Flink系列-第08讲:Flink 窗口、时间和水印
本课时主要介绍 Flink 中的时间和水印。
我们在之前的课时中反复提到过窗口和时间的概念,Flink 框架中支持事件时间、摄入时间和处理时间三种。而当我们在流式计算环境中数据从 Source 产生,再到转换和输出,这个过程由于网络和反压的原因会导致消息乱序。因此,需要有一个机制来解决这个问题,这个特别的机制就是“水印”。
Flink 的窗口和时间
我们在第 05 课时中讲解过 Flink 窗口的实现,根据窗口数据划分的不同,目前 Flink 支持如下 3 种:
-
滚动窗口,窗口数据有固定的大小,窗口中的数据不会叠加;
-
滑动窗口,窗口数据有固定的大小,并且有生成间隔;
-
会话窗口,窗口数据没有固定的大小,根据用户传入的参数进行划分,窗口数据无叠加。
Flink 中的时间分为三种:
-
事件时间(Event Time),即事件实际发生的时间;
-
摄入时间(Ingestion Time),事件进入流处理框架的时间;
-
处理时间(Processing Time),事件被处理的时间。
下面的图详细说明了这三种时间的区别和联系:
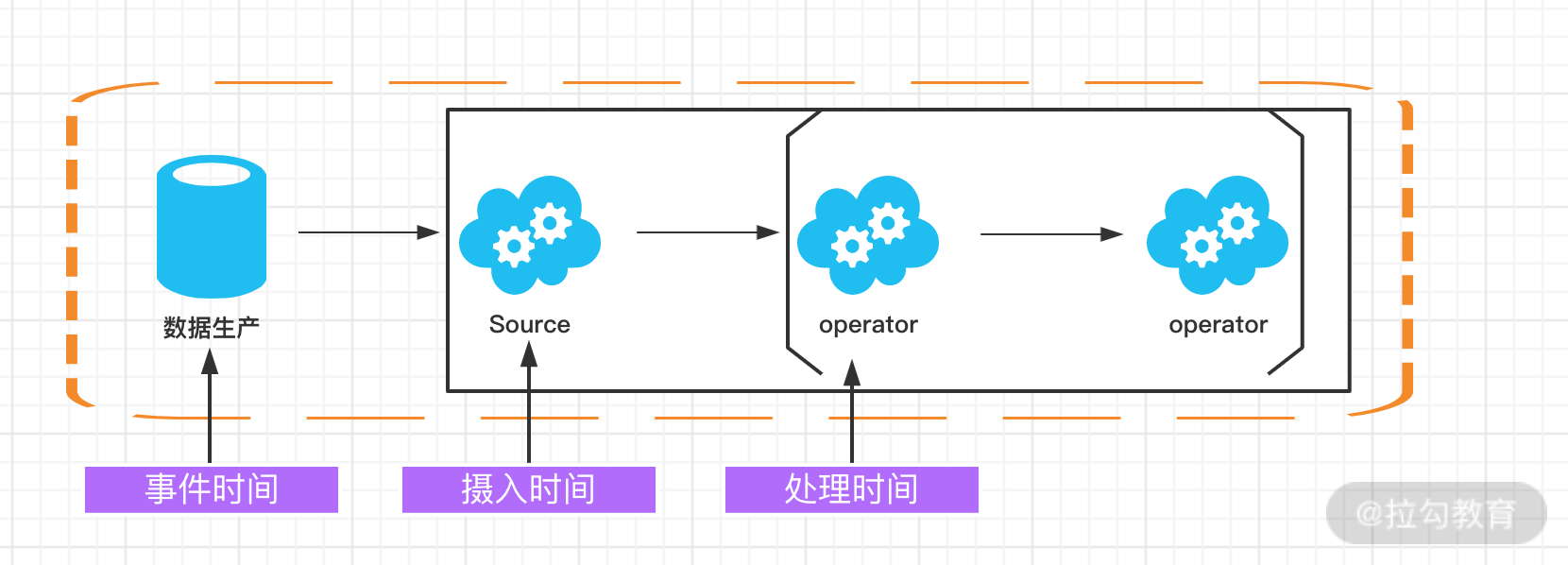
事件时间(Event Time)
事件时间(Event Time)指的是数据产生的时间,这个时间一般由数据生产方自身携带,比如 Kafka 消息,每个生成的消息中自带一个时间戳代表每条数据的产生时间。Event Time 从消息的产生就诞生了,不会改变,也是我们使用最频繁的时间。
利用 Event Time 需要指定如何生成事件时间的“水印”,并且一般和窗口配合使用,具体会在下面的“水印”内容中详细讲解。
我们可以在代码中指定 Flink 系统使用的时间类型为 EventTime:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置时间属性为 EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<MyEvent> stream = env.addSource(new FlinkKafkaConsumer09<MyEvent>(topic, schema, props));
stream
.keyBy( (event) -> event.getUser() )
.timeWindow(Time.hours(1))
.reduce( (a, b) -> a.add(b) )
.addSink(…);
Flink 注册 EventTime 是通过 InternalTimerServiceImpl.registerEventTimeTimer 来实现的:

可以看到,该方法有两个入参:namespace 和 time,其中 time 是触发定时器的时间,namespace 则被构造成为一个 TimerHeapInternalTimer 对象,然后将其放入 KeyGroupedInternalPriorityQueue 队列中。
那么 Flink 什么时候会使用这些 timer 触发计算呢?答案在这个方法里:
InternalTimeServiceImpl.advanceWatermark。
public void advanceWatermark(long time) throws Exception {
currentWatermark = time;
InternalTimer<K, N> timer;
while ((timer = eventTimeTimersQueue.peek()) != null && timer.getTimestamp() <= time) {
eventTimeTimersQueue.poll();
keyContext.setCurrentKey(timer.getKey());
triggerTarget.onEventTime(timer);
}
}
这个方法中的 while 循环部分会从 eventTimeTimersQueue 中依次取出触发时间小于参数 time 的所有定时器,调用 triggerTarget.onEventTime() 方法进行触发。
