DDD019-学习笔记
DDD是什么
领域驱动设计(Domain Driven Design) 是一种从系统分析到软件建模的一套方法论。以领域为核心驱动力的设计体系。
为什么需要DDD
- 面向对象设计,数据行为绑定,告别贫血模型
- 优先考虑领域模型,而不是切割数据和行为
- 准确传达业务规则
- 代码即设计
DDD的一些概念
战略设计:限界上下文、上下文映射图、子域
战术设计:聚合、实体、值对象、资源库、领域服务、领域事件、模块
战略设计
首先战略开始,不以战略开始,战术设计将无法有效实施。它强调的是业务战略上的重点,如何按重要性分配工作,以及如何进行最佳整合。
首先用限界上下文的战略设计模式来分离领域模型。然后在明确的限界上下文中发展一套领域模型的通用语言。进一步深入战略设计中将会了解到用子域处理系统无边界的复杂性。还会了解如何通过上下文映射来集成多个限界上下文。上下文映射图同时定义了两个进行集成的限界上下文之间的团队间关系及技术实现方式。
限界上下文
限界上下文是一个显式的语义和语境上的边界,领域模型便存在于边界之内。边界内,通用语言中的所有术语和词组都有特定的含义
子域
代表单一的,有逻辑的领域模型。最佳情况,限界上下文于子域一一对应。
子域有三种类型:
- 核心域:业务的核心,核心竞争力。
- 支撑域:辅助核心域
- 通用域:被整个业务系统使用
上下文映射图
上下文映射图就是表示两个或多个限界上下文之间的映射关系。
上下文组织和集成模式:
- 合作关系(Partnership):要么一起成功,要么一起失败,此时他们需要建立起一种合作关系。他们需要一起协调开发计划和集成管理。

- 共享内核(SharedKernel):模型和代码的共享将产生一种紧密的依赖性。常见做法就是通过二进制依赖(jar)的方式共享给所有上下文使用。
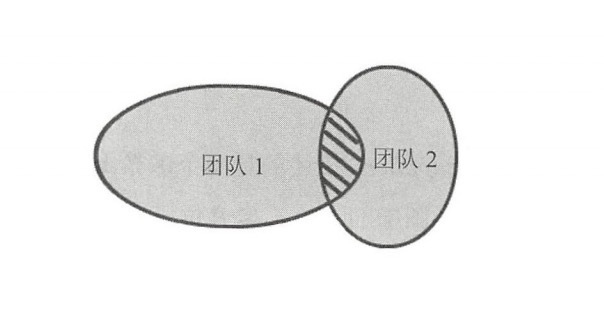
- 客户方-供应方开发(Customer-Supplier Development):客户方(D)提需求,供应方(U)配合做开发,现在用mq解耦的方式就非常类似这种。
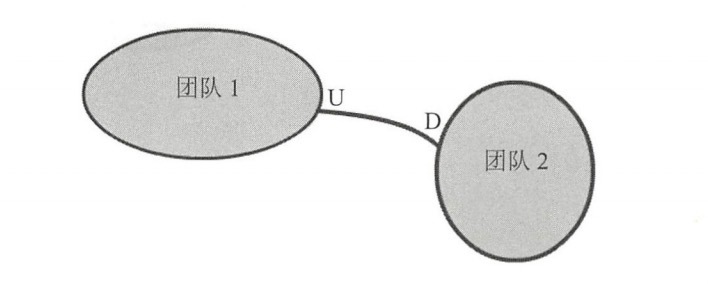
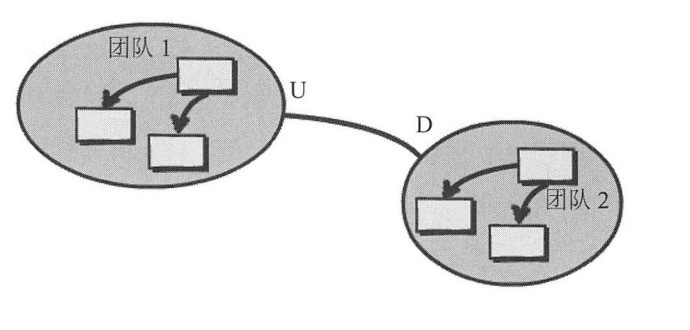
