DDD-二、战术领域驱动设计
与战略领域驱动设计相比,战术设计更加亲力亲为,更接近实际代码。战略设计处理抽象的整体,而战术设计处理类和模块。战术设计的目的是将域模型细化到可以转换为工作代码的阶段。
设计是一个迭代过程,因此将战略设计和战术设计结合起来是有意义的。你从战略设计开始,然后是战术设计。最大的领域模型设计启示和突破可能发生在战术设计期间,这反过来又会影响战略设计,因此您重复该过程。
同样,内容很大程度上基于Eric Evans 的《Domain-Driven Design: Tackling Complexity in the Heart of Software》和Vaughn _Vernon__的《_实现领域驱动设计》这本书,我强烈建议您阅读这两本书。和上一篇一样,我选择了尽可能用自己的话来解释,在适当的地方注入自己的想法、想法和经验。
通过这个简短的介绍,是时候拿出战术 DDD 工具箱并看看里面有什么了。
值对象
战术 DDD 中最重要的概念之一是_值对象_。这也是我在非 DDD 项目中使用最多的 DDD 构建块,希望阅读后你也会。
值对象是其值很重要的对象。这意味着具有完全相同值的两个值对象可以被认为是相同的值对象,因此可以互换。出于这个原因,值对象应该总是_不可变_的。您无需更改值对象的状态,而是将其替换为新实例。对于复杂的值对象,请考虑使用_构建器_或_本质_模式。
值对象不仅是数据的容器——它们还可以包含业务逻辑。值对象也是不可变的这一事实使业务操作既线程安全又无副作用。这是我如此喜欢值对象的原因之一,也是为什么您应该尝试将尽可能多的域概念建模为值对象。此外,尝试使值对象尽可能小且尽可能连贯——这使它们更易于维护和重用。
制作值对象的一个很好的起点是获取所有具有业务意义的单值属性并将它们包装为值对象。例如:
- 不要将 a
BigDecimal用于货币值,而是使用Money包装 a 的值对象BigDecimal。如果您处理的货币不止一种,您可能还想创建一个Currency值对象并让您的Money对象包装一个BigDecimal-Currency对。 - 不要对电话号码和电子邮件地址使用字符串,而是使用
PhoneNumber和EmailAddress值包装字符串的对象。
使用像这样的值对象有几个优点。首先,它们为价值带来了背景。您不需要知道特定字符串是否包含电话号码、电子邮件地址、名字或邮政编码,也不需要知道 aBigDecimal是货币值、百分比还是完全不同的东西。类型本身会立即告诉您正在处理的内容。
其次,您可以将可以对特定类型的值执行的所有业务操作添加到值对象本身。例如,一个Money对象可以包含加减货币金额或计算百分比的操作,同时确保底层证券的精度BigDecimal始终正确,并且Money操作中涉及的所有对象具有相同的货币。
第三,您可以确定值对象始终包含有效值。EmailAddress例如,您可以在值对象的构造函数中验证电子邮件地址输入字符串。
代码示例
Java 中的Money值对象可能看起来像这样(代码未经测试,为清楚起见省略了一些方法实现):
public class Money implements Serializable, Comparable<Money> {
private final BigDecimal amount;
private final Currency currency; // Currency is an enum or another value object
public Money(BigDecimal amount, Currency currency) {
this.currency = Objects.requireNonNull(currency);
this.amount = Objects.requireNonNull(amount).setScale(currency.getScale(), currency.getRoundingMode());
}
public Money add(Money other) {
assertSameCurrency(other);
return new Money(amount.add(other.amount), currency);
}
public Money subtract(Money other) {
assertSameCurrency(other);
return new Money(amount.subtract(other.amount), currency);
}
private void assertSameCurrency(Money other) {
if (!other.currency.equals(this.currency)) {
throw new IllegalArgumentException("Money objects must have the same currency");
}
}
public boolean equals(Object o) {
// Check that the currency and amount are the same
}
public int hashCode() {
// Calculate hash code based on currency and amount
}
public int compareTo(Money other) {
// Compare based on currency and amount
}
}
Java 中的StreetAddress值对象和相应的构建器可能看起来像这样(代码未经测试,为清楚起见省略了一些方法实现):
public class StreetAddress implements Serializable, Comparable<StreetAddress> {
private final String streetAddress;
private final PostalCode postalCode; // PostalCode is another value object
private final String city;
private final Country country; // Country is an enum
public StreetAddress(String streetAddress, PostalCode postalCode, String city, Country country) {
// Verify that required parameters are not null
// Assign the parameter values to their corresponding fields
}
// Getters and possible business logic methods omitted
public boolean equals(Object o) {
// Check that the fields are equal
}
public int hashCode() {
// Calculate hash code based on all fields
}
public int compareTo(StreetAddress other) {
// Compare however you want
}
public static class Builder {
private String streetAddress;
private PostalCode postalCode;
private String city;
private Country country;
public Builder() { // For creating new StreetAddresses
}
public Builder(StreetAddress original) { // For "modifying" existing StreetAddresses
streetAddress = original.streetAddress;
postalCode = original.postalCode;
city = original.city;
country = original.country;
}
public Builder withStreetAddress(String streetAddress) {
this.streetAddress = streetAddress;
return this;
}
// The rest of the 'with...' methods omitted
public StreetAddress build() {
return new StreetAddress(streetAddress, postalCode, city, country);
}
}
}
实体
战术 DDD 中的第二个重要概念和值对象的兄弟是_实体_。实体是其_身份_很重要的对象。为了能够确定实体的身份,每个实体都有一个唯一的_ID_,该 ID 在创建实体时分配,并且在实体的整个生命周期内保持不变。
即使所有其他属性不同,两个相同类型且具有相同 ID 的实体也被视为同一实体。同样,两个具有相同类型和相同属性但 ID 不同的实体被视为不同的实体,就像两个具有相同名称的个体不被视为相同一样。
与值对象相反,实体是可变的。但是,这并不意味着您应该为每个属性创建 setter 方法。尝试将所有状态更改操作建模为对应于业务操作的动词。setter 只会告诉您要更改的属性,但不会告诉您更改的原因。例如:假设您有一个EmploymentContract实体并且它有一个endDate属性。雇佣合同可能会终止,因为它们只是暂时的,首先是因为从一个公司分支机构内部转移到另一个公司,因为员工辞职或因为雇主解雇了员工。在所有这些情况下,endDate都发生了改变,但原因却截然不同。此外,根据合同终止的原因,可能还需要采取其他措施。一种terminateContract(reason, finalDay)方法已经不仅仅是一种setEndDate(finalDay)方法。
也就是说,setter 在 DDD 中仍然占有一席之地。在上面的示例中,可能有一个私有setEndDate(..)方法在设置之前确保结束日期在开始日期之后。此设置器将被其他实体方法使用,但不会暴露给外界。对于主数据和参考数据以及描述实体而不改变其业务状态的属性,使用 setter 比尝试将操作调整为动词更有意义。一个被调用的方法setDescription(..)可以说比describe(..).
