区块链1:让我们构建一个端到端的加密数据存储
当今软件中讨论的最普遍的问题之一是隐私。我们知道这个故事:Facebook/Google/Microsoft/etc 收集了大量关于我们的数据,而大多数用户无法控制这些数据。值得注意的是,所有这些数据收集并不是真正必要的。
构建无法访问用户数据的端到端加密产品是可能的,并且长期以来一直是可能的。最近,我们看到了许多新产品,例如 Signal、ProtonMail 和其他通过加密保证隐私的产品。我个人认为这很棒,因为它保护了用户并给予他们更多的自由和控制权。
作为构建 BulwarkID 的一部分,我构建了端到端加密 blob 存储机制,以允许用户在没有 BulwarkID 访问权限的情况下存储数据。该系统的目标是对用户数据进行加密,以使 BulwarkID 无法访问原始数据,并使数据存储合理匿名,数据和用户身份之间没有直接联系。
我称这个系统为 Vault;让我们看看它是如何建造的。
数据存储
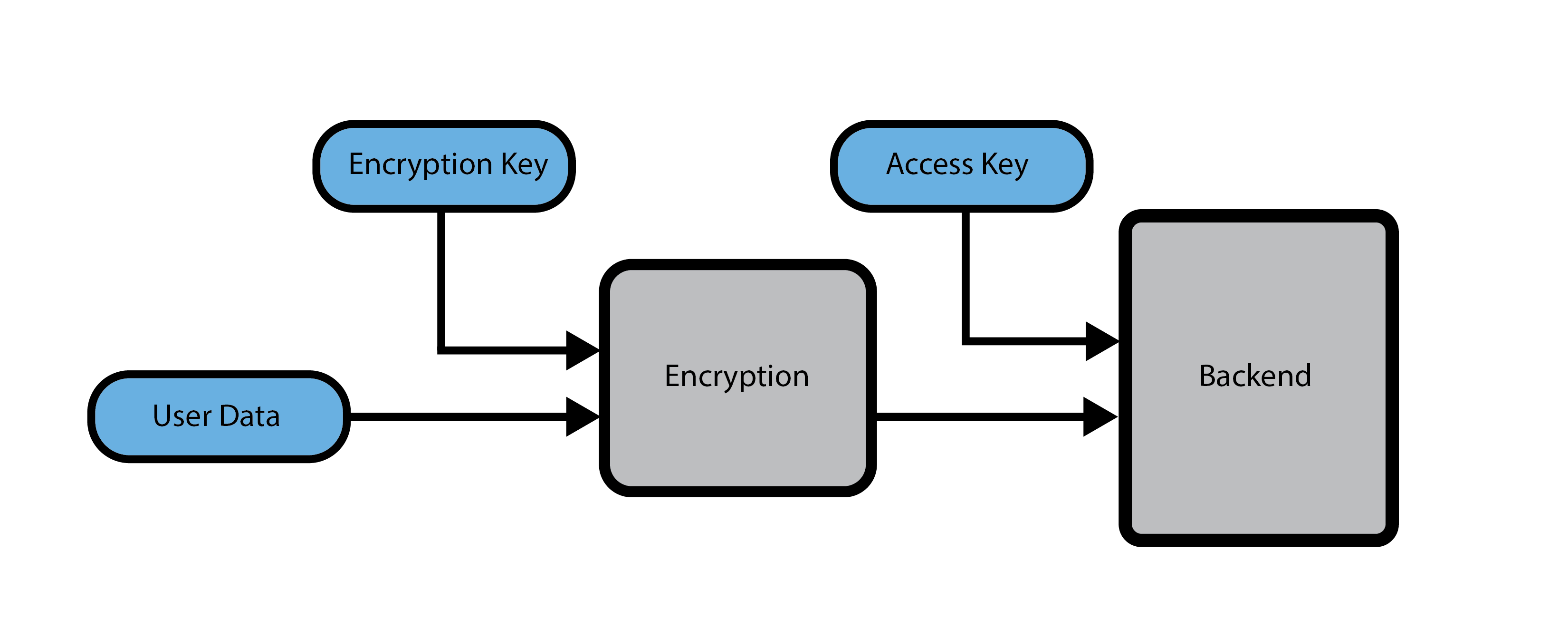
Vault 的基础是实际的数据存储。我们需要我们的存储既是私有的又是匿名的,与我们的用户没有直接联系。朝这个方向迈出的一个简单步骤是使用只有客户端才能访问的加密密钥来加密数据:我们可以使用256 位的AES-GCM密钥加密客户端上的用户数据,这是相当行业标准并且可以安全地加密用户数据.
