马蜂窝推荐排序算法模型是如何实现快速迭代的
Part.1 马蜂窝推荐系统架构
马蜂窝推荐系统主要由召回(Match)、排序(Rank)、重排序(Rerank)几个部分组成,整体架构图如下:
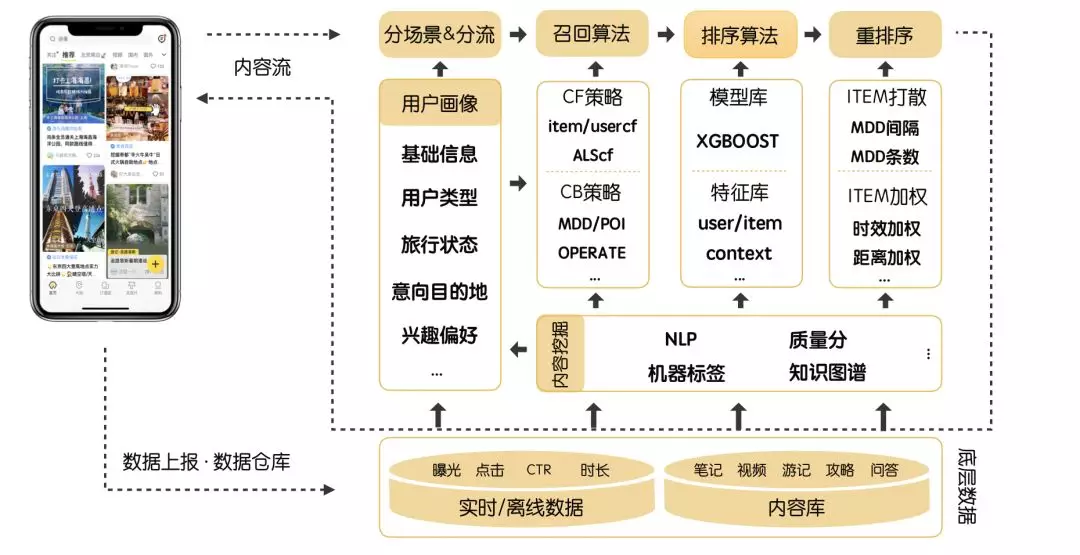
在召回阶段,系统会从海量的内容库筛选出符合用户偏好的候选集(百级、千级);排序阶段在此基础上,基于特定的优化目标(如点击率)对候选集内容进行更加精准的计算和选择,为每一条内容进行精确打分,进而从候选集的成百上千条内容中选出用户最感兴趣的少量高质量内容。
本文我们将重点介绍马蜂窝推荐系统中的核心之一——排序算法平台,它的整体架构如何;为了给用户呈现更加精准的推荐结果,在支撑模型快速、高效迭代的过程中,排序算法平台发挥了哪些作用及经历的实践。
Part.2 排序算法平台的演进
2.1 整体架构
目前,马蜂窝排序算法线上模型排序平台主要由 通用数据处理模块、可替换模型生产模块、监控与分析模块 三部分组成,各模块结构及平台整体工作流程如下图所示:
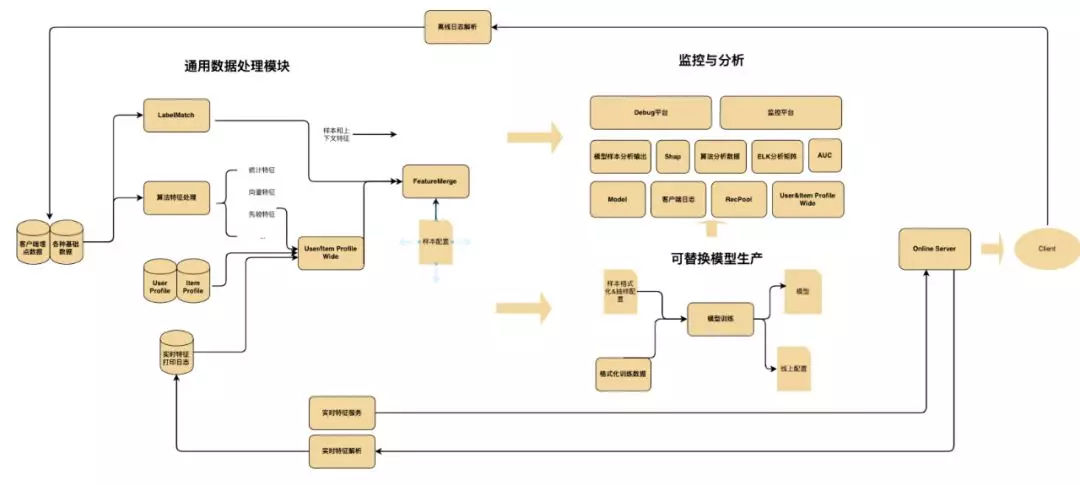
2.1.1 模块功能
(1) 通用数据处理模块
核心功能是特征建设以及训练样本的构建,也是整个排序算法最为基础和关键的部分。数据源涉及点击曝光日志、用户画像、内容画像等等,底层的数据处理依赖 Spark 离线批处理和 Flink 实时流处理。
(2) 可替换模型生产模块
主要负责训练集的构建、模型的训练以及生成线上配置,实现模型的无缝同步上线。
(3) 监控与分析模块
主要包括上游依赖数据的监控、推荐池的监控,特征的监控与分析,模型的可视化分析等功能。
各个模块的功能以及他们之间的交互使用 JSON 配置文件进行集成,使模型的训练和上线仅仅需要修改配置就能完成,极大提升了开发效率,为排序算法的快速迭代打下了坚实的基础。
2.1.2 主要配置文件类型
配置文件主要分为 TrainConfig、MergeConfig、OnlineConfig、CtrConfig 四类,其作用分别为:
(1)TrainConfig
指训练配置,主要包括训练集配置和模型配置:
-
训练集配置包括指定使用哪些特征进行训练;指定使用哪些时间段内的训练数据;指定场景、页面、和频道等
-
模型配置包括模型参数、训练集路径、测试集路径、模型保存路径等
