浏览器的工作原理 - 获取数据(第 2 部分,附插图)🚀
在上一篇文章中,我们谈到navigation了浏览器显示网站的第一步。今天我们将进入下一步,看看如何resources get fetched。
2. 数据获取
HTTP 请求
在我们与服务器建立安全连接后,浏览器将发送一个初始的HTTP GET request. 首先,浏览器将请求HTML页面的标记 ( ) 文档。它将使用 HTTP 协议执行此操作。
HTTP (Hypertext Transfer Protocol) is a protocol for fetching resources such as HTML documents. It is the foundation of any data exchange on the Web and it is a client-server protocol, which means requests are initiated by the recipient, usually the Web browser.

该方法- 例如:POST、GET、PUT、PATCH、DELETE 等
URI - 代表Uniform Resource Identifier. URI 用于识别 Internet 上的抽象或物理资源,如网站或电子邮件地址等资源。一个 URI 最多可以包含 5 个部分:
- scheme:用来表示正在使用什么协议
- 权限:用于标识域
- path:用于显示资源的确切路径
- 查询:用于表示请求动作
- 片段:用于引用资源的一部分
// URI parts
scheme :// authority path ? query # fragment
//URI example
https://example.com/users/user?name=Alice#address
https: // scheme name
example.com // authority
users/user // path
name=Alice // query
address // fragment
HTTP 标头字段- 是客户端程序和服务器在每个 HTTP 请求和响应上发送和接收的字符串列表(它们通常对最终用户不可见)。在请求的情况下,它们包含有关要获取的资源或请求资源的浏览器的更多信息。
如果您想查看这些标头的外观,请转到 Chrome 并打开开发人员工具 (F12)。转到网络选项卡并选择FETCH/XHR。在下面的屏幕截图中,我刚刚进行了 Google 搜索,Palm Springs请求标头如下所示:

HTTP 响应
服务器收到请求后,将对其进行处理并以HTTP response. 附加到响应的正文中,我们可以找到所有相关的标题和我们请求的 HTML 文档的内容。

状态码- 例如:200、400、401、504 网关超时等(我们的目标是200状态码,因为它告诉我们一切正常,请求成功)
响应头字段- 保存有关响应的附加信息,例如其位置或关于提供它的服务器。
文档示例HTML可能类似于:
<!doctype HTML>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>This is my page</title>
<link rel="stylesheet" src="styles.css"/>
<script src="mainScripts.js"></script>
</head>
<body>
<h1 class="heading">This is my page</h1>
<p>A paragraph with a <a href="https://example.com/about">link</a></p>
<div>
<img src="myImage.jpg" alt="image description"/>
</div>
<script src="sideEffectsScripts.js"></script>
</body>
</html>
对于我之前提到的同一个谷歌搜索,它是reponse headers这样的:
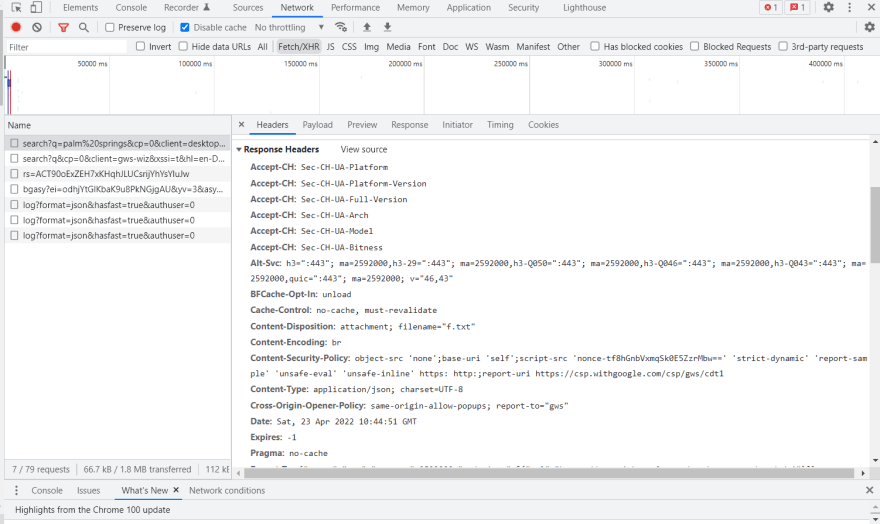
如果我们看一下 HTML 文档,我们会看到它引用了不同CSS的Javascript文件。在浏览器不会遇到这些链接之前,不会请求这些文件,但这不会发生在这一步,而是在parsing我们将在下一篇文章中讨论的阶段。此时,仅从服务器请求和接收 HTML。
此初始请求的响应包含接收到的第一个数据字节。Time to First Byte(TTFB) 是从用户提出请求(通过在地址栏中输入网站名称)到收到第一个 HTML 数据包(通常为 14kb)之间的时间。
TCP 慢启动和拥塞算法
TCP slow start是一种平衡网络连接速度的算法。第一个数据包为 14kb(或更小),其工作方式是逐渐增加传输的数据量,直到达到预定阈值。从服务器接收到每个数据包后,客户端以ACK message. 由于连接的容量有限,如果服务器发送太多数据包太快,它们将被丢弃。客户端不会发送任何内容ACK messages,因此服务器会将其解释为拥塞。这就是congestion algorithms发挥作用的地方。它们监视此已发送数据包和 ACK 消息流,以确定将流量发送到网络的速率并创建稳定的流量流。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/react/save01/%E6%B5%8F%E8%A7%88%E5%99%A8%E7%9A%84%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86-%E8%8E%B7%E5%8F%96%E6%95%B0%E6%8D%AE%E7%AC%AC-2-%E9%83%A8%E5%88%86%E9%99%84%E6%8F%92%E5%9B%BE/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


