音乐排序模型优化

分享嘉宾:Glad 腾讯音乐 高级算法工程师
编辑整理:韩晓婷 北京大学
出品平台:DataFunTalk
导读: 今天和大家分享一下QQ音乐的排序模型优化之路,包括QQ音乐推荐业务的发展背景,遇到的问题和解决方案,以及对未来的展望。
将会围绕下面五点展开:
- 背景介绍
- 用户感知模型
- 助力音乐生态
- 多品类流量探索
- 总结与展望
01 背景介绍

近年来我们音乐推荐业务的发展主要经历了以下阶段。
最初一名用户来到QQ音乐,想听点新鲜的歌曲,第一反应是找个性电台、每日30首或者歌单,这些也是我们的一些品牌产品。因此我们排序模型的目标就是在这些产品上帮助用户发现更好的音乐。
接下来随着我们的品牌产品做得越来越好,同时QQ音乐发展壮大,关注了音乐人的生态,提出了音乐人亿元激励计划,推荐业务随之也要对原生的音乐人长尾内容进行扶持,但这里排序模型一般只负责为用户推荐更好的音乐,怎么和扶持成为内容拉上关系,这就是我们这次分享需要探讨的一个问题。
到了后来,QQ音乐为了满足用户更多的音乐品类的需求,建设了很多相关产品,比如视频、长音频还有直播等等,这么多丰富的品类,不可能全部在首页展示,那么为用户推荐一些喜好的音乐品类,同时为平台带来更大的流量收益,是我们需要探索的一个方向。
这三个阶段就对应了后面的三个章节。
02 用户感知模型
首先介绍一下QQ音乐排序模型是如何帮助用户发现更好的音乐的。
先给大家分享一个故事,我的一个朋友打开QQ音乐,点开每日30首,选了一首听完之后感觉不错,就收藏了以后再听。听下一首不太行,切掉。再下一首,这首歌我好久都没听到了,QQ音乐也太懂我了!其实通过我这位朋友的故事,可以看到,QQ音乐里面用户听歌行为是非常丰富多样的,不同的行为代表着用户对歌曲不同的喜好程度。
排序模型的目标就是充分理解用户复杂多样的行为,帮助用户发现更好的音乐。
1. 优化排序方法
不同的行为样本量是不一样的,比如收藏和分享的行为样本量就很少。如果使用传统的PS模型,对这两种行为就会学习不充分。传统的最直接的解决方法是根据样本量的比例进行过采样,或者设计超参,影响这些不同行为的样本权重。这两种方法都意味着训练样本不符合真实的分布,影响最终的推荐效果。
因此,我们在第一阶段选择了优化排序方法。
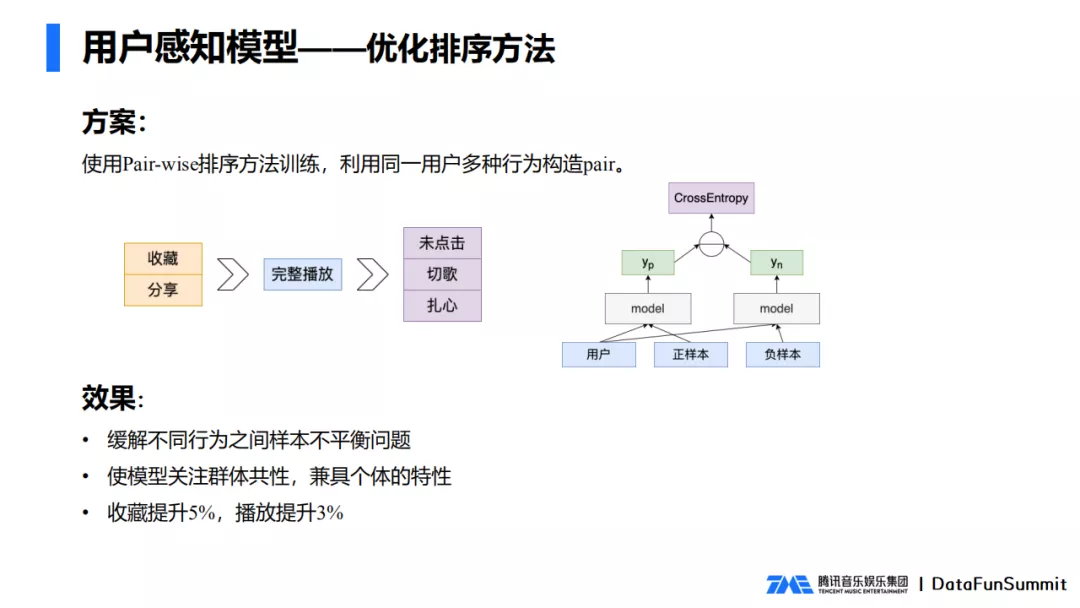
我们使用Pair-wise排序方法进行训练,利用同一个用户多种行为构造pair。比如收藏、分享就应该大于完整播放,再大于一些未点击、切歌、扎心等行为。
最终我们既缓解了不同行为之间样本的不平衡问题,又使得模型在关注群体共性的同时兼具个体特性。最终带来了收藏和播放的双重提升。
2. 优化模型结构
我们如何根据用户属性、语种偏好、历史行为和当前场景等等,帮助用户发现感兴趣的音乐呢?
