阿里飞猪林睿从核心因子预估实体识别如何实现文本和空间的搜索相关性

分享嘉宾:林睿 阿里巴巴 算法专家
编辑整理:李鹏 重庆邮电大学
出品平台:DataFunTalk
导读: 随着人们生活质量不断提高,出门旅行逐渐成为大众喜爱的消遣方式,酒店预定则是出游必不可少的一环。为了让用户拥有更好的体验,满足用户各种个性化地搜索,从而让用户在最短时间内找到心仪的酒店,文本将分享飞猪旅行酒店搜索相关性建设,主要包括:
- 酒店搜索背景
- 酒店相关性
- 基础建设
- 相关性建模
01 酒店搜索背景介绍
1. 酒店小搜背景
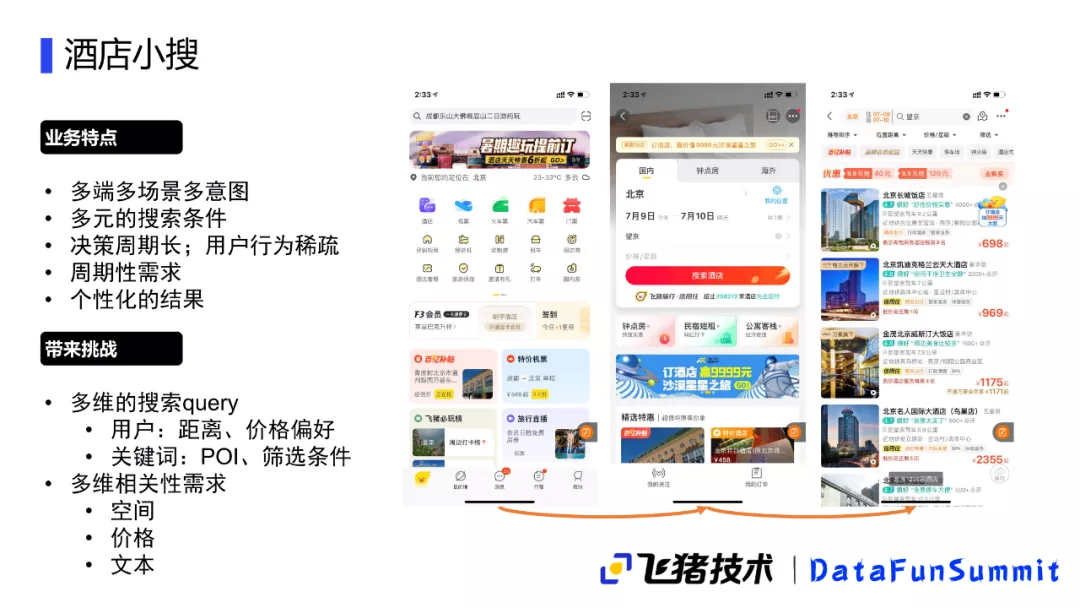
酒店搜索的主入口是飞猪应用主页的“酒店”,随后进入到搜索页面,这是一个比较大的垂直搜索页面,点击搜索酒店后会根据历史记录推荐一些用户想要搜索的酒店,这个业务是一个多端、多场景、多意图的搜索。不仅在飞猪APP上有酒店搜索的入口,在淘宝以及支付宝端也有酒店搜索的入口。毕竟各个端的用户行为、想法还是不太一致,因此各个端的排序也要做好,并且要做出一些差异。另外搜索方面的条件也是非常多元的,它不像传统的百度可能只有文本搜索,酒店搜索条件的多元体现在有文本、价格、星级和城市这样一些不同的条件。进入历史搜索页面后,还有各种各样的筛选条件,所以整个搜索条件是非常丰富的。
- 它与淘宝的搜索是不太相同的,酒店的用户行为比较稀疏,一个用户可能一年预定几次酒店,甚至几年订一次酒店,这也增加了算法上的一些难度
- 酒店的用户决策周期是比较长的,酒店的价格相对较高,在最终购买的决策之前,用户有比较多的一些点击行为和思考
- 酒店搜索个性化是比较强的,会有一些周期性的需求,比如一些出差用户会有周期性的需要等等
