基于Flink-CDC数据同步⽅案

前言
在业务数据处理过程中,我们时常会遇到不同业务模块 / 存储系统间实时数据同步需求。比如, 报表模块依赖订单模块数据进行增量更新,检索引擎依赖业务数据进行实时同步等。针对这类场景,我们目前采用了Flink-CDC的技术方案用于数据同步。
Flink-CDC(CDC,全称是 Change Data Capture),是基于Apache Flink® 生态的数据源连接器,该连接器集成了Debezium引擎。其目标是为了用于监控和捕获数据变更,以便下游服务针对变更进行相应处理。基于CDC场景,比较成熟的解决方案还包括 Maxwell、Canal等 。

方案对比
Flink - CDC(Debezium)/ Maxwell / Canal
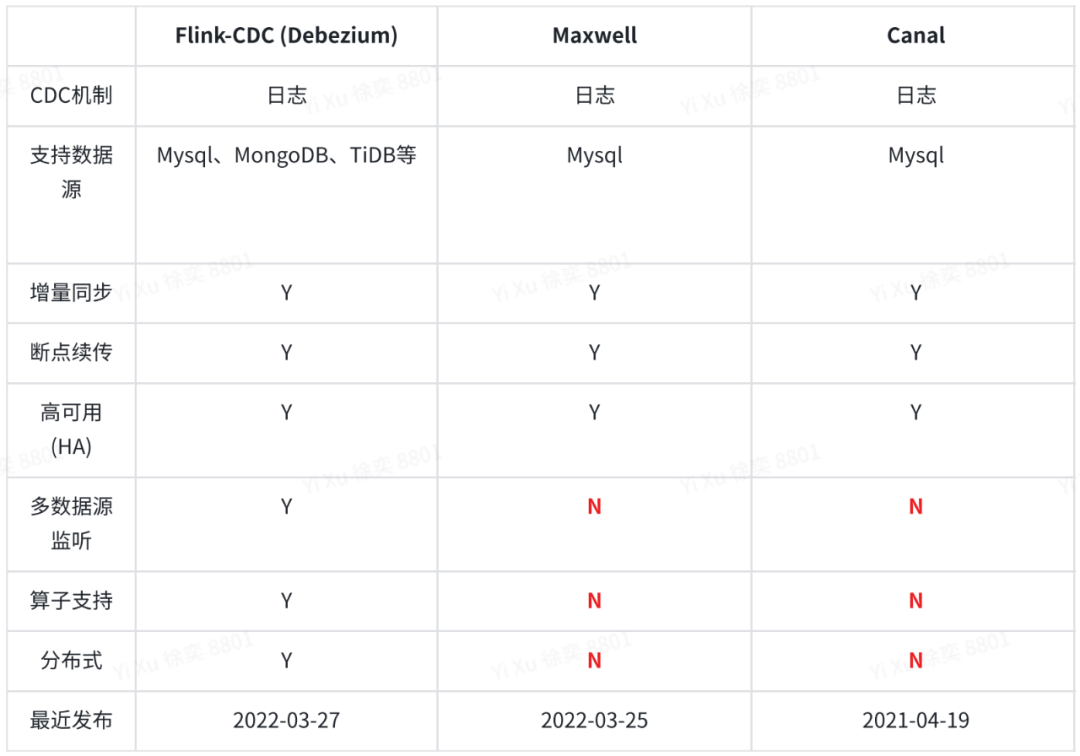
以上是我们进行的解决方案对比,可以看到相较于Maxwell、Canal,Flink-CDC在数据源支持上更为丰富,同时基于Apache Flink®生态,在数据同步任务的处理过程中,还提供了诸如Map、Filter、Union的丰富算子支持。
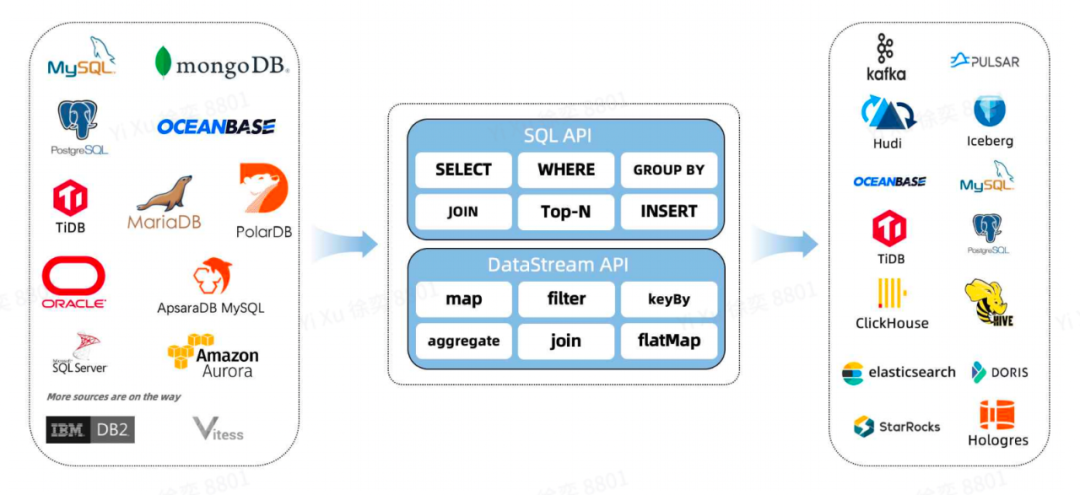
Flink-CDC ⽀持数据源、数据下游⽀持:

原理
以Mysql为例,Flink-CDC的底层原理实际上是基于读取数据库的Binlog日志,同时内置集成的Debezium引擎,会将Binlog日志解析为行级变更的数据结构。目前Flink-CDC支持 DataStream-API / SQL-API 两种实现进行CDC监控,以下我们主要以DataStream-API实现举例。
DataStream API实现:
|
|
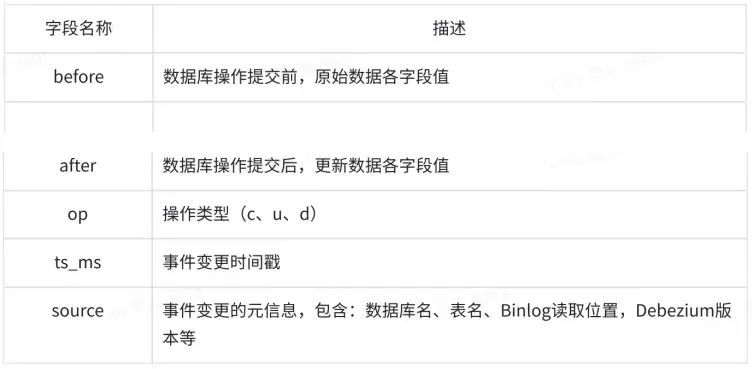
到这⾥Flink-CDC的基础配置已经完成,启动后如果order_infos.order_info_0数据变更,那么程序就 可以监听到对应的变更信息了。⽰例代码的下游配置为标准输出流,实际在线上业务场景,可通过dataStreamSource.addSink()的⽅式对接下游服务,⽐如Kafka / RabbitMq / Elasticsearch等。基本操作 Debezium 格式化后的数据结构,包含 before、after、source、op、ts_ms 5个字段,含义 如下:
INSERT⽰例:
{
# New Row Data
"after":{