我将用另一个例子来说明这一点。假设您有一个Person代表一个人的实体。这个人有一个firstName和一个lastName财产。现在,如果这只是一个简单的地址簿,您可以让用户根据需要更改此信息,您可以使用 settersetFirstName(..)和setLastName(..). 但是,如果您要建立官方的政府公民登记册,则更改姓名会更加复杂。你最终可能会得到类似changeName(firstName, lastName, reason, effectiveAsOfDate). 同样,上下文就是一切。
关于set get说明
Getter 方法作为 JavaBean 规范的一部分引入 Java。此规范在 Java 的第一个版本中不存在,这就是为什么您可以在标准 Java API 中找到一些不符合它的方法(例如String.length(),与 相对String.getLength())。
就我个人而言,我希望看到对 Java 中真实属性的支持。尽管他们可以在幕后使用 getter 和 setter,但我想以与普通字段相同的方式访问属性值mycontact.phoneNumber:我们还不能在 Java 中做到这一点,但是我们可以通过省略getgetter 的后缀来实现。在我看来,这使代码更加流畅,特别是如果您需要更深入地了解对象层次结构以获取某些内容:mycontact.address().streetNumber().
然而,摆脱 getter 也有一个缺点,那就是工具支持。所有 Java IDE 和许多库都依赖于 JavaBean 标准,这意味着您最终可能会手动编写本可以为您自动生成的代码,并添加本可以通过遵守约定来避免的注释。
实体还是值对象?
并不总是很容易知道是将某物建模为值对象还是实体。完全相同的现实世界概念可以在一个上下文中建模为实体,在另一个上下文中建模为值对象。让我们以街道地址为例。
如果您正在构建发票系统,街道地址只是您在发票上打印的内容。只要发票上的文本正确,使用什么对象实例都没有关系。在这种情况下,街道地址是一个值对象。
如果您正在为公用事业构建系统,您需要确切地知道进入给定公寓的燃气线路或电力线路。在这种情况下,街道地址是一个实体,它甚至可以拆分为更小的实体,如建筑物或公寓。
值对象更容易使用,因为它们是不可变的并且很小。因此,您应该针对具有较少实体和许多值对象的设计。
代码示例
Java 中的Person实体可能看起来像这样(代码未经测试,为清楚起见省略了一些方法实现):
public class Person {
private final PersonId personId;
private final EventLog changeLog;
private PersonName name;
private LocalDate birthDate;
private StreetAddress address;
private EmailAddress email;
private PhoneNumber phoneNumber;
public Person(PersonId personId, PersonName name) {
this.personId = Objects.requireNonNull(personId);
this.changeLog = new EventLog();
changeName(name, "initial name");
}
public void changeName(PersonName name, String reason) {
Objects.requireNonNull(name);
this.name = name;
this.changeLog.register(new NameChangeEvent(name), reason);
}
public Stream<PersonName> getNameHistory() {
return this.changeLog.eventsOfType(NameChangeEvent.class).map(NameChangeEvent::getNewName);
}
// Other getters omitted
public boolean equals(Object o) {
if (o == this) {
return true;
}
if (o == null || o.getClass() != getClass()) {
return false;
}
return personId.equals(((Person) o).personId);
}
public int hashCode() {
return personId.hashCode();
}
}
此示例中需要注意的一些事项:
- 值对象 -
PersonId- 用于实体 ID。我们也可以使用 UUID、字符串或 long,但值对象会立即告诉我们这是一个标识特定Person. - 除了实体 ID,该实体还使用许多其他值对象:
PersonName、LocalDate(是的,这也是一个值对象,即使它是标准 Java API 的一部分)StreetAddress、EmailAddress和PhoneNumber。 - 我们不使用 setter 来更改名称,而是使用一种业务方法,该方法还将更改以及更改名称的原因存储在事件日志中。
- 有一个 getter 用于检索名称更改的历史记录。
equals并且hashCode只检查实体 ID。
领域驱动设计和 CRUD
我们现在已经到了适合解决有关 DDD 和 CRUD 的问题的地步。CRUD 代表_Create_、Retrieve、Update_和_Delete,也是企业应用程序中常见的 UI 模式:
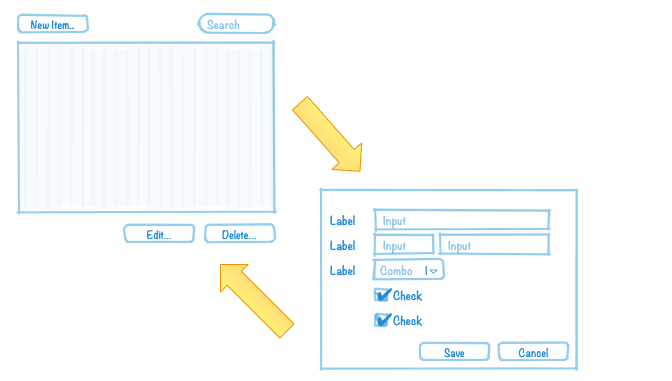
- 主视图由一个网格组成,可能带有过滤和排序,您可以在其中查找实体(检索)。
- 在主视图中,有一个用于创建新实体的按钮。单击按钮会弹出一个空表单,提交表单后,新实体会显示在网格中(创建)。
- 在主视图中,有一个用于编辑所选实体的按钮。单击该按钮会弹出一个包含实体数据的表单。提交表单时,实体会使用新信息(更新)进行更新。
- 在主视图中,有一个用于删除所选实体的按钮。单击该按钮会从网格中删除实体(删除)。
