贝壳找房深度语义匹配模型原理篇二交互篇
上期我们介绍了六种表示型的深度语义匹配模型,本期将为大家带来六种交互型的深度语义匹配模型。
一、前篇回顾
上期我们介绍了六种表示型的深度语义匹配模型,表示型的模型更侧重于对表示层的构建,其特点是对将要匹配的两个句子分别进行编码与特征提取,最后进行相似度交互计算。缺点是分别从两个对象单独提取特征,很难捕获匹配中的结构信息。因此可以更早的将两个对象进行交互,获取交互产生的特征,交互型的深度语义匹配模型完美的应用到了交互特征。
二、交互型深度语义匹配模型
交互型模型摒弃后匹配的思路,假设全局的匹配度依赖于局部的匹配度,在输入层就进行词语间的先匹配,并将匹配的结果作为灰度图进行后续的建模,其基本模型结构如下图所示:
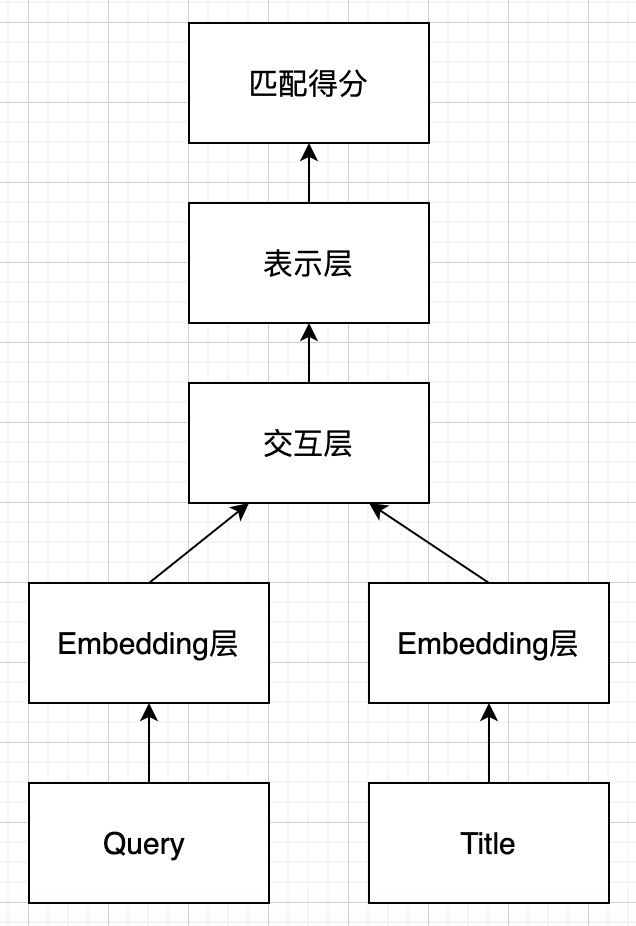
交互型匹配模型的特点是:
- 捕捉直接的匹配信号,将匹配信号作为特征建模。
- 交互层:两文本词与词构成交互矩阵,交互运算类似于 attention,加性乘性都可以。
- 表示层:负责对交互矩阵进行抽象表征,CNN、RNN均可。
交互型匹配模型的代表算法有: ARC-II、MatchPyramid、DeepMatch、ESIM、ABCNN、BIMPM等。
2.1 ARC-II
ARC-I,ARC-II 2014年由华为诺亚方舟实验室提出, ARC-I 是表示型匹配模型,上篇有讲解,ARC-II是交互型匹配模型,中文名是 卷积网络深度匹配模型,通过中文名称就可以get到两个点:卷积、深度,所以可以理解为多次应用卷积计算来建模,原文传送门 https://papers.nips.cc/paper/5550-convolutional-neural-network-architectures-for-matching-natural-language-sentences.pdf.
