量。经典的RAG应用范式及架构已经变得非常流行,允许开发者快速构建一个能够有效处理用户查询的应用。
经典RAG工作流程
- 接收用户问题
- 用户向系统提出一个问题或请求。
- 执行检索
- 应用程序使用预先向量化的文档库执行检索操作,寻找与用户查询最相关的知识片段。
- 合成响应
- 检索到的相关知识被送入到大语言模型中,模型基于这些信息生成一个准确且上下文相关的回答给用户。
向量化是这个过程中的一个重要步骤,它将文本数据转换成数值型向量表示,以便于后续的高效检索和处理。这一步骤对于提高整个RAG系统的效率至关重要。
Agentic RAG方案是一种基于AI Agent的方法,旨在解决企业中大量不同来源与类型的文档的知识密集型应用需求。它通过协调多个AI Agent的任务规划和工具能力,实现对多文档的、多类型的问答需求。
Agentic RAG方案的核心概念架构包括以下几个部分:
-
全局理解文档:Agentic RAG能够对文档进行全局的理解,从而回答关于知识内容的问题,如总结摘要等。
-
跨文档与知识库回答问题:Agentic RAG能够比较不同文档的内容,并回答关于它们之间差异的问题。
-
结合非知识工具的复合场景:Agentic RAG能够将文档中的信息提取出来,并与非知识工具相结合,实现复杂的应用场景,如向特定客户发送产品介绍等。 与传统的RAG架构相比,Agentic RAG方案具有更强的适应性和灵活性。虽然经典RAG在回答事实性问题时表现不错,但在处理跨文档或需要结合其他工具的场景时可能无法胜任。而Agentic RAG则借助AI Agent的任务规划和工具能力,能够更好地满足这些复杂需求。 Agentic RAG方案的实施步骤如下:
-
设计并训练AI Agent,使其具备任务规划和工具使用的能力。
-
配置Agentic RAG系统,使其能够管理和协调多个AI Agent的工作。
-
提供适当的输入数据和文档集合,以便Agentic RAG系统进行处理。
-
通过Agentic RAG系统,根据用户需求调用相应的AI Agent来完成特定的任务。
-
收集和分析结果,以评估Agentic RAG方案的性能和效果。 总之,Agentic RAG方案通过整合AI Agent的任务规划和工具能力,为处理企业中大量不同来源与类型的文档提供了一种有效的解决方案。它可以帮助企业更好地理解和利用这些文档中的知识,以满足各种复杂的问答需求。
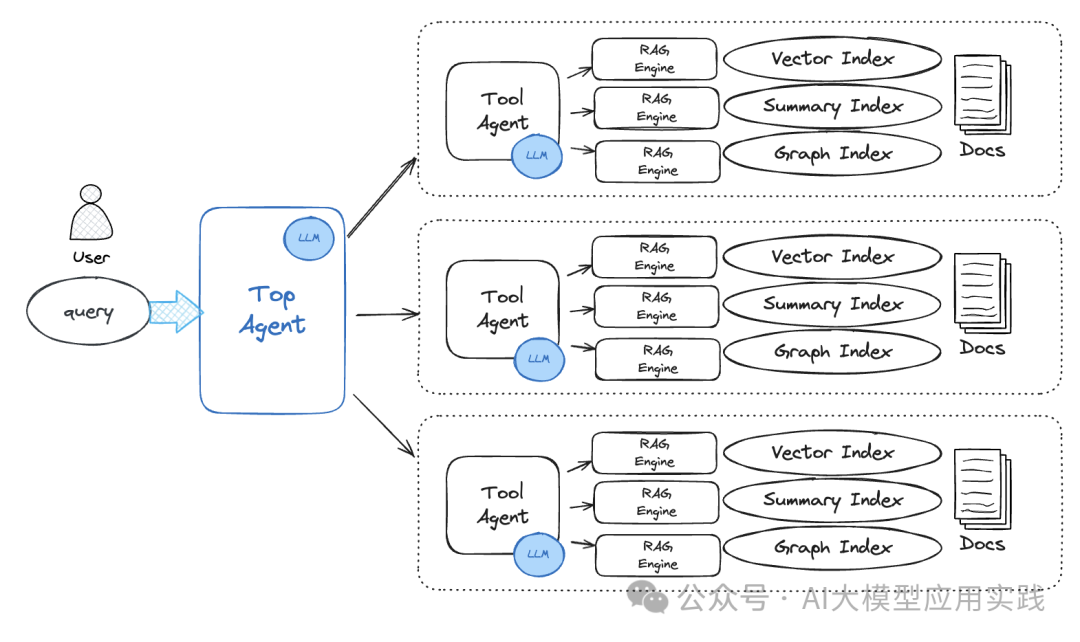
aaaaaaa在Agentic RAG架构中,RAG应用(或称RAG引擎)被设计为一种知识工具,供Agent使用。这种架构允许你针对单个文档或知识库构建不同类型的RAG引擎,每种引擎专长于处理特定类型的问题。例如:
- 向量索引RAG引擎:用于快速检索和回答基于事实性的问题。
- 摘要索引RAG引擎:适合用来生成对内容的总结性回复。