这种模式当然有它的位置,但在域驱动的应用程序中应该_是例外而不是规范。_原因如下: CRUD 应用程序只涉及结构化、显示和编辑数据。它通常不支持底层业务流程。当用户在系统中输入某些内容、更改某些内容或删除某些内容时,该决定背后是有商业原因的。也许变化是作为更大业务流程的一部分发生的?在 CRUD 系统中,更改的原因丢失了,业务流程在用户的脑海中。
真正的领域驱动用户界面将基于作为通用语言(以及领域模型)一部分的操作,并且业务流程内置于系统中,而不是用户的头脑中。反过来,这会导致系统比纯 CRUD 应用程序更健壮,但可以说灵活性较低。我将用一个讽刺的例子来说明这种差异:
公司 A 有一个域驱动的系统来管理员工,而公司 B 有一个 CRUD 驱动的方法。两家公司的员工都辞职了。会发生以下情况:
- A公司:
- 经理在系统中查找员工的记录。
- 经理选择“终止雇佣合同”操作。
- 系统会询问终止日期和原因。
- 经理输入所需信息并单击“终止合同”。
- 系统自动更新员工记录,撤销员工的用户凭证和电子办公密钥,并向工资系统发送通知。
- B公司:
- 经理在系统中查找员工的记录。
- 经理勾选“合同终止”复选框并输入终止日期,然后单击“保存”。
- 管理员登录用户管理系统,查找用户帐户,勾选“已禁用”复选框并单击“保存”。
- 经理登录办公室密钥管理系统,查找用户密钥,勾选“已禁用”复选框并单击“保存”。
- 经理向工资部门发送一封电子邮件,通知他们该员工已离职。
关键要点如下: 并非所有应用程序都适合域驱动设计,域驱动应用程序不仅有域驱动的后端,还有域驱动的用户界面。
聚合
现在,当我们知道实体和值对象是什么时,我们将看看下一个重要概念:聚合。聚合是一组具有某些特征的实体和值对象:
-
聚合被创建、检索和存储_为一个整体_。
-
聚合始终处于_一致_状态。
-
聚合由称为_聚合根_的实体拥有,其 ID 用于标识聚合本身。

此外,还有两个关于聚合的重要限制:
-
聚合只能通过其根从外部引用。聚合外的对象_不能_引用聚合内的任何其他实体。
-
聚合根负责在聚合内部强制执行_业务不变量_,确保聚合始终处于一致状态。
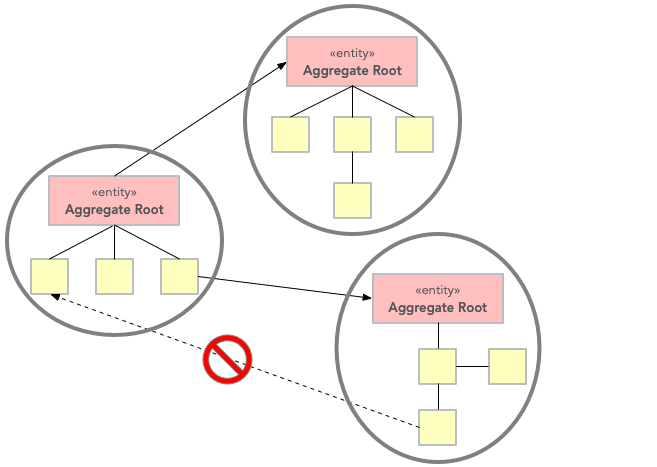
这意味着无论何时你设计一个实体,你都必须决定你将要制作什么样的实体:该实体将充当聚合根,还是我称之为_本地实体_,它存在于聚合内并位于监督聚合根?由于不能从聚合外部引用本地实体,因此它们的 ID 在聚合内是唯一的就足够了(它们具有_本地标识_),而聚合根必须具有全局唯一的 ID(它们具有_全局标识_)。但是,这种语义差异的重要性取决于您选择存储聚合的方式。在关系数据库中,对所有实体使用相同的主键生成机制是最有意义的。另一方面,如果将整个聚合保存为文档数据库中的单个文档,则为本地实体使用真正的本地 ID 更有意义。
那么你怎么知道一个实体是否是一个聚合根呢?首先,两个实体之间存在父子(或主从)关系这一事实并不会自动将父实体变为聚合根,而将子实体变为本地实体。在做出该决定之前需要更多信息。这是我的做法:
- 如何在应用程序中访问实体?
- 如果实体将通过 ID 或通过某种搜索来查找,则它可能是聚合根。
- 其他聚合是否需要引用它?
- 如果实体将在其他聚合中被引用,它肯定是聚合根。
- 如何在应用程序中修改实体?
- 如果它可以独立修改,它可能是一个聚合根。
- 如果在不更改另一个实体的情况下无法对其进行修改,则它可能是本地实体。
一旦你知道你正在创建一个聚合根,你如何让它强制执行业务不变量,这甚至意味着什么?业务不变量是无论聚合发生什么都必须始终保持的规则。一个简单的业务不变量可能是,在发票中,总金额必须始终是行项目金额的总和,无论是否添加、编辑或删除项目。不变量应该是通用语言和领域模型的一部分。
从技术上讲,聚合根可以以不同的方式强制执行业务不变量:
- 所有状态更改操作都是通过聚合根执行的。
- 允许对本地实体进行状态更改操作,但它们会在更改时通知聚合根。
在某些情况下,例如在发票总额的示例中,可以通过让聚合根在每次请求时动态计算总额来强制执行不变量。
我个人设计了我的聚合,以便立即且始终强制执行不变量。可以说,您可以通过引入在保存聚合之前执行的严格数据验证来获得相同的最终结果(Java EE 方式)。归根结底,这是个人品味的问题。
聚合设计指南
在设计聚合时,需要遵循某些准则。我选择称它们为准则而不是规则,因为在某些情况下打破它们是有意义的。
准则 1:保持聚合小
聚合总是作为一个整体进行检索和存储。您必须读取和写入的数据越少,您的系统性能就越好。出于同样的原因,您应该避免无限的一对多关联(集合),因为这些关联会随着时间的推移而变大。
拥有一个小的聚合也使聚合根更容易强制执行业务不变量,如果您更喜欢在聚合中使用值对象(不可变)而不是本地实体(可变),则更是如此。
准则 2:按 ID 引用其他聚合
与其直接引用另一个聚合,不如创建一个包装聚合根 ID 的值对象并将其用作引用。这使得维护聚合一致性边界变得更加容易,因为您甚至不会意外地从另一个聚合中更改一个聚合的状态。它还可以防止在检索聚合时从数据存储中检索深层对象树。
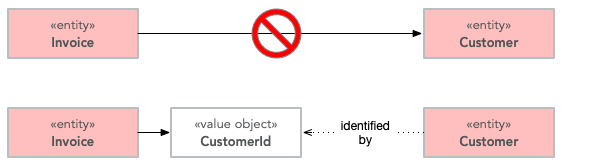
如果您确实需要访问其他聚合的数据并且没有更好的方法来解决问题,您可能需要打破此准则。您可以依赖持久性框架的延迟加载功能,但根据我的经验,它们往往导致的问题多于解决的问题。需要更多编码但更明确的方法是将存储库(稍后将详细介绍)作为方法参数传递:
public class Invoice extends AggregateRoot<InvoiceId> {
private CustomerId customerId;
// All the other methods and fields omitted
public void copyCustomerInformationToInvoice(CustomerRepository repository) {
Customer customer = repository.findById(customerId);
setCustomerName(customer.getName());
setCustomerAddress(customer.getAddress());
// etc.
