Flink系列-第18讲:如何进行生产环境作业监控
本课时主要讲解如何进行生产环境作业监控。
在第 15 课时“如何排查生产环境中的反压问题”中提到过我们应该如何发现任务是否出现反压,Flink 的后台页面是我们发现反压问题的第一选择,其后台页面可以直观、清晰地看到当前作业的运行状态。
在实际生产中,Flink 的后台页面可以方便我们对 Flink JobManager、TaskManager、执行计划、Slot 分配、是否反压等参数进行定位,对单个任务来讲可以方便地进行问题排查。
但是,对于很多大中型企业来讲,我们对进群的作业进行管理时,更多的是关心作业精细化实时运行状态。例如,实时吞吐量的同比环比、整个集群的任务运行概览、集群水位,或者监控利用 Flink 实现的 ETL 框架的运行情况等,这时候就需要设计专门的监控系统来监控集群的任务作业情况。
Flink Metrics
针对上面的情况,我们就用了 Flink 提供的另一个强大的功能:Flink Metrics。
Flink Metrics 是 Flink 实现的一套运行信息收集库,我们不但可以收集 Flink 本身提供的系统指标,比如 CPU、内存、线程使用情况、JVM 垃圾收集情况、网络和 IO 等,还可以通过继承和实现指定的类或者接口打点收集用户自定义的指标。
通过使用 Flink Metrics 我们可以轻松地做到:
-
实时采集 Flink 中的 Metrics 信息或者自定义用户需要的指标信息并进行展示;
-
通过 Flink 提供的 Rest API 收集这些信息,并且接入第三方系统进行展示。
Flink Metrics 分类
Flink 提供了四种类型的监控指标,分别是:Counter、Gauge、Histogram、Meter。
Counter
Counter 称为计数器,一般用来统计其中一个指标的总量,比如统计数据的输入、输出总量。
public class MyMapper extends RichMapFunction<String, String> {
private transient Counter counter;
@Override
public void open(Configuration config) {
this.counter = getRuntimeContext()
.getMetricGroup()
.counter("MyCounter");
}
@Override
public String map(String value) throws Exception {
this.counter.inc();
return value;
}
}
Gauge
Gauge 被用来统计某一个指标的瞬时值。举个例子,我们在监控 Flink 中某一个节点的内存使用情况或者某个 map 算子的输出值数量。
public class MyMapper extends RichMapFunction<String, String> {
private transient int valueNumber = 0L;
@Override
public void open(Configuration config) {
getRuntimeContext()
.getMetricGroup()
.gauge("MyGauge", new Gauge<Long>() {
@Override
public Long getValue() {
return valueNumber;
}
});
}
@Override
public String map(String value) throws Exception {
valueNumber++;
return value;
}
}
Meter
Meter 被用来计算一个指标的平均值。
public class MyMapper extends RichMapFunction<Long, Integer> {
private Meter meter;
@Override
public void open(Configuration config) {
this.meter = getRuntimeContext()
.getMetricGroup()
.meter("myMeter", new MyMeter());
}
@public Integer map(Long value) throws Exception {
this.meter.markEvent();
}
}
Histogram
Histogram 是直方图,Flink 中属于直方图的指标非常少,它通常被用来计算指标的最大值、最小值、中位数等。
