贝壳找房贝壳搜索平台实时流总体架构设计
- 2018-12-01
- 原创:孙要飞
背景:2017 年底到 2018 年初,公司战略调整,业务量及业务复杂度预期会有较大增长;面对新的挑战,搜索团队对整个搜索平台进行了重写,针对旧系统的一些问题,主要从可配置,异步化,并发,可扩展,全链路追踪,业务隔离等方面进行了设计。
1. 总体架构
如下图所示,新的实时流重度依赖 kafka,实现了平台各个处理阶段的异步化。
另外,整个服务的构建是基于 SpringCloud,借助 Spring config 实现了业务接入的可配置化。
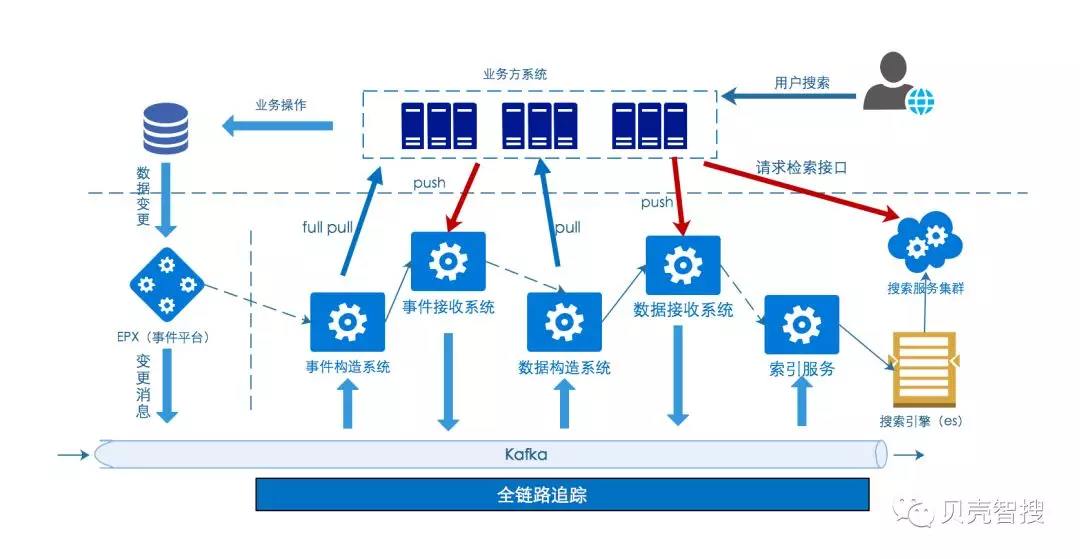
1.1 事件平台
事件平台作为一个独立的服务存在,对阿里开源的 canal 进行了定制化开发,实现对数据库变更的监听,并把变更格式化后写入 kafka;格式化后的事件示例如下:
1. `{`
2. `"changed":{`
3. `"field1":{`
4. `"after":"aaa",`
5. `"before":"a"`
6. `},`
7. `"field2":{`
8. `"after":"bb",`
9. `"before":"xx"`
10. `}`
11. `},`
12. `"content":{`
13. `"field1":"aa",`
14. `"field2":"bb",`
15. `"field3":"cc"`
16. `},`
17. `"database":"test_db",`
18. `"table":"test_table",`
19. `"timestamp":1521021260000,`
20. `"traceId":6976412492031196000,`
21. `"type":"UPDATE"`
22. `}`
1.2 事件构造/接收系统
事件构造/接收系统作为一个整体,消费事件平台的格式化数据,从中过滤出自己感兴趣的部分(比如哪个库,哪个表,哪些字段变更),并从事件中取出对应的业务唯一主键,重新写入下游的 kafka 队列中。
1.3 数据构造/接收系统
同事件构造/接收系统类似,数据构造/接收系统也是作为一个整体,作为前者的下游,拿上游 kafka 队列中的业务唯一主键,回调相应业务方,拿到业务方返回的索引数据,写入到下游 kafka。索引数据格式如下:
1. `{`
2. `"data":{`
3. `"fieldx":"123",`
4. `"fieldy":"yy",`
5. `"fieldz":"zz"`
6. `},`
7. `"id":"123",`
8. `"timestamp":1514377005000,`
9. `"action":"UPDATE",`
10. `"version":"v1.0",`
