阿里妈妈是如何做品牌风险管理的
作者:阿里妈妈风控团队
品牌风险管理是阿里妈妈风险管理中最核心的风险之一,一直备受商家和消费者关注。商家在没有品牌资质的情况下售卖假冒或山寨的品牌商品,会侵犯品牌商及消费者的权益。本文将主要介绍,阿里妈妈品牌风险识别体系是如何一步步炼成的。
▐ 一、背景
1.1 阿里妈妈品牌风险简介
在阿里妈妈业务中,鉴别品牌风险的第一步是识别出商品相关的品牌,第二步是结合商品的资质去判断是否属于品牌风险。本文重点关注图像中的品牌识别。
假货和山寨问题在业务上的定义包括:
- 涉嫌假冒商品:能判断是明显假货的商品(如低价)
- 涉嫌品牌侵权:出现明确的商标信息(注册商标或品牌中文或英文文字信息)
- 图片遮盖涂抹:存在针对商标信息的恶意遮盖涂抹
- 发布混淆信息(品牌山寨):在商品外观或商标上仿大牌,让消费者认为该商品为某知名品牌商品(主要为国际知名品牌)

左图正品 右图假货

左图正品 右图山寨
1.2 难点与方案
基于以上背景,我们着手研究品牌识别的整体方案。在提解决方案之前,我们先看一下品牌识别问题的难点。
1.2.1 难点
- 数据多样性(品类、展现形式、角度和遮挡等)。

- 品牌特征的多样性(以下都是adidas鞋的特征)。

- 部分数据没有logo或者logo很小。

- 山寨款式变化多样。

- 品牌规模大。
- 违规商品在总商品中占比极小,非对称(正常商品量远大于问题商品量)的场景下,做到高精度和高召回较难。
- 广告场景下对抗激烈,不仅体现在图片上的对抗,还有商品本身的对抗。比如下图一山寨商品买回去可以自己把nike上面多余的一块拆掉,最后一张图看着像匡威,但实际上框里面的文字不是converse。

1.2.2 方案
针对以上问题,我们提出了「品牌分类模型 + 品牌logo检测模型 + 品牌图像变异识别模型」的综合方案。另外,我们构建了大规模的品牌数据集,为我们识别能力的构建打下了坚实的基础。
**1)** 品牌分类模型
我们将分类模型应用在品牌识别问题上,验证了分类模型可对局部的小logo或者特征进行识别,取得了不错的效果。
- 一方面,分类模型中每一类可容纳不同的特征类型,只要每一种特征类型相应的数据量足够,就不容易被当成噪声。我们将同一个品牌所有数据当成一类,既解决了数据和品牌特征多样性的问题,又大大降低了数据构造的难度。
- 分类模型不光识别logo,也可以识别款式等非logo特征,解决了基于logo检测的模型无法识别品牌款式的问题,拓展了品牌识别的范围。
- 分类模型计算图片属于每个品牌的置信度,山寨款式天然更像对应的仿的品牌,所以分类模型天然可以召回山寨款式。
- 分类模型的资源损耗和品牌规模无关,10个品牌和100个品牌的计算开销和速度差别不大,经过加速后单台G41可以达到4000 qps,资源开销不再是瓶颈。
**2)品牌logo检测模型 **
虽然分类模型有以上优点,但也有一个比较大的局限性,即分类模型会依赖上下文信息,也就是除了受品牌特征本身影响,也会受商品本身的外观、排列以及背景的影响。比如一双椰子鞋放在一个和正常展示的数据差异非常大的背景中,有可能识别不了,故分类模型容易受到对抗攻击。检测模型将品牌识别的范围缩小到logo区域,logo的区域不像全图的背景容易发生变化,一般处于商品上或者背景的某个局部上,特征更加稳定,受对抗攻击的影响较小,可以作为一个稳定的识别能力。
**3)品牌变异图识别模型 **
业务上高发变异为图片拼接和商品堆砌(如下图)。拼接和堆砌的图片中商品主体过小,特征不明显,且高发的一些大牌款式违规并不存在logo,分类和检测模型都可能束手无策。不过这些图片从视觉上看有一定的规律,我们不直接识别品牌本身,而是去从侧面去召回有这些排列规律且视觉上比较接近的图片,作为一种补充召回手段。