- 尊奉者(Conformist):跟客户方-供应方开发类似,只是供应方没有开发功力。下游只能盲目的使用上游的模型。
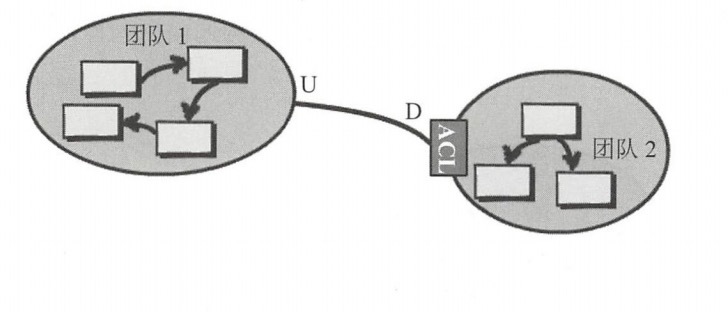
- 防腐层(Anticorruption Layer):简称ACL,在集成两个上下文,如果两边都状态良好,可以引入防腐层来作为两边的翻译,并且可以隔离两边的领域模型。
- 开放主机服务(Open Host Service):简称OHS,公开发布服务,公开的http服务,这是经常使用的
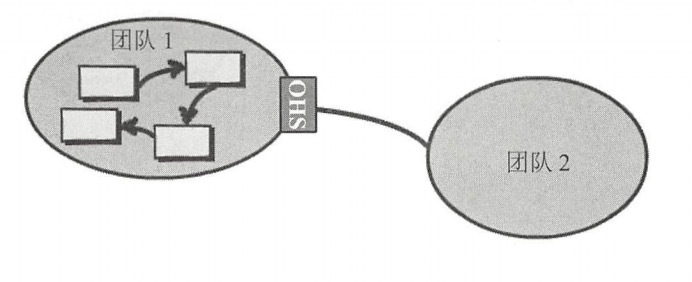
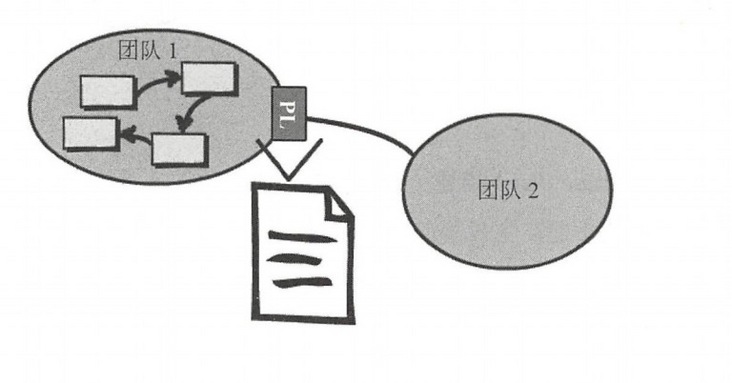
- 发布语言(Published Language):简称PL,在两个限界上下文之间翻译模型需要一种公用的语言,发布语言通常与开放主机服务一起使用。比如http服务,使用xml交互还是json做数据格式
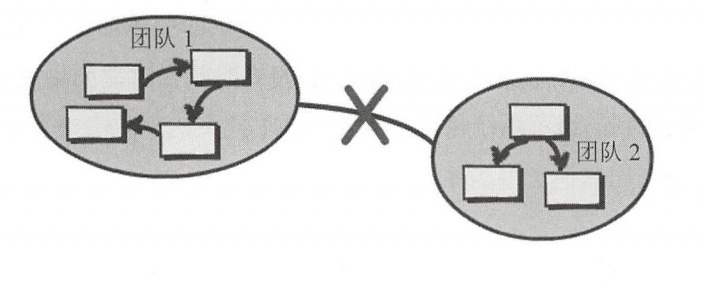
- 另谋他路(SeparateWay):声明两个限界上下文不存在任何关系,这也是一种很重的关系,完全独立各自开发
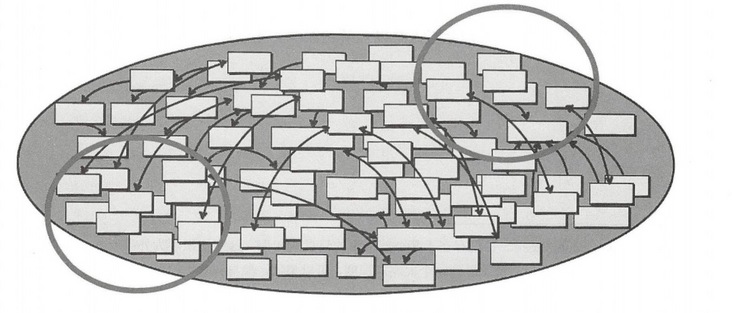
- 大泥球(Big Ball of Mud):对已有的一个大的混杂的系统,已经无法在内部梳理清楚了。你那怎么办呢?把这整个系统当成一个大泥球,对整个系统画在一个边界内,当成一个黑盒子,这样只要接口可用就行,也防止了大泥球内部的混杂扩展到其它系统上。对历史包袱的系统,可以采取这种做法。
示例
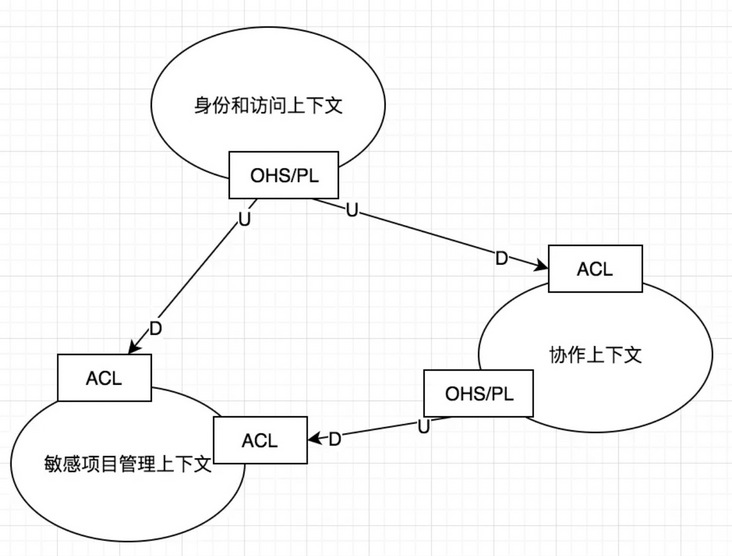
架构
分层
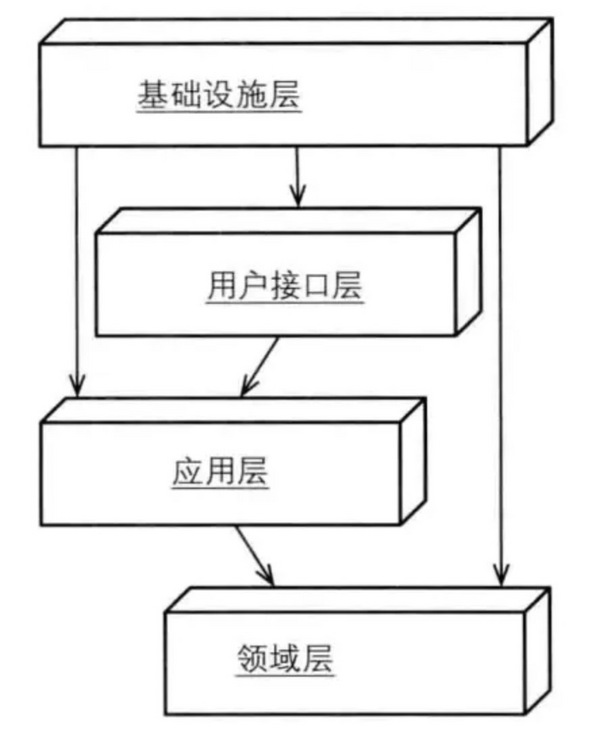
严格分层架构:某层只能与直接位于的下层发生耦合。
松散分层架构:允许上层与任意下层发生耦合
依赖倒置原则
高层模块不应该依赖于底层模块,两者都应该依赖于抽象
抽象不应该依赖于实现细节,实现细节应该依赖于接口
简单的说就是面向接口编程。
按照DIP的原则,领域层就可以不再依赖于基础设施层,基础设施层通过注入持久化的实现就完成了对领域层的解耦,采用依赖注入原则的新分层架构模型就变成如下所示:
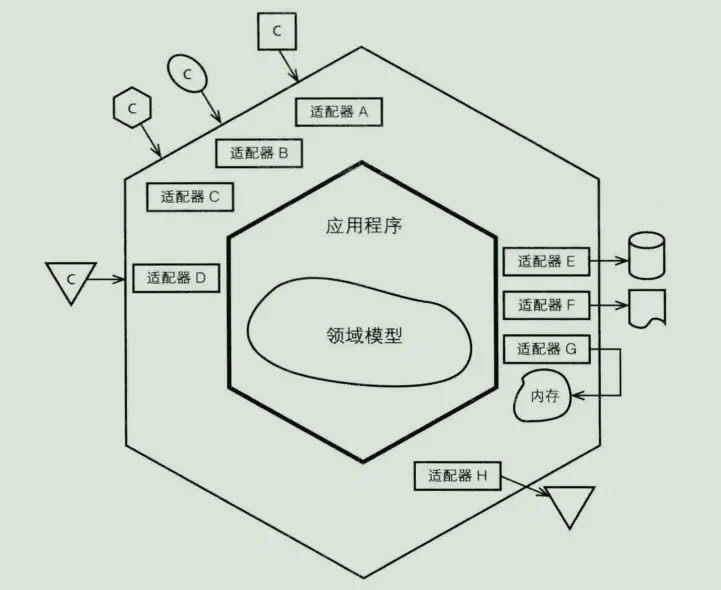
六边形架构(端口与适配器)
对于每一种外界类型,都有一个适配器与之对应。外界接口通过应用层api与内部进行交互。
对于右侧的端口与适配器,我们可以把资源库看成持久化的适配器。
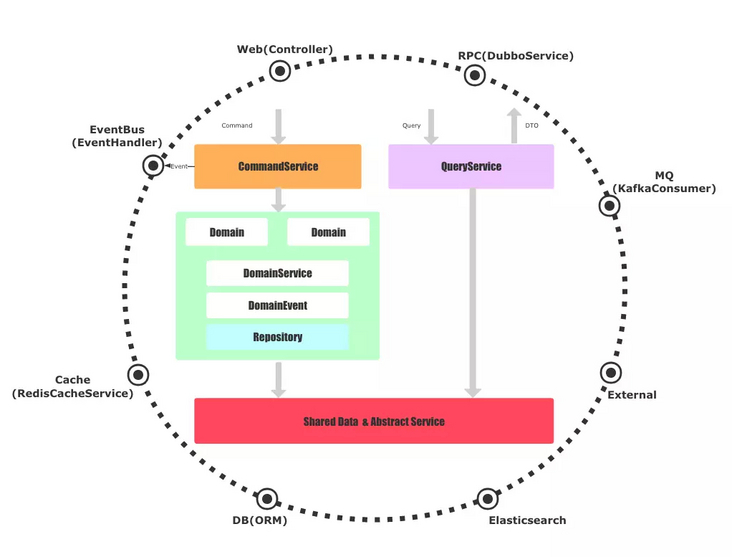 架构中,我们平等的看待Web、RPC、DB、MQ等外部服务,基础实施依赖圆圈内部的抽象。
架构中,我们平等的看待Web、RPC、DB、MQ等外部服务,基础实施依赖圆圈内部的抽象。
当一个命令Command请求过来时,会通过应用层的CommandService去协调领域层工作,而一个查询Query请求过来时,则直接通过基础实施的实现与数据库或者外部服务交互。再次强调,我们所有的抽象都定义在圆圈内部,实现都在基础设施。
命令和查询职责分离–CQRS
-
一个对象的一个方法修改了对象的状态,该方法便是一个命令(Command),它不应该返回数据,声明为void。
-
一个对象的一个方法如果返回了数据,该方法便是一个查询(Query),不应该通过直接或者间接的手段修改对象状态。
-
聚合只有Command方法,没有Query方法。
-
资源库只有add/save/fromId方法。
-
领域模型一分为二,命令模型(写模型)和查询模型(读模型)。
-
客户端和查询处理器
客户端:web浏览器、桌面应用等
查询处理器:一个只知道如何向数据库执行基本查询的简单组件,查询处理器不复杂,可以返回DTO或其它序列化的结果集,根据系统状态自定
-
查询模型:一种非规范化的数据模型,并不反映领域行为,只用于数据显示
-
客户端和命令处理器
聚合就是命令模型
命令模型拥有设计良好的契约和行为,将命令匹配到相应的契约是很直接的事情
-
事件订阅器更新查询模型
-
处理具有最终一致性的查询模型
事件驱动架构
- 事件驱动架构可以融入六边型架构,融合的比较好,也可以融入传统分层架构
- 管道和过滤器
- 长时处理过程
- 主动拉取状态检查:定时器和完成事件之间存在竞态条件可能造成失败
- 被动检查,收到事件后检查状态记录是否超时。问题:如果因为某种原因,一直收不到事件就一直不过期
- 事件源
