近期知识图谱顶会论文推荐你都读过哪几篇
精选 5 篇来自 EMNLP 2018、CIKM 2018、NAACL 2018 和 IJCAI 2018 的知识图谱相关工作,带你快速了解知识图谱领域最新研究进展。
本期内容选编自微信公众号「开放知识图谱」。
EMNLP 2018


■ 论文解读 | 刘兵,东南大学博士,研究方向为自然语言处理、信息抽取
论文动机
在远程监督任务中,除了语料的错误标注问题,还存在 句内噪声单词过多 的问题,即多数句子都存在一些与表达关系无关的词汇,这个问题未有人关注。当前研究的另一个问题是, 句子特征抽取器采用随机初始化的方法,存在不健壮的问题。
针对句内噪声的问题,本文采用 子树解析 的方法,去除与表达关系不相关的词汇;针对关系抽取器不健壮的问题,本文采用 迁移学习 的方法,用实体分类对模型的参数做预训练。
论文模型
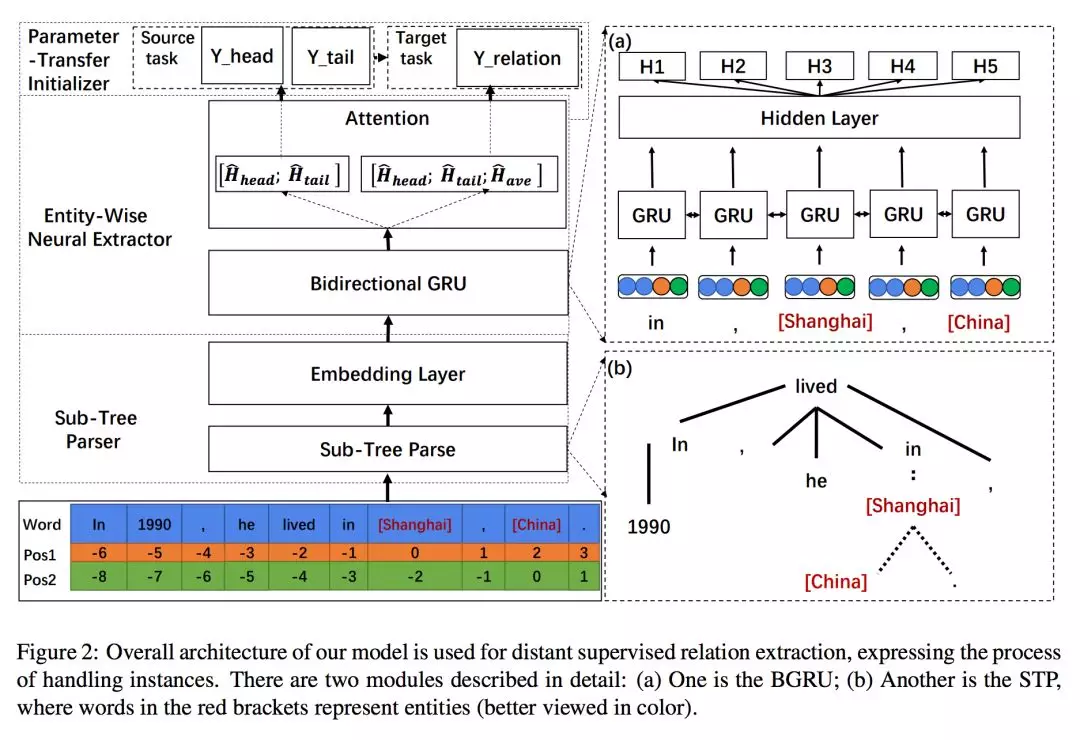
本文方法包括三个部分:
**1. 子树解析:**首先对句子做句法解析,然后找到两个实体最近的共有祖先,最后取以该节点为根节点的子树,保留句子中的这部分,其余部分丢弃;
**2. 构造含有多个注意力机制的关系抽取器:**采用 BGRU 作为句子语义抽取器,抽取器中添加面向单词的注意力和面向实体的注意力。然后采用面向句子的注意力方法,结合一个实体对对齐的多个句子的信息作为实体对间关系的语义表示,用于后续的关系分类;
**3. 参数迁移初始化:**将模型部分结构用于实体类型分类任务,训练得到的参数用作关系抽取器相应参数的初始化。
实验
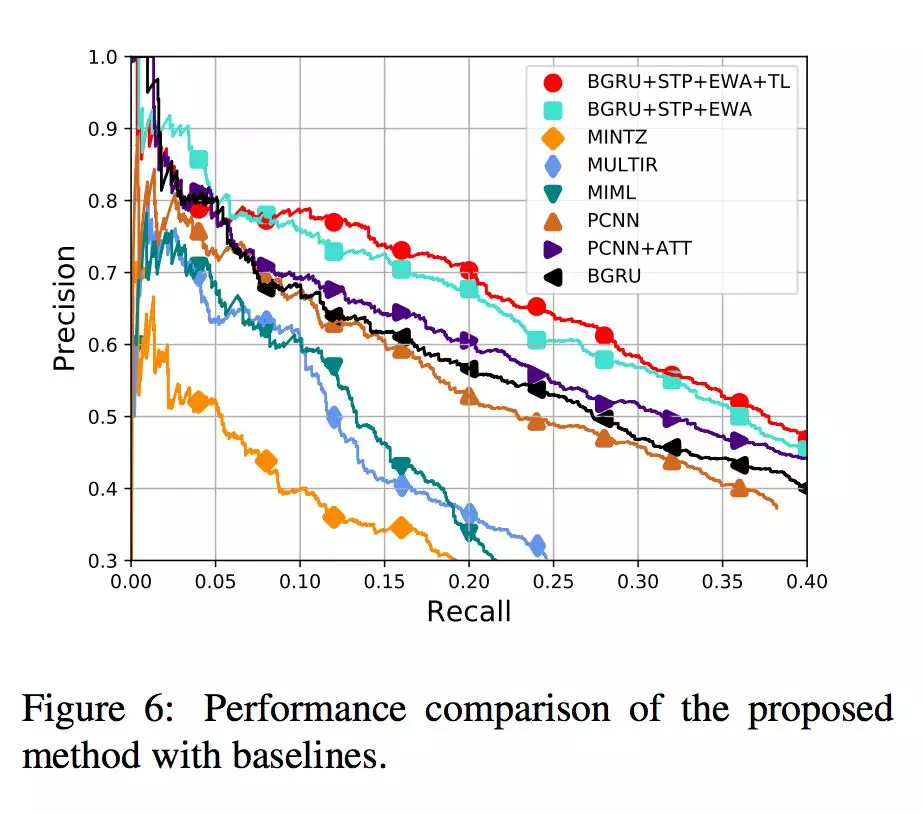
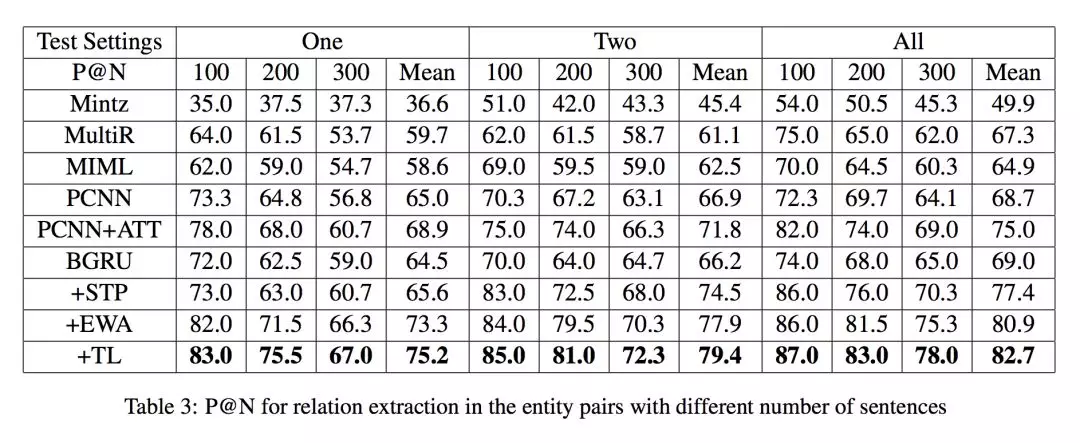
本文实验进行了 held-out evaluation 和 manual evaluation,结果如下图所示,可见取得了较好的效果。
NAACL 2018


■ 论文解读 | 谭亦鸣,东南大学博士,研究方向为知识库问答、自然语言处理