public class MyMapper extends RichMapFunction<Long, Integer> {
private Histogram histogram;
@Override
public void open(Configuration config) {
this.histogram = getRuntimeContext()
.getMetricGroup()
.histogram("myHistogram", new MyHistogram());
}
@public Integer map(Long value) throws Exception {
this.histogram.update(value);
}
}
这里需要特别指出的是,Flink 中的 Metrics 是一个多层的结构,以 Group 的方式存在,我们用来定位唯一的一个 Metrics 是通过 Metric Group + Metric Name 的方式。
源码分析
Flink Metrics 相关的实现都是通过 org.apache.flink.metrics.Metric 这个类实现的,整体的类图如下所示:
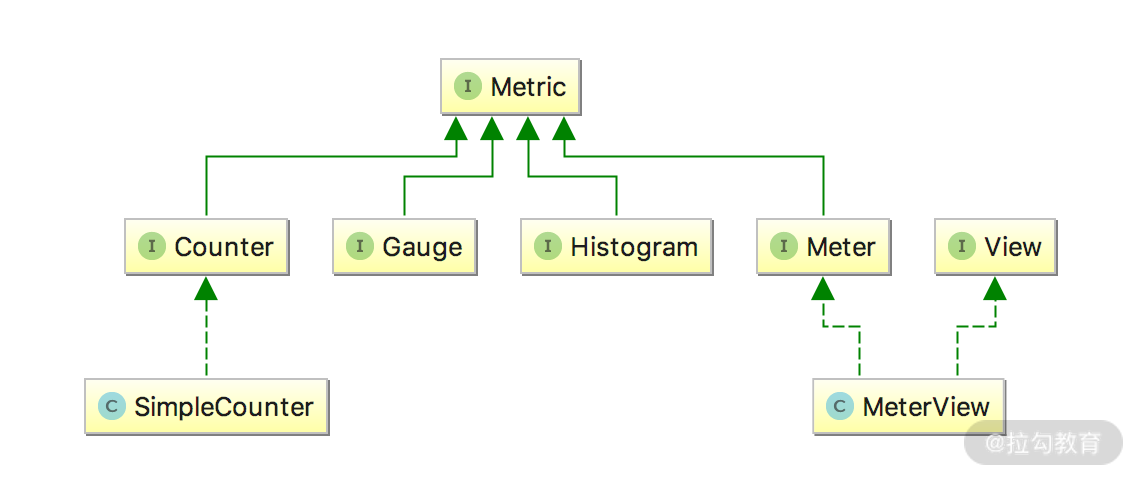
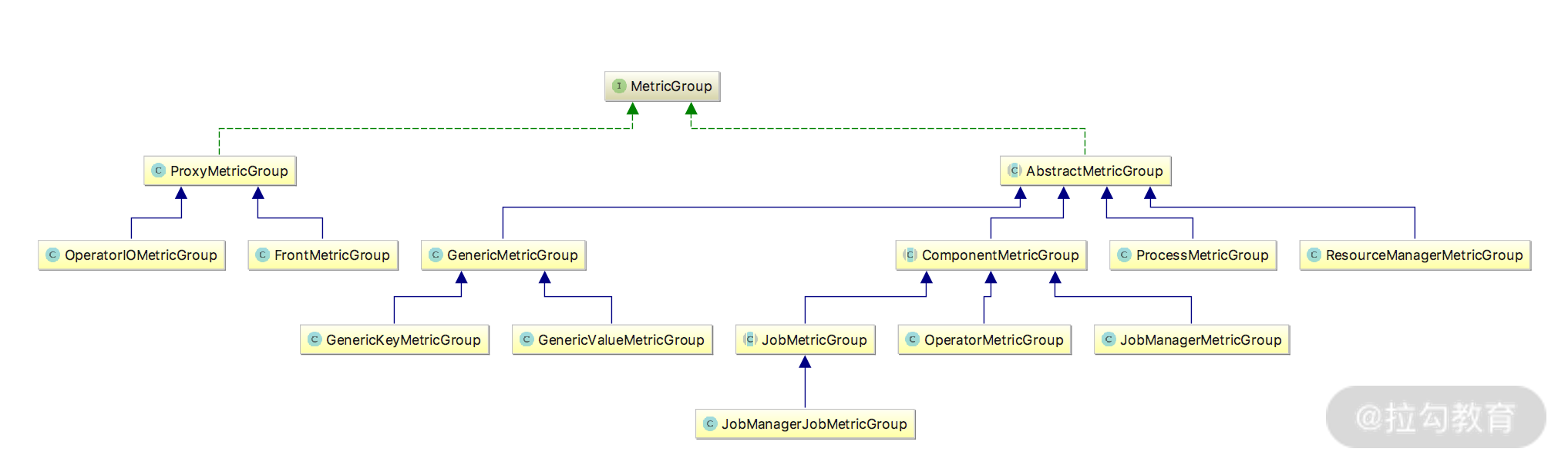
为了方便对 Metrics 进行管理和分类,Flink 提供了对 Metrics 进行分组的功能,这个功能是通过下图中 MetricGroup 实现的,在图中可以看到 MetricGroup 相关的子类的继承关系。
此外,Flink 还提供了向外披露 Metric 的监测结果的接口,该接口是 org.apache.flink.metrics.reporter.MetricReporter。这个接口的实现类通过 Metrics 的类型进行注册和移除。
public abstract class AbstractReporter implements MetricReporter, CharacterFilter {
protected final Logger log = LoggerFactory.getLogger(this.getClass());
protected final Map<Gauge<?>, String> gauges = new HashMap();
protected final Map<Counter, String> counters = new HashMap();
protected final Map<Histogram, String> histograms = new HashMap();
protected final Map<Meter, String> meters = new HashMap();
public AbstractReporter() {
}
public void notifyOfAddedMetric(Metric metric, String metricName, MetricGroup group) {
String name = group.getMetricIdentifier(metricName, this);
synchronized(this) {
if(metric instanceof Counter) {
this.counters.put((Counter)metric, name);
} else if(metric instanceof Gauge) {
this.gauges.put((Gauge)metric, name);
} else if(metric instanceof Histogram) {
this.histograms.put((Histogram)metric, name);
} else if(metric instanceof Meter) {
this.meters.put((Meter)metric, name);
} else {
this.log.warn("Cannot add unknown metric type {}. This indicates that the reporter does not support this metric type.", metric.getClass().getName());
}
}
}
public void notifyOfRemovedMetric(Metric metric, String metricName, MetricGroup group) {
synchronized(this) {
