Flink系列-第41讲:Flink 面试-源码篇
Flink 的源码篇包含了 Flink 的核心代码实现、Job 提交流程、数据交换、分布式快照机制、Flink SQL 的原理等考察点。你应该记得,我们在前面近 40个课时中几乎每一课时都有一定的篇幅是源码阅读,源码部分的考察是面试时十分重要的一关,如果你对 Flink 的源码有一定的研究而不仅仅停留在使用阶段,那么你的面试成功率将得到大幅提升。
我们本课时将把 Flink 面试中源码部分最高频的考点列举出来。
面试题 1:请从源码层面谈谈 Flink Job 的提交流程。
用户提交的 Flink Job 会被转化成一个 DAG 任务运行。Flink Job 的提交涉及的类主要包括:StreamGraph、JobGraph、ExecutionGraph、TaskManager、JobManager、ResourceManager。
JobManager 会把接收到的需要执行的应用程序进行打包,然后把 JobGraph 转换成可以执行的ExecutionGraph,接着向 ResourceManager 请求执行任务所需要的资源,也就是我们之前课程中提到的 Slot,如果资源获取成功 JobManager 会负责所有的任务调度,比如 Checkpoint,并且将任务派发给 TaskManager 去执行。
面试题 2:我们通常说的 Flink 的“三层图”结构是什么意思?
这道题要求面试者掌握Flink 框架引擎划分执行计划的详细过程。
一个 Flink 任务的 DAG 生成计算图大致经历以下3个过程。
-
首先,StreamGraph 的拓扑结构最接近代码层面,主要由 StreamNode 和 StreamEdge 构成,其中 StreamNode 对应着 Operator,它们通过 StreamEdge 进行链接。
-
其次,JobGraph 是能被 Flink 引擎识别的数据结构,由JobVertex、JobEdge和 IntermediateDataSet3个元素组成。我们可以把JobGraph 形象地比喻为一个抽水系统,JobVertex 是水泵,JobEdge 是水管,而 IntermediateDataSet 则是中间的蓄水池。