这些都是搜索业务上的一些特点,这些特点会带来一些挑战。首先就是刚才提到它的搜索条件比较多,与传统只有文本的搜索不同。除了要关注文本中提到的一些POI,以及一些筛选条件,也需要关注用户本身离它的距离和价格偏好。除了常规的文本相关性需求,在酒店搜索业务中还会有很多其它相关性需求,例如空间,用户可能需要定在某一个景点附近的酒店,或者是公司附近的酒店;还有价格,用户可能是学生党或者是准备穷游的人,会对价格有不同的偏好,这些都是要在酒店相关性排序上需要考虑的。
2. 酒店搜索架构
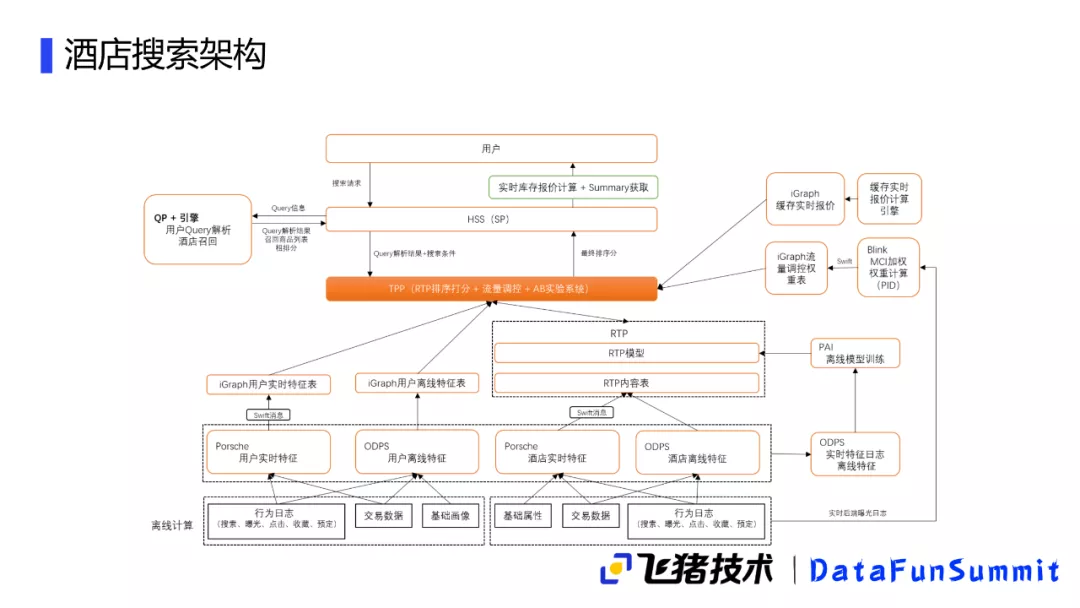
接下来介绍酒店的搜索架构,该架构和传统搜索还是比较相似的,它也是有一个SP,它会通过实时库链接到用户请求,然后调用请求搜索,接着用QP进行Query的解析,以及对相关酒店进行初排,拿到初排后会调用TPP服务来进行一个排序和打分。此外我们还会结合用户离线的一些行为数据,以及当时用户在线的实时交互特征,以及酒店的一些离线特征,例如名称和位置等。另外也会有一些酒店的实时特征,比如近期的一些成交量,还有一些库存之类的,还考虑到一些实时的报价特征等,最终做出这样一个排序来作为用户的搜索结果。这一次分享的主题主要侧重于酒店相关信息化部分,接下来介绍酒店的相关性部分。
02 酒店相关性介绍
1. 场景与相关性
酒店的相关性和传统文本相关性比会比较复杂,例如空搜/附近搜或景点/商圈搜索,我可能会比较注重于距离的一个敏感度,搜索附近肯定是希望住的酒店离这个位置比较接近;当你搜景点商圈的时候,你也肯定希望想要住在这个景点附近,或者是住在商圈之内,同样是对距离比较敏感的搜索。这两个搜索也是有些区别的,因为像空搜附近搜的时候,其实用户的需求比较泛,可能更多的要考虑用户个性化的一些需求;在搜索景点和商圈的时候,这个意图比较明确,因为一般搜景点的玩法是固定的,其实它和本身的搜索更为相关,和用户本身个性化可能关系不是那么大。