更困难的问题是,如果没有某种减少隐私的身份验证机制,客户如何找到和访问这些数据?为了解决这个问题,每个加密的 blob 都使用一个均匀分布的 256 位访问密钥来访问,该密钥允许对后端数据进行读写访问。请注意,此访问密钥不需要完全随机;它可以通过加密方式从其他数据中导出,甚至可以是数据本身的 SHA-256 哈希。
这种数据存储方案,其中数据使用随机加密密钥加密并使用随机访问密钥访问,实现了我们的隐私和匿名目标。BulwarkID 无法读取用户数据,因为它已加密,并且无法直接跟踪,因为所有访问都使用单独的、不透明的访问密钥而不是经过身份验证的请求。
需要注意的是,虽然访问密钥和加密数据不会暴露任何用户信息,但某些元数据(例如 IP 地址和其他指纹识别机制)可以通过跨请求跟踪用户来破坏用户隐私。然而,在这个级别上解决这些问题是很困难的,最好通过 Tor 来匿名化流量。
访问密钥和加密密钥

虽然我们现在可以使用随机访问和加密密钥来存储和检索私人数据,但这并不是一个非常方便的访问系统。需要跟踪每个 blob,并且需要跨设备管理密钥。这不是一个不可能解决的问题,但是有一个标准的方法来跟踪这些密钥会很有用。
一种解决方案就是使用简单的索引。每当客户端需要存储一条新数据时,生成一个新的访问密钥和一个新的加密密钥并将其添加到索引中(可能是 JSON blob)。我们可以用一些有用的东西来作为这个索引的键,比如虚拟文件系统中数据的完整路径。例如,当客户端想要访问时/user/profile,他们可以在他们的索引中查找访问和加密密钥/user/profile,然后从后端检索它。
如果我们也将索引存储在后端,此解决方案将变得更加有用。我们可以生成一个主访问密钥和一个主加密密钥,然后使用它们将 JSON blob 存储在后端,然后我们可以检索它们以访问我们存储的任何其他数据。这将我们需要跟踪的大量访问和加密密钥变成了一对。
主密钥和密钥派生
