Flink系列-第30讲:Flume 和 Kafka 整合和部署
Flume 概述
Flume 是 Hadoop 生态圈子中的一个重要组件,在上一课时中提过,它是一个分布式的、高可靠的、高可用的日志采集工具。
Flume 具有基于流式数据的简单灵活的架构,同时兼具高可靠性、高可用机制和故障转移机制。当我们使用 Flume 收集数据的速度超过下游的写入速度时,Flume 会自动做调整,使得数据的采集和推送能够平稳进行。
Flume 支持多路径采集、多管道数据接入和多管道数据输出。数据源可以是 HBase、HDFS 和文本文件,也可以是 Kafka 或者其他的 Flume 客户端。
Flume 的组件介绍
Flume 中有很多组件和概念,下面我把 Flume 中的核心组件一一进行介绍:
-
Client:客户端,用来运行 Flume Agent。
-
Event:Flume 中的数据单位,可以是一行日志、一条消息。
-
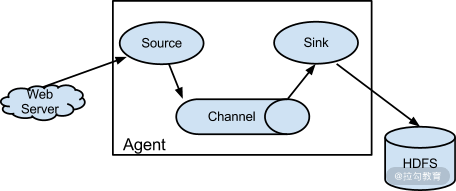
Agent:代表一个独立的 Flume 进程,包含三个组件:Source、Channel 和 Sink。
-
Source:数据的收集入口,用来获取 Event 并且传递给 Channel。
-
Channel:Event 的一个临时存储,是数据的临时通道,可以认为是一个队列。
-
Sink:从 Channel 中读取 Event,将 Event 中的数据传递给下游。
-
Flow:一个抽象概念,可以认为是一个从 Source 到达 Sink 的数据流向图。
Flume 本地环境搭建
我们在 Flume 的 官网下载安装包,在这里下载一个 1.8.0 的稳定版本,然后进行解压:
tar zxf apache-flume-1.8.0-bin.tar.gz
可以看到有几个关键的目录,其中 conf/ 目录则是我们存放配置文件的目录。
Flume 测试
我们在下载 Flume 后,需要进行测试,可以通过监听本地的端口输入,并且在控制台进行打印。
首先,需要修改 conf/ 目录下的 flume-env.sh,在里面配置 JAVA_HOME 等配置:
cd /usr/local/apache-flume-1.8.0-bin/conf
cp flume-env.sh.template flume-env.sh
然后在 flume-env.sh 里面设置 JAVA_HOME 和 FLUME_CLASSPATH 变量:
export JAVA_HOME=/usr/local/java/jdk1.8
FLUME_CLASSPATH="/usr/local/apache-flume-1.8.0-bin/"
创建一个配置文件 nc_logger.conf :
vim nc_logger.conf
更改配置如下:
# 定义这个 agent 中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 9000
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = logger
# 描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置 source channel sink 之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
我们使用如下命令启动一个 Flume Agent:
bin/flume-ng agent
-c conf
-f conf/nc_logger.conf
-n a1 -Dflume.root.logger=INFO,console
其中有几个关键的命令:
-
–conf (-c) 用来指定配置文件夹路径;
-
–conf-file(-f) 用来指定采集方案文件;
-
–name(-n) 用来指定 agent 名字;
-
-Dflume.root.logger=INFO,console 开启 flume 日志输出到终端。
用 nc 命令打开本地 9000 端口:
nc localhost 9000
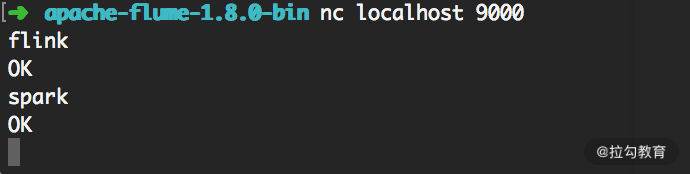
向端口输入几个单词,可以在另一端的控制台看到输出结果,如下图所示:

我们可以看到 9000 端口中输入的数据已经被打印出来了。
Flume + Kafka 整合
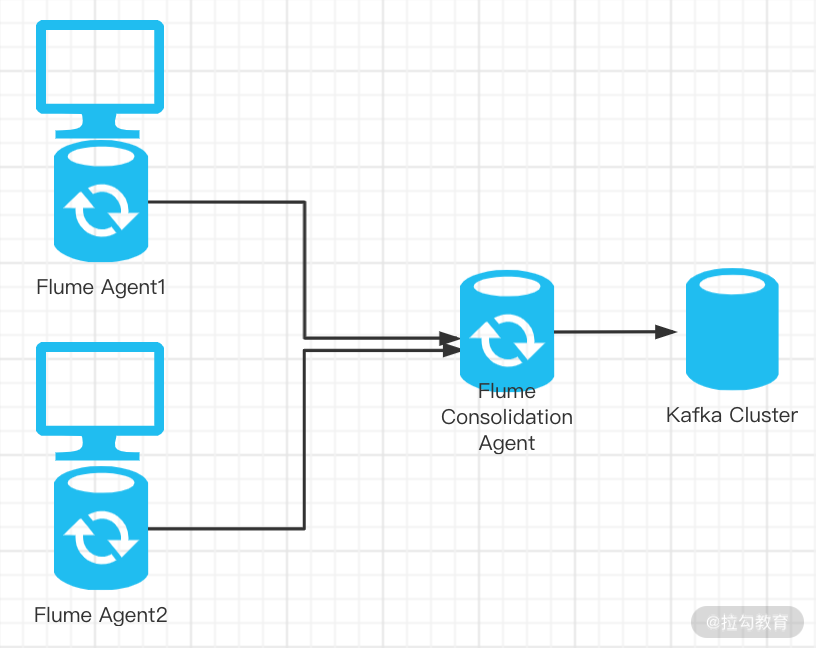
整体整合思路为,我们的两个 Flume Agent 分别部署在两台 Web 服务器上,用来采集两台服务器的业务日志,并且 Sink 到另一台 Flume Agent 上,然后将数据 Sink 到 Kafka 集群。在这里需要配置三个 Flume Agent。
首先在 Flume Agent 1 和 Flume Agent 2 上创建配置文件,具体如下。
修改 source、channel 和 sink 的配置,vim log_kafka.conf 代码如下:
# 定义这个 agent 中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source的配置,监听日志文件中的新增数据
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/logs/access.log