-
最后,ExecutionGraph 由 JobGraph 转换而来,包含了任务具体执行所需的内容,是最贴近底层实现的执行图。
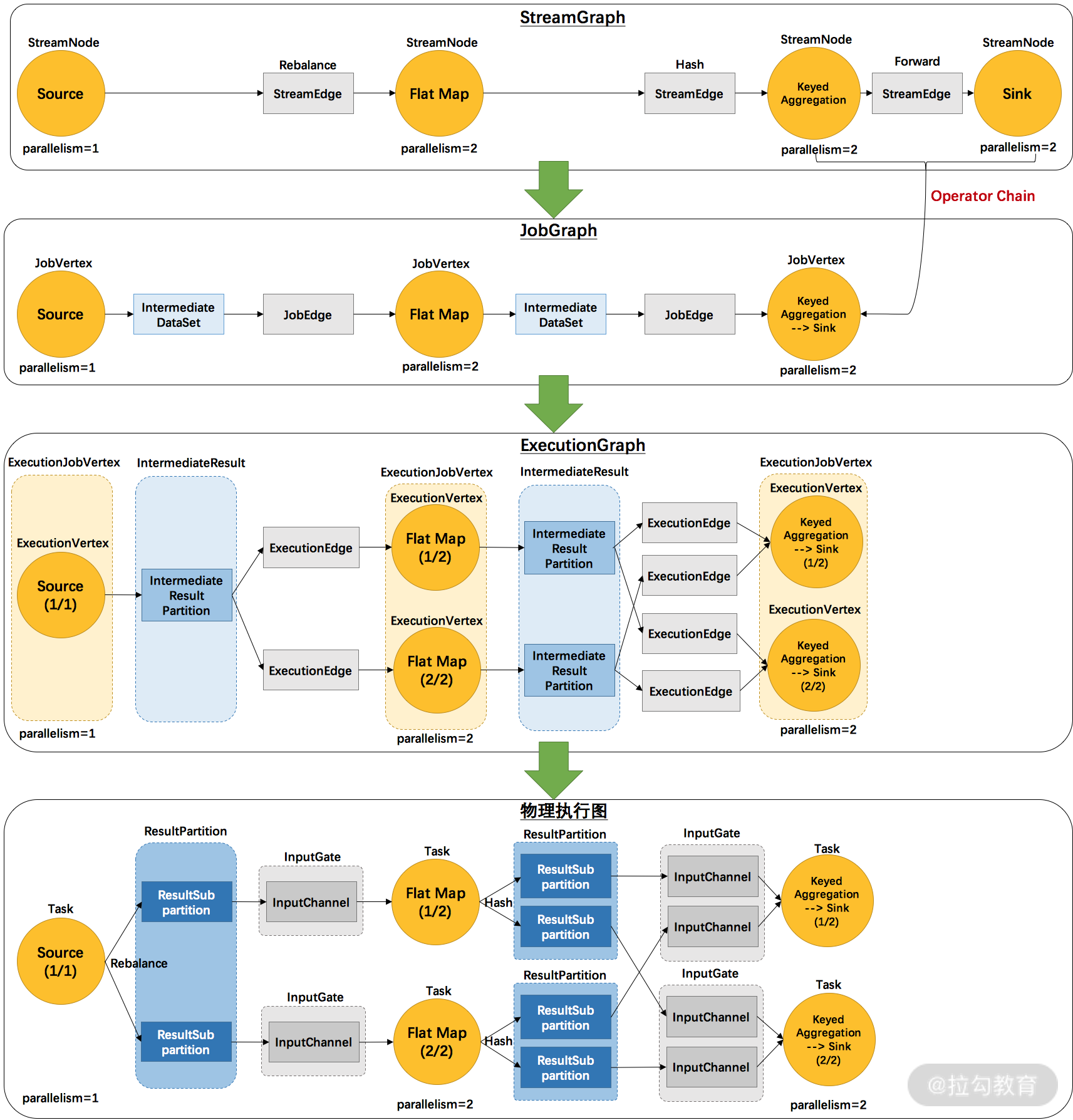
上图清晰展现了 Flink 各个图之间的转换过程和工作原理。
面试题 3:请从源码层面谈谈 JobManger 在集群中扮演了什么角色?
我们在第03课时“Flink 的编程模型与其他框架比较” 中专门用了一小节的内容来讲解 Flink 中的角色和作用,其中 JobManager 是 Flink 集群中非常重要的一个角色。
JobManager 负责整个 Flink 集群任务的调度及资源的管理,从客户端中获取提交的应用,然后根据集群中 TaskManager 上 TaskSlot 的使用情况,为提交的应用分配相应的 TaskSlot 资源并命令 TaskManager 启动从客户端中获取的应用。
JobManager 相当于整个集群的 Master 节点,且整个集群有且只有一个活跃的 JobManager,负责整个集群的任务管理和资源管理。
JobManager 和 TaskManager 之间通过 Actor System 进行通信,获取任务执行的情况并通过 Actor System 将应用的任务执行情况发送给客户端。
同时在任务执行的过程中,Flink JobManager 会触发 Checkpoint 操作,每个 TaskManager 节点收到 Checkpoint 触发指令后,完成 Checkpoint 操作,所有的 Checkpoint 协调过程都是在 Fink JobManager 中完成。
当任务完成后,Flink 会将任务执行的信息反馈给客户端,并且释放掉 TaskManager 中的资源以供下一次提交任务使用。
面试题 4:JobManger 在集群启动过程中起到什么作用?