本文关注任务为面向简单问题的知识库问答(仅用 KB 中的一个事实就能回答问题)。作者将任务划分为实体检测,实体链接,关系预测与证据整合,探究了简单的强基线。
通过基于 SIMPLEQUEST IONS 数据集上的实验,**作者发现基本的 LSTM 或者 GRU 加上一些启发式方法就能够在精确度上接近当前最优,并且在没有使用神经网络的情况下依然取得相当不错的性能。**这些结果反映出前人工作中,某些基于复杂神经网络方法表现出不必要的复杂性。
论文动机
近期的简单知识库问答工作中,随着神经网络模型复杂性的增加,性能也随之提升。作者认为这种趋势可能带来对网络结构有效性理解的缺失,Melis 等人的研究也佐证了这一点。他们发现,标准的 LSTM 通过适当的调参,就可以得到堪比最新网络模型的性能。
从这一观点出发,作者尝试去除不必要的复杂结构,直到获得一个尽可能简单但是性能优异的模型。
方法
实体检测(Entity Detection)
实体检测的目标是确认问题相关的实体,可以抽象为序列标注问题,即识别问题中的每个字符是否是实体。考虑到涉及序列处理,采用 RNN 是相对流行的做法。
在神经网络策略上,作者以问句的词嵌入矩阵作为输入,在双向LSTM和GRU上进行实验。因为是构建 baseline,作者并未在网络模型上添加 CRF 层。
非神经网络方法则选用 CRF,特征包括:词位置信息,词性标注,n-gram 等等。通过实体检测,可以得到表达实体的一系列关键词(字符)。
实体链接(Entity Linking)
作者将实体链接抽象为模糊字符串匹配问题,并未使用神经网络方法。
对于知识库中的所有实体,作者预先构造了知识库实体名称 n-gram 的倒排索引,在实体链接时,作者生成所有候选实体文本相应的 n-gram,并在倒排索引中查找和匹配它们(策略是优先匹配较大粒度的 n-gram)。获取到可能的实体列表后,采用 Levenshtein Distance 进行排序筛选。
关系预测(Relation Prediction)
关系预测的目标是确定问题所问的关系信息,作者将其抽象为句子分类问题。对于这个子任务,作者在神经网络方法分别尝试了 RNN 与 CNN 两种。
