阿里飞猪搜索技术的应用与创新
分享嘉宾:林睿 阿里飞猪
编辑整理:杜正海、Hoh
出品平台:DataFunTalk
导读: 旅行场景的搜索起初是为了满足用户某种特定的强需求而出现的,如机票、火车票、酒店等搜索。这些需求有着各自不同的特点,传统的旅行搜索往往会对不同业务进行定制化搜索策略。随着人工智能技术的不断发展,用户对产品的易用性提出了更高的要求。旅行场景的搜索逐渐发展为一个拥有旅行定制搜索策略的全文检索引擎。本文将为大家介绍阿里飞猪在旅行场景下搜索技术的应用与创新,主要内容包括:
- 猪搜背景
- 基础建设
- 召回策略
- 思考总结
01 猪搜背景
1. 飞猪搜索
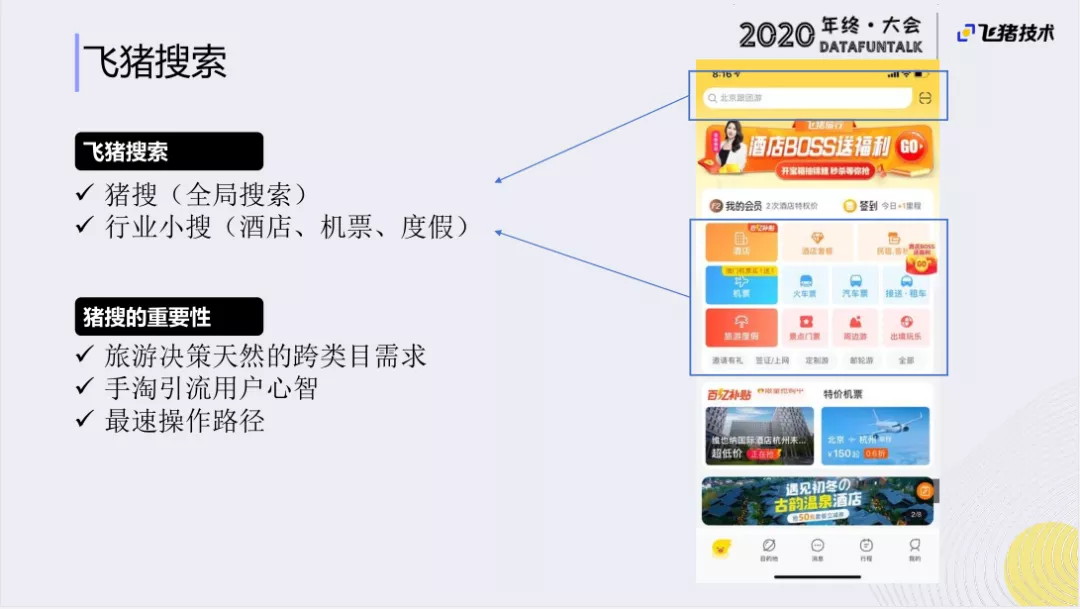
飞猪搜索业务分为两大部分:一是全局搜索,二是行业小搜。右边飞猪界面的全局搜索就是最上方的输入框。直接对应飞猪内部所有内容的搜索入口,都可以从全局搜索获得。右图中间部分就是产业小搜的垂直入口。比如搜索酒店机票和旅游度假产品,一般用户会使用行业小搜,垂直搜索需求。随着飞猪业务的发展,以及用户需求的变化,流量会从行业小搜逐渐迁移到飞猪的全局搜索上。主要是因为:
- 旅游行业是一个跨类目的需求。用户天然的需要定机票、酒店以及一些网络的门票,如果全部通过垂直搜索,需要进行多次点击,对用户来说不是很方便。
- 飞猪很多流量是由手淘引流过来的,手淘是一个全局的搜索。所以用户会习惯性的使用全局搜索来满足他的需求。
- 对用户来说,用全局搜索的操作是最方便的,路径最短。
2. 猪搜框架
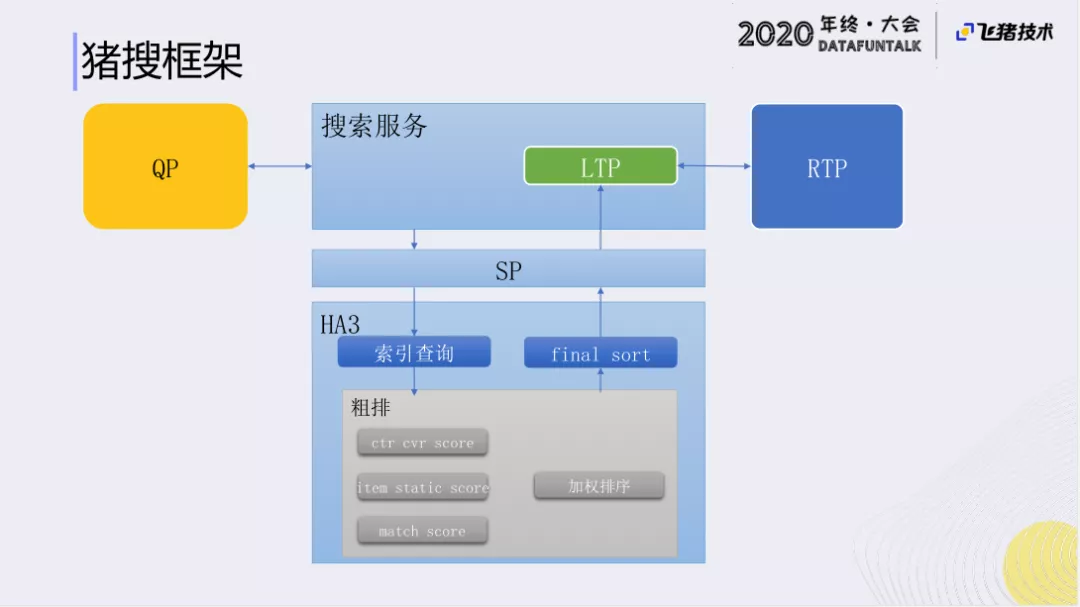
猪搜框架如图所示,首先通过调用QP来获得当前的Query理解,以及需要召回的Query生成,然后通过SP分页服务调用HA3倒排索引来获取召回的结果。通过粗排序和加权排序将结果通过LTP服务做重排序,最后将得到的结果展示给用户。这里主要介绍下QP的工作。
