Flink系列-第10讲:Flink Side OutPut 分流
这一课时将介绍 Flink 中提供的一个很重要的功能:旁路分流器。
分流场景
我们在生产实践中经常会遇到这样的场景,需把输入源按照需要进行拆分,比如我期望把订单流按照金额大小进行拆分,或者把用户访问日志按照访问者的地理位置进行拆分等。面对这样的需求该如何操作呢?
分流的方法
通常来说针对不同的场景,有以下三种办法进行流的拆分。
Filter 分流
Filter 方法我们在第 04 课时中(Flink 常用的 DataSet 和 DataStream API)讲过,这个算子用来根据用户输入的条件进行过滤,每个元素都会被 filter() 函数处理,如果 filter() 函数返回 true 则保留,否则丢弃。那么用在分流的场景,我们可以做多次 filter,把我们需要的不同数据生成不同的流。
来看下面的例子:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
<span class="hljs-comment">//获取数据源</span>
List data = <span class="hljs-keyword">new</span> ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">0</span>,<span class="hljs-number">1</span>,<span class="hljs-number">0</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">0</span>,<span class="hljs-number">1</span>,<span class="hljs-number">1</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">0</span>,<span class="hljs-number">2</span>,<span class="hljs-number">2</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">0</span>,<span class="hljs-number">1</span>,<span class="hljs-number">3</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">5</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">9</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">11</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">13</span>));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> zeroStream = items.filter((FilterFunction<Tuple3<Integer, Integer, Integer>>) value -> value.f0 == <span class="hljs-number">0</span>);
SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> oneStream = items.filter((FilterFunction<Tuple3<Integer, Integer, Integer>>) value -> value.f0 == <span class="hljs-number">1</span>);