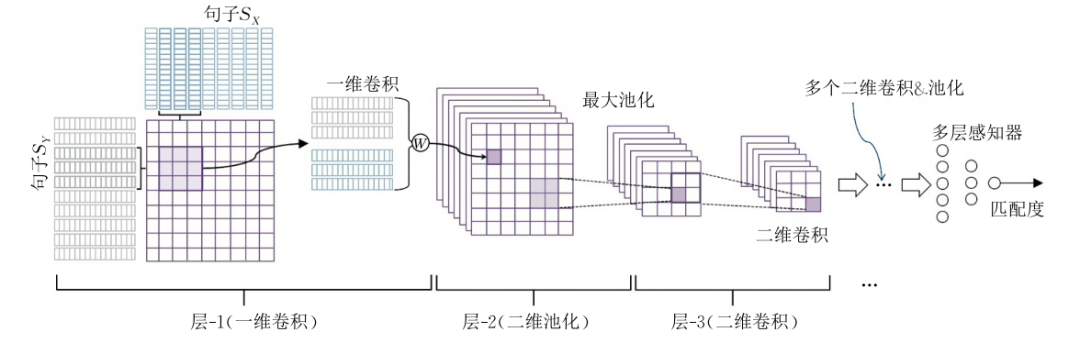
句子中每个词表示为词向量后,每个句子构成一个矩阵,用滑动窗口来选择词向量组作为基本单元进行卷积操作。假设有两个句子x和y,首先从sentence x中选取一个向量a,再从sentence y中将每一个向量和a进行卷积操作,通过这种操作,将两个句子中的向量进行两两组合,构成2D矩阵,该矩阵作为两个句子交互作用的一个初步表示。随后的卷积以这个2D矩阵为基础进行“卷积+池化”的操作若干次,最后得到一个描述两个句子整体关联的向量,最终由一个MLP来综合这个向量的每个维度得到匹配值。
ARC-II模型考虑了句子中词的顺序和交互信息,从而可以对两个句子的匹配关系进行相对完整的描述;然而还缺乏对于细微匹配关系的捕捉,在精确匹配上面还存在缺陷。
2.2 PairCNN
这篇文章2015年出自University of Trento,也是用CNN模型对文本进行语义表示。原文传送门: https://dl.acm.org/doi/pdf/10.1145/2766462.2767738.
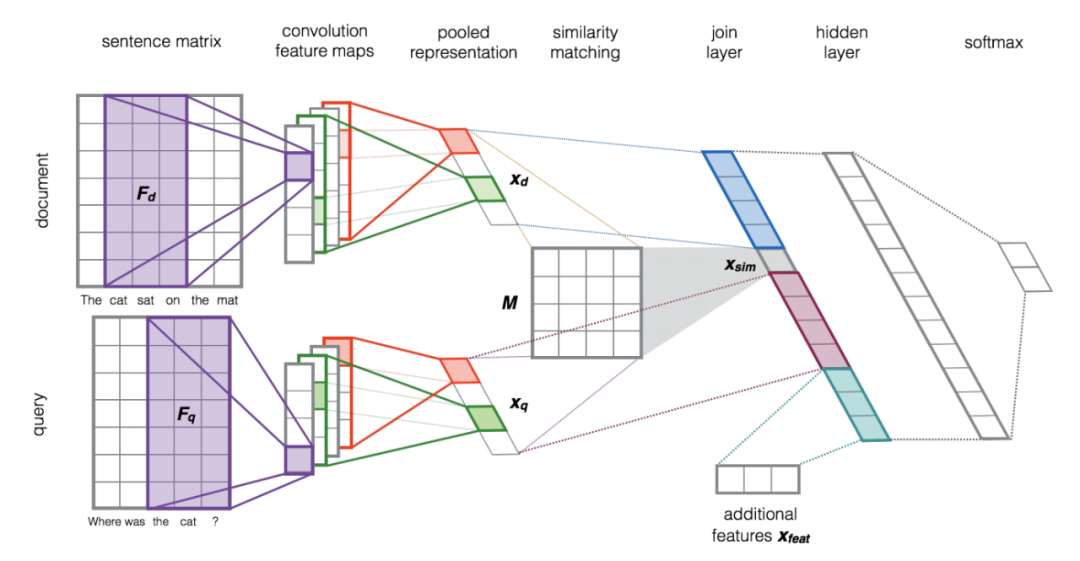
模型先分别对 query 和 document 做卷积和max池化,得到文本的语义向量,接着通过 M 矩阵变换得到语义向量的相似度,然后把 query 语义向量、query&document 的语义相似度、document 语义向量、外部特征拼接成n维向量,外部特征的加入是作者考虑到可能无法在词表中找到某些专有名词,从而会造成信息缺失,因此文中使用word overlap(单词重叠)和IDF word overlap(IDF加权后的单词重叠)作为外部特征,以加强query和document之间的关联关系。将拼接好的n维向量输入一个非线性变换隐层,最终用 softmax做概率归一化。用softmax 的输出作为监督信号,采用 cross-entropy 作为损失函数进行模型训练。