3. QP
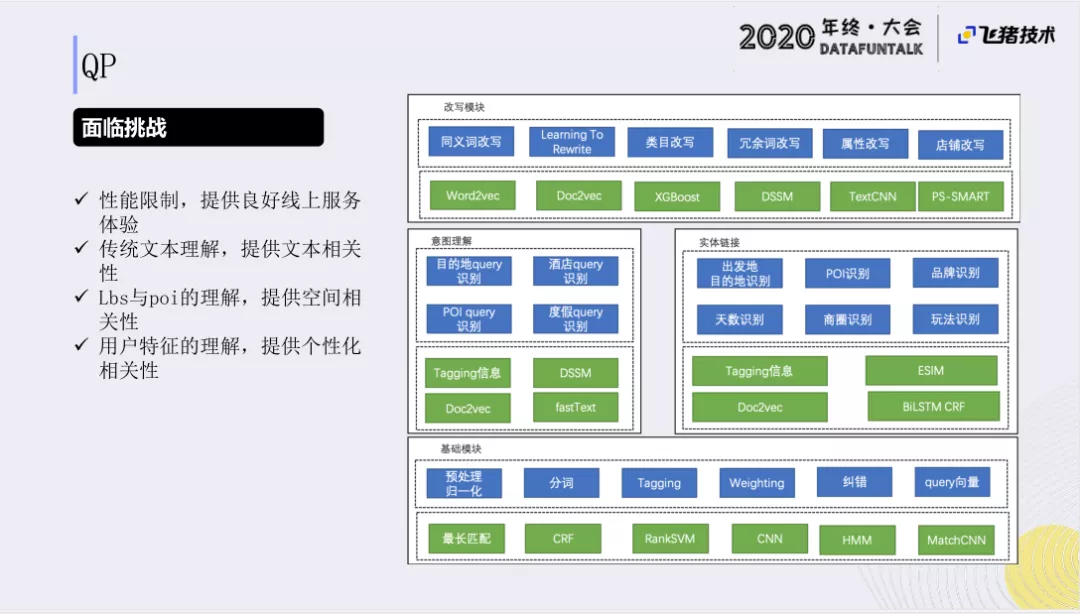
QP即Query理解与召回生成服务。在这个服务中,我们面临的挑战主要有:
- 性能限制:在业界,通常QP阶段只占用整个线上响应时间的1/10。所以,对性能要求比较高,响应时间不能过长,需要提供良好的线上服务体验。
- 文本理解:我们的QP和其他的全局搜索QP一样,也需要做传统的文本理解,提供文本相关性的能力。
- 独有挑战:在旅行场景下,会有一些特殊的要求。比如LBS与POI的理解能力,能够提供空间上的相关性。
- 特征理解:从业务发展角度,我们还需要用户特征的理解,可以提供个性化的相关性,来满足用户的需求。
02 基础建设
接下来,为大家介绍下飞猪在具体基础建设上的一些工作。
1. Query tagging
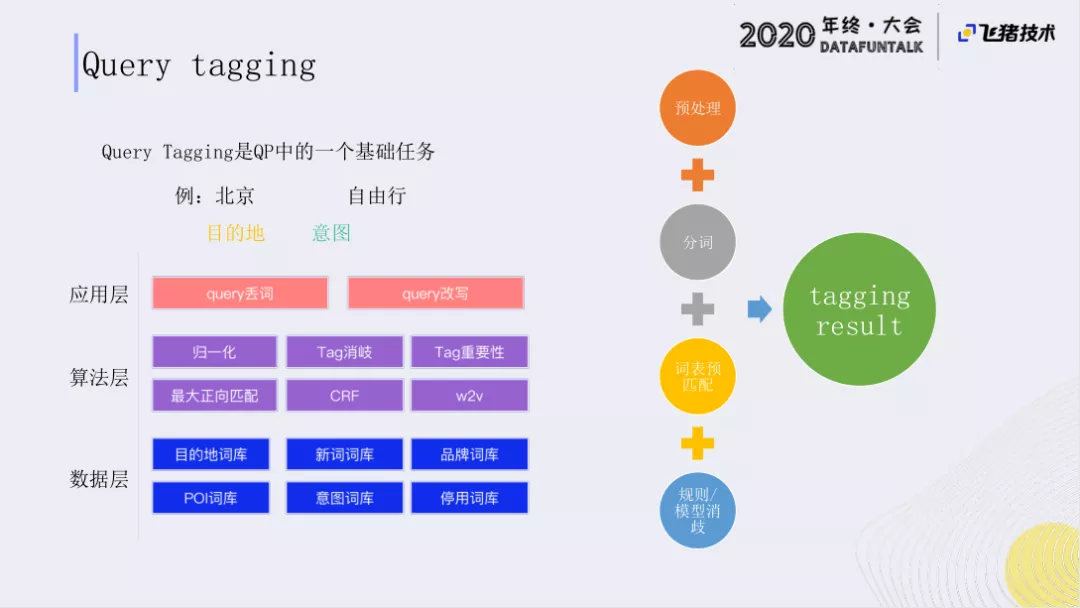
Tagging是QP中的一个基础任务。负责的功能是把一个query 打出目的地和意图。举个例子,“北京自由行”中“北京”就是用户的目的地,“自由行”是用户的意图需求,可以看出用户希望的是一个自由行的商品,而不是跟团游这类的产品,可能会更希望获得一些机票+酒店或者是无购物的产品。
这里的工作,主要分为以下几层:
- 数据层:通过离线挖掘出tagging词库。
- 算法层:通过Tag消歧、CRF等算法进行在线打标工作。
- 应用层:在tagging上的一些应用,如query丢词和query改写。
由于线上性能的限制,我们主要依赖于离线的挖掘。这里以我们内部比较重要的商品POI挖掘为例,来介绍下我们离线挖掘tagging 的工作。
2. 商品POI挖掘
① QueryTagging