zeroStream.print();
oneStream.printToErr();
<span class="hljs-comment">//打印结果</span>
String jobName = <span class="hljs-string">"user defined streaming source"</span>;
env.execute(jobName);
}
在上面的例子中我们使用 filter 算子将原始流进行了拆分,输入数据第一个元素为 0 的数据和第一个元素为 1 的数据分别被写入到了 zeroStream 和 oneStream 中,然后把两个流进行了打印。
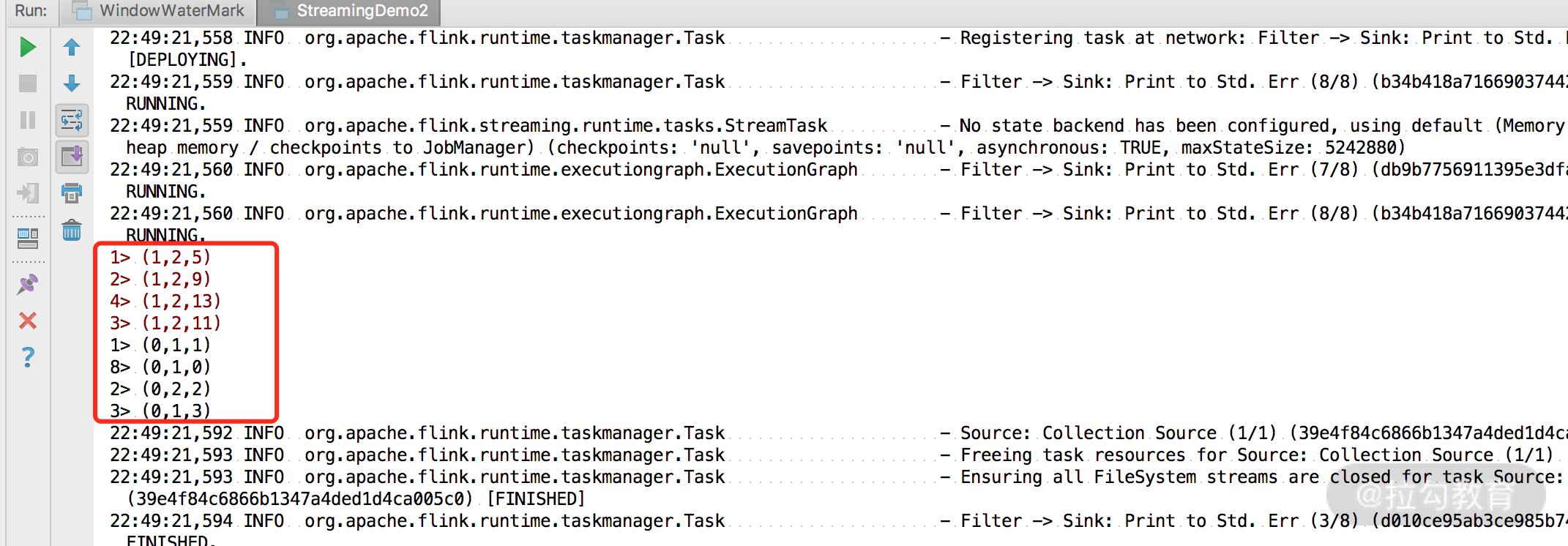
可以看到 zeroStream 和 oneStream 分别被打印出来。
Filter 的弊端是显而易见的,为了得到我们需要的流数据,需要多次遍历原始流,这样无形中浪费了我们集群的资源。
Split 分流
Split 也是 Flink 提供给我们将流进行切分的方法,需要在 split 算子中定义 OutputSelector,然后重写其中的 select 方法,将不同类型的数据进行标记,最后对返回的 SplitStream 使用 select 方法将对应的数据选择出来。
我们来看下面的例子:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
<span class="hljs-comment">//获取数据源</span>
List data = <span class="hljs-keyword">new</span> ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">0</span>,<span class="hljs-number">1</span>,<span class="hljs-number">0</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">0</span>,<span class="hljs-number">1</span>,<span class="hljs-number">1</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">0</span>,<span class="hljs-number">2</span>,<span class="hljs-number">2</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">0</span>,<span class="hljs-number">1</span>,<span class="hljs-number">3</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">5</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">9</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">11</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">13</span>));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