本文的改进点包括:1. 将 query 和 document 的语义向量及其相似度拼接成新的特征向量输入MLP;2.可以在模型的输入向量中方便地融入外部特征。
2.3 MatchPyramid
虽然ARC-II和PairCNN更早地让两段文本进行了交互,但是这个交互的意义其实并不明确,层次化的过程也比较模糊。MatchPyramid重新定义了两段文本交互的方式—- 匹配矩阵,该模型2016年由中科院提出,原文传送门 https://arxiv.org/abs/1602.06359。作者基于此模型,在2017.3-2017.6 Kaggle的Quora Question Pairs 比赛上,取得了全球第四的好成绩。
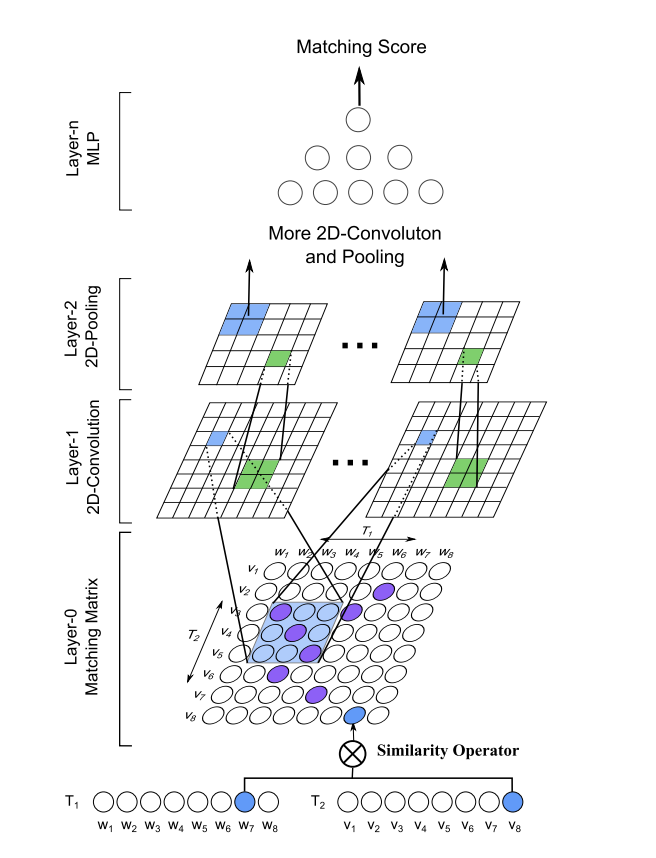
MatchPyramid模型的核心思想是层次化的构建匹配过程,借鉴了CNN在处理图像时的原理,因为CNN就是在提取像素、区域之间的相关性,进而提取图像的特征。我们看看文中举的例子:Query1:down the ages dumplings and noodles were popular in China. Query2: down the ages noodles and dumplings were famous Chinese food. 作者将每个单词看成一个像素,那么对于两个单词数为M,N的句子,构建相似度矩阵的大小就是M*N。
2.3.1匹配矩阵的构造
文中提出了三种构造匹配矩阵的方法:
