贝壳找房面向技术的贝壳一站式大数据开发平台实践
仰宗强@贝壳找房
本文根据贝壳找房资深工程师仰宗强老师在2020年"面向AI技术的工程架构实践"大会上的演讲速记整理而成。
1 开场
大家下午好,很荣幸来到这跟大家一起分享贝壳一站式大数据开发平台的落地实践。今天的分享主要分为以下四个部分:
- 贝壳的数据业务背景。
- 数据开发平台探索历程。
- 数据开发平台的整体情况介绍
- 未来规划与展望
2 贝壳的数据业务背景
在公司最早的时候,由于体量较小,基本上都是业务自行承担数据的获取需求的,随着公司规模的增长,对大数据的离线应用开发的需求越来越多。那么为了满足各类数据获取/计算等需求,我们在14年成立了大数据部门,专门针对大数据工作进行探索。首先我们针对贝壳数据需求进行了分析,基本上都是围绕物的数据、人的数据、行为数据这三大块来进行分析研究。

- 物:我们早在08年就开始进行筹建楼盘字典,用房间门牌号、标准户型图、配套设施信息等多维信息定义一套房屋,到目前为止,已经收录了2亿以上的房屋信息
- 行为:线上的浏览日志,下线的看房行程等行为信息
- 人:主要是经纪人、还有客户(买家、业主)以及品牌主的信息
然后我们针对大数据技术在业内进行了调研,一般都是遵循这三个逻辑:降本、增效、规范。
3 数据开发平台探索历程
接下来为大家介绍贝壳数据开发平台探索历程。在大数据部门成立伊始,我们进行hadoop搭建,使用Kafka+Sqoop+HDFS+Hive架构;随着业务需求量以及需求复杂度的迅速增加,我们开始有了平台化的需求,于是开始探索平台化架构;2019年,我们已经开始进行数据资产管理。
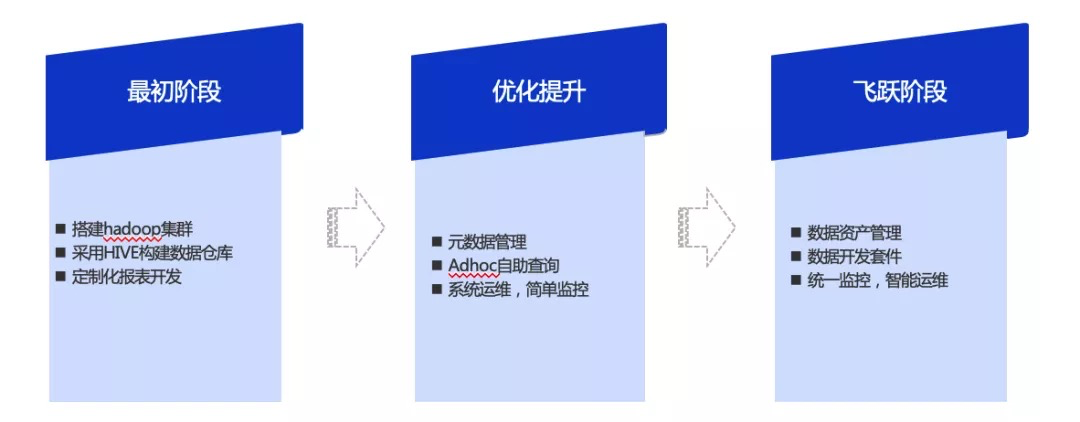
3.1 最初阶段
贝壳最早的大数据开发平台,非常的简单粗暴。经典的Kafka+Sqoop+HDFS+Hive,任务调度用Ooize,处理完之后的数据放在MySQL中,报表平台直接读取MySQL的数据做展示