}
}
在任何情况下,您都应该避免聚合之间的双向关系。
准则 3:每笔交易更改一个聚合
尝试设计您的操作,以便您仅在单个事务中对一个聚合进行更改。对于跨越多个聚合的操作,使用领域事件和最终一致性(稍后会详细介绍)。这可以防止意外的副作用,并在未来需要时更容易分发系统。作为奖励,它还使得在没有事务支持的情况下使用文档数据库变得更加容易。
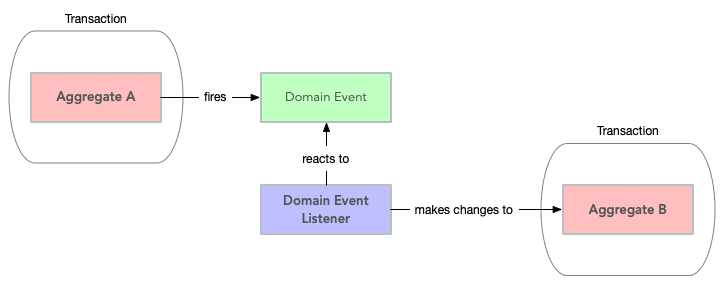
然而,这带来了增加复杂性的代价。您需要建立一个可靠地处理领域事件的基础设施。尤其是在一个单体应用程序中,您可以在同一个线程和事务中同步分派域事件,在我看来,增加的复杂性很少有动机。在我看来,一个好的折衷方案是仍然依赖域事件来更改其他聚合,但要在同一个事务中进行:
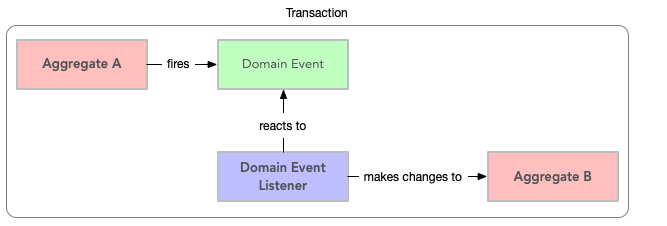
在任何情况下,您都应该尽量避免直接从另一个聚合中更改聚合的状态。
稍后我们将在讨论域事件时对此进行更多讨论。
准则 4:使用乐观锁定
聚合的一个关键特性是强制执行业务不变量并始终确保数据一致性。如果聚合最终由于数据存储更新冲突而损坏,这一切都是徒劳的。因此,您应该在保存聚合时使用乐观锁定来防止数据丢失。
乐观锁优于悲观锁的原因是,如果持久性框架不支持开箱即用,您自己很容易实现,并且易于分发和扩展。
坚持第一个准则也将有助于解决这个问题,因为小聚合(因此小交易)也降低了冲突的风险。
聚合、不变量、UI 绑定和验证
你们中的一些人现在可能想知道聚合和强制业务不变量如何与用户界面一起工作,更具体地说是表单绑定。如果要始终强制执行不变量并且聚合必须始终处于一致状态,那么当用户填写表单时您会做什么?此外,如果没有设置器,如何将表单字段绑定到聚合?
有多种方法可以处理这一问题。最简单的解决方案是在保存聚合之前推迟执行不变,为所有属性添加设置器并将实体直接绑定到表单。我个人不喜欢这种方法,因为我相信它更多是数据驱动而不是领域驱动。实体退化为数据持有者的风险很高,业务逻辑最终进入服务层(或更糟的是,在 UI 中)。
相反,我更喜欢另外两种方法。第一个是将表单及其内容建模为它们自己的领域模型概念。在现实世界中,如果你申请某样东西,你通常需要填写一份申请表并提交。然后处理申请,一旦提供了所有必要的信息并且您符合规则,申请就会被批准,您会得到您申请的任何东西。您可以在域模型中模拟此过程。例如,如果您有一个Membership聚合根,您还可以有一个MembershipApplication聚合根,用于收集创建Membership. 然后,应用程序对象可以在创建成员资格对象时用作输入。
第二种方法是第一种方法的变体,即_本质_模式。对于您需要编辑的每个实体或值对象,创建一个包含相同信息的可变本质对象。然后将这个本质对象绑定到表单。一旦本质对象包含所有必要的信息,它就可以用来创建真实的实体或值对象。与第一种方法的不同之处在于,本质对象不是领域模型的一部分,它们只是为了更容易与真实领域对象交互而存在的技术构造。在实践中,本质模式可能看起来像这样:
public class Person extends AggregateRoot<PersonId> {
private final DateOfBirth dateOfBirth;
// Rest of the fields omitted
public Person(String firstName, String lastName, LocalDate dateOfBirth) {
setDateOfBirth(dateOfBirth);
// Populate the rest of the fields
}
public Person(Person.Essence essence) {
setDateOfBirth(essence.getDateOfBirth());
// Populate the rest of the fields
}
private void setDateOfBirth(LocalDate dateOfBirth) {
this.dateOfBirth = Objects.requireNonNull(dateOfBirth, "dateOfBirth must not be null");
}
@Data // Lombok annotation to automatically generate getters and setters
public static class Essence {
private String firstName;
private String lastName;
private LocalDate dateOfBirth;
private String streetAddress;
private String postalCode;
private String city;
private Country country;
public Person createPerson() {
validate();
return new Person(this);
}
private void validate() {
// Make sure all necessary information has been entered, throw an exception if not
}
}
}
如果您愿意,如果您更熟悉该模式,则可以用构建器替换本质。最终结果将是相同的。
代码示例
这是一个聚合根 ( Order) 和具有本地标识的本地实体 ( OrderItem) 的示例(代码未经测试,为清楚起见省略了一些方法实现):
public class Order extends AggregateRoot<OrderId> { // ID type passed in as generic parameter
private CustomerId customer;
private String shippingName;
private PostalAddress shippingAddress;
private String billingName;
private PostalAddress billingAddress;
private Money total;
private Long nextFreeItemId;
private List<OrderItem> items = new ArrayList<>();
public Order(Customer customer) {
super(OrderId.createRandomUnique());
Objects.requireNonNull(customer);
// These setters are private and make sure the passed in parameters are valid:
setCustomer(customer.getId());
setShippingName(customer.getName());
setShippingAddress(customer.getAddress());
setBillingName(customer.getName());
setBillingAddress(customer.getAddress());
nextFreeItemId = 1L;
recalculateTotals();
}
public void changeShippingAddress(String name, PostalAddress address) {
setShippingName(name);
setShippingAddress(address);
}
public void changeBillingAddress(String name, PostalAddress address) {
setBillingName(name);
setBillingAddress(address);
}
private Long getNextFreeItemId() {
return nextFreeItemId++;
}
void recalculateTotals() { // Package visibility to make the method accessible from OrderItem
