通用排序框架在爱奇艺推荐的应用
推荐系统通常由多个阶段组成,比如,有的推荐系统分为Recall、PreRanking、Ranking、ReRanking等四个阶段。在爱奇艺,我们的推荐系统在非常多的场景中都有应用,推荐的内容也不尽相同(如长视频、短视频、主题、影人等)。但是万变不离其宗,在这些场景中,推荐系统的核心工作方式有一定的共性。为节约开发成本,同时也要保障不同场景下推荐系统的稳定性,我们将不同推荐场景排序模型中相似的部分成体系地提炼出来,并加以标准化、组件化,进而针对推荐场景排序问题提供了通用化的解决方案。这也是我们提出爱奇艺通用排序框架的初衷。目前这一框架已经在爱奇艺多端多个场景落地——长视频推荐:主APP首页猜你喜欢、TV端首页猜你想看,短视频推荐:主APP短视频播放器,长短视频混合推荐:主APP频道页瀑布流、TV端首页Feed等。正所谓,推荐的复杂性如黑夜迷雾,希望能破晓见黎明。
下面我们分3节来介绍通用排序框架:第1节对框架的环节进行了概述;第2节主要介绍框架详细的构造环节以及对应特性;第3节对框架的特性进行总结和展望。鉴于我们主要考虑的是视频播放场景,下文中我们以视频来指代推荐系统中的item。
01概述
近些年来,推荐系统中的排序模型有比较快速的发展:浅层模型如XGBoost+FM,深度模型如DeepFM、DCN、DIN、DSSM、MMoE等,在不同推荐场景中都取得了亮眼的效果。然而,这些模型有一些共同点:它们最终都服务于线上的打分预测;它们都要根据场景特性来筛选和制作特征、构造训练样本、训练模型、部署Ranking服务——这样一个完整的流程。通用排序框架正是对这一流程的一种归纳总结。对于不同的推荐场景,模型的特征制作和模型服务化过程是一致的,他们主要在构造样本,以及训练模型上有较多区别。
通用排序框架总共由4个环节组成,每个环节都是模块化的,有可执行的标准流程和完善的监控机制。这4个环节分别是:
1、特征制作与灌库;
2、特征回放;
3、Training;
4、Ranking。
如下图所示。其中环节1、3为独立于线上服务的过程;环节2、4为线上服务的一部分。
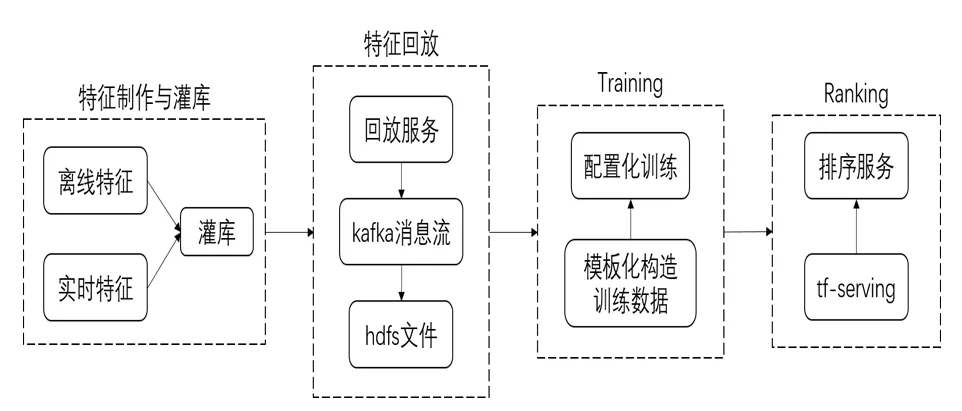
图1 排序框架结构
02 详细结构
2.1 特征制作与灌库
特征是推荐的基石,它决定了模型的上限。数据与特征描述了用户对视频的喜好,以及视频本身的质量。
从数据来源的角度来分类,我们可以把特征划分为: 属性特征、统计特征。前者一般是用户或视频的相对静态的属性;后者往往与用户行为有关。
从特征生产的角度来分类,我们又可以把特征划分为:离线特征、实时特征。前者一般产出频率为天级,后者一般为秒级。受限于实时计算的复杂度与性能考量,实时特征一般涵盖范围较离线特征小,更专注于用户行为的实时变化,以及用于捕捉用户短期偏好;相对比的是,离线特征大而全面,它更能描述用户长期偏好。