SplitStream<Tuple3<Integer, Integer, Integer>> splitStream = items.split(<span class="hljs-keyword">new</span> OutputSelector<Tuple3<Integer, Integer, Integer>>() {
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Iterable<String> <span class="hljs-title">select</span><span class="hljs-params">(Tuple3<Integer, Integer, Integer> value)</span> </span>{
List<String> tags = <span class="hljs-keyword">new</span> ArrayList<>();
<span class="hljs-keyword">if</span> (value.f0 == <span class="hljs-number">0</span>) {
tags.add(<span class="hljs-string">"zeroStream"</span>);
} <span class="hljs-keyword">else</span> <span class="hljs-keyword">if</span> (value.f0 == <span class="hljs-number">1</span>) {
tags.add(<span class="hljs-string">"oneStream"</span>);
}
<span class="hljs-keyword">return</span> tags;
}
});
splitStream.select(<span class="hljs-string">"zeroStream"</span>).print();
splitStream.select(<span class="hljs-string">"oneStream"</span>).printToErr();
<span class="hljs-comment">//打印结果</span>
String jobName = <span class="hljs-string">"user defined streaming source"</span>;
env.execute(jobName);
}
同样,我们把来源的数据使用 split 算子进行了切分,并且打印出结果。
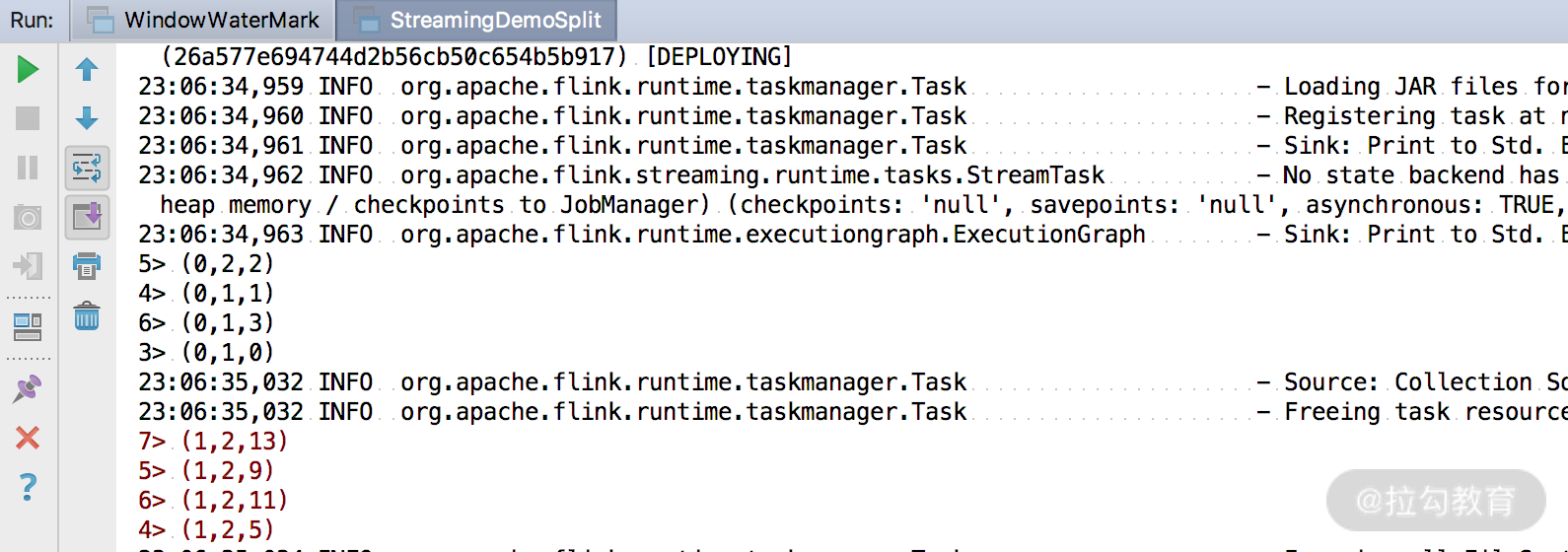
但是要注意,使用 split 算子切分过的流,是不能进行二次切分的,假如把上述切分出来的 zeroStream 和 oneStream 流再次调用 split 切分,控制台会抛出以下异常。
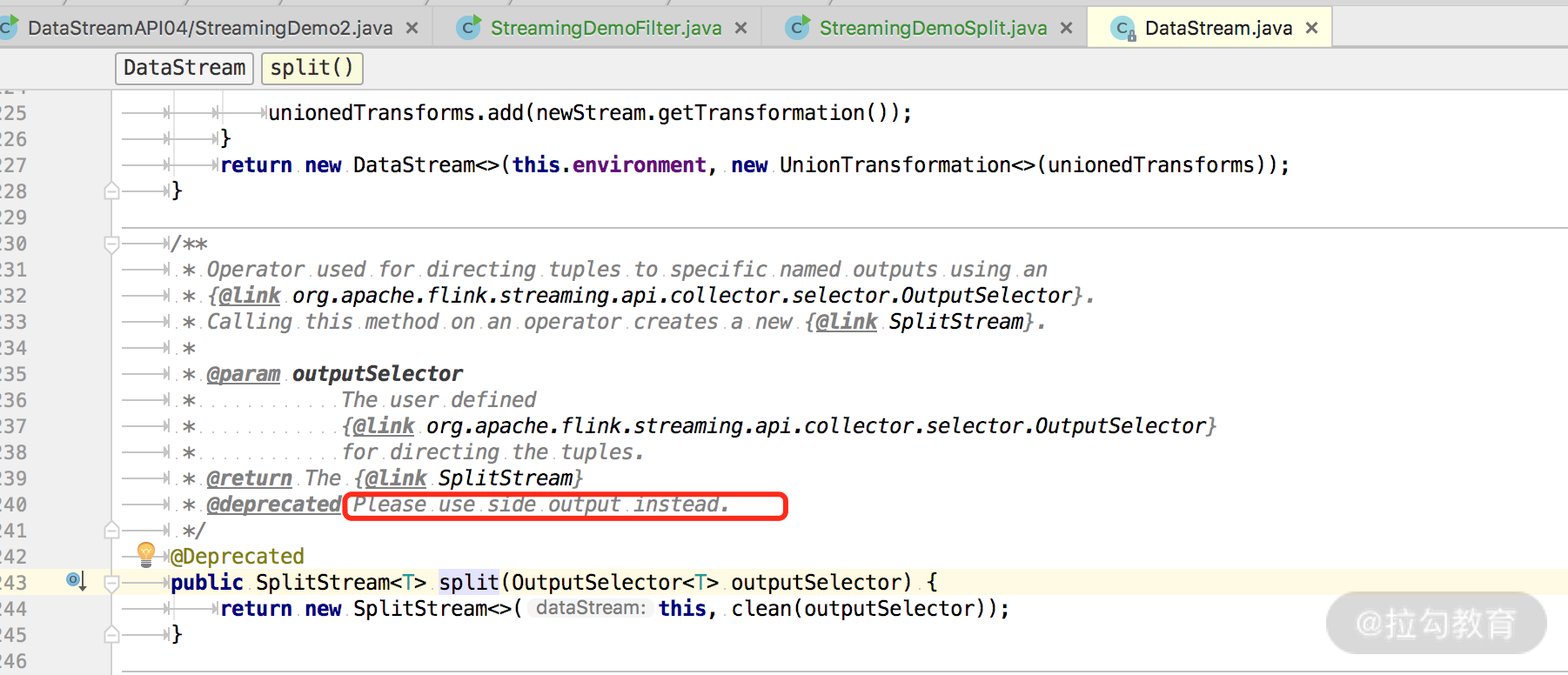
Exception in thread "main" java.lang.IllegalStateException: Consecutive multiple splits are not supported. Splits are deprecated. Please use side-outputs.
这是什么原因呢?我们在源码中可以看到注释,该方式已经废弃并且建议使用最新的 SideOutPut 进行分流操作。
SideOutPut 分流
