1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
|
/**
* @Author: Henry
* @Description: 数据报表
*
**/
public class DataReport {
private static Logger logger = LoggerFactory.getLogger(DataReport.class);
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度
env.setParallelism(5);
// 设置使用eventtime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// checkpoint配置
...
// 配置 kafkaSource
String topic = "auditLog"; // 审核日志
Properties prop = new Properties();
prop.setProperty("bootstrap.servers", "master:9092");
prop.setProperty("group.id", "con1");
FlinkKafkaConsumer011<String> myConsumer = new FlinkKafkaConsumer011<String>(
topic, new SimpleStringSchema(),prop);
/*
* 获取到kafka的数据
* {"dt":"审核时间{年月日 时分秒}", "type":"审核类型","username":"审核人姓名","area":"大区"}
* */
DataStreamSource<String> data = env.addSource(myConsumer);
// 对数据进行清洗
DataStream<Tuple3<Long, String, String>> mapData = data.map(
new MapFunction<String, Tuple3<Long, String, String>>() {
@Override
public Tuple3<Long, String, String> map(String line) throws Exception {
JSONObject jsonObject = JSON.parseObject(line);
String dt = jsonObject.getString("dt");
long time = 0;
try {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date parse = sdf.parse(dt);
time = parse.getTime();
} catch (ParseException e) {
//也可以把这个日志存储到其他介质中
logger.error("时间解析异常,dt:" + dt, e.getCause());
}
String type = jsonObject.getString("type");