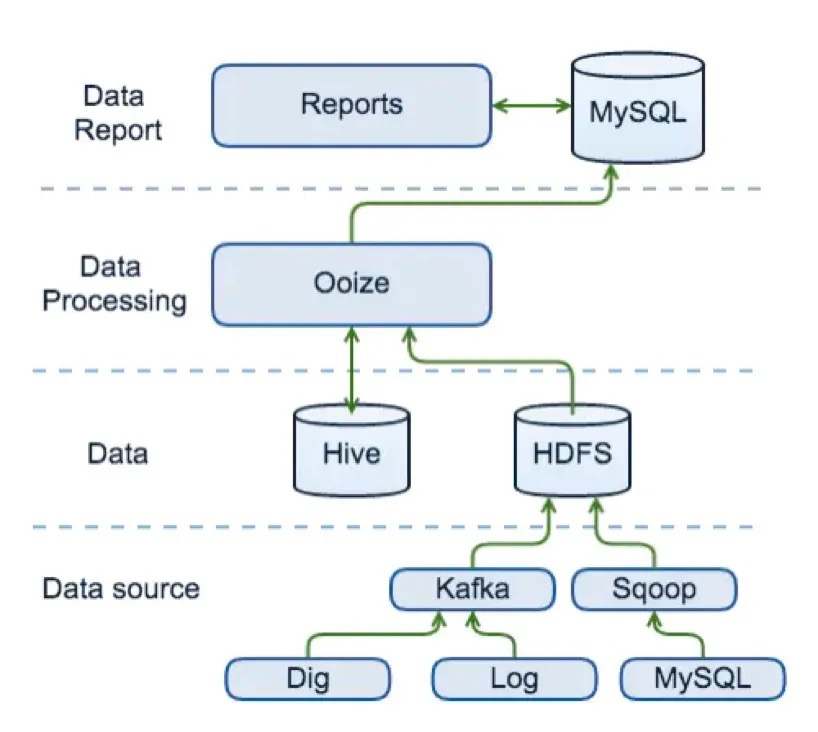
- 使用了开源组件,采用hadoop进行搭建集群,集成工具使用sqoop,数仓建设使用hive,任务调度框架使用的是ooize,然后直接同步到mysql进行报表展示
- 数仓使用 接入层、数仓层、应用层分层模型进行设计,大部分坑都已经被业界趟过了,可以避免踩一些不必要的坑
在早期这么做有一些好处:
- 开源组件,方便扩展和运维
- 业界成熟的数据仓库方案,分层模型设计
- 有利于技术人员培养
但是随着业务需求的不断增加,出现了各种各样的问题:
- 当决策层使用报表时发现总是慢了一拍,总会有新的需求出来。原因很简单:其实互联网公司的业务并不像传统行业(如银行、保险等)的业务那么稳定,因为互联网公司的发展比较快,业务更新迭代的也很快。
- 业务分析总有各种临时的需求,原因和1类似。
- 数据仓库工程师累成狗。因为所有的数据需求都需要数据仓库case by case 处理
- 集群作业运维困难,每个运行日志都需要去对应集群机器查找,一般一个小问题,可能都需要好几个小时去定位修复。
- 数据安全问题,对数据的申请需要进行集中的审批管理,对数据的使用需要进行持续的追踪备案,防止数据泄露。
3.2 平台化阶段
为了解决最初阶段出现的哪些问题,我们提出了平台化的方案,整体架构如下:
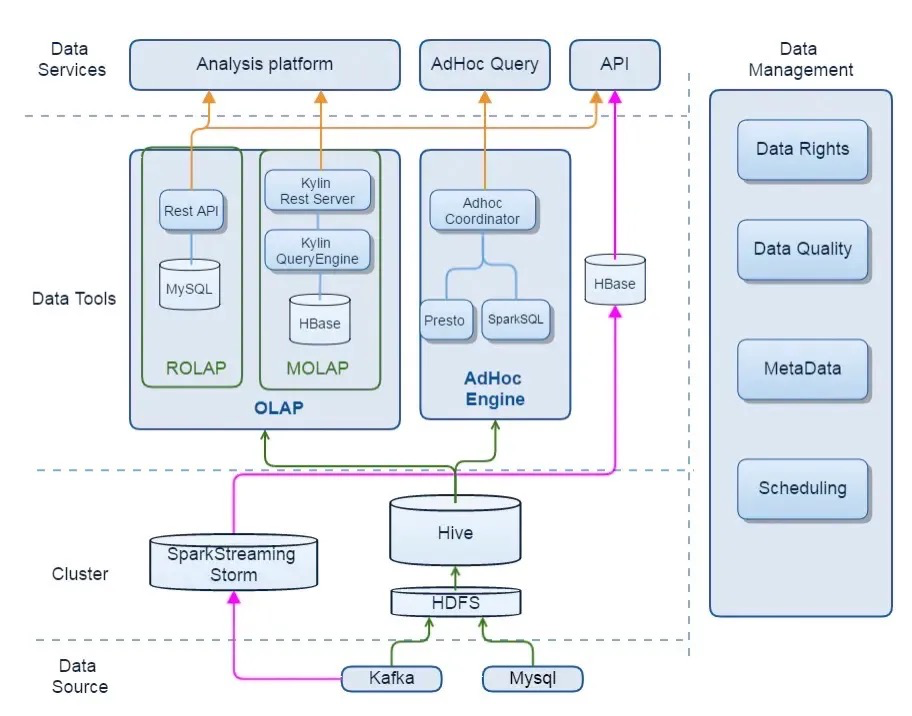
这个阶段我们干了几件事:
元数据管理系统上线
- 所有表的创建修改都经过元数据系统,可以实时清晰掌握仓库里的数据情况。
- 数据的接入和流出都通过元数据系统集中管控,所有的日志接入、mysql接入通过元数据来配置,数据申请也是走的元数据,方便集中管理运维。
- 用户可以通过平台进行搜索查询。