**RNNs:**与实体检测类似,作者也采用双向 RNN 与 GRU 构建模型,并仅依据隐状态作为证据进行分类,其他与目标检测模型一致。
**CNNs:**这里引用 Kim 等人(2014)的工作,简化为单通道,使用 2-4 宽度做特征映射。
非神经网络方法则采用了逻辑回归策略(Logistic Regression),特征方面选择了两组,其一是 tfidf 与 bi-gram,其二是词嵌入与关系词。
证据整合(Evidence Integration)
该任务的目标是从前面生成的 m 个候选实体与 n 个关系中选出 (m!=n) 一个实体-关系组合。 作者首先生成 m*n 个候选组合,考虑到实体检测和关系预测是相对独立的模型,这意味着很多组合意义不大,可以做初步消除。
在组合打分策略上,考虑到知识库中相同的共享节点,比如所有姓名为“亚当斯密”的人,作者对出现频率过高的实体进行打分限制。
实验结果
对比实验基于 SIMPLEQUESTIONS 数据集,并划分数据规模:训练集 75.9K,验证集 10.8K,测试集 21.7K。
作者进行了实体链接、关系预测和 end2end 问答三组实验:
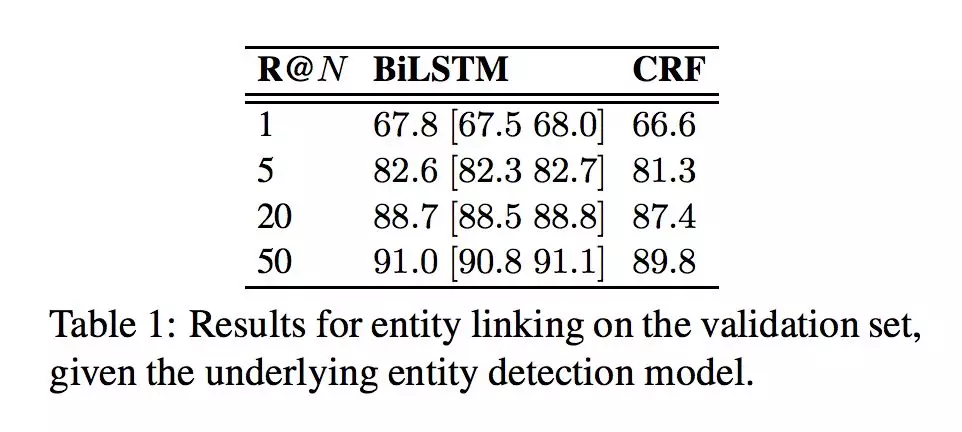
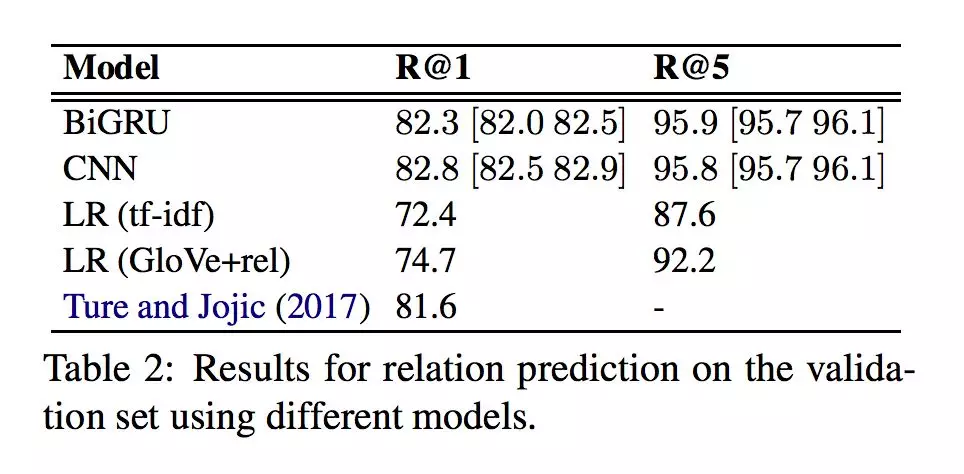

从各组实验的结果可以发现,本文建立的基础结构模型所得到的baseline在三个任务中,均超过了部分较新的工作。
总结
实验结果有效验证了作者的观点,基本的 LSTM 或者 GRU 通过有效的调试,能够在精确度上接近当前最优,而非神经网络方法配合新的特征组合也能够取得相当不错的性能。
CIKM 2018


■ 论文解读 | 黄焱晖,东南大学硕士,研究方向为知识图谱,自然语言处理
本文主要关注 Network Embedding 问题,以往的 network embedding 方法只将是网络中的边看作二分类的边 (0,1),忽略了边的标签信息。**本文提出的方法能够较好的保存网络结构和边的语义信息来进行 Network Embedding 的学习。**实验结果证明本文的方法在多标签结点分类任务中有着突出表现。