11. `"traceId": 6976412492031196000`
12. `}`
字段及释义
字段释义id业务相关唯一标识符,如房源 id,一般情况下对应 data 中某字段,不强制限制timestamp事件产生的时间traceId全链路追踪使用action事件类型,可用的类型为更新/删除/部分更新version数据版本,扩展使用data对应 es 索引中的数据
1.4 索引服务
作为数据构造/接收系统的下游服务,索引服务将构建好的数据直接写入到 es 中。除此之外,索引服务还承担了索引的管理工作,比如:索引初始化,索引结构调整,索引别名切换,索引数据恢复等等
- 可以看到,借助 kafka,整个架构内各个上下游服务之间实现了解耦,并且以上服务可以集群的方式自由部署及扩展
1.5 PULL + PUSH
为了便于灵活的接入,平台设计之初就确定了两种模式:PULL 和 PUSH。主要有以下三种场景:
- 无实时更新:可以直接采用 PUSH 的方式,把拼好的数据通过数据接收系统直接写入。
- 实时更新 +“1 对 1”:如房源,一个房源价格的变更,只会影响当前这个房源;这种场景,可以由平台来负责监听变更,最后 PULL 业务接口来实现数据的同步。
- 实时更新 +“1 对多”:还拿房源举例子,房源对应小区名变更,会影响到小区内所有房源;这种场景,业务方可以自己监听变更,然后把变更 PUSH 给数据接收系统。
另外,对应 2),业务方可以提供全量接口,事件构造系统拉取所有数据,然后包装成全量事件(实时增量为增量事件),对整个索引数据进行更新(索引概念后面介绍)
2. 问题及方案
2.1 并发 vs 数据一致性
为了提高数据同步的速度(主要针对全量更新或者刷数据的情况),整个实时流架构下各个服务都支持并发处理,这个功能由 kafka topic 的多 partition 来支持(partition 概念可以参考 http://kafka.apache.org/documentation/#intro_topics)。
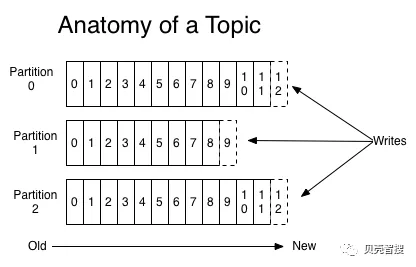
如上图所示,topic 配置有 0,1,2 三个 partition,对于同一个业务单元(如房源 123456)的多次变更,默认情况下会被写入到任何一个 partition,这时,由于消费进度不一致,后变更可能会被先处理,这样就有数据不一致的风险。问题就来了,我们如何能保证同一个业务单元的变更能写入到同一个 partiton 呢?
Kafka 生产者 client 文档中的描述如下:
If a valid partition number is specified that partition will be used when sending the record. If no partition is specified but a key is present a partition will be chosen using a hash of the key. If neither key nor partition is present a partition will be assigned in a round-robin fashion.
由于 partition 数本身是不可控的,所以直接指定 partition 写入是不可取的,而轮询的方式(round-robin)明显是有问题的,最终我们采用指定 key 的方式;在生产者写入数据到 kafka 时,以业务单元的唯一标识(如房源 Id)做为 key;这样我们就可以保证对应同一个业务单元,不管有多少次变更,相关信息都会写入到同一个 partition 中(也就是同一个队列中),从而在并发的同时保证数据的一致性
2.2 异步化 vs 全链路追踪
考虑到整个架构是基于 SpringCloud,最初选用的了 SpringCloud 生态下的 sleuth(对 zipkin 进行了封装)以实现全链路追踪,方便排查问题,分析处理过程中耗时情况。zipkin 官网效果图如下。
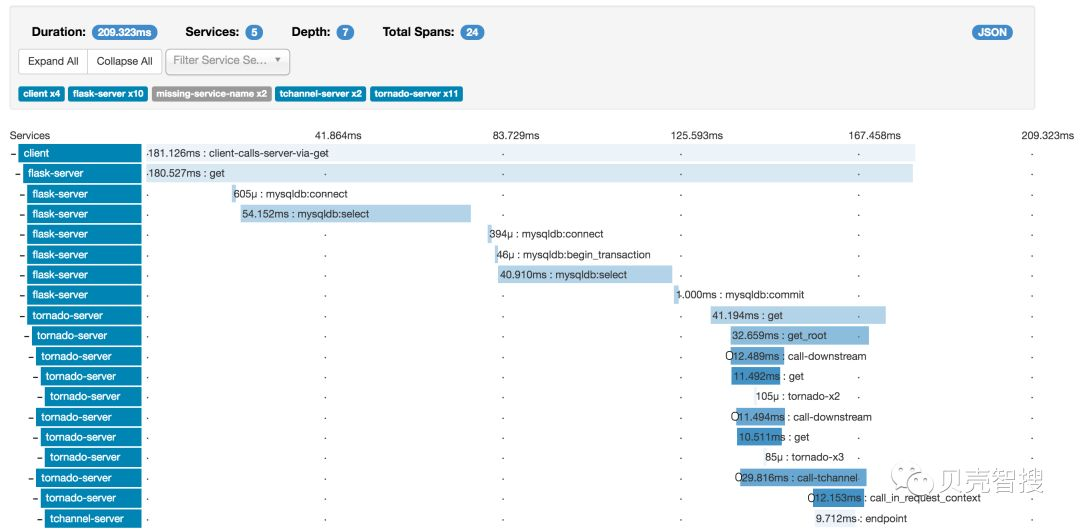
由上图可以很直观看到,所示的链路信息是同步请求的,也就是在结果返回前请求端会一直阻塞。由前文描述,我们可以知道,我们采用使用 kafka 使系统各个部署实现了异步化,这样就给全链路追踪带来的问题。虽然 zipkin 本身已经对 kafka 的传输有了支持(参考:Existing instrumentations),但是由于 kafka 消息的读/写都是批量的,并不能支持单条数据粒度的链路追踪(参考:Brave Kafka instrumentation)
通过对 sleuth Java 客户端的源码进行分析发现,全链路追踪的数据是由 traceId 来串起来的,默认情况下,traceId 是自动生成的。基于源码的分析,我们对 zipkin 客户端数据收集模块进行了重写,由业务代码来控制 traceId 的生成,并且,把 traceId 做为业务数据的一部分,在整个处理流程中一直传下去;显式控制追踪数据的上传,从而可灵活指定埋点,以及具体的埋点信息。
整体效果可见下图。
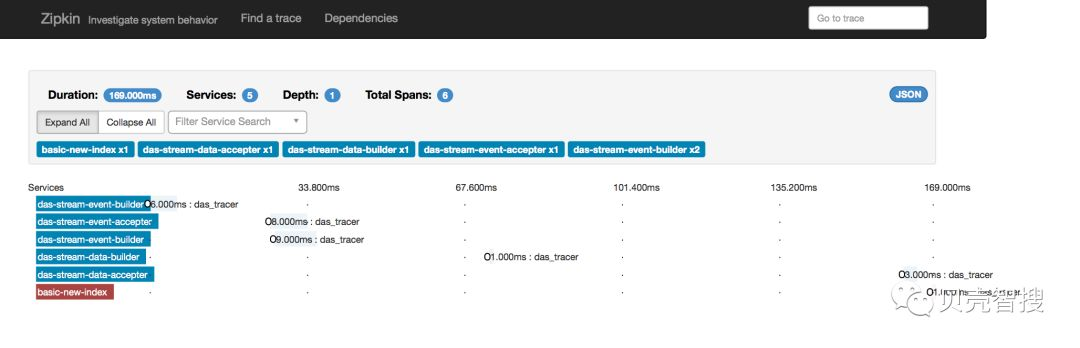
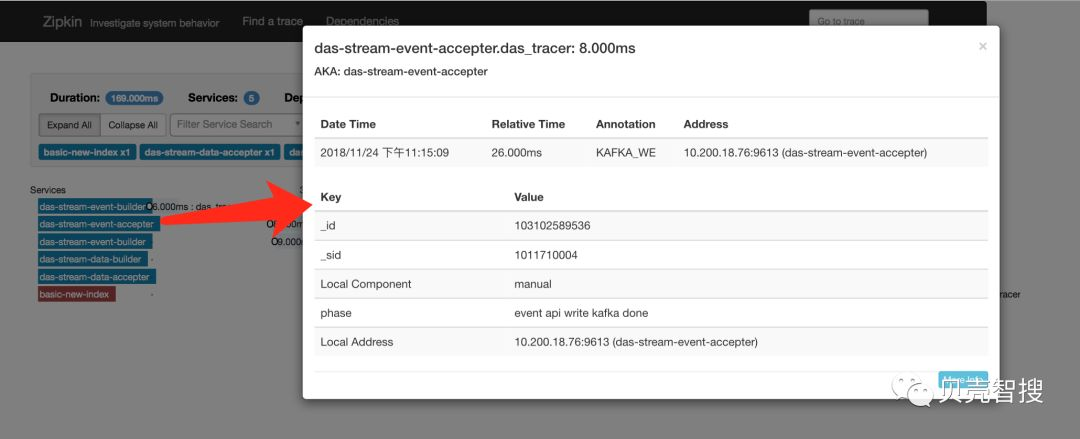
自定义埋点信息效果见下图。其中_sid 和_id 对应于具体的业务方以及具体的数据,可以做为 zipkin 页面上的检索条件。
2.3 可扩展 vs 业务隔离