- 知识图谱索引RAG引擎:能够解答那些需要理解上下文关联性的问题。 为了有效地管理这些不同的RAG引擎,引入了ToolAgent的概念。ToolAgent的角色是作为一个智能代理,它将各种RAG引擎作为自己的工具集,并通过大型语言模型(LLM)的能力,在负责的文档范围内选择合适的工具来回应用户提问。 更进一步地,整个系统由一个顶级代理TopAgent进行总体管理。TopAgent同样利用LLM的功能来规划、协调以及执行跨多个ToolAgent的复杂问题解决策略。这样,无论是从单一文档还是跨越多文档的知识查询,都能得到高效而准确的回答。 【实现Agentic RAG】 要开始实施这样一个简单的Agentic RAG系统,首先我们需要准备测试用的数据文件。假设我们有三个关于RAG主题的PDF文档,接下来步骤包括但不限于:
- 确定每个文档的名称与存储路径。2. 利用LlamaIndex或其他类似技术创建不同类型(如向量、摘要等)的索引。3. 对每个文档建立相应的RAG引擎实例。4. 定义ToolAgents并将它们绑定到各自的RAG引擎上。5. 配置TopAgent以统筹所有ToolAgents的工作流程。 此架构不仅适用于小规模测试,而且可以通过适当调整支持大规模文档集合。
|
|
【准备创建Tool Agent的函数】
创建一个针对单个文档生成Tool Agent的函数,在这个函数中,将对一个文档创建两个索引与对应的RAG引擎:
-
针对普通事实性问题的向量索引与RAG引擎
-
针对更高层语义理解的总结类问题的摘要索引与RAG引擎
最后,我们把这两个引擎作为一个Agent可使用的两个tool,构建一个Tool Agent返回。
|
|
这部分代码主要目的就是把两个查询的RAG引擎包装成工具(一个是query_tool,用于回答事实性问题;一个是summary_tool用于回答总结性问题,当然你还可以构建更多类型的引擎),最后构建一个ReAct思考范式的AI Agent,并把构建的RAG tools插入。
如果你了解LlamaIndex,可能会使用路由RouteQueryEngine来代替这里的Agent,实现接近的功能。但是要注意,Router与Agent是有区别的,路由仅仅是起到一个“选择”工具与“转发”的作用,并不会做多次迭代;而Agent则会观察工具返回的结果,且有可能会使用多个工具通过迭代来完成任务。
【批量创建Tool Agent】
有了上面的函数后,就可以批量创建好这些文档的Tool Agent。这里把每一个文档名字和对应的Agent保存在一个dict中:
|
|
【创建Top Agent】
最后,我们需要创建一个顶层的Top Agent,这个Agent的作用是接收客户的请求问题,然后规划这个问题的查询计划,并使用工具来完成,而这里的工具就是上面创建好的多个Tool Agent:
|
|
注意这里我们创建的Top Agent使用了OpenAIAgent,而不是ReActAgent,这也展示了这种架构的灵活性:不同Agent可以按需使用不同的推理范式。
【测试】
现在来简单测试这个Top Agent,并观察其执行的过程:
|
|
输入一个问题:Please introduce Retrieval Evaluator in C-RAG pattern?
