阿里文娱深度语义搜索相关性探索

分享嘉宾:闰辰 阿里文娱 高级算法专家
编辑整理:韩佳
导读: 大家都知道视频作为4G以及5G时代最便捷的信息载体。它在给用户带来极大便利的同时也会给搜索带来了更大的挑战。视频不论从制作、存储、计算还是分发,都比文字模态的信息要困难很多。今天分享会从四个方面给大家进行介绍:
- 阿里文娱搜索业务简介
- 相关性和排序
- 多模态视频搜索
- 深度语义相关性的一些探索
01 阿里文娱搜索业务简介
首先和大家分享下文娱搜索业务简介。
1. 阿里文娱搜索业务简介
搜索为整个阿里文娱提供一站式的搜索推荐服务,服务范围不仅包括优酷的全部的搜索入口,比如APP端、OTT大屏端、PC端还有网页端等等,还会涉及到大麦、淘票票等领域。涉及的检索内容从传统的影剧、动漫这些有版权的长视频影视库之外,还会覆盖社会各个领域的UPGC的视频内容,此外比如影人、演出、小说也都是大文娱搜索各个业务领域的需求,需要提供检索服务。
以用户为例,平台有亿级别的视频资源。不仅包括平台购买的有版权的OGC视频(如节目、电影和电视剧),还包括用户上传的一些UGC视频。
2. 用户价值→评估指标
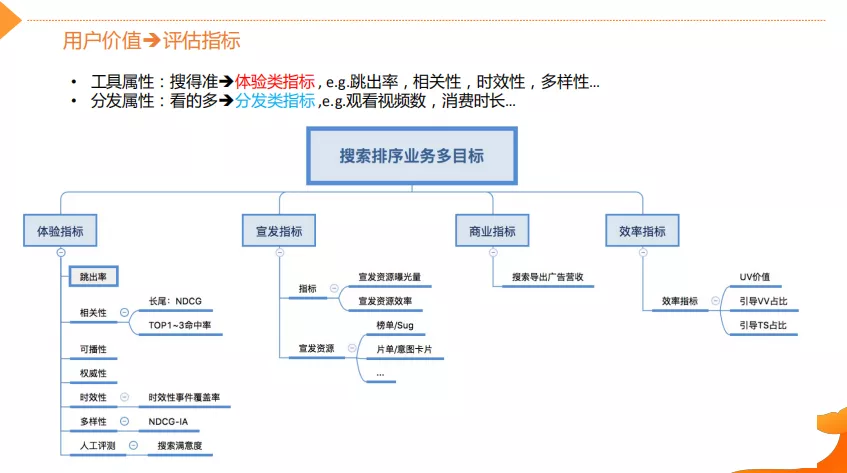
视频搜索技术是怎么做的呢?首先跟大家介绍一下视频搜索里面的用户价值是什么,以及它是如何影响搜索技术的。评估指标的用户价值在这里主要体现在两个维度。
第一个是工具属性,即用户将搜索服务作为寻找内容的工具,目标就是找准找全。
搜得到搜得准,既是用户价值的基础也是搜索的基础属性。从这个维度去评估搜索效果的好坏,就需要一系列的体验类的指标(跳出率、相关性、时效性和多样性等等)。可播性是视频搜索特有属性,是指视频能不能在优酷平台上进行播放。受内容版权以及监管方面的原因,有些内容是不可播放的。此外,还会定期去通过人工评测的方式来对搜索效果满意度做横向以及纵向的对比。
第二个是分发属性,即如何能让用户在平台消费更多的内容,带来更多的收益。
这里说的更多其实有两个维度的,第一个是观看的视频数VV,第二个是消费时长PS。这两个指标对于视频的垂直搜索领域是非常重要的,因为它直接衡量着用户的满意度。对于平台来说,搜索还需要能支持平台的宣发以及实现广告和会员等商业价值。这些属性决定了视频搜索业务是一个多目标优化的任务。
3. 搜索算法框架
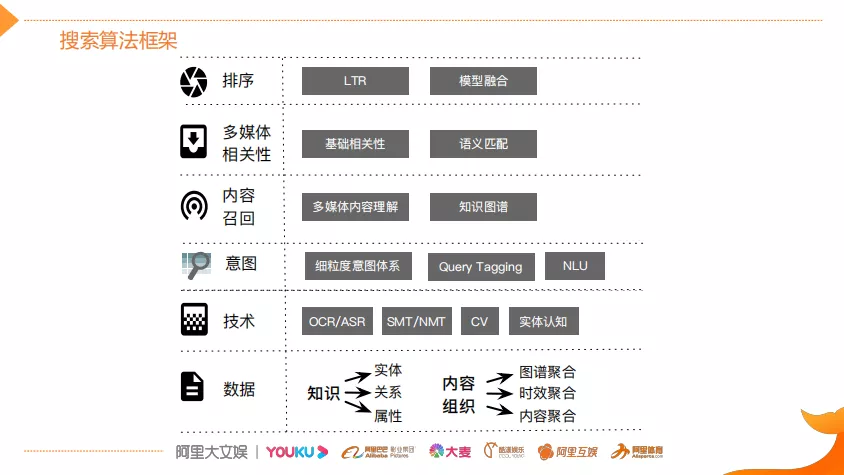
这里给出了搜索的算法框架,从上从下到上依次是数据层、基础技术层、Query的意图层、内容召回层、相关性层以及排序层。这个框架是比较high level的,先大概介绍不会涉及细节,希望大家能够大概理解视频搜索的关键技术全貌,将与后面内容关联比较紧密的内容在这里重点介绍,方便对后面内容的理解。
- 数据层:其最基础的是视频的内容,从视频内容中会抽取出相应的知识包括实体、关系和属性(比如一个节目它的演员是谁?它的角色是什么?它是哪一年发行的?)通过内容组织的方式做图谱的聚合,例如基于事件维度做时效性的聚合。
- 基础技术层:在数据层基础之上,利用基础的CV技术以及NLP能力来支撑上层对Query意图的理解、内容的召回以及后面的相关性和排序。意图层需要理解用户Query的意图是什么。首先对Query做成分的分析(Query Tagging),Tagging就是说标明Query中各个成分是什么意思(比如“步步惊心吴奇隆”这个query,需要识别出“步步惊心”是一个节目名,“吴奇隆”是一个人)。然后基于这些信息建立细粒度的意图体系,对用户表达的意图做深层次的理解(比如需要理解用户的query是想找节目的意图,还是看人物的周边信息以及通用的知识类的意图),基于这些意图可以去指导上层的召回相关性排序。