SideOutPut 是 Flink 框架为我们提供的最新的也是最为推荐的分流方法,在使用 SideOutPut 时,需要按照以下步骤进行:
- 定义 OutputTag
- 调用特定函数进行数据拆分
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
在这里我们使用 ProcessFunction 来讲解如何使用 SideOutPut:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
<span class="hljs-comment">//获取数据源</span>
List data = <span class="hljs-keyword">new</span> ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">0</span>,<span class="hljs-number">1</span>,<span class="hljs-number">0</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">0</span>,<span class="hljs-number">1</span>,<span class="hljs-number">1</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">0</span>,<span class="hljs-number">2</span>,<span class="hljs-number">2</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">0</span>,<span class="hljs-number">1</span>,<span class="hljs-number">3</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">5</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">9</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">11</span>));
data.add(<span class="hljs-keyword">new</span> Tuple3<>(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">13</span>));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
OutputTag<Tuple3<Integer,Integer,Integer>> zeroStream = <span class="hljs-keyword">new</span> OutputTag<Tuple3<Integer,Integer,Integer>>(<span class="hljs-string">"zeroStream"</span>) {};
OutputTag<Tuple3<Integer,Integer,Integer>> oneStream = <span class="hljs-keyword">new</span> OutputTag<Tuple3<Integer,Integer,Integer>>(<span class="hljs-string">"oneStream"</span>) {};
SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> processStream= items.process(<span class="hljs-keyword">new</span> ProcessFunction<Tuple3<Integer, Integer, Integer>, Tuple3<Integer, Integer, Integer>>() {
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">void</span> <span class="hljs-title">processElement</span><span class="hljs-params">(Tuple3<Integer, Integer, Integer> value, Context ctx, Collector<Tuple3<Integer, Integer, Integer>> out)</span> <span class="hljs-keyword">throws</span> Exception </span>{
<span class="hljs-keyword">if</span> (value.f0 == <span class="hljs-number">0</span>) {
ctx.output(zeroStream, value);
} <span class="hljs-keyword">else</span> <span class="hljs-keyword">if</span> (value.f0 == <span class="hljs-number">1</span>) {
ctx.output(oneStream, value);
}
}
});
DataStream<Tuple3<Integer, Integer, Integer>> zeroSideOutput = processStream.getSideOutput(zeroStream);
DataStream<Tuple3<Integer, Integer, Integer>> oneSideOutput = processStream.getSideOutput(oneStream);
zeroSideOutput.print();
oneSideOutput.printToErr();
<span class="hljs-comment">//打印结果</span>
String jobName = <span class="hljs-string">"user defined streaming source"</span>;
env.execute(jobName);
}
可以看到,我们将流进行了拆分,并且成功打印出了结果。这里要注意,Flink 最新提供的 SideOutPut 方式拆分流是可以多次进行拆分的,无需担心会爆出异常。
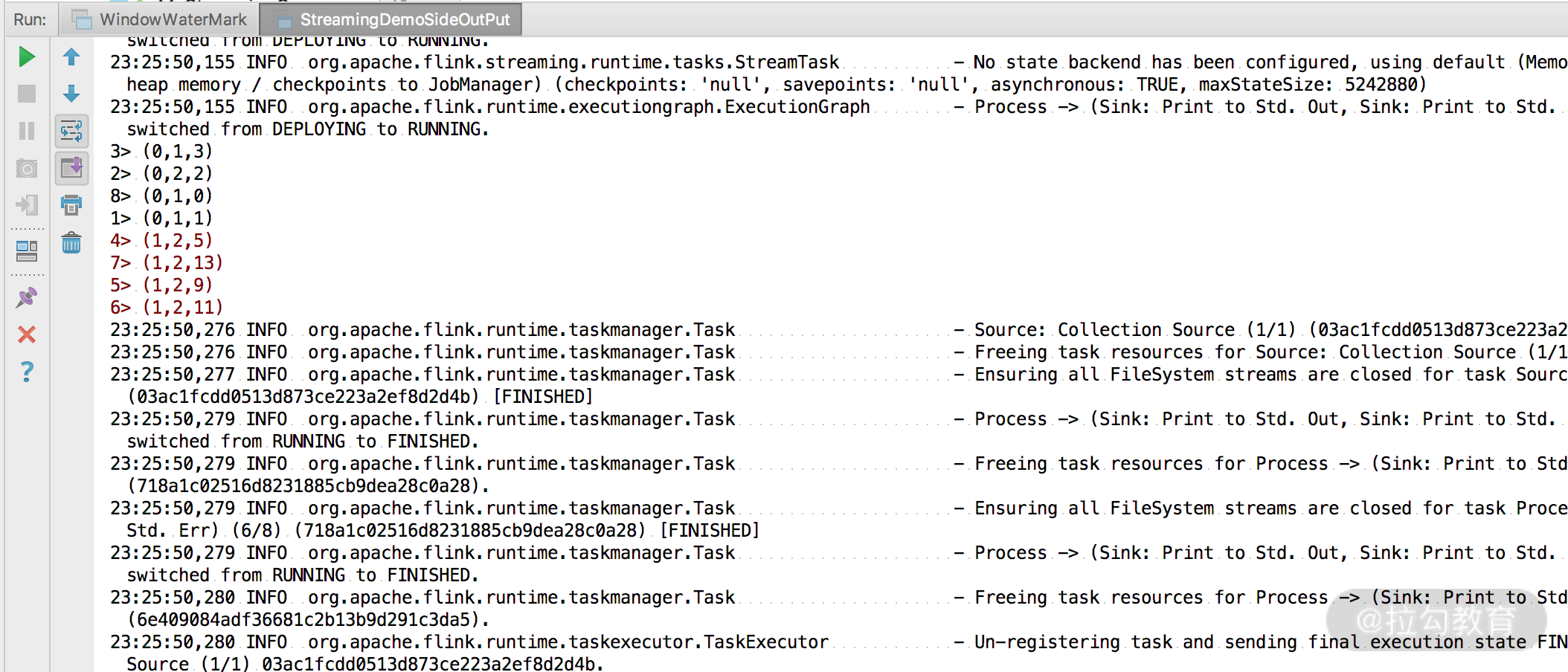
总结
这一课时我们讲解了 Flink 的一个小的知识点,是我们生产实践中经常遇到的场景,Flink 在最新的版本中也推荐我们使用 SideOutPut 进行流的拆分。
精选评论
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/bi/flink/2045-%E7%AC%AC10%E8%AE%B2Flink-Side-OutPut-%E5%88%86%E6%B5%81/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