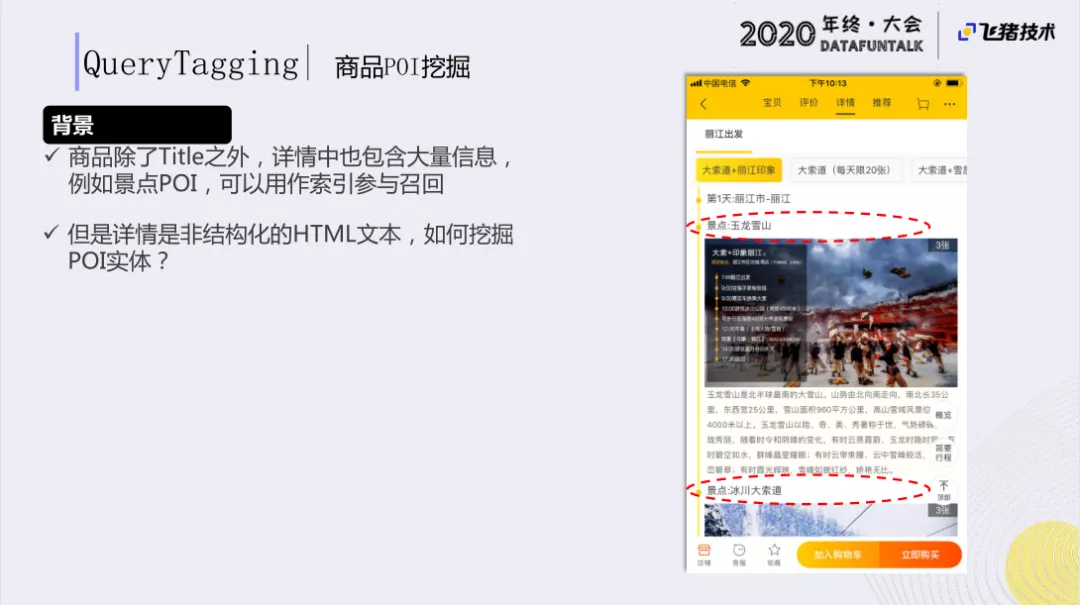 POI的挖掘除了商品title 可能会有一些景点信息外,详情也会包含大量的信息。因此,我们需要从这些内容中挖掘出有价值的信息,来扩充词表。例如图中的景点POI,可以用作索引参与召回,但是详情是非结构化的HTML文本,要挖掘POI实体,会有比较大的难度。
POI的挖掘除了商品title 可能会有一些景点信息外,详情也会包含大量的信息。因此,我们需要从这些内容中挖掘出有价值的信息,来扩充词表。例如图中的景点POI,可以用作索引参与召回,但是详情是非结构化的HTML文本,要挖掘POI实体,会有比较大的难度。
② 建模方式
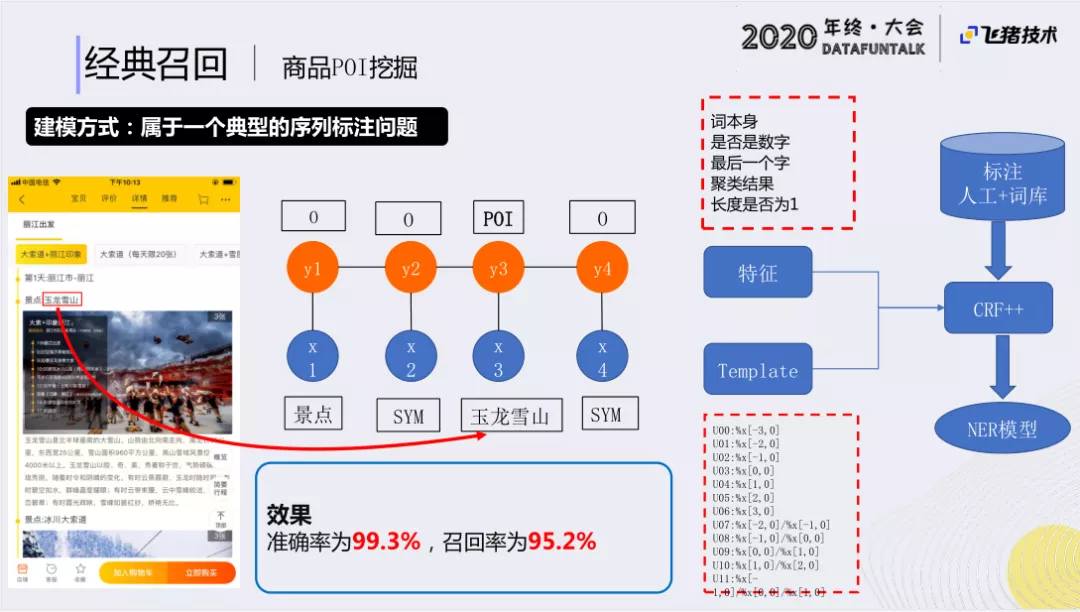
我们采用了典型的序列标注问题来解决这个问题。我们通过一些特征,如词特征、数字特征、类目特征,进行筛选,通过人工标注来训练我们的CRF++模型。后续我们还升级成了Template下的模型来训练NER模型,使我们可以在离线,对接了大量的文本数据,进行序列标注。最终,我们达到了99%以上的准确率,召回率也超过95%。扩充了大量的没有挖掘出POI商品/POI特征的度假商品,使它们产生了POI的特征,可以更好地为后续的POI及检索做出服务。
3. 同义词挖掘
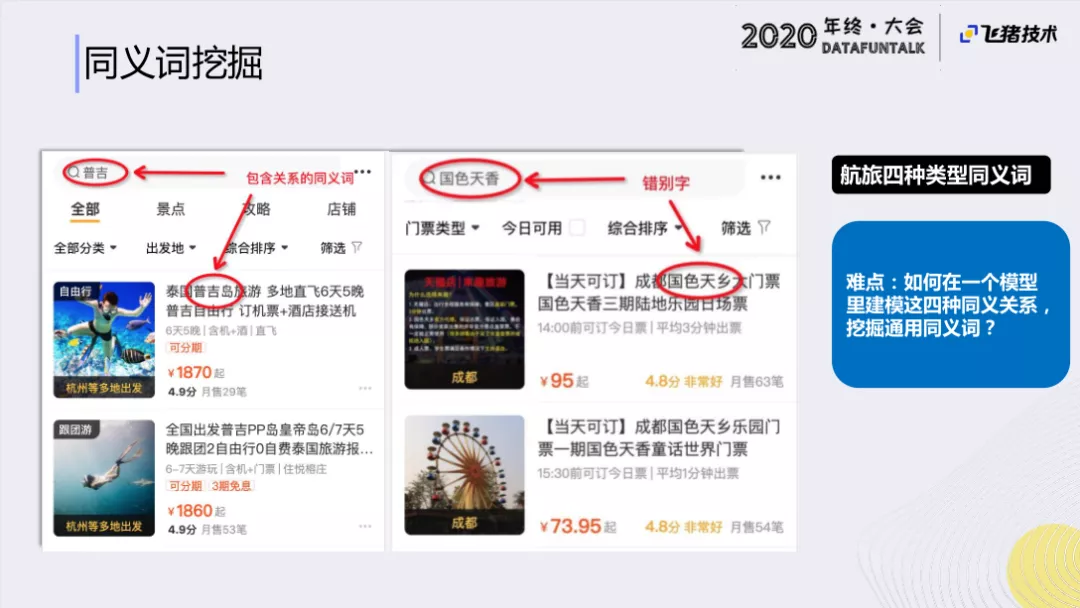
在旅行行业,存在四种类型的同义词:
- 翻译类:如“迪斯尼”,可能有不同的中文描述方式
- 中英文词:有的用户用英文来描述,而有的用户用中文来表述,但是商家描述的title是英文
- 包含关系:比如“普吉”和“普吉岛”,可能“普吉”这个POI是“普吉岛”这个大POI下的子POI
- 错别字:比如“国色天香”,在图中应该是“国色天乡”
我们希望可以用一个通用的模型来解决这种同义词关系。
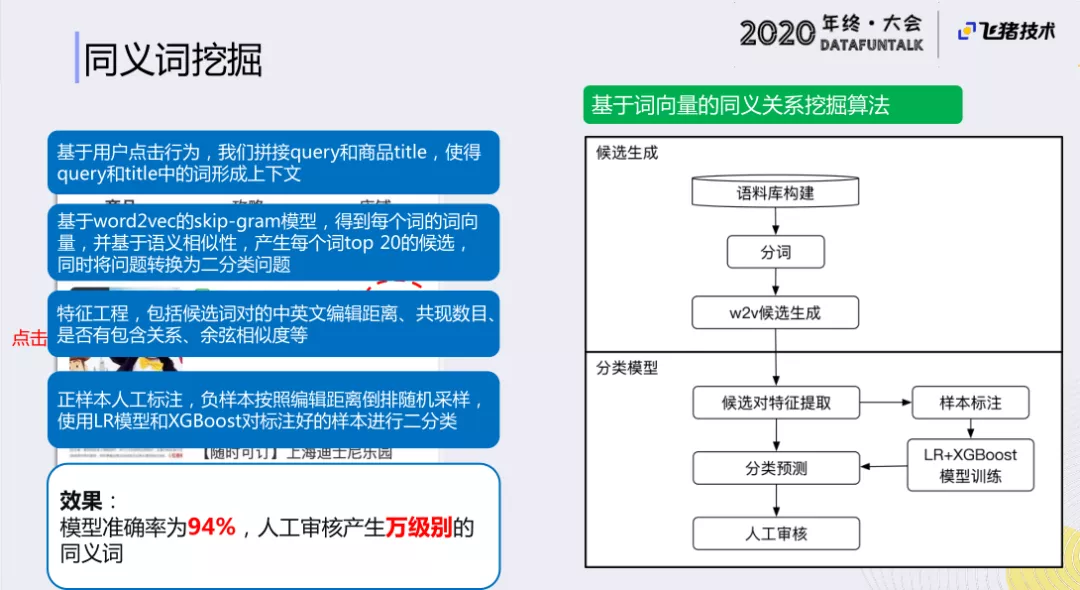
