零基础入门数据挖掘特征工程实战
作者:吴忠强,Datawhale 优秀学习者
系列文章:
摘要:对于数据挖掘项目,本文将学习应该从哪些角度做特征工程?从哪些角度做数据清洗,如何对特征进行增删,如何使用 PCA 降维技术等。
特征工程(Feature Engineering)对特征进行进一步分析,并对数据进行处理。常见的特征工程包括:异常值处理、缺失值处理、数据分桶、特征处理、特征构造、特征筛选及降维等。
数据及背景
https://tianchi.aliyun.com/competition/entrance/231784/information(阿里天池-零基础入门数据挖掘)
异常值处理
常用的异常值处理操作包括 BOX-COX 转换(处理有偏分布),箱线图分析删除异常值, 长尾截断等方式, 当然这些操作一般都是处理数值型的数据。
BOX-COX 转换
关于 box-cox 转换,一般是用于连续的变量不满足正态的时候,在做线性回归的过程中,一般线性模型假定:
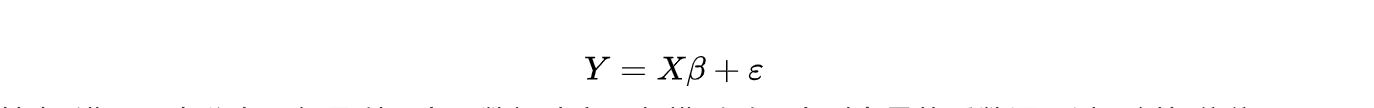
其中ε满足正态分布,但是利用实际数据建立回归模型时,个别变量的系数通不过。例如往往不可观测的误差 ε 可能是和预测变量相关的,不服从正态分布,于是给线性回归的最小二乘估计系数的结果带来误差,为了使模型满足线性性、独立性、方差齐性以及正态性,需改变数据形式,故应用 BOX-COX 转换。具体详情这里不做过多介绍,当然还有很多转换非正态数据分布的方式:
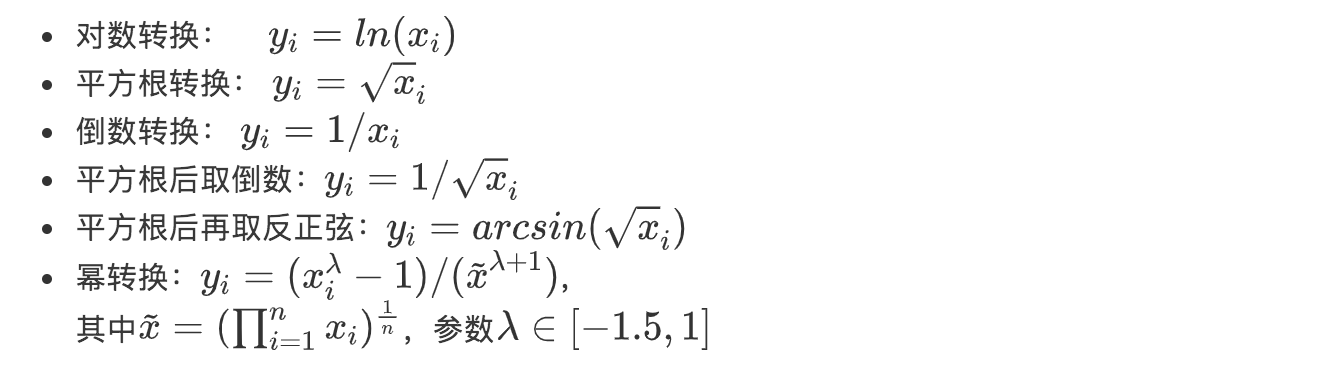
在一些情况下(P 值 <0.003)上述方法很难实现正态化处理,所以优先使用 BOX-COX 转换,但是当 P 值 >0.003 时两种方法均可,优先考虑普通的平方变换。
BOX-COX 的变换公式:
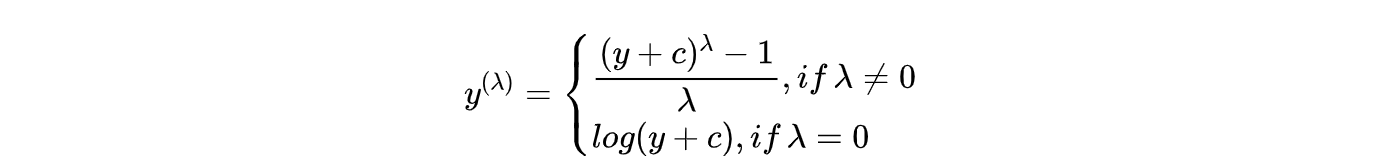
具体实现:
from scipy.stats import boxcoxboxcox_transformed_data = boxcox(original_data)
箱线图
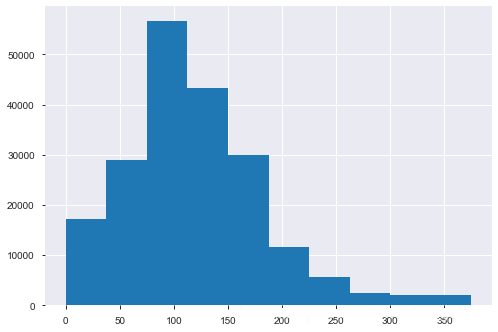
接下来,介绍一下箱线图筛选异常并进行截尾。从上面的探索中发现,某些数值型字段有异常点,可以看一下 power 这个字段:
# power 属性是有异常点的 num_data.boxplot(['power'])
结果如下:
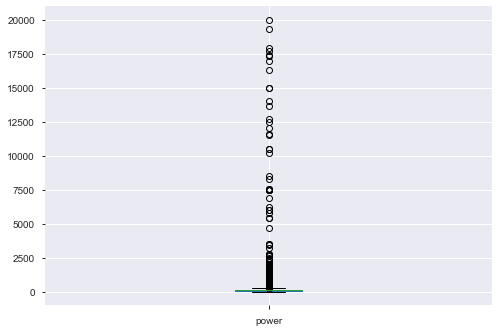
所以,下面用箱线图去捕获异常,然后进行截尾, 这里不用删除,其原因为:
- 笔者已经合并了训练集和测试集,若删除的话,肯定会删除测试集的数据
- 删除有时候会改变数据的分布等
所以这里考虑使用截尾的方式:
"""这里包装了一个异常值处理的代码,可以随便调用"""
def outliers_proc(data, col_name, scale=3):
"""
用于截尾异常值, 默认用 box_plot(scale=3)进行清洗
param:
data:接收 pandas 数据格式
col_name: pandas 列名
scale: 尺度
"""
data_col = data[col_name]
Q1 = data_col.quantile(0.25) # 0.25 分位数
Q3 = data_col.quantile(0.75) # 0,75 分位数
IQR = Q3 - Q1
data_col[data_col < Q1 - (scale * IQR)] = Q1 - (scale * IQR)
data_col[data_col > Q3 + (scale * IQR)] = Q3 + (scale * IQR)
return data[col_name]
num_data['power'] = outliers_proc(num_data, 'power')
再看一下数据:

当然,如果想删除这些异常点,可参考下列代码:
def outliers_proc(data, col_name, scale=3):
"""
用于清洗异常值,默认用 box_plot(scale=3)进行清洗
:param data: 接收 pandas 数据格式
:param col_name: pandas 列名
:param scale: 尺度
:return:
"""
def box_plot_outliers(data_ser, box_scale):
"""
利用箱线图去除异常值
:param data_ser: 接收 pandas.Series 数据格式
:param box_scale: 箱线图尺度,
:return:
"""
iqr = box_scale * (data_ser.quantile(0.75) - data_ser.quantile(0.25))
val_low = data_ser.quantile(0.25) - iqr
val_up = data_ser.quantile(0.75) + iqr
rule_low = (data_ser < val_loW)
rule_up = (data_ser > val_up)
return (rule_low, rule_up), (val_low, val_up)
data_n = data.copy()
data_series = data_n[col_name]
