阿里基于的机器学习平台

分享嘉宾:杨旭 阿里巴巴 资深算法专家
编辑整理:朱荣
导读: Alink是基于Flink流批一体的机器学习平台,提供一系列算法,可以帮助处理各种机器学习任务,比如统计分析、机器学习、实时预测、个性化推荐和异常检测。除了提供Java API也提供了PyAlink,可以轻松部署到单机及集群环境,通过Jupyter、Zepplin等notebook使用。Alink已在阿里巴巴内部支持了众多的应用场景,并在2019年11月的Flink Forward Asia大会上宣布开源,随后不断迭代发布新的版本,增强功能,提升易用性。
本文主要介绍基于Flink平台的机器算法的功能、性能与使用实践,帮助大家快速上手Alink机器学习平台。其中重点介绍了python语言使用的PyAlink的方法和实例,同时对FM算法进行了详细的介绍,帮助大家更好上手Alink并在实际工作中得到广泛应用。
主要围绕下面俩点展开:
- Alink基本介绍
- ALink快速入门
01 Alink基本介绍
首先跟大家介绍一下Alink的基本情况:
1. 什么是Alink?

Alink是由阿里计算平台事业部研发的基于Flink的机器学习算法平台,名称由Alibaba Algorithm AI Flink Blink 单词的公共部分组成。
Alink提供了丰富的算法库并天然可以支持批式和流式的处理,帮助数据分析和应用开发人员完成从数据处理、特征工程、模型训练、预测多节点端到端整体流程。
Alink提供Java API和Python API两种方式进行调用,Java API方便工程人员快速将Alink接入到现有系统中,Python API也叫PyAlink是方便提供机器学习同学完成快速的实验。