- 召回层:涉及到的多媒体内容理解是视频搜索的重点,因为和传统搜索不一样,视频内容它传递的信息是非常丰富的,很难用标题的短短十几个字精准的刻画,而且用户在检索的时候,因为口语化他需求的表达其实是差别非常大的,这就存在着天然的语义鸿沟或者说是知识鸿沟,所以不能把视频当作一个黑盒子,而需要利用NLP的能力、CV的能力以及其他的技术能力对视频的内容做一个全面的分析结构。
- 相关性:涉及到的主要就是基础的相关性以及语义匹配的一些技术,还有后面重点介绍的深度语义相关性计算。
- 排序层:主要按照前面提到的体验和分发这两个维度去整体提升搜索效果。排序它主要是用到机器学习的Learning to Rank的一些模型去提升分发效果,同时还要优化体验类的目标,比如说时效性多样性等等。它是典型的多目标优化任务。
02 相关性和排序
下面重点介绍一下相关性和排序,这两大搜索的核心模块。
1. 搜索相关性-挑战
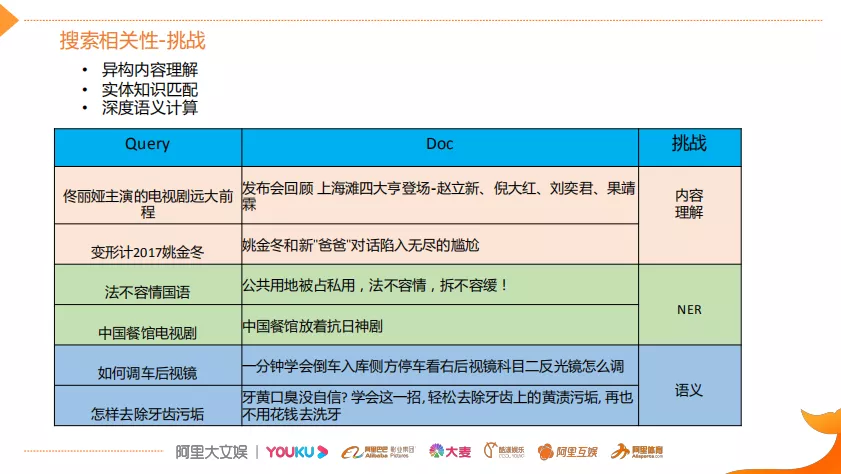
相关性的定义为给定一个用户的Query和一个文档Doc判断Query和Doc是否相关。相对于通用搜索而言,视频搜索存在了三大特殊的挑战,如下:
- 异构内容理解:表中的两个帖子,用户Query和视频标题Doc从字面上来看,是不相关。通过对视频内容进行理解,丰富元信息,建立异构内容的相关性。(比如,用户Query“变形计2017姚金冬”,Doc中只有姚金冬,实际上通过视频内容的理解可以知道姚京东和变形计的关系,同时知道是2017年拍摄的。)所以通过对内容理解和IP指纹,比如把IP周边的这种视频和IP本身关联起来,就能够丰富视频的元信息,提升异构内容的相关性匹配度。
- 实体知识匹配:视频存在大量的领域知识,需要利用知识对视频内容(如:标题内容)进行结构化理解。用NER抽取出标题的实体、CV技术辅助提升其识别准确率。(比如,用户Query“法不容情国语”,Query端通过成分分析得到“法不容情”是一个节目名。但是,Doc端用户上传的是一个社会现象,需要对Doc端进行结构化的理解,可以推理出Doc端的对“法不容情”的理解并不是说的一个节目。)基于这些信息,在相关性匹配的时候,就可以利用这种先验知识来做更好的判断,决定最终的相关性。
- 深度语义计算:这个挑战其实是在通用的搜索领域也会遇到,但是,视频搜索领域它的领域挑战更大,因为它更多的需要结合知识,还有视频内容的理解去联动,才能更好的解决。这个在后面会详细介绍。
2. 搜索相关性
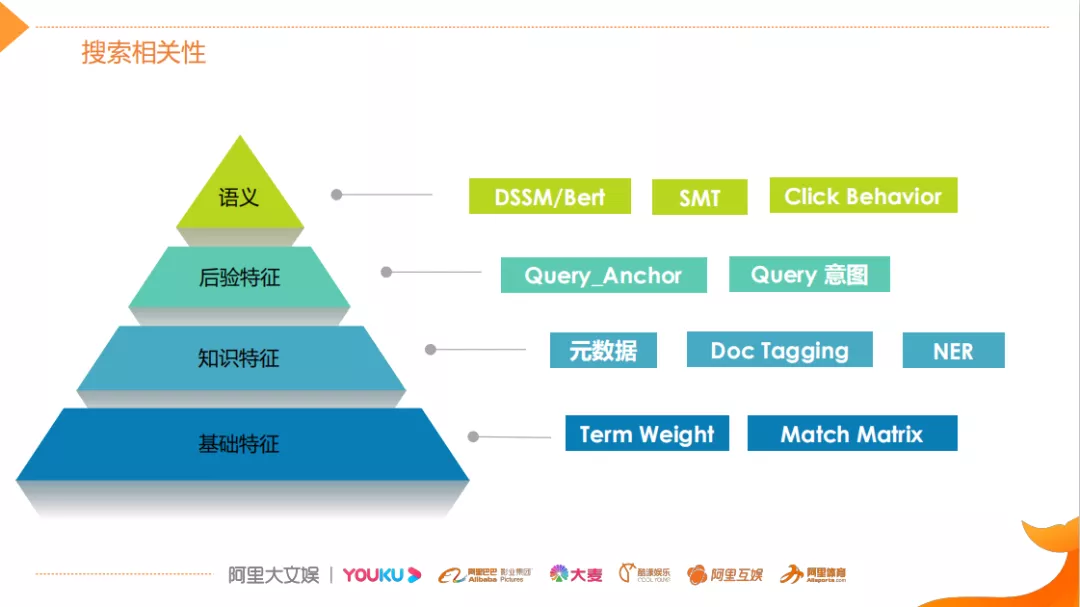
对于搜索相关性而言,通用解法主要从四个维度展开,具体内容如下:
基础特征:即基于文本的字面匹配,包括Term Weigh和基于Term级别匹配矩阵。
- 知识特征:主要是通过内容理解以及视频自身所带的元信息进行知识维度的特征抽取,例如视频中人物所关联的节目以及所关联的一些元信息,用来做一些知识类的匹配。其中,Doc Tagging类似于前面介绍的Query Tagging,但它需要综合利用内容理解NLP技术以及关系数据,识别视频中标题的成分。