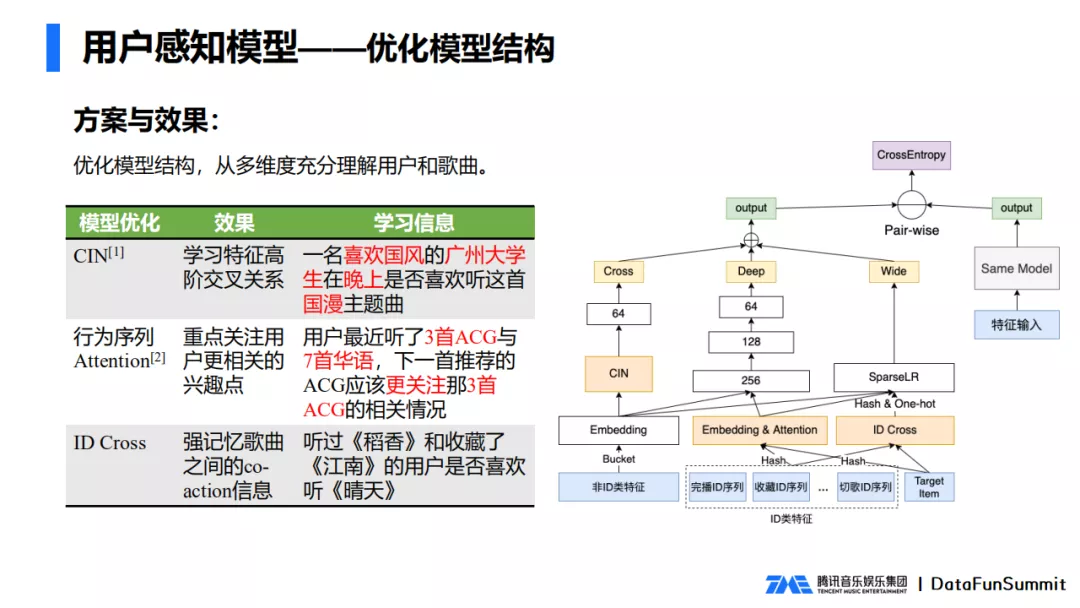
我们参考了业界和学界的一些成功经验,结合QQ音乐实际场景,优化了模型结构,从多维度充分理解用户和歌曲。
模型的输入主要包含了用户和歌曲的基础信息,统计特征,上下文信息和用户多个行为域的ID序列,将用户多种行为序列分开,以此让模型对用户的正向和负向行为有充分的刻画。比如收藏和分享就是明显的正向行为。
模型经过三个模块进行学习,每个模块都从不同的角度去理解用户和歌曲。
- CIN模块, 主要是学习了特征之间的高阶交叉关系。他最终就可以知道一名喜欢国风的广州大学生在网上是否喜欢听这首国漫的主题曲。
- 行为attention模块, 重点关注了用户行为历史中更相关的一些兴趣点,比如用户最近听了3首ACG和7首华语,下一首推了ACG,那就应该更关注那3首ACG的相关情况。
- ID Cross模块 ,是对用户历史行为中的歌曲序列和待排序的歌曲ID进行两两交叉,然后强记忆歌曲之间的co-action信息。学习出经过稻香,还有收藏过江南的用户,是否喜欢听晴天。
通过这一系列的模型结构的优化,我们对用户的行为理解更加深入,就可以在各个维度帮助用户发现更好的音乐。
3. 优化学习目标
在下一个阶段,我们发现了前面说到的一些Pair-wise模型会有以下两个问题:
- 第一个就是人为构造行为之间的关系,忽略了不同用户之间的差别;
- 第二个问题就是所有行为共同share一个模型,样本少的一些行为学习仍然是不够充分的。这就会导致模型无法准确地预测这些行为,为用户推荐意料之外的一些音乐,最终容易缺乏惊喜感。