2. Alink功能介绍
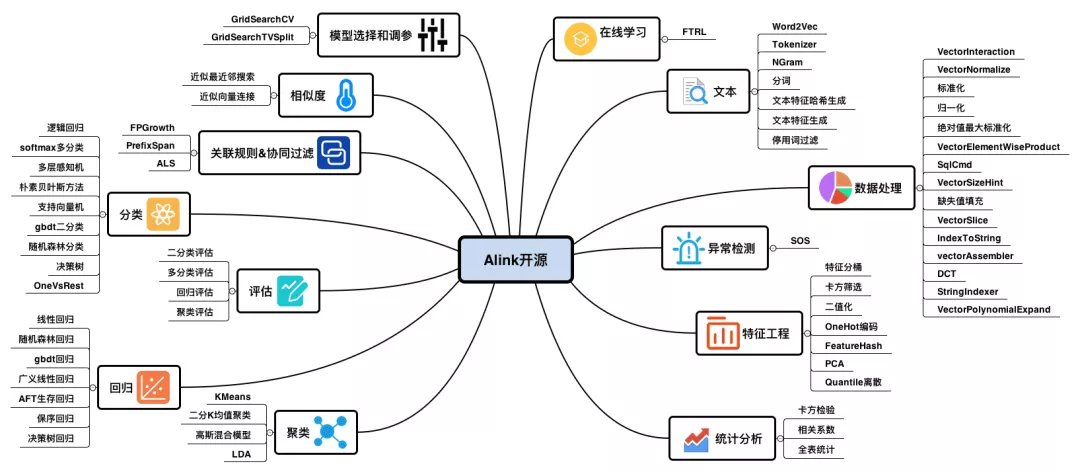
Alink作为一个重要的机器学习的平台,覆盖机器学习各阶段13大类的62项功能点,囊括了机器学习核心的分类算法、聚类算法、回归算法三类算法,并附带了4项模型评估的方法,同时还包括关联规则和协同过滤算法、相似度算法等数据挖掘方面算法。
- 在算法完成部分后,也提供了评估模型的评估方法,包括二分类评估、多分类评估、回归评估、聚类评估。
- 在算法应用之前Alink为使用者准备了数据预处理、异常检查、文本处理等辅助功能处理工具。
- 在在线学习方面Alink也准备了FTRL,可以在线状态中训练,在实时场景中提供模型实时更新机制,增强学习模型调整等时效性。
- 在机器学习中的模型选择与调试参数服务,为大家提供有效的参数调优。
3. Alink性能比对
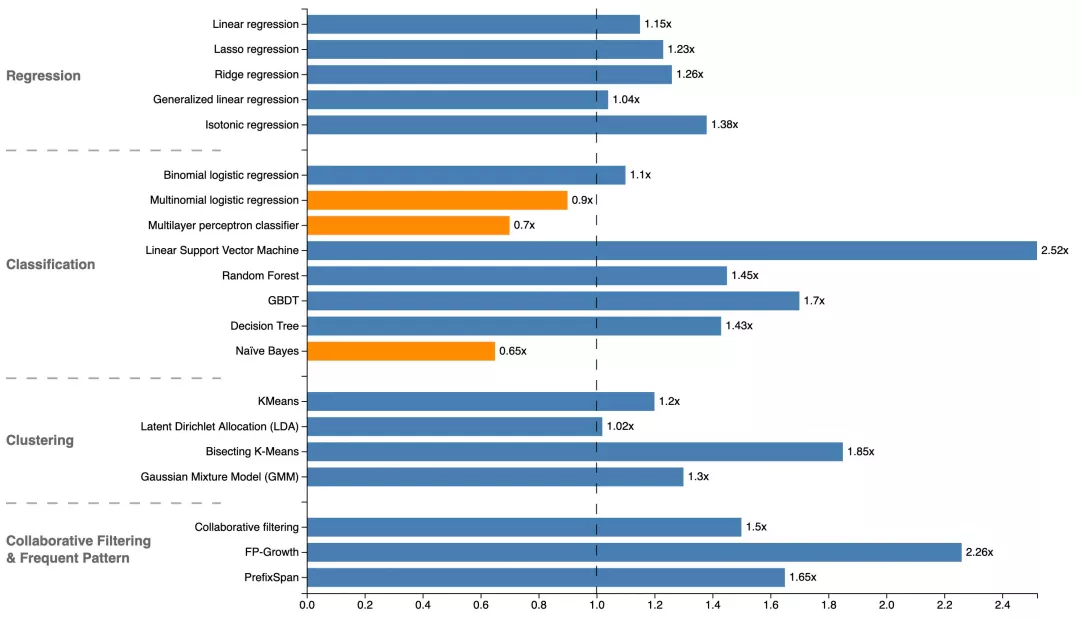
利用加速比对Alink与Sparkml进行性能评测。具体的测试方法是使用相同的测试数据,相同的参数,用Sparkml的计算时间除以Alink的计算时间。从下图实际测试对比数据可知,Alink在大部分算法性能优于Spark,个别算法性能比Spark弱,整体是一个相当的水平。
4. Alink建设进展
2019年7月发布Alink version 1.2.0:
- 支持Flink多版本 1.11、1.10、1.09;
- 支持多忘记系统:本地文件系统,Hadoop文件系统,阿里云oss文件系统;
- CSV格式读取、导出组件支持各文件系统;
- 推出AK格式读取、导出组件,简化文件数据操作;