- 后验特征:后验特征在某些情况下比先验特征(基础特征和知识特征)更加重要,因为用户搜索一个Query之后,用户和搜索结果之间产生交互,比如形成Query和Doc的交互。搜索领域比较常用的交互特征为Query_Anchor,它基于搜索日志中这种用户的共点击行为,从Doc维度去挖掘与Doc相关联的Query,基于Query做后验匹配。
- 语义特征:主要指文本层面的语义匹配。以往利用DSSM双塔模型,近期利用离线或在线Bert语义模型完成离线或者在线的语义计算。除了匹配层面之外,语义特征还可以支持实现召回,通过SMT和Click Behavior(点击行为分析)对Query进行语义扩展,能够扩大召回的范围,更好的进行语义匹配。
3. 相关性数据集构建和特征体系
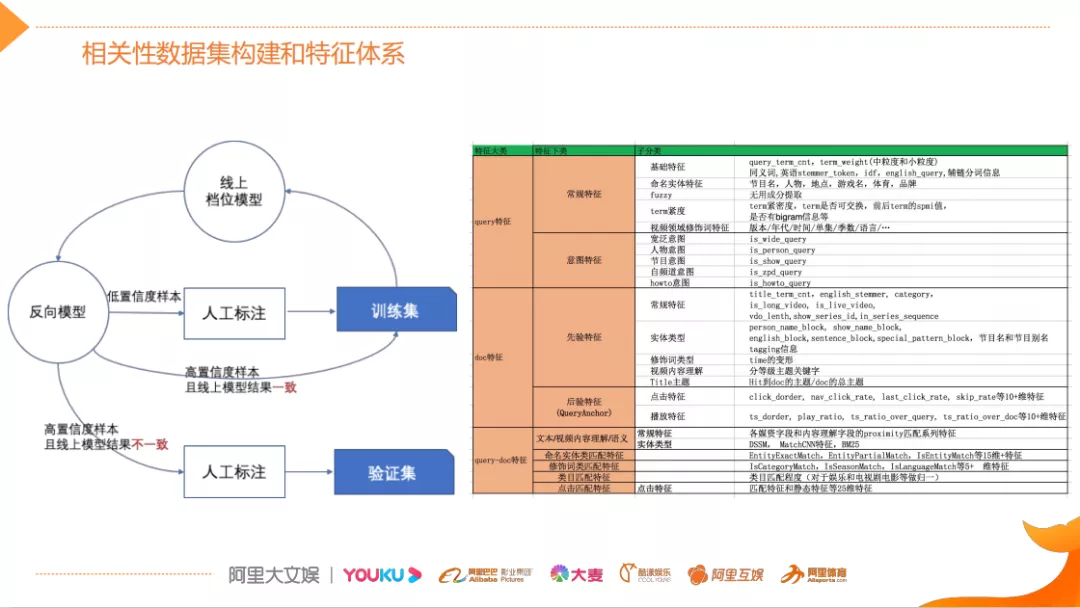
具体做法,首先对相关性的数据进行构建,比较好的办法是通过人工标注来构建相关性数据集,其中标注的规范尤为重要。该数据集一般通过众包的方式获取,因为数据集较大并且必须结合实际业务和用户需求。本文对相关性数据的构建,不仅是希望标注样本的相关性的等级(比如将文档分成完全相关、完全不相关和部分相关三级)还会针对同等级的样本标注它们之间偏序关系或者服务上层的排序,所以标注质量和成本是本文关注的重点。针对成本,需要高效的问题样本自动发现机制,左图展示的基于Q-Learning的思想,它的目的是为了加快标注效率,同时提升标注的质量
本文具体将数据集分成验证集和训练集。验证集主要指针对特定类型的线上的体验问题构建的,有一定的针对性。训练集(回归集)的目的是为了评估算法在针对验证集进行迭代优化的过程中,不会对线上的整体效果有负面的影响。基于训练集去不断的迭代线上模型,对于线上模型预测不是那么准确样本,通过反向的模型对这种问题样本进行挖掘,挖掘出的给外包去标注。这里的挖掘主要是挖掘一些模型的预测结果和线上的指标概括比较大的,这些case就能够形成一个快速的迭代的闭环,提升模型精度的模式,能够大大的提升整个标注的质量和效率。
右图展示了目前相关性的整体特征的划分。最上层的是Query的特征,包含一些常规的字面匹配特征,还有意图相关的一些特征,比如Query是人物意图还是节目意图。中间是文档类的特征,包含一些先验的特征,比如说从文档标题中解构的特征和一些基础的文本匹配特征,除了先验特征更重要的是后验特征,它主要是用来做一些分发类的目标。最下层的是Query和DOC的匹配的特征,分为基础的文本匹配和意图匹配,比如类目的匹配,还有这种知识层面的匹配以及语义匹配。
4. 排序特征体系
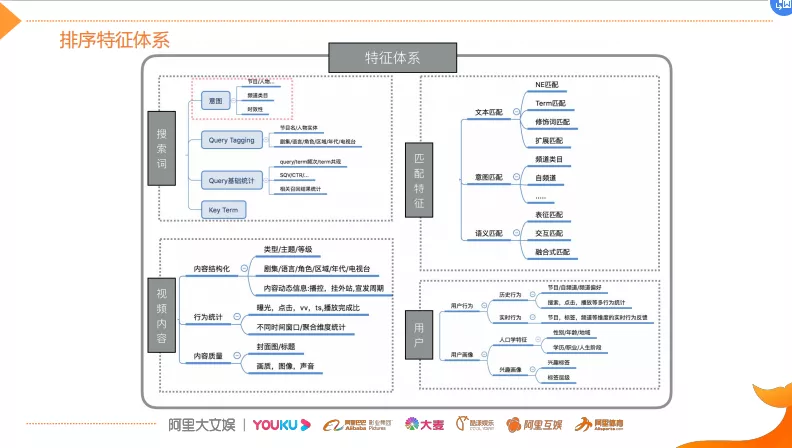
基于相关性的特征,上层排序在特征基础之上做一些整合和丰富。这里主要分为四大块的排序特征体系,那么除了Query和DOC以及它们的匹配特征之外,这些都是各业务领域通用的,比如除了技术匹配类、Query统计之外,还会增加一些视频平台所特有特征,比如说实时播控,它是为了解决排序除了体验目标之外,还要解决分发类的目标,因为它在决策领域很重要。
在视频内容特征组里面,内容质量是比较重要。因为用户每天上传的视频量非常大,所以需要做好内容质量的评估。我们会负责提供高质量视频内容特征,它主要是从封面图、标题、画质、图像等各个模块去评估这种质量。
最后一个是用户的特征,它主要包括一些用户的行为特征,画像特征。它主要是用在一些宽泛的搜索场景中来提升系统的个性化能力,比如说我们这边的频道页的搜索排序,宽泛排序等等。
03 多模态视频搜索
为什么要多模态?