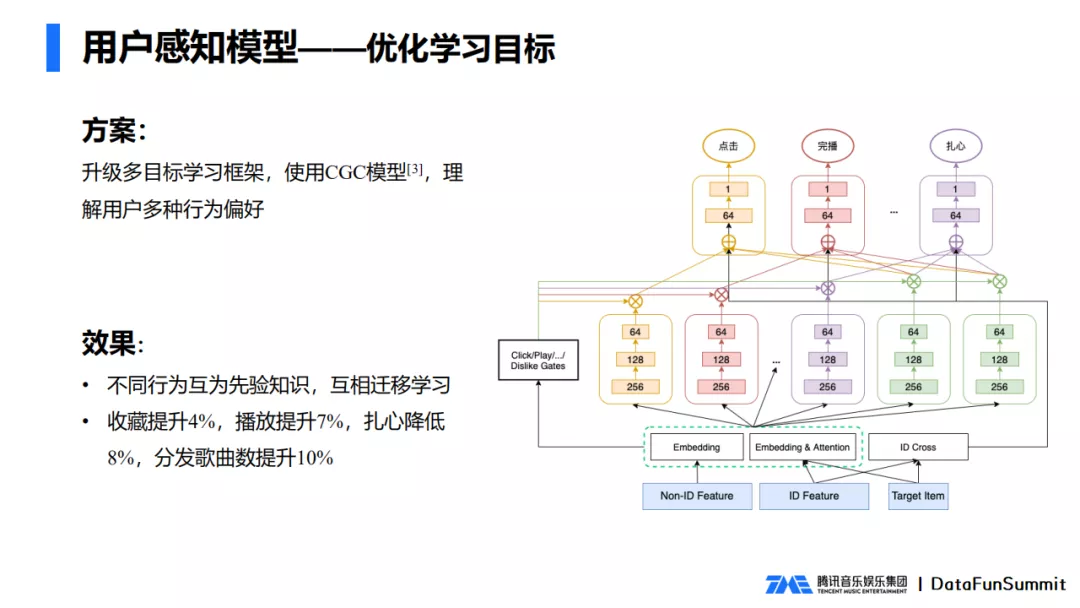
针对这两个问题,我们的排序模型升级到多目标的学习框架,主要使用的是CGC模型。每一种行为都是一个预测目标,不同行为之间既有共享的一些信息,也有一些独立的信息,充分理解用户多种行为偏好。
最终不同行为之间互为先验知识,互相迁移学习。为从来没有收藏行为但有播放行为的用户,推荐更可能收藏的音乐,他就会很有惊喜感,真正做到帮助用户发现更好的音乐。
多目标学习框架极大地优化了我们推荐的用户体验,播放和收藏有明显的提升,扎心也明显下降,分发歌曲数提升了10%。
通过上述多个阶段的优化,QQ音乐排序模型对用户丰富多样的行为有了充分的理解,最终帮助用户发现更好的音乐,也带来了平台流量的极大提升。
03 助力音乐生态
接下来介绍QQ音乐排序模型如何扶持原生长尾内容。
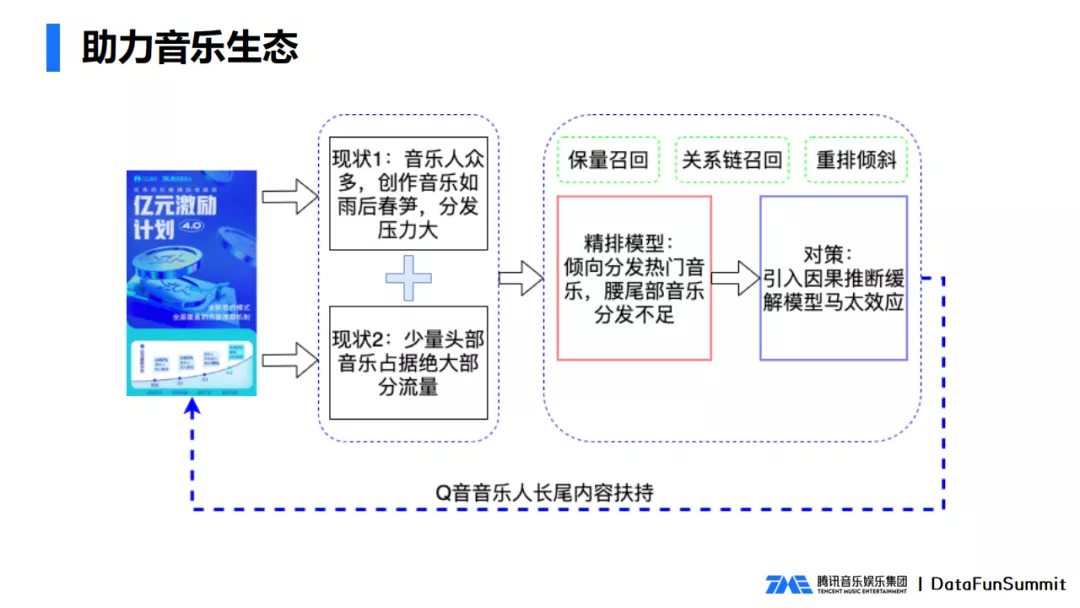
为了鼓励音乐人更好地创作歌曲,我们提出了音乐人亿元激励计划,鼓励音乐人在我们平台发歌,给一些金钱上的支持。推荐业务团队同样也要履行平台的责任,帮助扶持原生的长尾内容,助力音乐生态。
当时最大的矛盾就是音乐人和原创的作品如雨后春笋一般涌现,而少数头部的音乐又占据了绝大部分的流量。推荐业务团队通过多种方法去扶持长尾内容,比如保量召回、关系链召回、重排倾斜等等,这些工作都是在召回层和重排层,而不是在排序层。