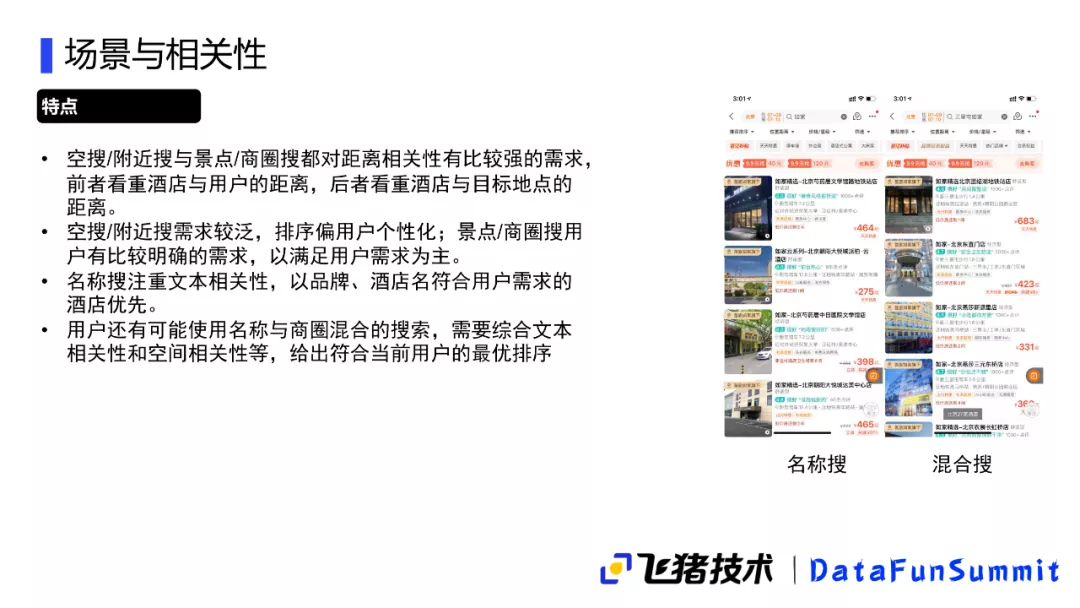
另外用户可能会搜索一些名称品牌,比如如家,他肯定希望想要一个如家的酒店,或者可能跟具体名称相关的一些酒店,这时候会涉及到一些文本相关性的判断,因为用户也可能记不特别清楚这个酒店的名称。另外还会有一些混合的情况,比如用户搜索了“三里屯如家”这种类型的query,既满足距离的位置限制,也满足文本的匹配程度。
2. 酒店的相关性

综上,整体的酒店相关性是比较复杂的一个情况,它是由文本、空间、价格这样多元融合的一个相关性,同时它也受到用户、场景及query中筛选条件的不同,它每一次搜索需要给用户展现一个相关度,也会有不同的侧重。前面提到的这些问题会导致酒店多元化的一个相关性,这会影响数据的标签标注,很难标出一个相关的数据集。它也很个性化,人工也不太好标注。现在整个相关性的模型训练,只能更多的依赖这种点击以及成交的一些label来帮助我们做相关性的一些训练。
综上,我们对酒店相关性的一个方案,就是按以下的步骤来展开:
- 首先是要识别用户的需求,系统对距离、价格这些的敏感程度以及一些相关程度
- 然后构建一个多元的相关性,能同时识别文本、价格、空间这样的相关性
- 最终根据用户的需求对这些相关性进行一个融合,进而得到整体的相关性来增强酒店排序的效果
03 基础建设介绍
1. 核心因子预估
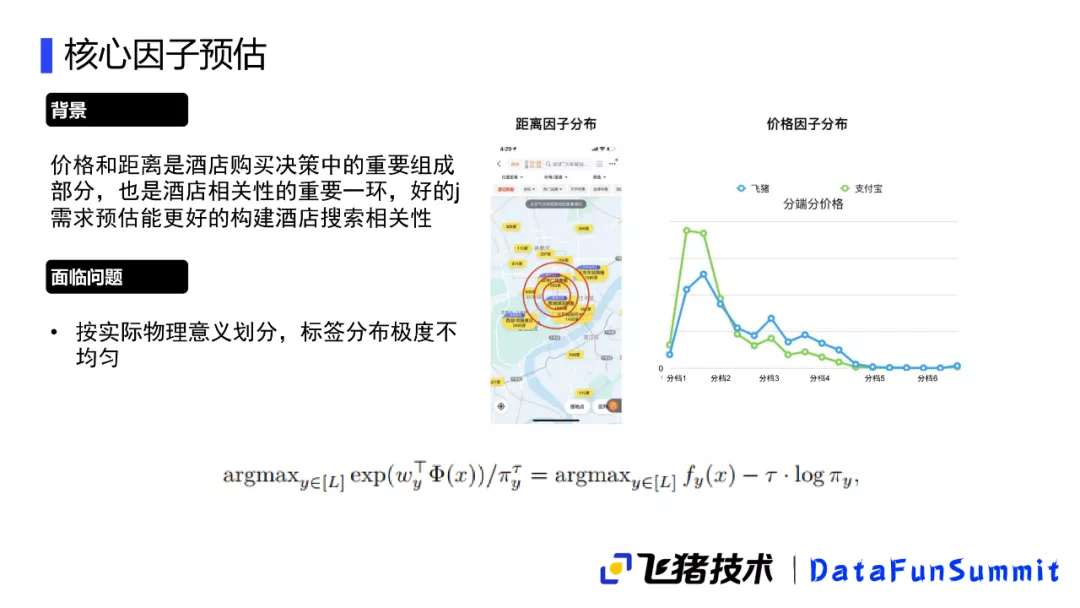