这就是 EventTime 从注册到触发的流程。
处理时间(Processing Time)
处理时间(Processing Time)指的是数据被 Flink 框架处理时机器的系统时间,Processing Time 是 Flink 的时间系统中最简单的概念,但是这个时间存在一定的不确定性,比如消息到达处理节点延迟等影响。
我们同样可以在代码中指定 Flink 系统使用的时间为 Processing Time:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
同样,也可以在源码中找到 Flink 是如何注册和使用 Processing Time 的。
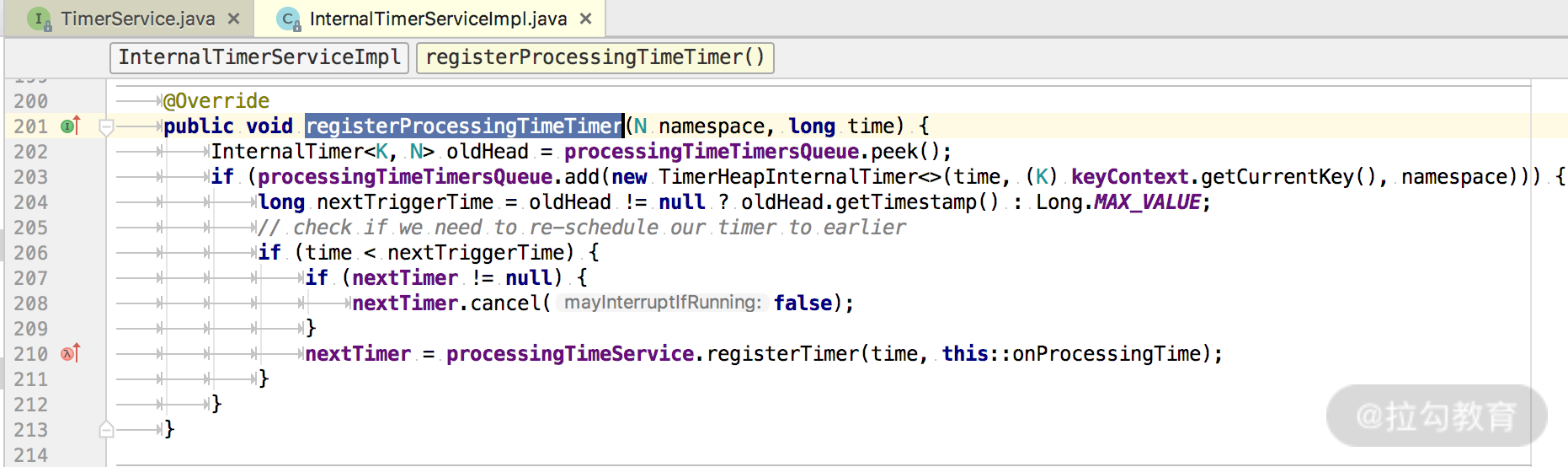
registerProcessingTimeTimer() 方法为我们展示了如何注册一个 ProcessingTime 定时器:
每当一个新的定时器被加入到 processingTimeTimersQueue 这个优先级队列中时,如果新来的 Timer 时间戳更小,那么更小的这个 Timer 会被重新注册 ScheduledThreadPoolExecutor 定时执行器上。
Processing Time 被触发是在 InternalTimeServiceImpl 的 onProcessingTime() 方法中:
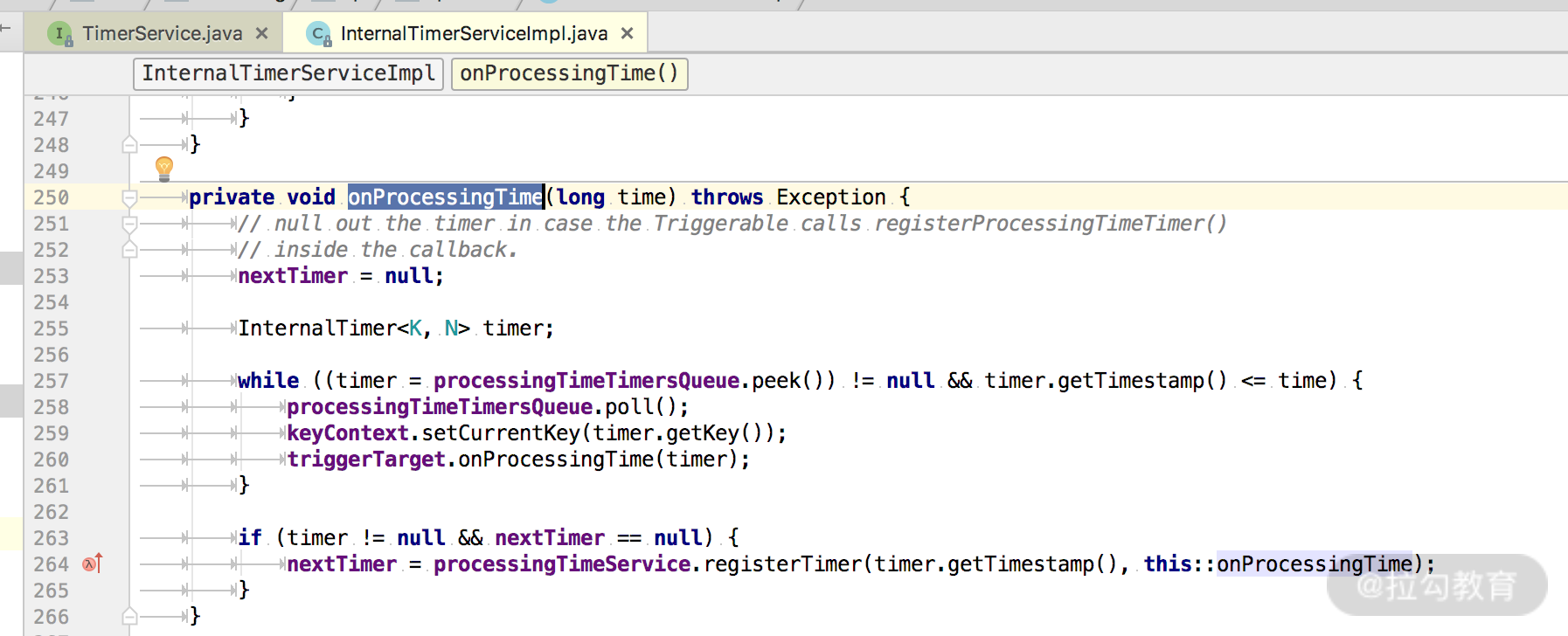
一直循环获取时间小于入参 time 的所有定时器,并运行 triggerTarget 的 onProcessingTime() 方法。
摄入时间(Ingestion Time)
摄入时间(Ingestion Time)是事件进入 Flink 系统的时间,在 Flink 的 Source 中,每个事件会把当前时间作为时间戳,后续做窗口处理都会基于这个时间。理论上 Ingestion Time 处于 Event Time 和 Processing Time之间。
与事件时间相比,摄入时间无法处理延时和无序的情况,但是不需要明确执行如何生成 watermark。在系统内部,摄入时间采用更类似于事件时间的处理方式进行处理,但是有自动生成的时间戳和自动的 watermark。
可以防止 Flink 内部处理数据是发生乱序的情况,但无法解决数据到达 Flink 之前发生的乱序问题。如果需要处理此类问题,建议使用 EventTime。
Ingestion Time 的时间类型生成相关的代码在 AutomaticWatermarkContext 中:
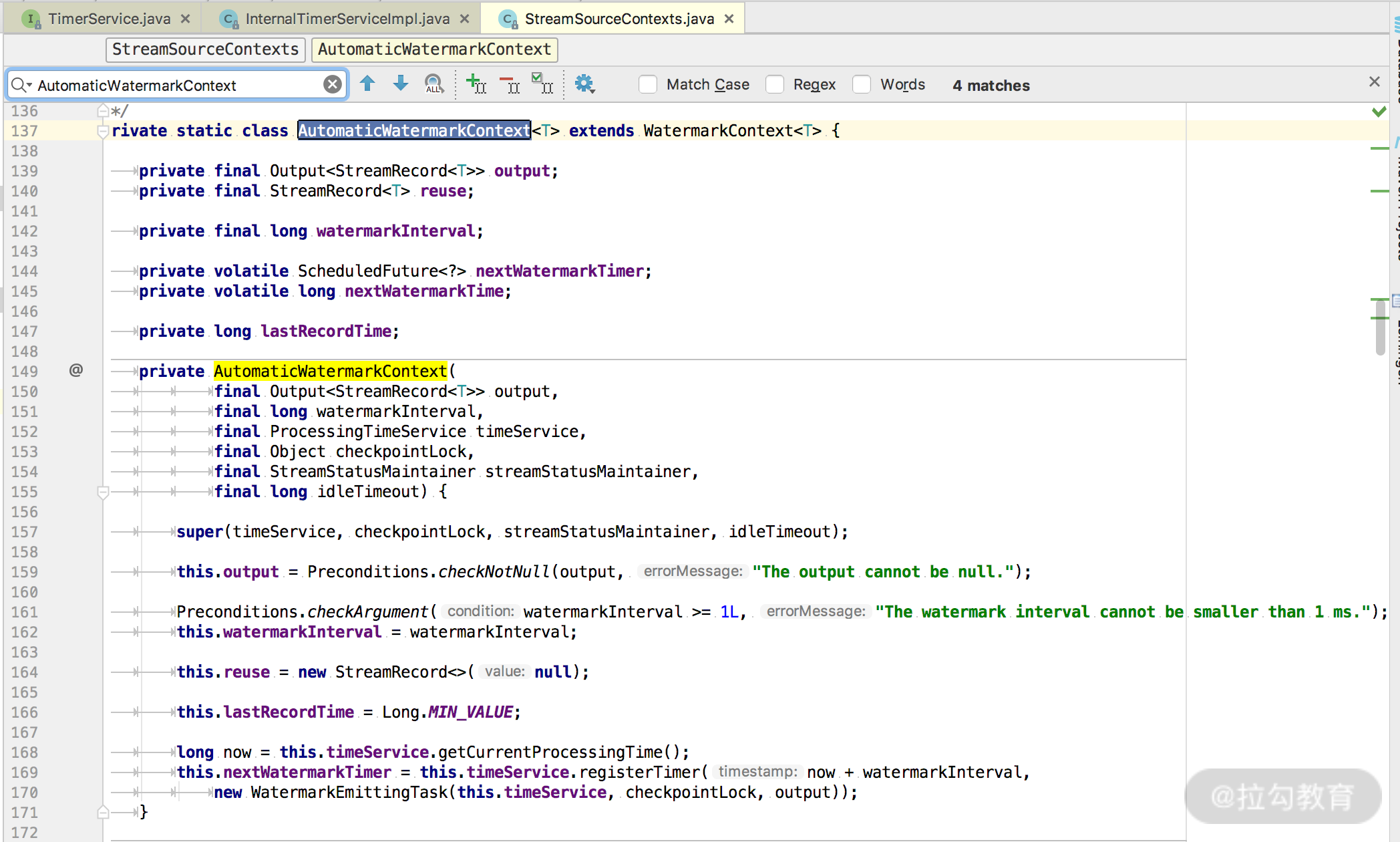
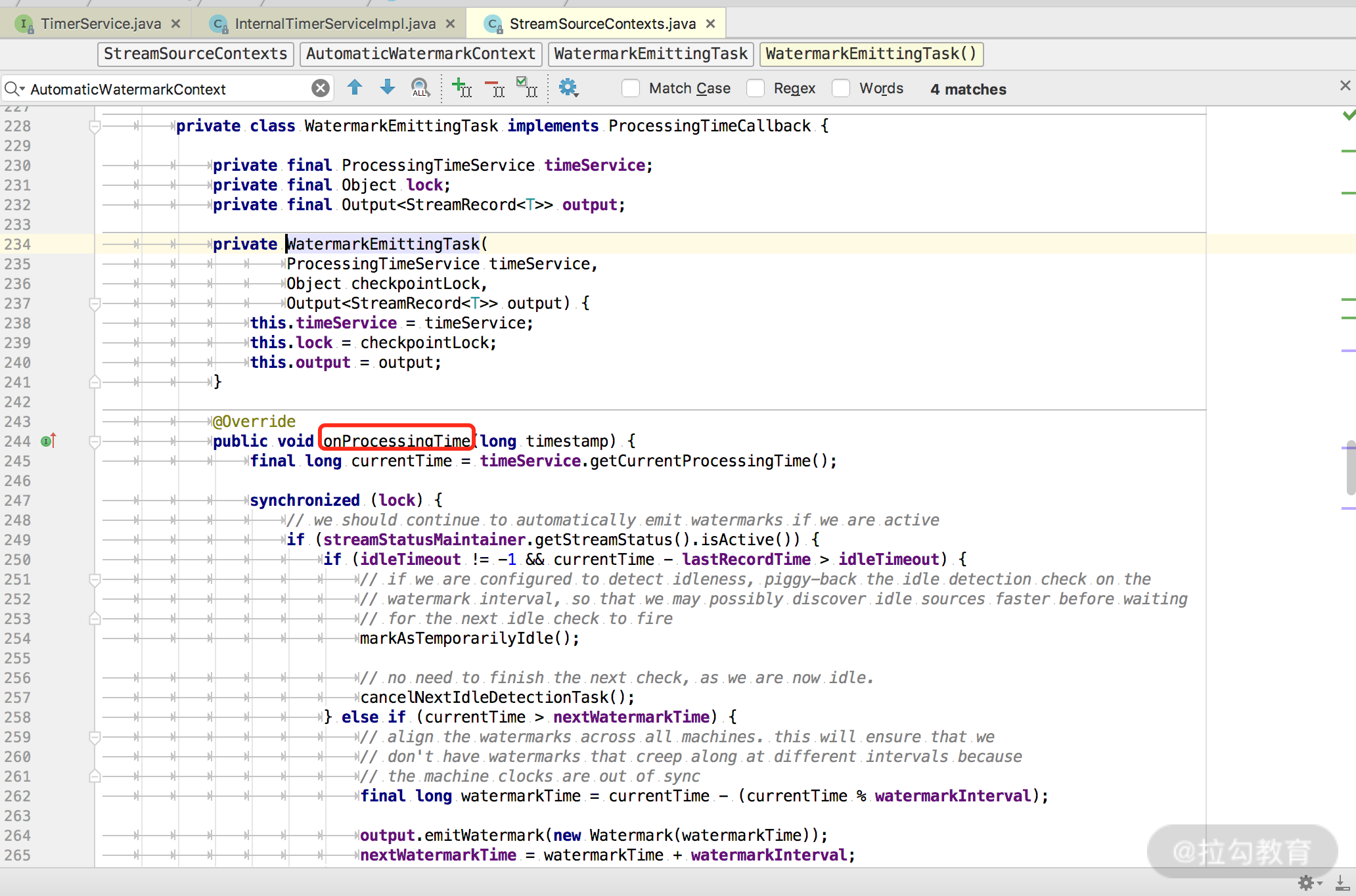
我们可以看出,这里会设置一个 watermark 发送定时器,在 watermarkInterval 时间之后触发。
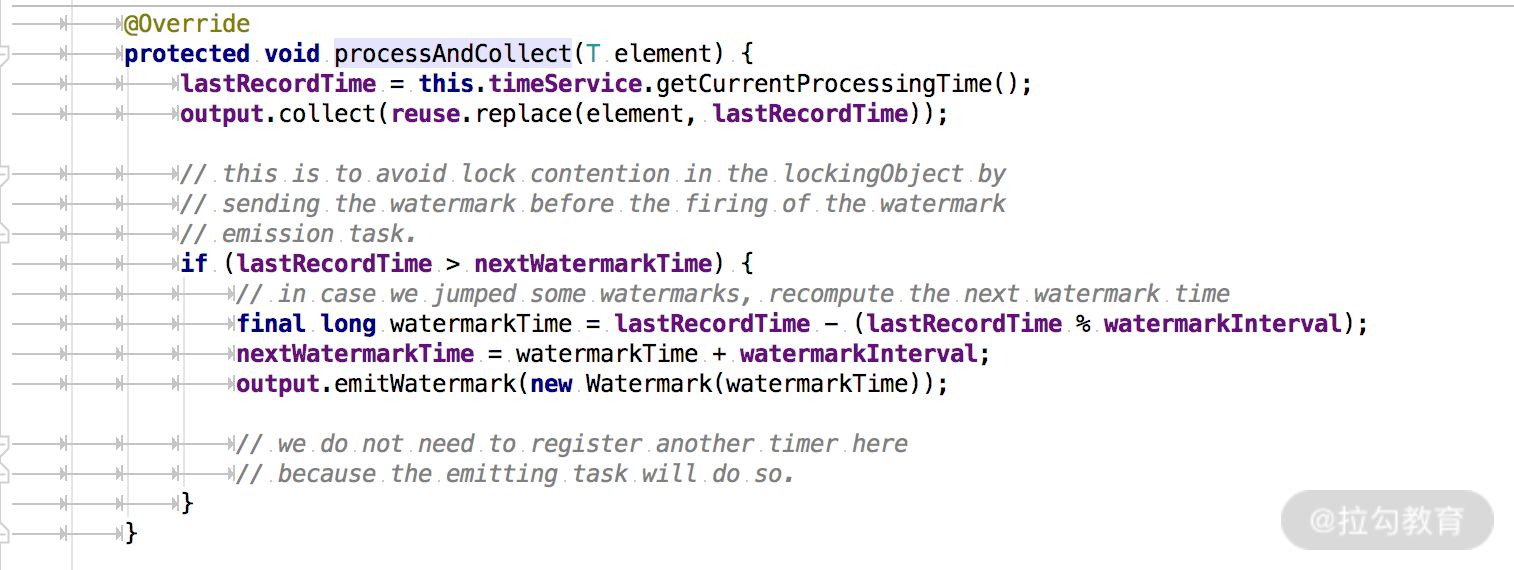
处理数据的代码在 processAndCollect() 方法中:
水印(WaterMark)
水印(WaterMark)是 Flink 框架中最晦涩难懂的概念之一,有很大一部分原因是因为翻译的原因。
WaterMark 在正常的英文翻译中是水位,但是在 Flink 框架中,翻译为“水位线”更为合理,它在本质上是一个时间戳。
在上面的时间类型中我们知道,Flink 中的时间:
EventTime 每条数据都携带时间戳;
-
ProcessingTime 数据不携带任何时间戳的信息;
-
IngestionTime 和 EventTime 类似,不同的是 Flink 会使用系统时间作为时间戳绑定到每条数据,可以防止 Flink 内部处理数据是发生乱序的情况,但无法解决数据到达 Flink 之前发生的乱序问题。
所以,我们在处理消息乱序的情况时,会用 EventTime 和 WaterMark 进行配合使用。
首先我们要明确几个基本问题。
水印的本质是什么