一定要注意,这道题目和面试题 3 有一定的相似性,但是这里会要求我们从源码层面介绍 JobManager 在启动过程中涉及的主要类和方法。
首先,我们要回答出 JobManager 的主要职责,主要包括负责整个 Flink 集群任务调度和资源的管理,并且负责接收 Flink 作业、调度 Task、收集作业状态和管理 TaskManager。
然后,如果开发者能从源码层面回答出涉及的关键方法,会大大增加面试官的印象。
-
RegisterTaskManager:它由想要注册到 JobManager 的 TaskManager 发送,注册成功则通过 AcknowledgeRegistration 消息进行 Ack。
-
SubmitJob:将 Job 提交给 Client,提交的信息是 JobGraph 形式的作业描述信息。
-
CancelJob:请求取消指定ID的作业,成功会返回 CancellationSuccess,否则返回 CancellationFailure。
-
UpdateTaskExecutionState:由 TaskManager 发送,用来更新执行节点(ExecutionVertex)的状态;成功则返回 true,否则返回 false。
-
RequestNextInputSplit:TaskManager 上的 Task 请求下一个输入 split,成功则返回 NextInputSplit,否则返回 null。
-
JobStatusChanged:它意味着作业的状态(RUNNING、CANCELING、FINISHED等)发生变化,这个消息由 ExecutionGraph 发送。
面试题 5:TaskManager 在集群中扮演了什么角色?
这道题和面试题 3 类似,TaskManager 是集群中的 Worker 角色,我们在第 03 课时“Flink 的编程模型与其他框架比较”中也对 TaskManager 做过详细讲解。
TaskManager 相当于整个集群的 Slave 节点,负责具体的任务执行和对应任务在每个节点上的资源申请和管理。
客户端通过将编写好的 Flink 应用编译打包,提交到 JobManager,然后 JobManager 会根据已注册在 JobManager 中 TaskManager 的资源情况,将任务分配给有资源的 TaskManager 节点,然后启动并运行任务。
TaskManager 从 JobManager 接收需要部署的任务,然后使用 Slot 资源启动 Task,建立数据接入的网络连接,接收数据并开始数据处理。同时 TaskManager 之间的数据交互都是通过数据流的方式进行的。
可以看出,Flink 的任务运行其实是采用多线程的方式,这和 MapReduce 多 JVM 并行的方式有很大的区别,Flink 能够极大提高 CPU 使用效率,在多个任务和 Task 之间通过 TaskSlot 方式共享系统资源,每个 TaskManager 中通过管理多个 TaskSlot 资源池对资源进行有效管理。
面试题 6:TaskManger 的启动过程是怎样的?
相比 JobManager而言,TaskManager 的启动流程较为简单,启动类入口为org.apache.flink.runtime.taskexecutor.TaskManagerRunner。核心的入口如下所示:
public static void runTaskManager(Configuration configuration, ResourceID resourceId) throws Exception {
//主要初始化一些service,并新建一个TaskExecutor
final TaskManagerRunner taskManagerRunner = new TaskManagerRunner(configuration,resourceId);
//调用TaskExecutor的start()方法
taskManagerRunner.start();
}
启动过程中主要进行 Slot 资源的分配、RPC 服务的初始化,以及JobManager 进行通信等。
面试题 7:Flink 计算资源的调度是如何实现的?
这类问题的难度都非常高,考察开发人员在进行资源配置和调优的过程中是否对源码有足够的了解。我们在第 17 课时“生产环境中的并行度和资源配置”中对 Flink 中的资源有过详细讲解。
TaskManager 中最细粒度的资源是 Task slot,代表了一个固定大小的资源子集,每个 TaskManager 会将其所占有的资源平分给它的 slot。
通过调整 task slot 的数量,用户可以定义 task 之间是如何相互隔离的。每个 TaskManager 有一个 slot,也就意味着每个 task 运行在独立的 JVM 中;每个 TaskManager中有多个 slot 的话,也就意味着多个 task 运行在同一个 JVM 中。
而在同一个 JVM 进程中的 task,可以共享 TCP 连接(基于多路复用)和心跳消息,可以减少数据的网络传输,也能共享一些数据结构,在一定程度上减少了每个 task 的消耗。 每个 slot 可以接受单个 task,也可以接受多个连续 task 组成的 pipeline,如下图所示。FlatMap 函数占用一个 taskslot,而 key Agg 函数和 sink 函数共用一个 taskslot:
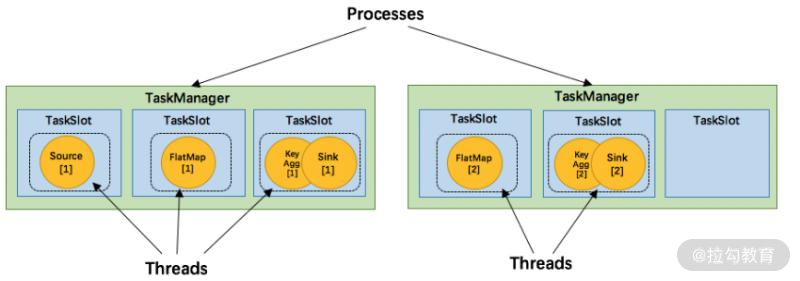
面试题 8:请你谈谈 Flink 的数据抽象及数据交换过程?