一般认为排序模型只负责为用户推荐更好的音乐,如何扶持长尾内容呢?我们把排序模型扶持长尾内容的问题转化成了缓解马太效应的问题。
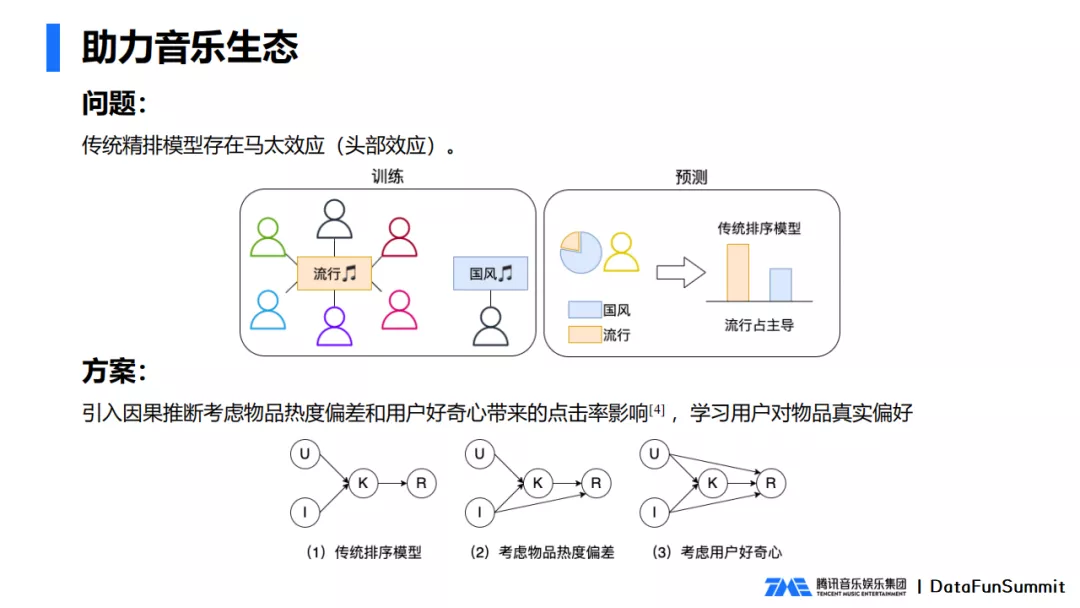
我们来看一下传统金牌模型中的马太效应究竟是如何形成的,如上图例子,在训练的过程中,样本里面有比较多的用户喜欢听流行音乐,而比较少的用户喜欢听国风音乐,传统的排序模型就会学习到大家更喜欢听流行音乐这个结论。在预测的过程中,有一名用户他主要听国风,也喜欢听流行音乐,传统排序模型就因为他学到了大家都喜欢听流行音乐这个结论,而推更多的流行音乐给到这名用户,忽略了用户本身的一些国风偏好,这就形成了马太效应。
为了解决这个问题,我们引入了因果推断,消除了物品热度的偏差和用户好奇心对点击率带来的影响,让排序模型学习出用户对物品的真实偏好。
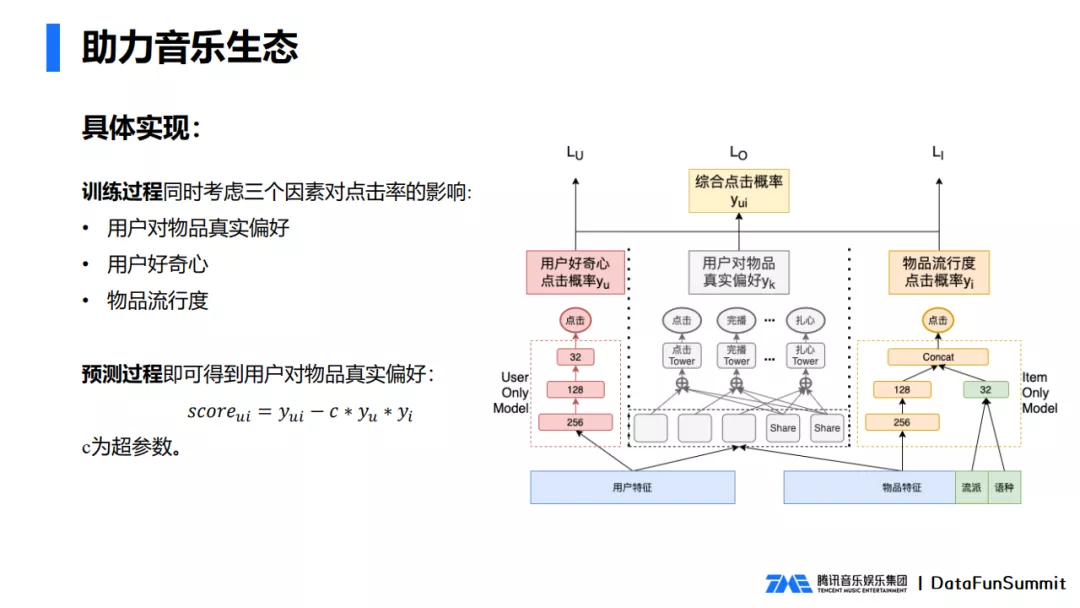
具体的模型如图所示,除了中间部分前面我们提到的多目标学习框架预测了用户对物品的点击率以外,两边分别加入了user only model和item only model,只输入用户特征和只输入物品特征,分别预测了用户好奇心和物品热度对最终点击率的影响。模型在训练过程中同时考虑这三个因素对点击率的影响,那么在预测的过程中就可以减去用户好奇心和物品热度影响,得到用户对物品的真实偏好,排除了马太效应的影响。
最终通过引入因果推断,既缓解了传统模型的马太效应,达到扶持长尾内容的效果,分发有极大的提升,又进一步地理解了用户的偏好,优化了推荐的体验,使得用户的收藏率也提升明显。