rule, value = box_plot_outliers(data_series, box_scale=scale)
index = np.arange(data_series.shape[0])[rule[0] | rule[1]]
print("Delete number is: {}".format(len(index)))
data_n = data_n.drop(index)
data_n.reset_index(drop=True, inplace=True)
print("Now column number is: {}".format(data_n.shape[0]))
index_low = np.arange(data_series.shape[0])[rule[0]]
outliers = data_series.iloc[index_low]
print("Description of data less than the lower bound is:")
print(pd.Series(outliers).describe())
index_up = np.arange(data_series.shape[0])[rule[1]]
outliers = data_series.iloc[index_up]
print("Description of data larger than the upper bound is:")
print(pd.Series(outliers).describe())
fig, ax = plt.subplots(1, 2, figsize=(10, 7))
sns.boxplot(y=data[col_name], data=data, palette="Set1", ax=ax[0])
sns.boxplot(y=data_n[col_name], data=data_n, palette="Set1", ax=ax[1])
return data_n
这个代码是直接删除数据,这个如果要使用,不要对测试集用哈。下面看看 power 这个特征的分布也不错了,所以就没再进一步处理 power,至于其他的数值型是不是需要截尾,需要自己决策。
缺失值处理
关于缺失值处理的方式, 有几种情况:
- 不处理(这是针对 xgboost 等树模型),有些模型有处理缺失的机制,所以可以不处理
- 如果缺失的太多,可以考虑删除该列
- 插值补全(均值,中位数,众数,建模预测,多重插补等)
- 分箱处理,缺失值一个箱。
下面整理几种填充值的方式:
# 删除重复值
data.drop_duplicates()
# dropna()可以直接删除缺失样本,但是有点不太好
# 填充固定值
train_data.fillna(0, inplace=True) # 填充 0
data.fillna({0:1000, 1:100, 2:0, 4:5}) # 可以使用字典的形式为不用列设定不同的填充值
train_data.fillna(train_data.mean(),inplace=True) # 填充均值
train_data.fillna(train_data.median(),inplace=True) # 填充中位数
train_data.fillna(train_data.mode(),inplace=True) # 填充众数
train_data.fillna(method='pad', inplace=True) # 填充前一条数据的值,但是前一条也不一定有值
train_data.fillna(method='bfill', inplace=True) # 填充后一条数据的值,但是后一条也不一定有值
"""插值法:用插值法拟合出缺失的数据,然后进行填充。"""
for f in features:
train_data[f] = train_data[f].interpolate()
train_data.dropna(inplace=True)
"""填充 KNN 数据:先利用 knn 计算临近的 k 个数据,然后填充他们的均值"""
from fancyimpute import KNN
train_data_x = pd.DataFrame(KNN(k=6).fit_transform(train_data_x), columns=features)
# 还可以填充模型预测的值, 这一个在我正在写的数据竞赛修炼笔记的第三篇里面可以看到,并且超级精彩,还在写
再回到这个比赛中,在数据探索中已经看到了缺失值的情况:
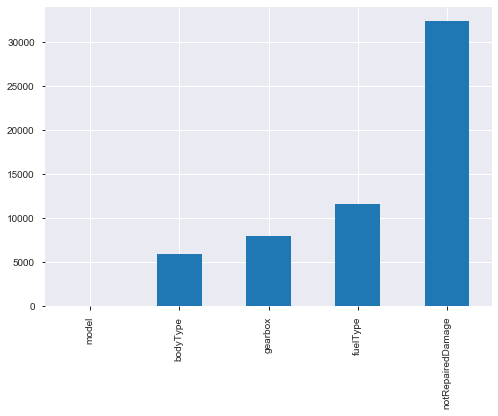 上图可以看到缺失情况, 都是类别特征的缺失,notRepaired 这个特征的缺失比较严重, 可以尝试填充, 但目前关于类别缺失,感觉上面的方式都不太好,所以这个也是一个比较困难的地方,感觉用模型预测填充比较不错。但目前不做进一步处理,因为后面的树模型可以自行处理缺失。当然 OneHot 的时候,会把空值处理成全 0 的一种表示,类似于一种新类型了。
上图可以看到缺失情况, 都是类别特征的缺失,notRepaired 这个特征的缺失比较严重, 可以尝试填充, 但目前关于类别缺失,感觉上面的方式都不太好,所以这个也是一个比较困难的地方,感觉用模型预测填充比较不错。但目前不做进一步处理,因为后面的树模型可以自行处理缺失。当然 OneHot 的时候,会把空值处理成全 0 的一种表示,类似于一种新类型了。
数据分桶
连续值经常离散化或者分离成“箱子”进行分析, 为什么要做数据分桶呢?