- 对于聚合的每次命令操作,都至少一个领域事件发布出去,表示操作的执行结果
- 每一个领域事件都将被保存到事件存储中
- 从资源库获取聚合时,将根据发生在聚合上的事件来重建聚合,事件的重放顺序与其产生顺序相同
- 聚合快照:将聚合的某一事件发生时的状态快照序列化存储下来。以减少重放事件时的耗时
战术设计
实体
DDD中要求实体是唯一的且可持续变化的。意思是说在实体的生命周期内,无论其如何变化,其仍旧是同一个实体。唯一性由唯一的身份标识来决定的。可变性也正反映了实体本身的状态和行为。
实体 = 唯一身份标识 + 可变性【状态(属性) + 行为(方法或领域事件或领域服务)】
为什么使用实体
在使用DDD时,将数据模型转换为实体模型
唯一标识
在设计实体时。我们首先考虑实体的本质特征,特别是实体的唯一标识和对实体的查找,而不是一开始便关注实体的属性和行为。
值对象可以存储实体的唯一标识,与身份相关的行为可以封装在值对象中,避免泄漏到模型的其他部份或客户端中。
创建策略
- 用户提供唯一标识
- 应用程序生成唯一标识
- 持久化机制生成唯一标识
- 另一个限界上下文提供唯一标识
标识生成时间
延迟生成方式
及早生成方式
委派标识
两个标识,一个为领域所用,一个为ORM所用。委派标识没有业务意义,迎合ORM而建。对外要隐藏,不是领域模型的一部分。
模式,层超类型,protected类型的委派标识字段。
标识稳定性,不应该修改实体的唯一标识。
发现实体及其本质特性
挖掘实体的行为:set方法不是完全要禁止,在其符合通用语言(有语义)的时候,或者完成客户端单个请求不用调用多个set时才有理由使用set方法。多个set方法使语义充潢歧义,使领域事件的发送也无法应对到单个命令上
创建实体:实体维护了一个或多个不变条件(整个生命周期中都必须保持事务一致性的状态),聚合关注不变条件
跟踪变化:使用领域事件跟踪领域实体的状态变化,将领域专家所关心的状态改变建模成事件。
值对象
当你只关心某个对象的属性时,该对象便可作为一个值对象。为其添加有意义的属性,并赋予它相应的行为。我们需要将值对象看成不变对象,不要给它任何身份标识,还应该尽量避免像实体对象一样的复杂性。
值对象=值+对象=将一个值用对象的方式进行表述,来表达一个具体的固定不变的概念。
为什么使用值对象
使用不变的值对象使得我们做更少的职责假设