- Indicator: 0-1类型,每个序列对应的词相同为1,不同为0。
- Cosine: cosine距离,使用预训练的Glove将词转为向量,之后计算序列对应的词的cosine距离。
- Dot Product: 点积,同上,但是将cosine距离改为点积距离。
2.3.2卷积层细节
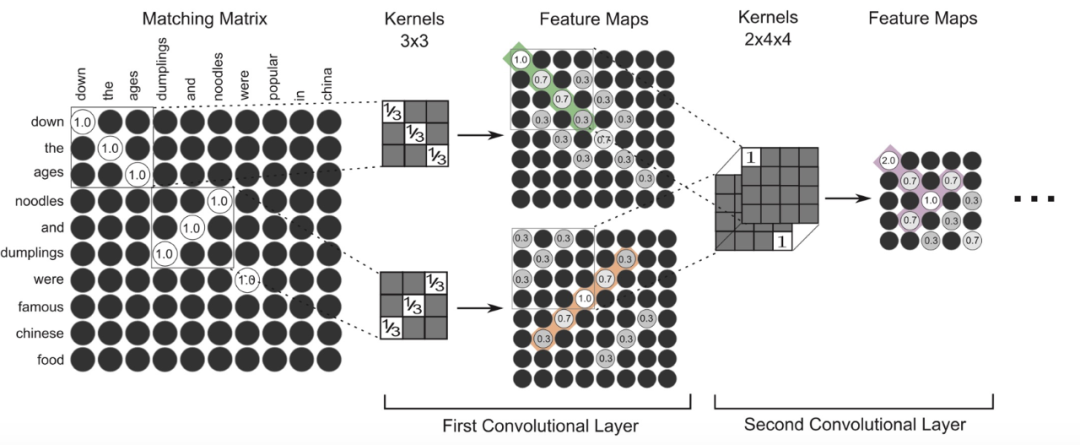
利用两层的CNN对相似度矩阵进行特征抽取,这里要注意的是由于上一层的相似度矩阵shape不一致,在第一层CNN后面进行maxpool的时候,要使用动态pool。最后用两层的全连接对CNN的结果进行转换,使用sigmoid激活,使用softmax函数得到最终分类概率。
总的来说,通过多层的卷积,MatchPyramid可以在单词或者句子级别自动捕获重要的匹配模式。
2.4 ABCNN
AB为Attention-Based,即基于注意力机制的卷积神经网络。这篇文章来自于慕尼黑大学信息语言处理中心,原文传送门: https://www.transacl.org/ojs/index.php/tacl/article/view/831/194。本文的作者也采用了CNN的结构来提取特征,并用attention机制进行进一步的特征处理,作者一共提出了三种attention的建模方法。
ABCNN的基础是BCNN(Bi-CNN),BCNN的网络结构如下图所示,四层分别是:输入层、卷积层、池化层和输出层。
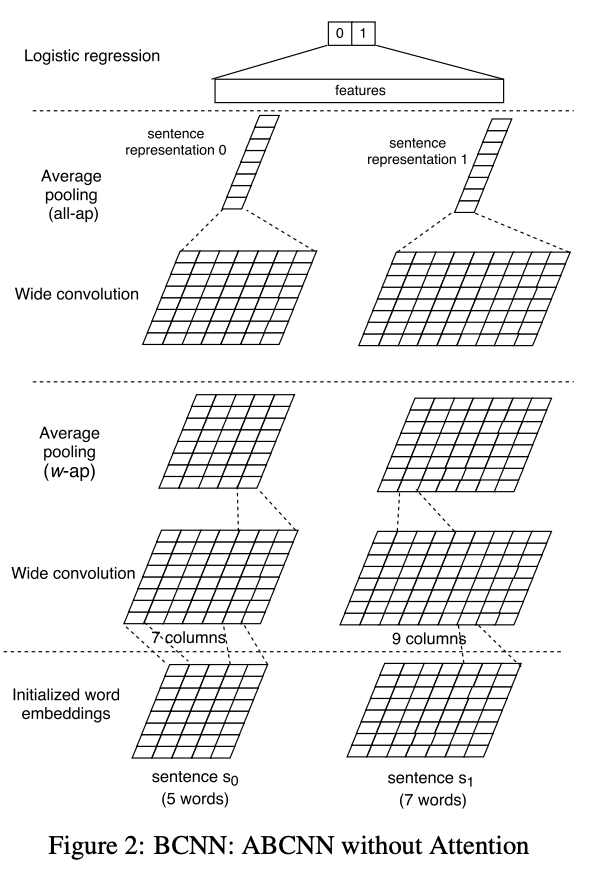
BCNN方式就是正常的一个CNN网络架构,并没有进行交互产生交互信息,因此引入了Attention机制,文章提了三种结构:ABCNN-1, ABCNN-2和ABCNN-3.