- 离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
- 离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
- LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
- 离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
- 特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化
当然还有很多原因,LightGBM 在改进 XGBoost 时就增加了数据分桶,增强了模型的泛化性。现在介绍数据分桶的方式:
- 等频分桶
- 等距分桶
- Best-KS 分桶(类似利用基尼指数进行二分类)
- 卡方分桶
最好将数据分桶的特征作为新一列的特征,不要把原来的数据给替换掉, 所以在这里通过分桶的方式做一个特征出来看看,以 power 为例:
"""下面以 power 为例进行分桶, 当然构造一列新特征了"""
bin = [i*10 for i in range(31)]
num_data['power_bin'] = pd.cut(num_data['power'], bin, labels=False)
当然这里的新特征会有缺失。这里也放一个数据分桶的其他例子(迁移之用)
# 连续值经常离散化或者分离成“箱子”进行分析。
# 假设某项研究中一组人群的数据,想将他们进行分组,放入离散的年龄框中
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
# 如果按年龄分成 18-25, 26-35, 36-60, 61 以上的若干组,可以使用 pandas 中的 cut
bins = [18, 25, 35, 60, 100] # 定义箱子的边
cats = pd.cut(ages, bins)
print(cats) # 这是个 categories 对象 通过 bin 分成了四个区间, 然后返回每个年龄属于哪个区间
# codes 属性
print(cats.codes) # 这里返回一个数组,指明每一个年龄属于哪个区间
print(cats.categories)
print(pd.value_counts(cats)) # 返回结果是每个区间年龄的个数
# 与区间的数学符号一致, 小括号表示开放,中括号表示封闭, 可以通过 right 参数改变
print(pd.cut(ages, bins, right=False))
# 可以通过 labels 自定义箱名或者区间名
group_names = ['Youth', 'YonngAdult', 'MiddleAged', 'Senior']
data = pd.cut(ages, bins, labels=group_names)
print(data)
print(pd.value_counts(data))
# 如果将箱子的边替代为箱子的个数,pandas 将根据数据中的最小值和最大值计算出等长的箱子
data2 = np.random.rand(20)
print(pd.cut(data2, 4, precision=2)) # precision=2 将十进制精度限制在 2 位
# qcut 是另一个分箱相关的函数, 基于样本分位数进行分箱。取决于数据的分布,使用 cut 不会使每个箱子具有相同数据数量的数据点,而 qcut,使用
# 样本的分位数,可以获得等长的箱
data3 = np.random.randn(1000) # 正太分布
cats = pd.qcut(data3, 4)
print(pd.value_counts(cats))
结果如下:

数据转换
数据转换的方式有:
- 数据归一化(MinMaxScaler);
- 标准化(StandardScaler);
- 对数变换(log1p);
- 转换数据类型(astype);
- 独热编码(OneHotEncoder);
- 标签编码(LabelEncoder);
- 修复偏斜特征(boxcox1p)等。
- 数值特征归一化, 因为这里数值的取值范围相差很大
minmax = MinMaxScaler()
num_data_minmax = minmax.fit_transform(num_data)
num_data_minmax = pd.DataFrame(num_data_minmax, columns=num_data.columns, index=num_data.index)
- 类别特征独热一下
"""类别特征某些需要独热编码一下"""
hot_features = ['bodyType', 'fuelType', 'gearbox', 'notRepairedDamage']
cat_data_hot = pd.get_dummies(cat_data, columns=hot_features)
- 关于高势集特征 model,也就是类别中取值个数非常多的, 一般可以使用聚类的方式,然后独热,这里就采用了这种方式:
from scipy.cluster.hierarchy import linkage, dendrogram
#from sklearn.cluster import AgglomerativeClustering
from sklearn.cluster import KMeans
ac = KMeans(n_clusters=3)
ac.fit(model_price_data)
model_fea = ac.predict(model_price_data)
plt.scatter(model_price_data[:,0], model_price_data[:,1], c=model_fea)
cat_data_hot['model_fea'] = model_fea
cat_data_hot = pd.get_dummies(cat_data_hot, columns=['model_fea'])
效果如下:
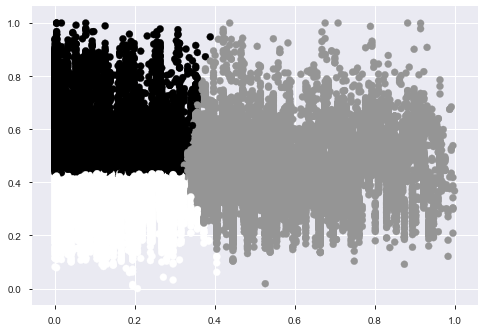
但是发现 KMeans 聚类不好,可以尝试层次聚类试试,并且这个聚类数量啥的应该也会有影响,这里只是提供一个思路,我觉得这个特征做的并不是太好,还需改进。