String area = jsonObject.getString("area");
return new Tuple3<>(time, type, area);
}
});
// 过滤掉异常数据
DataStream<Tuple3<Long, String, String>> filterData = mapData.filter(
new FilterFunction<Tuple3<Long, String, String>>() {
@Override
public boolean filter(Tuple3<Long, String, String> value) throws Exception {
boolean flag = true;
if (value.f0 == 0) { // 即 time 字段为0
flag = false;
}
return flag;
}
});
// 保存迟到太久的数据
OutputTag<Tuple3<Long, String, String>> outputTag = new OutputTag<Tuple3<Long, String, String>>("late-data"){};
/*
* 窗口统计操作
* */
SingleOutputStreamOperator<Tuple4<String, String, String, Long>> resultData = filterData.assignTimestampsAndWatermarks(
new MyWatermark())
.keyBy(1, 2) // 根据第1、2个字段,即type、area分组,第0个字段是timestamp
.window(TumblingEventTimeWindows.of(Time.minutes(30))) // 每隔一分钟统计前一分钟的数据
.allowedLateness(Time.seconds(30)) // 允许迟到30s
.sideOutputLateData(outputTag) // 记录迟到太久的数据
.apply(new MyAggFunction());
// 获取迟到太久的数据
DataStream<Tuple3<Long, String, String>> sideOutput = resultData.getSideOutput(outputTag);
// 存储迟到太久的数据到kafka中
String outTopic = "lateLog";
Properties outprop = new Properties();
outprop.setProperty("bootstrap.servers", "master:9092");
// 设置事务超时时间
outprop.setProperty("transaction.timeout.ms", 60000*15+"");
FlinkKafkaProducer011<String> myProducer = new FlinkKafkaProducer011<String>(
outTopic,
new KeyedSerializationSchemaWrapper<String>(