值对象的特性
- 它度量或者描述了领城中的一件东西。
- 它可以作为不变量。
- 它将不同的相关的属性组合成一个概念整体
- 当度量和描述改变时,可以用另一个值对象予以替换。
- 它可以和其他值对象进行相等性比较。
- 它不会对协作对象造成副作用
实现
值对象有两个构造
第一个:包含所有属性的构造函数,对基本属性的赋值调用私有的setter方法(自委派性)
第二个:复制作用的构造函数,用于将一个值对象复制为另一个新的值对象(浅复制即可,深复制太复杂,对于不变的值对象共享属性不会出现什么问题)
无副作用方法的名字很重要,不推荐使用java bean规范,除非其有通用语言的意义。推荐:String.endWith(),startWith(), indexOf()等。值对象的设计,方法不要遵循JavaBean规范。其setter更违背了值对象的不变性原则
持久化值对象
持久化机制不应该影响到值对象的建模;根据领域模型来设计数据模型,而不是根据数据模型来设计领域模型
ORM与单个值对象
实体和值对象一对一映射,值对象的属性作为字段存在和实体同一张表中
多个值对象序列化到单个列中
实体引用了List和Set属性的值对象集合
使用数据库实体保存多个值对象
值对象单独一个数据库实体表存储,并且带有一个委派主键标识,这个标识不对客户端展示。领域模型依然是一个值对象。持久化相关的逻辑没有泄漏到模型或客户端上去。
领域服务
当领域中的某个操作过程或转换过程不是实体或值对象的职责时,我们便应该将该操作放在一个单独的接口中,即领域服务。请确保该服务和通用语言时一致的。并且保证它是无状态的。
概述
- 用于实现某个领域的任务,不适合放在聚合或值对象上时,就放在领域服务上
- 放在聚合根的静态方法上有悖DDD
- 避免在聚合中调用资源库
可以用领域服务的情况
- 执行一个显著的业务操作
- 对领域对象进行转换
- 以多个领域对象作为输入参数进行计算,结果产生一个值对象
领域事件
领域事件是一个领域模型中极其重要的部分,用来表示领域中发生的事件。忽略不相关的领域活动,同时明确领域专家要跟踪或希望被通知的事情,或与其他模型对象中的状态更改相关联
领域事件 = 事件发布 + 事件存储 + 事件分发 + 事件处理。
建模领域事件
- 根据限界上下文的通用语言来命名事件及其属性