2.4.1 ABCNN-1
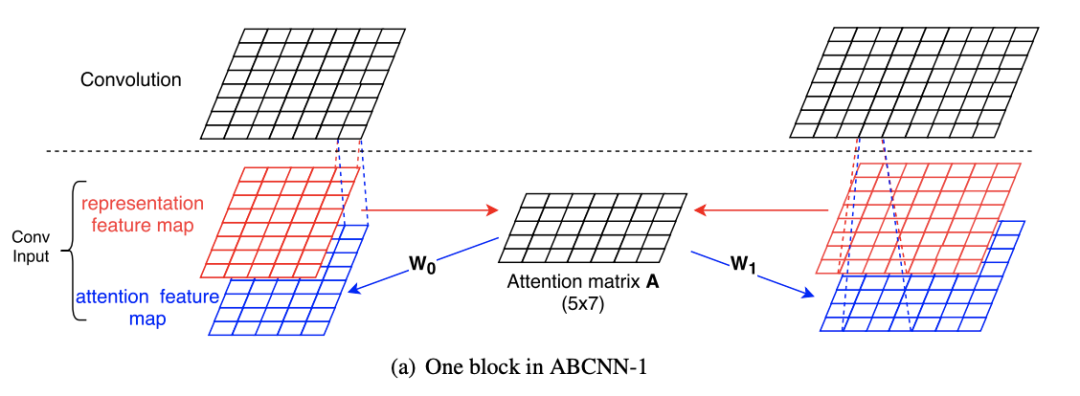
ABCNN-1是在输入层之后,卷积层之前添加注意力矩阵A,A用来定义两个句子之间词的关系。图中红色矩阵与BCNN的输入层一致,表示word级别的词向量,蓝色矩阵为phrase级,是高一级的词向量表示。蓝色矩阵是由注意力矩阵A和红色词向量矩阵计算生成。注意力矩阵A的计算方式为:
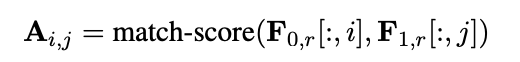
即Matrix A中数值Ai,j的计算是由sentence1第i个单词的向量与sentence2中第j个单词的距离度量。作者使用的是两个向量的欧几里德距离。得到了attention矩阵A,则可以计算句子的attention特征:
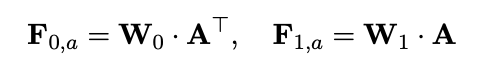
接下来将句子的原始词向量表示和Attention特征表示叠加,输入到卷积层进行计算。
2.4.2 ABCNN-2
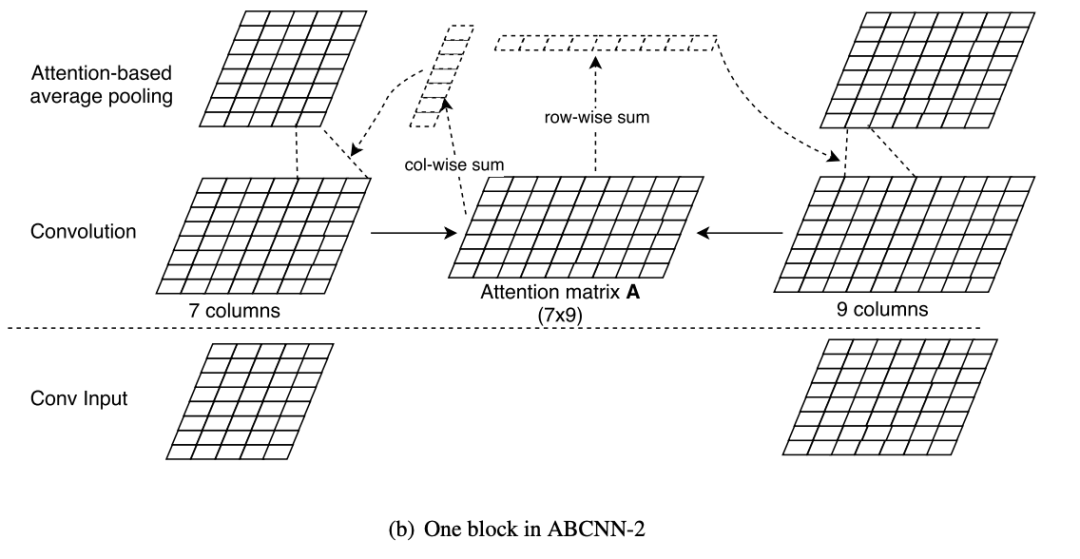
ABCNN-2 是在卷积层之后,池化层之前添加注意力矩阵A。其计算方式与ABCNN-1 相同,sentence0第j个词的词权重为a0j,sentence1第j个词的词权重为a1j。
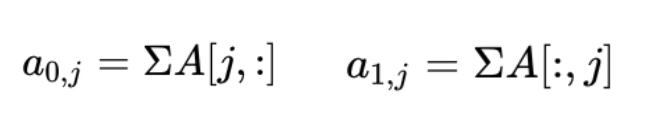