特征构造
在特征构造的时候,需要借助一些背景知识,遵循的一般原则就是需要发挥想象力,尽可能多的创造特征,不用先考虑哪些特征可能好,可能不好,先弥补这个广度。特征构造的时候需要考虑数值特征,类别特征,时间特征。
- 对于数值特征,一般会尝试一些它们之间的加减组合(当然不要乱来,根据特征表达的含义)或者提取一些统计特征
- 对于类别特征,我们一般会尝试之间的交叉组合,embedding 也是一种思路
- 对于时间特征,这一块又可以作为一个大专题来学习,在时间序列的预测中这一块非常重要,也会非常复杂,需要就尽可能多的挖掘时间信息,会有不同的方式技巧。当然在这个比赛中涉及的实际序列数据有一点点,不会那么复杂。
从这个比赛开始,看看这几种类型的特征如何进行构造新特征出来。

根据上面的描述, 下面就可以着手进行构造特征了,由于在数据清洗的时候就根据字段的类型不同把数据进行了划分,现在可以直接对特征进行构造。
时间特征的构造(time_data)
根据上面的分析,可以构造的时间特征如下:
- 汽车的上线日期与汽车的注册日期之差就是汽车的使用时间,一般来说与价格成反比
- 对汽车的使用时间进行分箱,使用了 3 年以下,3-7 年,7-10 年和 10 年以上,分为四个等级, 10 年之后就是报废车了,应该会影响价格
- 淡旺季也会影响价格,所以可以从汽车的上线日期上提取一下淡旺季信息
汽车的使用时间特征
createDate-regDate, 反应汽车使用时间,一般来说与价格成反比。但要注意的问题就是时间格式, regDateFalse 这个字段有些是 0 月,如果忽略错误计算的话,使用时间有一些会是空值, 当然可以考虑删除这些空值,但是因为训练集和测试集合并了,那么就不轻易删除了。
本文采取的办法是把错误字段都给他加 1 个月,然后计算出天数之后在加上 30 天(这个有不同的处理方式, 但是一般不喜欢删除或者置为空,因为删除和空值都有潜在的副作用)
# 这里是为了标记一下哪些字段有错误
def regDateFalse(x):
if str(x)[4:6] == '00':
return 1
else:
return 0
time_data['regDateFalse'] = time_data['regDate'].apply(lambda x: regDateFalse(x))
# 这里是改正错误字段
def changeFalse(x):
x = str(x)
if x[4:6] == '00':
x = x[0:4] + '01' + x[6:]
x = int(x)
return x
time_data['regDate'] = time_data['regDate'].apply(lambda x: changeFalse(x))
# 使用时间:data['creatDate'] - data['regDate'],反应汽车使用时间,一般来说价格与使用时间成反比
# 不过要注意,数据里有时间出错的格式,所以我们需要 errors='coerce'
time_data['used_time'] = (pd.to_datetime(time_data['creatDate'], format='%Y%m%d') -
pd.to_datetime(time_data['regDate'], format='%Y%m%d')).dt.days
# 修改错误
# 但是需要加上那一个月
time_data.loc[time_data.regDateFalse==1, 'used_time'] += 30
# 删除标记列
del time_data['regDateFalse']
这样,一个特征构造完毕, used_time 字段,表示汽车的使用时间。全部构造完毕之后,我们再看一下结果。
汽车是不是符合报废
时间特征还可以继续提取,我们假设用了 10 年的车作为报废车的话, 那么我们可以根据使用天数计算出年数, 然后根据年数构造出一个特征是不是报废
# 使用时间换成年来表示
time_data['used_time'] = time_data['used_time'] / 365.0
time_data['Is_scrap'] = time_data['used_time'].apply(lambda x: 1 if x>=10 else 0)
我们还可以对 used_time 进行分享,这个是根据背景估价的方法可以发现, 汽车的使用时间 3 年,3-7 年,10 年以上的估价会有不同,所以分一下箱
bins = [0, 3, 7, 10, 20, 30]
time_data['estivalue'] = pd.cut(time_data['used_time'], bins, labels=False)
这样就又构造了两个时间特征。Is_scrap 表示是否报废, estivalue 表示使用时间的分箱。
是不是淡旺季
这个是根据汽车的上线售卖时间看, 每年的 2, 3 月份及 6,7,8 月份是整个汽车行业的低谷, 年初和年末及 9 月份是二手车销售的黄金时期, 所以根据上线时间选出淡旺季。
# 选出淡旺季
low_seasons = ['3', '6', '7', '8']
time_data['is_low_seasons'] = time_data['creatDate'].apply(lambda x: 1 if str(x)[5] in low_seasons else 0)
# 独热一下
time_data = pd.get_dummies(time_data, columns=['is_low_seasons'])
# 这样时间特征构造完毕,删除日期了
del time_data['regDate']
del time_data['creatDate']
看一下最后的构造结果, 报废特征没有构造,因为发现了一个特点就是这里的数据 10 年以上的车会偏斜,所以感觉这个用 10 年作为分界线不太合适,只是提供一种思路。
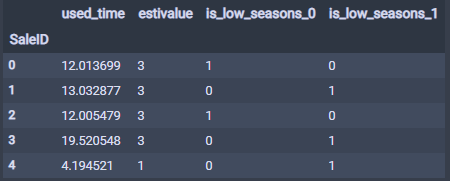
根据汽车的使用时间或者淡旺季分桶进行统计特征的构造
# 构造统计特征的话需要在训练集上先计算
train_data_timestats = train_data.copy() # 不要动train_data
train_data_timestats['estivalue'] = time_data['estivalue'][:train_data.shape[0]]