接下来介绍一下我们在酒店相关性基础上做的一些工作,首先是对核心因子的预估,就是刚刚提到的距离和价格这两个因子,这是酒店预定决策中很重要的一环,在酒店相关性构造中也很重要,需要一个好的预估来构造相关性识别。从图中可以看到标签的分布非常不均匀,一般情况下高价酒店需要的人是比较少的,距离远的酒店大概率也是不太需要的。如果我们按照实际物理意义的远近高低价格来做一个划分,这个标签的分布会比较不均匀,为了解决这种不均匀的问题,我们对最终的方案要进行一个修正。要求先验概率比较大的类别需要有更大的逻辑,才能说它是比较有偏好的先验概率,比较低的类别可能就不用那么严格要求,就只需要比较低的逻辑,我们就可以认为它是对这个有比较好的偏好。总体来看,这样的修正在整体效果上还是比较好的,这里以价格为例,可以看到在一线城市价格的需求是比较高的,而在二三线城市它对低价位的需求是比较高的。在机场、酒店、车站的附近,用户对酒店的需求价格可能没那么高,可能就是临时住宿一天,并且对酒店的整个价格和星级舒适度的要求也不会那么高;但是在风景区或者校区公司,用户会对酒店的价格、舒适度有一定的要求。另外从提前天数的分布我们也能看出来,用户对酒店的价格也是有不同的需求,如果在当天预定就可能比较紧张地入住,可能对价格没有那么大的需求,如果提前好几天一个旅行的规划,用户对价格、舒适度会有一定要求,整体来说也是比较符合常人的基本认知,整体的效果还是比较好的。
2. 核心实体识别

我们还做了核心实体的识别工作,这是为了能更准确地计算文本相关性,需要对POI还有酒店名称,包括一些品牌实体进行识别,识别出来的POI也要能够方便计算空间相关性,需要知道景点或者公司的具体位置才能更好地计算空间相关性。我们在做实体识别的时候也会遇到一些问题,首先是实体识别的准确率,另外就是实体具体对应真实地图上的哪个POI。举个例子比如西湖,大家可能都会觉得是去杭州西湖,但实际上在其他城市也会有西湖,比如福州它也会有一些西湖的需求。所以我们还需要对实体进行一个消歧,让它能够正确映射到对应实体上,这样才能做后续的文本处理。