调度系统重构,之前我们采用oozie+python+shell解决,任务量有5000多个,维护困难,且遇到数据修复问题,难以迅速定位。为了解决这些问题,我们参考了oozie、airflow等开源软件,自主研发了新的任务调度系统,上线之后取得了非常好的效果:
- 任务配置简单,在图形上简单的拖曳即可操作。
- 提供常用的ETL组件,零编码。举个例子,以前发送数据邮件,需要自己写脚本,目前在我们界面只需配置收件人和数据表即可。
- 一键修复追溯,将排查问题修复数据的时间由一人天缩减到10分钟。Adhoc即席查询,之前我们使用的hue,速度比较慢。通过调研市面上的各种快速查询工具,我们采用了Presto和Spark SQL双引擎,搭配数据地图,可以满足大部分临时需求场景。API上线,主要是定制化开发restful 接口,直接对接业务。
搭建产品化的数据服务平台,数据仓库能量转移到数据建设方面,包括数仓建设和集市建设。数据工程主要职责不再是运维集群,而是搭建数据服务平台和构建业务数据产品。这样做的好处是:
- 解决了数据仓库的瓶颈问题。
- 让BI和业务同学自行进行数据自助提取&分析,效率更高。
- 业务数据产品可以直接使用数据服务平台提高效率,缩减公司成本。
但是这么做有缺点:
- 数仓表/任务量剧增,造成集群资源相当紧张;
- 集中的几个人 -> 分散到业务,质量无法把控。
3.3 数据资产化阶段
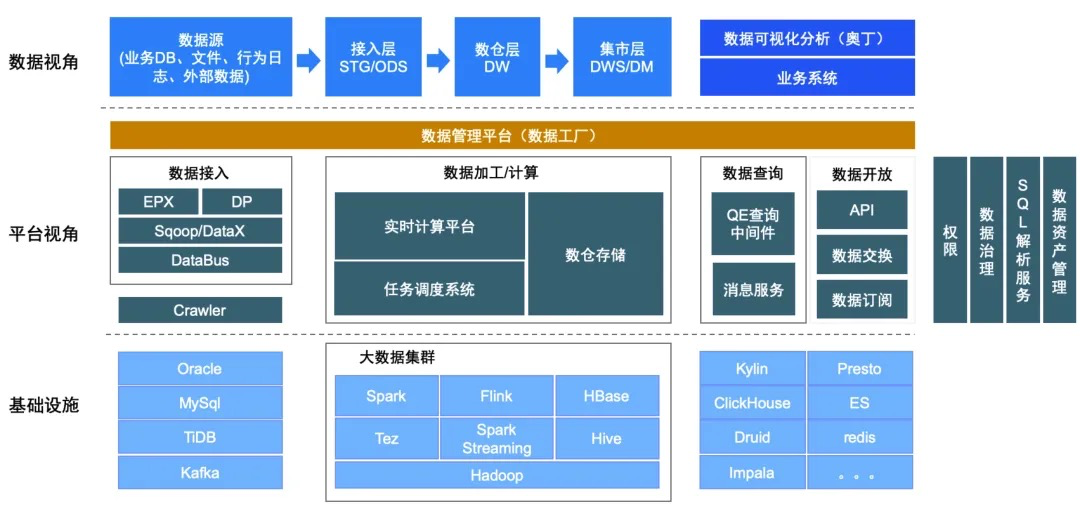
- 大量的增加了可视化编程工具,简化开发流程;
- 增加了大量的管理工具和自动化运维工具,进行了数据标准化和质量管控;
- 对外开放了大量的数据,实现了数据资产盘活。
4 数据开发平台的整体情况介绍
4.1 数据管理
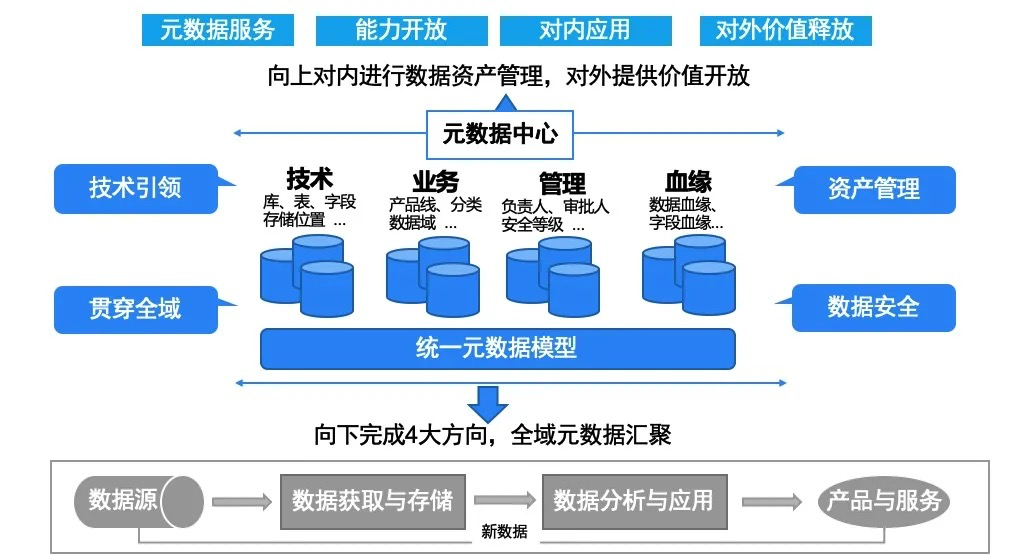
特点:
- 统一元数据模型,管理包括结构化数据、半结构数据、非结构化数据的相关元数据。
- 贯穿全域,元数据打通数据源、数据仓库、数据应用,记录数据从产生到消费的完整链路。