- 支持模型信息摘要、输出;
- FM分类、回归算法;
2019年6月发布Alink version 1.1.2:
- 新增30个数据格式转化组件;
- 支持多版本Hive数据源;
- 在Pipline和LocalPredictor中指出SQL Select操作;
2019年4月发布Alink version 1.1.1:
- 提升使用体验,参数检查方面更加智能;
2019年2月发布Alink version 1.1.0:
- 支持Flink1.1.0和Flink1.9的平台部署问题,PyAlink增加兼容PyFlink的功能;
- 改进UDF/UDTF功能;
- 支持JAVA Maven安装和 Python PyPl安装;
- 支持多版本的Kafka数据源;
2018年12月发布Alink version 1.0.1:
- 重点解决windows系统上的安装问题。
2018年11月首次发布Alink version 1.0,在Flink Forword Aisa大会上开源。
02 Alink快速入门
接下来为大家详细的介绍Alink的使用方式:
1. 使用Maven构建Alink项目简介

Java使用者借助Maven中央仓库,大家只需要4步就可以很容易的构建出Alink项目。第一步:创建项目;第二步:修改pom文件,导入Alink项目jar包;第三步:拷贝修改Alink Java Demo Code;第四步:构建运行;
详细过程可以参考:
http://zhuanlan.zhilu.com/p/110059114
2. PyAlink安装实践