04 多品类流量探索
到了下一个阶段,随着QQ音乐的发展,为了满足用户更多的音乐品类诉求,QQ音乐建设了很多新的音乐品类,比如视频、长音频、直播等。这么多的音乐品类,如何更好地推荐给用户,同时实现平台的更大的流量价值,这就是我们最后要探讨的问题。
音乐品类日益增多,我们主要面临两个问题:
- 第一个问题,品类碎片化,不同品类之间缺乏一些协同的信息。举个例子,一个主要听个性电台,但从来没有听长音频的用户,无法被推荐到感兴趣的长音频内容。
- 第二个问题就是首页样式的固定。首页只有个性电台、每日30首和歌单,这一方面会导致喜欢长音频的用户需要往下拉才能找到长音频模块,另外导致长音频这种能留住用户更长时间、有更大的业务价值的模块,没有办法获得更多的用户。因此首页样式的固定,既浪费了流量,又没有触达到用户。
针对上述两个问题,我们采取了以下解决方案:
- 第一是 跨领域推荐 ,以用户为中心,对各个品类之间的信息进行迁移,学习联通各个品类之间的信息。
- 第二,我们建设了 模块个性化 体系,尊重用户消费投票的同时,探索品类更大的收益。
1. 跨领域推荐
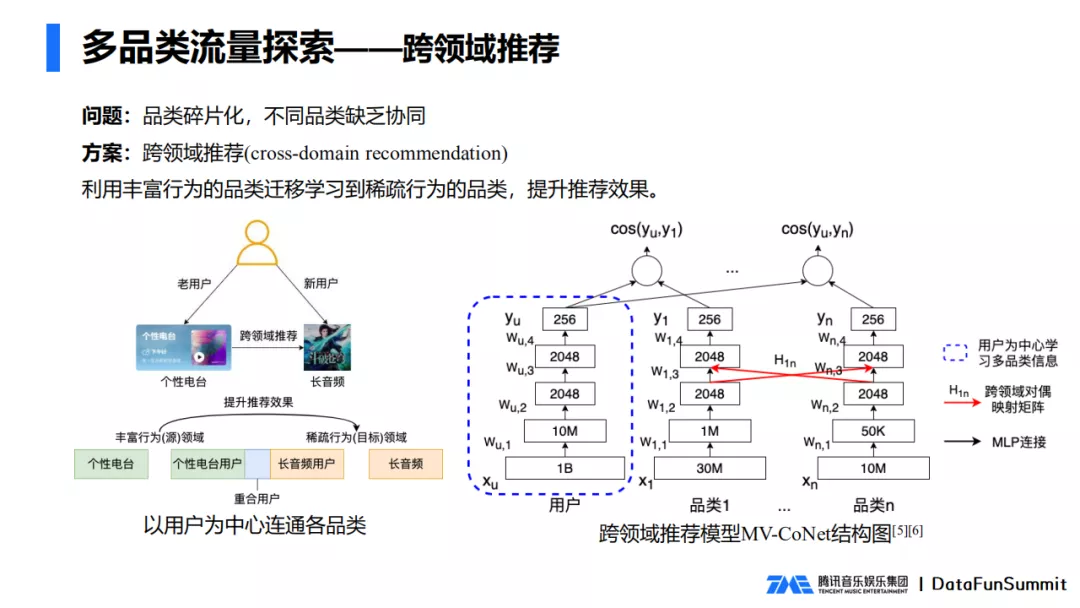
跨领域推荐的工作就是我们以用户为中心,联通各个品类,将丰富行为的品类信息迁移学习到稀疏行为的品类。比如个性电台学习到的信息迁移到长音频,帮助长音频为用户推荐更好的内容。