索引解决方案有效,但它有技术上的权衡。每个保管库访问都需要拥有最新版本的索引,这需要客户端之间的某种同步机制。随着越来越多的密钥被添加,并且随着我们可能扩展到更多的用例,例如多用户数据,这个同步问题变得更加复杂。能够获取单个数据(例如某个根密钥或主密钥)并将其确定性地转换为多个密钥将很有用。
这就是我们可以用密钥派生来做的事情。HKDF是一个加密函数,它接受一些输入材料(加上盐)并从中派生出新的、加密安全的密钥材料。新材料仍然受到输入材料初始熵的限制,但这种方法确实允许我们将一些高熵材料拉伸成多个可用键。
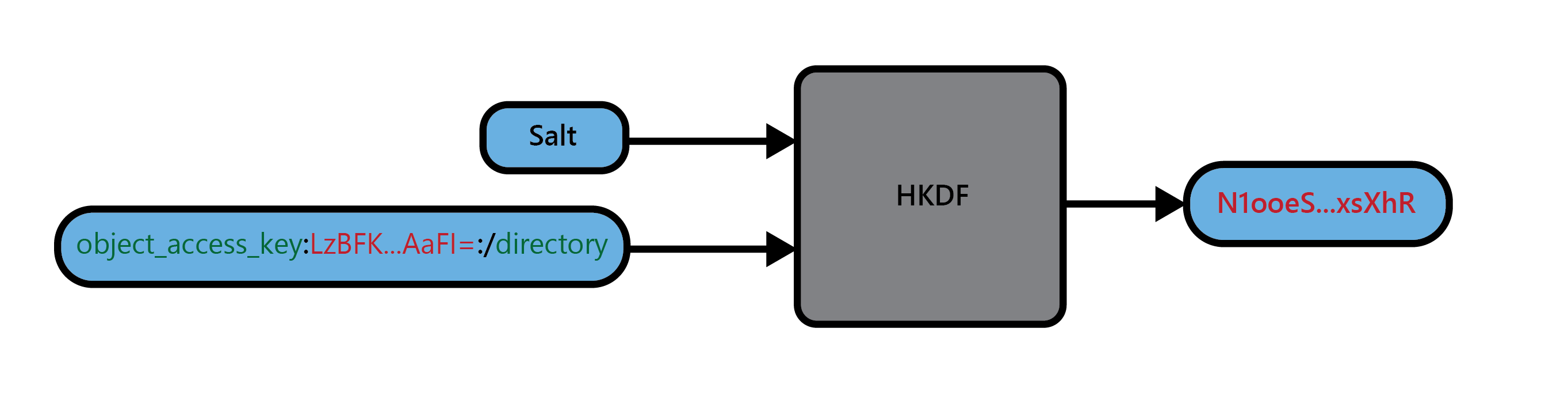
假设我们从一些高熵材料开始,例如 256 位的密码随机主密钥。我们可以将此秘密与文件路径结合起来,并使用 HKDF 生成访问密钥和加密密钥。在 Vault 中,我们对表单object_access_key:<master secret>:<path>的输入数据使用 HKDF 以导出访问密钥,并使用表单的输入数据object_encryption_key:<master secret>:<path>导出加密密钥。在这种情况下,path 是一个唯一的文件路径,用于标识该主密钥的 blob。
在实践中,这有其自身的局限性。主要限制是每个路径和主密钥都有一个单一的确定性访问和加密密钥(巧合的是,这也是该系统的主要优点)。这意味着,如果我们想要轮换密钥,我们需要更改系统中每条数据的访问密钥和加密密钥。
Vault 将两者结合使用。存储索引可用于大多数对象,以便轻松轮换密钥,并且密钥派生将在存储索引不可行的有限容量中使用。即,密钥派生用于访问索引本身;客户端可以使用单个 256 位主密钥和路径导出索引密钥/directory。
使用用户名和密码登录
虽然只用一个主密钥就能够从系统中检索所有用户数据很不错,但这并不是大多数用户希望能够登录的方式。这个事实可以通过在本地存储主密钥来掩盖在设备上,但这无助于跨设备同步的问题。大多数用户想要的是能够使用普通的用户名和密码登录系统。
有一种方法可以将用户名和密码变成主密钥。PBKDF2 允许我们将低熵材料转化为均匀分布但仍然是低熵的关键材料。这也使得逆向相对困难,因为计算成本高,因此暴力破解成本高。当您需要基于低熵材料的确定性加密时,通常使用 PBKDF2,例如在密码管理器中加密保险库,因此这正是我们所需要的。