4)品牌数据集
我们坚信数据是识别能力的基础和保障,需要用更加丰富的数据来提升模型的泛化能力,数据是知识,知识不够的时候很难做出准确的判断。当然数据的多样性是无穷的,我们不可能全部获取,而是在可控代价下尽可能获取更丰富有代表性的数据。当前我们构建了品牌的分类和检测数据集(本文我们使用其中212个品牌数据做实验),同时配合一份品牌特征识别点的领域知识数据。
5)各个模型之间的协同

▐ 二、数据集
数据集是品牌识别模型构建的基础,本质上给模型提供了相对丰富的领域知识。这里包含了品牌识别特征点、品牌分类数据集、品牌logo检测数据集、品牌算法评价方案。
2.1 品牌特征定义
品牌特征的定义实际上是为了给出一个标准,数据集的建设必须有标准,这样才能可参考可衡量。不同于ImagNet数据集中的自然类别比较通用,品牌类别的判断是一个有很强的领域知识的问题。以奢侈品牌GUCCI为例,下面图片中的商品都是GUCCI的商品,红色框内是品牌特征识别点:

通过这上面的例子可以看到品牌特征的丰富性,尤其是大牌和奢侈品,他们有能力不断推出自己的设计和元素。阿里妈妈运营同学在这块有较深的积累,整理出了这份品牌特征。有了这份品牌特征之后,外包标注就有可行性了,大家参照同一个标准,有据可查。
但是实际标注的时候依然会遇到很多问题,如:
- 大众款式的判定
某一些品牌的款式比较大众,或者被山寨之后比较大众,大众款式不适合被处罚,但是大众款式的判断没有一个统一的标准。下面这几个是大众款式,从左到右分别是仿匡威、周仰杰、crocs:

- 山寨的判定
比如下面这些channel哪些该算品牌侵权或山寨,哪些不该算,尺度很难把握。

- 品牌特征的可识别性
有些品牌的logo非常小,到底多大的logo具备可识别性,这个也需要作出判断。

类似的问题还有很多,我们会结合业务和算法能力去综合判断并在和外包交互的过程中逐步细化沉淀标准和案例库。
2.2 分类数据集
- 关于类别构造
我们将每个品牌的所有数据归为一类,包括所有的品类、特征点、款式。分类模型有能力在一类中容纳所有典型特征,只要相关特征的样本没有因太少而被淹没。同时对业务应用而言,资质只和品牌相关,判断是侵权或山寨只需要识别品牌结果,无需细分到具体的款式。这种类别构造方式大大降低了数据集建设的复杂度,一方面类别的数量大大降低,另一方面无需具体去控制每一种细分特征的数据量。
- 关于数据分布,接近线上真实分布
品牌类别中的数据分布对于模型的学习比较关键。我们把握一个基本原则,尽量靠近线上真实的分布,这样业务上出现的多的数据能得到更多的重视,也符合业务管控的天然诉求,同时将数据获取的问题简化,无需花大量的精力去干预数据内部的分布。
- 关于标注数据的获取
首先,淘宝基础商品表里有部分数据有品牌相关信息,这部分数据作为重要的初始数据来源;其次是业务处罚数据,作为重要的补充来源;第三是评论图,可以提升样本多样性。还有一些特定的重要款式无法通过品牌信息去大量获取。关于重要款式,阿里妈妈运营有比较强的领域知识,提供了很多搜索关键词去定向获取,如下图是adidas重点款式的搜索关键词:

此外,旗舰店也是我们获取样本的来源之一。
2.3 检测数据集
检测数据集的构建相对简单,我们在分类数据集的基础上抽样数据进行标注。不同于分类数据,检测数据更加注重侵权的业务,所以检测数据集中品牌特征的定义为品牌注册的商标或者品牌名,一个品牌也会有多个商标和多种不同的展现形式。如下图分别是森海塞尔和立白会在图片中出现的形式:

为了简化标注,一张图只标注一个品牌的检测框,检测框为标准矩形,无倾斜角。另外,针对一个品牌有多种logo的情况,我们为了简化也将这些不同的logo当成一类(在前期我们验证了检测模型可以处理单类有多种logo的情况),可能会有一定的性能损失,但大大简化了数据集构建的难度。标注样例如下:

2.4 算法评价
由于任务是品牌识别,只要给出识别的品牌即可,无需具体logo的位置,所以检测和分类共用一份数据集。整体的评价方案是闭集评测集测召回(考察整体品牌召回能力),开集评测集测召回数据比例(关系到审核的开销),业务评测集评价在业务数据上的表现(考察在历史漏出数据上的表现)。
2.4.1闭集评测集测召回
- 数据集情况
212个品牌,总共180605条数据,平均每个品牌852条数据,准确率97%以上,每个品牌的数据包含对应品牌的关键特征,关键特征包含了品牌logo、特定品牌款式、特定设计、品牌名称等,每个品牌也可能包含多个类目的数据。
- 评价指标
平均召回率=(\sum_{i=0}^n 品牌i召回率)/n
2.4.2 开集评测集测召回比例
- 数据集情况
线上随机抽取500万数据。算法召回的比例决定了审核的量级,在实际应用的时候比较重要。
- 评价指标
召回比例=模型召回疑似品牌数据量/模型计算数据量
2.4.3 业务评测集评价在业务数据上的表现
- 数据集情况
获取品牌模型上线之后历史大盘、专项评测和投诉获取到的知识产权风险数据,共1449条,其中966条包含logo。标注所属品牌名以及是否有品牌logo,用于评测新模型在历史遗漏数据上的效能提升。
- 评价指标
召回率=召回品牌数据/总品牌数据
▐ 三、品牌分类算法
我们将分类模型应用在品牌识别问题上,解决品牌款式、品牌山寨、品牌logo等的识别问题,同时解决性能的瓶颈问题。之前我们在非对称风险识别问题上(如色情识别)用分类模型进行了一定的实践,分类模型可以识别细节的、局部的色情特征,所以我们推测分类模型也可以识别局部的品牌特征,基于这个认知我们进行尝试。
3.1 可行性研究
3.1.1 Nike品牌识别
我们选取nike品牌来最小代价验证品牌分类模型识别的可行性,Nike品牌包含了图形和文字两种模式,模式相对固定,在部分图片上logo会非常小:
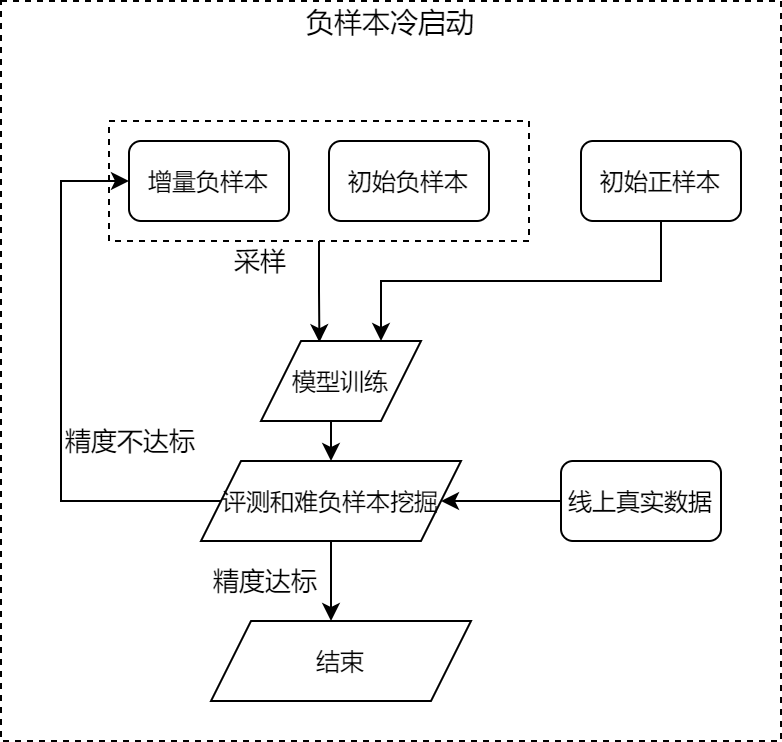
 选取nike品牌下的1万样本作为正样本,随机选1万样本作为负样本,学习二分类模型,利用下图中的快速冷启动方法迭代多轮(核心是不断挖掘难负样本,学到好的分类边界):