空间相关性的计算我们采用是这样的方案:
- 首先利用BERT加CRF的方式对用户输入的关键词进行NER识别,找出用户输入文本中的实体,因为BERT本身已经比较强大,所以我们通过简单的实体库和对训练数据进行一些数据增强后,就能得到实体识别一个比较高的准确率结果了
- 得到一个实体词后,通常会通过倒排序召回、向量召回以及用户的一些行为,即用户在行为上的一些点击行为进行召回,同样也能得到一些候选品牌,或者说POI的真实ID,我们会利用这种文本相关性的得分,来分析这种ID上对应的一些热度以及点击
- 利用所在城市的一些特征,来构建一个排序模型,最终选出一个最合适的实体作为单层识别实体的一个映射。有了这些实体识别结果以及核心因子识别能力,我们就能对用户的搜索有一个比较好的需求识别
04 相关性建模介绍
1. 文本相关性
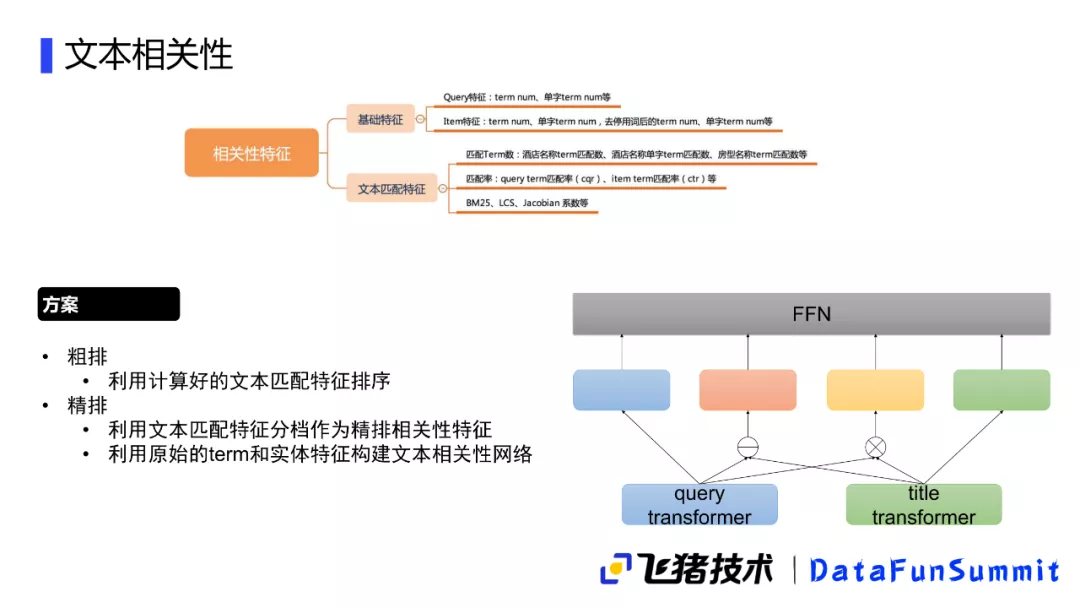
接下来就需要根据这些需求识别结果来构建相关性模型,首先是文本相关性这一块分成了两个步骤:
- 一是在粗排中利用BM25和Jaccard等一些方式,来计算初步的文本匹配得分,并用这个得分按照一定阈值进行分档,这个分档在粗排中可以作为一次粗的筛选来得到一些候选的酒店;
- 二是在精排模型中会利用计算的分档方案作为一个特征,同时使用酒店名字的一些文本,以及用户搜索中的一些关键词,以此来构建一个文本相关性的网络。这里由于对性能的要求,该网络是比较简单的,我们通过transformer来对query以及title的分词结果来抽取文本特征,得到query和title的文本向量表示,然后进行求差以及按位相乘的操作,会得到两个新的相关向量,将这个向量与原始的query、title以及transformer抽取到的句子特征向量进行匹配,然后通过一个FFN来作为文本相似度的一个特征向量。