Python使用者借助PyPl,也可以两部构建Alink的使用环境。第一步,针对不同操作系统调整部署环境,包括MacOS、Windows、阿里云服务器。第二步,从PyPl选择最新版本的PyAlink安装,如果之前有PyAlink需要先卸载旧版本,再通过PyPl进行安装。
① PyAlink任务在notebook上运行

PyAlink的运行方式分为两种,一种是本地运行,一种是集群运行;在Alink1.1.1以后优化了运行集群运行地址指定的方式,用户可以更简洁的运行PyAlink的任务。
② 基于PyFlink的Alink

Alink Operator与PyFlink Table可以相互转化,方便串联Flink和Alink的工作流。在1.1.1新版本中还提供了getMLEnv接口,能直接使用flink的提交运行方式直接进行提交 run -py *.py 往集群提交作业。例如:直接使用 python keans.py 。
③ PyAlink使用体验的改进

为方便的使用PyAlink,最新版本也对于两个方面进行了优化。一个是Python UDF运行中将自动检测python3命令,确定运行版本。另一个优化是对DataFrame和BatchOperator互转性能做了提升,优化后性能提升了80%左右;对collectToDataFrame进行了同样的优化。
3. Alink支持的数据源
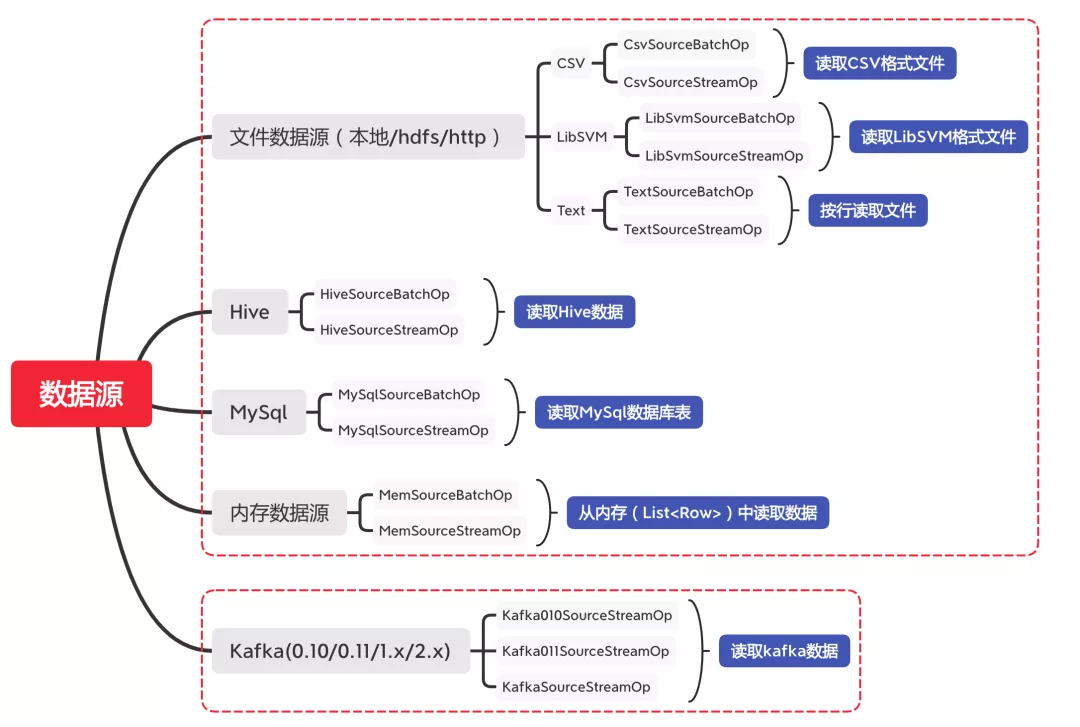
Alink支持批式和流式5种类型的数据源,其中批式数据源包括文件数据源、Hive、Mysql、内存数据;流式数据源主要是针对Kafka。
① 读写Kafka示例

