趣头条基于的实时数据分析平台

分享嘉宾:王金海 趣头条
编辑整理:王彦
内容来源:Flink Forward Asia
出品平台:DataFunTalk
导读: 趣头条一直致力于使用大数据分析指导业务发展。目前在实时化领域主要使用 Flink+ClickHouse 解决方案,覆盖场景包括实时数据报表、Adhoc 即时查询、事件分析、漏斗分析、留存分析等精细化运营策略,整体响应 80% 在 1 秒内完成,大大提升了用户实时取数体验,推动业务更快迭代发展。
本次分享主要内容:
- 业务场景与现状分析
- Flink to Hive 的小时级场景
- Flink to ClickHouse 的秒级场景
- 未来规划
趣头条的查询页面,分为离线查询和实时查询。离线查询有 presto,spark,hive 等,实时查询则引入了 ClickHouse 计算引擎。

上图为实时数据报表,左边为数据指标的曲线图,右边为详细数据指标,目前数据指标的采集和计算,每五分钟一个时间窗口,当然也会有三分钟或者一分钟的特殊情况。数据都是从 Kafka 实时导入 ClickHouse 进行计算的。
1. 小时级实现架构图
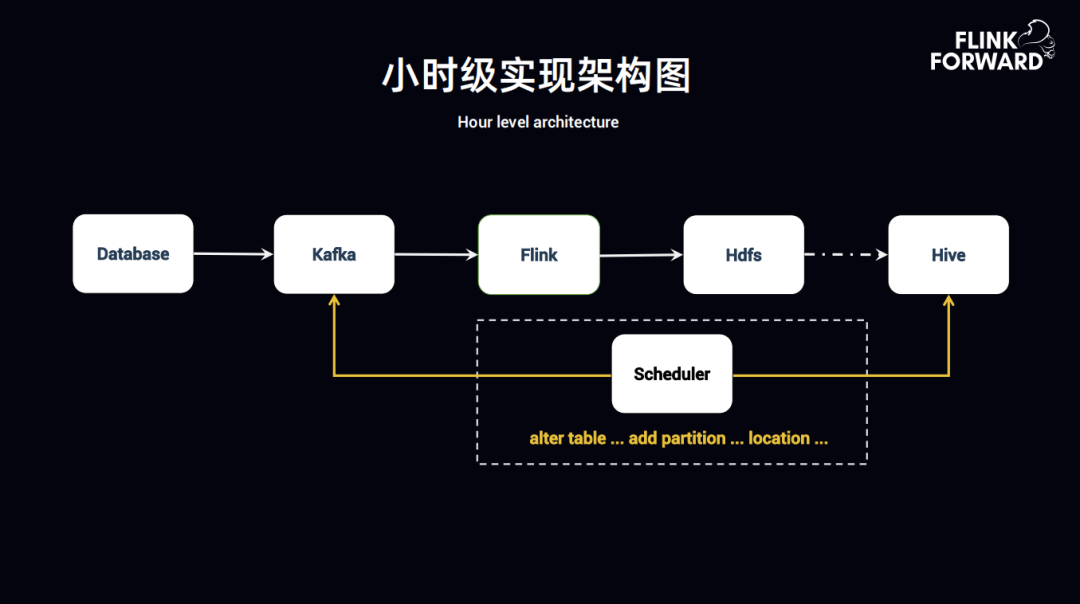
Flink-to-Hive 小时级实现架构图如图所示,架构实现的思路如下:
Database 中的 Binlog 抽数据到 Kafka,同时 Log server 数据也会上报到 Kafka,所有的实时数据落地到 Kafka 之后,通过 Flink 抽取到 HDFS 上。HDFS 到 Hive 之间有条虚线,即 Flink 落地到 HDFS 后,通过程序监控,Flink 在消费完成时,数据落地到 Hive 中可能是小时级的或者是半小时级的,甚至是分钟级的,此时需要知道数据的 Event time 已经到了什么时间,然后再去触发比如 alert table、add partition、 add location 等,把分区写进 Hive 中。这时还需要看一下当前的 Flink 任务的数据时间消费到了什么时间,如 9 点的数据要落地时,需要看一下 Kafka 里 Flink 数据消费是否到了 9 点,然后在 Hive 中触发分区写入。
2. 实现原理
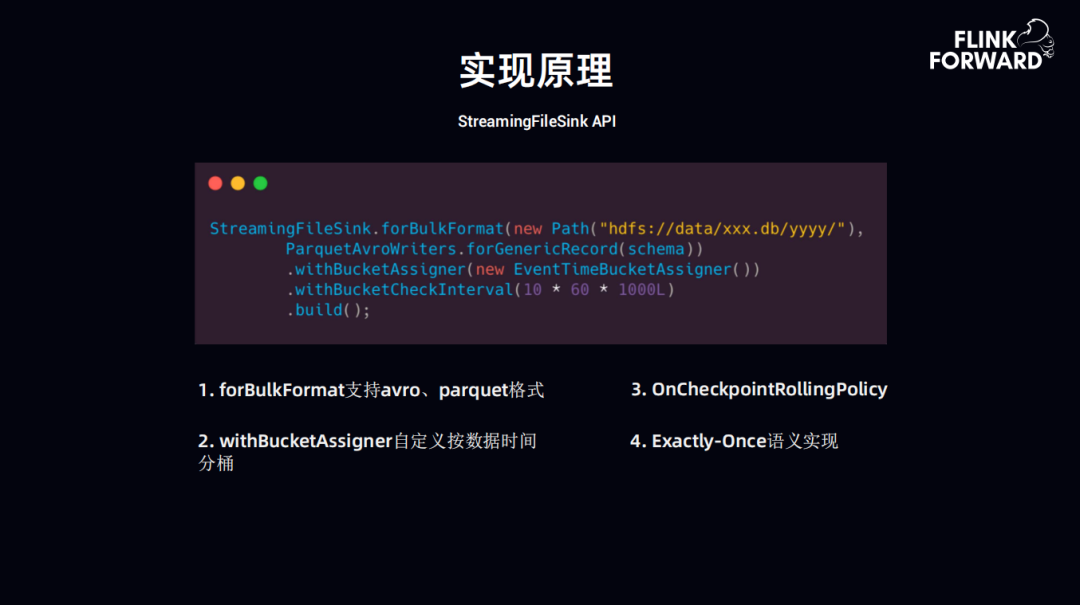
