Flink系列-第17讲:生产环境中的并行度和资源设置
在使用 Flink 处理生产实际问题时,并行度和资源的配置调优是我们经常要面对的工作之一,如何有效和正确地配置并行度是我们的任务能够高效执行的必要条件。这一课时就来看一下生产环境的并行度和资源配置问题。
Flink 中的计算资源
通常我们说的 Flink 中的计算资源是指具体任务的 Task。首先要理解 Flink 中的计算资源的一些核心概念,比如 Slot、Chain、Task 等,正确理解这些概念有助于开发者了解 Flink 中的计算资源是如何进行隔离和管理的,也有助于我们快速地定位生产中的问题。
Task Slot
我们在第 03 课时“Flink 的编程模型与其他框架比较” 中提到过,在实际生产中,Flink 都是以集群在运行,在运行的过程中包含了两类进程,其中之一就是:TaskManager。
在 Flink 集群中,一个 TaskManger 就是一个 JVM 进程,并且会用独立的线程来执行 task,为了控制一个 TaskManger 能接受多少个 task,Flink 提出了 Task Slot 的概念。
我们可以简单地把 Task Slot 理解为 TaskManager 的计算资源子集。假如一个 TaskManager 拥有 5 个 Slot,那么该 TaskManager 的计算资源会被平均分为 5 份,不同的 task 在不同的 Slot 中执行,避免资源竞争。但需要注意的是,Slot 仅仅用来做内存的隔离,对 CPU 不起作用。那么运行在同一个 JVM 的 task 可以共享 TCP 连接,以减少网络传输,在一定程度上提高了程序的运行效率,降低了资源消耗。
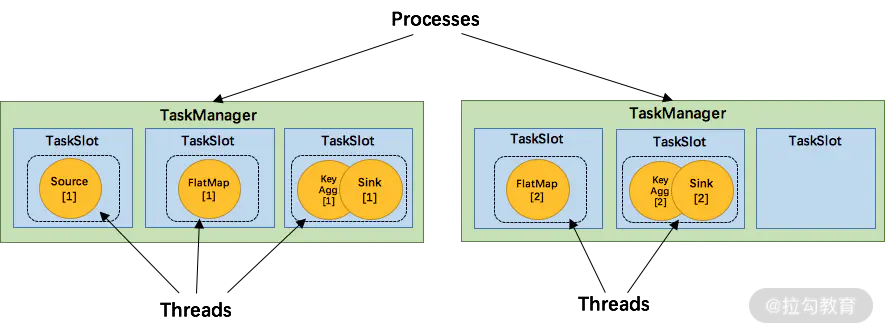
Slot 共享
默认情况下,Flink 还允许同一个 Job 的子任务共享 Slot。因为在一个 Flink 任务中,有很多的算子,这些算子的计算压力各不相同,比如简单的 map 和 filter 算子所需要的资源不多,但是有些算子比如 window、group by 则需要更多的计算资源才能满足计算所需。这时候那些资源需求大的算子就可以共用其他的 Slot,提高整个集群的资源利用率。
Operator Chain
此外,Flink 自身会把不同的算子的 task 连接在一起组成一个新的 task。这么做是因为 Flink 本身提供了非常有效的任务优化手段,因为 task 是在同一个线程中执行,那么可以有效减少线程间上下文的切换,并且减少序列化/反序列化带来的资源消耗,从而在整体上提高我们任务的吞吐量。
