阿里融合与的个性化预估模型

文章作者:阿里B2B算法团队
内容来源:牛技
出品平台:DataFun
背景
以电商场景优化用户点击为例,推荐系统的任务是从海量的候选商品中选出用户最感兴趣且最可能点击的商品。为了提升检索的效率,通常分为两阶段来检索。召回/候选生成(Matching/Candidate Generation)阶段根据U2I相关性从整个候选集中筛选出少量的候选商品(比如1000个),常用协同过滤方法。排序(Ranking)阶段根据排序模型预估这小部分候选商品的CTR,排序后展示给用户。
推荐系统中CTR预估的重要性不言而喻,其中个性化是提升CTR模型效果的关键。本文介绍一种全新的排序模型,主要的思想是融合Match中的协同过滤思想,在Rank模型中表征U2I的相关性,从而提升模型的个性化能力,并取得不俗的效果。
搜索场景中用户通过输入搜索词显式地表达用户的意图,而推荐场景中没有这种显式获取用户意图的方式。用户的意图往往隐藏在用户行为序列中,可以说用户行为序列就是推荐中的query。因此,对用户行为序列进行建模来抽取其中的用户意图就非常重要。DIN[1]以及DIEN[2]等后续工作关注用户兴趣的表征以提升模型效果,而我们的工作在此基础上又往前走了一步,关注U2I相关性的表征。U2I相关性可以直接衡量用户对目标商品的偏好强度。可以理解成从用户特征(用户兴趣表征)到U2I交叉特征(U2I相关性表征)的升级。
表征U2I相关性很容易想到召回中的协同过滤(CF)。I2I CF是工业界最常见的方法,预计算I2I的相似度,然后根据用户的行为和I2I相似度间接得到U2I相关性。因子分解(factorization)的方法更加直接,通过用户表征和商品表征的内积直接得到U2I相关性,这里暂且称这种方法为U2I CF。最近有一些深度学习的方法进入到相关领域:比如I2I CF中有NAIS[7],用attention机制区分用户行为的重要性,和DIN[1]的做法相似;U2I CF中有DNN4YouTube[3],把召回建模成大规模多分类问题,也就是常说的DeepMatch。DeepMatch可以看做factorization技术的非线性泛化。我们根据协同过滤中的U2I CF和I2I CF分别构建了两个子网络来表征U2I相关性。
模型介绍
DMR(Deep Match to Rank)模型的网络结构如图所示。仅仅依靠MLP隐式的特征交叉很难捕捉到U2I的相关性。对于输入到MLP中的U2I交叉特征,除了手工构建的U2I交叉特征,我们通过User-to-Item子网络和Item-to-Item子网络来表征U2I相关性,进一步提升模型的表达能力。
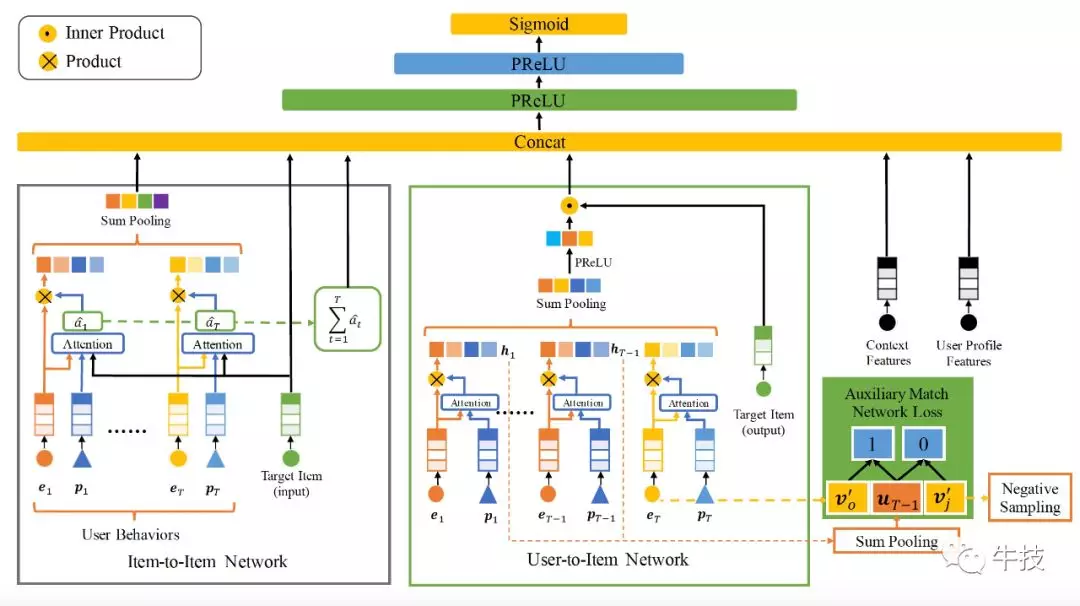
User-to-Item网络
受factorization方法的启发,我们用user representation和item representation的内积来表征U2I相关性,这可以看做是一种显式的特征交叉。user representation根据用户行为特征得到,一种简单的方法是做average pooling,即把每个行为特征看得同等重要。我们考虑到行为时间等context特征对行为重要性的区分度,采用attention机制,以位置编码(positional encoding,参考Transformer[4])等context特征作为query去适应性地学习每个行为的权重。其中位置编码行为序列按时间顺序排列后的编号,表达行为时间的远近。公式如下:
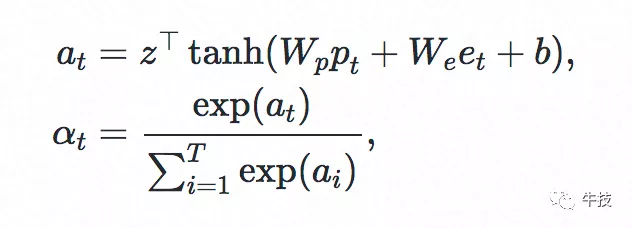

,商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