这块的实现原理主要是使用 Flink 高阶版本的特性 StreamingFileSink。
StreamingFileSink 的主要功能如下:
- forBulkFormat 支持 avro、parquet 格式,也就是支持链式的存储格式
- withBucketAssigner 自定义按数据时间分桶,支持数据时间的分桶,上图用到该功能的地方定义了一个 EventtimeBucket,按照数据的时间落地到离线中
- OnCheckpointRollingPolicy,会根据 CheckPoint 时间来进行数据的落地,此处可以理解为按照数据的时间,比如按照一定的 CheckPoint 时间内进行数据落地、回滚,数据落地策略还可以按照数据大小落地
- Exactly-Once 语义实现,Flink 中自带的 StreamingFileSink 是用 Exactly-Once 语义来实现的。Flink 中有两个 Exactly-Once 的实现,第一个是 Kafka 的 Exactly-Once,第二个是 StreamingFileSink 实现了 Exactly-Once 语义,像上图中 CheckpointRollingPolicy 设置的是十分钟落地一次到 HDFS 文件中
下面来具体说一下 Exactly-Once 是如何实现的。
\\ ① Exactly-Once**
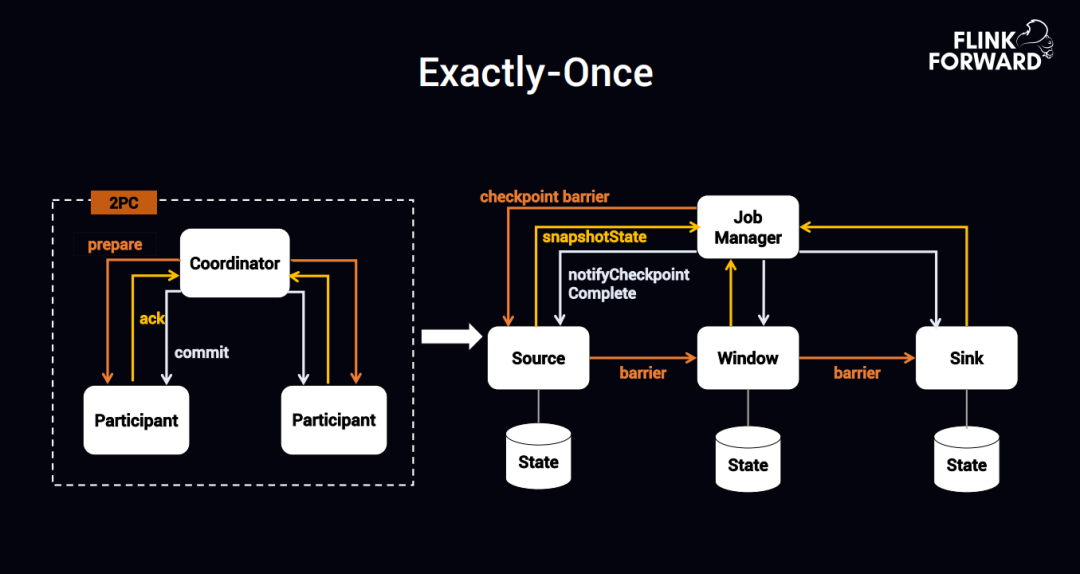
具体实现 Exactly-Once 的方式,如上图所示,左侧是一个二阶段的模型,Coordinator 发一个 perpare,所有的参与者或者执行者开始触发 ack 动作,Coordinator 收到所有人的 ack 动作后,就开始执行 commit,所有的执行者就把左右的数据进行落地。到了 Flink 这块,Source 收到了 checkpoint barrier 流的时候,开始触发 snapshorState 发送到 Job Manager,Job Manager 把所有的 CheckPoint 都完成以后,会发送一个 notifyCheckpointComplete,Flink 这块跟上图左边的二阶段提交协议是一致的,Flink 也是可以实现二阶段提交协议的。