this.total = items.stream().map(OrderItem::getSubTotal).reduce(Money.ZERO, Money::add);
}
public OrderItem addItem(Product product) {
OrderItem item = new OrderItem(getNextFreeItemId(), this);
item.setProductId(product.getId());
item.setDescription(product.getName());
this.items.add(item);
return item;
}
// Getters, private setters and other methods omitted
}
public class OrderItem extends LocalEntity<Long> { // ID type passed in as generic parameter
private Order order;
private ProductId product;
private String description;
private int quantity;
private Money price;
private Money subTotal;
OrderItem(Long id, Order order) {
super(id);
this.order = Objects.requireNonNull(order);
this.quantity = 0;
this.price = Money.ZERO;
recalculateSubTotal();
}
private void recalculateSubTotal() {
Money oldSubTotal = this.subTotal;
this.subTotal = price.multiply(quantity);
if (oldSubTotal != null && !oldSubTotal.equals(this.subTotal)) {
this.order.recalculateTotals(); // Invoke aggregate root to enforce invariants
}
}
public void setQuantity(int quantity) {
if (quantity < 0) {
throw new IllegalArgumentException("Quantity cannot be negative");
}
this.quantity = quantity;
recalculateSubTotal();
}
public void setPrice(Money price) {
Objects.requireNonNull(price, "price must not be null");
this.price = price;
recalculateSubTotal();
}
// Getters and other setters omitted
}
领域事件
到目前为止,我们只查看了域模型中的“事物”。但是,这些只能用于描述模型在任何给定时刻所处的静态状态。在许多业务模型中,您还需要能够描述发生的事情并改变模型的状态。为此,您可以使用_域事件_。
Evans 关于领域驱动设计的书中没有包含领域事件。它们后来被添加到工具箱中,并包含在弗农的书中。
领域事件是领域模型中发生的任何可能对系统的其他部分感兴趣的事情。领域事件可以是粗粒度的(例如,创建特定聚合根或启动进程)或细粒度(例如,特定聚合根的特定属性被更改)。
领域事件通常具有以下特征:
- 它们是不可变的(毕竟,你无法改变过去)。
- 当相关事件发生时,它们有一个时间戳。
- 他们_可能_有一个唯一的 ID,有助于区分一个事件和另一个事件。这取决于事件的类型以及事件的分布方式。
- 它们由聚合根或域服务发布(稍后将详细介绍)。
一旦一个领域事件被发布,它就可以被一个或多个_领域事件监听_器接收到,这反过来可能触发额外的处理和新的领域事件等。发布者不知道事件发生了什么,监听器也不应该被能够影响发布者(换句话说,从发布者的角度来看,发布域事件应该没有副作用)。因此,建议_域事件侦听器不要在发布事件的同一事务中运行_。
从设计的角度来看,领域事件的最大优势在于它们使系统具有可扩展性。您可以根据需要添加任意数量的域事件侦听器来触发新的业务逻辑,而无需更改现有代码。这自然假设首先发布了正确的事件。有些事件您可能会提前知道,但其他事件会在以后进一步显现。当然,您可以尝试猜测将需要哪些类型的事件并将它们添加到您的模型中,但是您也有可能因在任何地方都不使用的域事件而阻塞系统。更好的方法是尽可能轻松地发布域事件,然后在您意识到需要它们时添加缺少的事件。
关于事件溯源的说明
事件溯源是一种设计模式,其中系统的状态作为事件的有序日志持续存在。每个甚至更改系统的状态,并且可以通过从头到尾重播事件日志随时计算当前状态。这种模式在历史与当前状态同样重要(甚至更重要)的应用程序中特别有用,例如财务分类帐或医疗记录。
根据我的经验,典型业务系统的大多数部分不需要事件溯源,但有些部分需要。在我看来,强制整个系统使用事件溯源作为持久性模型是矫枉过正的。但是,我发现域事件可用于在需要时实现事件溯源。在实践中,这意味着每一个改变模型状态的操作也会发布一个存储在一些事件日志中的领域事件。如何在技术上做到这一点超出了本文的范围。
分发领域事件
只有当您有可靠的方式将它们分发给侦听器时,域事件才可用。在单体应用中,您可以使用标准观察者模式来处理内存中的分布。但是,即使在这种情况下,如果您遵循在单独的事务中运行事件发布者的良好做法,您也可能需要更复杂的东西。如果其中一个事件侦听器失败并且必须重新发送事件怎么办?
Vernon 提出了两种不同的远程和本地分发事件的方式。我鼓励您阅读他的书以了解详细信息,但我将在这里对选项进行简短摘要。
通过消息队列分发
此解决方案需要外部消息传递解决方案 (MQ),例如 AMQP 或 JMS。该解决方案需要支持发布-订阅模型并保证交付。发布域事件时,生产者将其发送到 MQ。域事件侦听器订阅 MQ 并将立即收到通知。

该模型的优点是速度快、非常容易实现,并且依赖于现有的经过验证的真正消息传递解决方案。缺点是您必须设置和维护 MQ 解决方案,如果有新的消费者订阅,则无法接收过去的事件。
通过事件日志分发
该解决方案不需要额外的组件,但需要一些编码。发布域事件时,会将其附加到事件日志中。域事件侦听器定期轮询此日志以检查新事件。他们还跟踪他们已经处理了哪些事件,以避免每次都查看整个事件日志。

该模型的优点是它不需要任何额外的组件,并且它包含一个完整的事件历史记录,可以为新的事件侦听器重播。缺点是它需要一些工作来实现,并且监听器发布和接收事件之间的延迟最多是轮询间隔。
关于最终一致性的说明
在分布式系统或多个数据存储参与同一逻辑事务的情况下,数据一致性始终是一个挑战。高级应用服务器支持可用于解决此问题的分布式事务,但它们需要专门的软件并且配置和维护起来可能很复杂。如果_强一致性_是绝对要求,你别无选择,只能使用分布式事务,但在很多情况下,从业务角度来看,强一致性实际上并不那么重要。从我们在单个 ACID 事务中让单个应用程序与单个数据库进行通信的时代开始,我们只习惯于考虑强一致性。
强一致性的替代方案是_最终一致性_。这意味着应用程序中的数据最终将变得一致,但有时系统的所有部分并非彼此同步,_这完全_没问题。设计最终一致性的应用程序需要不同的思维方式,但反过来会导致系统比仅需要强一致性的系统更具弹性和可扩展性。
在域驱动的系统中,域事件是实现最终一致性的绝佳方式。当另一个模块或系统发生某些事情时,任何需要自我更新的系统或模块都可以订阅来自该系统的域事件:
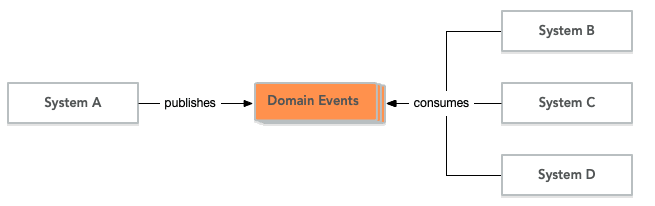
在上面的示例中,对系统 A 所做的任何更改_最终_都将通过域事件传播到系统 B、C 和 D。每个系统将使用自己的本地事务来实际更新数据存储。根据事件分发机制和系统的负载,传播时间可以从不到一秒(所有系统都在同一个网络中运行,事件立即推送给订阅者)到几个小时甚至几天(有些系统处于脱机状态,仅偶尔连接到网络以下载自上次签入以来发生的所有域事件)。