我们的办法是基于用户点击行为,拼接query和商品title,使得query和title中的词形成上下文,然后基于word2vec的skip-gram模型,得到每个词的词向量,并基于语义相似性,产生每个词top 20的候选,同时将问题转换为二分类问题。
另外,在特征工程上,我们会利用中英文的编辑距离、共现数目以及是否包含关系、余弦相似度等来构建特征。
然后,我们通过人工标注来构建正样本,负样本按照编辑距离倒排随机采样,使用LR模型和XGBoost对标注好的样本进行二分类。
最后,我们还会经过一层人工审核,因为同义词的影响面积比较大,如果直接通过算法挖掘,在线上的效果可能不会特别好。所以我们没有采用复杂的模型,只是够用就可以了。这样在万级别的人工标注上,我们的准确率可以达到94%。
4. 纠错
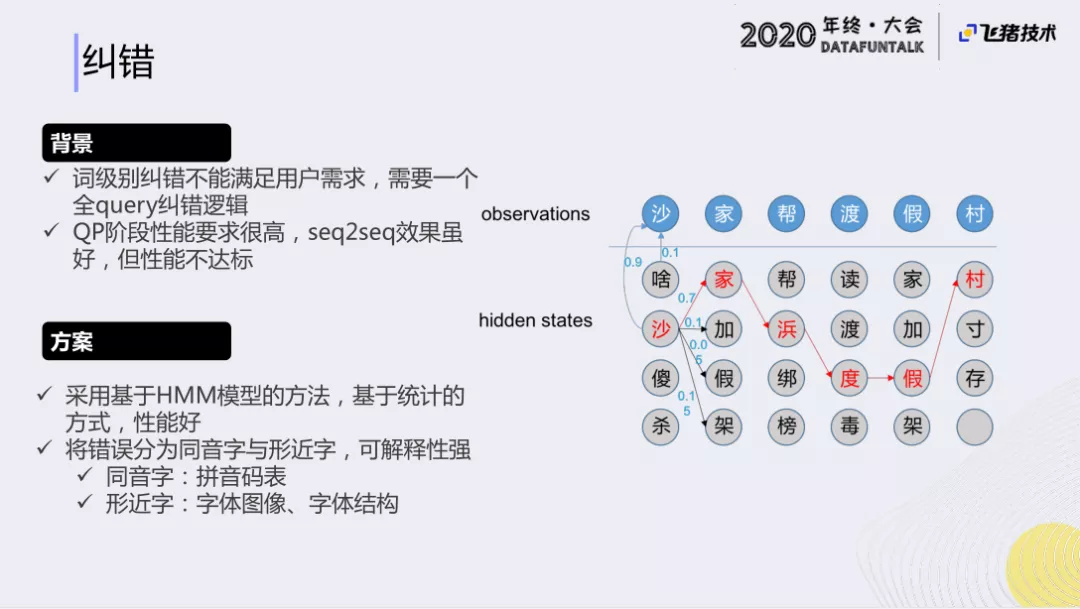
① 背景
对于纠错,刚才提到了词级别的错误,事实上,整个Query中也会出现一些错误。只用词级别的纠错,不能满足用户需求,需要一个全query纠错逻辑。
由于QP阶段对性能要求很高,现在业界常用的seq2seq方法,虽然效果很好,但整体性能不达标。我们可以在离线利用seq2seq来挖掘高频的信息,但在线上很难应用seq2seq的方法来做纠错。
② 方案
我们的方案是采用传统的隐马尔科夫模型,基于统计的方式来做,能够达到线上的性能要求。将错误分为同音字与形近字,可以获得比较强的可解释性。
- 同音字:因为汉字都可以查到拼音码表,我们可以很容易的构建一个同音字的集合,然后通过一些统计的方式,就能获得同音词生成概率。
- 形近字:比较难获得,因为很难判断两个字是否有些相似。我们这里,通过字体图像和字体结构来解决的。
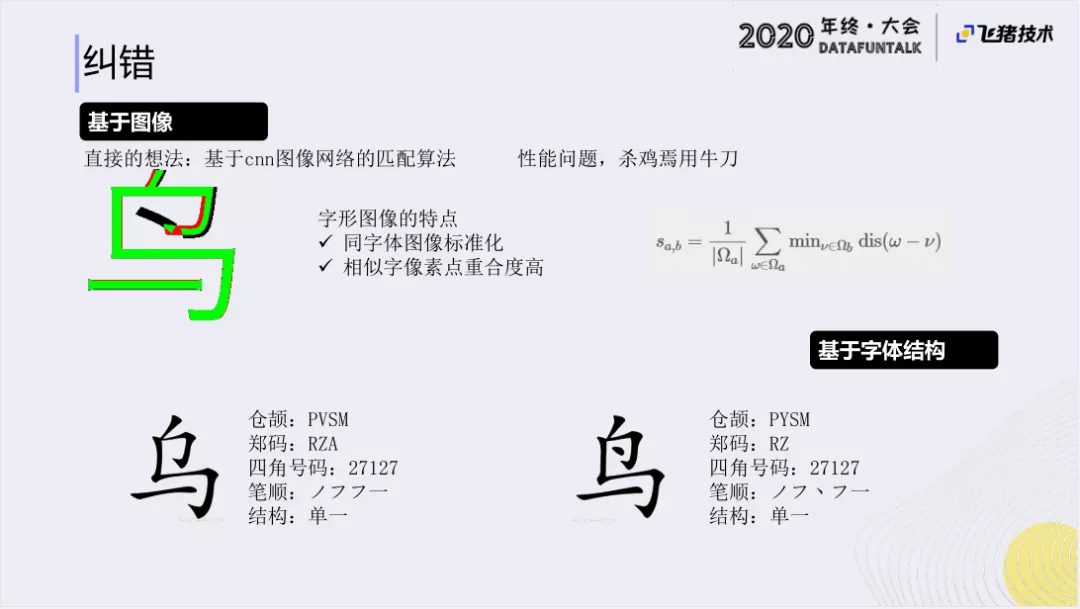
③ 基于图像
说到基于图像的方式,最直接的方式就是基于CNN图像网络的匹配算法。但是出于性能方面的考虑,这种方法的效果往往达不到我们的性能要求,所以我们采用了一个比较简单且有效的方法,就是我们直接对两个可能形近的字的图像进行计算。对形近字而言,我们在标准的字体库中,发现它有两个特点:
如鸟和乌两个字,在字体库里的图直接对比,它们的重合度是非常高的,由于字体库里的字,它的标准化程度是很高的,可以通过这种方式来进行计算。我们这里基于图像的方式,就是采用我们对字体库里的两个字来进行每个点的一个具体的计算。
另外,对于鸟和乌这个字,鸟这个字的每一个点在乌字上找到和它最近的一个点,作为这两个点相似度,那对于每一个点,我们都可以找到一个距离,然后通过求和的均值计算,我们就可以得到这个两个字距离的相似度。
通过离线对两个字以各自的图像进行计算,那就可以获得比较相似的一些字。
④ 基于字体结构
另外,我们还会通过字体结构的方式来进行计算。像仓颉、郑码、四角号码的编码,是基于这个字的情况来做的编码。对于俩个形近字,它们的仓颉码、郑码、四角号码往往也会比较相似。所以,我们通过序列的相似计算,可以获得这两个形近字的相似度,然后通过相似度进行阈值计算,就可以得到字形相似的集合。
03 召回策略
接下来为大家介绍下飞猪在召回策略上的一些技术:
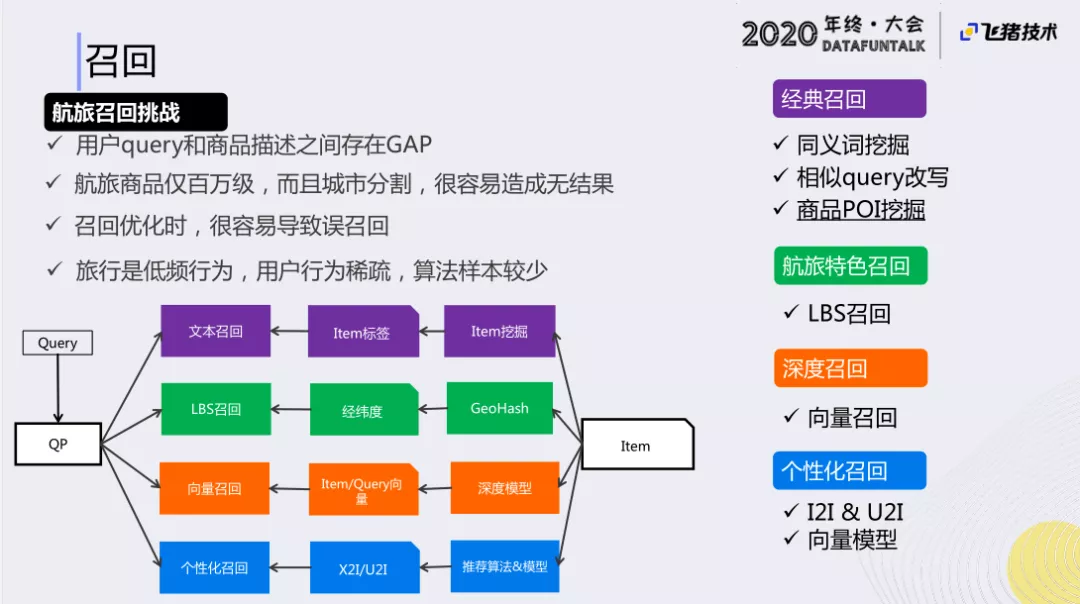
航旅召回跟常用的搜索召回有相似的地方,也有不同,面临的挑战主要有:
- 用户query和商品描述之间存在GAP
- 航旅商品仅百万级,而且城市分割,很容易造成无结果
- 召回优化时,很容易导致误召回
- 旅行是低频行为,用户行为稀疏,算法样本较少
鉴于这种情况,我们对用户的召回分成了以下四种召回方式:经典召回(同义词挖掘、相似query改写、商品POI挖掘)、LBS召回、向量召回、个性化召回(I2I&U2I以及向量模型),来满足用户的需求。
1. 经典召回
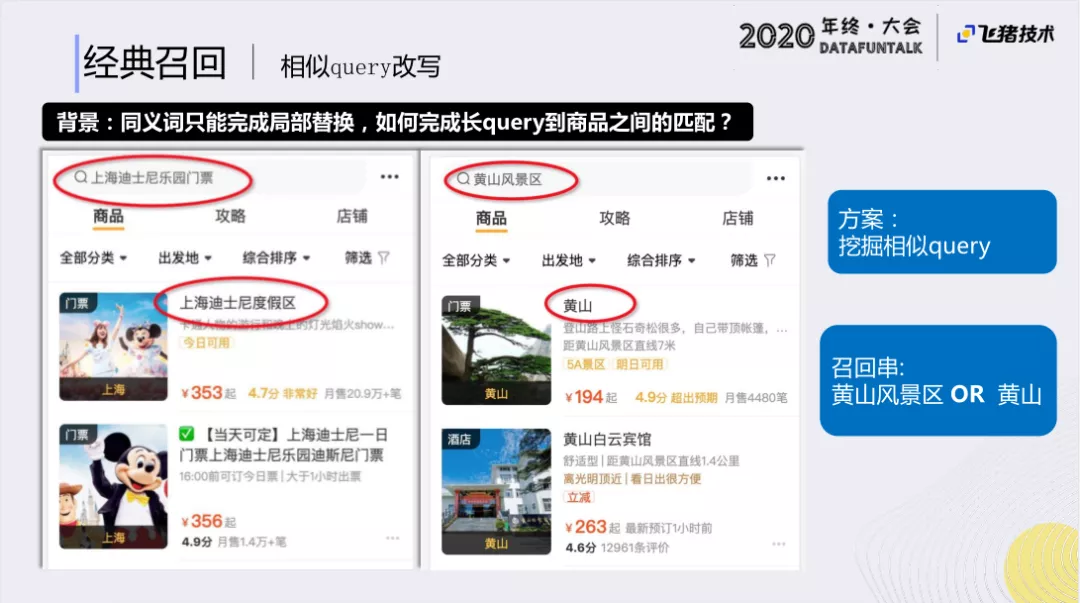