\\ ② 如何使用 Flink 实现二阶段提交协议**
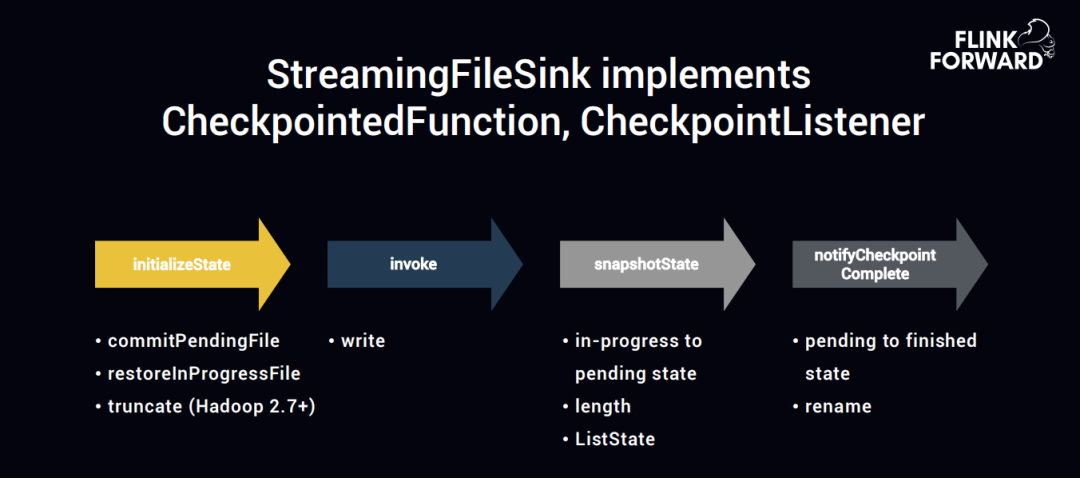
首先 StramingFileSink 实现了两个接口,分别是 CheckpointedFunction 和 CheckpointListener。
- CheckpointedFunction 实现了 initialzeState 和 snaoshotState 这两个函数;
- CheckpointListener 是 notifyCheckPoint Complete 的方法实现。
所以这两个接口可以实现二阶段提交的语义,initialzeState 算子刚启动的时候,它会启动三个动作 commitpendingFile、restoreInProgressFile、truncate。
第一步 commitpedingFile,也就是实时的数据落地到 HDFS 的时候,有三个状态,第一个状态是 in-progress,即正在进行中的一个状态,第二个状态是 pending 的状态,第三个状态是 finish 的状态。
在实时的写入时,如果 CheckPoint 还没有在这之间成功的时候,程序出问题了,那接下来启动的时候就会触发 initialzeState,会把曾经 pending 的 file 进行 commit,然后把写了一半的文件比如 in-progress 文件重置或者截断,进行重置或者截断是使用的是 Hadoop 的 2.7 版本的 turncate 方式。也就是数据在一直写入,但是写入没有达到一个 CheckPoint 周期,也就是说中间数据断开了,下一次启动的时候,要么把之前没有写完整的数据截断掉,之前 CheckPoint 触发已经写好的数据直接 commit。
第二步 invoke 就是数据实时的写入
第三步 snapshotState 在触发 CheckPoint 的时候会把 in-progress 文件转成 pending state 文件,也就是开始提交文件,同时记录 length 长度。记录长度是因为前边的步骤需要 truncate 来截断多长,snapshot 时,是没有真正的写入到 HDFS,其实是写入到 ListState,等所有的 CheckPoint 算子都完成了,就把 ListState 中的数据都刷到 HDFS 中,只要数据存在 Flink 自带的 state 中,不断把数据成功的刷到 HDFS 中就行了。