"order_id":"mock_oid_01",
"shop_id":"mock_sid_01",
"order_status":"CANCELLED",
"payment_method":"Wallet V2",
"total_amount":"8881.000000",
"create_datetime":"2020-09-03T03:03:36Z",
"update_datetime":"2022-04-08T02:23:12Z",
"transaction_id":"a154111f857514b0"
},
# Metadata
"source":{
"version":"1.4.1.Final",
"connector":"mysql",
"name":"mysql_binlog_source",
"ts_ms":"1649384718000",
"db":"order_infos",
"table":"order_info_01",
"server_id":"225",
"gtid":"d2f4fc13-9df2-11ec-a9f6-0242ac1f0002",
"file":"mysql-bin.000025",
"pos":"45950793",
"row":"0",
"thread":"27273"
},
"op":"c",
"ts_ms":"1649384718067"
}
UPDATE⽰例:
{
# Old Row Data
"before":{
"order_id":"mock_oid_01",
"shop_id":"mock_sid_01",
"order_status":"SHIPPING",
"payment_method":"Wallet V2",
"total_amount":"8881.000000",
"create_datetime":"2020-09-03T03:03:36Z",
"update_datetime":"2022-04-08T02:23:12Z",
"transaction_id":"a154111f857514b0"
},
# New Row Data
"after":{
"order_id":"mock_oid_01",
"shop_id":"mock_sid_01",
"order_status":"CANCELLED",
"payment_method":"Wallet V2",
"total_amount":"8881.000000",