研究背景
Network Embedding 的工作就是学习得到低维度的向量来表示网络中的结点,低维度的向量包含了结点之间边的复杂信息。这些学习得到的向量可以用来结点分类,结点与结点之间的关系预测。
论文模型
本文将总体的损失函数分为两块:Structural Loss 和 Relational Loss,定义为:
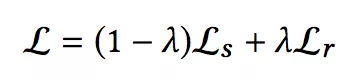
Structural Loss:
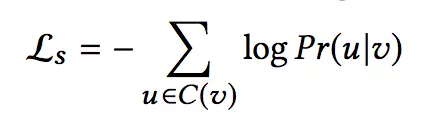
给定中心结点 u,模型最大化观察到“上下文”结点 v 的情况下 u 的概率,C(v) 表示点 v 的“上下文”结点,“上下文”结点不是直接连接的结点,而是用类似于 DeepWalk 中的 random walk 方法得到。通过不断在网络中游走,得到多串序列,在序列中结点V的“上下文”结点为以点V为中心的窗口大小内的结点。
本文采用 skip-gram 模型来定义 Pr(u|v),Φ(v) 是结点作为中心词的向量,Φ‘(v) 是结点作为“上下文”的向量。Pr(u|v) 的定义为一个 softmax 函数,同 word2vec 一样,采用负采样的方法来加快训练。
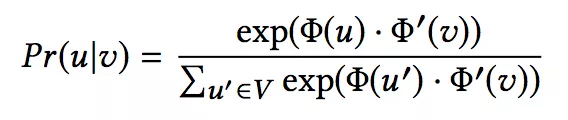
Relational Loss:
以前也有方法利用了结点的标签,但是没有利用边的标签信息。本文将边的标签信息利用起来。边 e 的向量由两端的结点 u,v 定义得到,定义为:
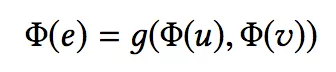
其中 g 函数是将结点向量映射为边向量的函数 Rd*Rd->Rd’ ,本文发现简单的连接操作效果最好。
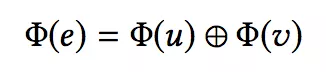
将边的向量信息置入一个前馈神经网络,第 k 层隐藏层定义为:
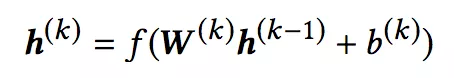