第四步 notifyCheckPoint Complete 会触发 pending 动作到 finished 状态的数据写入,实现的方式直接使用 rename,Streaming 会不断的写入 HDFS 中的临时文件,等到 notifyCheckPoint 结束之后,直接做一个 rename 动作,写成正式文件。
3. 跨集群多 nameservices

趣头条的实时集群跟离线集群是独立的,实时集群目前是一套,离线集群是有多套。通过实时集群要写入到离线集群,这样就会遇到一个问题,HDFS nameservices 问题,如果在实时集群中把所有的离线集群的 nameservice 用 namenode HA 的方式全部打入到实时集群,是不太合适的。所以使用 Flink 任务中 resource 下边把 HDFS 中的 XML 文件中间加 final 标签,设置为 true。此处的 value 标签中,stream 是一个实时集群,date 是一个离线集群,这样把两个 HA 配置在 value 标签,从而达到实时集群是实时集群,离线集群是离线集群,中间的 HDFS 中 set 不需要相互修改,直接在客户端时间就行了。
4. 多用户写入权限
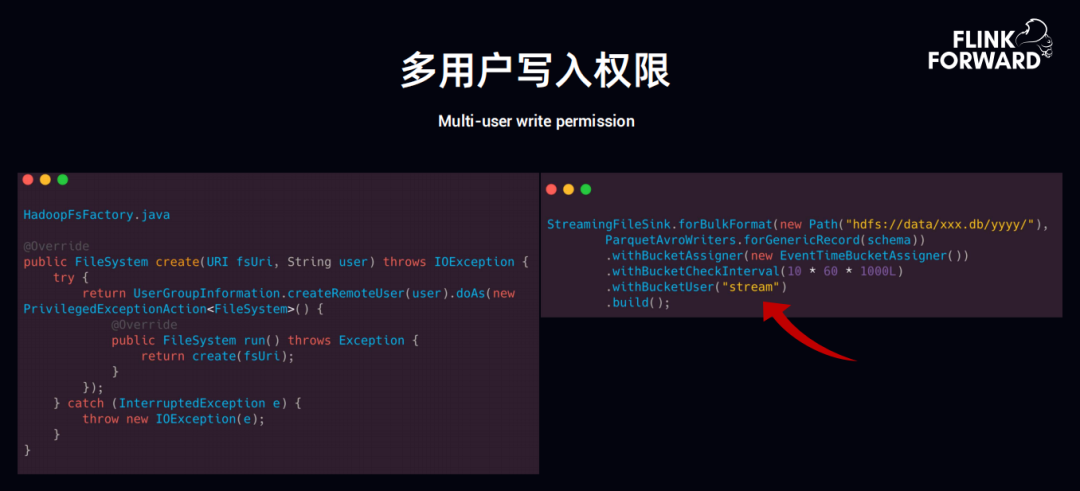
针对多用户权限写入的问题,实时写入离线 HDFS 中的时候,会涉及到用户权限。遇到用户权限时,也会有一个问题,Flink 实时提交的用户,是定义好的,所有的程序里用户是同一个,但是离线是多个用户,Flink 目前对于这块用户的权限做的还不够好,所以我们自己改造了一下,在 API 中添加了 withBucketUser,上边已经配置好了 nameServices,然后通过该参数来配置具体是那个用户来写入 HDFS 中,这是 API 层级的。
API 层级的好处是一个 Flink 程序可以写多个,可以指定不同的 HDFS 的不同的用户就可以。具体实现就是在 Hadoop file system 中加一个 ugi.do as,代理用户。以上是趣头条用 Flink 在实时数据同步到 Hive 做的一些工作。其中会有一些小文件的问题,针对小文件,我们通过后台程序定期的 merge,如果 CheckPoint 的时间很短,就会出现大量的小文件的问题。