train_data_timestats['price'] = train_target
train_gt = train_data_timestats.groupby('estivalue')
all_info = {}
for kind, kind_data in train_gt:
info = {}
kind_data = kind_data[kind_data['price'] > 0]
info['estivalue_count'] = len(kind_data)
info['estivalue_price_max'] = kind_data.price.max()
info['estivalue_price_median'] = kind_data.price.median()
info['estivalue_price_min'] = kind_data.price.min()
info['estivalue_price_sum'] = kind_data.price.sum()
info['estivalueprice_std'] = kind_data.price.std()
info['estivalue_price_average'] = round(kind_data.price.sum() / (len(kind_data) + 1), 2)
all_info[kind] = info
estivalue_fe = pd.DataFrame(all_info).T.reset_index().rename(columns={"index": "estivalue"})
time_data = time_data.merge(estivalue_fe, how='left', on='estivalue')
这样, 时间特征就基本构造完毕,最后的结果如下:

这样,时间特征这块就构造了 10 个特征出来, 当然还可以更多, 由于篇幅原因,其他的可以自行尝试。
类别特征的构造(cat_data)
经过上面的分析,可以构造的类别特征如下:
- 从邮编中提取城市信息, 因为是德国的数据,所以参考德国的邮编,加入先验知识, 但是感觉这个没有用,可以先试一下
- 最好是从 regioncode 中提取出是不是华东地区,因为华东地区是二手车交易的主要地区(这个没弄出来,不知道这些编码到底指的哪跟哪)
- 私用车和商用车分开(bodyType 提取)
- 是不是微型车单独处理,所以感觉那些车的类型 OneHot 的时候有点分散了(bodyType 这个提取,然后 one-hot)
- 新能源车和燃油车分开(在 fuelType 中提取,然后进行 OneHot)
- 地区编码还是有影响的, 不同的地区汽车的保率不同
- 品牌这块可以提取一些统计量, 统计特征的话上面这些新构造的特征其实也可以提取
注意,OneHot 不要太早,否则有些特征就没法提取潜在信息了。
邮编特征
从邮编中提取城市信息, 因为是德国的数据,所以参考德国的邮编,加入先验知识。
cat_data['city'] = cat_data['regionCode'].apply(lambda x: str(x)[0])
私用车和商务车分开(bodyType)
com_car = [2.0, 3.0, 6.0] # 商用车
GL_car = [0.0, 4.0, 5.0] # 豪华系列
self_car = [1.0, 7.0]
def class_bodyType(x):
if x in GL_car:
return 0
elif x in com_car:
return 1
else:
return 2
cat_data['car_class'] = cat_data['bodyType'].apply(lambda x : class_bodyType(x))
新能源车和燃油车分开(fuelType)
# 是否是新能源
is_fuel = [0.0, 1.0, 2.0, 3.0]
cat_data['is_fuel'] = cat_data['fuelType'].apply(lambda x: 1 if x in is_fuel else 0)
构造统计特征
这一块依然是可以构造很多统计特征,可以根据 brand, 燃油类型, gearbox 类型,车型等,都可以,这里只拿一个举例,其他的类似,可以封装成一个函数处理。
以 gearbox 构建统计特征:
train_data_gearbox = train_data.copy() # 不要动train_data
train_data_gearbox['gearbox'] = cat_data['gearbox'][:train_data.shape[0]]
train_data_gearbox['price'] = train_target
train_gb = train_data_gearbox.groupby('gearbox')
all_info = {}
for kind, kind_data in train_gb:
info = {}
kind_data = kind_data[kind_data['price'] > 0]
info['gearbox_count'] = len(kind_data)
info['gearbox_price_max'] = kind_data.price.max()
info['gearbox_price_median'] = kind_data.price.median()
info['gearbox_price_min'] = kind_data.price.min()
info['gearbox_price_sum'] = kind_data.price.sum()
info['gearbox_std'] = kind_data.price.std()
info['gearbox_price_average'] = round(kind_data.price.sum() / (len(kind_data) + 1), 2)
all_info[kind] = info
gearbox_fe = pd.DataFrame(all_info).T.reset_index().rename(columns={"index": "gearbox"})
cat_data = cat_data.merge(gearbox_fe, how='left', on='gearbox')