ABCNN-2 模型中的pooling 方法,是根据计算出的Attention权重向量加权求和计算得到的。公式如下:
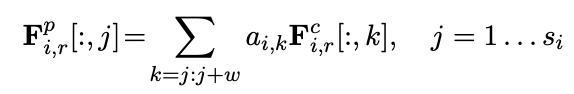
其中表示第i个sentence中第r个词池化后的特征,表示第i句话第r个词卷积后的词向量。剩余层操作和BCNN相同。
2.4.3 ABCNN-3
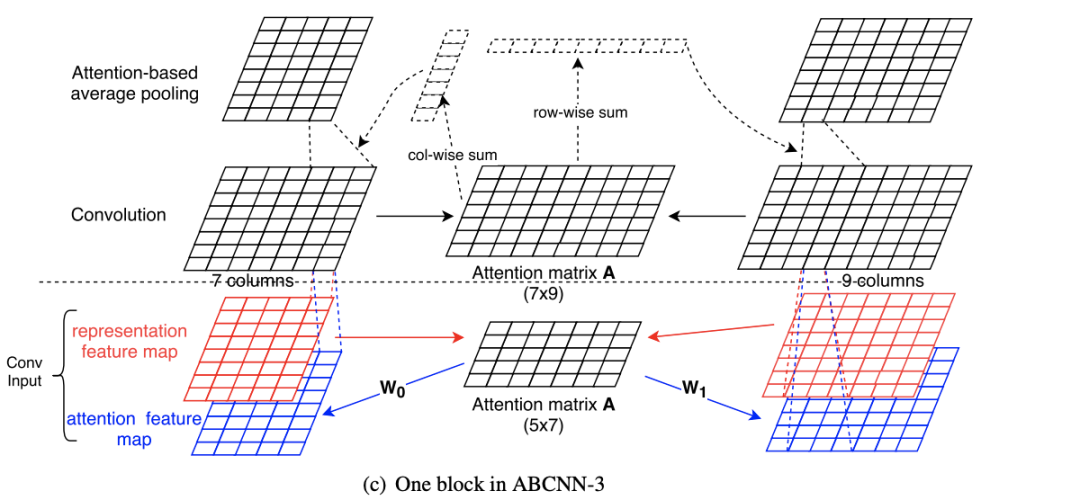
从图中可以看出,ABCNN-3是ABCNN-1和ABCNN-2的结合,卷积层和池化层都添加了attention机制,这里就不再多说了。
2.5 ESIM
2017年提出的ESIM, 全称为Enhanced Sequential Inference Model,该模型本身是用来文本推理的,给定前提p和假设h,判断p和h是否有关联,也可以用来作文本匹配。该模型综合应用了BiLSTM 和注意力机制,在文本匹配中效果十分强大,号称 短文本匹配神器。原文传送门 https://arxiv.org/abs/1609.06038,下图中左侧为ESIM 的模型结构。
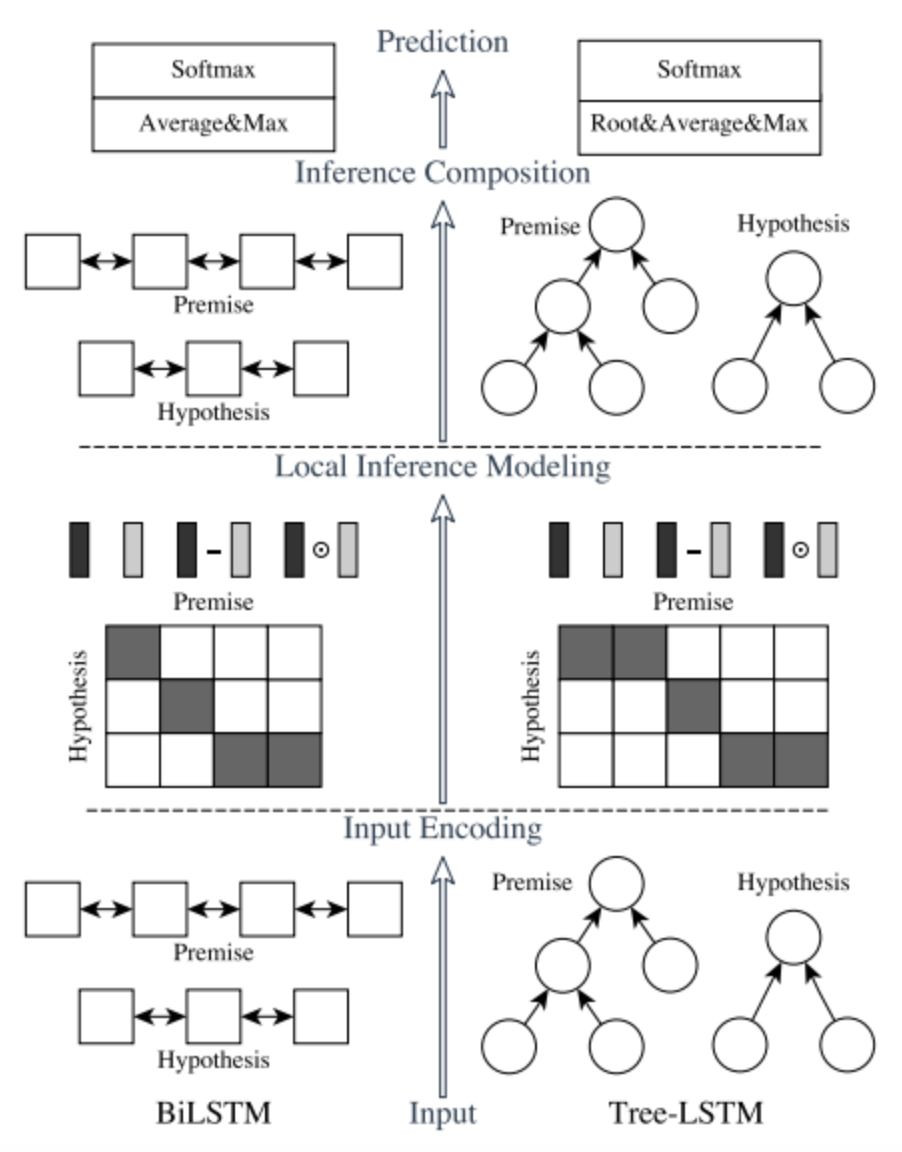
ESIM一共包含四部分,输入层、交互层、聚合层和预测层。
2.5.1 输入层
输入一般可以采用预训练好的词向量或者添加embedding层,接下来就是一个BiLSTM,作用是为embedding做特征提取,最后把其隐藏状态的值保留下来。