因为基于文本模块的搜索系统,比如说基于标题和描述的文本搜索,它在视频搜索里面会遇到一些困难,首先就是单模态的信息缺失,用户的上传视频的时候,标题往往都比较简单,它很难将丰富的视频内容表达清楚,并且有些文字信息与视频内容是不相关的,此外,用户搜索的意图越来越多元化,即使是版权视频搜索也不在于其中这种节目名字查询,它往往会有更多的社交与互动的需求。还有一些就是去闭塞的需求,也就是这种内容而创的用户,他需要去找各种各样的视频片段素材,那这部分的需求也需要用多模态的技术支撑。另一方面,多模态的好处就在于它能够将语音文字图像和视频等各种模态集成起来。综合多模态的信息来深度理解视频,帮助用户找到真正他们想要的视频内容,做出很多新的搜索体。
1. 多模态视频搜索
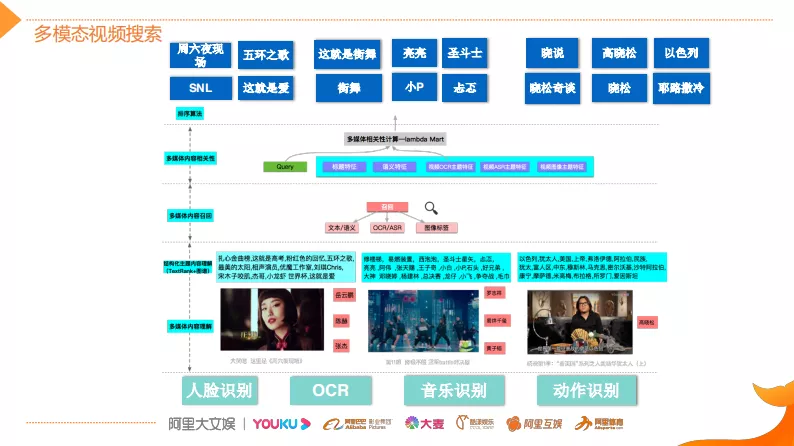
该框架图是用户搜索用到的一个多模态解决方案。目前在工业界和学术界对于多模态的研究热点都非常高,但是学术界往往喜欢端到端的解决方案。比如说将Query和视频映射到一个中间的模态,然后在中间的模式做语义匹配,之后做相似性。这种端到端的解决方案,它对于短小视频的理解肯定是不错的方案,但是针对长视频而言,它很难做到真正准确的理解。因为长视频包含的内容信息是更加多维和更加宽泛的,同时噪音也多。更重要一点,工业界似乎已经对整个系统的可解释性和可控性要求比较高。所以说很少采用单一的端到端的解决方案。
优酷的多模态搜索采用的是一个三阶段的解决方案。第一阶段利用CV技术将其它模态(如图片、视频)的信息降维到一个文本模态,将其做结构化的内容理解。第二阶段通过多模态的内容检索实现召回,在上层通过多模态的内容相关性排序算法达成最终的动态的检索效果,比如上图中《这就是街舞》,基于人脸识别技术能够识别出视频中出现的明星人物(易烊千玺、黄子韬等明星),然后通过OCR和AR技术来识别视频中的对话内容并转化成文本,最后基于文本去做结构化的理解。结构化的文本需要有系统性的理解和组织,本文主要是利用关键词的抽取进行核心概念的理解,并形成内容主题。同时还会利用音乐识别、动作识别、场景识别等等CV技术,来不断丰富视频的结构内容,从而做到在用户做各种组合搜索的时候,系统都能够召回而且排序结果比较好。
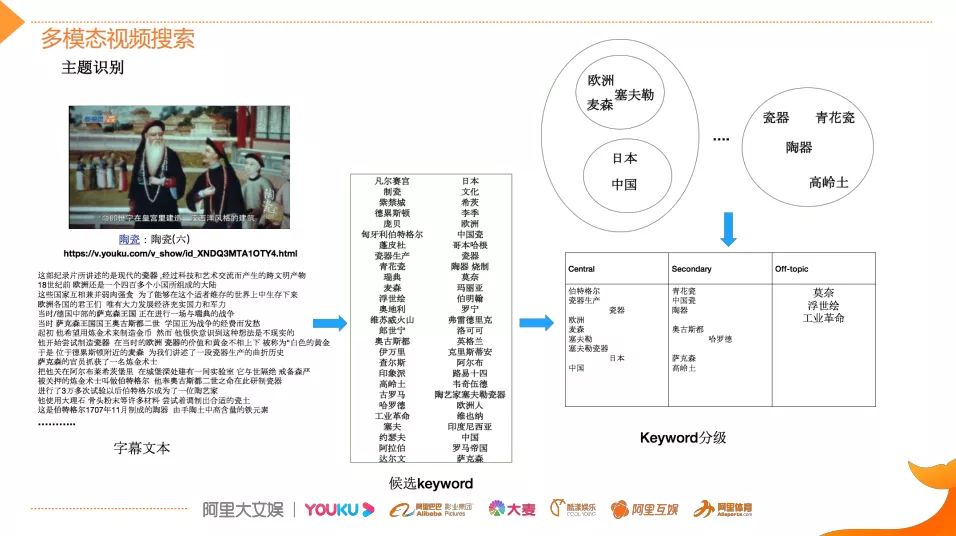
这里有一个案例,通过这个案例来介绍本文在做多模态视频搜索时,是如何提取并且组织内容关键词,在视频内容降维成文本模态之后怎么做好文本内容的组织与理解。