2. 空间相关性
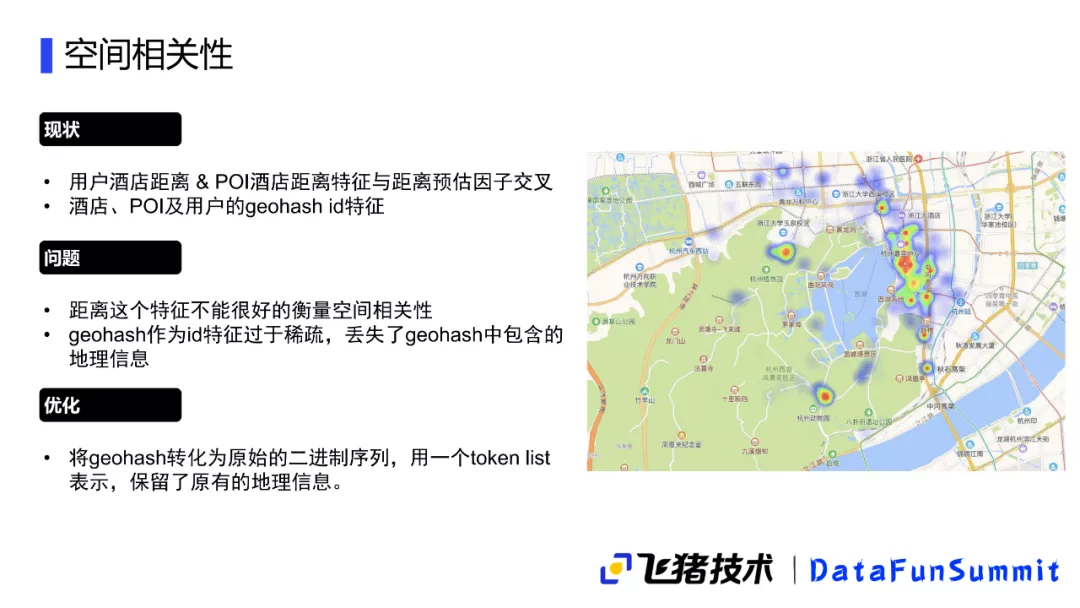
接下来介绍空间相关性的建模过程。这块我们原始有一些积累,原始的方案是比较简单的,首先是利用用户到达酒店的一个距离,以及POI到酒店的距离做一个特征。另外刚才用到的距离预估因子分布,做成一个特征交叉输入到排序模型中,作为另一种空间相关性特征。
同时使用酒店POI以及用户的geohash特征作为用户当时所在地的一个表示,这里介绍一下什么是geohash特征,就是可以通过一定的编码方式将经纬度映射到一个网格上,每一个网格就可以用一个geohash来表示,但是它可能会有一些问题,比如在红点这个位置它被分在了中间这个格子,其实它离上面的格子也非常近,所以我们在用具有geohash特征的时候,会考虑它周围八个格子的信息,即综合当前所在格以及周围八格的信息,共同构建一个位置特征输入到模型中做空间相关性计算。
即使这样,方案也还是有一些问题,首先是距离的特征,它并不能很好地衡量空间相关性。举个例子,在上图中当用户搜索西湖的时候,我们对用户所点击的酒店进行一个热力图分析,发现用户在搜西湖附近的酒店,它是有一些比较分散的分布,并不是离西湖越近它会热度越高,因为用户可能会想靠近一些其它的地方,比如浙大的一个校区,以及杭州动物园的其它景点,用户可能会综合考虑要去各个景点的一个方便程度,因此不一定要预定在西湖最近,所以仅有距离这个特征并不能够很好地衡量空间相关性。