"create_datetime":"2020-09-03T03:03:36Z",
"update_datetime":"2022-04-08T02:23:12Z",
"transaction_id":"a154111f857514b0"
},
# Metadata
"source":{
"version":"1.4.1.Final",
"connector":"mysql",
"name":"mysql_binlog_source",
"ts_ms":"1649384718000",
"db":"order_infos",
"table":"order_info_01",
"server_id":"225",
"gtid":"d2f4fc13-9df2-11ec-a9f6-0242ac1f0002",
"file":"mysql-bin.000025",
"pos":"45950793",
"row":"0",
"thread":"27273"
},
"op":"u",
"ts_ms":"1649384718067"
}
DELETE⽰例:
{
# Old Row Data
"before":{
"order_id":"mock_oid_01",
"shop_id":"mock_sid_01",
"order_status":"SHIPPING",
"payment_method":"Wallet V2",
"total_amount":"8881.000000",
"create_datetime":"2020-09-03T03:03:36Z",
"update_datetime":"2022-04-08T02:23:12Z",
"transaction_id":"a154111f857514b0"
},
# Metadata
"source":{
"version":"1.4.1.Final",
"connector":"mysql",
"name":"mysql_binlog_source",
"ts_ms":"1649384718000",
"db":"order_infos",
"table":"order_info_01",
"server_id":"225",
"gtid":"d2f4fc13-9df2-11ec-a9f6-0242ac1f0002",
"file":"mysql-bin.000025",
"pos":"45950793",
"row":"0",
"thread":"27273"