- 如果事件由聚合上的命令操作产生,则应该根据操作方法的名字来命名领域事件
- 事件的名字应该反映过去发生的事情
- 领域事件应该都有一个发生时间属性,同时要包括另外的属性:比哪些聚合跟此事件相关,继承统一的DomainEvent接口
- 事件所带的属性能够反映出该事件的来源。事件对象提供getter方法。事件属性应该是只读的,没有setter方法
- 是否有必要消除事件的重复提交
- 一个业务用例对应一个事务,一个事务对应一个聚合根,也即在一次事务中,只能对一个聚合根进行操作。当一个聚合依赖另一个聚合时,可以通过事件实现它们状态的最终一致性
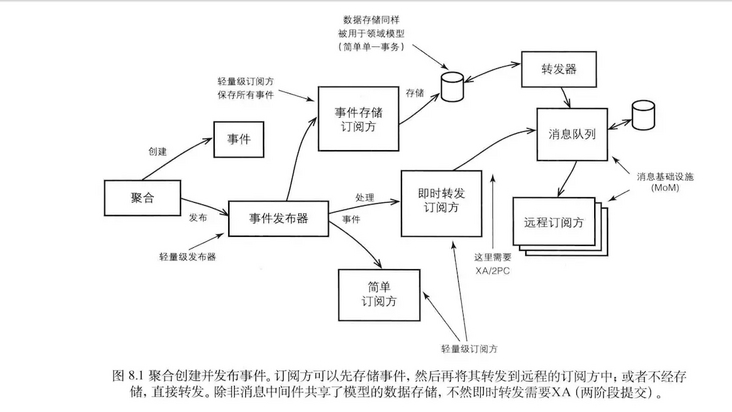
模块
模块的设计是基于领域模型的,要符合通用语言的表述。其次,模块的设计要符合高内聚低耦合的设计思想。
领域模型命名规范
- 顶级模块下一层模块名定位了一个限界上下文(就是一个应用子域),如com.smudge.atum
- 示例:com.smudge.atum.domain.aggregate,该层定义模型中的聚合。
- 上述命名规范与传统的分层架构和六边形架构兼容
聚合
聚合是领域对象的显式分组,旨在支持领域模型的行为和不变性,同时充当一致性和事务性边界。一个聚合包含聚合根、实体和值对象。
聚合设计原则
- 在一致性边界之内建模真正的不变条件
- 一致性。事务一致性、最终一致性。一个事务中只修改一个聚合,反之:不能在一个事务中同时修改多个聚合实例,真要这么做的话要考虑最终一致性
- 不变条件。指的是一个业务规则,该规则应该总是保持一致的
- 设计小聚合。根实体(Root Entity)表示聚合,绝大多数根实体可以设计为聚合
- 通过唯一标识引用其它聚合
- 在边界之外使用最终一致性
打破原则的理由
- 方便用户界面
- 一组聚合只有一个用户在处理它们,保证用户-聚合亲和度使我们有理由在单个事务中修改多个聚合实例,因为这不会违背聚合不变条件
- 全局事务
- 查询性能
实现
- 创建具有唯一标识的根实体(将实体建成聚合根)
- 优先使用值对象
- 使用迪米特法则
- “告诉而非询问”原则
- Version实现乐观并发
- 聚合中不应该注入资源库或者领域服务
聚合根、实体、值对象