原则上,在以上描述的架构中,我们是可以接入的业务数目是没有限制的,各个结点都是可以根据需求来扩展的。但是,在具体的使用中,我们还是遇到了一些问题,某个业务出现异常,导致整个系统不可用的情况。
2.3.1 硬件资源共享的风险
在我们的一次事故中,事件构造系统出现过硬件资源共享引发的问题。由 1.2 可知,事件构造系统是主要功能是消费事件平台的 kafka 消息,从中提取感兴趣的数据,为了排查问题以及对消费延时感知,我们会把消费到的数据打印日志持久化到磁盘中,并且在延时(由消息生成时间对比系统当前时间)时发出报警。某天,由于某业务异常操作(后续排查到是大批量刷数据),导致单位时间内日志打印过多,磁盘空间占满,并且报警队列过大,内存溢出,最终导致整个服务 block,影响到了所有业务。
2.3.2 线程共享的风险
在事件/数据接收系统中,kafka 消息写入时,是共用同一个 producer 的,producer 本身是线程安全,官方文档也是推荐多线程共享使用的。但是,在我们的实际使用中,发现了这样的问题:新上线业务,由于 kafka topic 漏申请,导致整个服务 block。后续分析具体原因发现,同一个 producer,其中有个缓冲区是共享的,某个 topic 不存在,对应的数据就会在缓冲区中堆积,直到堆积满,从而影响到我其它业务的正常使用。
以上问题,我们通过系统升级和流程规范都已经解决,但是其中也暴露的问题值得我们深思。作为一个平台提供方,所接入业务的重要程度、更新的量级、对数据实时性的要求都是不一样的。如果硬件资源(如网络 IO、内存、磁盘都共享)和线程资源共享,那么业务之间是存在相互影响的,并且这个风险基本上是不可控的。
由此,在我们已经规划(也是在实施中)的服务部署方案中,机房、业务类型、重要程度、业务量级都是考虑因素,我们以此对服务进行分组部署,避免相互干扰
2.4 全量 + 增量 vs 数据一致性
2.4.1 基本概念和问题
概念定义
- 全量:对应某个业务在某个时间点的所有有效数据
- 增量:某个业务实时更新的数据
- 索引:对应 es 中的一个索引,具体概念类似数据库的一张表
- 别名:对应 es 中的别名,可以指向一个索引,在别名和索引一对一的情况下,访问别名等同访问索引;es 本身支持别名和索引多对多;平台的设计是通过别名来读取 es 数据的;
- 消费者分组:kafka 中的 consumer group 概念,对于同一个 topic,多个消费者分组可以消费完整的数据,彼此相互不影响
- 数据一致性:数据的最终一致性,对于某个业务方,在可以容忍的时间内,搜索索引中的数据量与业务方的数据量一致,所有数据的值与业务方数据保持一致。
在存在实时增量的场景下,一般都会存在以下问题:
- 1)全量和增量同时进行时,如何保证数据的先后顺序?
- 2)全量数据如何不影响正常增量的实时性?
- 3)全量结束后如何删除旧数据?
- 4)全量/增量如何保证数据不丢失?
