LRU cache implementation
LRU cache stand for Least Recently Used Cache,which evict least recently used entry.As Cache purpose is to provide fast and efficient way of retrieving data, it need to meet certain requirement.
Some of the Requirement are
- fixed size:cache need to have some bounds to limit memory usages.
- Fast Access:Cache Inert and lookup operation should be fast, preferably O(1) time
- Replacement of Entry in case,Memory Limit is reached:A cache shoule have efficient algorithm to evict when memory is full.
In case of LRU cache we evict least recently used entry so we have to keep track of recently used entries, entries which have not been used from long time and which have been used recently, plus lookup and insertion operation should be fast enough .
When we think about O(1) lookup, obvious data structure comes in our mind is HashMap.HashMap provide O(1) insertion and lookup,but HashMap does not has mechanism of tracking which entry has been queried recently and which not.
To track this we require another data-structure which provide fast insertion ,deletion and updation,in case of LRU we use Doubly Linkedlist.Reason for choosing doubly LinkList is O(1) deletion,updation and insertion if we have the address of Node on which this operation has to perform
So our Implementation of LRU cache will have HashMap and Doubly LinkedList.In which HashMap will hold the keys and address of the Nodes of Doubly LinkedList.And Doubly LinkedList will hold the values of keys.
As we need to keep track of Recently used entries,we will use a clever approach.We will remove element from bottom and add element on start of LinkedList and whenever any entries is accessed,it will be moved to top.so that recently used entries will be on Top and Least used will be on Bottom.
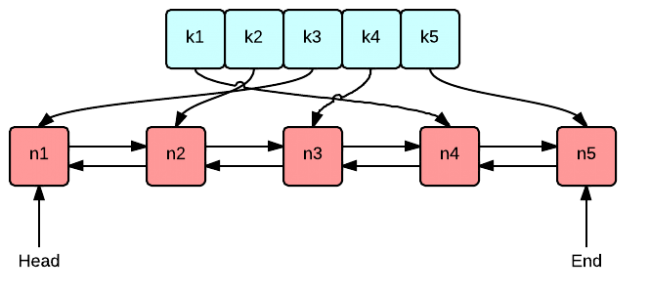
Let implementation the LRU Cache
package com.learning;
/* package whatever; // don't place package name! */
import java.util.HashMap;
class Entry {
int value;
int key;
Entry left;
Entry right;
}
public class LRUCache {
HashMap<Integer, Entry> hashmap;
Entry start, end;
int LRU_SIZE = 4; // Here i am setting 4 to test the LRU cache
// implementation, it can make be dynamic
public LRUCache() {
hashmap = new HashMap<Integer, Entry>();
}
public int getEntry(int key) {
if (hashmap.containsKey(key)) // Key Already Exist, just update the
{
Entry entry = hashmap.get(key);
removeNode(entry);
addAtTop(entry);
return entry.value;
}
return -1;
}
public void putEntry(int key, int value) {
if (hashmap.containsKey(key)) // Key Already Exist, just update the value and move it to top
{
Entry entry = hashmap.get(key);
entry.value = value;
removeNode(entry);
addAtTop(entry);
} else {
Entry newnode = new Entry();
newnode.left = null;
newnode.right = null;
newnode.value = value;
newnode.key = key;
if (hashmap.size() > LRU_SIZE) // We have reached maxium size so need to make room for new element.
{
hashmap.remove(end.key);
removeNode(end);
addAtTop(newnode);
} else {
addAtTop(newnode);
}
hashmap.put(key, newnode);
}
}
public void addAtTop(Entry node) {
node.right = start;
node.left = null;
if (start != null)
start.left = node;
start = node;
if (end == null)
end = start;
}
public void removeNode(Entry node) {
if (node.left != null) {
node.left.right = node.right;
} else {
start = node.right;
}
if (node.right != null) {
node.right.left = node.left;
} else {
end = node.left;
}
}
public static void main(String[] args) throws java.lang.Exception {
// your code goes here
LRUCache lrucache = new LRUCache();
lrucache.putEntry(1, 1);
lrucache.putEntry(10, 15);
lrucache.putEntry(15, 10);
lrucache.putEntry(10, 16);
lrucache.putEntry(12, 15);
lrucache.putEntry(18, 10);
lrucache.putEntry(13, 16);
System.out.println(lrucache.getEntry(1));
System.out.println(lrucache.getEntry(10));
System.out.println(lrucache.getEntry(15));
}
}
I hope code and tutorial is self explanatory.
来源:https://medium.com/@krishankantsinghal/my-first-blog-on-medium-583159139237
总结:最近最少使用算法,内存有限制,查找得快,删除得快,插入也得快
-
获取缓存
根据key从字典查找,如果存在,返回值,双向链表删除当前值,插入到最顶端
-
插入缓存
- 如果已经存在,更新值,并移动到链表顶端
- 不存在,生成一个新的节点,插入到顶端,如果满了,删除最后一个
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/arithmetic/lru-cache/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