new SimpleStringSchema()),
outprop,
FlinkKafkaProducer011.Semantic.EXACTLY_ONCE);
// 迟到太久的数据存储到 kafka 中
sideOutput.map(new MapFunction<Tuple3<Long, String, String>, String>() {
@Override
public String map(Tuple3<Long, String, String> value) throws Exception {
return value.f0+"\t"+value.f1+"\t"+value.f2;
}
}).addSink(myProducer);
/*
* 把计算的结存储到 ES 中
* */
List<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("master", 9200, "http"));
ElasticsearchSink.Builder<Tuple4<String, String, String, Long>> esSinkBuilder = new ElasticsearchSink.Builder<
Tuple4<String, String, String, Long>>(
httpHosts,
new ElasticsearchSinkFunction<Tuple4<String, String, String, Long>>() {
public IndexRequest createIndexRequest(Tuple4<String, String, String, Long> element) {
Map<String, Object> json = new HashMap<>();
json.put("time",element.f0);
json.put("type",element.f1);
json.put("area",element.f2);
json.put("count",element.f3);
//使用time+type+area 保证id唯一
String id = element.f0.replace(" ","_")+"-"+element.f1+"-"+element.f2;
return Requests.indexRequest()
.index("auditindex")
.type("audittype")
.id(id)
.source(json);
}
@Override
public void process(Tuple4<String, String, String, Long> element,
RuntimeContext ctx, RequestIndexer indexer) {
indexer.add(createIndexRequest(element));
}
}
);
// ES是有缓冲区的,这里设置1代表,每增加一条数据直接就刷新到ES
esSinkBuilder.setBulkFlushMaxActions(1);