水印的出现是为了解决实时计算中的数据乱序问题,它的本质是 DataStream 中一个带有时间戳的元素。如果 Flink 系统中出现了一个 WaterMark T,那么就意味着 EventTime < T 的数据都已经到达,窗口的结束时间和 T 相同的那个窗口被触发进行计算了。
也就是说:水印是 Flink 判断迟到数据的标准,同时也是窗口触发的标记。
在程序并行度大于 1 的情况下,会有多个流产生水印和窗口,这时候 Flink 会选取时间戳最小的水印。
水印是如何生成的
Flink 提供了 assignTimestampsAndWatermarks() 方法来实现水印的提取和指定,该方法接受的入参有 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks 两种。
整体的类图如下:
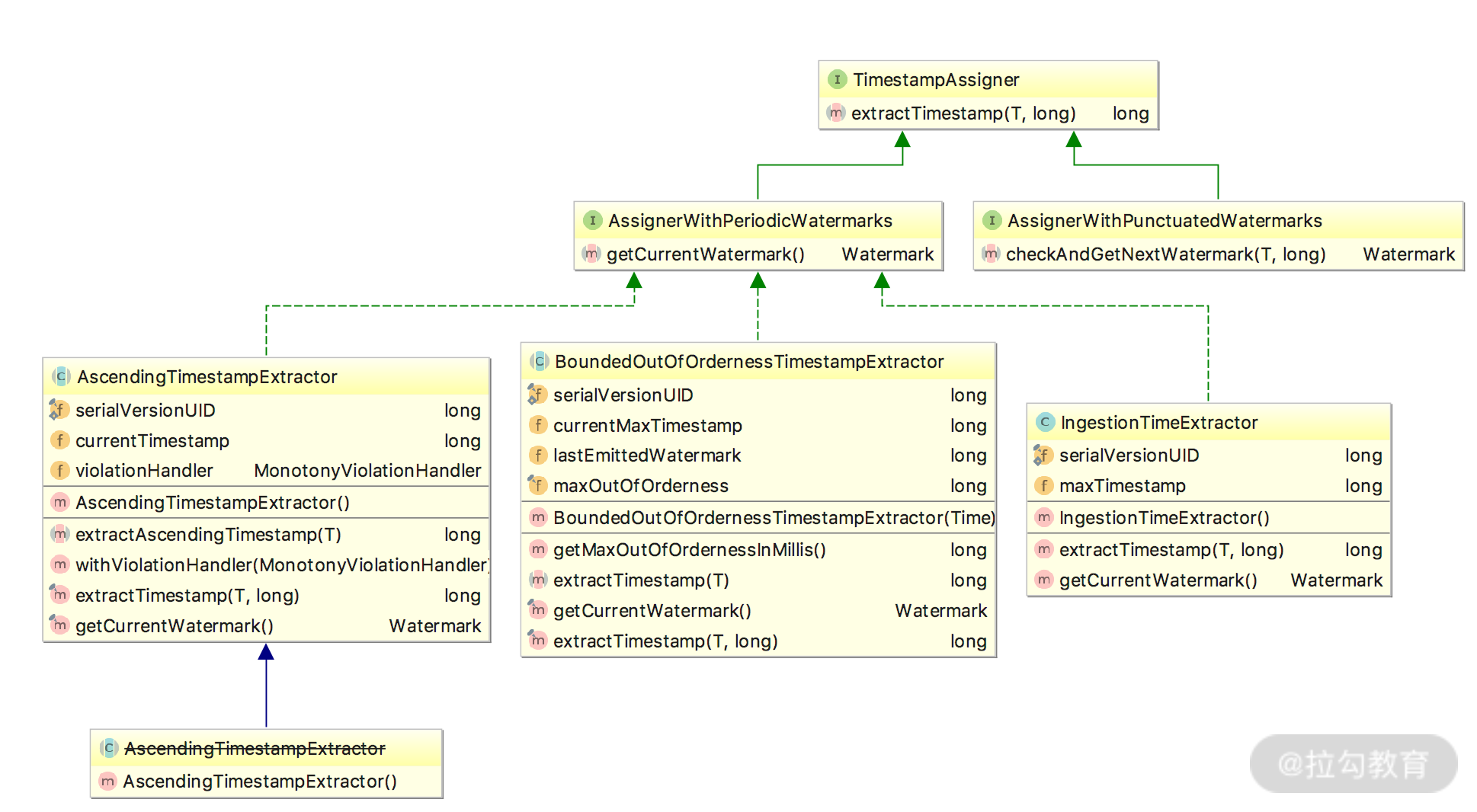
水印种类
周期性水印
我们在使用 AssignerWithPeriodicWatermarks 周期生成水印时,周期默认的时间是 200ms,这个时间的指定位置为:
@PublicEvolving
public void setStreamTimeCharacteristic(TimeCharacteristic characteristic) {
this.timeCharacteristic = Preconditions.checkNotNull(characteristic);
if (characteristic == TimeCharacteristic.ProcessingTime) {
getConfig().setAutoWatermarkInterval(0);
} else {
getConfig().setAutoWatermarkInterval(200);
}
}
是否还记得上面我们在讲时间类型时会通过 env.setStreamTimeCharacteristic() 方法指定 Flink 系统的时间类型,这个 setStreamTimeCharacteristic() 方法中会做判断,如果用户传入的是 TimeCharacteristic.eventTime 类型,那么 AutoWatermarkInterval 的值则为 200ms ,如上述代码所示。当前我们也可以使用 ExecutionConfig.setAutoWatermarkInterval() 方法来指定自动生成的时间间隔。
在上述的类图中可以看出,我们需要通过 TimestampAssigner 的 extractTimestamp() 方法来提取 EventTime。
Flink 在这里提供了 3 种提取 EventTime() 的方法,分别是:
-
AscendingTimestampExtractor
-
BoundedOutOfOrdernessTimestampExtractor
-
IngestionTimeExtractor
这三种方法中 BoundedOutOfOrdernessTimestampExtractor() 用的最多,需特别注意,在这个方法中的 maxOutOfOrderness 参数,该参数指的是允许数据乱序的时间范围。简单说,这种方式允许数据迟到 maxOutOfOrderness 这么长的时间。
public BoundedOutOfOrdernessTimestampExtractor(Time maxOutOfOrderness) {
if (maxOutOfOrderness.toMilliseconds() < 0) {
throw new RuntimeException("Tried to set the maximum allowed " +
"lateness to " + maxOutOfOrderness + ". This parameter cannot be negative.");
}
this.maxOutOfOrderness = maxOutOfOrderness.toMilliseconds();
this.currentMaxTimestamp = Long.MIN_VALUE + this.maxOutOfOrderness;
}
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">abstract</span> <span class="hljs-keyword">long</span> <span class="hljs-title">extractTimestamp</span><span class="hljs-params">(T element)</span></span>;
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">final</span> Watermark <span class="hljs-title">getCurrentWatermark</span><span class="hljs-params">()</span> </span>{
<span class="hljs-keyword">long</span> potentialWM = currentMaxTimestamp - maxOutOfOrderness;
<span class="hljs-keyword">if</span> (potentialWM >= lastEmittedWatermark) {
lastEmittedWatermark = potentialWM;
}
<span class="hljs-keyword">return</span> <span class="hljs-keyword">new</span> Watermark(lastEmittedWatermark);
}
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">final</span> <span class="hljs-keyword">long</span> <span class="hljs-title">extractTimestamp</span><span class="hljs-params">(T element, <span class="hljs-keyword">long</span> previousElementTimestamp)</span> </span>{
<span class="hljs-keyword">long</span> timestamp = extractTimestamp(element);
<span class="hljs-keyword">if</span> (timestamp > currentMaxTimestamp) {
currentMaxTimestamp = timestamp;
}
<span class="hljs-keyword">return</span> timestamp;
}
PunctuatedWatermark 水印
这种水印的生成方式 Flink 没有提供内置实现,它适用于根据接收到的消息判断是否需要产生水印的情况,用这种水印生成的方式并不多见。
举个简单的例子,假如我们发现接收到的数据 MyData 中以字符串 watermark 开头则产生一个水印:
data.assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks<UserActionRecord>() {
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Watermark <span class="hljs-title">checkAndGetNextWatermark</span><span class="hljs-params">(MyData data, <span class="hljs-keyword">long</span> l)</span> </span>{
<span class="hljs-keyword">return</span> data.getRecord.startsWith(<span class="hljs-string">"watermark"</span>) ? <span class="hljs-keyword">new</span> Watermark(l) : <span class="hljs-keyword">null</span>;
