关键词库-Go中使用爬虫框架
简介
本项目基于golang开发,是一个开放的垂直领域的爬虫框架,框架中将各个功能模块区分开,方便使用者重新实现子模块,进而构建自己垂直方方向的爬虫。
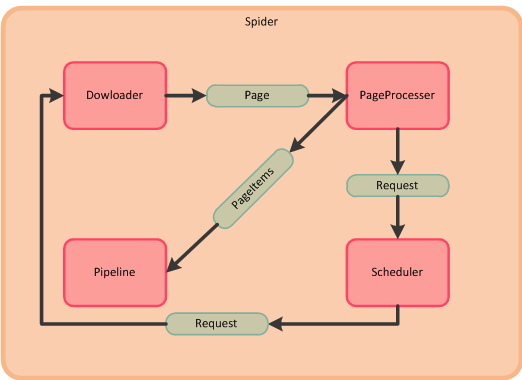
本项目将爬虫的各个功能流程区分成Spider模块(主控),Downloader模块(下载器),PageProcesser模块(页面分析),Scheduler模块(任务队列),Pipeline模块(结果输出);
执行过程简述:
- Spider模块从Scheduler模块中获取包含待抓取url的Request对象,启动一个协程,一个协程执行一次爬取过程,此处我们把协程也看成Spider,Spider把Request对象传入Downloader,Downloader下载该Request对象中url所对应的页面或者其他类型的数据,生成Page对象;
- Spider调用PageProcesser模块解析Page对象中的页面数据,并存入Page对象中的PageItems中(以Key-Value对的形式保存),同时存入解析结果中的待抓取链接,Spider会将待抓取链接存入Scheduler模块中的Request队列中;
- Spider调用Pipeline模块输出Page中的PageItems的结果;
- 执行步骤1,直至Scheduler中所有链接被处理完成,则Spider被挂起等待下一个待抓取链接或者终止。
执行过程相应的Spider核心代码,代码代表一次爬取过程:
// core processer
func (this *Spider) pageProcess(req *request.Request) {
// Get Page
p := this.pDownloader.Download(req)
if p == nil {
return
}
// Parse Page
this.pPageProcesser.Process(p)
for _, req := range p.GetTargetRequests() {
this.addRequest(req)
}
// Output
if !p.GetSkip() {
for _, pip := range this.pPiplelines {
pip.Process(p.GetPageItems(), this)
}
}
this.sleep()
}
项目安装与示例执行
- 安装本包和依赖包
go get github.com/hu17889/go_spider/...
go get github.com/PuerkitoBio/goquery
go get github.com/bitly/go-simplejson
go get golang.org/x/net/html/charset
示例执行:
- 编译:
go install github.com/hu17889/go_spider/example/github_repo_page_processor - 执行:
./bin/github_repo_page_processor
展示一个简单爬虫示例
示例的功能是爬取下面的项目以及项目详情页的相关信息,并将内容输出到标准输出。
一般在自己的爬虫main包中需要实现爬虫创建,初始化,以及PageProcesser模块的继承实现。可以实现自己的子模块或者使用项目中已经存在的子模块,通过Spider对象中相应的Set或者Add函数将模块引入爬虫。本项目支持链式调用。
spider.NewSpider(NewMyPageProcesser(), "TaskName"). // 创建PageProcesser和Spider,设置任务名称
AddUrl("https://github.com/hu17889?tab=repositories", "html"). // 加入初始爬取链接,需要设置爬取结果类型,方便找到相应的解析器
AddPipeline(pipeline.NewPipelineConsole()). // 引入PipelineConsole输入结果到标准输出
SetThreadnum(3). // 设置爬取参数:并发个数
Run() // 开始执行
完整代码如下:
//
package main
/*
Packages must be imported:
"core/common/page"
"core/spider"
Pckages may be imported:
"core/pipeline": scawler result persistent;
"github.com/PuerkitoBio/goquery": html dom parser.
*/
import (
"github.com/PuerkitoBio/goquery"
"github.com/hu17889/go_spider/core/common/page"
"github.com/hu17889/go_spider/core/pipeline"
"github.com/hu17889/go_spider/core/spider"
"strings"
)
type MyPageProcesser struct {
}
func NewMyPageProcesser() *MyPageProcesser {
return &MyPageProcesser{}
}
// Parse html dom here and record the parse result that we want to Page.