从标识角度:聚合根是实体,具有全局的唯一标识。而实体只有在聚合内部有唯一的本地标识,值对象没有唯一标识,通过属性判断相等性,实现Equals方法。
从是否只读的角度:聚合根除了唯一标识外,其他所有状态信息都理论上可变。实体是可变的。值对象不可变,是只读的。
从生命周期角度:聚合根有独立的生命周期,实体的生命周期从属于其所属的聚合,实体完全由其所属的聚合根负责管理维护。值对象无生命周期可言,因为只是一个值。
聚合根、实体、值对象对象之间如何建立关联
聚合根到聚合根:通过ID关联;
聚合根到其内部的实体,直接对象引用;
聚合根到值对象,直接对象引用;
实体对其他对象的引用规则:
- 能引用其所属聚合内的聚合根、实体、值对象。
- 能引用外部聚合根,但推荐以ID的方式关联,另外也可以关联某个外部聚合内的实体,但必须是ID关联,否则就出现同一个实体的引用被两个聚合根持有,这是不允许的,一个实体的引用只能被其所属的聚合根持有。
值对象对其他对象的引用规则:只需确保值对象是只读的即可,推荐值对象的所有属性都尽量是值对象。
工厂
领域模型中的工厂
- 将创建复杂对象和聚合的职责分配给一个单独的对象,它并不承担领域模型中的职责,但是领域设计的一部份
- 对于聚合来说,我们应该一次性的创建整个聚合,并且确保它的不变条件得到满足
- 工厂只承担创建模型的工作,不具有其它领域行为
- 一个含有工厂方法的聚合根的主要职责是完成它的聚合行为
- 在聚合上使用工厂方法能更好的表达通用语言,这是使用构造函数所不能表达的
聚合根中的工厂方法
- 聚合根中的工厂方法表现出了领域概念
- 工厂方法可以提供守卫措施
领域服务中的工厂
- 在集成限界上下文时,领域服务作为工厂
- 领域服务的接口放在领域模型内,实现放在基础设施层
资源库
是聚合的管理,仓储介于领域模型和数据模型之间,主要用于聚合的持久化和检索。它隔离了领域模型和数据模型,以便我们关注于领域模型而不需要考虑如何进行持久化。
只为聚合创建资源库
聚合和资源库存在一对一的关系
实现
- 第一步,定义资源库接口,接口中有put或save类似的方法
- 与面向集合的资源库的不同点:面向集合的资源库只有在新增时调用add即可,面向持久化的无论是新增还是修改都要调用save
- 实现类放在基础设施层,将领域的概念与持久化相关的概念相分离,依赖倒置原则。基础设施层位与所有层之上,并且单向向下引用领域层