我们主要参考业界广泛使用的MDN模型,并且在此基础上新增品类之间的对偶映射矩阵,得到的MV-CoNet模型。模型以用户为中心,使用DSSM模型框架,每个品类就是一个塔,所有的品类共享用户的信息,分别学习用户对各个品类的偏好。除此以外,品类两两之间会连接一个对偶映射矩阵,刻画了品类之间的关系,达到迁移学习的效果。
最终通过跨领域推荐,稀疏行为的品类也能向用户推荐更感兴趣的内容,帮助用户探索更多的音乐品类,提升了用户在平台内整体的粘性。
2. 模块个性化
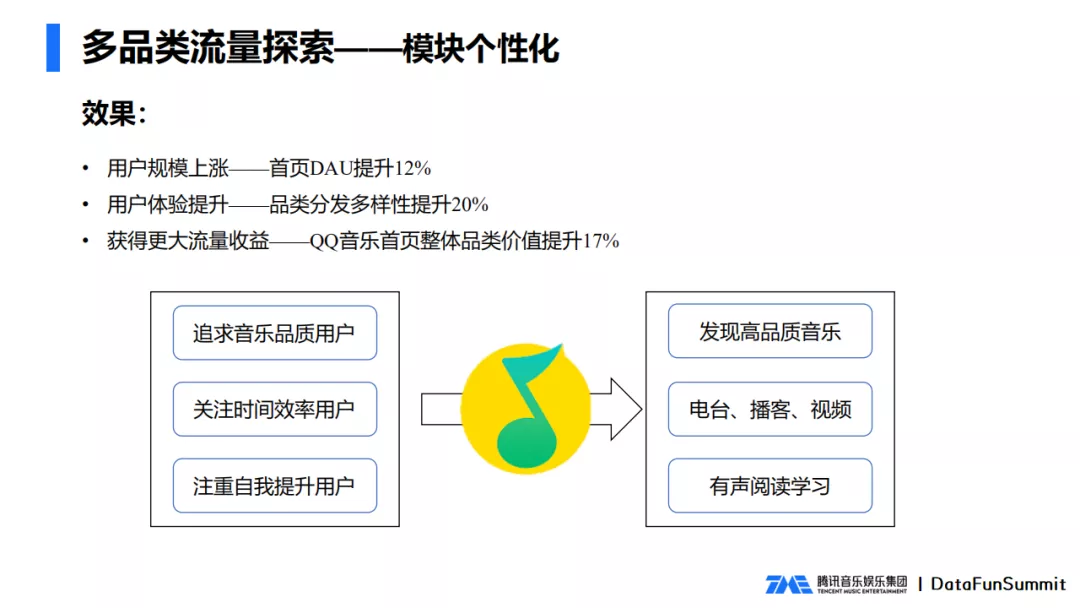
前面说到了,首页样式的固定会导致流量效率低,并且用户无法直接触达到喜好的品类,那么我们就让用户喜好的品类出现在首页,提升用户的体验,扩大消费的规模,同时也要把更大价值的品类往前放,以获取整个平台的更大的流量收入。
为了实现上述目标,我们设计了模块个性化架构,同时我们在评估指标里面兼顾了用户数还有品类价值。具体的方案如下所示。
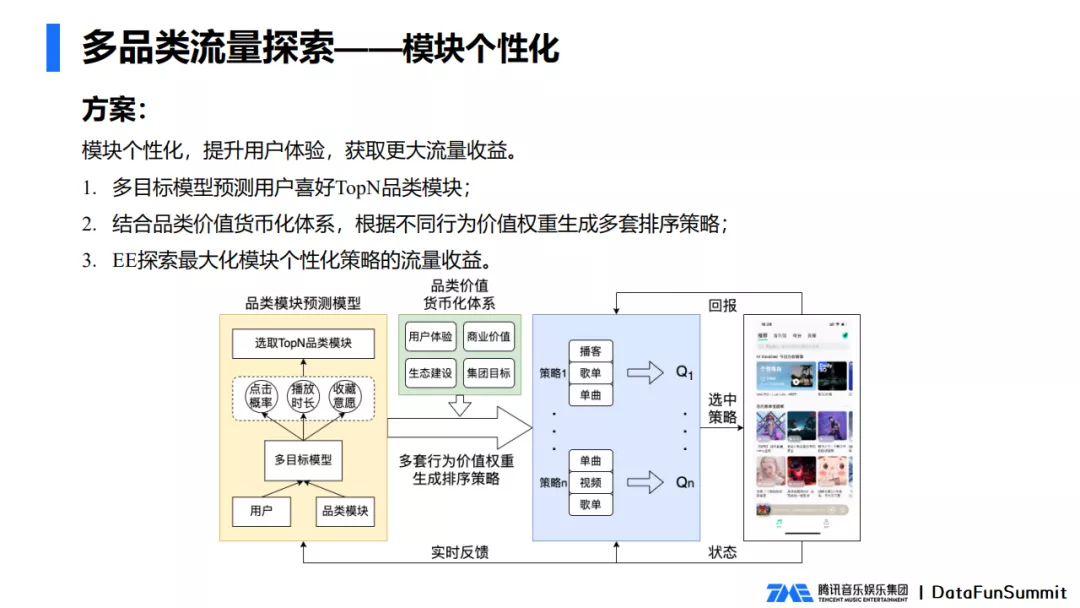
首先我们利用多目标模型预测出用户的TopN喜好品类,然后结合品类价值货币化体系生成多套排序策略。品类价值货币化体系是评估哪些品类对平台更有价值,比如长音频一方面很好地补充音频内容的核心竞争力,另一方面又很能提高用户停留时长和粘性,所以长音频的品类价值就很高。
最后,我们根据生成的多套排序策略,进行EE探索最大化个性化策略的流量收益。
通过这样的品类个性化架构,我们兼顾了用户的体验和品类的价值,带来了DAU品类分发多样性和品类价值的明显提升,为建设更良好的QQ音乐品类生态提供了帮助。现在无论是追求音乐品质的用户,关注时间效率的用户,还是注重自我提升的用户,都能在QQ音乐推荐首页快速找到对应的内容。