这个问题涉及 Flink 中的内存设计和定义,需要你将核心的类答出来。
我们知道 JVM 在对象序列化上有一些固有的缺陷,主要体现在存储对象的密度较低,含有大量不需要的信息,并且 FGC 还会对整体的吞吐和响应有严重影响。
为了降低这些影响,Flink 实现了自己的内存管理。主要体现在,Flink 定义了自己的内存抽象:MemorySegment。
public abstract class MemorySegment {
protected static final Unsafe UNSAFE;
protected static final long BYTE_ARRAY_BASE_OFFSET;
private static final boolean LITTLE_ENDIAN;
protected byte[] heapMemory;
protected long address;
protected long addressLimit;
protected int size;
protected Object owner;
MemorySegment(byte[] buffer, Object owner) {
if (buffer == null) {
throw new NullPointerException("buffer");
} else {
this.heapMemory = buffer;
this.address = BYTE_ARRAY_BASE_OFFSET;
this.size = buffer.length;
this.addressLimit = this.address + (long)this.size;
this.owner = owner;
}
}
...
我们可以把MemorySegment 看作是一个 32KB大的内存块的抽象,这块内存既可以是 JVM 里的一个 byte[],也可以是堆外内存(DirectByteBuffer)。
在 MemorySegment 这个抽象之上,Flink 抽象出了两个关键的进行数据转换的类:
-