}
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">long</span> <span class="hljs-title">extractTimestamp</span><span class="hljs-params">(MyData data, <span class="hljs-keyword">long</span> l)</span> </span>{
<span class="hljs-keyword">return</span> data.getTimestamp();
}
});
class MyData{
private String record;
private Long timestamp;
public String getRecord() {
return record;
}
public void setRecord(String record) {
this.record = record;
}
public Timestamp getTimestamp() {
return timestamp;
}
public void setTimestamp(Timestamp timestamp) {
this.timestamp = timestamp;
}
}
案例
我们上面讲解了 Flink 关于水印和时间的生成,以及使用,下面举一个例子来讲解。
模拟一个实时接收 Socket 的 DataStream 程序,代码中使用 AssignerWithPeriodicWatermarks 来设置水印,将接收到的数据进行转换,分组并且在一个 5
秒的窗口内获取该窗口中第二个元素最小的那条数据。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
<span class="hljs-comment">//设置为eventtime事件类型</span>
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
<span class="hljs-comment">//设置水印生成时间间隔100ms</span>
env.getConfig().setAutoWatermarkInterval(<span class="hljs-number">100</span>);
DataStream<String> dataStream = env
.socketTextStream(<span class="hljs-string">"127.0.0.1"</span>, <span class="hljs-number">9000</span>)
.assignTimestampsAndWatermarks(<span class="hljs-keyword">new</span> AssignerWithPeriodicWatermarks<String>() {
<span class="hljs-keyword">private</span> Long currentTimeStamp = <span class="hljs-number">0L</span>;
<span class="hljs-comment">//设置允许乱序时间</span>
<span class="hljs-keyword">private</span> Long maxOutOfOrderness = <span class="hljs-number">5000L</span>;
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Watermark <span class="hljs-title">getCurrentWatermark</span><span class="hljs-params">()</span> </span>{