选取nike品牌下的1万样本作为正样本,随机选1万样本作为负样本,学习二分类模型,利用下图中的快速冷启动方法迭代多轮(核心是不断挖掘难负样本,学到好的分类边界):
 全网nike样本库107万,用来测召回,线上随机取100万数据测召回比例和业务精度,标注后结果如下表格:
全网nike样本库107万,用来测召回,线上随机取100万数据测召回比例和业务精度,标注后结果如下表格:
nike类别置信度闭集召回率开集业务精度开集召回比例>0.574.6%14%0.32%>0.960.9%41.2%0.095%>0.9946%68.7%0.038%
这里有一个发现,60.9%的有效召回集中在0.095%的数据里面,而另外的2.25%的数据里面只有13.7%的有效召回。也就是说,大部分有效的品牌召回集中在高置信度部分。这个特性对我们在业务上的应用有指导意义,可以通过牺牲少量的召回大幅减少审核比例。召回能力的绝对值和数据集的难度有关(实际的召回会比表中的召回更高,一方面是因为我们默认某个品牌id下的图片都属于对应品牌,实际上并不是;另一方面,上面的模型只迭代了精度,并没有优化召回)。
基于以上结果,我们初步判断分类模型有希望在较小的代价下召回较大部分的品牌风险。
3.1.3 大规模品牌识别
品牌数量增加之后,我们把所有品牌数据当成一类,非品牌数据当成另外一类,整体进行精度迭代,至于品牌之间的混淆,暂不考虑。这里有一个比较重要的特性,迭代前期识别精度越低的品牌在后续精度优化中受到更多的重视,因为我们整体随机取badcase,精度差的品牌的badcase占比相对高。但是到后期不同品牌之间会有差异,有的品牌在业务中出现的比例高,在整体的召回中比例会高,但不代表精度差,有些品牌在业务中出现比例极低,虽然在整体召回比例中低,但是精度可能也比较差(不过好在召回比例低的那些品牌即使精度差对整体的工单量影响也不大,可以不必强求学到高精度),后期优化的时候就需要有选择性的加入迭代的badcase,本身精度已经比较高的品牌不适宜继续迭代,否则会牺牲召回,迭代的重点放在低精度的品牌上。下面是训练过程中我们总结的几个要点:1)不同品牌负样本的均衡 训练数据中负样本(badcase样本)的构造比较重要,负样本的总量和hard sample的比例决定了召回和精度的折中,属于不同品牌的负样本之间的比例决定了不同品牌的精度和召回的平衡,在负样本总量不变的情况下增加A品牌的负样本比例减少B品牌的负样本比例会提升A的精度并降低A的召回同时降低B的精度并提升B的召回。