当然下面就可以把 bodyType 和 fuelType 删除,因为该提取的信息也提取完了,该独热的独热。
# 删掉bodyType和fuelType,然后把gearbox, car_class is_fuel独热一下, 这个不能太早,构造晚了统计特征之后再独热
del cat_data['bodyType']
del cat_data['fuelType']
cat_data = pd.get_dummies(cat_data, columns=['gearbox', 'car_class', 'is_fuel', 'notRepairedDamage'])
这样,把类别特征构造完毕。最终结果如下:

本文构造了 41 个特征,当然可以更多, 也是自己尝试。
数值特征的构造(num_data)
数值特征这块,由于大部分都是匿名特征,处理起来不是太好处理,只能尝试一些加减组合和统计特征
对里程进行一个分箱操作
一部车有效寿命 30 万公里,将其分为 5 段,每段 6 万公里,每段价值依序为新车价的 5/15、4/15、3/15、2/15、1/15。假设新车价 12 万元,已行驶 7.5 万公里(5 年左右),那么该车估值为 12 万元 ×(3+3+2+1)÷15=7.2 万元。
# 分成三段
bins = [0, 5, 10, 15]
num_data['kil_bin'] = pd.cut(num_data['kilometer'], bins, labels=False)
V 系列特征的统计特征
平均值, 总和和标准差
v_features = ['v_' + str(i) for i in range(15)]
num_data['v_sum'] = num_data[v_features].apply(lambda x: x.sum(), axis=1)
num_data['v_mean'] = num_data[v_features].apply(lambda x: x.mean(), axis=1)
num_data['v_std'] = num_data[v_features].apply(lambda x: x.std(), axis=1)
这样,数值特征构造完毕,最终构造的结果特征如下:
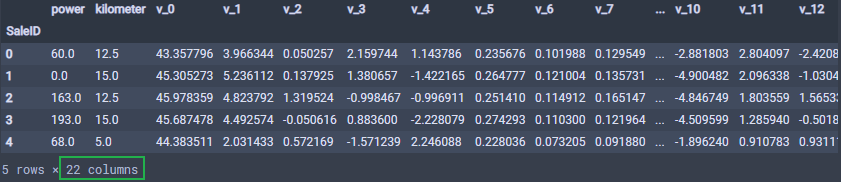
通过上面的步骤,特征工程就完成了。简单的梳理一下, 基于二手车的背景信息进行特征构造的,首先是构造的时间特征, 构造了使用时间,是否报废,使用时间分箱, 是否淡旺季等特征;然后是类别特征,构造了邮编特征,是否私用,是否新能源,是否微型车,并且还提取了大量统计特征;最后是数值特征,给 kilometer 分箱, 对 V 特征进行了统计等。
最后我们合并一下所有的数据
final_data = pd.concat([num_data, cat_data, time_data], axis=1)
final_data.shape # (200000, 74)
final_data.head()
特征构造后的最终数据:

最终有 74 个特征, 当然还可以更多,但是太多了也不是个好事,会造成冗余,特征相关等特征,对后面的模型造成一些负担。所以,还得进行特征筛选才可以,毕竟上面的 74 个特征不可能都是有用的,甚至有些还会造成负面影响。
特征选择
特征选择(排序)对于数据科学家、机器学习从业者来说非常重要。好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。
但是拿到数据集,一个特征选择方法,往往很难同时完成这两个目的。通常情况下,我们经常不管三七二十一,选择一种自己最熟悉或者最方便的特征选择方法(往往目的是降维,而忽略了对特征和数据理解的目的), 但是真的好使吗?只能说具体问题具体分析,也许会暴力出奇迹呢。
特征选择主要有两个功能:
- 减少特征数量、降维,使模型泛化能力更强,减少过拟合
- 增强对特征和特征值之间的理解
通常来说,从两个方面考虑来选择特征:
- 特征是否发散:如果一个特征不发散,例如方差接近于 0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。
根据特征选择的形式又可以将特征选择方法分为 3 种:
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于 Filter 方法,但是是通过训练来确定特征的优劣。
首先,导入之前处理备份的数据:
# 导入最后的数据
final_data = pd.read_csv('./pre_data/pre_data_beifen.csv')
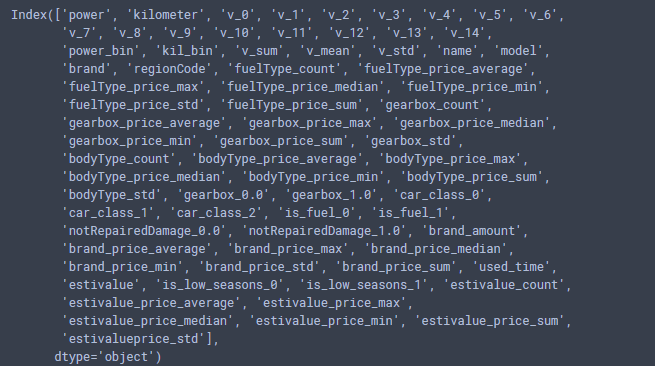
还是上面的 final_data, 看一下构造的特征:
过滤式
主要思想: 对每一维特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该特征的重要性,然后依据权重排序。先进行特征选择,然后去训练学习器,所以特征选择的过程与学习器无关。相当于先对特征进行过滤操作,然后用特征子集来训练分类器。
主要方法:
- 移除低方差的特征;
- 相关系数排序,分别计算每个特征与输出值之间的相关系数,设定一个阈值,选择相关系数大于阈值的部分特征;
- 利用假设检验得到特征与输出值之间的相关性,方法有比如卡方检验、t 检验、F 检验等。
- 互信息,利用互信息从信息熵的角度分析相关性。
这里,本文为大家提供一些有价值的小 tricks:
- 对于数值型特征,方差很小的特征可以不要,因为太小没有什么区分度,提供不了太多的信息,对于分类特征,也是同理,取值个数高度偏斜的那种可以先去掉。
- 根据与目标的相关性等选出比较相关的特征(当然有时候根据字段含义也可以选)
- 卡方检验一般是检查离散变量与离散变量的相关性,当然离散变量的相关性信息增益和信息增益比也是不错的选择(可以通过决策树模型来评估来看),person 系数一般是查看连续变量与连续变量的线性相关关系。
去掉取值变化小的特征
这应该是最简单的特征选择方法了:假设某特征的特征值只有 0 和 1,并且在所有输入样本中,95% 的实例的该特征取值都是 1,那就可以认为这个特征作用不大。如果 100% 都是 1,那这个特征就没意义了。
