透过现象看机器学习奥卡姆剃刀没有免费的午餐丑小鸭定理等
编辑来源:Datawhale
作者:邱锡鹏,复旦大学教授
寄语:本文对 PAC 学习理论、没有免费的午餐定理、丑小鸭定理、奥卡姆剃刀原理等机器学习中有名的理论或定理进行了详细的梳理。
在机器学习中,有一些非常有名的理论或定理,这些理论不仅有助于我们从本质理解机器学习特性,更好地学习相关理论,更重要的是可以有助于我们理解很多生活哲学,比如奥卡姆剃刀原理所延伸的极简主义:如无必要,勿增实体的理念,让我们一起细品吧。
没有免费午餐定理
没有免费午餐定理(NFL)是由 Wolpert 和 Macerday 在最优化理论中提出的。没有免费午餐定理证明:对于基于迭代的最优化算法,不存在某种算法对所有问题(有限的搜索空间内)都有效。
如果一个算法对某些问题有效,那么它一定在另外一些问题上比纯随机搜索算法更差。也就是说,不能脱离具体问题来谈论算法的优劣,任何算法都有局限性。 必须要“具体问题具体分析”。
没有免费午餐定理对于机器学习算法也同样适用。不存在一种机器学习算法适合于任何领域或任务。 如果有人宣称自己的模型在所有问题上都好于其他模型,那么他肯定是在吹牛。

丑小鸭定理
丑小鸭定理(Ugly Duckling Theorem)是 1969 年由渡边慧提出的[Watanable,1969]。“丑小鸭与白天鹅之间的区别和两只白天鹅之间的区别一样大”。这个定理初看好像不符合常识,但是仔细思考后是非常有道理的。
因为世界上不存在相似性的客观标准,一切相似性的标准都是主观的。
如果从体型大小或外貌的角度来看,丑小鸭和白天鹅的区别大于两只白天鹅的区别;但是如果从基因的角度来看,丑小鸭与它父母的差别要小于它父母和其他白天鹅之间的差别。

奥卡姆剃刀原理
奥卡姆剃刀原理是由 14 世纪逻辑学家 William of Occam 提出的一个解决问题的法则:“如无必要,勿增实体“。

奥卡姆剃刀的思想和机器学习上正则化思想十分类似:简单的模型泛化能力更好。如果有两个性能相近的模型,我们应该选择更简单的模型。
因此,在机器学习的学习准则上,我们经常会引入参数正则化来限制模型能力,避免过拟合。
 奥卡姆剃刀的一种形式化是最小描述长度(Minimum Description Length,MDL)原则,即对一个数据集𝒟,最好的模型𝑓 ∈ ℱ 是会使得数据集的压缩效果最好,即编码长度最小。
奥卡姆剃刀的一种形式化是最小描述长度(Minimum Description Length,MDL)原则,即对一个数据集𝒟,最好的模型𝑓 ∈ ℱ 是会使得数据集的压缩效果最好,即编码长度最小。
最小描述长度也可以通过贝叶斯学习的观点来解释[MacKay, 2003]。模型𝑓 在数据集𝒟 上的对数后验概率为
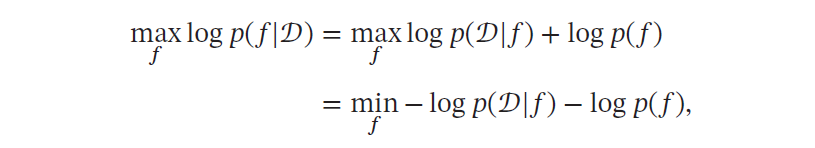
其中 − log 𝑝(𝑓) 和 − log 𝑝(𝒟| 𝑓) 可以分别看作是模型𝑓 的编码长度和在该模型下数据集𝒟 的编码长度。也就是说,我们不但要使得模型𝑓 可以编码数据集𝒟,也要使得模型𝑓 尽可能简单。
PAC 学习理论
当使用机器学习方法来解决某个特定问题时,通常靠经验或者多次试验来选择合适的模型、训练样本数量以及学习算法收敛的速度等。
但是经验判断或多次试验往往成本比较高,也不太可靠,因此希望有一套理论能够分析问题难度、计算模型能力,为学习算法提供理论保证,并指导机器学习模型和学�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%80%8F%E8%BF%87%E7%8E%B0%E8%B1%A1%E7%9C%8B%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%A5%A5%E5%8D%A1%E5%A7%86%E5%89%83%E5%88%80%E6%B2%A1%E6%9C%89%E5%85%8D%E8%B4%B9%E7%9A%84%E5%8D%88%E9%A4%90%E4%B8%91%E5%B0%8F%E9%B8%AD%E5%AE%9A%E7%90%86%E7%AD%89/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