05 总结与展望
最后,我们总结一下今天介绍的内容。
随着QQ音乐的发展,推荐业务承担了越来越多的责任。一开始我们专注帮助用户发现更好的音乐,从多个方面优化模型结构,多维度理解用户丰富多样的行为。
后来,QQ音乐提出了亿元激励计划排序模型,扶持原生长尾内容。我们把这个问题转化成缓解马太效应问题,引入因果推断,既扶持了长尾内容,又进一步挖掘了用户的真实兴趣。
目前,随着音乐品类的不断丰富,我们探索流量的最大收益,通过跨领域推荐联通各个品类的信息,为用户推荐更好的内容,同时提出了模块个性化的框架,兼顾用户的体验和流量收入。
我们深知以上说的几个方向,还有很多值得优化的地方。我们会进一步优化模块的结构,更好地帮助用户发现音乐。进一步优化因果推断,消除模型中更多的bias,进一步挖掘用户感兴趣的音乐。我们也会继续优化跨领域推荐的技术,使用DQN等一些强化学习,持续优化流量效率。
最后,希望和大家互相交流,共同学习,一起为这些难题找到更好的解决方案。
06 精彩问答
Q1: 品类分发多样性跟品类价值是如何计算的?
A: 固定每天三首个性电台还有歌单,以此为base,如果我们分发更多的品类且每个用户分发不同的品类,我们综合平均一下就可以得到多样性的权衡评估指标,两两之间的相似;长音频帮助我们留住用户更多的时间,我们就说它品类价值最大。
Q2:“扎心”这个目标线上如何生效的?