if(metric instanceof Counter) {
this.counters.remove(metric);
} else if(metric instanceof Gauge) {
this.gauges.remove(metric);
} else if(metric instanceof Histogram) {
this.histograms.remove(metric);
} else if(metric instanceof Meter) {
this.meters.remove(metric);
} else {
this.log.warn("Cannot remove unknown metric type {}. This indicates that the reporter does not support this metric type.", metric.getClass().getName());
}
}
}
}
获取 Metrics
获取 Metrics 的方法有多种,首先我们可以通过 Flink 的后台管理页面看到部分指标;其次可以通过 Flink 提供的 Http 接口查询 Flink 任务的状态信息,因为 Flink Http 接口返回的都是 Json 信息,我们可以很方便地将 Json 进行解析;最后一种方法是,我们可以通过 Metric Reporter 获取。下面分别对这两者进行详细讲解。
Flink HTTP 接口
Flink 提供了丰富的接口来协助我们查询 Flink 中任务运行的状态,所有的请求都可以通过访问
http://hostname:8081/ 加指定的 URI 方式查询,Flink 支持的所有 HTTP 接口你都可以点击这里查询到。
Flink 支持的接口包括:
/config
/overview
/jobs
/joboverview/running
/joboverview/completed
/jobs/<jobid>
/jobs/<jobid>/vertices
/jobs/<jobid>/config
/jobs/<jobid>/exceptions
/jobs/<jobid>/accumulators
/jobs/<jobid>/vertices/<vertexid>
/jobs/<jobid>/vertices/<vertexid>/subtasktimes
/jobs/<jobid>/vertices/<vertexid>/taskmanagers
/jobs/<jobid>/vertices/<vertexid>/accumulators
/jobs/<jobid>/vertices/<vertexid>/subtasks/accumulators
/jobs/<jobid>/vertices/<vertexid>/subtasks/<subtasknum>
/jobs/<jobid>/vertices/<vertexid>/subtasks/<subtasknum>/attempts/<attempt>
/jobs/<jobid>/vertices/<vertexid>/subtasks/<subtasknum>/attempts/<attempt>/accumulators
/jobs/<jobid>/plan
/jars/upload
/jars
/jars/:jarid
/jars/:jarid/plan
/jars/:jarid/run
举个例子,我们可以通过查询 /joboverview 访问集群中所有任务的概览,结果类似如下形式:
{
"running":[],
"finished":[
{
"jid": "7684be6004e4e955c2a558a9bc463f65",
"name": "Flink Java Job at Wed Sep 16 18:08:21 CEST 2015",
"state": "FINISHED",
"start-time": 1442419702857,
"end-time": 1442419975312,
"duration":272455,
"last-modification": 1442419975312,
"tasks": {
"total": 6,
"pending": 0,
"running": 0,
"finished": 6,
"canceling": 0,
"canceled": 0,
"failed": 0
}
},
{
"jid": "49306f94d0920216b636e8dd503a6409",
"name": "Flink Java Job at Wed Sep 16 18:16:39 CEST 2015",
...