刚刚已经介绍过同义词挖掘和商品POI挖掘,这里主要介绍下相似query改写。以“上海迪士尼乐园门票”为例,其实标准的商品是“上海迪士尼度假区”,而“黄山风景区”的标准商品其实是“黄山”。在这样的情况下,如果我们直接创建搜索,可能召回的效果比较差。因而,我们会进行一些相似query挖掘,来满足这种query和title GAP的情况。
Learning To Rewrite:
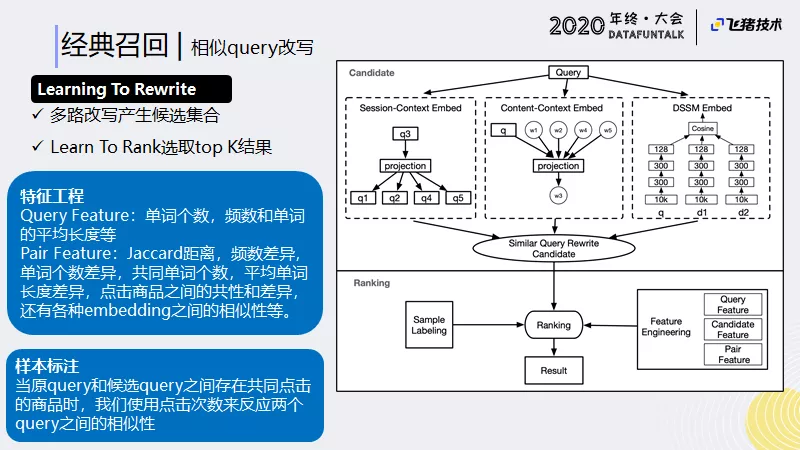
我们思路是使用多路改写产生候选集合,然后用learning to Rank 选取top K结果。
首先假设用户在筛选中输入了query,这个query是比较相似的。因为用户在筛选中是想要获得他想要的结果。如果用户第一个query,没有得到想要的结果,用户会进行一些改写。就相当于用户帮助我们完成了一次改写,我们从中可以学到用户改写的信息。这里我们是用类似word2vec的模型实现的。
另外,从query相似度来看,我从文本上也可以获得一个相似的query文本。这里我们采用的是doc2vec模型,来获得文本相似性。
最后,通过query和title点击,可以训练一个双塔结构的语义相似度模型,来获得query和title相似性的特征。
通过这三种方式,我们可以获得想要的相似query改写的候选。
对于候选,通过一些人工标注及线上的埋点信息,来获得原query和候选query相似的标注。这样我们就可以训练一个模型来进行相似query的排序工作。
最终,我们线上使用的模型是PS-SMART 模型。加上规则过滤之后,准确率可以达到99%。可以影响线上36%的PV,对一次UV的无结果率可以相对降低18%。
2. 航旅特色召回:LBS召回
 由于用户是在旅行场景下搜索,用户天然会需要LBS 相关的信息。如果是差旅用户,可能会定阿里巴巴园区附近的酒店,如果是旅游用户,可能会定黄山风景区附近的酒店。这就需要识别用户想要的商品大概在什么样的LBS范围内。解决的方法是通过对query中用户POI的识别,获取用户的经纬度,进行召回上的限制。