向上对内数据资产管理、对外提供价值释放。这块,我们通过数据地图
- 用户可以快速注册HIVE表:包括库、表、字段等这些技术信息;分类、标签等业务信息;还有负责人、安全等级、审批人等管理信息
- 用户可以快速查找指定数据,并能够自助的理解信息。
- 还可以通过平台,能够看到贝壳的数据资产,我们引入工作空间的概念,针对资产进行合理资源划分
4.2 数据集成
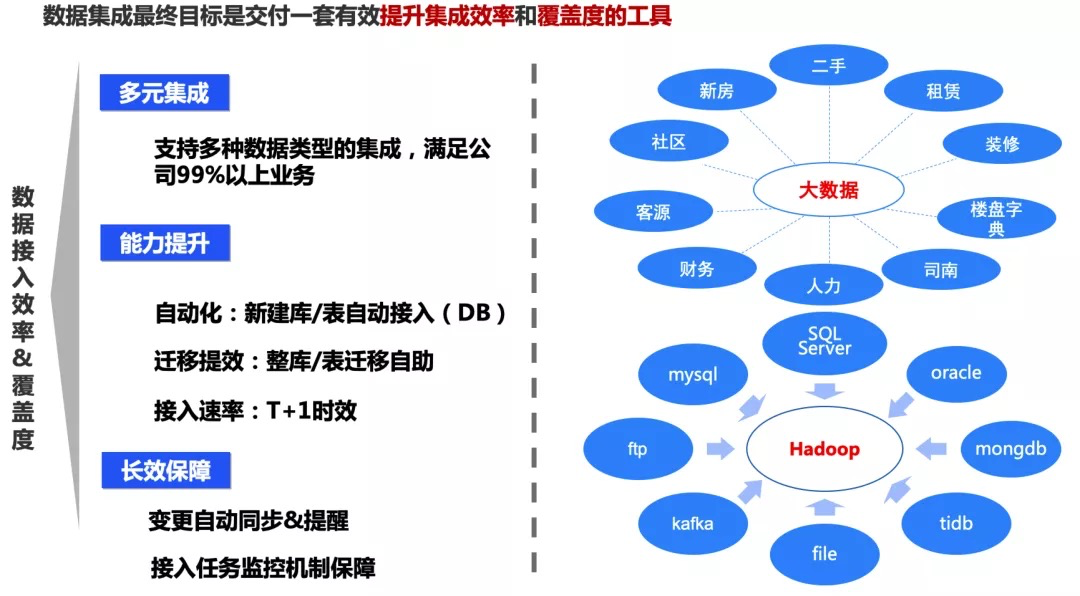
早期的数据集成都是特别粗暴的Sqoop和kafka任务,那玩意谁用谁知道,维护简直是要了命了。现在改用DataX、DataBus等工具,效率杠杠的。
- 自动化接入,针对集中管理的MYSQL数据库,新库/新表申请创建时,可以消息同步,并自动接入;
- 针对表结构变更时,如果不会对后续任务产生以影响,例如增加字段,则继续进行,如果是字段发生跨类型变化,就会进行通知报警。
针对业务开发出现数据库重大结构变更时,与DBA合作实现了审批和通知的线上化,提前告知结构较大变动的情况。
4.3 作业调度
当数据集成到大数据之后,数据开发人员怎么去数仓&集市建设呢?我们提供了一套从建表、逻辑研发到测试上线整个流程。一个数据开发人员在逻辑处理无误的情况下,一般
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%B4%9D%E5%A3%B3%E6%89%BE%E6%88%BF%E9%9D%A2%E5%90%91%E6%8A%80%E6%9C%AF%E7%9A%84%E8%B4%9D%E5%A3%B3%E4%B8%80%E7%AB%99%E5%BC%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B9%B3%E5%8F%B0%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