事务管理
- 事务的管理绝对不该放在领域模型和领域层中,事务放在应用层,然后为每个主要的用例创建一个门面,门面的方法是粗粒度的,每一个用例流对应一个业务方法。当用户界面层调用门面中的一个业务方法时,该方法都将开始一个事务。
- 警告:不要过度的在领域模型上使用事务,我们必须慎重的设计聚合以保证事确的一致性边界。
资源库VS数据访问对象(DAO)
- DAO主要从数据库表的角度看待问题,并且提供CRUD操作。Martin Fowler将DAO相关的设施与领域模型分离开来对待。他指出诸如“表模块”,“表数据网关”和”活动记录“这样的模式应该用于事务脚本中。这些与DAO相关的模式只是对数据库表的一层封装。
- 资源库和"数据映射器"则更偏向于对象,通常被应用于领域模型。
- DAO模式中所执行的CRUD操作都是可以放在聚合中实现的,要避免在领域模型领域模型中使用DAO模式
- 在设计资源库时我们应该采用面向集合的方式,而不是面向数据访问的方式,这有助于你将自己的领域当作模型来看待,而不是CRUD操作。
集成限界上下文
领域服务接口位于领域模型层(六边形内部),实现位为基础设施层(六边形外部,即端口和适配器所在位置)。
应用服务
应用服务是用来表达用例和用户故事(User Story)的主要手段。
应用层通过应用服务接口来暴露系统的全部功能。在应用服务的实现中,它负责编排和转发,它将要实现的功能委托给一个或多个领域对象来实现,它本身只负责处理业务用例的执行顺序以及结果的拼装。通过这样一种方式,它隐藏了领域层的复杂性及其内部实现机制。
应用层相对来说是较“薄”的一层,除了定义应用服务之外,在该层我们可以进行安全认证,权限校验,持久化事务控制,或者向其他系统发生基于事件的消息通知,另外还可以用于创建邮件以发送给客户等。
应用层作为展现层与领域层的桥梁。展现层使用VO(视图模型)进行界面展示,与应用层通过DTO(数据传输对象)进行数据交互,从而达到展现层与DO(领域对象)解耦的目的。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/DDD/DDD019-%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


