Flink系列-第40讲:Flink 面试-进阶篇
Flink 面试进阶篇主要包含了 Flink 中的数据传输、容错机制、序列化、数据热点、反压等实际生产环境中遇到的问题等考察点。这一阶段主要考察我们对 Flink 掌握的深度,也是给面试官留下好印象的关键环节。
面试题 1:请谈谈你对 Flink Table & SQL 的了解情况?以及 TableEnvironment 这个类有什么样的作用?
这道题考察的是对 Flink Table & SQL 的掌握情况,要知道 Flink 中的 TableEnvironment 有 5 个之多,那么对于 TableEnvironment 的掌握就显得特别重要。
TableEnvironment 是 Table API 和 SQL 集成的核心概念,它主要被用来创建 Table & SQL 程序的上下文执行环境,这个类主要用来:
-
在内部 catalog 中注册表
-
注册外部 catalog
-
执行 SQL 查询
-
注册用户定义(标量、表或聚合)函数
-
将 DataStream 或 DataSet 转换为表
-
持有对 ExecutionEnvironment 或 StreamExecutionEnvironment 的引用
面试题 2:Flink SQL 的原理是什么?请谈谈整个 SQL 的解析过程。
我们在第 05 课时“Flink Table & SQL 编程和案例” 中提过 Flink 把 SQL 的解析、优化和执行教给了 Calcite。
这道题比较深入,我们在使用 Flink Table & SQL 时要知道它的运行原理,才能针对性地做一些调优。
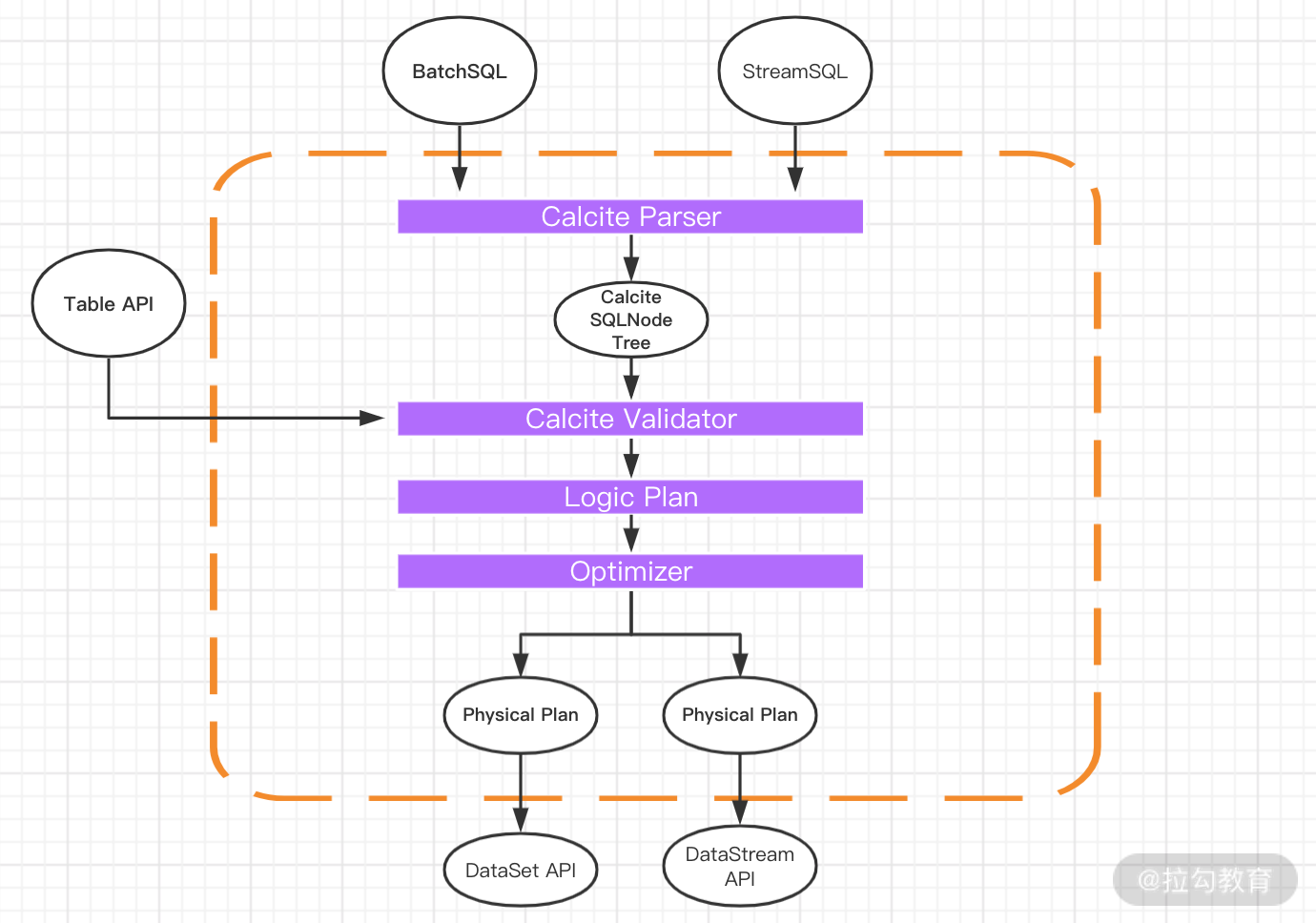
基于此,一次完整的 SQL 解析过程如下图所示:
-
用户使用对外提供的 Stream SQL 语法来开发业务应用;
-
用 calcite 对 StreamSQL 进行语法检验,语法检验通过后,转换成 calcite 的逻辑树节点,最终形成 calcite 的逻辑计划;
-
采用 Flink 自定义的优化规则和 calcite 火山模型、启发式模型共同对逻辑树进行优化,生成最优的 Flink 物理计划;
-
对物理计划采用 janino codegen 生成代码,生成用低阶 API DataStream 描述的流应用,并提交到 Flink 平台执行。
面试题 3:请谈谈你对 Flink 容错的理解。
Flink 的容错机制是非常重要的一个特性,我们在回答这个问题时,要把 CheckPoint 和 State 都答出来,并且阐述一下原理。
Flink 实现容错主要靠强大的 CheckPoint 和 State 机制。Checkpoint 负责定时制作分布式快照、对程序中的状态进行备份;State 用来存储计算过程中的中间状态。
Flink 提供了三种可用的状态后端用于在不同情况下进行状态后端的保存:
-
MemoryStateBackend
-
FsStateBackend
-
RocksDBStateBackend
面试题 4 :Flink 是如何保证 Exactly-once 语义的
这道题在面试时一定会遇到,Flink 的“精确一次”语义的支持是区别于其他框架最显著的特性之一。