由于用户是在旅行场景下搜索,用户天然会需要LBS 相关的信息。如果是差旅用户,可能会定阿里巴巴园区附近的酒店,如果是旅游用户,可能会定黄山风景区附近的酒店。这就需要识别用户想要的商品大概在什么样的LBS范围内。解决的方法是通过对query中用户POI的识别,获取用户的经纬度,进行召回上的限制。
建模过程:
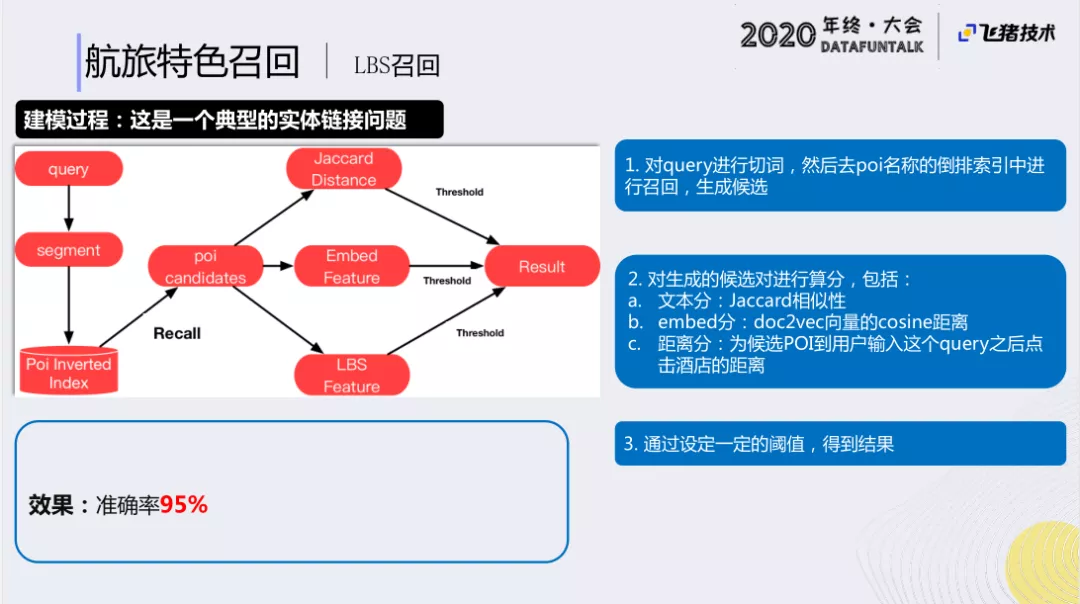
首先会对query进行常规的分词,然后在POI专用的倒排索引库进行检索,获得候选POI。接下来对候选POI query进行特征计算,计算出文本相似性、embedding相似距离,以及用户当前位置输入后,与历史点击的商品地点的距离做特征。然后用特征构建模型算出一个分数,通过一定的阈值得到结果。
最后,我们的准确率可以达到95%,GMV和成交都得到了一定的提升。
3. 深度召回:向量召回
① 背景
前面提到的都是一些简单的文本召回,以及LBS召回等偏传统的方法。前面说过,我们的商品按照目的地切换后,还是很稀疏,还会存在无召回的情况。对于这种情况,我们想到引入向量召回的方式进行补充召回。可以覆盖改写没有的情况,可以召回一些原来不能召回的产品。
② 向量召回整体架构
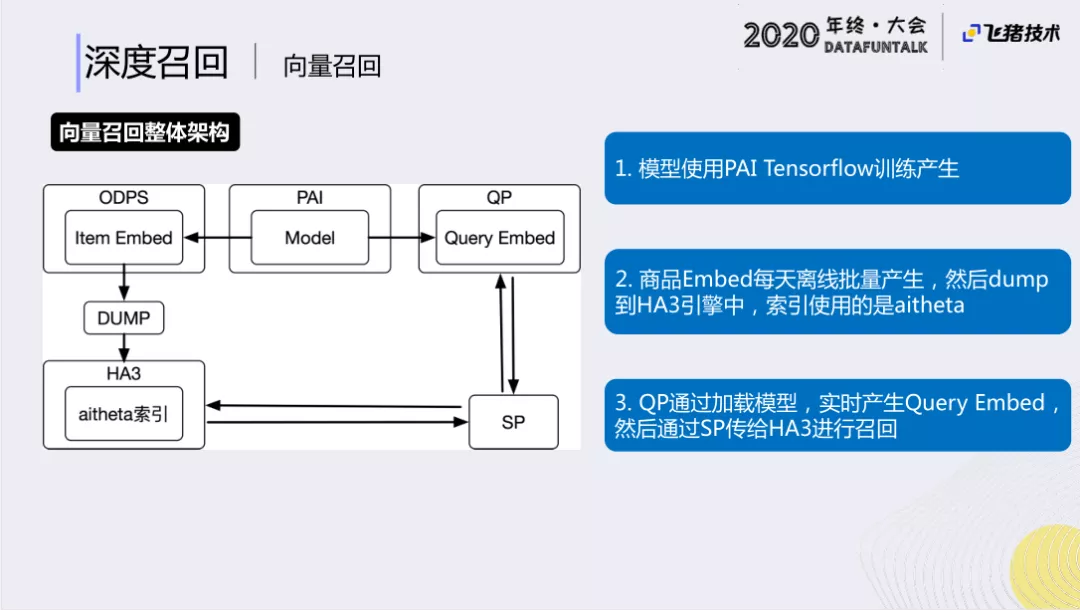
向量召回架构如上图。在线通过对query 进行embedding。离线通过HA3引擎,把所有的item embedding存储到HA3引擎中。最后,SP通过从QP获得query embedding,进行HA3检索,获得需要的商品。
③ 模型结构
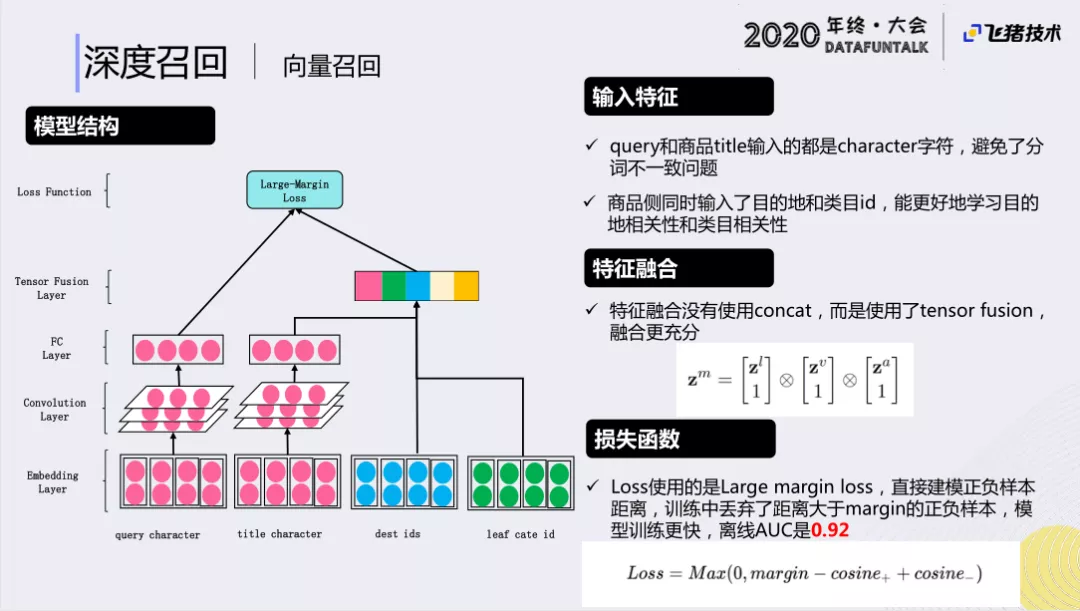
模型结构,如上所示:
- query侧:通过对query的文本,进行卷积层特征抽取。