(2)MergeConfig
指特征配置,包括上下文特征、用户特征、物品特征、交叉特征的选择。
这里,我们将交叉特征的计算方式也实现了配置化。例如用户特征中有一些向量特征,内容特征也有一些向量特征。当我们希望使用某两个向量的余弦相似度或者欧式距离作为一个交叉特征给模型使用时,这种交叉特征的选择和计算方式可以直接通过配置实现,并且同步的线上配置中供线上使用。
(3)OnlineConfig
指线上配置,训练数据构建的过程中自动生成供线上使用,包括特征的配置(上下文特征、用户特征、内容特征、交叉特征)、模型的路径、特征的版本。
(4)CtrConfig
指默认 CTR 配置,作用为针对用户和内容的 CTR 特征进行平滑处理。
2.1.3 特征工程
从应用的视角来看,特征主要包括三类,用户特征(User Feature)、内容特征(Article Feature)、上下文特征(Context Feature)。
如果按获取的方式又可以分为:
-
统计特征(Statistics Feature):包括用户、内容、特定时间段内的点击量/曝光量/CTR 等
-
向量特征(Embedding Feature):以标签、目的地等信息为基础,利用用户点击行为历史,使用 Word2Vec 训练的向量特征等;
-
交叉特征(Cross Feature):基于标签或目的地向量,构建用户向量或物品向量,从而得到用户与物品的相似度特征等
2.2 排序算法平台 V1
在排序算法平台 V1 阶段,通过简单的 JSON 文件配置,平台就能够实现特征的选择、训练集的选择、分场景 XGBoost 模型的训练、XGBoost 模型离线 AUC 的评估、生成线上配置文件自动同步上线等功能。
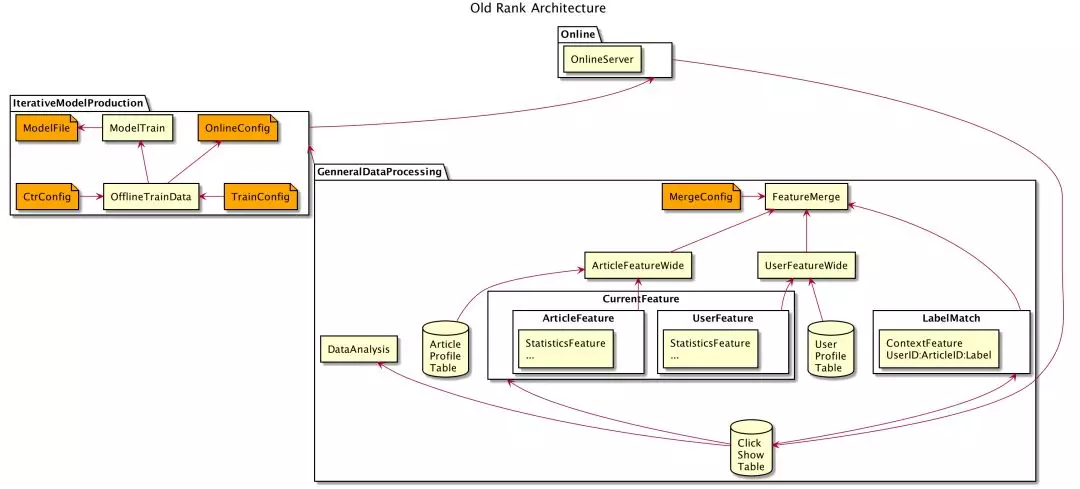
但在使用过程中,我们仍然发现了一些存在的问题:
-
模型上线效果与预期表现不一致时,很难排查和定位原因,影响模型的迭代开发
-
由于模型的不可解释性,很难建立对模型和特征的深入认识,以辅助模型的优化
2.3 排序算法平台 V2
针对上面存在的这些问题,我们在排序算法平台的监控分析模块增加了 数据验证、模型解释 的功能,帮助我们对模型的持续迭代优化提供更加科学、精准的依据。
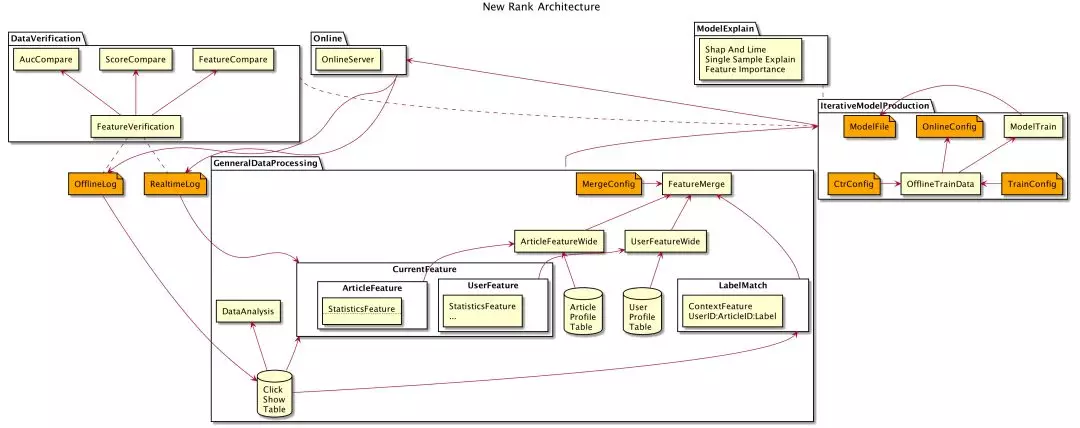
2.3.1 数据验证(DataVerification)
在算法平台 V1 阶段,当模型离线效果(AUC)表现很好,而线上效果不符合预期时,我们很难排查定位问题,影响模型迭代。
通过对问题的调查和分析我们发现,造成线上效果不符合预期的一个很重要的原因,可能是目前模型的训练集是基于数仓每天汇总的一张点击曝光表得到。由于数据上报延迟等原因,这张离线的点击曝光表中的一些上下文特征与实时的点击曝光行为可能存在误差,带来一些离线和线上特征不一致的问题。
针对这种情况,我们增加了数据验证的功能,将离线构建的训练集与线上打印的实时特征日志进行各个维度的对比分析。
具体做法就是以线上的实时点击曝光日志(包含所使用的模型、特征以及模型预测分等信息)为基础,为每条实时点击曝光记录都增加一个唯一 ID,在离线汇总的点击曝光表中也会保留这个唯一 ID。这样,针对一条点击曝光记录,我们就可以将离线构建的训练集中的特征,与线上实际使用的特征关联起来,对线上和离线模型的 AUC、线上和离线模型的预测分以及特征的情况进行对比,从而发现一些问题。
举例来说,在之前的模型迭代过程中,模型离线 AUC 很高,但是线上效果却并不理想。通过数据验证,我们首先对比了线上和离线模型 AUC 的情况,发现存在效果不一致的现象,接着对比线上和离线模型的预测分,并找到线上和离线预测分相差最大的 TopK 个样本,对它们的离线特征和线上特征进行对比分析。最后发现是由于数据上报延迟造成了一些线上和离线上下文特征的不一致,以及线上XGBoost、DMatrix 构建时选的 missingValue 参数有问题,从而导致了线上和离线模型预测分存在偏差。上述问题修复后,线上 UV 点击率提升了 16.79%,PV 点击率提升了 19.10%。
通过数据验证的功能和解决策略,我们快速定位到了问题的原因,加速算法模型迭代开发的过程,提升了线上的应用效果。
2.3.2 模型解释(ModelExplain)
模型解释可以打开机器学习模型的黑盒,增加我们对模型决策的信任,帮助理解模型决策,为改进模型提供启发。关于模型解释的一些概念,推荐给大家两篇文章来帮助理解:《Why Should I Trust You Explaining the Predictions of Any Classifier》、《A Unified Approach to Interpreting Model Predictions》。
在实际开发中,我们总是在模型的准确性与模型的可解释性之间权衡。简单的模型拥有很好的解释性,但是准确性不高;而复杂的模型提高模型准确性的同时又牺牲了模型的可解释性。使用简单的模型解释复杂的模型是当前模型解释的核心方法之一。
目前,我们线上模型排序使用的是 XGBoost 模型。但在 XGBoost 模型中,传统的基于特征重要性的模型解释方法,只能从整体上对每个特征给出一个重要性的衡量,不支持对模型的局部输出解释,或者说单样本模型输出解释。在这样的背景下,我们的模型解释模块使用了新的模型解释方法 Shap 和 Lime,不仅支持特征的重要性,也支持模型的局部解释,使我们可以了解到在单个样本中,某个特征的某个取值对模型的输出可以起到何种程度的正向或负向作用。
下面通过一个从实际场景中简化的示例来介绍模型解释的核心功能。首先介绍一下几个特征的含义:
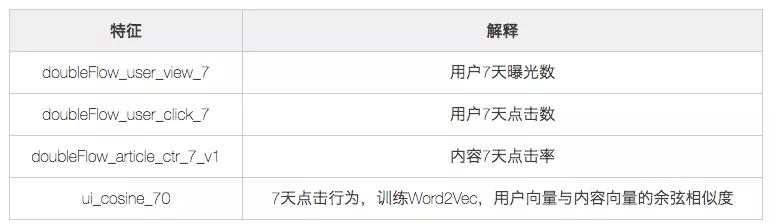

我们的模型解释会对单个样本给出以下的分析:
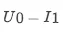

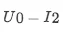

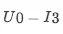

如图所示,模型对单个样本,
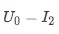 ,
,
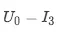 的预测值为 0.094930, 0.073473, 0.066176。针对单个样本的预测,各个特征值起到多大的正负向作用可以从图中的特征条形带的长度看出,红色代表正向作用,蓝色代表负向作用。这个值是由下表中的 shap_value 值决定的:
的预测值为 0.094930, 0.073473, 0.066176。针对单个样本的预测,各个特征值起到多大的正负向作用可以从图中的特征条形带的长度看出,红色代表正向作用,蓝色代表负向作用。这个值是由下表中的 shap_value 值决定的:
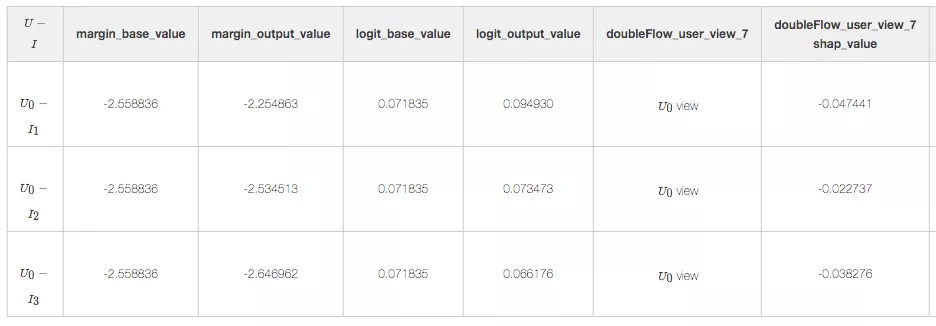

其中, logit_output_value = 1.0 / (1 + np.exp(-margin_output_value)),logit_base_value = 1.0 / (1 + np.exp(-margin_base_value)),output_value 是 XGBoost 模型输出值;base_value 是模型期望输出;近似等于整个训练集中模型预测值的均值;shap_value 是对该特征对预测结果起到的正负向作用的一个衡量。
模型预测值logit_output_value,0.094930>0.073473>0.066176,所以排序结果为 I1_>__ > I__2__> I__3,U__0-__I1 _的预测值为0.094930,特征 doubleFlow_article_ctr_7_v1= _I1 _ctr 起到了 0.062029 的正向作用,使得预测值相较于基值,有增加的趋势。同理,ui_cosine_70=0.894006,起到了 0.188769 的正向作用。
直观上我们可以看出,内容 7 天点击率以及用户-内容相似度越高,模型预测值越高,这也是符合预期的。实际场景中,我们会有更多的特征。
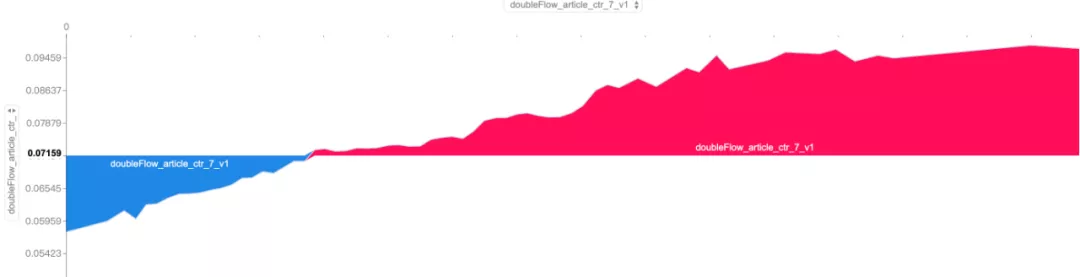
Shap 模型解释最核心的功能是支持局部单样本分析,当然它也支持全局的分析,如特征重要性,特征正负向作用,特征交互等。下图是对特征 doubleFlow_article_ctr_7_v1 的分析,可以看出,内容 7 天点击率小于阈值对模型的预测起负向作用,大于阈值对模型的预测起正向作用。
Part.3 近期规划
近期,排序算法平台将继续提升训练模型的线上应用效果,并把特征的实时作为工作重点,快速反映线上的变化。
当前排序算法平台使用的 XGBoost 模型优点是不需要太多的特征工程,包括特征缺失值处理、连续特征离散化、交叉特征构建等。但也存在许多不足,包括:
1. 很难处理高纬稀疏特征
2. 需要加载完整的数据集到内存进行模型的训练,不支持在线学习算法,很难实现模型的实时更新。
针对这些问题,后期我们将进行 Wide&Deep,DeepFM 等深度模型的建设,如下图所示:
,商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