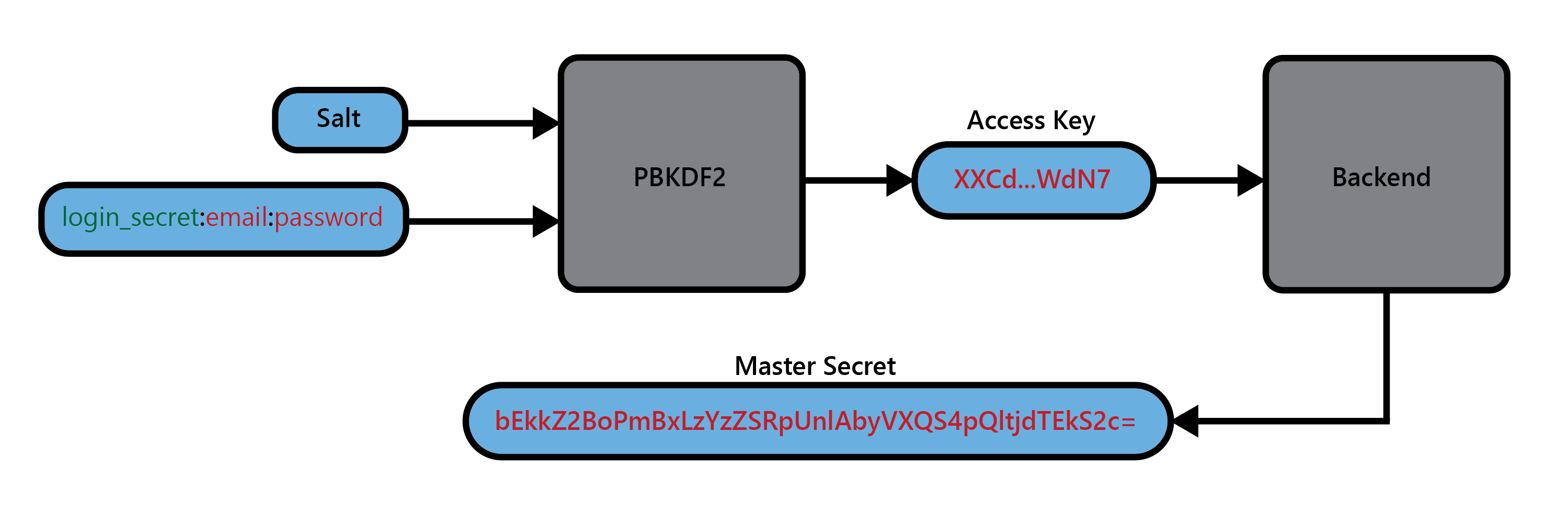
在 Vault 中,我们使用PBKDF2login_secret:<username>:<password>通过输入表单材料并导出 256 位密码来导出“登录主密码” 。然后,我们使用这个登录密钥来使用 HKDF 派生访问和加密密钥,如上所述,以检索存储在后端的高熵主密钥。
为什么要从后端检索一个单独的主密码,而不仅仅是使用登录密码作为主密码?一方面,我们希望允许用户更改他们的用户名和密码,而无需使用新的登录密码重新加密所有内容;只需更改登录密码并将旧的主密码存储在新位置即可变得容易。
其次,我们希望尽可能地包含低熵数据的使用。PBKDF2 可以使它难以逆转,但实际上并没有向输入材料添加熵。通过在后端交换低熵登录密码和高熵主密码,我们可以更合理地保证系统其余部分的安全保证得到维护。
概括
总之,在 Vault 中,用户可以使用他们的用户名/密码来派生登录密码,该密码可以交换为主密码。然后可以使用此主密钥来派生访问密钥,以从系统中特定路径检索对象。大多数对象都使用随机访问密钥存储,这些访问密钥存储在 的密钥目录中/directory,这是从路径到访问和加密密钥的映射。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/web3.0/%E5%8C%BA%E5%9D%97%E9%93%BE1%E8%AE%A9%E6%88%91%E4%BB%AC%E6%9E%84%E5%BB%BA%E4%B8%80%E4%B8%AA%E7%AB%AF%E5%88%B0%E7%AB%AF%E7%9A%84%E5%8A%A0%E5%AF%86%E6%95%B0%E6%8D%AE%E5%AD%98%E5%82%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