并行度
Flink 使用并行度来定义某一个算子被切分成多少个子任务。我们的 Flink 代码会被转换成逻辑视图,在实际运行时,根据用户的并行度配置会被转换成对应的子任务进行执行。
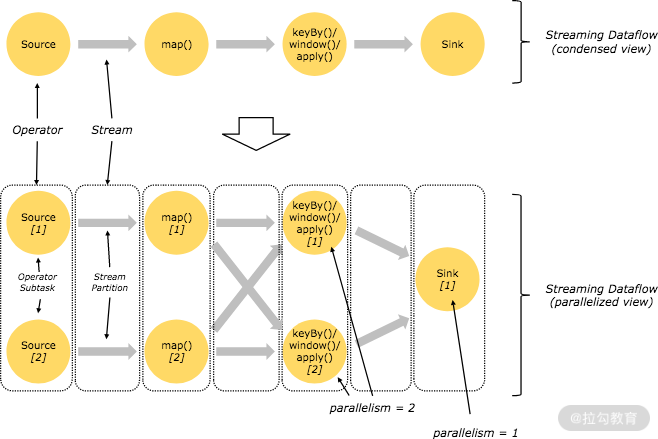
源码解析
Flink Job 在执行中会通过 SlotProvider 向 ResourceManager 申请资源,RM 负责协调 TaskManager,满足 JobManager 的资源请求。
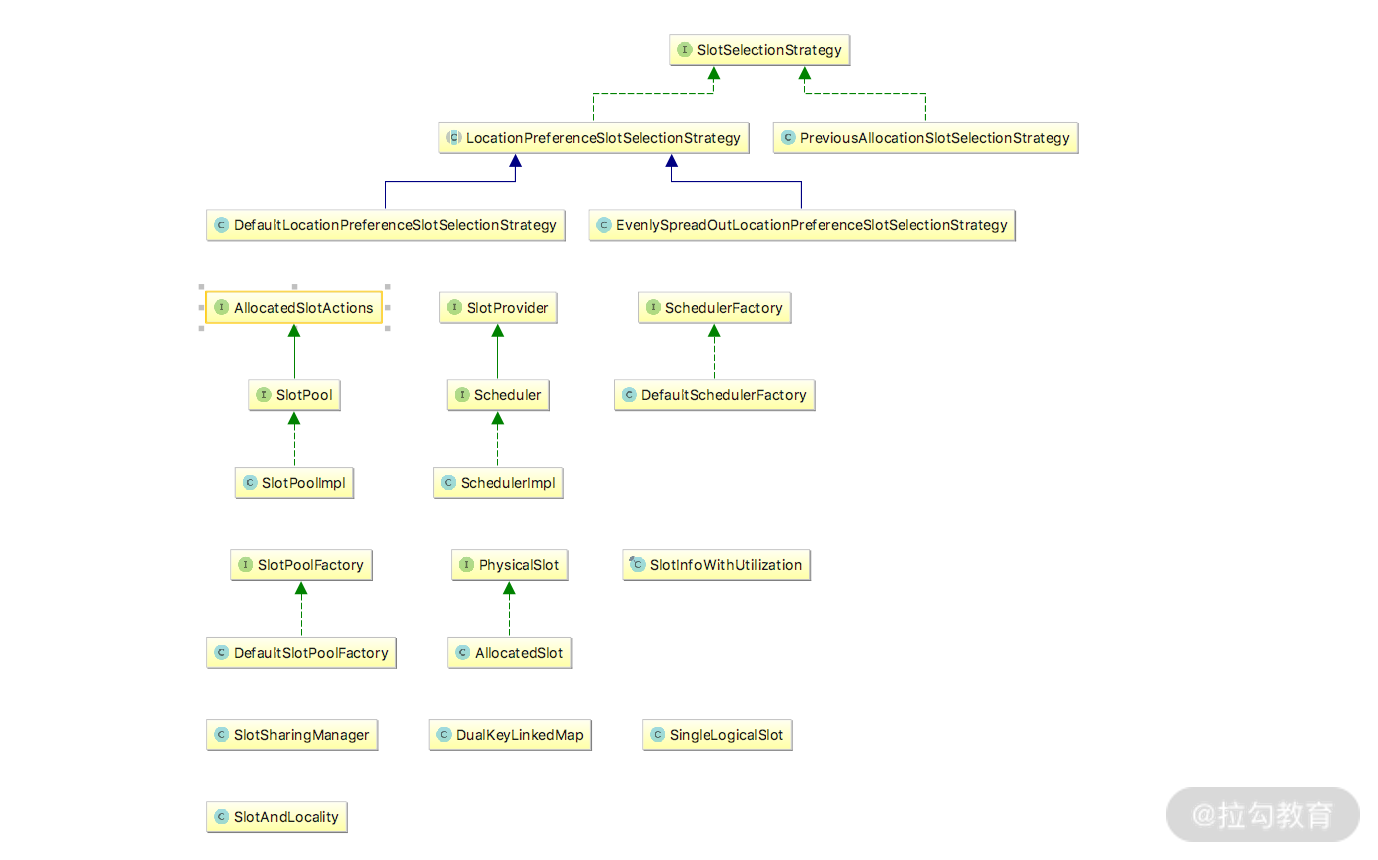
整体的类图如上图所示,SlotProvider 中的 allocateSlot 方法负责向 SlotPool 申请可用的 slot 资源,通过 returnLogicSlot 将空闲的 slot 释放至 SlotPool。
在整个 Flink 的资源管理的类中,核心的类包括 Scheduler、SlotPool、JobMaster。它们之间的交互流程主要包括:Scheduler 调度器会向 SlotPool 资源池申请和释放 Slot;如果 SlotPool 不能满足需求,那么会向 ResourceManager 发起申请;获取到的资源通过 JobMaster 分配给 SlotPool。
关于更多的资源管理的实现流程,可以参考上面的类图查看源码。
如何设置并行度
Flink 本身支持不同级别来设置我们任务并行度的方法,它们分别是:
- 算子级别
- 环境级别
- 客户端级别
- 集群配置级别
下面依次讲解 Flink 中的四种并行度的设置方法,以及它们的优先级。
算子级别
我们在编写 Flink 程序时,可以在代码中显示的制定不同算子的并行度。用经典的 wordcount 程序举例:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = ...
DataStream<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.setParallelism(10)
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1).setParallelism(1);
wordCounts.print();
env.execute("word count");
如上述代码所示,我们可以通过显示的调用 setParallelism() 方法来显示的指定每个算子的并行度配置。