#sink配置,使用avro日志做数据的消费
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = flumeagent03
a1.sinks.k1.port = 9000
#channel配置,使用文件做数据的临时缓存
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/temp/flume/checkpoint
a1.channels.c1.dataDirs = /home/temp/flume/data
#描述和配置 source channel sink 之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c
上述配置会监听 /home/logs/access.log 文件中的数据变化,并且将数据 Sink 到 flumeagent03 的 9000 端口。
然后我们分别启动 Flume Agent 1 和 Flume Agent 2,命令如下:
$ flume-ng agent
-c conf
-n a1
-f conf/log_kafka.conf >/dev/null 2>&1 &
第三个 Flume Agent 用来接收上述两个 Agent 的数据,并且发送到 Kafka。我们需要启动本地 Kafka,并且创建一个名为 log_kafka 的 Topic。
然后,我们创建 Flume 配置文件,具体如下。
修改 source、channel 和 sink 的配置,vim flume_kafka.conf 代码如下:
# 定义这个 agent 中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#source配置
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 9000
#sink配置
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = log_kafka
a1.sinks.k1.brokerList = 127.0.0.1:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
#channel配置
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#描述和配置 source channel sink 之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置完成后,我们启动该 Flume Agent:
$ flume-ng agent
-c conf
-n a1
-f conf/flume_kafka.conf >/dev/null 2>&1 &
我们在第 24 课时“Flink 消费 Kafka 数据开发” 中详细讲解了 Flink 消费 Kafka 数据的开发。当 Flume Agent 1 和 2 中监听到新的日志数据后,数据就会被 Sink 到 Kafka 指定的 Topic,我们就可以消费 Kafka 中的数据了。
总结
这一课时首先介绍了 Flume 和 Kafka 的整合和部署,然后详细介绍了 Flume 的组件并且搭建了 Flume 的本地环境进行测试,最后介绍了 Flume 和 Kafka 整合的配置文件编写。通过本课时的学习,相信你对 Flume 有了深入了解,在实际应用中可以正确配置 Flume Agent。
精选评论
*帅:
为什么agent1和agent2不直接sink到kafka呢?
讲师回复:
在实际生产环境中,我们需要Flume Consolidation Agent做Flume的高可用
**冰:
还有个问题,你说第三个FLUME是做高可用,这一个单节点如何高可用了?kafka是集群的,不是更符合高可用的要求吗?
讲师回复:
Consolidation这种模式,通常用来处理日志数据来源是几十上百个节点的这种情况,故障发生主要在collector。你考虑的很对,可以通过kafka这种中间件实现故障转移。因为flume高可用方案重点就不再agent上。
**冰:
老师,这里我有个问题,source采用tail -f 读取更新的数据,这种重启服务时会有数据丢失吗?
讲师回复:
tail -f 也就是我们在日常环境做做测试,实际生产中是不会这么玩的。
**伯:
您好,我想咨询一下Flume配置的时候为什么要启动第三个FLUME而不是前面两个Flume收集到的日志直接推送到kafka中。
讲师回复:
小数据量规模是可以的,但是生产商一般会做Flume的高可用。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/bi/flink/2065-%E7%AC%AC30%E8%AE%B2Flume-%E5%92%8C-Kafka-%E6%95%B4%E5%90%88%E5%92%8C%E9%83%A8%E7%BD%B2/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