所以要单方面调控部分品牌的精度和召回只能单独增加或减少这部分品牌的负样本数量,其他品牌的负样本则不操作,也可以调控负样本中困难样本的比例来实现。2)品牌规模对学习难度的影响 品牌规模大了之后数据量增加,训练的时间必然增长。而从训练的难度来看,实际上是减少了,举个例子,当品牌中只有一个鞋类品牌时,如何让模型学到鞋子上的某个特征或logo,是要花较大的代价的,你需要告诉模型鞋子不是这个品牌的特征,即使长得像的鞋子也不是这个品牌的特征,而如果品牌中有大量鞋子类别时,模型天然就会关注到不同鞋子品牌差异的地方以及同一品牌鞋子共性的地方,难度自然降低。
3.2 模型结果和优化尝试
基于上文中总结出的方案,我们在212个品牌数据集上训练得到base模型,在我们的评测集上结果如下:
闭集评测集:
版本平均召回率线上召回数据比例(数据有波动,仅供参考)Base58.6%1%
业务评测集(本身属于漏召回的为主,整体效果会偏差):
版本不含logo数据召回率含logo数据召回率Base25.5%51.1%
我们对正负样本进行提纯优化并引入审核业务数据,得到优化后的版本:
闭集评测集:
版本平均召回率线上召回数据比例Base58.6%1%优化版60.0%1.14%
业务评测集:
版本不含logo数据召回率含logo数据召回率Base25.5%51.1%优化版45.8%62.5%
优化后的版本在业务评测集效果提升明显,主要得益于审核业务数据的引入。不过分类模型平均召回率还有提升空间,主要受制于品牌问题本身的复杂度以及对低召回比例的要求,我们可以结合其他识别能力去综合提升品牌的召回。
3.3 结果可视化
我们通过品牌分类模型反推原始图像中对最终结果贡献大的部分,一些样例如下(左边原图,中间能量图,右边合成图):
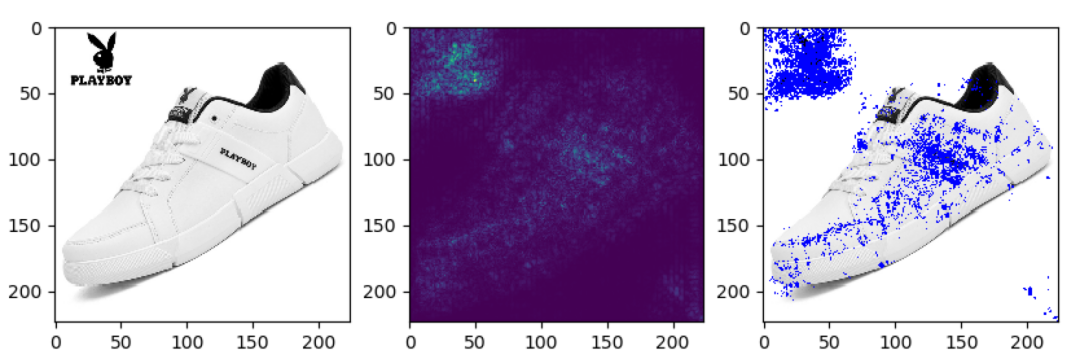
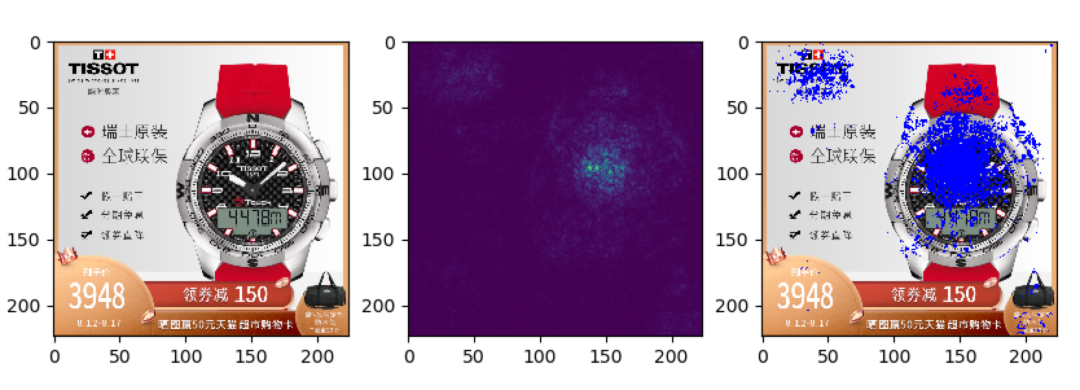
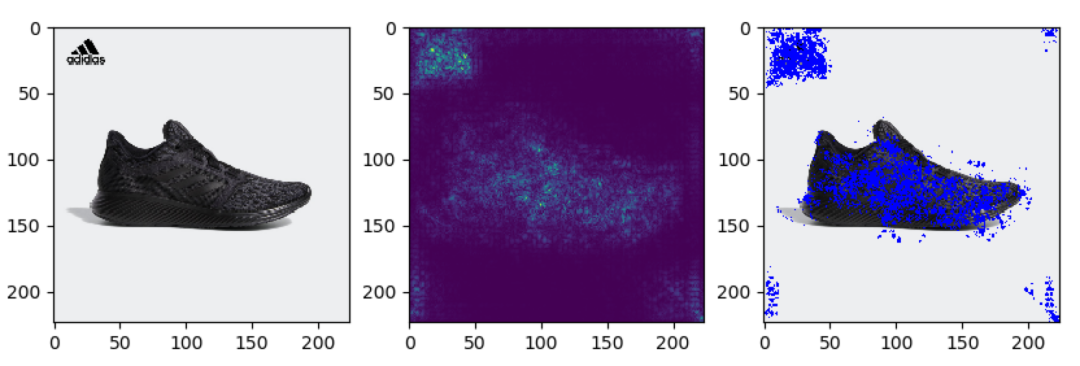
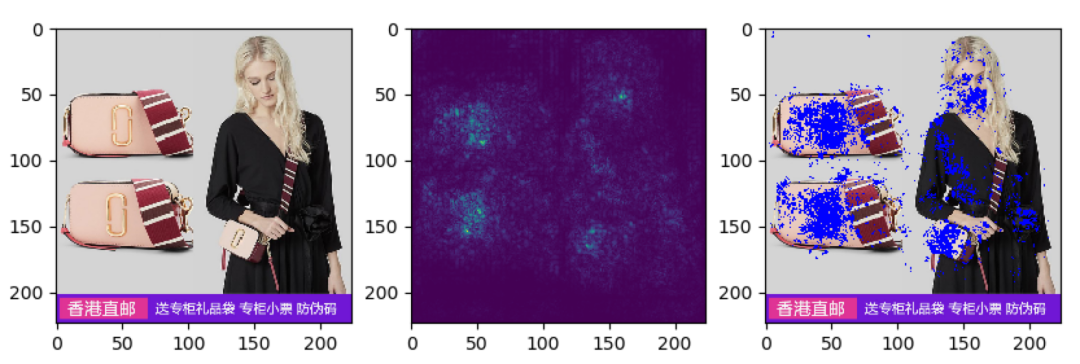