当特征值都是离散型变量的时候这种方法才能用,如果是连续型变量,就需要将连续变量离散化之后才能用,而且实际当中,一般不太会有 95% 以上都取某个值的特征存在,所以这种方法虽然简单但是不太好用。
可以把它作为特征选择的预处理,先去掉那些取值变化小的特征,然后再从接下来提到的的特征选择方法中选择合适的进行进一步的特征选择。例如,我们前面的 seller 和 offerType 特征。
# 对方差的大小排序
select_data.std().sort_values() # select_data是final_data去掉了独热的那些特征
根据这个,可以把方差非常小的特征作为备选的删除特征(备选,可别先盲目删除)
单变量特征选择
单变量特征选择能够对每一个特征进行测试,衡量该特征和响应变量之间的关系,根据得分扔掉不好的特征。对于回归和分类问题可以采用卡方检验等方式对特征进行测试。
这种方法比较简单,易于运行,易于理解,通常对于理解数据有较好的效果(但对特征优化、提高泛化能力来说不一定有效);这种方法有许多改进的版本、变种。
下面重点介绍一下 pearson 相关系数,皮尔森相关系数是一种最简单的,比较常用的方式。能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1 表示完全的负相关(这个变量下降,那个就会上升),+1 表示完全的正相关,0 表示没有线性相关。
Pearson Correlation 速度快、易于计算,经常在拿到数据(经过清洗和特征提取之后的)之后第一时间就执行。Scipy 的 pearsonr 方法能够同时计算相关系数和 p-value, 当然 pandas 的 corr 也可以计算。
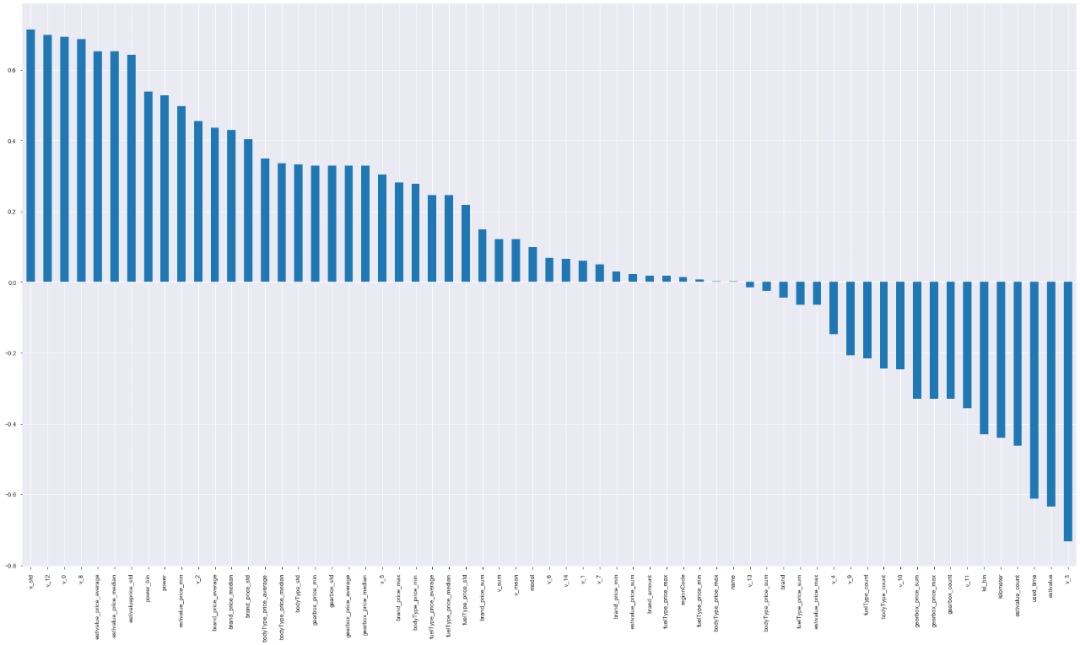
直接根据 pearson 系数画出图像:
corr = select_data.corr('pearson') # .corr('spearman')
plt.figure(figsize=(25, 15))
corr['price'].sort_values(ascending=False)[1:].plot(kind='bar')
plt.tight_layout()
结果如下:
当然,这个数据用 pearson 系数可能不是那么合理,可以使用 spearman 系数,这个被认为是排列后的变量的 pearson 的相关系数, 具体的可以看(Pearson)皮尔逊相关系数和 spearman 相关系数, 这里只整理两者的区别和使用场景, 区别如下:
- 连续数据,正态分布,线性关系,用 pearson 相关系数是最恰当,当然用 spearman 相关系数也可以,效率没有 pearson 相关系数高。
- 上述任一条件不满足,就用 spearman 相关系数,不能用 pearson 相关系数。
- 两个定序测量数据(顺序变量)之间也用 spearman 相关系数,不能用 pearson 相关系数。
- Pearson 相关系数的一个明显缺陷是,作为特征排序机制,他只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系,Pearson 相关性也可能会接近 0。
当然还可以画出热力图来,这个不陌生了吧, 这个的目的是可以看变量之间的关系, 相关性大的,可以考虑保留其中一个:
# 下面看一下互相之间的关系
f, ax = plt.subplots(figsize=(50, 30))
sns.heatmap(corr, annot=True)
结果如下:
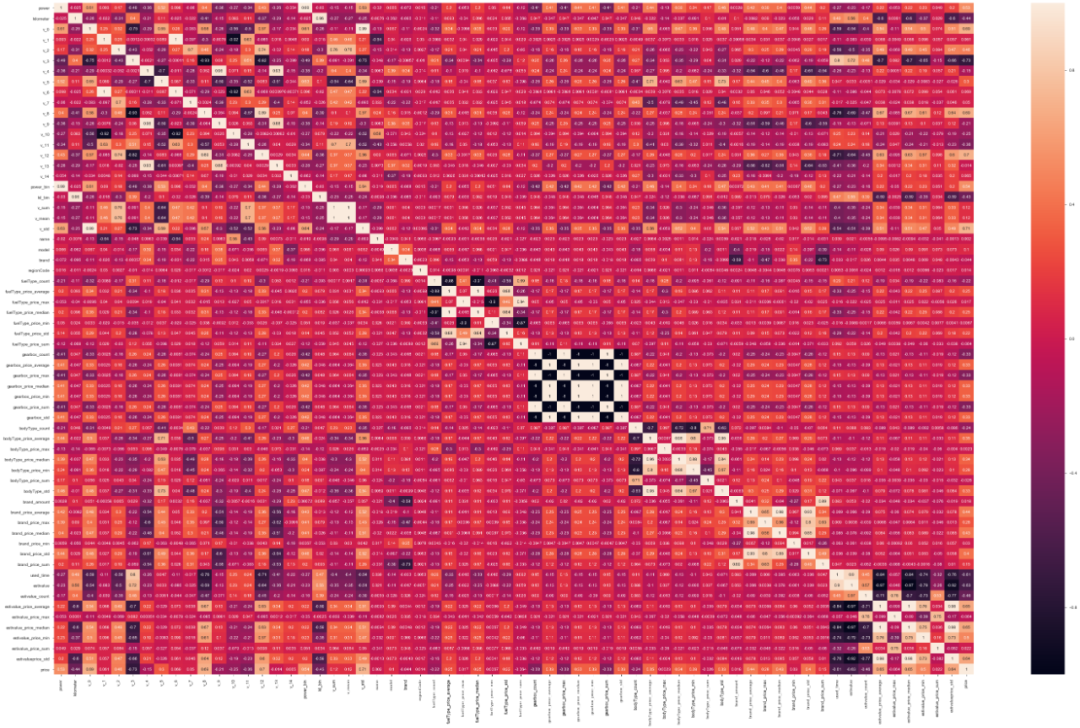
从上面两个步骤中,就可以发现一些结论:
- 根据与 price 的线性相关关系来看的话,我们可以考虑正负相关 0.6 以上的特征, v_std, v_12, v_0, v_8, estivalue_price_average, estivalue_price_median, estivalue_price_std, kil_bin, kilmoeter, estivalue_count, used_time, estivalue, v_3
- 某些变量之间有很强的的关联性,比如 v_mean 和 v_sum,这俩的相关性是 1,所以可以删掉其中一个。
当然,依然是备选删除选项和备选保留选项(这些都先别做), 因为我们有时候不能盲目,就比如上面的相关性,明明知道 pearson 的缺陷是无法捕捉非线性相关,所以得出的这个结论也是片面的结论。这些都是备选,先做个心中有数,后面再用一些别的方式看看再说(如果现在就删除了,后面的方法就不好判断了)
包裹式
单变量特征选择方法独立的衡量每个特征与响应变量之间的关系,另一种主流的特征选择方法是基于机器学习模型的方法。有些机器学习方法本身就具有对特征进行打分的机制,或者很容易将其运用到特征选择任务中,例如回归模型,SVM,决策树,随机森林等等。
主要思想:包裹式从初始特征集合中不断的选择特征子集,训练学习器,根据学习器的性能来对子集进行评价,直到选择出最佳的子集。包裹式特征选择直接针对给定学习器进行优化。
主要方法:递归特征消除算法, 基于机器学习模型的特征排序
优缺点:
优点:从最终学习器的性能来看,包裹式比过滤式更好;
缺点:由于特征选择过程中需要多次训练学习器,因此包裹式特征选择的计算开销通常比过滤式特征选择要大得多。
下面,这里整理基于学习模型的特征排序方法,这种方法的思路是直接使用你要用的机器学习算法,针对每个单独的特征和响应变量建立预测模型。其实 Pearson 相关系数等价于线性回归里的标准化回归系数。
假如某个特征和响应变量之间的关系是非线性的,可以用基于树的方法(决策树、随机森林)、或者扩展的线性模型等。基于树的方法比较易于使用,因为他们对非线性关系的建模比较好,并且不需要太多的调试。但要注意过拟合问题,因此树的深度最好不要太大,再就是运用交叉验证。
我们可以用随机森林来跑一下,看看随机森林比较喜欢特征:
from sklearn.model_selection import cross_val_score, ShuffleSplit
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import KFold
X = select_data.iloc[:, :-1]
Y = select_data['price']
names = select_data.columns