其中,W(k) 为第 k 层的权重矩阵,b(k) 为第 k 层的偏置矩阵,h(0)=Φ(e)。
并且将预测出的边的标签与真实的边的标签计算二元交叉损失函数。真实的边的标签向量为 y,神经网络预测的边的标签向量为 yˆ。边的损失函数定义为:
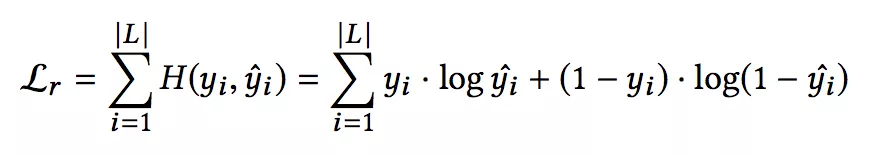
本文算法的伪代码如下:

结果分析
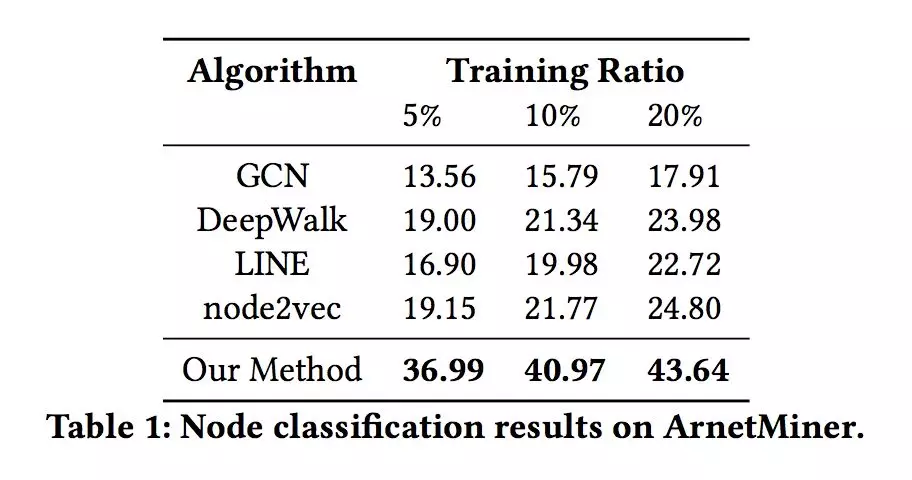
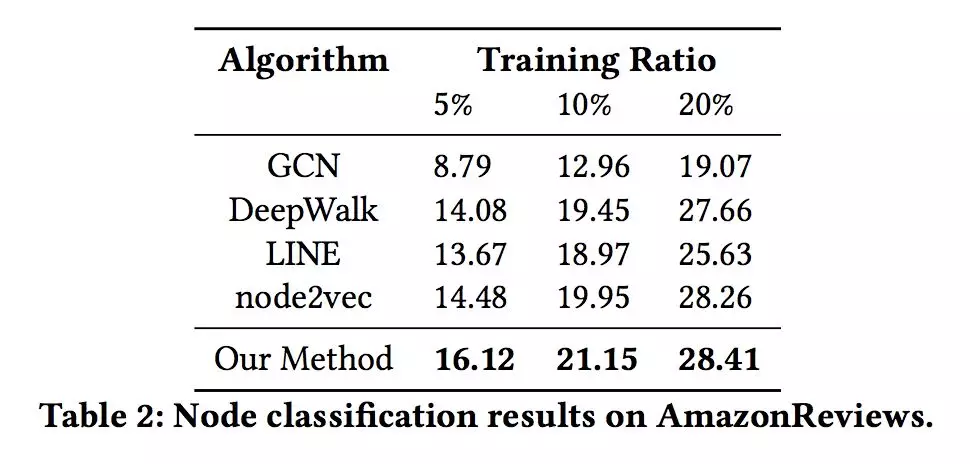
表 1 和表 2 展示了五种方法在两个数据集上结点分类的表现。本文使用了 5%,10%,20% 含有标签的结点。本文考虑到了在现实中,有标签关系的稀有性,所以本文只使用了 10% 的标签数据。
可以观察到即使是很小比例的标签关系,结果也优于基础方法。在 ArnetMiner 数据集上表现得比 AmazonReviews 好的原因是,类似于 ArnetMiner 数据集的协作网络,关系的标签通常指明了结点的特征了,所以对于结点分类来说,高于 AmazonReviewers 是正常现象。
总结
本文的方法相比于以往的 Network Embedding 方法的优势在于,**除了利用了网络的结构信息,同时也利用了网络中的边的标签信息。**在真实世界的网络中证实了本文的方法通过捕捉结点之间的不同的关系,在结点分类任务中,网络中的结点表示能获得更好的效果。
EMNLP 2018


■ 解读 | 杨帆,浙江大学硕士,研究方向为知识图谱、自然语言处理
论文动机
如今的知识图谱规模很大但是完成度不高,long-tail 关系在知识图谱中很常见,之前致力于完善知识图谱的方法对每个关系都需要大量的训练样本(三元组),而新加入的关系其样本数量通常不是很多。
为解决这个问题, 本文提出了 One-Shot 场景下的关系学习模型,该模型通过学习实体的 embedding 和相应的局部图结构来获得一个匹配度量函数,最终推导出新的三元组。
论文亮点