如图,该视频讲的是欧洲陶瓷,但是它的标题非常简单就是陶瓷这几个字,字幕文本是利用OCR技术识别出来的。字幕文本所承载的内容关键词词数非常大,此外,内容和关键词属于多得多的关系,所以通过多样化的关键词抽取技术来提取候选关键词,同时能够扩大候选词来源的多样性。基于NER的方法能够确保抽取的关键词是百科类的实体,有比较广泛的知识内涵。而新词发现的方法,它结合N-gram以及语言模型等多种能力来扩大对未知知识领域的挖掘。挖掘的候选关键词的量其实是非常大的,在关键词基础之上,根据视频的内容和候选词的匹配程度或者说相关性来进行关键词的分级,通过分类模型将其分类成最核心的关键词,有普通的关键词以及提及关键词。关键词分级的核心特征除了文本特征之外,还会采用音频、视频等多模态的特征来共同训练,进而提升分类准确率,将关键词和内容表达的关联度预测更加精准。在这一过程中会面临一些挑战,比如这个视频讲的是欧洲瓷器的发展史,但是视频标题很简单。我们虽然把内容将变成文本之后,能够利用前面提到的关键词提取技术抽取出欧洲、麦森和塞夫勒等关键词,但是如何把这些关键词和欧洲联系起来,理解这个视频讲的是欧洲的发展史,而不是中国或者日本。此外,对于瓷器领域(比如陶青花、瓷高岭土)的知识实体,怎么知道该实体和瓷器讲的是类似的事情,那么这里就需要有科技作为支撑了。因为科技的实体知识库能够涵盖比较广泛的领域,比如说全行业的丰富的实体信息,能够帮助提取核心内容主题。此外,算法还需要有实体间的关系推理的能力,才能更加全面的理解视频,然后更好地支撑上层的召回、匹配和排序。
2. 效果案例
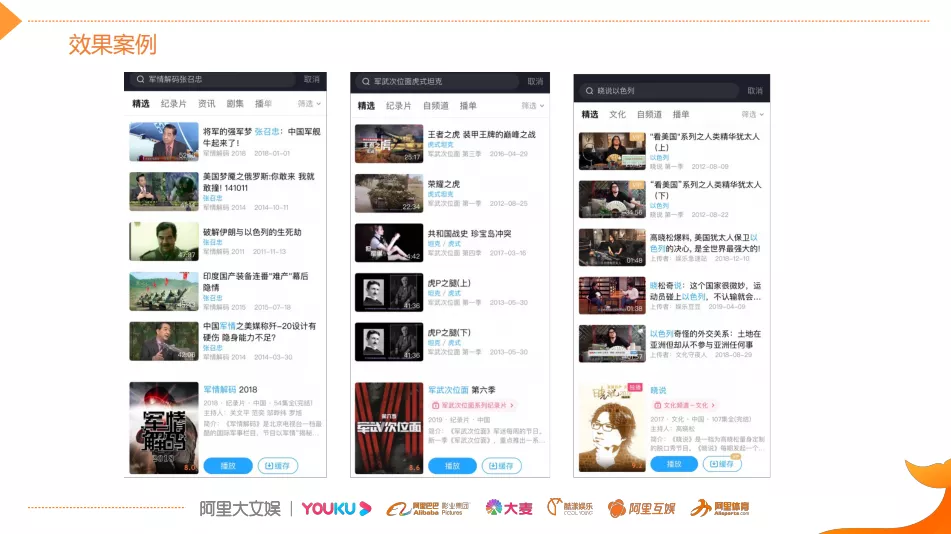
上图是基于多媒体实现的搜索案例的上线效果。最左边这案例,当用户搜索“军情解码张召忠”时,可以看出来排在前面的几个视频,它内容都是张召忠主讲的。但是,标题上其实没有张召忠这个名字,我们是通过算法将内容进行理解,将它从视频模块中抽取出来,同时以这种关键字的方式进行外显。其它的案例也是类似的,就是说视频开头中没有用户想要的东西,但是视频内容中有,所以这个时候就需要用多媒体视频检索的方式。
04 深度语义相关性的一些探索
最后介绍一下深度语义相关性上的一些探索,之前介绍的内容都是在来阿里文娱前阿里文娱的一些工作,来阿里文娱的三个月在深度语义相关性方面做了一些探索的工作,给大家分享一下。
1. 字面匹配 V.S. 语义匹配
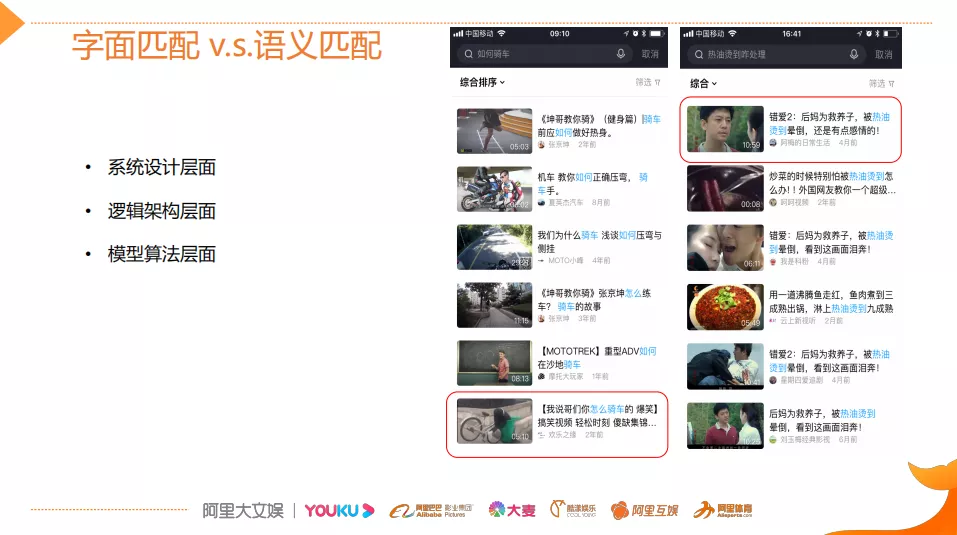
为什么要做这种深度语义计算?