为了成功实现最终一致性,您必须有一个可靠的系统来分发域事件,即使在首次发布事件时某些订阅者当前不在线时也能正常工作。您还需要围绕任何数据可能随时过时的假设来设计业务逻辑和用户界面。您还需要对数据不一致的时间长度进行限制。您可能会惊讶地发现,有些数据可能会在几天内保持不一致,而其他数据必须在几秒钟甚至更短的时间内更新。
代码示例
这是一个聚合根 () 的示例,它在订单发货时Order发布域事件 ( )。OrderShipped域侦听器 ( InvoiceCreator) 将接收事件并在单独的事务中创建新发票。假设有一种机制可以在保存聚合根时发布所有注册的事件(代码未经测试,为清楚起见省略了一些方法实现):
public class OrderShipped implements DomainEvent {
private final OrderId order;
private final Instant occurredOn;
public OrderShipped(OrderId order, Instant occurredOn) {
this.order = order;
this.occurredOn = occurredOn;
}
// Getters omitted
}
public class Order extends AggregateRoot<OrderId> {
// Other methods omitted
public void ship() {
// Do some business logic
registerEvent(new OrderShipped(this.getId(), Instant.now()));
}
}
public class InvoiceCreator {
final OrderRepository orderRepository;
final InvoiceRepository invoiceRepository;
// Constructor omitted
@DomainEventListener
@Transactional
public void onOrderShipped(OrderShipped event) {
var order = orderRepository.find(event.getOrderId());
var invoice = invoiceFactory.createInvoiceFor(order);
invoiceRepository.save(invoice);
}
}
可移动和静态对象
在继续之前,我想向您介绍_可移动_和_静态_对象。这些不是真正的 DDD 术语,而是我在考虑域模型的不同部分时自己使用的术语。在我的世界中,可移动对象是可以有多个实例并且可以在应用程序的不同部分之间传递的任何对象。值对象、实体和领域事件都是可移动的对象。
另一方面,静态对象是一个单例(或池化资源),它始终位于一个位置并由应用程序的其他部分调用,但很少被传递(除非被注入到其他静态对象中)。存储库、域服务和工厂都是静态对象。
这种差异很重要,因为它决定了您可以在对象之间建立什么样的关系。静态对象可以保存对其他静态对象和可移动对象的引用。
可移动对象可以保存对其他可移动对象的引用。但是,可移动对象_永远不能_持有对静态对象的引用。如果可移动对象需要与静态对象交互,则必须将静态对象作为方法参数传递给将与其交互的方法。这使得可移动对象更具可移植性和独立性,因为您无需在每次反序列化它们时查找和注入对静态对象的任何引用到可移动对象中。
其他领域对象
当您使用域驱动代码时,有时会遇到类不适合值对象、实体或域事件模型的情况。根据我的经验,这通常发生在以下情况:
- 来自外部系统的任何信息(= 另一个有界上下文)。从您的角度来看,这些信息是不可变的,但它有一个用于唯一标识它的全局 ID。
- 用于描述其他实体的类型数据(Vaughn Vernon 将这些对象称为_标准类型_)。这些对象具有全局 ID,甚至在某种程度上可能是可变的,但对于应用程序本身的所有实际目的,它们是不可变的。
- 框架/基础设施级实体,用于在数据库中存储审计条目或域事件。它们可能具有也可能没有全局 ID,并且可能是可变的,也可能不是可变的,具体取决于用例。
我处理这些情况的方法是使用以DomainObject. 域对象是任何与域模型相关的可移动对象。如果一个对象是纯粹的值对象或不是纯粹的实体,我可以将它声明为域对象,在 JavaDocs 中解释它的作用和原因,然后继续。
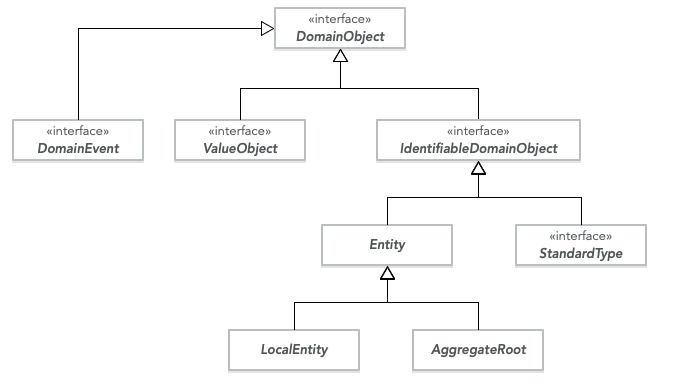
我喜欢在层次结构的顶部使用接口,因为你可以以任何你喜欢的方式组合它们,甚至可以enums实现它们。一些接口是标记接口,没有任何方法,仅用于指示实现类在域模型中所起的作用。在上图中,类和接口如下:
DomainObject- 所有域对象的顶级标记界面。DomainEvent- 所有领域事件的接口。这通常包含有关事件的一些元数据,例如事件的日期和时间,但它也可能是一个标记界面。ValueObject- 所有值对象的标记接口。这个接口的实现需要是不可变的并且实现equals()和hashCode(). 不幸的是,没有办法从接口级别强制执行此操作,即使那样会很好。IdentifiableDomainObject- 可以在某些上下文中唯一标识的所有域对象的接口。我经常把它设计成一个泛型接口,ID 类型作为泛型参数。StandardType- 标准类型的标记接口。Entity- 实体的抽象基类。我经常包含一个 ID 字段equals()并hashCode()相应地实施。根据持久性框架,我还可能向此类添加乐观锁定信息。LocalEntity- 本地实体的抽象基类。如果我对本地实体使用本地身份,则此类将包含用于管理该身份的代码。否则,它可能只是一个空的标记类。AggregateRoot- 聚合根的抽象基类。如果我对本地实体使用本地身份,则此类将包含用于生成新本地 ID 的代码。该类还将包含用于分派领域事件的代码。如果类中没有包含乐观锁信息Entity,那么这里肯定包含。根据应用程序的要求,也可以将审核信息(创建、上次更新等)添加到此类。
代码示例
在此代码示例中,我们有两个有界上下文,身份管理_和_员工管理:

员工管理上下文需要来自身份管理上下文的一些(但不是全部)有关用户的信息。为此有一个 REST 端点,数据被序列化为 JSON。
在身份管理上下文中,aUser表示如下:
public class User extends AggregateRoot<UserId> {
private String userName;
private String firstName;
private String lastName;
private Instant validFrom;
private Instant validTo;
private boolean disabled;
private Instant nextPasswordChange;
private List<Password> passwordHistory;
// Getters, setters and business logic omitted
}
在员工管理上下文中,我们只需要用户 ID 和名称。用户将由 ID 唯一标识,但名称显示在 UI 中。我们显然无法更改任何用户信息,因此用户信息是不可变的。代码如下所示:
public class User implements IdentifiableDomainObject<UserId> {
private final UserId userId;
private final String firstName;
private final String lastName;
@JsonCreator // We can deserialize the incoming JSON directly into an instance of this class.
public User(String userId, String firstName, String lastName) {
// Populate fields, convert incoming userId string parameter into a UserId value object instance.