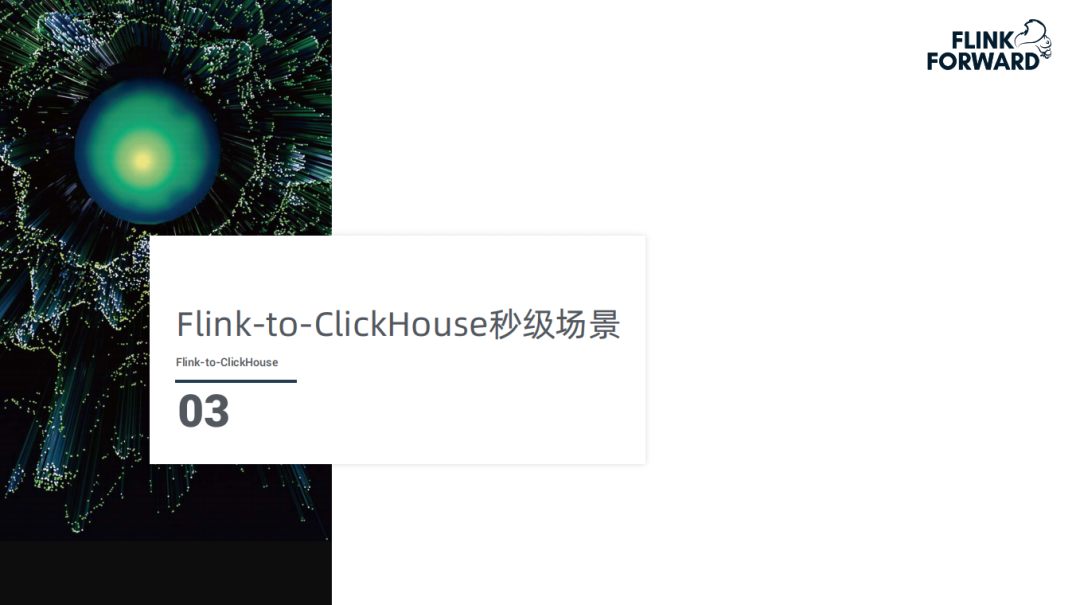
1. 秒级实现架构图
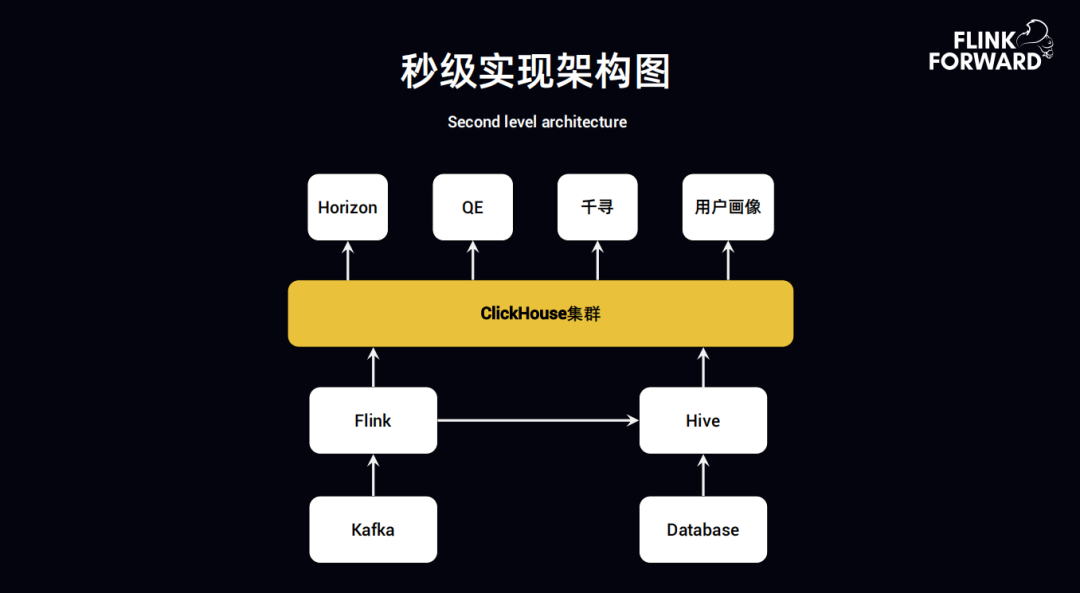
首先来解释一下趣头条使用 Flink+ClickHouse 的场景,最开始展示的很多实时指标,可能是每五分钟计算一次,也可能是每三分钟计算一次。如果每一个实时指标用一个 Flink 任务,即使是 FlinkSQL 来写,比如消费一个 Kafka Topic,计算它的日活、新增、流程等,当用户提出一个新的需求,那这个 Flink 任务是需要修改还是再启动一个 Flink 任务来消费这个 Topic,这样的话就会出现 Flink 任务在不断的修改或者不断的启动新的 Flink 新的任务。为了解决这个问题,就让 Flink 后边接一个套 ClickHouse 实现整体的 OLAP。
上图为秒级实现架构图,从 Kafka 到 Flink 到 Hive 然后再到 ClickHouse 集群,对接外部 Horizon ( 实时报表 )、QE ( 实时 adhoc 查询 )、千寻 ( 数据分析 )、用户画像 ( 实时的用户画像 )。
2. Why Flink+ClickHouse

具体来说为什么要用 Flink+ClickHouse,主要有以下几点:
- 指标实现支持 SQL 描述,以前的方案使用是 storm 的程序,通过 stormsql 实现,包括 flinksql,这些内容对于 UDF 支持相对有限,但是现在这套 Flink+ClickHouse 基本上可以把分析师提的指标通过 SQL 实现。
- 指标的上下线互不影响,这个主要是解决上边提到的关于 Flink 任务消费了 topic 以后,假如用户提出新的指标的时候,是启动新任务还是要不断修改的问题。
- 数据可回溯,方便异常排查,这个就类似上边提到的假如我的日活掉了,需要知道哪些指标的口径的逻辑掉了、哪个上报的数据掉了,如 cmd 掉了还是数据流 kafka 掉了还是用户上报的时候指标没有上报导致的日活掉了。假如单纯的 flink 的话,只是会计算出那个指标掉了,是没办法回溯的。