因为传统的字面匹配或者说字面相关性,其实解决不了一些语义的问题。这里有两个案例。
第一个案例用户搜“如何骑车”其实是想找攻略的,图中给出了传统的方法的结果。字面匹配的结果并不是一个攻略,而是一个搞笑的视频。
第二个案例用户想要找的是“被热油烫伤有什么处理方法”,这是一类如何做的Query,但是结果并不太理想,都是字面匹配,并不是用户想要的,所以说需要做深度语义计算。主要是从三个层面完成,系统设计层面、逻辑架构层面和模型的算法层面。
2. 相关性系统设计

首先看看相关性的系统设计,本文结合业务需求做了新的系统设计。
老版相关性是用来提各种特征,LTR基于这种特征做一些多目标的优化。该方法存在问题,即其将体验类问题和分发类问题耦合在一起,使得LTR学习的并不是很好。因此,新版的相关性系统设计就和LTR做了明显的功能上的划分。新版相关性主要解体验类问题,LTR解分发的问题,这样将体验问题和分发问题进行解耦,这里并不是说LTR就不管体验类问题了,而是互为兜底。这样做有两点好处,第一点能够提升整个搜索结果的秩序感,给用户提供他们最想的内容;第二点在秩序感的保证基础之上,通过LTR可以增加用户的粘性来引导用户看的更多。
这里举了个例子,就是对相关性进行了增长规范,即将其分成三或四档。相关性主要就是在做这种分档。
- 一档:用户意图不满足。比如Query“步步惊心,吴奇隆”这个DOC中说的步步惊心根本就不是这个电视机剧,所以不召回。
- 二档:用户部分意图满足。比如说满足用户的主意图,但是不满足次意图,这种可以作为推荐或者相关的结果展示给用户,
- 三档:用户的意图完全满足。这种是比较高相关性的一个结果。
3. 相关性逻辑结构
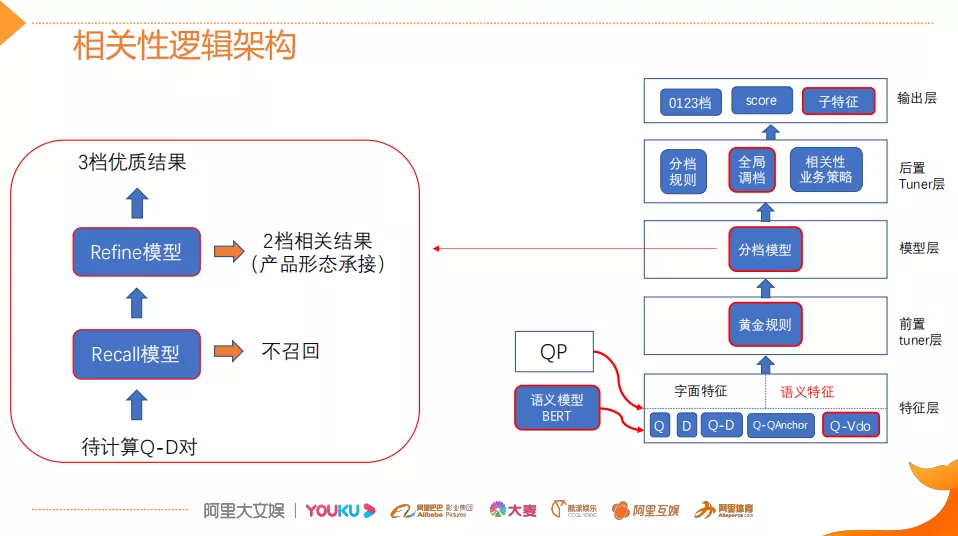
接下来看新版的相关性的逻辑架构。老版的逻辑架构主要是抽特征,同时用一些规则去拟合这种分档。新版相关性将原来的规则模型替换为三层的结构:前置的tuner层、模型层以及后置的tuner层。
- 前置的tuner层:主要包含一些黄金的规则,在训练集上准确率超过95%的这种规则策略,当满足这些条件时,不进行模型处理,直接通过规则处理。
- 模型层:当黄金规则处理不了时,利用分档的模型做兜底。分档的模型含有两个子模型为Recall模型和Refine模型,两个模型的结构一样,但它们使用的特征以及样本的选择是不一样的。分档模型的好处在于将整个相关性分档的功能进行了解耦,一个是用来发现高相关性的优质DOC,另外一个是用来降低相关性的岔道和进行过滤。这种语义特征是作为特征放到分档模型中,而不是直接用深度模型。为什么不直接用深度模型呢?因为工业界需要高度的可控和可解释性,分档模型还是用的这种传统的GBDT模型。
- 后置的tuner层:该层对于因为样本数据不均衡、核心特征缺少等原因没有学出来的情况,会添加一些人工的兜底规则进行补充。比如说会针对视频内容理解特征做了一些规则。该层中还全局调档的一个Tuner,它的作用是基于全局的DOC匹配再做一些调整,消除下层的模型。模型输出的这种档位、它的Score和子特征输出给LTR,进行最终的基于分发的排序。
4. 深度语义相关性框架
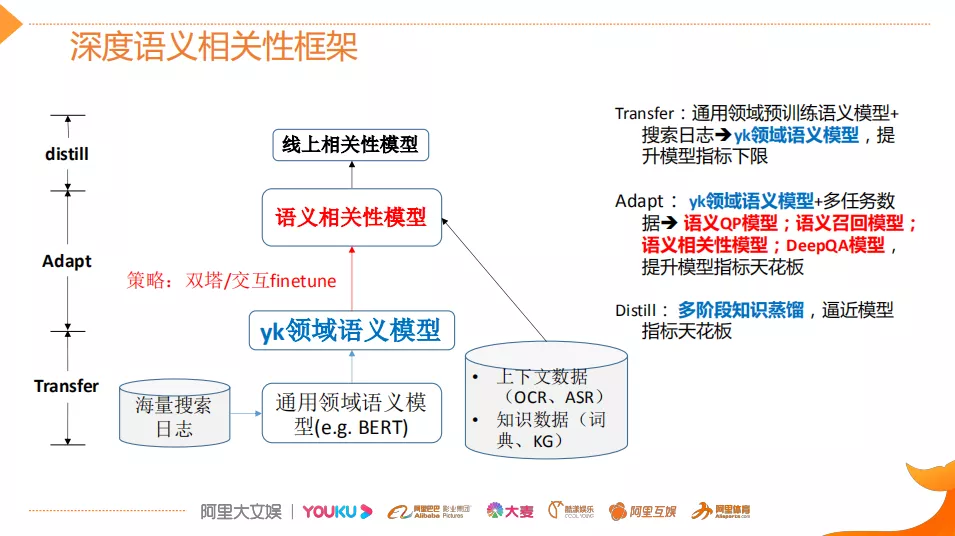