}
public String getFullName() {
return String.format("%s %s", firstName, lastName);
}
// Other getters omitted.
public boolean equals(Object o) {
// Check userId only
}
public int hashCode() {
// Calculate based on userId only
}
}
存储库
我们现在已经介绍了域模型的所有可移动对象,是时候继续讨论静态对象了。第一个静态对象是_存储库_。存储库是聚合的持久容器。保存到存储库中的任何聚合都可以在以后从那里检索,即使在系统重新启动之后也是如此。
至少,存储库应具有以下功能:
- 将聚合整体保存在某种数据存储中的能力
- 能够根据其 ID 完整地检索聚合
- 能够根据其 ID 完全删除聚合
在大多数情况下,要真正可用,存储库还需要更高级的查询方法。
在实践中,存储库是到外部数据存储(如关系数据库、NoSQL 数据库、目录服务甚至文件系统)的域感知接口。即使实际存储隐藏在存储库后面,它的存储语义通常也会泄漏并限制存储库的外观。因此,存储库通常要么是_面向集合的,要么是面向_持久_性的_。
面向集合的存储库旨在模拟内存中的对象集合。一旦将聚合添加到集合中,对其所做的任何更改都将自动保留,直到从存储库中删除聚合。换句话说,面向集合的存储库将具有诸如保存的方法add(),remove()但没有保存方法。
另一方面,面向持久性的存储库不会尝试模仿集合。相反,它充当外部持久性解决方案的外观,并包含诸如insert()、update()和delete(). 对聚合所做的任何更改都必须通过调用update()方法显式保存到存储库中。
在项目开始时正确获取存储库类型很重要,因为它们在语义上完全不同。通常,面向持久性的存储库更容易实现,并且可以与大多数现有的持久性框架一起使用。除非底层持久性框架开箱即用地支持它,否则面向集合的存储库更难实现。
代码示例
此示例演示了面向集合和面向持久性的存储库之间的区别。首先我们看一下面向集合的存储库:
public interface OrderRepository {
Optional<Order> get(OrderId id);
boolean contains(OrderID id);
void add(Order order);
void remove(Order order);
Page<Order> search(OrderSpecification specification, int offset, int size);
}
// Would be used like this:
public void doSomethingWithOrder(OrderId id) {
orderRepository.get(id).ifPresent(order -> order.doSomething());
// Changes will be automatically persisted.
}
然后是面向持久性的存储库:
public interface OrderRepository {
Optional<Order> findById(OrderId id);
boolean exists(OrderId id);
Order save(Order order);
void delete(Order order);
Page<Order> findAll(OrderSpecification specification, int offset, int size);
}
// Would be used like this:
public void doSomethingWithOrder(OrderId id) {
orderRepository.findById(id).ifPresent(order -> {
order.doSomething();
orderRepository.save(order);
});
}
关于 CQRS 的注意事项
存储库始终保存和检索完整的聚合。这意味着它们可能会非常慢,具体取决于它们的实现方式以及必须为每个聚合构建的对象图的大小。从用户体验的角度来看,这可能是有问题的,尤其是两个用例。第一个是一个小型列表,您希望在其中显示聚合列表,但仅使用一个或两个属性。当您只需要几个属性值时,就提出一个完整的对象图是浪费时间和计算资源,并且通常会导致用户体验迟缓。另一种情况是当您需要组合来自多个聚合的数据以便在列表中显示单个项目时。这可能会导致更差的性能。
只要数据集和聚合很小,性能损失可能是可以接受的,但如果到了性能根本无法接受的时候,有一个解决方案:命令查询职责分离 (CQRS)。
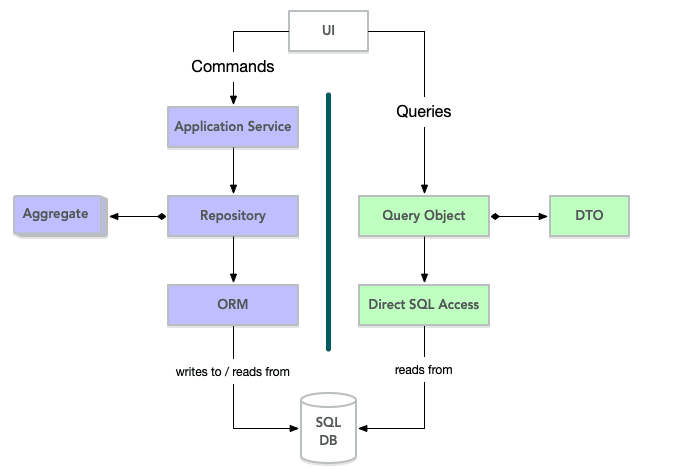
CQRS 是一种将写入(命令)和读取(查询)操作完全分离的模式。深入细节超出了本文的范围,但就 DDD 而言,您可以像这样应用模式:
- 所有改变系统状态的用户操作都以正常方式通过存储库。
- 所有查询都会绕过存储库并直接进入底层数据库,只获取需要的数据,而不获取其他数据。
- 如果需要,您甚至可以为用户界面中的每个视图设计单独的查询对象
- 查询对象返回的数据传输对象 (DTO) 必须包含聚合 ID,以便在需要对其进行更改时从存储库中检索正确的聚合。
在许多项目中,您最终可能会在某些视图中使用 CQRS,而在其他视图中使用直接存储库查询。
域服务
我们已经提到值对象和实体都可以(并且应该)包含业务逻辑。但是,在某些情况下,一段逻辑根本不适合一个特定的值对象或一个特定的实体。将业务逻辑放在错误的位置是一个坏主意,因此我们需要另一种解决方案。输入我们的第二个静态对象:域服务。
域服务具有以下特点:
- 他们是无国籍的
- 它们具有高度凝聚力(意味着它们专门做一件事且只做一件事)
- 它们包含不适合其他地方的业务逻辑
- 它们可以与其他域服务交互,并在某种程度上与存储库交互
- 他们可以发布领域事件
在最简单的形式中,域服务可以是一个带有静态方法的实用程序类。更高级的域服务可以实现为单例,其中注入了其他域服务和存储库。
不应将域服务与_应用程序服务_混淆。我们将在本系列的下一篇文章中仔细研究应用程序服务,但简而言之,应用程序服务充当隔离域模型与世界其他部分之间的中间人。应用程序服务负责处理事务、确保系统安全、查找适当的聚合、调用它们的方法并将更改保存回数据库。应用程序服务本身不包含任何业务逻辑。
您可以将应用程序和域服务之间的区别总结如下:域服务仅负责制定业务决策,而应用程序服务仅负责编排(查找正确的对象并以正确的顺序调用正确的方法)。因此,域服务通常不应调用任何改变数据库状态的存储库方法——这是应用程序服务的责任。
代码示例
在第一个示例中,我们将创建一个域服务来检查是否允许进行某个货币交易。实现大大简化,但显然是根据一些预定义的业务规则做出业务决策。
在这种情况下,由于业务逻辑非常简单,您可能已经能够将其直接添加到Account类中。然而,一旦更高级的业务规则开始发挥作用,将决策转移到自己的类中是有意义的(特别是如果规则随时间变化或依赖于某些外部配置)。另一个表明此逻辑可能属于域服务的迹象是它涉及多个聚合(两个帐户)。
