马蜂窝多层分流系统的设计与实现
导读:
5 月 23 日,马蜂窝旅游网宣布完成 2.5 亿美元新一轮融资,此轮融资由腾讯领投。
在接授腾讯《潜望》栏目的专访时,马蜂窝 CEO 陈罡谈到,「现在马蜂窝是个数据驱动的公司,要以结果说话,能用 ABTest 解决的问题就没有必要谈其他」。
作为一家数据驱动的公司,当前在马蜂窝 ABTest 已经基本覆盖所有业务线并稳定运行。本篇文章,我们就来说一说驱动马蜂窝快速增长和优化的 ABTest 是什么,它究竟长什么样子。
什么是 ABTest
产品的改变不是由我们随便「拍脑袋」得出,而是需要由实际的数据驱动,让用户的反馈来指导我们如何更好地改善服务。正如马蜂窝 CEO 陈罡在接受专访时所说:「有些东西是需要 Sense,但大部分东西是可以用 Science 来做判断的。」
说到 ABTest 相信很多读者都不陌生。简单来说,ABTest 就是将用户分成不同的组,,同时在线试验产品的不同版本,通过用户反馈的真实数据来找出采用哪一个版本方案更好的过程。
我们将原始版本作为对照组,以每个版本进行尽量是小的流量迭代作为原则去使用 ABTest。一旦指标分析完成,用户反馈数据表现最佳的版本再去全量上线。
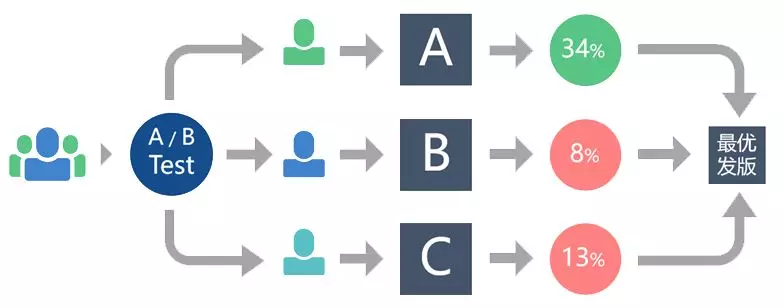
很多时候,一个按钮、一张图片或者一句文案的调整,可能都会带来非常明显的增长。这里分享一个ABTest 在马蜂窝的应用案例:
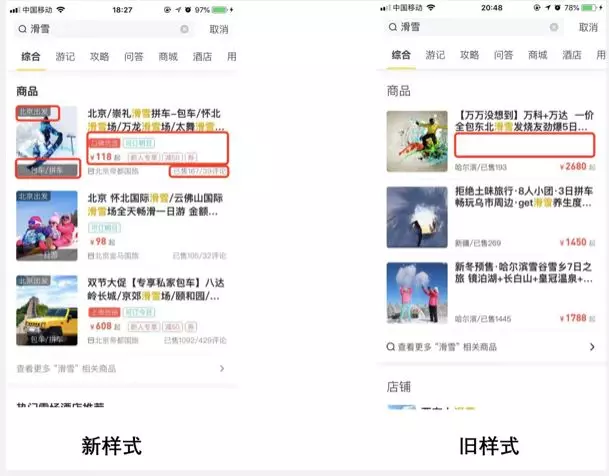
如图所示,之前我们搜索团队和电商团队希望优化一个关于「滑雪」的搜索列表。可以看到优化之前的页面显示从感觉上是比较单薄的。但是大家又不确定复杂一些的展现形式会不会让用户觉得不够简洁,产生反感。因此,我们将改版前后的页面放在线上进行了 ABTest。最终的数据反馈表明,优化之后的样式 UV 提高了 15.21%,转化率提高了 11.83%。使用 ABTest 帮助我们降低了迭代的风险。
通过这个例子,我们可以更加直观地理解 ABTest 的几个特性:
-
先验性:采用流量分割与小流量测试的方式,先让线上部分小流量用户使用,来验证我们的想法,再根据数据反馈来推广到全流量,减少产品损失。
-
并行性:我们可以同时运行两个或两个以上版本的试验同时去对比,而且保证每个版本所处的环境一致的,这样以前整个季度才能确定要不要发版的情况,现在可能只需要一周的时间,避免流程复杂和周期长的问题,节省验证时间。
-
科学性:统计试验结果的时候,ABTest 要求用统计的指标来判断这个结果是否可行,避免我们依靠经验主义去做决策。
为了让我们的验证结论更加准确、合理并且高效,我们参照 Google 的做法实现了一套算法保障机制,来严格实现流量的科学分配。
基于 Openresty 的多层分流模型
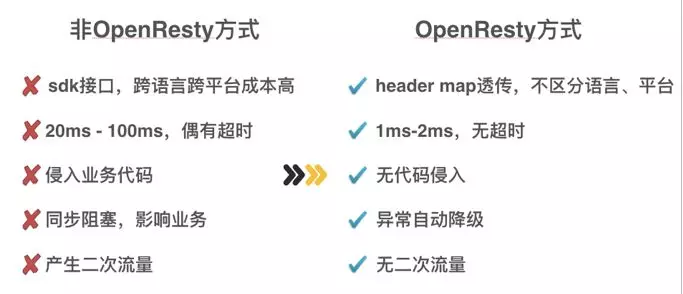
大部分公司的 ABTest 都是通过提供接口,由业务方获取用户数据然后调用接口的方式进行,这样会将原有的流量放大一倍,并且对业务侵入比较明显,支持场景较为单一,导致多业务方需求需要开发出很多分流系统,针对不同的场景也难以复用。
为了解决以上问题,我们的分流系统选择基于 Openresty 实现,通过 HTTP 或者 GRPC 协议来传递分流信息。这样一来,分流系统就工作在业务的上游,并且由于 Openresty 自带流量分发的特性不会产生二次流量。对于业务方而言,只需要提供差异化的服务即可,不会侵入到业务当中。
选型 Openresty 来做 ABTest 的原因主要有以下几个:
整体流程
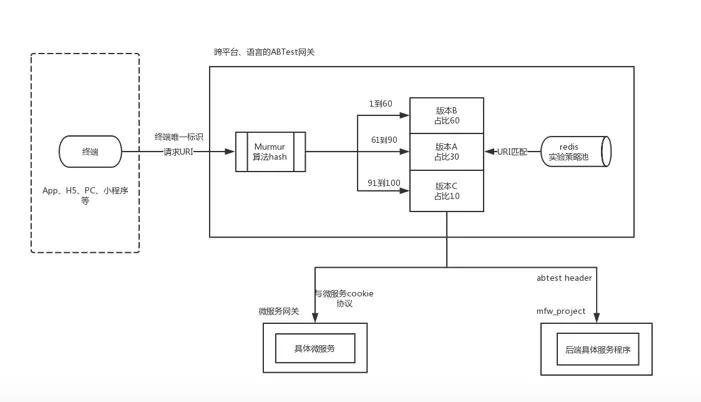
在设计 ABTest 系统的时候我们拆分出来分流三要素,第一是确定的终端,终端上包含了设备和用户信息;第二是确定的 URI ;第三是与之匹配的分配策略,也就是流量如何分配。
首先设备发起请求,AB 网关从请求中提取设备 ID 、URI 等信息,这时终端信息和 URI 信息已经确定了。然后通过 URI 信息遍历匹配到对应的策略,请求经过分流算法找到当前匹配的 AB 实验和版本后,AB 网关会通过两种方式来通知下游。针对运行在物理 web 机的应用会在 header 中添加一个名为 abtest 的 key,里面包含命中的 AB 实验和版本信息。针对微服务应用,会将命中微服务的信息添加到 Cookie 中交由微服务网关去处理。
稳定分流保障:MurmurHash算法
分流算法我们采用的 MurmurHash 算法,参与算法的 Hash 因子有设备 id、策略 id、流量层 id。
MurmurHash 是业内 ABTest 常用的一个算法,它可以应用到很多开源项目上,比如说 Redis、Memcached、Cassandra、HBase 等。MurmurHash 有两个明显的特点:
-
快,比安全散列算法快几十倍
-
变化足够激烈,对于相似字符串,比如说「abc」和「 abd 」能够均匀散布在哈希环上,主要是用来实现正交和互斥实验的分流
下面简单解释下正交和互斥:
-
互斥。指两个实验流量独立,用户只能进入其中一个实验。一般是针对于同一流量层上的实验而言,比如图文混排列表实验和纯图列表实验,同一个用户在同一时刻只能看到一个实验,所以他们互斥。
-
正交。正交是指用户进入所有的实验之间没有必然关系。比如进入实验 1 中 a 版本的用户再进行其它实验时也是均匀分布的,而不是集中在某一块区间内。
流量层内实验分流
流量层内实验的 hash 因子有设备 id、流量层 id。当请求流经一个流量层时,只会命中层内一个实验,即同一个用户同一个请求每层最多只会命中一个实验。首先对 hash 因子进行 hash 操作,采用 murmurhash2 算法,可以保证 hash 因子微小变化但是结果的值变化激烈,然后对 100 求余之后+1,最终得到 1 到 100 之间的数值。
示意图如下:
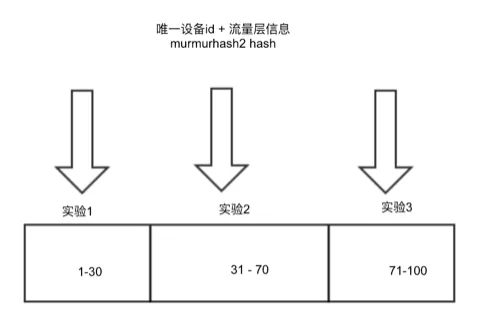
实验内版本分流
实验的 hash 因子有设备 id、策略 id、流量层 id。采用相同的策略进行版本匹配。匹配规则如下:
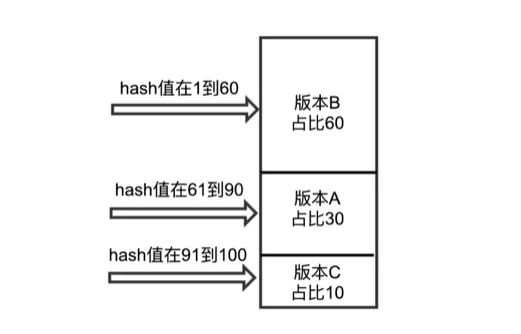
稳定性保障:多级缓存策略
刚才说到,每一个请求来临之后,系统都会尝试去获取与之匹配的实验策略。实验策略是在从后台配置的,我们通过消息队列的形式,将经过配置之后的策略,同步到我们的策略池当中。
我们最初的方案是每一个请求来临之后,都会从 Redis 当中去读取数据,这样的话对 Redis 的稳定性要求较高,大量的请求也会对 Redis 造成比较高的压力。因此,我们引入了多级缓存机制来组成策略池。策略池总共分为三层:
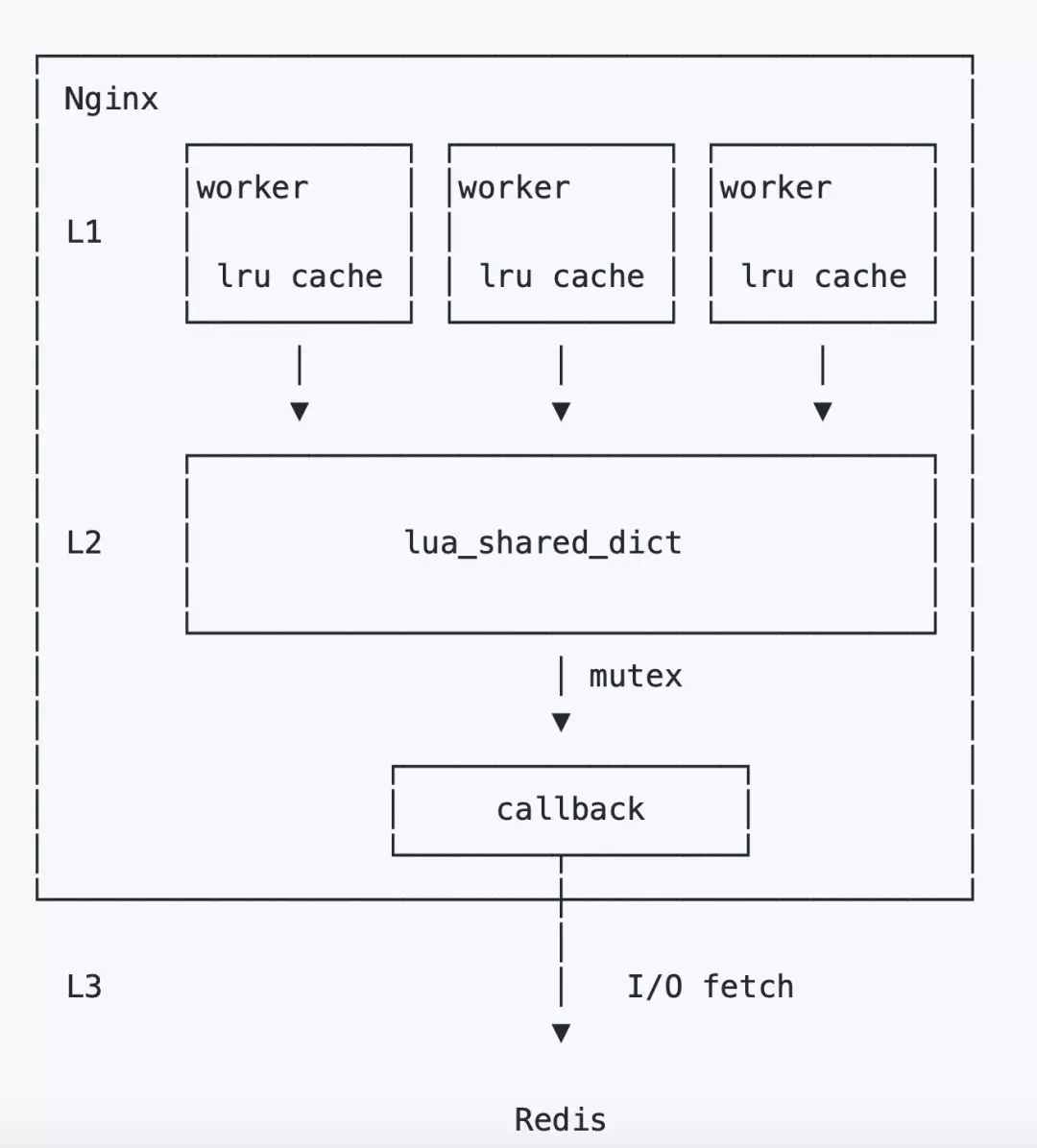
第一层 lrucache,是一个简单高效的缓存策略。它的特点是伴随着 Nginx worker 进程的生命周期存在,worker 独占,十分高效。由于独占的特性,每一份缓存都会在每个 worker 进程中存在,所以它会占用较多的内存。
第二层 lua_shared_dic t,顾名思义,这个缓存可以跨 worker 共享。当 Nginx reload 时它的数据也会不丢失,只有当 restart 的时候才会丢失。但有个特点,为了安全读写,实现了读写锁。所以再某些极端情况下可能会存在性能问题。
第三层 Redis。
从整套策略上来看,虽然采用了多级缓存,但仍然存在着一定的风险,就是当 L1�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%A9%AC%E8%9C%82%E7%AA%9D%E5%A4%9A%E5%B1%82%E5%88%86%E6%B5%81%E7%B3%BB%E7%BB%9F%E7%9A%84%E8%AE%BE%E8%AE%A1%E4%B8%8E%E5%AE%9E%E7%8E%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