// Package goquery (http://godoc.org/github.com/PuerkitoBio/goquery) is used to parse html.
func (this *MyPageProcesser) Process(p *page.Page) {
query := p.GetHtmlParser()
var urls []string
query.Find("h3[class='wb-break-all'] a").Each(func(i int, s *goquery.Selection) {
href, _ := s.Attr("href")
urls = append(urls, "http://github.com/"+href)
})
// these urls will be saved and crawed by other coroutines.
p.AddTargetRequests(urls, "html")
name := query.Find(".author a").Text()
name = strings.Trim(name, " \t\n")
repository := query.Find("strong[itemprop='name'] a").Text()
repository = strings.Trim(repository, " \t\n")
//readme, _ := query.Find("#readme").Html()
if name == "" {
p.SetSkip(true)
}
// the entity we want to save by Pipeline
p.AddField("author", name)
p.AddField("project", repository)
//p.AddField("readme", readme)
}
func (this *MyPageProcesser) Finish() {
}
func main() {
// spider input:
// PageProcesser ;
// task name used in Pipeline for record;
spider.NewSpider(NewMyPageProcesser(), "TaskName").
AddUrl("https://github.com/hu17889?tab=repositories", "html"). // start url, html is the responce type ("html" or "json")
AddPipeline(pipeline.NewPipelineConsole()). // print result on screen
SetThreadnum(3). // crawl request by three Coroutines
Run()
}
模块介绍
Spider
用户一般无需自己实现。
功能:完成爬虫初始化,如加入各个默认子模块,管理并发,调度其他模块以及相关参数设置。
重要方法:
- 爬取启动方法:Get,GetAll,Run
- 添加抓取链接: AddUrl, AddUrls, AddRequest, AddRequests
- 主模块选择方法:AddPipeline,SetScheduler,SetDownloader
- 参数设置:SetExitWhenComplete,SetThreadnum(设置爬虫并发数),SetSleepTime(设置爬取后的挂起时间)
- 监控方法:OpenFileLog,OpenFileLogDefault(打开日志文件,使用mlog包进行记录日志),CloseFileLog,OpenStrace(打开跟踪,打印了爬虫执行信息到stderr),CloseStrace
Downloader
用户可选择自己实现。
功能:Spider从Scheduler的Request队列中获取包含待抓取url的Request对象,传入Downloader,Downloader下载该Request对象中的url所对应的页面或者其他类型的数据,现在支持(html,json,jsonp,text)几种结果类型,生成Page对象,同时找到下载结果所对应的解析go包并生成解析器存入Page对象中,如html是goquery包,json数据是simplejson包,jsonp数据会转成json数据,text是只存储了返回的原始字符串。
重要方法
- Download 下载方法,返回包含下载内容(数据,header,cookies,request信息)的Page对象。
PageProcesser
用户必须实现此模块。
功能:这个模块主要做页面解析,用户需要在此处获取有用数据和下一步爬取的链接。PageProcesser的前后实现步骤如下:Spider调用PageProcesser模块解析页面中的数据,并存入Page对象中的PageItems对象中(以Key-Value对的形式保存),同时存入解析结果中的待抓取链接,Spider会将待抓取链接存入Scheduler模块中的Request队列中;所以用户可以根据自己的需求进行个性化实现爬虫解析功能。
重要方法
- Process,爬取对象解析
Page
用户无需实现此模块。
功能:记录当前爬取对象的各种信息。
重要方法
- 获取爬取结果内容:GetJson,GetHtmlParser,GetBodyStr(原始内容)
- 获取爬取对象信息:GetRequest,GetCookies,GetHeader
- 爬取状态:IsSucc(是否爬取成功from Download模块),Errormsg(爬取错误信息from Download模块)
- 影响输出和后续爬取过程的方法:SetSkip,GetSkip(此次爬取结果不存储),AddTargetRequest,AddTargetRequests(设置待爬取链接),AddTargetRequestWithParams, AddTargetRequestsWithParams,AddField(保存解析内容的KV对)
Scheduler
用户一般无需自己实现。
功能:Scheduler实际上是一个Request对象队列,用来保存尚未被爬取的页面链接和相应的信息,当前队列是缓存到内存中(QueueScheduler),后续会增加基于Redis的队列,解决Spider异常失败后未爬取链接丢失问题;
Pipeline
用户可以选择自己实现。
功能:此模块主要完成数据的输出与持久化。在PageProcesser模块中可用数据被存入了Page对象中的PageItems对象中,此处会获取PageItems的结果并按照自己的要求输出。已有的样例有:PipelineConsole(输出到标准输出),PipelineFile(输出到文件中)
Request
功能: 包含一次请求的各种设置,如url,header,cookies等;
相关包以及推荐工具包
存储
数据解析
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/crawler/%E5%85%B3%E9%94%AE%E8%AF%8D%E5%BA%93-Go%E4%B8%AD%E4%BD%BF%E7%94%A8%E7%88%AC%E8%99%AB%E6%A1%86%E6%9E%B6/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