public class TransactionValidator {
public boolean isValid(Money amount, Account from, Account to) {
if (!from.getCurrency().equals(amount.getCurrency())) {
return false;
}
if (!to.getCurrency().equals(amount.getCurrency())) {
return false;
}
if (from.getBalance().isLessThan(amount)) {
return false;
}
if (amount.isGreaterThan(someThreshold)) {
return false;
}
return true;
}
}
在第二个示例中,我们将研究一个具有特殊功能的域服务:它的接口是域模型的一部分,但它的实现不是。当您需要来自外部世界的信息以便在您的域模型中做出业务决策时,可能会出现这种情况,但您对这些信息的来源不感兴趣。
public interface CurrencyExchangeService {
Money convertToCurrency(Money currentAmount, Currency desiredCurrency);
}
当域模型被连接起来时,例如使用依赖注入框架,你可以注入这个接口的正确实现。您可以有一个调用本地缓存,另一个调用远程 Web 服务,第三个仅用于测试,依此类推。
工厂
我们最终看起来像的静态对象是_factory_。顾名思义,工厂负责创建新的聚合。但是,这并不意味着您需要为每个聚合创建一个新工厂。在大多数情况下,聚合根的构造函数足以设置聚合,使其处于一致状态。在以下情况下,您通常需要单独的工厂:
- 业务逻辑参与聚合的创建
- 聚合的结构和内容可能因输入数据而异
- 输入数据非常广泛,以至于需要构建器模式(或类似的东西)
- 工厂正在从一个有界上下文转换到另一个
工厂可以是聚合根类上的静态工厂方法,也可以是单独的工厂类。工厂可以与其他工厂、存储库和域服务交互,但绝不能改变数据库的状态(因此不能保存或删除)。
代码示例
在此示例中,我们将查看在两个有界上下文之间进行转换的工厂。在发货上下文中,客户_不再被称为客户,而是_发货收件人。客户 ID 仍然被存储,以便我们稍后可以在需要时将这两个概念联系在一起。
public class ShipmentRecipientFactory {
private final PostOfficeRepository postOfficeRepository;
private final StreetAddressRepository streetAddressRepository;
// Initializing constructor omitted
ShipmentRecipient createShipmentRecipient(Customer customer) {
var postOffice = postOfficeRepository.findByPostalCode(customer.postalCode());
var streetAddress = streetAddressRepository.findByPostOfficeAndName(postOffice, customer.streetAddress());
var recipient = new ShipmentRecipient(customer.fullName(), streetAddress);
recipient.associateWithCustomer(customer.id());
return recipient;
}
}
模块
几乎是时候继续下一篇文章了,但在我们离开战术领域驱动设计之前,我们还需要了解一个概念,那就是_模块_。
DDD 中的模块对应于 Java中的_包和 C# 中的__命名空间_。一个模块可以对应一个有界上下文,但通常,一个有界上下文将具有多个模块。
属于一起的类应该被分组到同一个模块中。但是,您不应该基于类的类型创建模块,而是基于从业务角度来看这些类如何适合域模型。也就是说,您不应_将_所有存储库放入一个模块中,将所有实体放入另一个模块中,等等。相反,您应该将与特定聚合或特定业务流程相关的所有类放入同一模块中。这使您的代码更容易导航,因为_属于一起并一起工作的类也一起存在_。
模块示例
这是按类型对类进行分组的模块结构示例。不要这样做:
- foo.bar.domain.model.services
AuthenticationServicePasswordEncoder
- foo.bar.domain.model。存储库
UserRepositoryRoleRepository
- foo.bar.domain.model。实体
UserRole
- foo.bar.domain.model。价值对象
UserIdRoleIdUserName
更好的方法是按进程和聚合对类进行分组。改为这样做:
- foo.bar.domain.model。验证
AuthenticationService
- foo.bar.domain.model。用户
UserUserRepositoryUserIdUserNamePasswordEncoder
- foo.bar.domain.model。角色
RoleRoleRepositoryRoleId
为什么战术领域驱动设计很重要?
就像我在本系列第一篇文章的介绍中提到的那样,我在挽救一个遭受严重数据不一致问题的项目时首先遇到了领域驱动设计。在没有任何领域模型或通用语言的情况下,我们开始将现有数据模型转换为聚合,将数据访问对象转换为存储库。由于这些引入软件的限制,我们设法摆脱了不一致的问题,最终软件可以部署到生产中。
与战术领域驱动设计的第一次接触向我证明,即使项目在所有其他方面都不是领域驱动的,您也可以从中受益。在我参与的所有项目中,我最喜欢的 DDD 构建块是_值对象_。它很容易引入并立即使代码更易于阅读和理解,因为它为您的属性带来了上下文。不变性也倾向于使复杂的事情变得更简单。
我也经常尝试将数据模型分组到聚合和存储库中,即使数据模型在其他方面完全贫乏(只有 getter 和 setter,没有任何业务逻辑)。这有助于保持数据的一致性,并避免在通过不同机制更新同一实体时出现奇怪的副作用和乐观锁定异常。
域事件对于解耦代码很有用,但这是一把双刃剑。如果您过多地依赖事件,您的代码将变得更加难以理解和调试,因为无法立即清楚特定事件将触发哪些其他操作或首先触发特定操作的事件是什么。
与其他软件设计模式一样,战术领域驱动设计为您通常遇到的一组问题提供解决方案,尤其是在构建企业软件时。您可以使用的工具越多,您就越容易解决作为软件开发人员在职业生涯中不可避免地遇到的问题。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/DDD/DDD-%E4%BA%8C%E6%88%98%E6%9C%AF%E9%A2%86%E5%9F%9F%E9%A9%B1%E5%8A%A8%E8%AE%BE%E8%AE%A1/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