},
"op":"d",
"ts_ms":"1649384718067"
}

实践
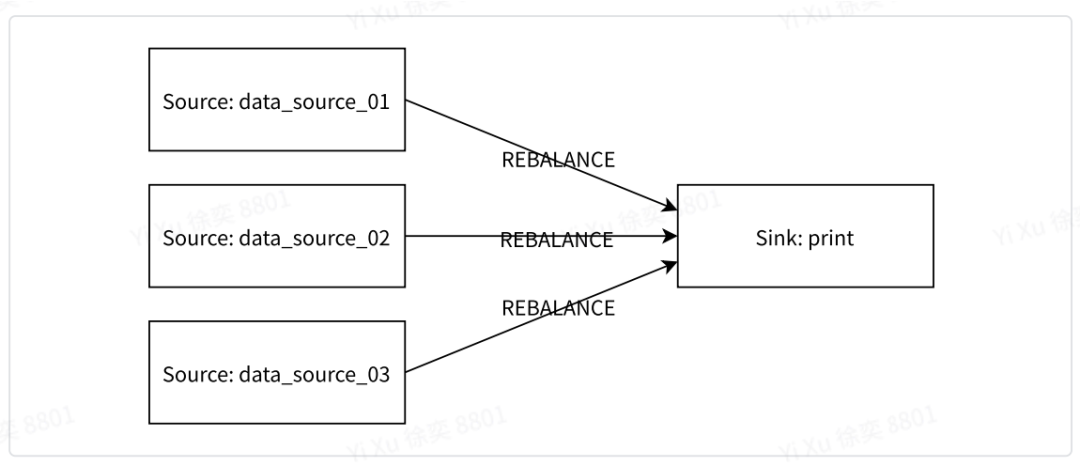
在多个数据源同步场景下,Flink提供了union算⼦⽅便进⾏多数据流的合并。 拓扑结构:
示例代码:
|
|
4.2数据过滤&转换增加Filter算子进行异常数据过滤、增加Map算子进行数据格式转换。 拓扑结构:
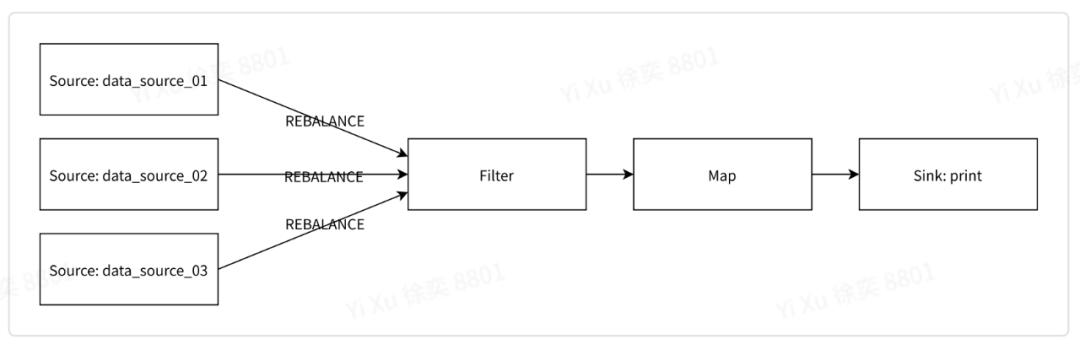
示例代码:
# 过滤异常数据
dataStreamSource.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
if (value == null) {
return false;
}
return true;
}
});
# 数据转换
dataStreamSource.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value.trim();
}
});
增加addSink调用,配置数据流写入Kafka服务。
拓扑结构:
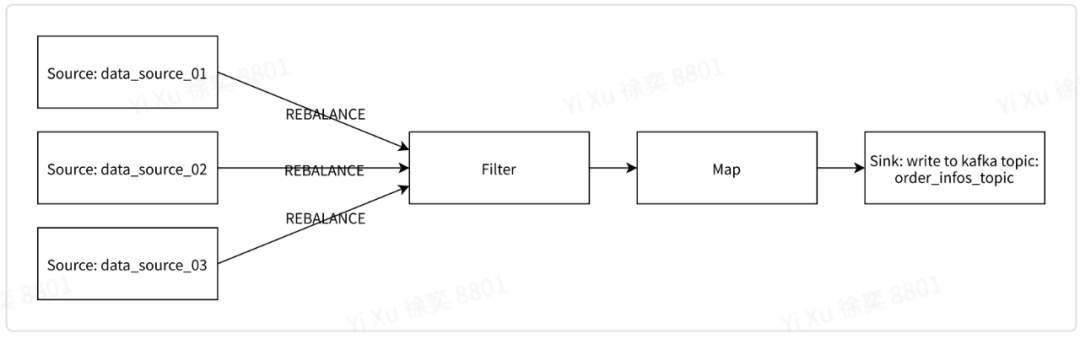
示例代码:
|
|

总结
到这里一个基本的Flink-CDC的数据同步逻辑就实现了。Flink-CDC方案,目前已落地生产环境并得到有效验证,日均千万级的数据同步,业务检索系统可达到秒级同步,报表数据可达到分钟级同步。
当然,这其中也包含了基于生产环境更多因素优化。比如Flink任务基于窗口的数据合并,任务并行度配置等。
后续,随着业务数据的增长,数据同步仍然会面临很多挑战,我们会持续优化并完善数据同步方案,也欢迎对数据同步 / ETL感兴趣的同学,可以提出您的建议共同学习交流。

参考资料
https://github.com/ververica/flink-cdc-connectors
https://github.com/zendesk/maxwell
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/bi/flink/%E5%9F%BA%E4%BA%8EFlink-CDC%E6%95%B0%E6%8D%AE%E5%90%8C%E6%AD%A5%E6%A1%88/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


