003 Apache Doris 创建表
2.3 建表
使用 CREATE TABLE 命令建立一个表(Table)。更多详细参数可以查看:
HELP CREATE TABLE;
首先切换数据库:
USE example_db;
Doris支持支持单分区和复合分区两种建表方式。
2.3.1 单分区
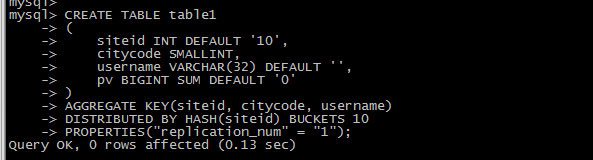
建立一个名字为 table1 的逻辑表。分桶列为 siteid,桶数为 10。
这个表的 schema 如下:
siteid:类型是INT(4字节), 默认值为10
citycode:类型是SMALLINT(2字节)
username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, Doris内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)
建表语句如下:
CREATE TABLE table1
(
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");
2.3.2 复合分区
在复合分区中
- 第一级称为 Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
- 第二级称为 Distribution,即分桶。用户可以指定一个或多个维度列以及桶数对数据进行 HASH 分布。
以下场景推荐使用复合分区:
- 有时间维度或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
- 历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N 天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送 DELETE 语句进行数据删除。
- 解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
用户也可以不使用复合分区,即使用单分区。则数据只做 HASH 分布。
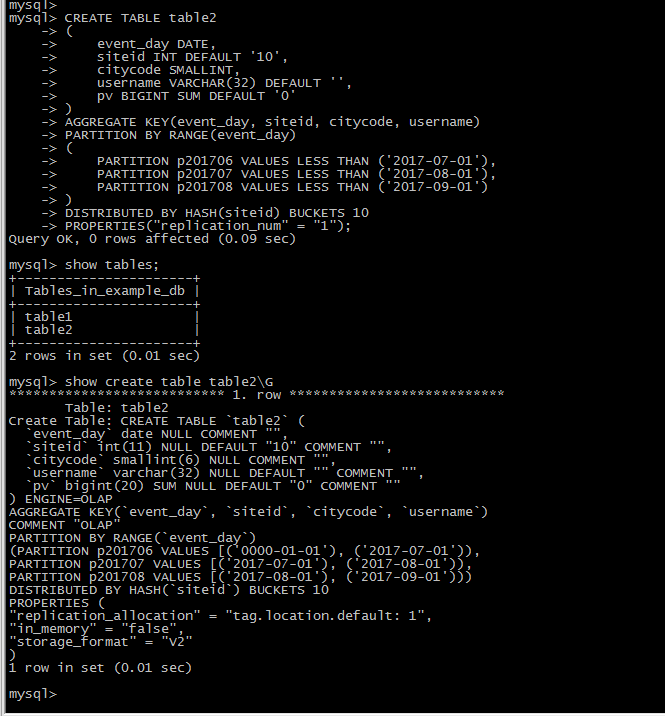
复合分区建表 建立一个名字为 table2 的逻辑表。
这个表的 schema 如下:
event_day:类型是DATE,无默认值
siteid:类型是INT(4字节), 默认值为10
citycode:类型是SMALLINT(2字节)
username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, Doris 内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)
我们使用 event_day 列作为分区列,建立3个分区: p201706, p201707, p201708 p201706:范围为 [最小值, 2017-07-01) p201707:范围为 [2017-07-01, 2017-08-01) p201708:范围为 [2017-08-01, 2017-09-01)
注意区间为左闭右开。
每个分区使用 siteid 进行哈希分桶,桶数为10
建表语句如下:
CREATE TABLE table2
(
event_day DATE,
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, siteid, citycode, username)
PARTITION BY RANGE(event_day)
(
PARTITION p201706 VALUES LESS THAN ('2017-07-01'),
PARTITION p201707 VALUES LESS THAN ('2017-08-01'),
PARTITION p201708 VALUES LESS THAN ('2017-09-01')
)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");
注意事项:
- 上述表通过设置 replication_num 建的都是单副本的表,Doris建议用户采用默认的 3 副本设置,以保证高可用。
- 可以对复合分区表动态的增删分区。详见 HELP ALTER TABLE 中 Partition 相关部分。
- 数据导入可以导入指定的 Partition。详见 HELP LOAD。
- 可以动态修改表的 Schema。
- 可以对 Table 增加上卷表(Rollup)以提高查询性能,这部分可以参见高级使用指南关于 Rollup 的描述。
- 表的列的Null属性默认为true,会对查询性能有一定的影响。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/bi/doris/003-Apache-Doris-%E5%88%9B%E5%BB%BA%E8%A1%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