另外刚才提到的geohash特征,虽然它有二维空间的一个特征,但是它过于稀疏,因此我们只好把它映射到一个ID上,这个ID在学习的时候已经丢掉了它本身的一些地理信息,已经没有原来的经纬度和地理接近的一些信息,我们只是通过学习来得知这个ID和那个ID是比较近的,是通过数据训练学出来的,经纬度它天然带一些这种接近或不接近的信息,这些信息我们在做特征的时候就把它丢掉了,这样又由于geohash比较稀疏,可能学习起来也就很难得到我们想要的一个结果。综上,我们考虑了对空间的一些特征进行优化,将原始的二进制序列进行保留,用这个二进制序列来构建一个tokenlist,这样来表达一个地理信息,从而保留经纬度本身的一些距离关系。
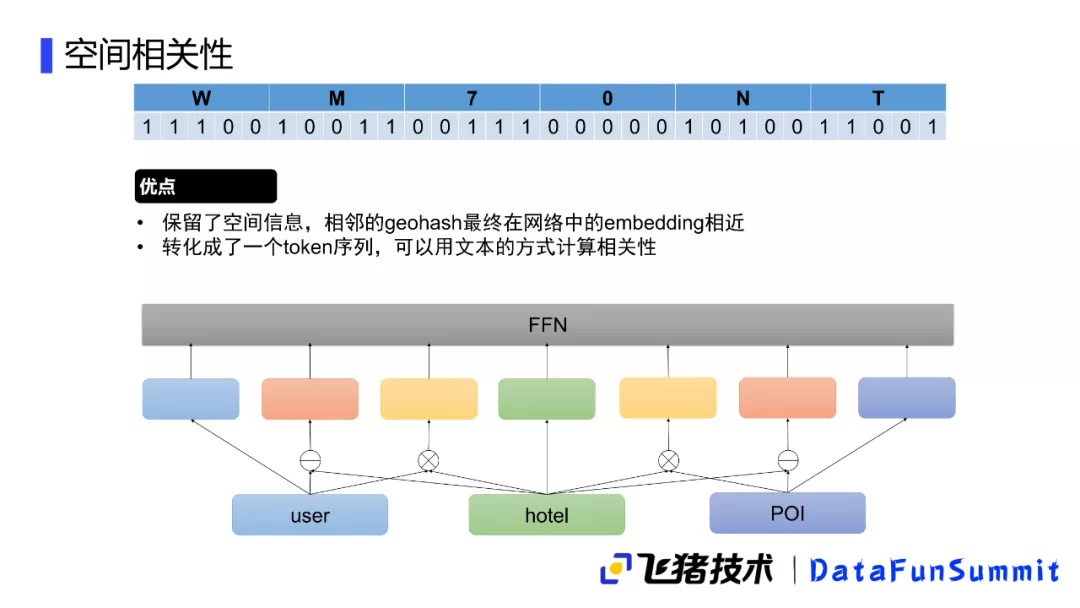
这里举一个例子,我们通过还原它原始的二进制编码,可以得到一个零一表征的序列,由于geohash的一个特性,零一序列的前缀相同越多,得到的这两个序列就越接近。转成这样一个编码后,将它当成一个文本特征来处理,从而可以得到两个文本,它们的前缀相同越多,它们就越接近,这和文本相似度其实也是比较相像的。由此我们就得到了这样一个方法:
- 将geohash转成一个二进制编码,然后用二进制编码的文本表示作为它的空间特征,这样来计算就可以比较好地衡量空间相关性
- 和刚才文本相关性计算也比较类似,我们会将用户、酒店以及POI的geohash转化成一个文本序列,这个序列也是通过一个网络抽取的特征向量
- 得到特征向量后也是通过这种计算,它的差以及单位点乘的方式得到它的交叉向量,最后将这些向量分配在一起,得到最终空间相关性的向量表示
3. 多场景相关性
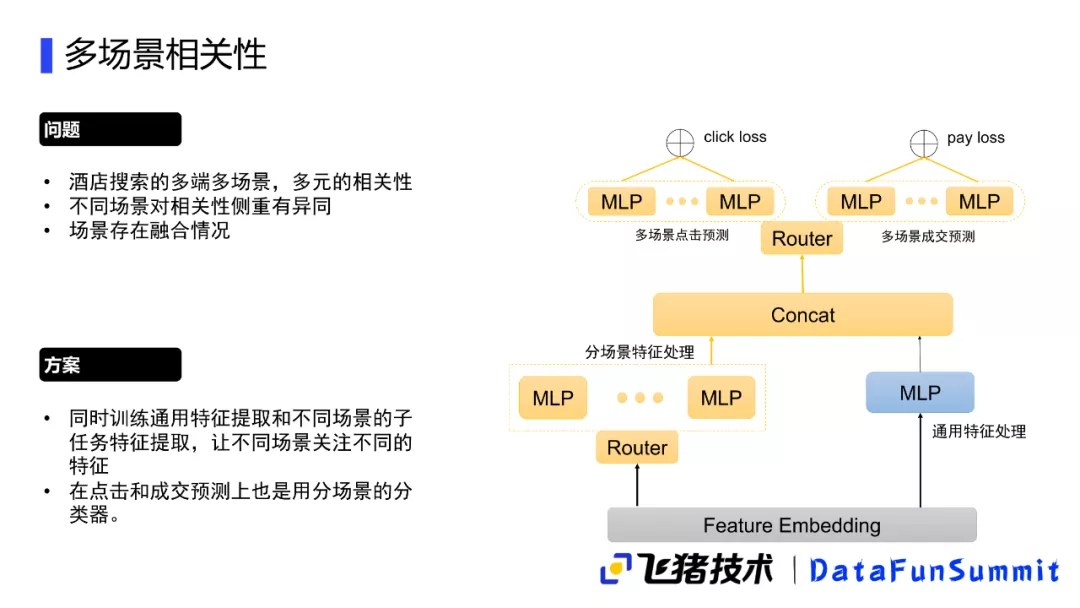