以逻辑回归模型为例使用Kafka分为四步:第一步定义Kafka数据源;第二步使用json提取组件解析Kafka中的数据,完成数据类型转换;第三步加载逻辑回归模型,对流数据进行预测;第四步将预测结果再次写出到Kafka。
② 将JSON格式的字符串解析为多列
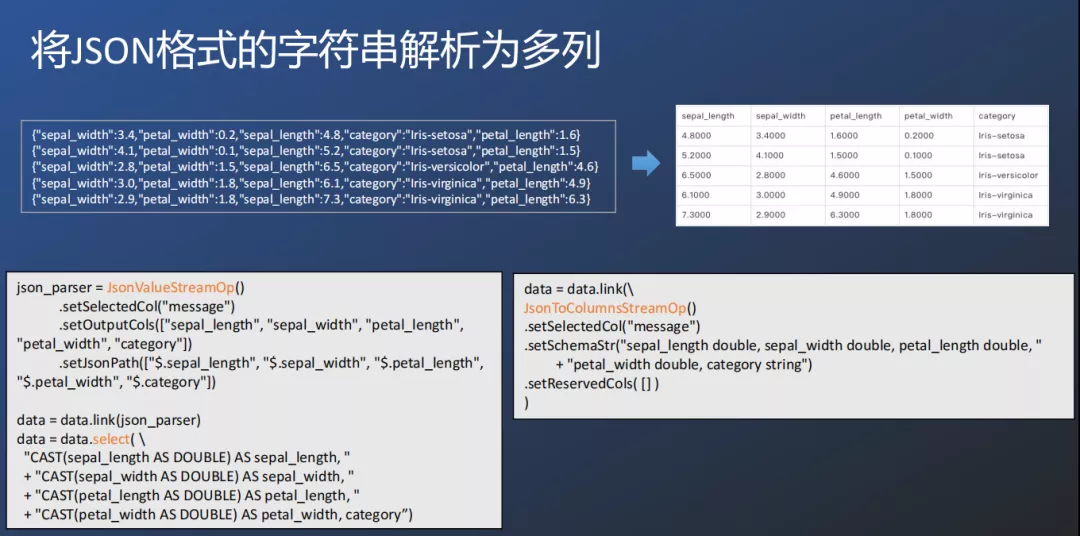
Alink也针对json格式的数据进行解析组件JsonToColumnsStreamOp,比json_parser更方便的处理json格式到表格字段列格式的数据转化。
③ 日志的字符串解析为多列
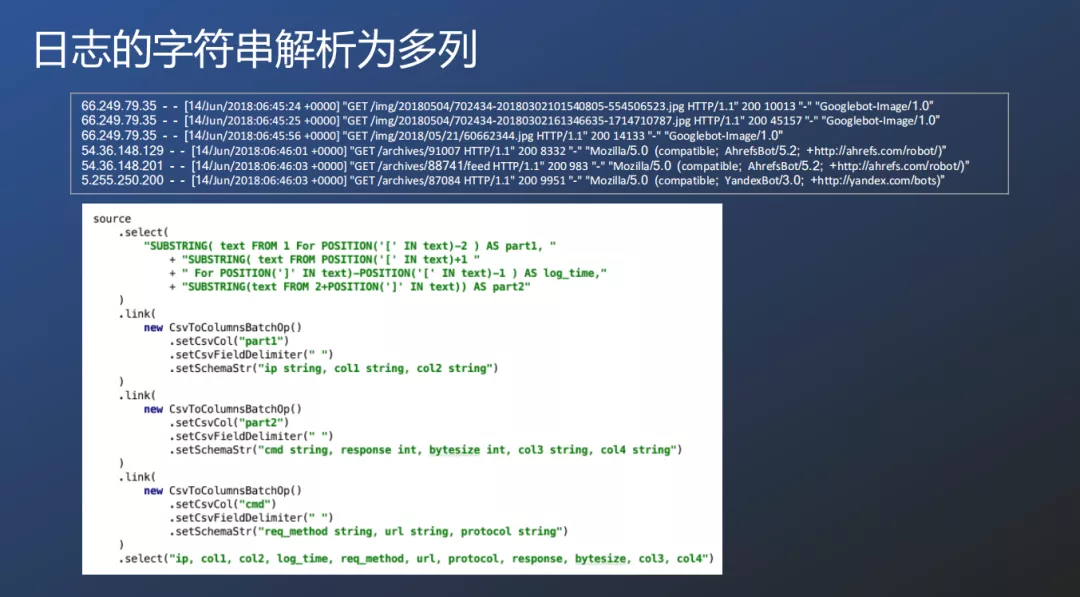
在PyPlink中可以通过分布方式进行处理,先处理【】括号内的数据,再处理CSV格式的数据,PyPlink提供了select选择组件和link管道组件。
④ Alink类型转换组件
Alink框架中常用Columns、Vector、Triple等类型的数据作为算法的输入输出,但用户可能会有多种输入输出数据类型的需求。因此Alink提供了全面的类型转换组件,作为衔接使用户数据与Alink算法数据的桥梁。
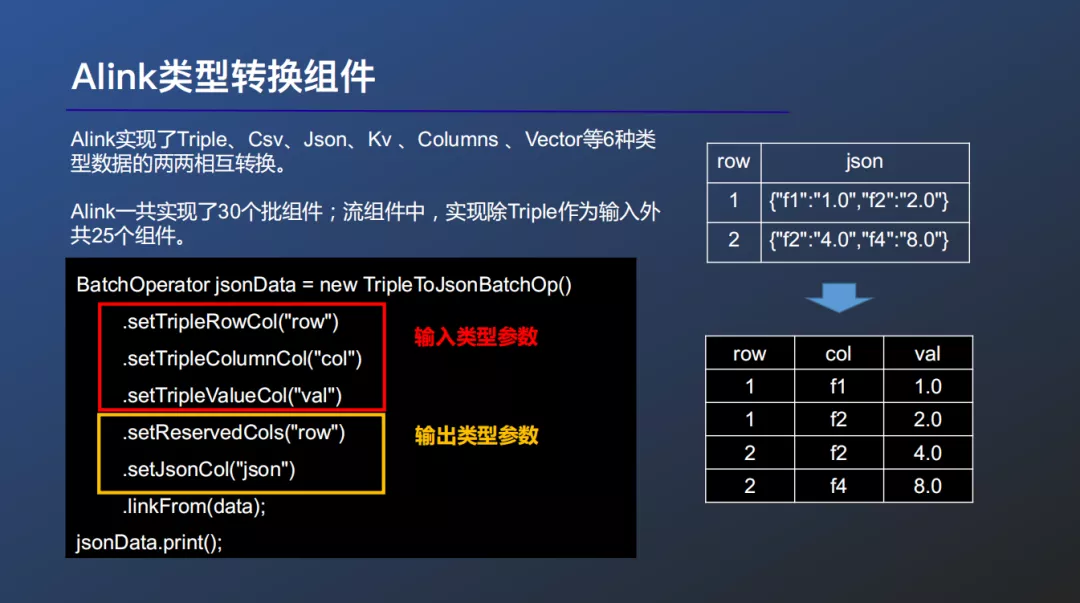
Alink共支持T
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%98%BF%E9%87%8C%E5%9F%BA%E4%BA%8E%E7%9A%84%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%B9%B3%E5%8F%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