在框架中,离线、实时特征的制作过程有相应的固定流程,即流水线作业。我们对该制作哪些特征、以及如何制作,都进行了规范化。这里不赘述特征制作方面的工作,主要介绍一下特征产出后被线上服务使用的过程。
1)离线特征灌库:灌库,指的是将离线产出的特征数据,以特定的格式写入高性能KV库(如Couchbase、Redis等),供线上服务读取使用。离线特征产出后,一般存储在HDFS等文件系统中,线上无法直接使用,需要经过灌库才能被线上服务使用。灌库的数据格式由框架的组件——Feature_Online——自动生成。
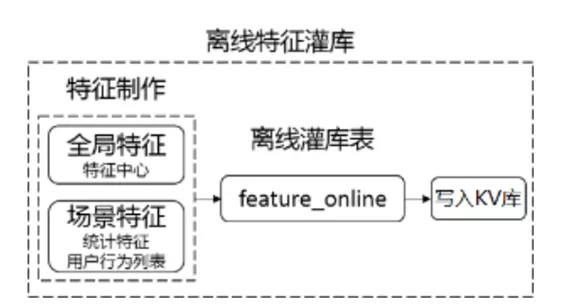
图2 离线特征灌库流程示意图
Feature_Online的目的是通过配置化的方式自动生成固定格式的灌库表。在推荐工程化过程中有一个经典的困扰,就是算法工程师需要花费一定的精力来梳理特征的使用,这部分工作重复度很高且易出错。其采用自动化生成SQL的方式,杜绝了人工操作带来的BUG,具有配置化、严格依赖管理、特征上下线灵活等优势。Feature_Online有几个特性:输入自定义、操作配置化、输出格式统一。
2)实时特征服务:实时特征具有即产出即使用的特性,框架采用DUBBO RPC的方式提供统一的实时特征取数服务,简化了不同推荐场景的接入,响应时间在毫秒级。
实时特征通常专注于行为类来源的特征,例如:用户的实时观影列表、视频的实时统计特征等等。数据来源于线上用户行为日志——展示、点击、观影,经过一个统一的Flink任务进行消费处理,数据被聚合后处理为对应的实时特征,接下来类似于离线特征一样,也是写入高性能KV库中,供线上服务读取使用。数据聚合、灌库的过程都集成在Flink任务当中。
2.2 特征回放
特征回放是将线上服务用于打分排序的特征,通过落日志的方式“回放”下来:就像拍摄视频一样,对每一次请求时所有的特征都进行了记录,并标记了该次请求的事件ID。这样,当我们获取了用户的展示、点击、观影等行为日志之后,通过join事件ID,我们就可以知道在请求那一瞬间的所有特征,这就是“回放”。
特征回放是常用的一种基础的技术手段,在工业界被大量的应用。早期的模型训练方式,一般是使用这一步产出的Features与标注得到的Label进行拼接从而得到训练数据。其存在两个缺陷:
1)离线特征从产出到被线上使用的时间是不确定的,难以确定线上被使用的版本,因而训练数据无法模拟真实的线上环境;
2)缺少实时特征。特征回放解决了这两个缺陷。
如下图所示,当推荐引擎收到调用请求时,会拉取用户和视频的特征,先用这些特征对视频进行打分排序,再将这些特征进行回放。
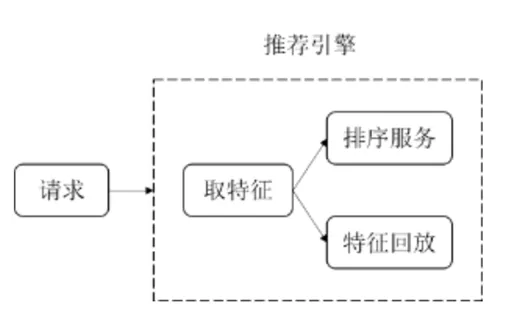