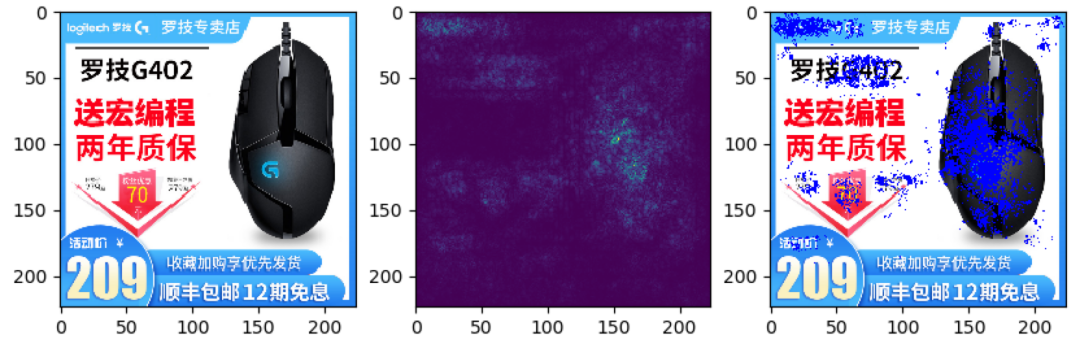
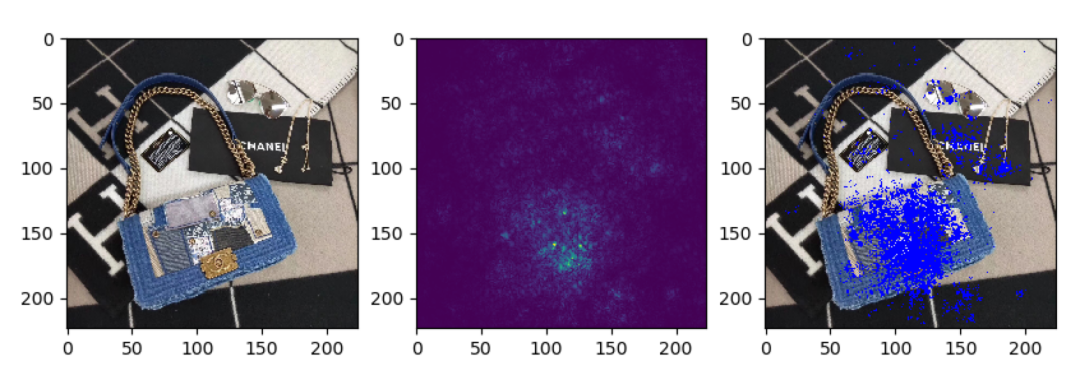
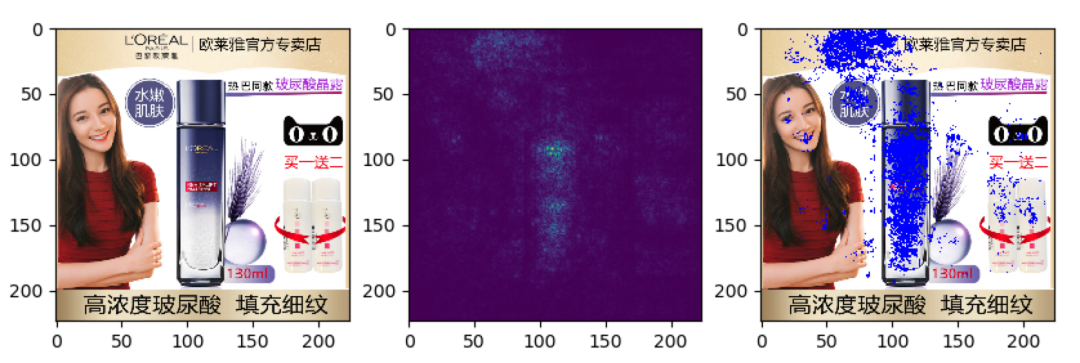
可以看出,模型确实关注到了品牌特征区域,再次验证了分类模型在品牌识别问题上的可行性。
四、品牌检测算法
虽然分类模型有较好的性能且能识别款式和山寨,但是容易受背景变化以及展示变化等上下文信息的影响,对抗能力较弱,基于检测的算法能减少背景的干扰,只关注品牌logo区域,能提供相对稳定的品牌logo识别能力,我们实现了基于logo检测的品牌识别算法。
4.1 品牌logo检测算法的实现
logo检测有一些传统的方法,比如基于sift特征或者haar特征。但是这类特征鲁棒性不够,对于具有非刚性变换,变异logo的图片,识别效果较差。对于大品牌来说(如channel),会存在着各种样式的logo,这个问题会更加突出。所以我们选择基于CNN的目标检测算法来解决品牌logo检测的问题。
4.1.1 基础检测模型构建
现有的基于锚点框(anchor)的通用物体检测算法,可以分为一步法(one-stage)和二步法(two-stage)两类。一步法检测器速度更快,效果次之(如SSD、yolo等);而二步法检测器拥有更好的检测效果,但算法耗时偏高(Faster R-CNN、Mask R-CNN等)。
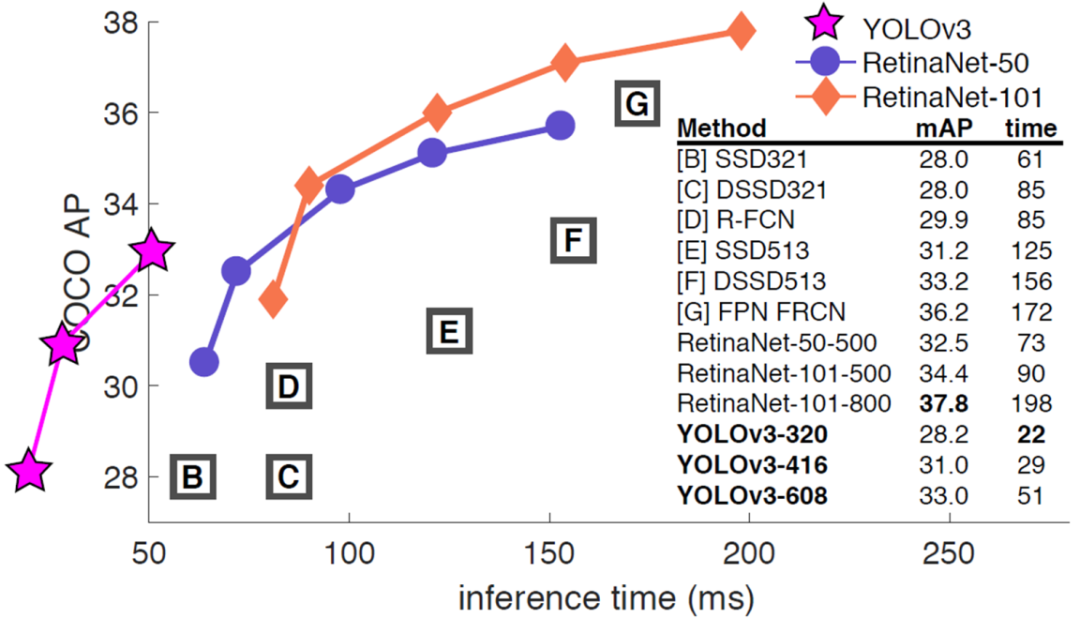
考虑到广告风控场景日均亿级别的流量规模,我们调研了业界主流的目标检测算法,综合计算资源和算法性能的平衡,最终选择了单步检测器yolov3作为我们的base模型,并在此基础上进行算法的优化和调整。如上图所示,和其他主流算法相比较,如SSD、RetinaNet等,yolov3算法具有较好的速度与精度的平衡,且对小目标的识别能力较强。我们将标注好的检测数据集分成训练集和测试集,使用yolov3作为基础检测算法,经过调参之后,模型在测试集上的最佳mAP为78.06%。
4.2 检测算法的优化
基于所构建的品牌logo检测基础模型,我们又对该算法进行了一系列相关优化,使其更加适用于品牌识别任务。主要包括:数据增强处理、损失函数设计和网络结构优化等。