- 计算快,一个周期内完成所有的指标计算,现在的 horizon 曲线可能是几百上千,需要在五分钟之内或者十分钟之内,把所有分时、累时、以及维度下降的指标全部计算出来。
- 支持实时流,分部署部署,运维简单。
目前趣头条 Flink 集群有 100+ 台 32 核 128 G 3.5T SSD,日数据量 2000+ 亿,日查询量 21w+ 次,80% 查询在 1s 内完成。
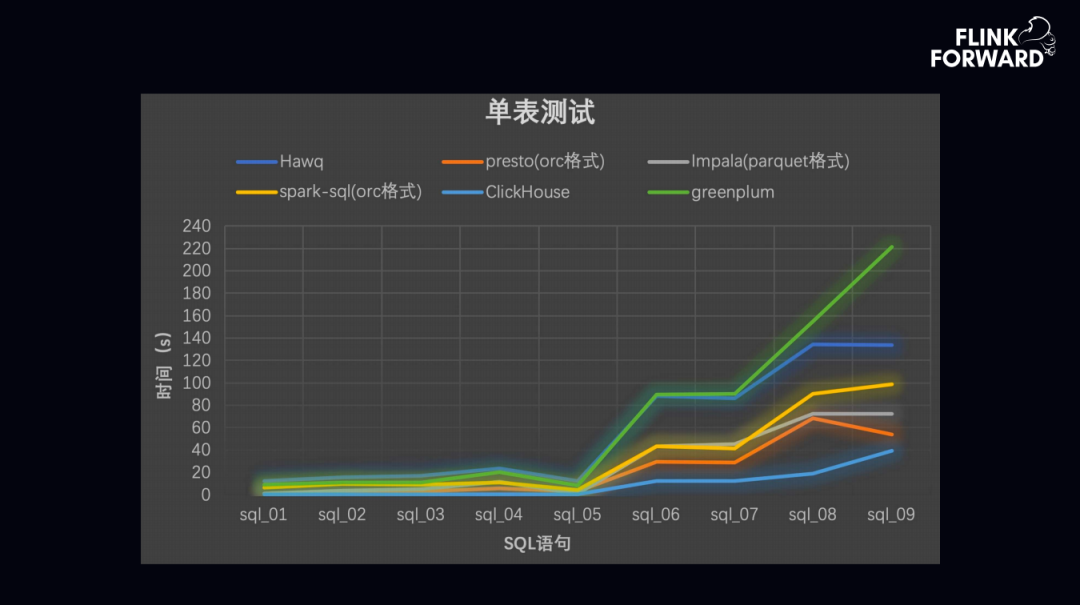
上图为单表测试结果。ClickHouse 单表测试速度快。但受制于架构,ClickHouse 的 Join 较弱。
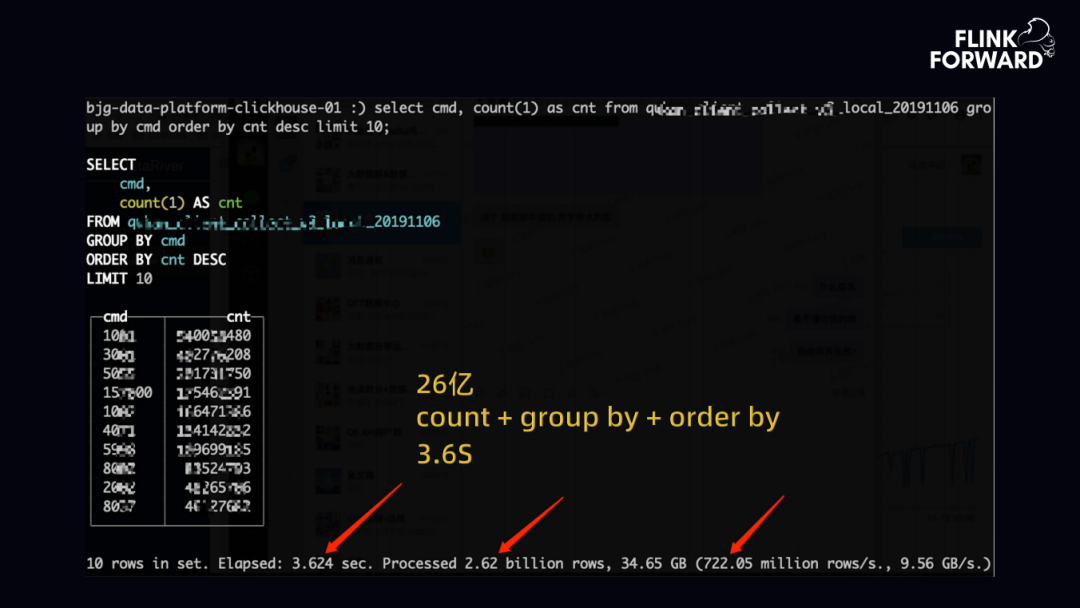
上图是处理相对较为复杂的 SQL,count+group by+order by,ClickHouse 在 3.6s 内完成 26 亿数据计算。
3. Why ClickHouse so Fast
接下来说一下为什么 ClickHouse 这么快,主要是有以下几点:
- 列式存储 +LZ4、ZSTD 数据压缩:列式存储基本是通用的。
- 计算存储本地化 + 向量化执行:计算存储本地化,ClickHouse 跟 presto 不一样,presto 数据可能存在 Hadoop 集群里边或者 HDFS 中,需要把数据拉过来,然后进行实时的计算;而 ClickHouse 是每一台计算机器需要的数据存储在本地的 ssd 盘,只要计算本地的数据就可以了,比如求 count 之类的,计算完成后把其他的节点进行合并就可以了。
- LSM merge tree+Index:LSM merge tree,他会不断的使用 batch 的形式把数据写入到 ClickHouse 之后,在后台做了一个线程把数据进行 merge,做一个 index 索引,也就是给这张数据表建立很多索引,类如常见的 DT 的时间索引、小时级的数据索引来提高查询性能或者速度。
- SIMD+LLVM 优化:SIMD 就是一个单指令多数据集,LLVM 是一个 C++ 的编译器
- SQL 语法、UDF 完善:在这块有很大的需求,比如数据分析以及维度下坠,常规的 horizon 数据报表可能就是 count、sum、以及 group by、order by 等,但是在一些维度下坠或者是数据分析领域,可能会有一个窗口期的概念,在一段窗口期内的留存,所以要用到一些更高的特性,类如时间窗口的功能。
