微软Edge-TTS:免费开源AI中文语音工具 --知识铺
Edge-TTS是一个由微软推出的Python库,用于将文本转换为语音。它利用了微软Azure Cognitive Services的功能,无需Microsoft Edge、Windows或API密钥即可使用。该库支持40多种语言和300种声音,为用户提供高质量的语音输出。作为国内付费TTS服务的替代品,Edge-TTS在GitHub上获得了超过3000颗星,受到了开发者们的广泛欢迎。 Edge-TTS的主要特点包括:
- 无需安装Microsoft Edge或Windows操作系统。2. 无需API密钥,直接使用。3. 支持40多种语言和300种声音选择。4. 提供高质量的语音输出,满足不同开发需求。5. 适用于需要语音功能的开发者。
总之,Edge-TTS是一个方便、高效的文本转语音工具,可以帮助开发者快速实现语音功能,提高用户体验。
1.安装部署
首先,你需要通过Python包管理工具pip来安装Edge-TTS库。只需在命令行中输入以下命令(没有python环境的自行配置一下):
|
|
如果只想使用edge-tts和edge-playback命令,最好使用 pipx:
|
|
安装完成后,你就可以开始使用Edge-TTS来将文本转换为语音了。Edge-TTS支持多种语言和不同的声音选项,你可以根据需要选择合适的声音。
2.文本转语音
我们先来个hello world,只需要一行代码!
|
|
执行完毕之后,会在你执行的目录下,生成hello.mp3文件
如果你想立即播放带有字幕的内容,可以使用以下edge-playback命令:
|
|
注意以上需要安装mpv命令行播放器。所有命令也都edge-tts可以工作。edge-playback
3.支持的语言和音色
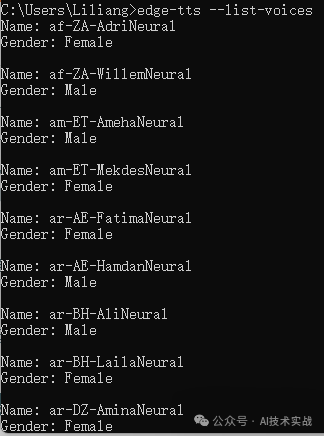
edge-tts支持英语、汉语、日语、韩语、法语等40多种语言,共300多种可选声音,执行以下命令查询:
|
|
如下图所示:
语音合成参数说明
在进行语音合成时,可以通过指定参数来选择不同的声音。以下是参数的详细说明:
-
Gender: 声音的性别。
-
Name: 声音的名称,格式为
语言-国家或地区-声音名称,例如zh-CN-YunjianNeural。 -
zh表示语言为中文。 -
CN表示国家或地区为中国。 -
YunjianNeural为声音的具体名称。
使用示例
要使用特定的声音进行语音合成,可以使用--voice参数。例如,使用zh-CN-YunyangNeural声音合成中文音频的命令如下:
|
|
注意事项
-
确保选择的声音名称符合格式要求。
-
根据需要选择合适的语言和国家或地区代码。
|
|
4.调整语速、音量和音调
可以对生成的语音进行细微修改。
|
|
语音合成服务的命令行和代码转换方法
1. 命令行转换
在使用命令行进行语音合成时,需要注意参数的正确格式。例如,使用 --rate=-50% 而不是 --rate -50%。如果缺少等号,-50% 将被错误地解释为另一个参数。
2. 代码转换
除了使用命令行,我们还可以通过编写代码来实现语音合成服务,并通过HTTP接口提供服务。
示例代码
以下是一个Python代码示例,该代码实现了语音合成功能。你可以将这段代码保存到一个名为 tts.py 的文件中。
python# 这里假设有一个名为tts.py的文件,包含了语音合成的代码
|
|
运行python tts.py,稍等即可在d盘生成合成后的音频test.mp3。
关于 edge-playback 命令的说明
edge-playback 实际上是 edge-tts 的一个封装,用于播放生成的语音。它接受与 edge-tts 选项相同的参数。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek002/post/20240918/%E5%BE%AE%E8%BD%AFEdge-TTS%E5%85%8D%E8%B4%B9%E5%BC%80%E6%BA%90AI%E4%B8%AD%E6%96%87%E8%AF%AD%E9%9F%B3%E5%B7%A5%E5%85%B7--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com