rf = RandomForestRegressor(n_estimators=20, max_depth=4)
kfold = KFold(n_splits=5, shuffle=True, random_state=7)
scores = []
for column in X.columns:
print(column)
tempx = X[column].values.reshape(-1, 1)
score = cross_val_score(rf, tempx, Y, scoring="r2",
cv=kfold)
scores.append((round(np.mean(score), 3), column))
print(sorted(scores, reverse=True))
这里对喜欢的特征排序并打分,结果如下:
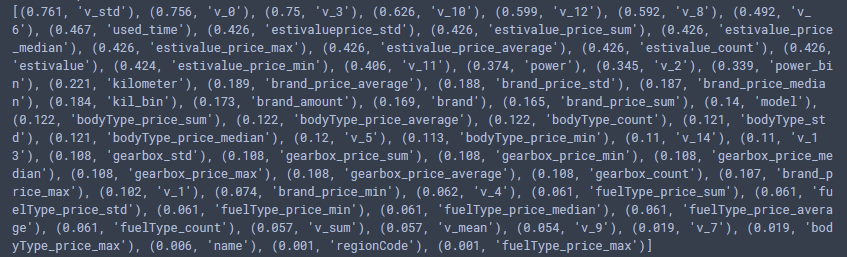
这里就可以看出随机森林有用的特征排序,如果我们后面选择随机森林作为模型,就可以根据这个特征重要度选择特征。当然,如果你是 xgboost,xgboost 里面有个画特征重要性的函数,可以这样做:
# 下面再用xgboost跑一下
from xgboost import XGBRegressor
from xgboost import plot_importance
xgb = XGBRegressor()
xgb.fit(X, Y)
plt.figure(figsize=(20, 10))
plot_importance(xgb)
plt.show()
这样,直接把 xgboost 感兴趣的特征画出来:
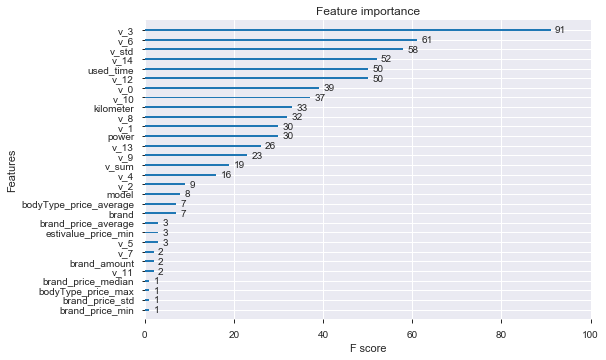
最后,我们把上面的这两种方式封装起来, 还可以画出边际效应:
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
# sfs = SFS(LinearRegression(), k_features=20, forward=True, floating=False, scoring='r2', cv=0)
sfs = SFS(RandomForestRegressor(n_estimators=10, max_depth=4), k_features=20, forward=True, floating=False, scoring='r2', cv=0)
X = select_data.iloc[:, :-1]
Y = select_data['price']
sfs.fit(X, Y)
sfs.k_feature_names_ # 随机森林放这里跑太慢了,所以中断了
结果如下:
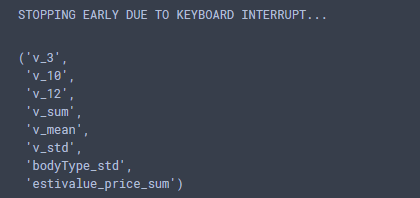
画出边际效应:
# 画出边际效应
from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs
fig1 = plot_sfs(sfs.get_metric_dict(), kind='std_dev')
plt.grid()
plt.show()
这个也是看选出的特征的重要性:
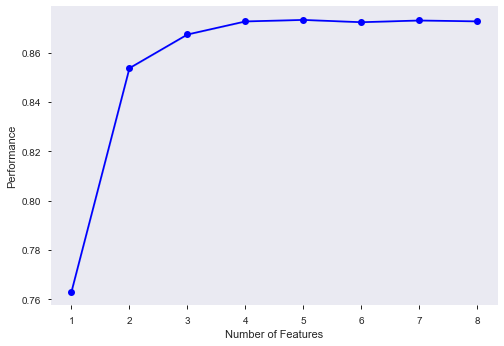
这样,根据我们使用的模型,我们可以对特征进行一个选择,综合上面的这几种方式,我们就可以把保留和删除的特征给选出来了,该删除的可以删除了。
如果真的这样尝试一下,就会发现保留的特征里面, v_std, v_3, used_time, power, kilometer, estivalue 等这些特征都在,虽然我们不知道 v 系列特征的含义,但是汽车使用时间,发动机功率,行驶公里, 汽车使用时间的分箱特征其实对 price 的影响都是比较大的。
嵌入式
在过滤式和包裹式特征选择方法中,特征选择过程与学习器训练过程有明显的分别。而嵌入式特征选择在学习器 训练过程中自动地进行特征选择。嵌入式选择最常用的是 L1 正则化与 L2 正则化。在对线性回归模型加入两种正则化方法后,他们分别变成了岭回归与 Lasso 回归。
主要思想:在模型既定的情况下学习出对提高模型准确性最好的特征。也就是在确定模型的过程中,挑选出那些对模型的训练有重要意义的特征。
主要方法:简单易学的机器学习算法–岭回归(Ridge Regression),就是线性回归过程加入了 L2 正则项。
L1 正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择
L2 正则化在拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参 数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性 回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移 得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』
这里简单介绍一下怎么使用,其实和上面机器学习模型的使用方法一样, 所以有时候这些方法没有必要严格的区分开:
from sklearn.linear_model import LinearRegression, Ridge,Lasso
models = [LinearRegression(), Ridge(), Lasso()]
result = dict()
for model in models:
model_name = str(model).split('(')[0]
scores = cross_val_score(model, X=train_X, y=train_y, verbose=0, cv=5, s
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%9B%B6%E5%9F%BA%E7%A1%80%E5%85%A5%E9%97%A8%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98%E7%89%B9%E5%BE%81%E5%B7%A5%E7%A8%8B%E5%AE%9E%E6%88%98/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