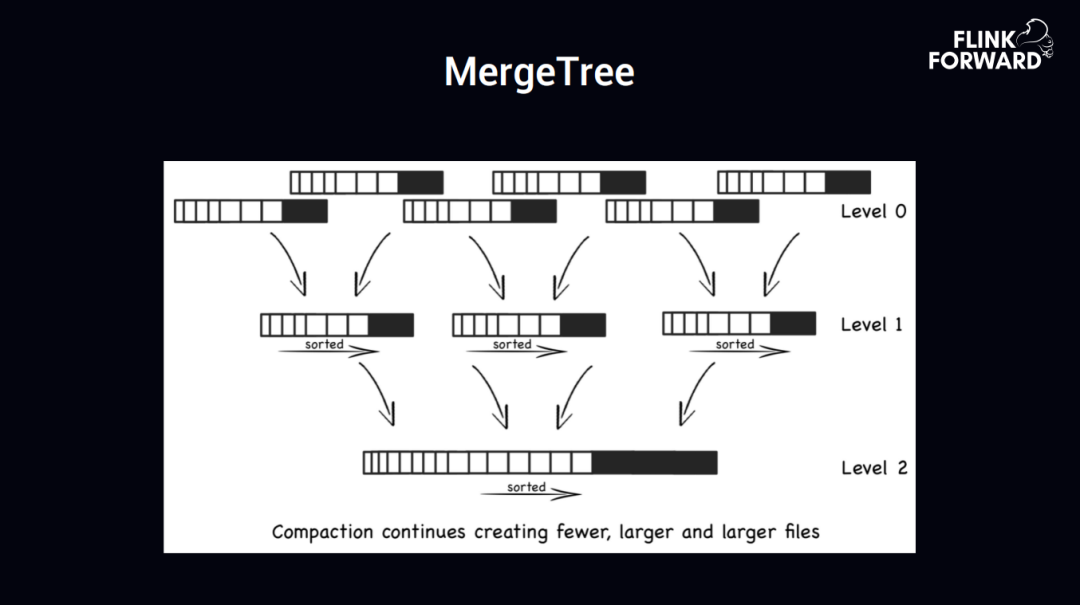
上图是 MergeTree 的运行原理图解,最上边的第一层是数据一个 batch 一个 batch 的实时写入,后台会做每一个层级的数据 merge,这块跟 HBase 差不多的实现,merge 的时候会进行数据的排序,然后做一个数据索引。

上图是 ClickHouse Connector,ClickHouse 有两个概念,local table 和 distribute table。local table 是用来写的,当然 distribute table 也可以写入,但是会出现很大的 io 问题,所以尽量不要写 distribute table。但是可以读 distribute table。5-10w 一个 batch 进行数据写入,正常的情况下,是 5 秒一个周期。
RoundRobinClickHouse DataSource 这块是趣头条自己实现的;
ClickHouse 官方 API 使用:
BalancedClickHouseDataSource 实现的。
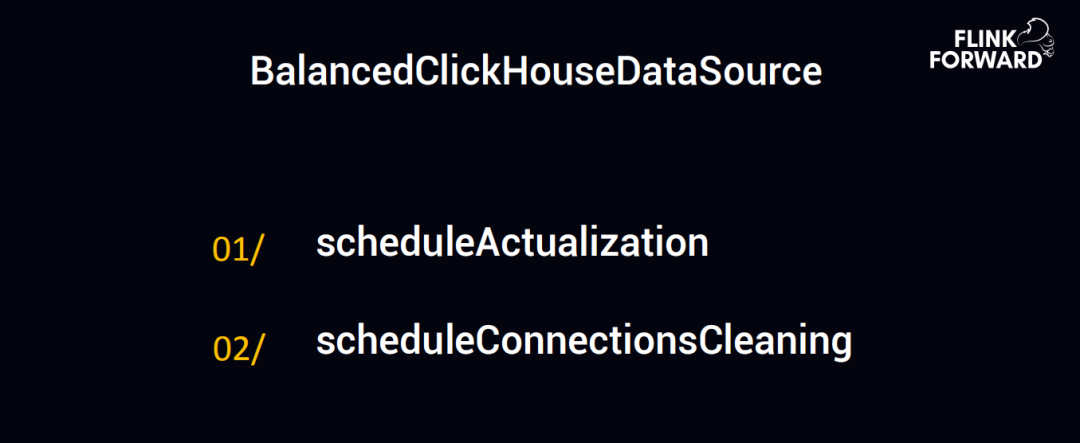
上图是 ClickHouse 官方 API 使用:
BalancedClickHouseDataSource
里边有一个问题,比如 MySQL 配置一个 ip 和端口号就可以把数据写入了,但是这块要写入 local table 的,所以必须要知道这一个集群到底有多少 local table,每一个 local table 的 ip 和端口号,假如有 100 台机器,就必须要把这 100 台机器的 ip 和端口号配置好,然后进行写入。
官方的 API 中有两个 schedule:
- 一个是 scheduleActualization
- 另一个是 scheduleConnectionsCleaning
第一个是指 100 台机器配置了 100 个 ip 或者端口号,可能会有一些机器出现 ping 不通或者服务无响应,这块是定时的做一个 Actualiza 来发现这些机器哪些无法连接,触发一个下限来把这些 ip 删除掉。