<span class="hljs-keyword">return</span> <span class="hljs-keyword">new</span> Watermark(currentTimeStamp - maxOutOfOrderness);
}
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">long</span> <span class="hljs-title">extractTimestamp</span><span class="hljs-params">(String s, <span class="hljs-keyword">long</span> l)</span> </span>{
String[] arr = s.split(<span class="hljs-string">","</span>);
<span class="hljs-keyword">long</span> timeStamp = Long.parseLong(arr[<span class="hljs-number">1</span>]);
currentTimeStamp = Math.max(timeStamp, currentTimeStamp);
System.err.println(s + <span class="hljs-string">",EventTime:"</span> + timeStamp + <span class="hljs-string">",watermark:"</span> + (currentTimeStamp - maxOutOfOrderness));
<span class="hljs-keyword">return</span> timeStamp;
}
});
dataStream.map(<span class="hljs-keyword">new</span> MapFunction<String, Tuple2<String, Long>>() {
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Tuple2<String, Long> <span class="hljs-title">map</span><span class="hljs-params">(String s)</span> <span class="hljs-keyword">throws</span> Exception </span>{
String[] split = s.split(<span class="hljs-string">","</span>);
<span class="hljs-keyword">return</span> <span class="hljs-keyword">new</span> Tuple2<String, Long>(split[<span class="hljs-number">0</span>], Long.parseLong(split[<span class="hljs-number">1</span>]));
}
})
.keyBy(<span class="hljs-number">0</span>)
.window(TumblingEventTimeWindows.of(Time.seconds(<span class="hljs-number">5</span>)))
.minBy(<span class="hljs-number">1</span>)
.print();
env.execute(<span class="hljs-string">"WaterMark Test Demo"</span>);
}
我们第一次试验的数据如下:
flink,1588659181000
flink,1588659182000
flink,1588659183000
flink,1588659184000
flink,1588659185000