在实际生产中,我们推荐在算子级别显示指定各自的并行度,方便进行显示和精确的资源控制。
环境级别
环境级别的并行度设置指的是我们可以通过调用 env.setParallelism() 方法来设置整个任务的并行度:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(5);
...
一旦设置了这个参数,表明我们任务中的所有算子的并行度都是指定的值,生产环境中并不推荐。
客户端级别
我们可以在使用命令提交 Flink Job 的时候指定并行度,当任务执行时发现代码中没有设置并行度,便会采用我们提交命令时的参数。
通过 -p 命令来指定任务提交时候的并行度:
./bin/flink run -p 5 ../wordCount-java*.jar
集群配置级别
我们的 flink-conf.yaml 文件中有一个参数 parallelism.default,该参数会在用户不设置任何其他的并行度配置时生效:

需要特别指出的是,设置并行度的优先级依次是:
算子级别 > 环境级别 > 客户端级别 > 集群配置级别
我们推荐在生产环境中使用算子级别的并行度进行资源控制。
总结
本课时我们讲解了 Flink 中和资源相关的几个重要概念,并且讲解了并行度设置的四种方法,我们在生产环境中的并行度设置是经过多次调优得出的。通过本课时的学习,你将会了解 Flink 中的并行度设置方法,并且能在生产环境中正确设置并行度。
精选评论
**阳:
0802打卡:https://share.mubu.com/doc/3pcf1yMWIc1 生产环境中的并行度和资源设置,算子级别集群配置级别。task slot的目的是避免资源竞争,slot共享是提高整个集群的利用率,operation chain是为了提高任务的吞吐量,并行度代表算子被切分成多少子任务
*强:
slot不共享内存但是共享cpu,运行在同一个 JVM 的 task 可以共享 TCP 连接,以减少网络传输
*涛:
清析易懂
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/bi/flink/2052-%E7%AC%AC17%E8%AE%B2%E7%94%9F%E4%BA%A7%E7%8E%AF%E5%A2%83%E4%B8%AD%E7%9A%84%E5%B9%B6%E8%A1%8C%E5%BA%A6%E5%92%8C%E8%B5%84%E6%BA%90%E8%AE%BE%E7%BD%AE/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