第二个 scheduleConnectionsCleaning,因为 ClickHouse 是 http 的方式,定期的会把一些没用的 http 的请求清理掉。
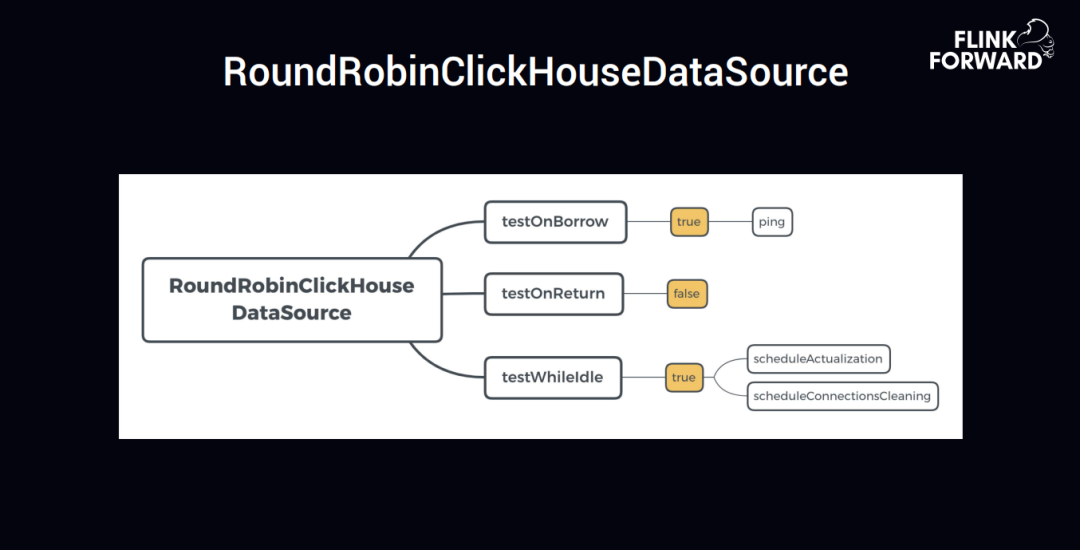
针对于官方提供的 API,趣头条对这方面做了一个加强,开发了一个 RoundRobinClickHouseDataSource,实现了三个语义,分别是 testOnBorrow、testOnReturn、testWhileldle。
第一个 testOnBorrow 取链接的时候,设置 为 true,然后去 ping 一下这个链接能不能拿到,ClickHouse 写入的时候,使用的 batch,所以尽量就是拿链接的时候要拿到成功的链接;第二个 testOnReturn 设置为 false,testWhileldle 设置为 true,把上边官方的两个 schedule 功能集成进去了。为什么要实现 RoundRobin,主要是因为假如有 100 台机器,ClickHouse 相对于 Hadoop 来说,还是需要好好维护一下,如果是 insert 的话,后台是不断 merge 的过程,insert 速度大于 merge 速度时候,会导致 merge 速度永远跟不上,所以就写完这台机器接下来写别的机器,以及 5 秒一个间隔的写,使 merge 的速度尽量跟上 insert 的速度,这块是整个部分最需要注意的地方。
4. Backfill
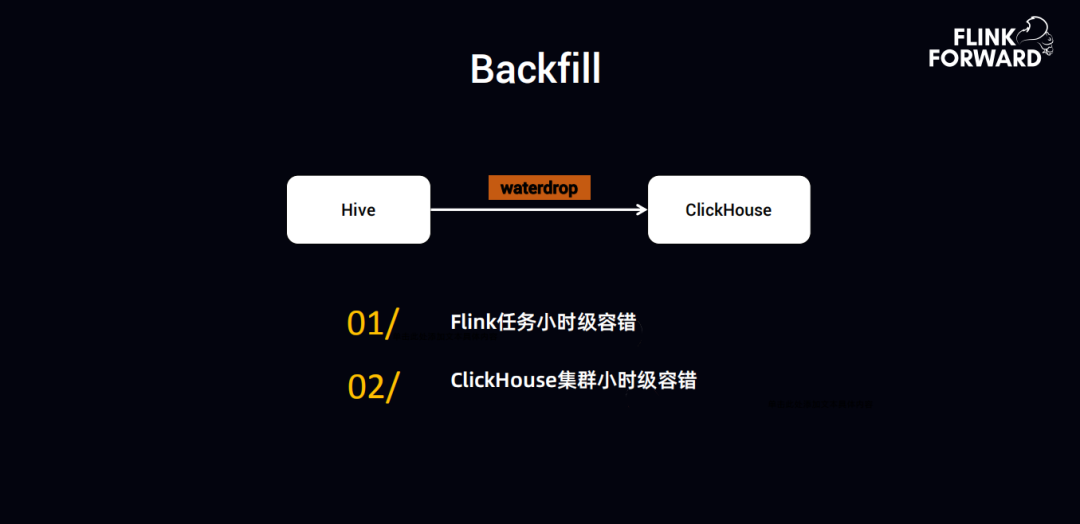
趣头条针对集群容错做了一些优化,主要包括两点:
- 第一点是 Flink 任务小时级容错
- 第二点是 ClickHouse 集群小时级容错
Flink 导入数据到 ClickHouse,来实现数据的查询、报�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%B6%A3%E5%A4%B4%E6%9D%A1%E5%9F%BA%E4%BA%8E%E7%9A%84%E5%AE%9E%E6%97%B6%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B9%B3%E5%8F%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