- 商品侧:我们主要的工作在这里,除了文本上对用户目的地的需求,对商品类目的需求也是比较关注的。所以在商品特征上,使用了商品title文本的卷积特征,以及目的地类目id 的特征。
对这三个特征,我们没有使用简单的concat,而是使用了tensor fusion进行三个向量的外积,可以让特征更好的融合。
最后,通过全链接层进行特征抽取,计算向量内积。
对于损失函数,我们使用的large margin loss。对于学的足够充分的case ,就丢弃掉,不再进行学习,让模型更快的达到我们想要的效果。
④ 样本选择

在样本选择上,我们对正负样本也做了一些探索。
集团内通用的方法:
- 正样本:query下用户点击的商品
- 负样本:未点击的商品
这样的方法更适合在排序上使用,而不太适合召回。以左图为例,用户点击了“上海迪士尼度假区”,未点击的是下面的商品,虽然可能是由于商品的标题标准化比较低,用户未点击,但不能说它是不相关的商品。
我们的方法:
- 正样本:和集团一样,使用点击的商品
- 负样本:随机选取的样本作为负样本
使用随机选择有两方面:一是在全量商品中,进行随机选择;二是在一个类目或者目的地下,进行随机选择。这样可以提升训练的难度,达到我们想要的效果。
⑤ 模型产出与使用方式

最终产出的分数,也给排序使用了,作为排序的一个特征,取得了不错的效果,可以排在第4位。另外,线上召回可以让无结果率降低32.7%。同时,扩充了1.7倍�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%98%BF%E9%87%8C%E9%A3%9E%E7%8C%AA%E6%90%9C%E7%B4%A2%E6%8A%80%E6%9C%AF%E7%9A%84%E5%BA%94%E7%94%A8%E4%B8%8E%E5%88%9B%E6%96%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