本文提出的模型有以下亮点:
1. 只依赖于实体的 embedding 和局部图结构(之前的方法依赖于关系的良好表示);
2. 一旦训练完成便可以预测任何关系(之前的方法需要微调来适应新的关系)。
概念
本文主要针对 (h,r,?) 类型的推测,即从候选集合中选出最合适的 t 来构造新的三元组 (h,r,t),主要符号含义如下:
G{(h,r,t)}:即原始 KG,三元组集合
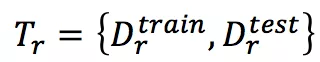 :对应于 G 中的一个关系(任务),每个 Tr 中所有三元组的 r 相同
:对应于 G 中的一个关系(任务),每个 Tr 中所有三元组的 r 相同
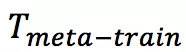 :任务集合
:任务集合
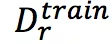 :只含有一个三元组
:只含有一个三元组
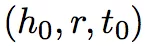
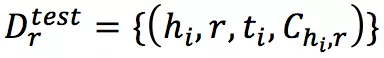 :
:
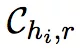 为候选 t 集合
为候选 t 集合
G’:G 的子集,作为背景知识
论文模型
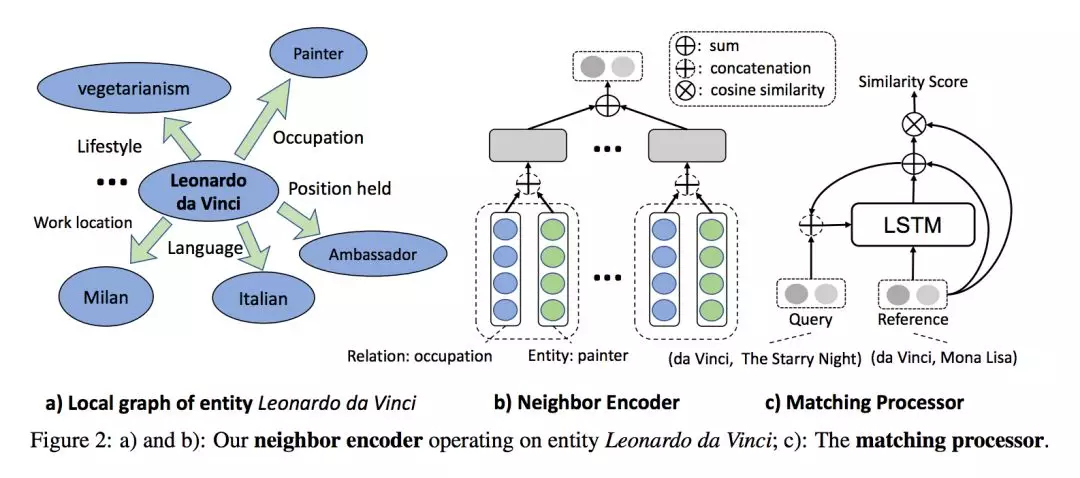
本文模型由两部分组成:
**1. Neighbor Encoder:**该模块利用局部图结构对(h,t)实体对进行编码,首先对任意 h/t 构建其 one-hop Neighbor set Ne,再利用 Encoding function f(Ne)编码,最后将 h 和 t 的编码连接起来便得到 (h,t) 实体对的表示,f(Ne) 形式如下:
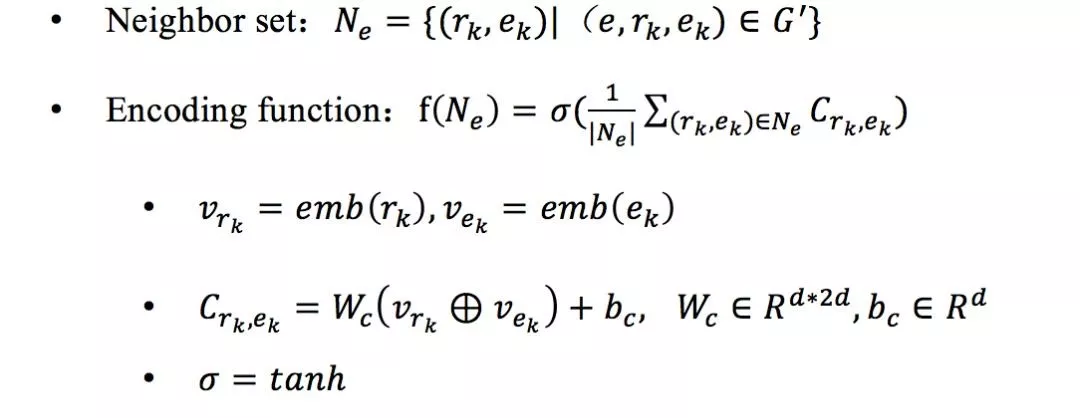
**2. Matching Processor:**对于候选集
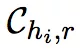 中的每一个