Flink 通过实现两阶段提交和状态保存来实现端到端的一致性语义,分为以下几个步骤:
-
开始事务(beginTransaction),创建一个临时文件夹,然后把数据写入这个文件夹里面;
-
预提交(preCommit),将内存中缓存的数据写入文件并关闭;
-
正式提交(Commit),将之前写完的临时文件放入目标目录下,这代表着最终的数据会有一些延迟;
-
丢弃(Abort),丢弃临时文件。
我们在第 14 课时“Flink Exactly-once 实现原理解析”中还对 Flink 分布式快照的核心元素 Barrier 和两阶段提交的原理做过详细讲解,可以参考。
面试题 5:请谈谈 Flink 中的内存管理
Flink 的内存管理一般会在面试者与面试官讨论反压问题解决方案时被提及,对于内存管理的准确掌握也是我们进行内存调优和配置的前提。
Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上,此外,Flink 大量使用了堆外内存。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。
Flink 为了直接操作二进制数据实现了自己的序列化框架。
理论上 Flink 的内存管理分为以下 3 部分。
-
Network Buffers:这个是在 TaskManager 启动的时候分配的,这是一组用于缓存网络数据的内存,每个块是 32K,默认分配 2048 个,可以通过“taskmanager.network.numberOfBuffers”修改。
-
Memory Manage pool:大量的 Memory Segment 块,用于运行时的算法(Sort/Join/Shuffle 等),这部分启动时会被分配。根据配置文件中的各种参数来计算内存的分配方法,并且内存的分配支持预分配和 lazy load,默认懒加载的方式。
-
User Code,这个是除了 Memory Manager 之外的内存用于 User Code 和 TaskManager 本身的数据结构。
面试题 6:请谈谈你遇到的数据倾斜问题?Flink 中的 Window 出现了数据倾斜,你有什么解决办法?
这道题也是面试中一定会被提及的问题,数据倾斜是大数据领域最常见的问题之一。Flink 中对于数据倾斜的调优极其重要,我们一定要掌握。
我们在第 16 课时“如何处理生产环境中的数据倾斜问题”中对于这个问题有过一整节的讲解。
产生数据倾斜的原因主要有 2 个方面:
-
业务上有严重的数据热点,比如滴滴打车的订单数据中北京、上海等几个城市的订单量远远超过其他地区;
-
技术上大量使用了 KeyBy、GroupBy 等操作,错误的使用了分组 Key,人为产生数据热点。
因此解决问题的思路也很清晰:
-
业务上要尽量避免热点 key 的设计,例如我们可以把北京、上海等热点城市分成不同的区域,并进行单独处理;
-
技术上出现热点时,要调整方案打散原来的 key,避免直接聚合;此外 Flink 还提供了大量的功能可以避免数据倾斜。
另外我们还可以结合实际工作中出现的问题做举例说明。
面试题 7:Flink 任务出现很高的延迟,你会如何入手解决类似问题?