4.2.1 数据增强处理
数据增强处理的优化,是提升模型性能一个非常有效的途径。我们在yolov3原有的图像裁剪、随机翻转和颜色扰动的基础上,添加了图像随机平移扰动、软标签设计,并综合引入yolov4和yolov5中提升算法性能极为有效的mix-up和mosaic数据增强算法。所生成的训练样本示例如下图所示。在提升了训练样本丰富度基础上,有效解决了小尺度logo的检测问题,下图是数据增强之后的训练样本示例。
4.2.2 损失函数设计
目标检测算法的损失函数,包含分类损失函数和窗口回归损失函数两部分。前者用于约束模型分类的更准,后者用于约束模型预测框定位更准。yolo系列算法选择多类别的交叉熵损失函数作为模型的分类损失函数,在通用目标检测任务中取得了较好的结果。但在品牌logo数据集中,由于logo数量普遍偏少,且logo稀疏的图片占比极高,正负样本失衡问题较为严重。因此我们引入了Focal Loss作为模型的分类损失函数,并针对正样本配置了一个较高的比值(0.7,默认为0.25),以强化正样本的权重。实验中发现,在品牌logo数据集中,该设计取得了较好的性能提升。
现有主流的窗口回归损失函数,可以分为两大类,一类是基于坐标距离回归的损失函数,如L2 Loss、smooth L1 Loss等;另一类为基于IoU回归的损失函数,如GIoU Loss、DIoU Loss等。实验中发现,在品牌logo数据集中,选择DIoU Loss替代原有的smooth L1 Loss能有最佳的定位效果。
4.2.3 网络结构优化
针对特征提取网络的设计,原有yolov3算法使用Darknet53作为基础网络,我们参考了yolov5的网络结构优化思路(SPPNet+CSPNet+Focus模块),并针对检测头进行了优化处理。相较于yolov3,新模型在inference耗时减少52%基础上(P100 gpu),mAP提升13.5%。无论算法的吞吐效率,还是算法性能,均有较大提升。
模型训练尺度测试尺度模型大小测试耗时mAPyolov3608416245M50ms78.06%新模型64064044.5M24ms89.89%
4.3 检测算法效果展示