resultData.addSink(esSinkBuilder.build());
env.execute("DataReport");
}
}
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154
|
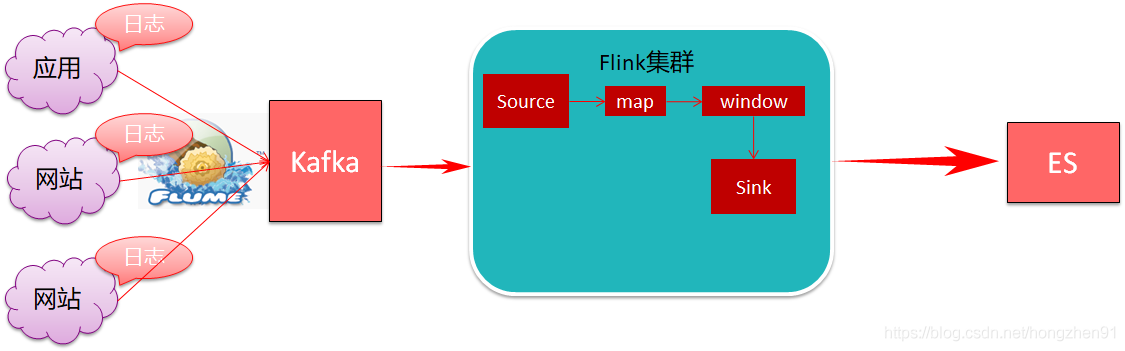


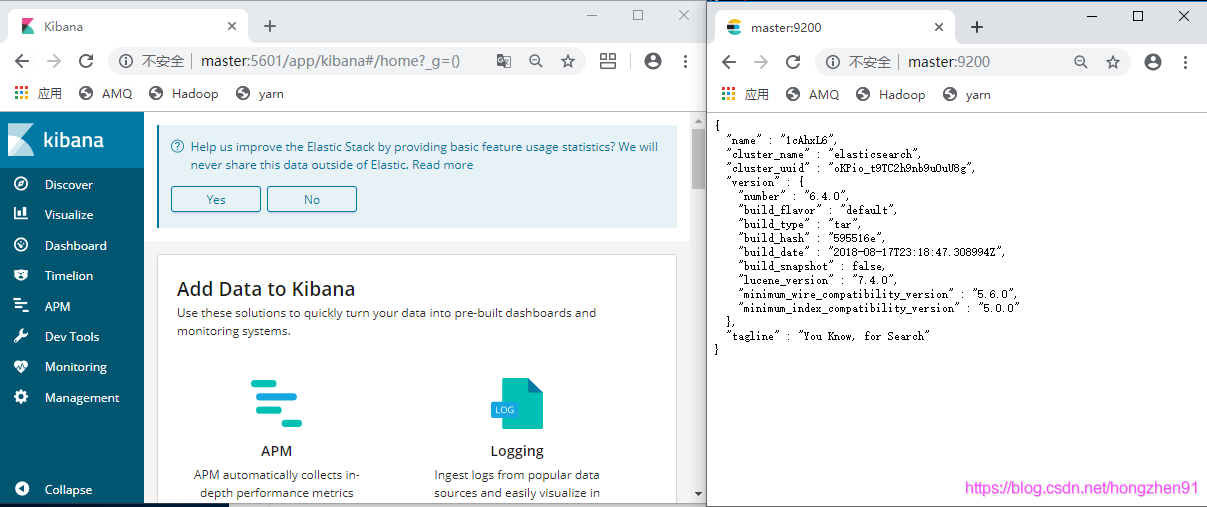
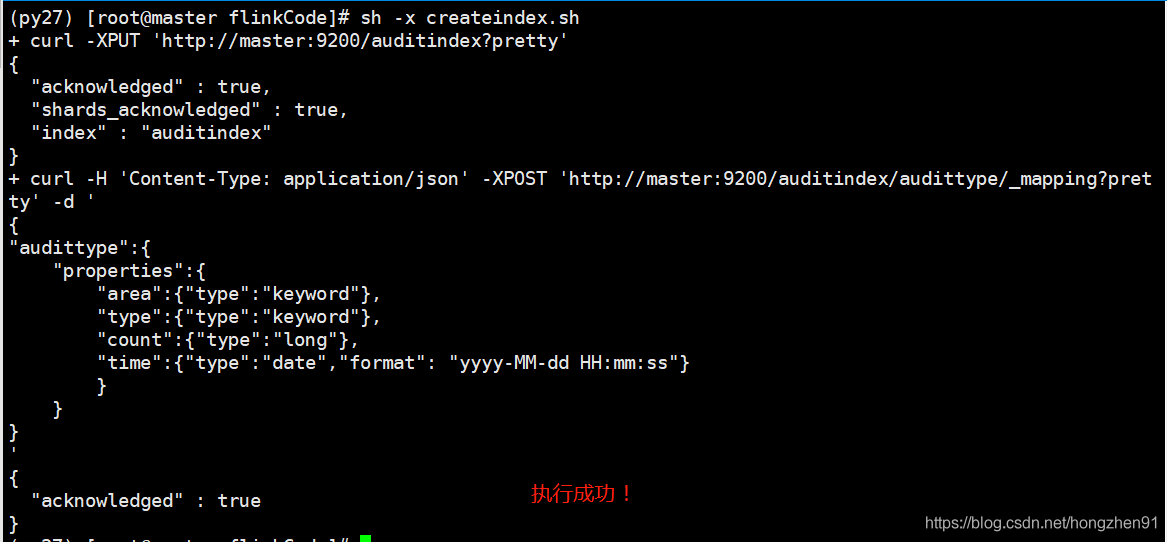
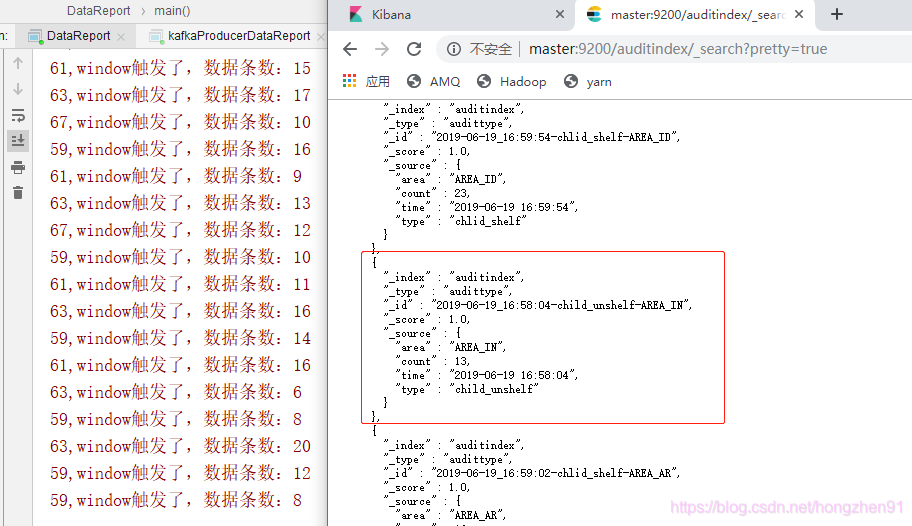
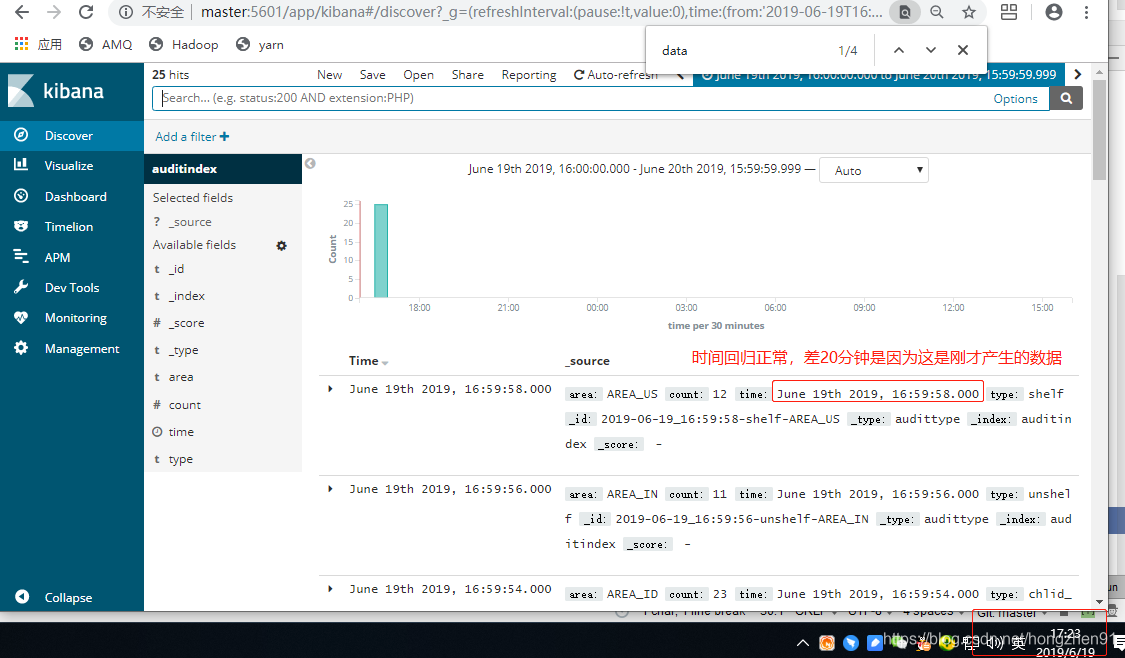
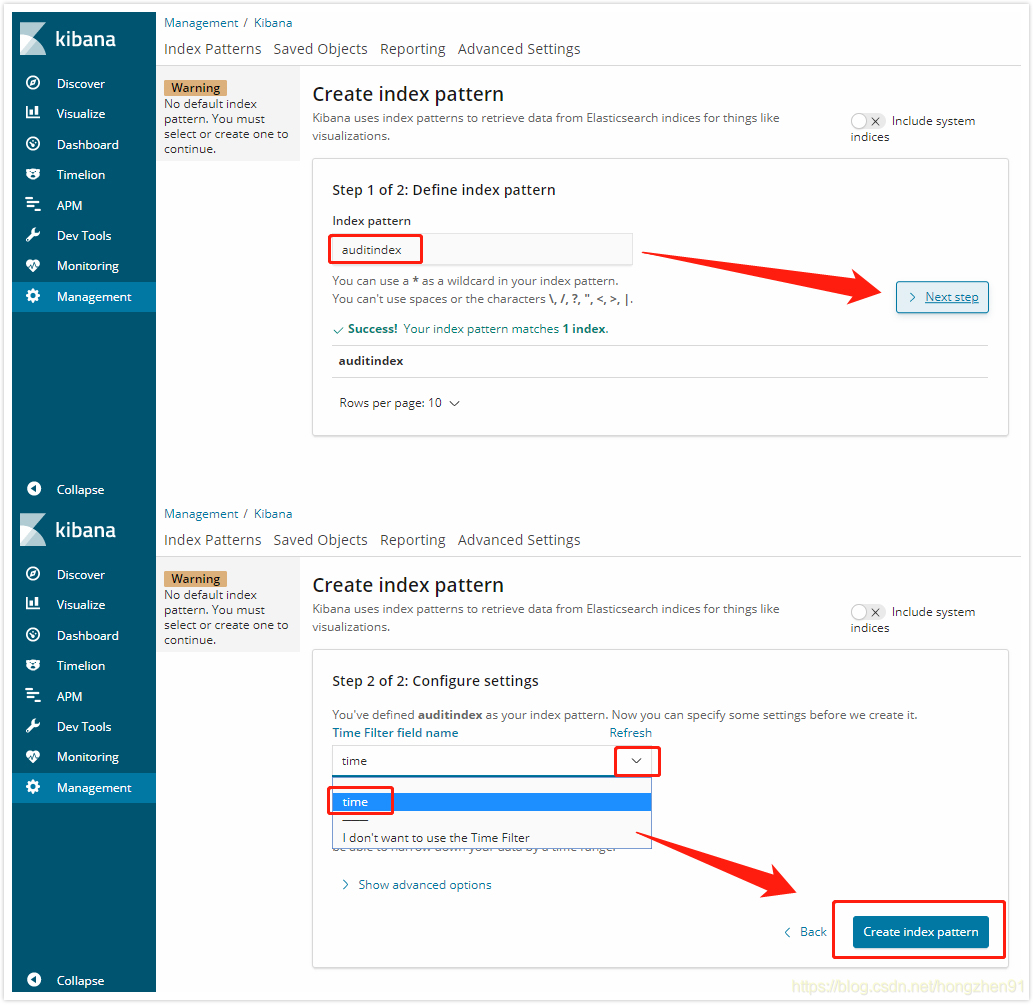 2. Discover 查看数据:
2. Discover 查看数据:
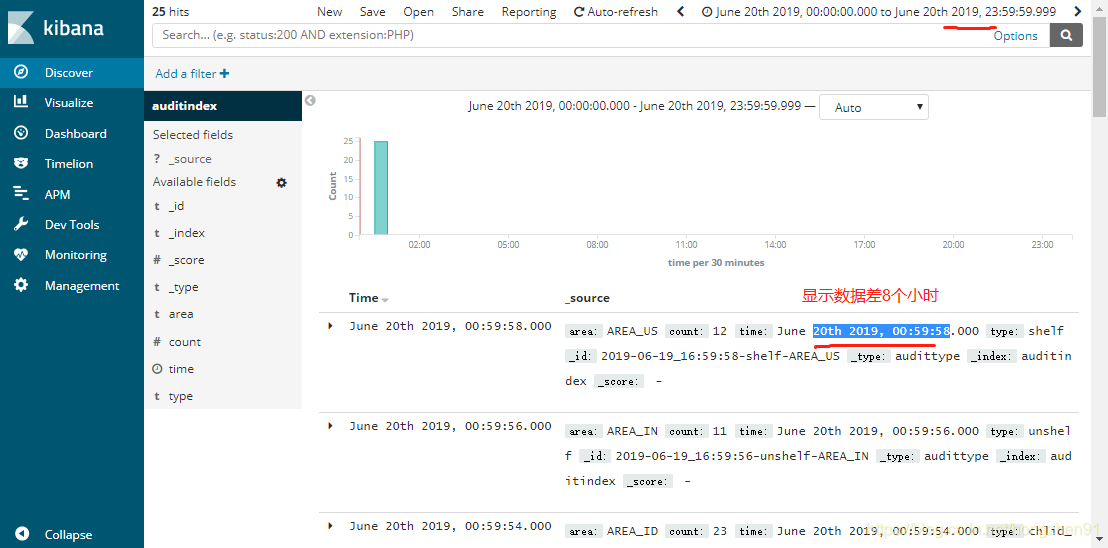
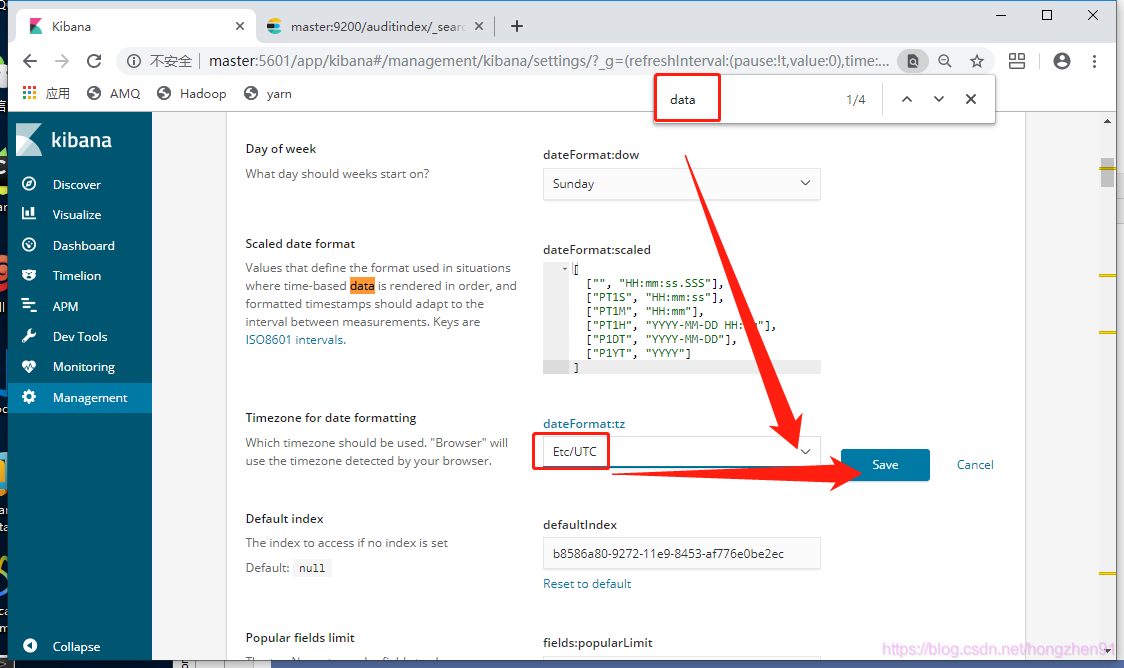 重新刷新并查看数据:
重新刷新并查看数据:
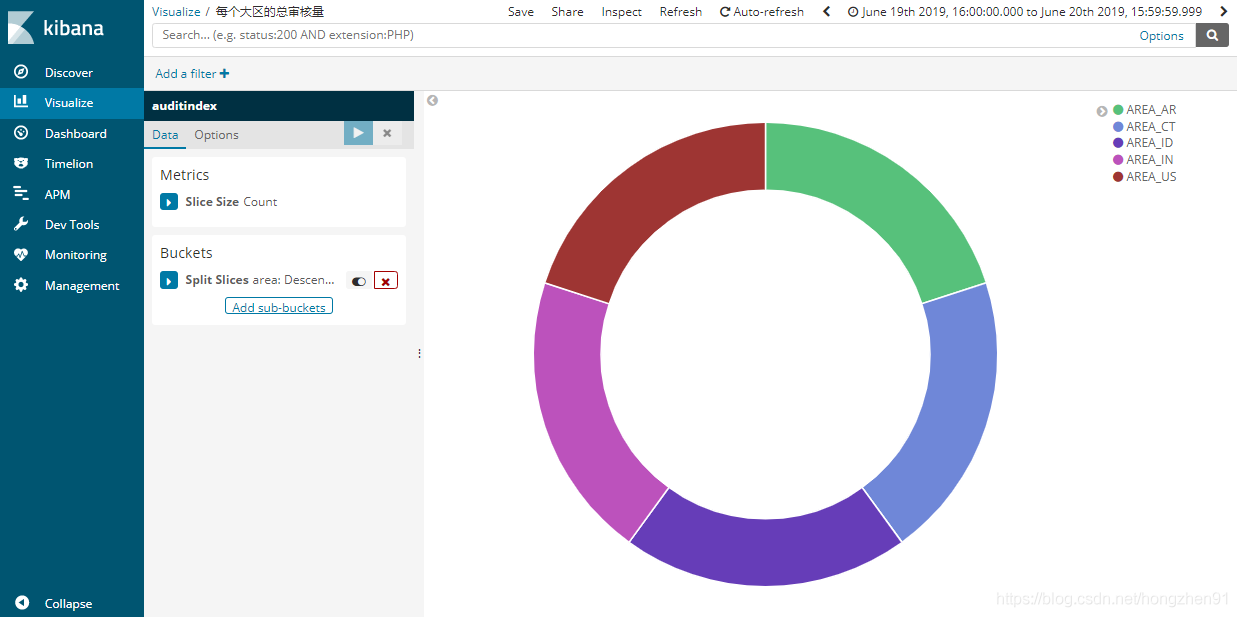
 3. 新建饼图对数据可视化操作:
3. 新建饼图对数据可视化操作:
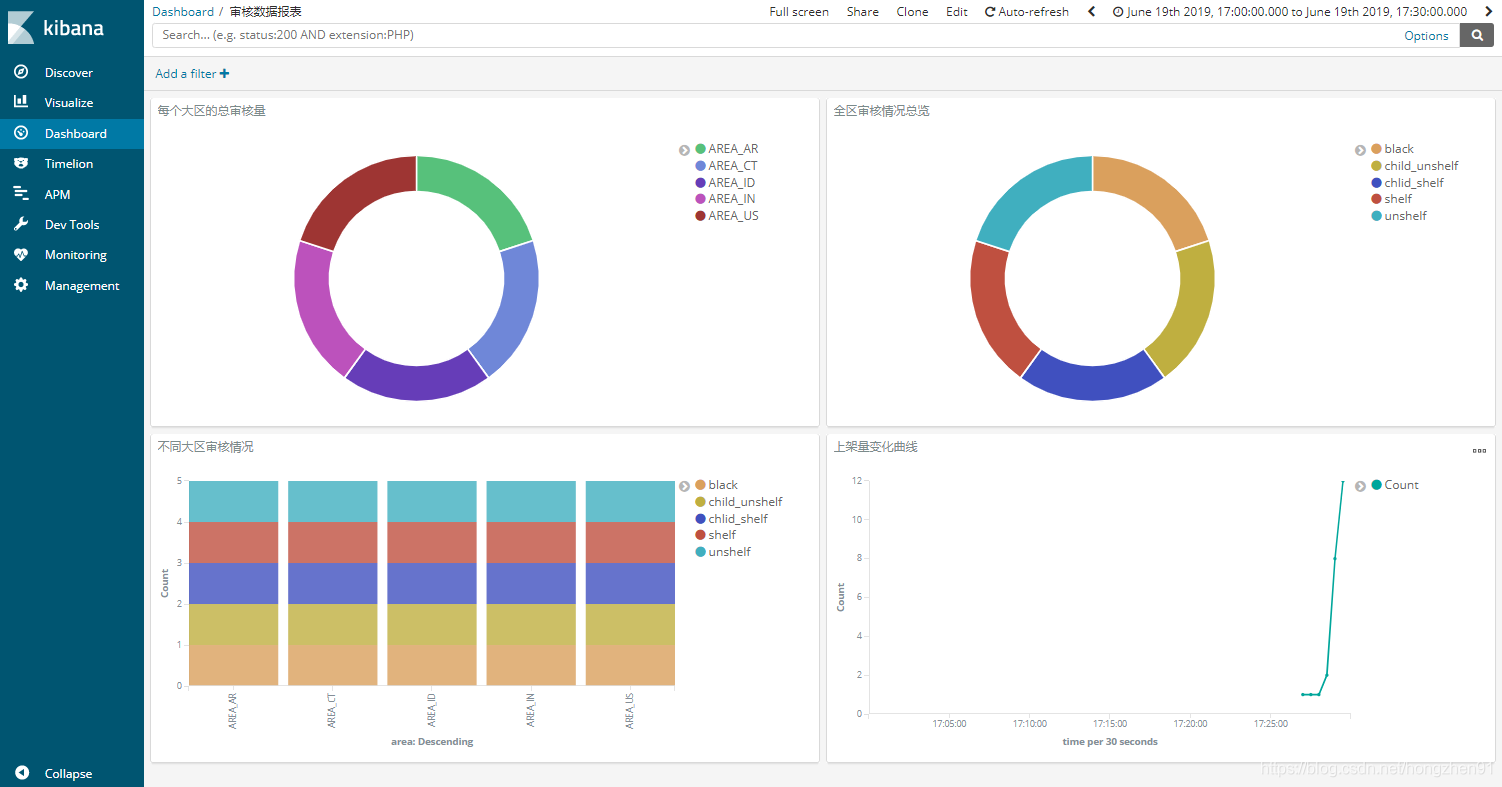
 4. 新建 Dashboard 添加可视化图:
4. 新建 Dashboard 添加可视化图: