风控特征时间滑窗统计特征体系
原文作者:求是汪在路上(知乎ID)
风控业务背景
俗话说, 路遥知马力,日久见人心。在风控中也是如此,我们常从时间维度提取借款人在不同时间点的特征,以此来判断借款人的风险。在实践中,这类特征通常会占到80%以上。由于是通过时间切片和聚合统计函数来构造,因此一般被称为 时间滑窗统计特征。
本文的主要意义在于:
- 对于需要入门风控建模的同学而言,希望能帮助你快速上手特征工程。
- 对已经有特征工程经验的同学而言,希望能带给你一些风控业务理解。
目录
Part 1. 观察期、观察点及表现期
Part 2. RFM模型介绍
Part 3. 时间滑窗 数量 统计类特征
Part 4. 时间滑窗 占比 统计类特征
Part 5. 时间滑窗 趋势 统计类特征
Part 6. 时间滑窗 稳定性 衍生特征
Part 7. 第三方多头借贷变量衍生
Part 8. 总结
致谢
版权声明
参考资料
Part 1. 观察期、观察点及表现期
理解这三者的概念是风控建模前期样本准备的基础,在此简单介绍。
- 观察点(Observation Point):并非是一个具体的时间点,而是一个时间区间,表示的是客户申请贷款的时间。在该时间段申请的客户 可能 会是我们用来建模的样本 。(提示:为什么用“可能”这个描述,因为还需剔除一些强规则命中的异常样本,这部分样本将不会加入建模)
- 观察期(Observation Window):用以 构造特征X 的时间窗口。相对于观察点而言,是 历史 时间。观察期的选择依赖于用户数据的厚薄程度。通常数据越厚,可提取的信息也就越全面、可靠。
- 表现期 (Performance Window):定义 好坏标签Y 的时间窗口。相对于观察点而言,是 未来 时间。由于风险需要有一定时间窗才能表现出来,因此信贷风险具有 滞后性。表现期的长短可以通过Vintage分析和滚动率分析来确定,在此不做展开。
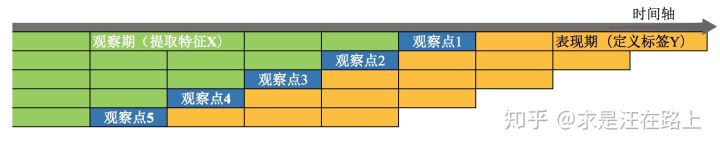
图 1 - 观察期、观察点及表现期
表现期越长,信用风险暴露将越彻底,但意味着观察期离当前将越远,用以提取样本特征的历史数据将越陈旧,建模样本和未来样本的差异也越大。反之,表现期越短,风险还未暴露完全,但好处是能用到更近的样本。
Part 2. RFM模型介绍
RFM模型最早是用来衡量客户价值和客户创利能力。理解RFM框架的思想是构造统计类特征的基础,其含义为:
- R(Recency):客户最近一次交易消费时间的间隔。R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近。
- F(Frequency):客户在最近一段时间内交易消费的次数。F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。
- M(Monetary):客户在最近一段时间内交易消费的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。
Part 3. 时间滑窗数量统计类特征
对于不同数据源,我们可以统计得到不同内容的RFM特征。例如:
- 运营商数据:用户每天的通话记录次数、时长等。
- 信用卡账单或电商交易数据:用户每天的交易笔数、金额等。
- 埋点行为数据:用户每天在某页面的浏览量、点击量等。
- 设备数据:用户每天的登陆、活跃次数。
为了扩展更多的维度,我们常会维护一个分类名单库(或 分类指标体系),可参考《 信贷风控中的名单库挖掘、使用和维护》。接下来,我们就可以继续 细分类目 来统计。例如:
- 信用卡交易数据:用户每天在母婴用品、交通出行、餐饮、美容美发等交易笔数、金额。
- 设备App数据:用户手机上安装的借贷类、生活类、运动类、音乐类等App的数量。
以设备App数据为例,我们将统计得到如下数据:
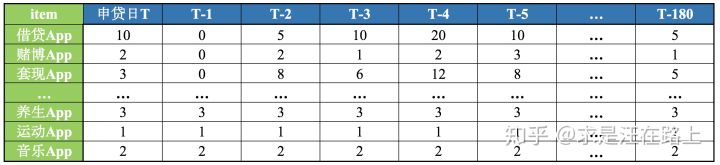
图 2 - 截止下单日,用户每天统计的App数量
需要指出的是,我们 需要结合业务去分析数据,数据因为业务才具有温度。
🌟 敲黑板划重点1——了解数据采集逻辑
特征是从原始数据中提取的信息,如果数据源采集上就存在问题,那么所构造的特征也必然有问题。
对于一些采集客观、可靠的数据源而言,分析过程就相对简单。例如,如果用户某天没有打电话,那么这天的通话次数为0,这是因为运营商客观保留了用户的原始数据。这时候, 0的含义就是用户在当天未有通话行为。当然,对于用户借用他人手机打电话这种情况,则不在考虑范围内。
对于依赖于用户登陆、活跃行为才能采集到的数据,就更需要结合采集方式来分析。例如,在设备App数据中,如果某天统计得到用户安装的借贷类App为0。这个数字后面可能有哪些原因呢?可能的猜想有:
- 1. 统计函数原理:用户这一天并没有使用手机,导致数据采集上缺失。但SQL中count()函数在统计时会count(null) = 0,也就是说会将缺失值填充默认值为0。
- 2. 用户使用行为:用户使用了 新安卓手机,数据采集正常,但确实没安装借贷类App,因此用户维度统计值为0。或者,用户使用了 老安卓手机,但主动卸载了所有借贷类App。
- 3. 数据采集技术:用户使用了**苹果手机,**由于无法采集到App数据,哪怕手机上实际安装了借贷App,但统计值也为0。
- 4. 变量构造逻辑:虽然手机上安装了借贷类App,但并不在你的借贷App名单库中,因此匹配数为0。
那么到底是哪种原因呢?对于这些猜想,我们可以从以下维度加以佐证:
- 用户当天是否活跃?
- 用户使用设备是否出现新的UMID(设备ID)?
- 用户使用设备的平台(iOS / Android)?
- 名单库是否很久没有维护?
这也就是需要 结合业务经验对多个特征交叉衍生新特征 的原因,这种特征具有强业务含义,因此往往能发挥出更好的效果。
🌟 敲黑板划重点2——定义观察期有效性
我们还需 考虑观察期的有效性,以及不同用户的数据厚薄程度。
比如,如果一个用户手机号网龄才6个月,那么在统计最近6个月、12个月、24个月的通话记录次数时,可想而知这几个变量的数值都是一样的。
同理,对于手机号网龄分别是6个月的新用户和6年的老用户而言,“最近12个月的通话记录次数”这种特征是 不公平(unfair) 的。两者的 数据厚薄程度 不同,新用户的观察期实际上只有6个月,而老用户的观察期是12个月。
为了区分这种情况,有以下建议:
1. 定义观察期有效性, 在时间滑窗统计时,更需要有意识地留出有效的观察期。
2. 定义分群变量。比如将数据有效期只有6个月和12个月的用户分成2个群体。
Part 4. 时间滑窗占比统计类特征
在得到数量统计类特征后,我们继续衍生 占比(ratio)类特征,一方面可用来去除量纲影响,另一方面 衡量用户的行为偏好。例如:
最近N个月内 母婴类 消费次数 占比 = 最近N个月内 母婴类 消费 次数 / 最近N个月内消费次数
如果用户在某类消�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%A3%8E%E6%8E%A7%E7%89%B9%E5%BE%81%E6%97%B6%E9%97%B4%E6%BB%91%E7%AA%97%E7%BB%9F%E8%AE%A1%E7%89%B9%E5%BE%81%E4%BD%93%E7%B3%BB/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