这是一个实操性很强的问题,我们在回答这类问题一定要结合实际情况来说。在生产环境中处理这类问题会从以下方面入手:
-
在 Flink 的后台任务管理中,可以看到 Flink 的哪个算子和 task 出现了反压;
-
资源调优和算子调优,资源调优即对作业中的 Operator 并发数(Parallelism)、CPU(Core)、堆内存(Heap_memory)等参数进行调优;
-
作业参数调优,并行度的设置、State 的设置、Checkpoint 的设置。
面试题 8: 请谈谈你们是如何处理脏数据的?
这也是一个开放性的面试题,建议你结合自己的实际业务来谈。比如可以通过一个 fliter 算子将不符合规则的数据过滤出去。当然了,我们也可以在数据源头就将一些不合理的数据抛弃,不允许进入 Flink 系统参与计算。
面试题 9:请谈谈 Operator Chain 这个概念?
算子链是我们进行任务调优一定会遇到的问题,主要考察我们对于概念是否正确理解,实际操作中有怎样的指导作用。
为了更高效地分布式执行,Flink 会尽可能地将 Operator 的 Subtask 链接(Chain)在一起形成 Task,每个 Task 在一个线程中执行。将 Operators 链接成 Task 是非常有效的优化,它能减少:
-
线程之间的切换;
-
消息的序列化/反序列化;
-
数据在缓冲区的交换;
-
延迟的同时提高整体的吞吐量。
这就是我们所说的算子链。
面试题 10:Flink 在什么情况下才会把 Operator Chain 在一起形成算子链?
这道题是有标准答案的,截止 1.11 版本,Flink 的算子之间形成算子链需要以下条件:
-
上下游的并行度一致
-
下游节点的入度为 1(即下游节点没有来自其他节点的输入)
-
上下游节点都在同一个 Slot Group 中
-
下游节点的 Chain 策略为 ALWAYS(可以与上下游链接,Map、Flatmap、Filter 等默认是 ALWAYS)
-
上游节点的 Chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source 默认是 HEAD)
-
两个节点间数据分区方式是 Forward
-
用户没有禁用 Chain
面试题 11:请谈谈 Flink 中的分布式快照机制是如何实现的?
这道题也是考察我们对于 Flink 掌握深度的一个问题,需要你完全理解 Flink 中的分布式快照机制的实现原理。
Flink 容错机制的核心部分是制作分布式数据流和操作算子状态的一致性快照,这些快照充当一致性 Checkpoint,系统可以在发生故障时回滚。Flink 用于制作这些快照的机制在“分布式数据流的轻量级异步快照”中进行了描述,它受到分布式快照的标准 Chandy-Lamport 算法的启发,专门针对 Flink 的执行模型而定制。
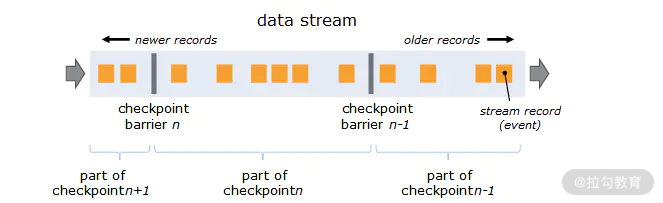
barrier 在数据流源处被注入并行数据流中。快照 n 的 barrier 被插入的位置(我们称为 Sn)是快照所包含的数据在数据源中最大位置。例如,在 Apache Kafka 中,此位置将是分区中最后一条记录的偏移量,将该位置 Sn 报告给 Checkpoint 协调器(Flink 的 JobManager)。
接着 barrier 向下游流动。当一个中间操作算子从其所有输入流中收到快照 n 的 barrier 时,它会为快照 n 发出 barrier 进入其所有输出流中。 一旦 sink 操作算子(流式 DAG 的末端)从其所有输入流接收到 barrier n,它就向 checkpoint 协调器确认快照 n 完成。在所有 sink 确认快照后,意味着快照已完成。
一旦完成快照 n,job 将永远不再向数据源请求 Sn 之前的记录,因为此时这些记录(及其后续记录)将已经通过整个数据流拓扑,也即已经被处理结束。
总结
这一课时我们主要介绍了 Flink 面试中的一些有深度的问题,这些问题是我们在技术面试中能否通过的关键部分,也是考察我们对于 Flink 掌握深度的部分。由于篇幅的原因我们不能 100% 覆盖所有高级进阶的面试题目,建议你参考我之前的文章《全网第一份 | Flink 学习面试灵魂40问,看看你能答上来几个》和《Flink 面试通关手册》。
精选评论
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/bi/flink/2075-%E7%AC%AC40%E8%AE%B2Flink-%E9%9D%A2%E8%AF%95-%E8%BF%9B%E9%98%B6%E7%AF%87/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