A:把这一部分预测的权重减掉,不推荐更容易“扎心”的内容,“扎心”这个目标更多的是帮助迁移学习,让目标之间学到共同的信息还有独立的信息,帮助模型为用户推荐一些更有惊喜感的内容。
Q3:跨领域参考哪些论文
A:参见下图

Q4:排序中多样性是如何实现的?
A:分两个阶段做,第一阶段通过重排,比如业界广泛应用的MMR,DPP等手段,结合前面召回训练出的音乐Embedding,再结合一些重排算法,就可以提升整体多样性;在精排模型的部分,离线是有一个训练的模型,专门针对列表的整体进行预测,由于线上的复杂性,我们通过离线预测把信息导到线上,结合起来去做预测,而不是线上实时预测的。
Q5:如果用户对同类或者同标签内容表现出扎心收藏两种相反的行为特征,这种情况我们以后推荐会用什么样的策略?
A:我们现在模型其实更多是大规模ID,一首歌或者一个用户,就是一个很明显的特征或样本,这样其实很难同时存在“扎心”和“收藏”,但比如说一个用户既喜欢国语流行,又不喜欢某一部分国语流行,这样就通过我们的用户画像构建去识别用户,对每一类用户下面的细分标签进行区分。
Q6:多目标模型使用的特征和单目标模型使用的特征是否有差异?
A:刚进行多目标升级框架的时候,整个特征是往后�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%9F%B3%E4%B9%90%E6%8E%92%E5%BA%8F%E6%A8%A1%E5%9E%8B%E4%BC%98%E5%8C%96/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