可以做一个简单的判断,第一条数据的时间戳为 1588659181000,窗口的大小为 5 秒,那么应该会在 flink,1588659185000 这条数据出现时触发窗口的计算。
我们用 nc -lk 9000 命令启动端口,然后输出上述试验数据,看到控制台的输出:
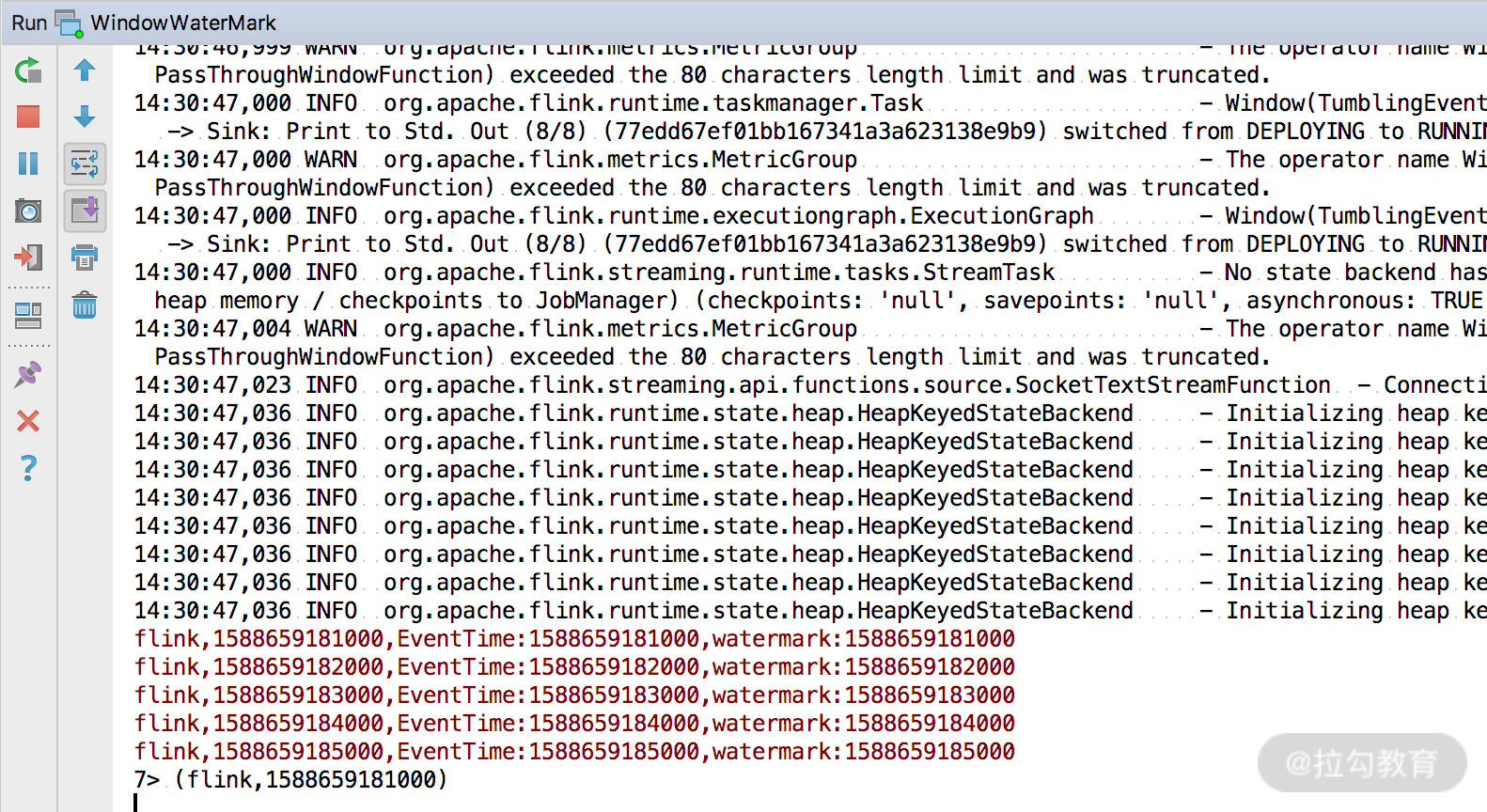
很明显,可以看到当第五条数据出现后,窗口触发了计算。
下面再模拟一下数据乱序的情况,假设我们的数据来源如下:
flink,1588659181000
flink,1588659182000
flink,1588659183000
flink,1588659184000
flink,1588659185000
flink,1588659180000
flink,1588659186000
flink,1588659187000
flink,1588659188000
flink,1588659189000
flink,1588659190000
其中的 flink,1588659180000 为乱序消息,来看看会发生什么?
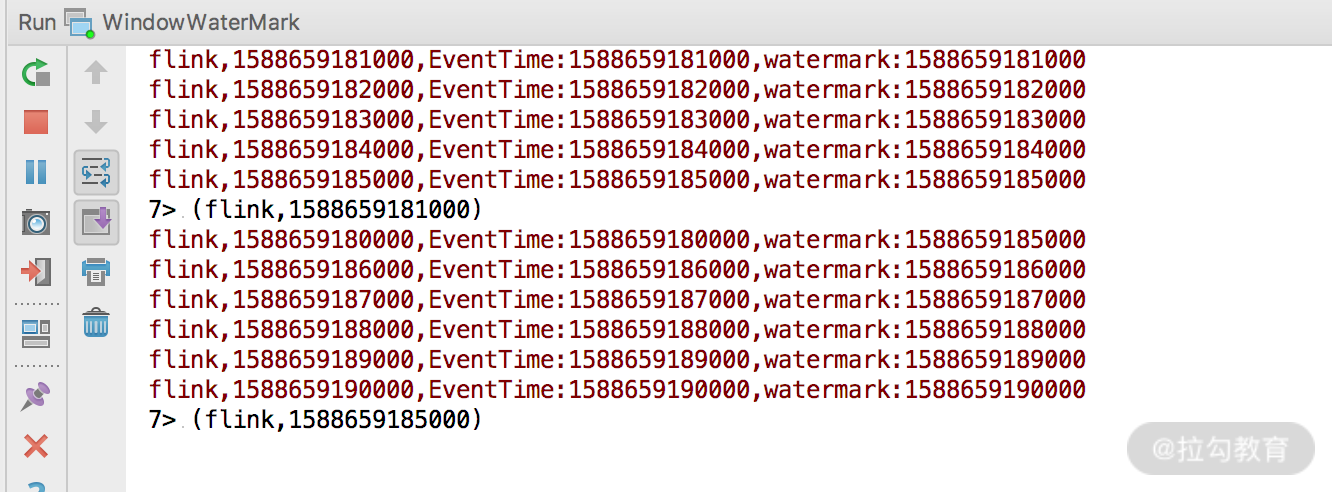
可以看到,时间戳为 1588659180000 的这条消息并没有被处理,因为此时代码中的允许乱序时间 private Long maxOutOfOrderness = 0L 即不处理乱序消息。
下面修改 private Long maxOutOfOrderness = 5000L,即代表允许消息的乱序时间为 5 秒,然后把同样的数据发往 socket 端口。
可以看到,我们把所有数据发送出去仅触发了一次窗口计算,并且输出的结果中 watermark 的时间往后顺延了 5 秒钟。所以,maxOutOfOrderness 的设置会影响窗口的计算时间和水印的时间,如下图所示:

假如我们继续向 socket 中发送数据:
flink,1588659191000
flink,1588659192000
flink,1588659193000
flink,1588659194000
flink,1588659195000
可以看到下一次窗口的触发时间:

在这里要特别说明,Flink 在用时间 + 窗口 + 水印来解决实际生产中的数据乱序问题,有如下的触发条件:
-
watermark 时间 >= window_end_time;
-
在 [window_start_time,window_end_time) 中有数据存在,这个窗口是左闭右开的。
此外,因为 WaterMark 的生成是以对象的形式发送到下游,同样会消耗内存,因此水印的生成时间和频率都要进行严格控制,否则会影响我们的正常作业。
总结
这一课时我们学习了 Flink 的时间类型和水印生成,内容偏多并且水印部分理解起来需要时间,建议你结合源码再进一步学习。
精选评论
*磊:
不得不说,今天开始有点看不懂了。。
编辑回复:
加油~
**7540:
您好,最后一个图片筛选出来的数据,那个时间不知道是怎么算的?麻烦老师解答一下
讲师回复:
核心问题是:maxOutOfOrderness 的设置会影响窗口的计算时间和水印的时间。你要理解这句话,你可以认为加入正常的水印是100,那么当时设置允许乱序这个水印就会顺延。最后一个图中,有一条乱序消息,他的存在导致水印往后延迟了5秒钟。
*放:
看来好久才明白:我们的时间窗口的开始时间是第一条数据,窗口时间是5秒后,那么我什么时候开始做kyeBy和minBy的计算呢就是等到整个窗口都完了,也就是 flink,1588659185000 这条数据出现,中间的时间的数据出现多少条我也不管.当它出现时一个时间窗口才完整.第二就是如果事件时间比水印时间小,那么这条数据我不会处理 而加上乱序时间5秒,意味着我的窗口计算是5秒,还要考虑5秒延迟的数据.而水印时间就帮我们考虑了这个延迟, 如果水印时间达到1588659185000,意味着比这个时间低的数据都已到达.那么我们就可以开始计算上一个窗口的数据了,因为不会有比这个时间更低的数据允许进来参与窗口的计算.(水印时间自己减去乱序时间)总结:直到水印的的时间 =数据开始时间 + 窗口时间,才开始计算这个窗口的transform操作.