中的每一个
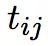 ,利用 LSTM 计算
,利用 LSTM 计算
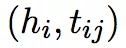 和
和
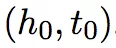 的相似度,相似度最高的
的相似度,相似度最高的
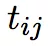 即为
即为
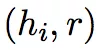 对应的 t,迭代过程如下:
对应的 t,迭代过程如下:
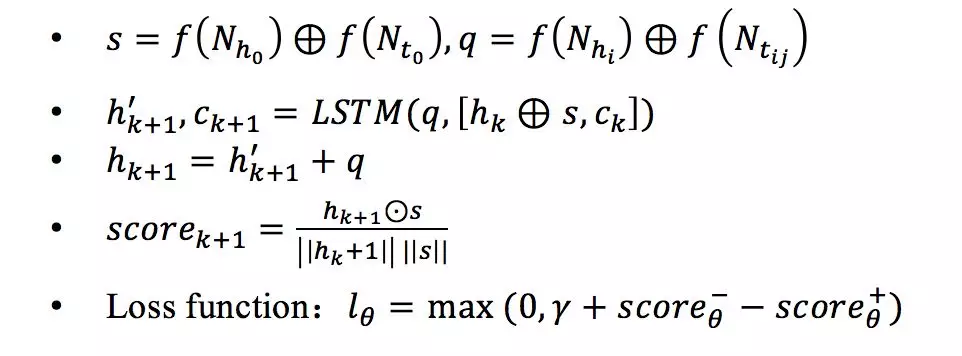
实验
数据集
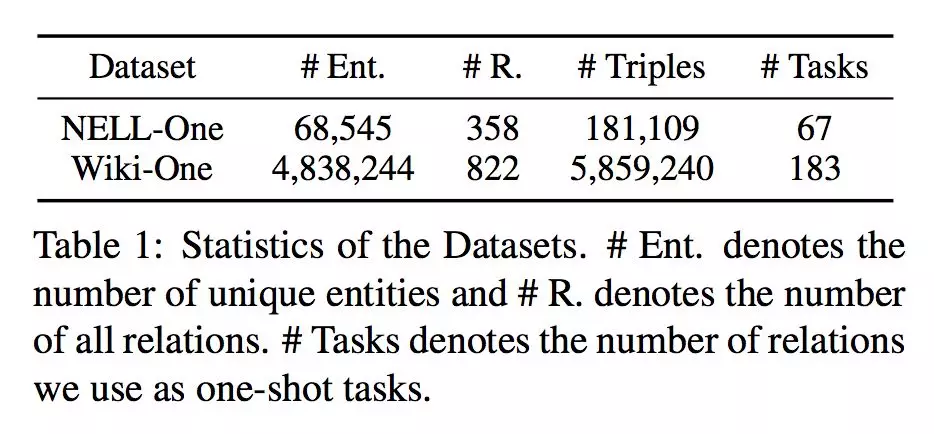
本文的两个数据集 NELL-One 和 Wiki-One 是作者分别基于 NELL 和 Wikidata 构建(选取其中三元组数量在 50~500 之间的关系)。
**实验结果 **
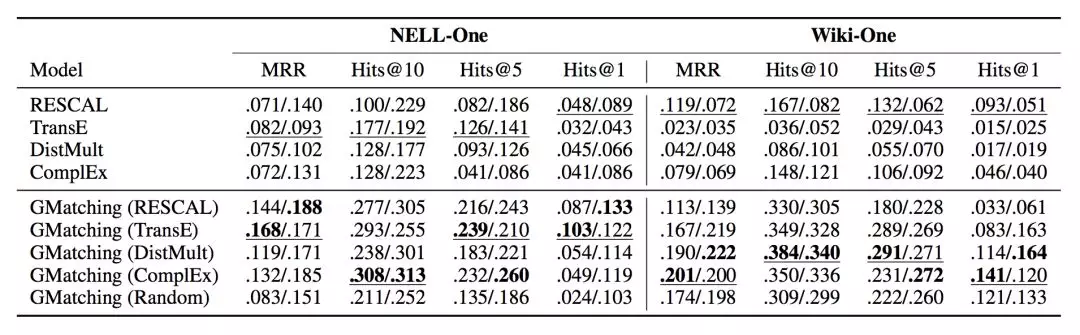
作者将本文提出的模型(GMatching)与之前基于 embedding 的模型在 NELL-One 和 Wiki-One 两个数据集上进行了比较,结果显示该模型各项指标均优于之前的模型。
总结
本文提出的模型利用实体的局部图结构以及学习度量来匹配实体对,一经训练可以直接适用于预测任何关系,并在 One-Shot 场景下表现出优越性能。
IJCAI 2018


■ 论文解读 | 汪寒,浙江大学硕士,研究方向为知识图谱、自然语言处理
论文动机
传统的规则挖掘算法因计算量过大等原因无法应用在大规模 KG 上。为了解决这个问题, 本文提出了一种新的规则挖掘模型 RLvLR (Rule Learning via Learning Representation),通过利用表示学习的 embedding 和一种新的子图采样方法来解决之前工作不能在大规模 KG 上 scalable 的问题。