图3 特征回放示意图
特征回放遵循推荐引擎的漏斗模式,参与回放的视频个数等于推荐引擎最终返回的视频个数。
特征回放有2个重要的优势:
1)实时特征参与训练:实时特征一般被认为在推荐中具有重要的意义,是推荐引擎捕捉用户实时兴趣的基础。传统的模型训练样本组织工作,无法获取实时特征:样本组织工作分为构造标注数据、特征数据两部分。特征数据则需要算法工程师自行拼接,未曾记录事件发生时的实时特征,自然也就无法还原在事件发生时用户的实时行为、视频的实时统计指标。特征回放解决了这个问题,将事件ID发生时的实时特征完全记录下来,落在日志中,样本处理只需通过事件ID拼接标注数据即可。
2)线上线下特征一致性:特征一致性一直是制约推荐引擎效果的一个重要问题,如果线上预测使用的特征与线下训练使用的特征不一致,那么推荐的准确性也无从谈起。在特征回放机制下,训练与预测使用同一份特征。预测使用的特征来自于线上服务日志,而线上服务日志来自于请求时引擎获取的特征,两者份属同源,自然一致。
特征回放极大地解放了算法工程师在训练样本组织工作中的精力,使其能够更专注于模型本身的迭代优化,而不是将精力都浪费在清洗、拼接特征和标注数据上面。
下图是目前框架采用的特征回放流程示意图。
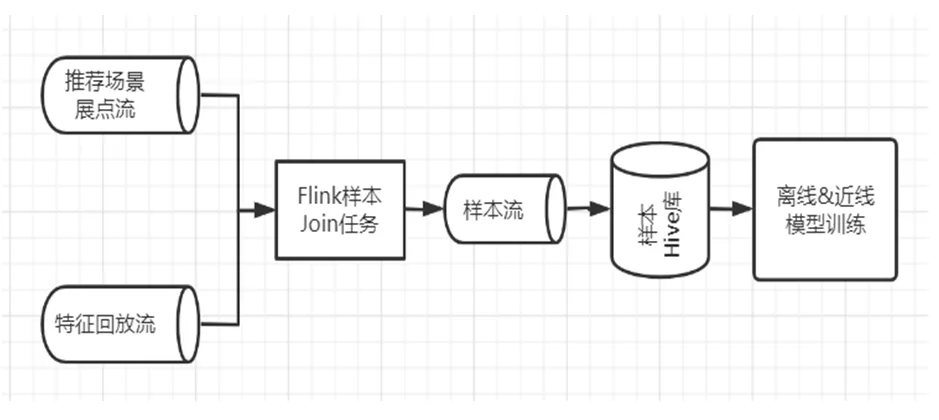
图4 特征回放流程示意图
框架深度结合特征回放机制,这1环节有2大特性:
1)回放服务模板化,接入迅速:在上1小节“2.1 特征制作与灌库”的工作准备完毕后,只需要更改少量的代码,即可部署,极大地减少了这一部分的接入工作量。
2)回放覆盖率监控:数据与特征决定了模型的上限。那么,算法工程师除 了需要关心特征的质量,还需要关心特征的覆盖率。框架集成了通用化的监控组件,对特征回放落地的日志中所有特征的覆盖率有详细的监控数据,做到一目 了然。
特征回放产出了可供训练模型使用的特征集,即Features。
2.3 Training
我们把模型训练抽象为训练数据制作和模型训练(模型训练依托一个配置化的训练框架)这2个部分。
1)训练数据制作:
- Label&Upsampling:Label,即标注数据。除了常规的标注正负样本之外,我们还考虑到对正样本进行Upsampling的问题。正样本Upsampling的本质,是在学习当前目标的基础上,希望对特定的目标进行进一步地学习。例如:在CTR预估中,对时长高的正样本进行Upsampling。在主APP首页猜你喜欢场景中,我们通过Upsampling的方式大幅提升了用户首次播放视频的总次数。
- 特征算子:若当前的推荐场景中有100个特征,经分析其中85个特征能起到更好的作用,因此采用2种不同的特征算子配置,配置1采用全部100个特征,配置2采用85个特征,分别训练2个不同的模型,那么线上就可以使用这2个模型进行AB实验,进而验证业务效果的优劣。