五、变异风险识别
主要从侧面去识别一些检测和分类模型比较难以识别的风险,作为一种补充手段。一些困难的变异case如下图:
 一开始我们尝试直接去学习拼接和堆砌这种特征,发现召回的量级过大,线上100万的数据召回了18万疑似拼接和堆砌的样本。案例如下图:
一开始我们尝试直接去学习拼接和堆砌这种特征,发现召回的量级过大,线上100万的数据召回了18万疑似拼接和堆砌的样本。案例如下图:
 所以,单纯靠拼接和堆砌这种侧面特征是不可行的,没有区分度,我们必须引入违规商品本身的外观特征。比如椰子鞋的样子,首饰的样子,这样能排除掉大部分的无关样本,最终版本模型可以在0.11%的召回比例下闭集召回率达到82.1%。
所以,单纯靠拼接和堆砌这种侧面特征是不可行的,没有区分度,我们必须引入违规商品本身的外观特征。比如椰子鞋的样子,首饰的样子,这样能排除掉大部分的无关样本,最终版本模型可以在0.11%的召回比例下闭集召回率达到82.1%。
六、算法融合
我们尝试了将图片品牌分类模型和文本品牌识别模型进行融合,以及图片分类模型和检测模型融合,看互补性,结果如下:
闭集评测集:
版本平均召回率线上召回数据比例图片Base分类模型**58.6%**1%文本Base模型83.0%3.20%图片Base分类模型+文本Base模型80.3%1.46%图片检测Base模型yoloV353.8%0.95%图片Base分类模型+图片检测Base模型yoloV370.3%<1.95%
业务评测集(只有图片,无法追溯标题等信息,只看和检测模型融合):
版本含logo数据召回率图片base分类模型51.1%图片检测Base模型yoloV341.4%图片Base分类�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%98%BF%E9%87%8C%E5%A6%88%E5%A6%88%E6%98%AF%E5%A6%82%E4%BD%95%E5%81%9A%E5%93%81%E7%89%8C%E9%A3%8E%E9%99%A9%E7%AE%A1%E7%90%86%E7%9A%84/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