下面跟大家聊一下这边所开发的深度语义的相关性框架,也就是说对于BERT这些预训练模型是怎么在优酷场景进行落地的?参考了工业界常用的方法设计的这种三阶段的这种语义框架。
- 第一个阶段transfer:它主要用到通用领域的预训练的语言模型(比如说谷歌或哈工大训练出来BERT),然后用优酷搜索日志对它进行重新的一个pre-train这样就得到了优酷领域的语义模型,那么这个模型的目的是为了提升模型指标的下限,它往往能够提升base BERT的2%-3%的指标。基于transfer阶段之后,获得了一个优酷领域的语义模型。
- 第二阶段Adapt:它主要是基于优酷领域的语义模型以及多任务的数据,训练出一系列的这种模型,比如说这里的Query分析叫QP、召回模型、相关性排序,它其实是基于同一个base模型去训练出来的。Adapt阶段的作用是为了提升模型指标的天花板也是上限。那么在模型最终离线的时候是可以这样用,但是在线因为考虑到性能,还需要做最后一步蒸馏。
- 第三阶段distill:本文用到的是多阶段的知识蒸馏,它的目的是为了逼近模型指标的天花板,除了使用文本数据之外,还使用各种上下文数据以及前面提到的知识数据。
5. 深度模型选型
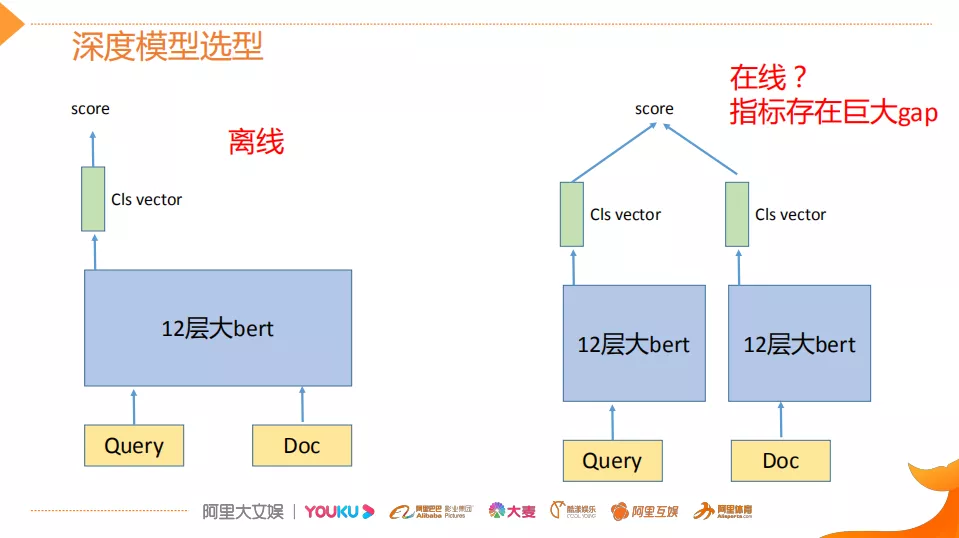
深度模型选型这块,其实大家都比较清楚,左图是传统的BERT的用法,它是一个交互型的,离线可以这样使用,而且本文也是这使用的。但是在线,因为考虑到性能的压力,往往都会选择这种双塔的结构,那么双塔的结构,它和交互型的这种BERT相比,它虽然效率提升,但是它的指标是存在着比较巨大的gap。
6. 非对称双塔模型(在线部署)
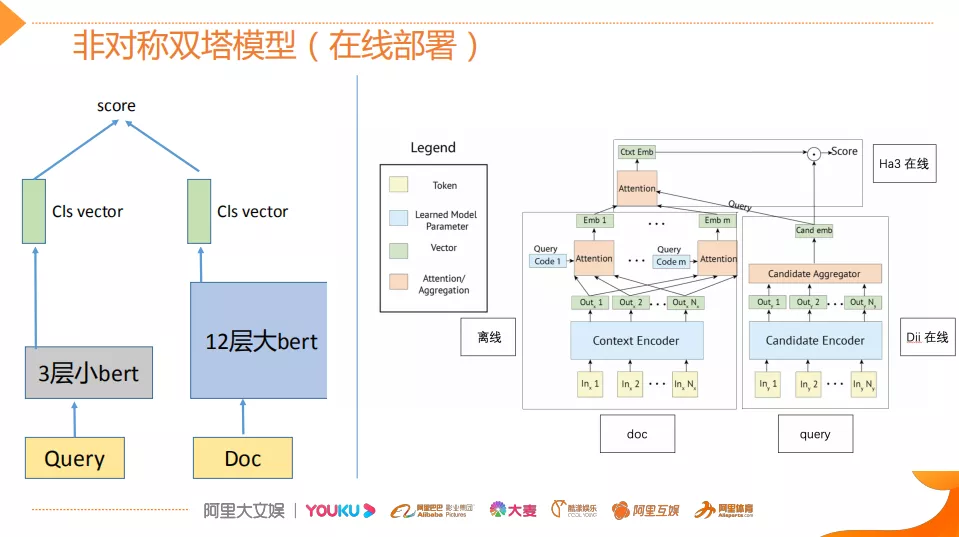
那么怎么消除这个gap?做了两点工作,第一点在线部署时用一个非对称的双塔模型,比如说Doc端可以离线算好存起来。Query端用一个三层的小BERT,因为它考虑到并发性。同时为了降低双塔模型的指标衰减,对于Doc侧,它其实保存的并不是一个Embedding,它是M组的Embedding,M组可以理解为从M个侧面刻画Doc的特征,这样也是为了最大限度的去保留Doc侧的一些丰富的信息。然后再离线侧,可以通过这个比较复杂的12层的BERT去跑它的多组的这种Embedding,然后在线侧用Dii对Query用一个三层的小BERT的产生它的这个Embedding之后,在Ha3侧也就是引擎侧,基于attention去算Query侧的Embedding 和Doc侧M个Embedding 之间的这种权重,之后做一个点乘得到最终的Score。这样做可以说是既让这个指标衰减的不是那么厉害,同时又能够让在线的Query侧的特征抽取能够保证线上的并发效果,只这么做其实还是不够的。因为这个Query侧的模型换成小模型之后,它的指标会进一步衰减,为了减缓这种衰减,采用了一个多阶段的蒸馏方案。
7. 多阶段蒸馏方案
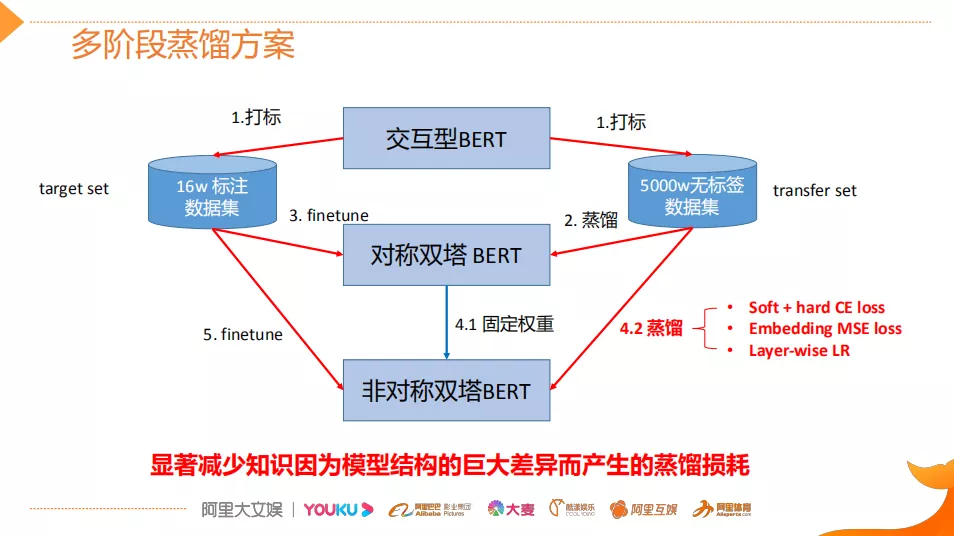