}]
}
Flink Reporter
Flink 还提供了很多内置的 Reporter,这些 Reporter 在 Flink 的官网中可以查询到。
例如,Flink 提供了 Graphite、InfluxDB、Prometheus 等内置的 Reporter,我们可以方便地对这些外部系统进行集成。关于它们的详细配置也可以在 Flink 官网的详情页面中看到。
这里我们举一个 Flink 和 InfluxDB、Grafana 集成进行 Flink 集群任务监控的案例。在这个监控系统中,InfluxDB 扮演了 Flink 中监控数据存储者的角色,Grafana 则扮演了数据展示者的角色。
-
InfluxDB 的安装
InfluxDB 是一个由 InfluxData 开发的开源时序型数据,由 Go 写成,着力于高性能地查询与存储时序型数据。InfluxDB 被广泛应用于存储系统的监控数据,IoT 行业的实时数据等场景。
InfluxDB 的安装过程很简单,我们不在这里赘述了,需要注意的事项是修改 InfluxDB 的配置 /etc/influxdb/influxdb.conf:
[admin]
enabled = true
bind-address = ":8083"
我们就可以通过 8083 端口打开 InfluxDB 的控制台了。
-
Grafana 的安装
安装可以直接点击这里参考官网说明,Grafana 的默认账号和密码分别是 admin、admin,可以通过 3000 端口进行访问。
-
修改 flink-conf.yaml
我们需要在 flink 的配置文件中新增以下配置:
metrics.reporter.influxdb.class: org.apache.flink.metrics.influxdb.InfluxdbReporter
metrics.reporter.influxdb.host: xxx.xxx.xxx.xxx
metrics.reporter.influxdb.port: 8086
metrics.reporter.influxdb.db: flink
同时,将 flink-metrics-influxdb-1.10.0.jar 这个包复制到 flink 的 /lib 目录下,然后启动 Flink。
我们就可以在 Grafana 中看到 Metrics 信息了。
事实上,常用的 Flink 实时监控大盘包括但不限于:Prometheus+Grafana、Flink 日志接入 ELK等可以供用户选择。结合易用性、稳定性和接入成本,综合考虑,我们推荐实际监控中可以采用 Prometheus/InfluxDB+Grafana 相配合的方式。
总结
这一课时我们讲解了 Flink Metrics 指标的分类,并且从源码层面介绍了 Flink Metrics 的实现原理,最后还讲解了 Flink 监控这个 Metrics 的方式。我们在实际生产中应该灵活选取合适的监控方法,搭建自己的 Flink 任务监控大盘。
精选评论
**军:
大佬,问下在yarn下如果nodemanager挂掉了,配置了nm的recover,那么taskmanager也可以直接重启恢复吗
讲师回复:
taskManager的重启严格上来讲是受Flink的JobManager,如果JobManager发生recover,TaskManager也会被重启。
**阳:
0803打卡:https://share.mubu.com/doc/61tskwLu681 如何进行生产环境作业监控。目前公司对flink的监控就是采用influxDB进行的
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/bi/flink/2053-%E7%AC%AC18%E8%AE%B2%E5%A6%82%E4%BD%95%E8%BF%9B%E8%A1%8C%E7%94%9F%E4%BA%A7%E7%8E%AF%E5%A2%83%E4%BD%9C%E4%B8%9A%E7%9B%91%E6%8E%A7/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