- Label与Features的自由组合:1、相同的Label下比较不同的Features;2、相同的Features下比较不同的Labels。框架可以灵活地支持Label与Features的自由组合,并进行了版本管理。
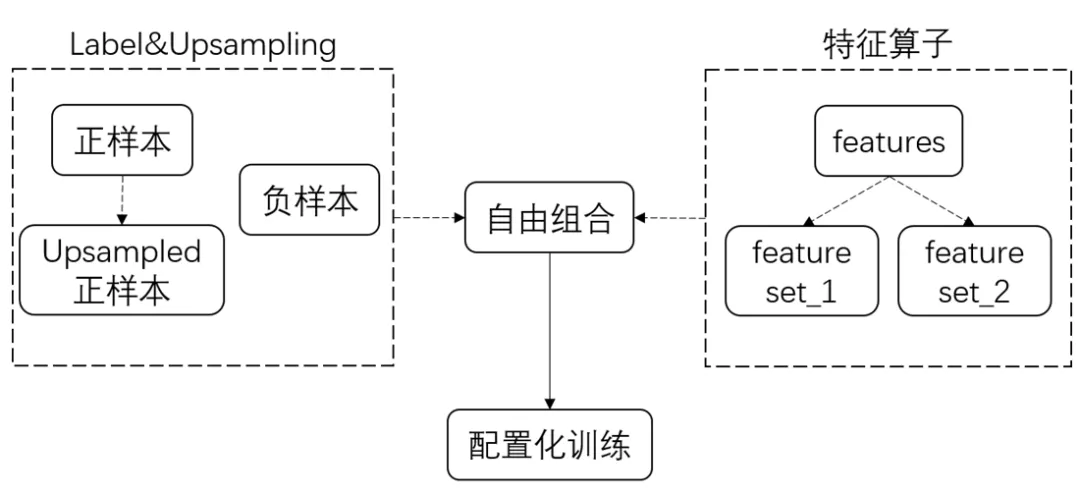
图5 模型训练流程示意图
2)配置化的训练框架:提供了推荐常用模型的训练方案,目前已经支持:DNN、DeepFM、DCN、DIN、DSSM、MMoE等多种模型。只需修改配置文件,无需额外开发模型,即可开始训练。这极大地节省了算法工程师自行开发模型和调参的工作精力。保存的模型为固定格式,无缝衔接地对接线上的TF-Serving服务,更好更快地服务于业务效果的优化迭代。
- Make TFRecords:将训练数据转换为TFRecords文件形式来进行训练,格式固定,包含3种数据:Label,离散特征,连续特征。
- Choose Model:在已经已经支持的模型内选择需要训练的模型结构;一般来讲,一份数据可以训练多种结构的模型用以AB测试。可以通过编写少量的代码自定义新的模型结构。
- Define Config:通过配置的形式来指定模型训练使用的超参数、数据集、特征定义、网络结构参数、网络顶层输出方式等关键性的参数,模型调参十分便捷。
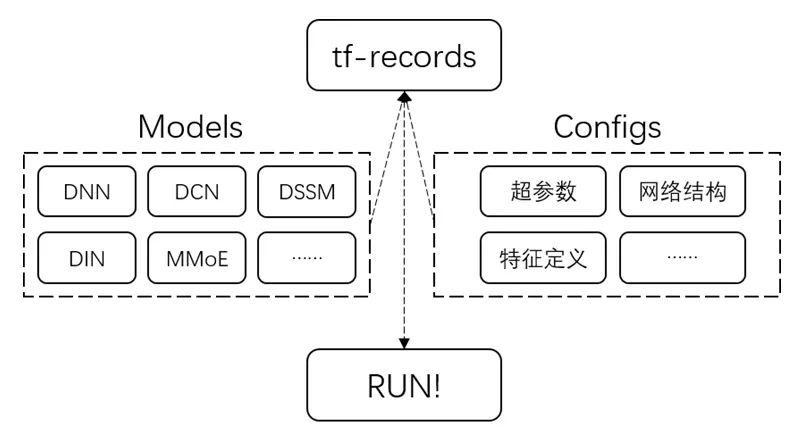
图6 配置化训练框架示意图
2.4 Ranking
Ranking在框架中分为2个环节: 1)推理服务;2)排序服务
1)推理服务,即依托于TensorFlow Saved Model的TF-Serving。
2)排序服务是承接推荐引擎与推理服务的桥梁,如图7所示。
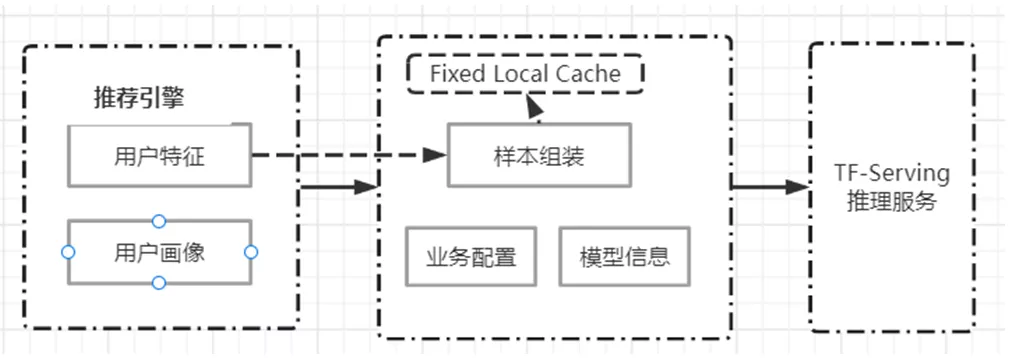
图7 Rank服务架构图
Rank服务通过优化提供了快速部署和高性能的预测能力,主要包括:
- 用户特征前置,有两点好处:
1)引擎获取设备特征可以配置较长的超时时间,提升获取用户特征的成功率;
2)如果引擎获取成功,排序服务不需要再取用户特征,如果请求告知引擎获取用户特征失败,排序服务尝试取用户特征,进一步提升用户特征参与模型预测的成功率;
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%80%9A%E7%94%A8%E6%8E%92%E5%BA%8F%E6%A1%86%E6%9E%B6%E5%9C%A8%E7%88%B1%E5%A5%87%E8%89%BA%E6%8E%A8%E8%8D%90%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