以上问题,在存在实时增量的场景都是不可回避的话题,贝壳搜索平台在迭代过程解决这几个问题主要采用了两种方式:1)单索引 + 多消费者分组;2)多索引别名关联方案
2.4.2 全量方式
2.4.1 方案 1:单索引 + 多消费者分组
该方案下,无全量时,只存在一个 es 索引,做全量时会新建一个索引;在做全量过程,旧的索引只写入增量,新的索引会写入增量和全量数据;全量结束时,别名指向新的索引。示意图如下,需要注意的是,每次全量索引 B 不是同一个索引。
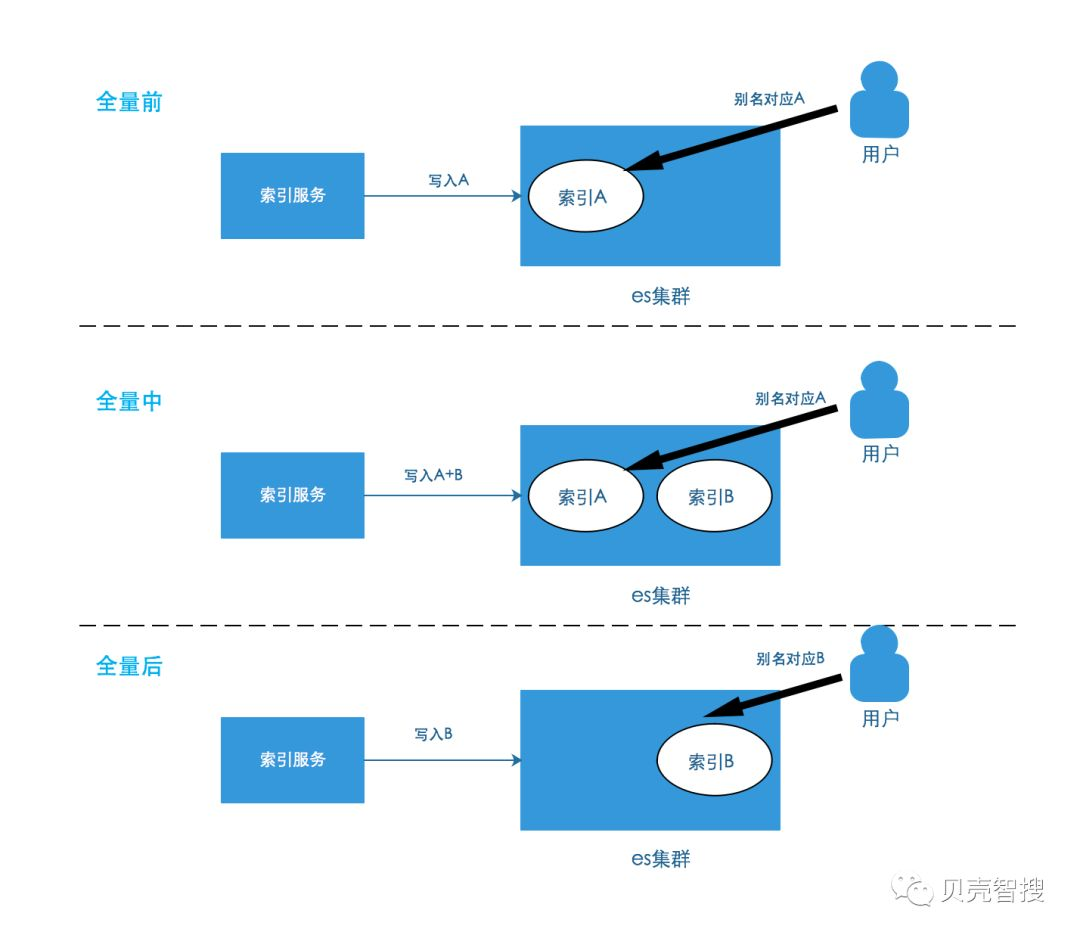
- 数据先后顺序两种方案解决方式是一致的,可以参考 2.1 的描述。以同一个房源为例,变更事件本身是不区分顺序的,最终写到索引的数据都是来自于数据构造系统。对于同一个索引,同一个房源变更都只会被同
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%B4%9D%E5%A3%B3%E6%89%BE%E6%88%BF%E8%B4%9D%E5%A3%B3%E6%90%9C%E7%B4%A2%E5%B9%B3%E5%8F%B0%E5%AE%9E%E6%97%B6%E6%B5%81%E6%80%BB%E4%BD%93%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