论文亮点
本文亮点主要包括:
1. 采样只与对应规则相关的子图,在保存了必要信息的前提下极大减少了算法的搜索空间和计算量;
2. 提出了 argument embedding,将规则表示为 predicate sequence。
概念
1. closed-pathrule,LHS 记为 body(r),RHS 记为 head(r);
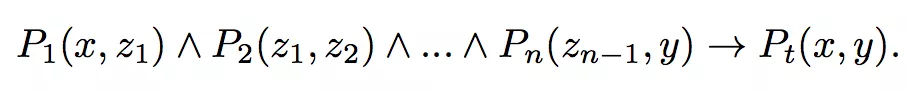
2. support degree of r,满足 r 的实体对个数;
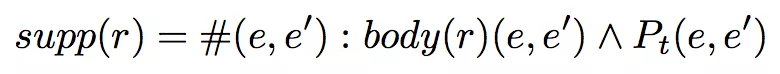
3. standard confidence 和 head coverage。
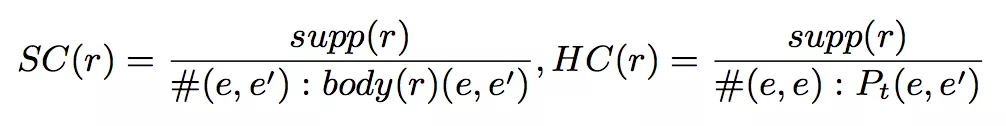
论文方法

Sampling Method
以 head predicate Pt 为输入,把 KG 看成无向图,选择到 Pt 的头尾实体路径长不超过 len-1 的实体和关系组成子图 K’=(E’,F’),后面所有的计算都基于这个子图。
**Argument Embedding **
对于谓词 P,它的 subject argument 定义为所有出现在 subject 上实体的 embedding 的加权平均,object argument 则为尾实体上实�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%BF%91%E6%9C%9F%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E9%A1%B6%E4%BC%9A%E8%AE%BA%E6%96%87%E6%8E%A8%E8%8D%90%E4%BD%A0%E9%83%BD%E8%AF%BB%E8%BF%87%E5%93%AA%E5%87%A0%E7%AF%87/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