Buffer,用于各个 TaskManager 进行数据传输;
-
StreamRecord,用于 Java 对象和 Buffer 对象互相转换。
面试题9:谈谈 Flink 的 SQL 部分是如何实现的?
Table SQL 是 Flink 提供的高级 API 操作。Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
我们在第 5 课时“Flink Table & SQL 编程和案例”中进行过非常详细的讲解。
Flink 把 SQL 的解析、优化和执行教给了Calcite。从图中可以看到,无论是批查询 SQL 还是流式查询 SQL,都会经过对应的转换器 Parser 转换成为节点树 SQLNode tree,然后生成逻辑执行计划 Logical Plan,逻辑执行计划在经过优化后生成真正可以执行的物理执行计划,交给 DataSet 或者 DataStream 的 API 去执行。
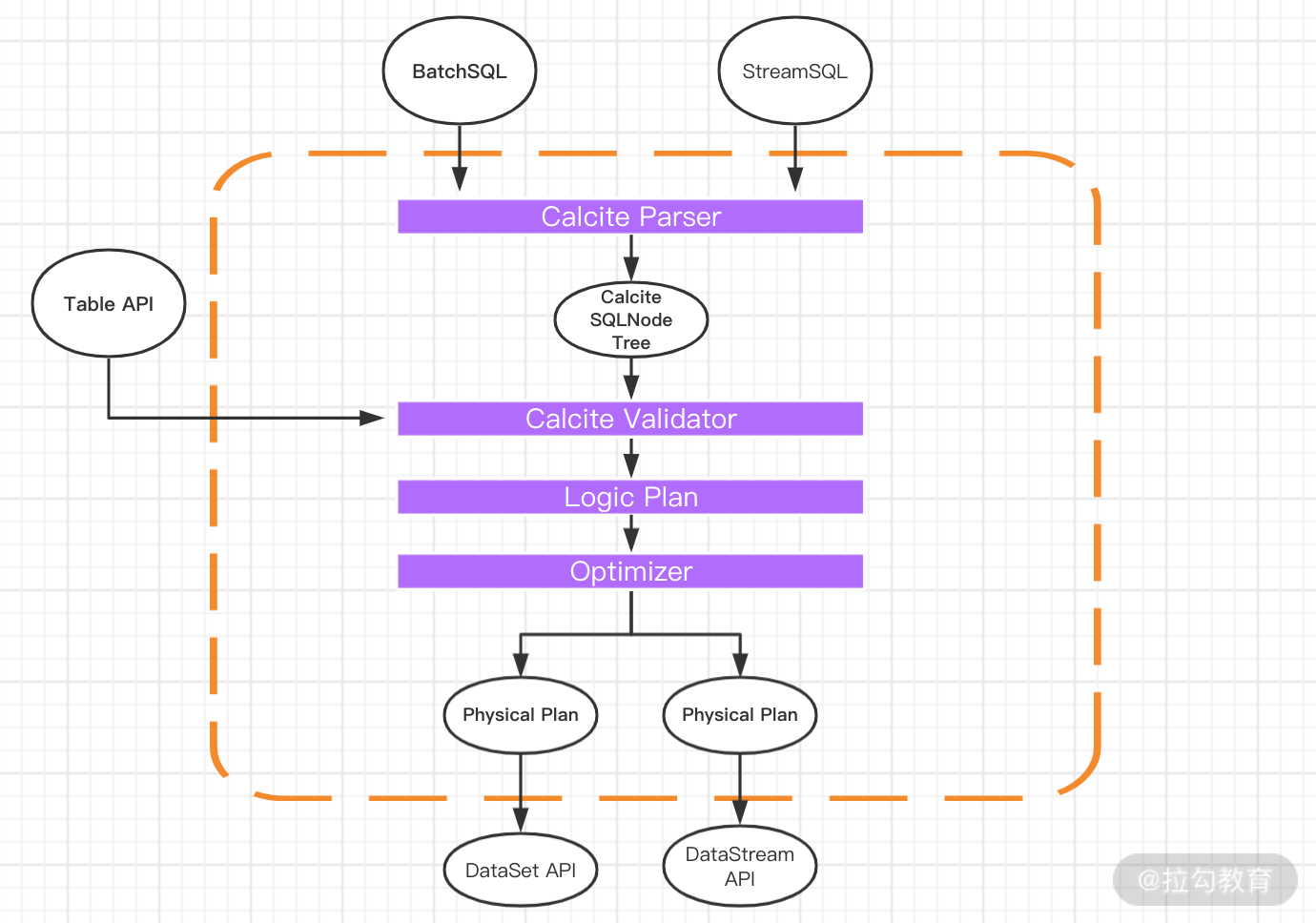
上图清晰地展示了 SQL 的整个解析和转换过程,当 SQL 被转换为可以执行的物理执行计划后会被分发到各个 TaskManager 节点中去,并且最后翻译成代码运行。
总结
这一课时我们介绍了 Flink 源码面试中的一些经典题目,在之前的课程中都会花一定的篇幅去介绍源码和实现。可以这么说,源码的阅读决定了我们是否真正掌握了一个框架,建议你在学习 Flink 的每个模块时都要养成阅读源码的习惯。另外,抽空也可以参考我之前的面试相关文章《全网第一份 | Flink学习面试灵魂40问,看看你能答上来几个》和《Flink面试通关手册》。
精选评论
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/bi/flink/2076-%E7%AC%AC41%E8%AE%B2Flink-%E9%9D%A2%E8%AF%95-%E6%BA%90%E7%A0%81%E7%AF%87/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