**富:
老师您好,我想问下你第二个乱序的例子,计算的窗口分别是[158865917600,1588659180000],[1588659180000,158865918500),[158865918500,1588659190000] 吗? 因为设置了maxOutOfOrderness,对于eventTime=1588659181000的数据来说,延迟了5秒再触发这个窗口计算,然后第一个窗口因为没有在这个窗口区间范围的数据,就不计算了
讲师回复:
是的。首先你要理解,maxOutOfOrderness这个参数会导致窗口和计算时间整体后移,等到延迟时间才会触发窗口计算。
**冉:
如果新来一条分组为flink2的数据,触发了flink2的窗口,会影响flink组窗口的触发吗?
讲师回复:
如果你是分组+窗口聚合,那么数据会先被分组,然后在进行窗口触发的检查。是不会互相影响的
**川:
老师您好,我发现一个问题:假设记录 B:{flink,1588659195000} 先到达,记录 A:{flink,1588659194000} 后到达,窗口的长度是3秒 [1588659193000~1588659196000);我实验发现后到的 A 将会被放到和 B 同一窗口内,但 A 会被放在 B 后面,处理顺序是先处理 B 后处理A。也就是说,水印机制无法保证窗口内数据的有序,,,请问这个问题有没有什么解决办法呢
讲师回复:
我还没有遇到过这个问题。但是可以试试在继承processfunction中覆写processElement方法,在这个方法中自己用PriorityQueue将消息根据时间戳排序,然后在onTimer方法里按顺序取出。
**飞:
双流join中,设定滑动窗口,在一个slide中关联到的数据,在下一个slide中如果还满足条件,还会输出吗?
讲师回复:
会的,只要匹配到就会输出。所以双流join时都会在sink侧做幂等。
**用户3113:
老师您好,我这有两个问题:我没太理解为什么第二个乱序的例子结果是1588659185000,按照不处理乱序的模式,1588659180000舍弃,那后面的最小时间不应该是1588659186000么还有为何1588659180000对应的水印时间是1588659185000
讲师回复:
第一个问题,不处理乱序的模式,1588659180000舍弃,但是此时最小的值是85000,因为这个窗口是左闭右开的。第二个问题,因为我们设置的乱序事件是5秒,那么每条数据对应的水印都会等待5秒,也就是原来的事件加5秒。
**威:
flink,1588659181000,EventTime:1588659181000,watermark is:1588659176000flink,1588659182000,EventTime:1588659182000,watermark is:1588659177000flink,1588659183000,EventTime:1588659183000,watermark is:1588659178000flink,1588659184000,EventTime:1588659184000,watermark is:1588659179000flink,1588659185000,EventTime:1588659185000,watermark is:1588659180000flink,1588659190000,EventTime:1588659190000,watermark is:15886591850005 (flink,1588659181000)我跑了,应该是这样的,和老师的例子不一样,它的watermark应该是当前时间戳减5000,延时嘛,所以第六条数据,时间戳触发了窗口计算,这才有结果
讲师回复:
没错,关键就是乱序事件的设置。乱序时间会导致水印的产生延迟。
**耀:
数据如果先经过map处理 然后再assignTimestampsAndWatermarks 这些打印不出来东西 调换一下顺序 就可以了 这是为什么呢
讲师回复:
不会的,map后在assignTimestampsAndWatermarks是正常操作,你可以参考一下官网的例子。或者网上搜索一些例子,我感觉可能跟你的代码有关。
*奇:
老师,窗口内数据去重咋实现?比方说我想实现每五分钟统计最近十分钟的活跃人数,数据是用户信息和事件信息
讲师回复:
在第20讲会专门讲如何去重
**用户3693:
老师,您好,
我才刚开始研究Flink。用Flink处理过去的数据时,我用的事件时间,从数据中提取出来的时间字段。可是使用window进行聚合时,确出不来数据,所以我还没搞明白,窗口的开始时间是以收到的第一条数据的时间(包括事件时间或者系统时间)开始的还是从运行程序的那一刻(task被调度时)的时间?
讲师回复:
窗口的开始时间参考Flink中的这个类:getWindowStartWithOffset
**昊:
执行代码后控制台没有看到窗口触发了计算log,只能看到接收到的数据log。需要改什么吗?我拿老师github 上的代码呢
讲师回复:
在git pull一下代码
**3897:
flink,1588659181000flink,1588659182000flink,1588659183000flink,1588659184000flink,1588659185000我在本地用文章中的代码测试,为啥没有触发窗口计算呢?是不是还有其他要修改的?
讲师回复:
重新拉取一下代码,启动试试看。
**晨:
打卡 2020年5 月15日
123:
打卡
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/bi/flink/2043-%E7%AC%AC08%E8%AE%B2Flink-%E7%AA%97%E5%8F%A3%E6%97%B6%E9%97%B4%E5%92%8C%E6%B0%B4%E5%8D%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