前面也提到,酒店预定的相关性是比较多元的多场景,因此它需要做一个多元的融合。因此,我们提出了一种多场景多元相关性的融合方案。我们使用了两种特征处理的MLP来实现这个功能,一种就是通用的特征处理,对所有前面抽到的相关性特征,以及酒店固有的一些属性特征,进行一个通用特征处理,得到一个特征向量;另外我们通过前面QP阶段识别到的不同场景,比如商圈搜索、附近搜索、名称搜索之类的场景进行划分,通过一个路口可以走不同的场景来进行MLP的特征抽取,这样可以让这两个特征抽取网络侧重于不同的特征。特征向量是分配的,在进行预测的时候也会通过不同的场景,用不同的预测网络进行点击以及成交的预测,这样就可以学到一个统一的模型来处理不同的场景,并且还能比较好地处理一些场景融合的问题。
4. 详情页特征
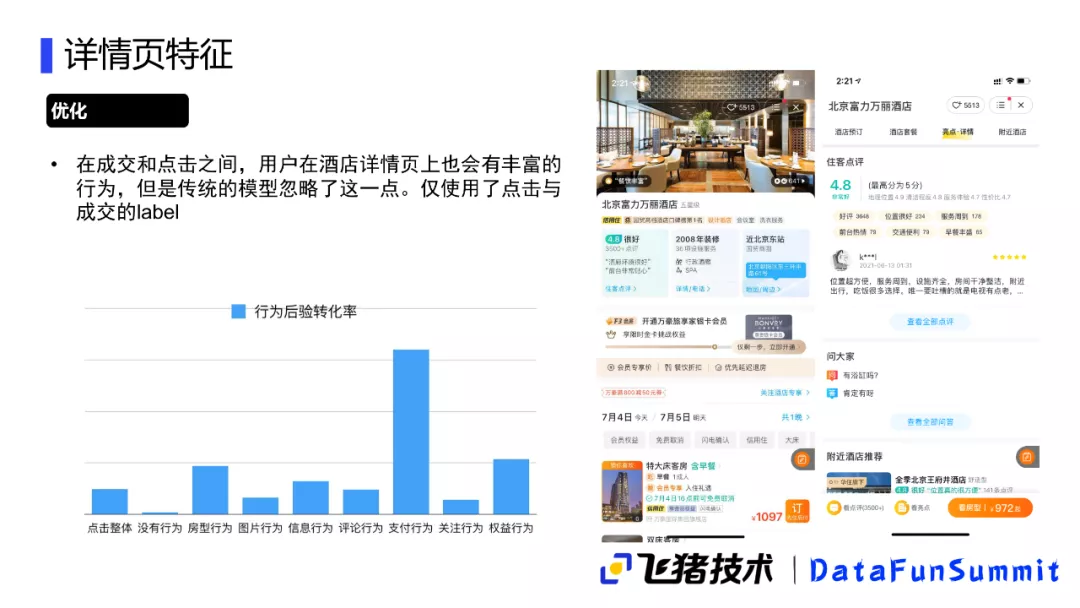
最后介绍对其他相关性的一些优化,前面也提到由于标注的难度,我们主要依赖用户点击�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%98%BF%E9%87%8C%E9%A3%9E%E7%8C%AA%E6%9E%97%E7%9D%BF%E4%BB%8E%E6%A0%B8%E5%BF%83%E5%9B%A0%E5%AD%90%E9%A2%84%E4%BC%B0%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB%E5%A6%82%E4%BD%95%E5%AE%9E%E7%8E%B0%E6%96%87%E6%9C%AC%E5%92%8C%E7%A9%BA%E9%97%B4%E7%9A%84%E6%90%9C%E7%B4%A2%E7%9B%B8%E5%85%B3%E6%80%A7/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