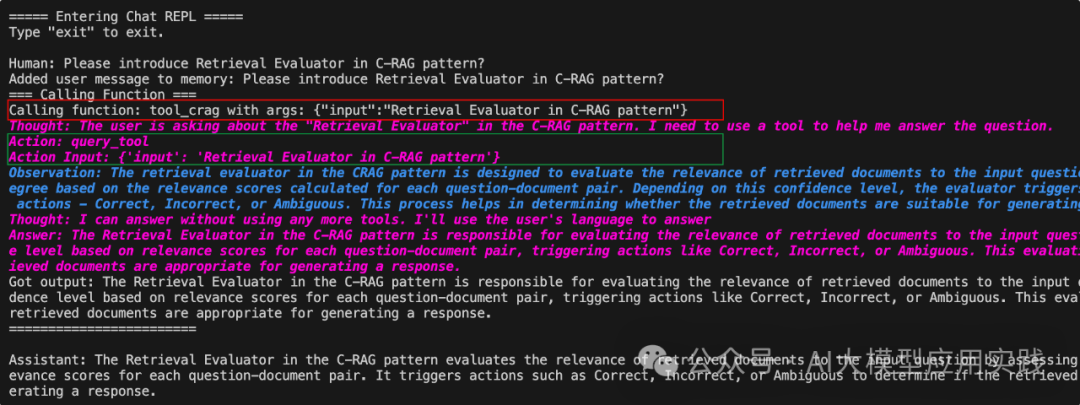
注意观察这里红线与绿色部分内容,可以看出Agent的“思考”过程:
1.在TopAgent这一层,由于我们使用了OpenAIAgent,其是通过OpenAI的function calling来实现,因此这里显示LLM要求进行函数调用,需要调用tool_crag,输入参数为"Retrieval Evaluator in C-RAG pattern"。而这里的函数名tool_crag,也就是后端Tool Agent的名称。
2.然后来到Tool Agent层,Tool Agent收到请求后,通过ReAct范式的思考过程,决定需要调用query_tool工具,也就是通过向量索引进行响应的RAG引擎。在调用这个引擎后,获得了返回内容(observation的内容)。收到返回后Tool Agent通过观察与推理,认为可以回答这个问题,因此Tool Agent运行结束,并返回结果给Top Agent
3.Top Agent收到函数调用的结果后,认为无需再次进行其他函数调用,因此直接输出了结果,整个迭代过程结束。
当然,你也可以自行测试更复杂的文档任务,比如:要求对比两个文档中某个知识点的区别等。
03
HOT SUMMER
进一步优化Agentic RAG
上面我们只用了三个文档,构建了针对他们的Tool Agent。那么如果这里的文档数量是几十或者几百,过多的Tool Agent作为Tools塞给Top Agent进行推理选择时会带来一些问题:
-
LLM产生困惑并推理错误的概率会提高
-
过多的Tools信息导致上下文过大,成本与延迟增加
一种可行的方法是:**利用RAG的思想对Tools进行检索,即只把本次输入问题语义相关的Tools(即这里的多个ToolAgent)交给Top Agent使用。**这里借助LlamaIndex中的Object Index来实现:Object Index可以对任意Python对象构建向量化的索引,并通过输入问题来检索出相关的Objects。
现在可以对上面的代码做简单的改造,给Top Agent在推理时增加tools检索功能,从而能够缩小tools选择的范围。只需要在创建Top Agent之前针对tools创建一个Object Index的检索器用来根据输入问题检索相关的tools:
|
|
然后将创建Top Agent的代码做简单的修改,不再传入all_tools,而是传入tools检索器:
|
|
现在如果你继续测试这个Agent,会发现仍然可以达到相同的效果。当然,如果你需要验证这里检索出来的tools正确性,可以直接对tool_retriever调用检索方法来观察(输入相同的自然语言问题)输出的tools信息:
|
|
Agentic RAG总结 相对于更适用于对几个文档进行简单查询的经典RAG应用,Agentic RAG的方法通过更具有自主能力的AI Agent来对其进行增强,具备了极大的灵活性与扩展性,几乎可以完成任意基于知识的复杂任务:
-
基于RAG之上的Tool Agent将不再局限于简单的回答事实性的问题,通过扩展更多的后端RAG引擎,可以完成更多的知识型任务。比如:整理、摘要生成、数据分析、甚至借助API访问外部系统等
-
Top Agent管理与协调下的多个Tool Agent可以通过协作完成联合型的任务。比如对两个不同文档中的知识做对比与汇总,这也是经典问答型的RAG无法完成的任务类型。
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek002/post/20240918/%E6%9E%84%E5%BB%BAAgentic-RAG-AI-Agent%E6%99%BA%E8%83%BD%E4%BD%93%E6%95%99%E7%A8%8B--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com