给大家介绍一下多阶段的蒸馏方案。如图有两份数据,一份数据为transfer set,它是一个5000w的无标签的数据及优酷的点击日志;第二份数据为target set,它是一些人工标注的数据集。
① 打标: 用交互型的BERT(指标最好,但只能离线使用)作为teacher。在以上两个数据上进行打标,得到BERT soft label。
② 蒸馏: 用无标签的数据蒸馏。并不是用BERT直接蒸馏目标模型,而是用它去蒸馏对称的双塔BERT,也就是说Query侧和Doc侧都是12层的BERT。
③ 用target set 进行finetune: 获得了中间模态的对称双塔BERT。
④ 固定权重和蒸馏:
-
固定权重:将对称双塔BERT的权重复制到非对称双塔BERT(目标student),然后权重固定之后,
-
蒸馏:再一次用transfer set对student进行蒸馏,该蒸馏包含如下几步:
① 首先会有多种loss,它既包括了这种label的hard loss,也包括了这种soft的label的这种cross entropy loss,基于这个loss,其实因为这个loss是对最终预测层产生作用。
② 为了更加充分的去学习Query侧的三层小BERT的效果,还会用到Embedding MSE loss,那它是怎么做的呢?就是用这种中间模态的boss,它会在这种数据集上进行打标,打标完了之后它保存的不是label,而是对于每个query它会产生出的一些Embedding,然后用这个Embedding同时去监督非对称的双塔BERT就让它学习的更加充分。
③ 这里有实践中的一个细节,因为线上有存储的压力,所以不可能把BERT base的768维向量进行存储,肯定是要进行降维,一般是用一个Dance Network进行降维,但是这个Dance Networ,因为它在BERT的top之上,如果使用相同大小的学习率的话,它会学习的非常不充分,导致最后的指标非常差,所以这个地方用到的Layer-wise的learning rate,也就是说让降维的Dance Network的学习率要远远大于底层的BERT的学习率,这样的话能够使得降维产生的信息损失降得非常低,然后他的指标能够很好地逼近于teacher model。它的目的是通过这种多阶段的逐步降低学生网络和老师网络之间的差异,而不是一步到位,这样就能够减少知识因为模型结构的巨大差异而产生的蒸馏的损耗。这个效果也是比较显著的,通过这种多阶段蒸馏现在已经能够达到在两个点以内的指标损失。
8. 融合知识的深度语义匹配
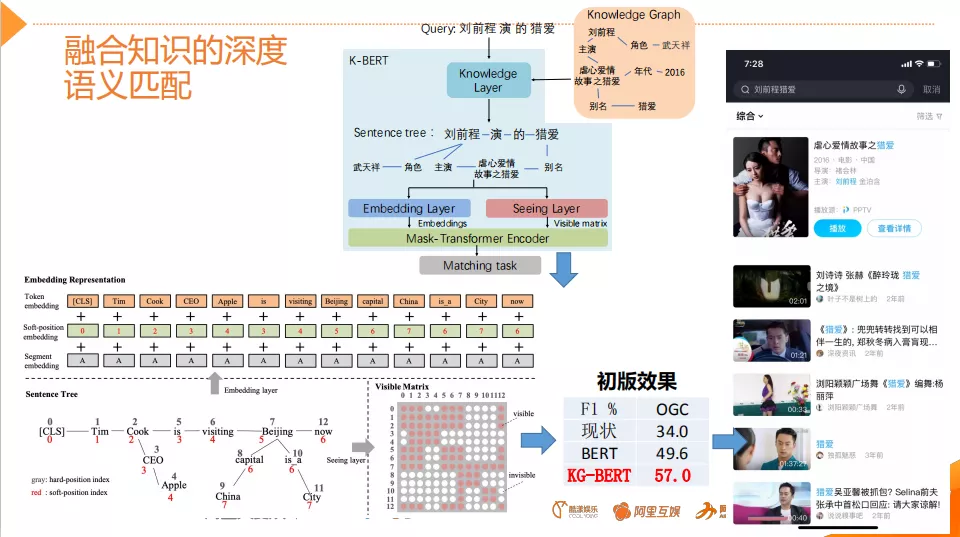
接下来介绍在模型层面上的一点优化工作,为什么做融合知识的深度语义匹配?因为在�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%98%BF%E9%87%8C%E6%96%87%E5%A8%B1%E6%B7%B1%E5%BA%A6%E8%AF%AD%E4%B9%89%E6%90%9C%E7%B4%A2%E7%9B%B8%E5%85%B3%E6%80%A7%E6%8E%A2%E7%B4%A2/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