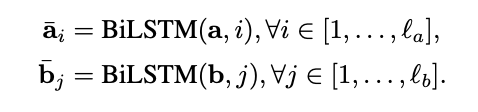
2.5.2 交互层
接下来就是需要分析这两个句子之间的联系了,这层是ESIM的点睛之笔, 主要在句子基础上表征了两个句子词语之间的关系,并凸显了某一句中的单词对另一句各单词之间的产生的影响。首先,使用点积的方式计算a句中第i个词和b句中第j个词之间的attention权重。
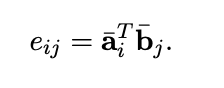
然后对两句各单词之间进行交互性计算,该词与另一句子联系越大,则计算出的值也会越大:
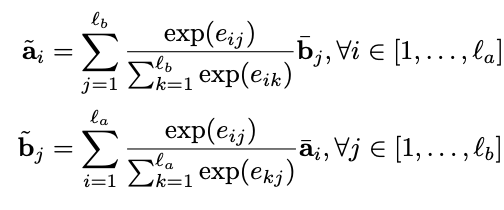
上述两步称为Local Inference Modelling,相当于先用attention机制计算出a句某一单词和b句中各个单词的权重,然后再将权重赋予b句各个单词,用来表征a句中的该单词,形成一个新的序列,b句亦然。简单来说可以这样理解:a句中有个单词“boy”,首先分析这个词和另一句话中各个词之间的联系,计算得到的结果标准化之后作为权重,用另一句话中的各个词向量按照权重去表示"boy"。
得到了新的序列之后进行差异分析,判断两个句子之间的联系是否足够大,将每句话的原BiLSTM序列和新序列进行差和积操作,并将所有序列拼接起来形成一个序列。这步称为Enhancement of local inference information。
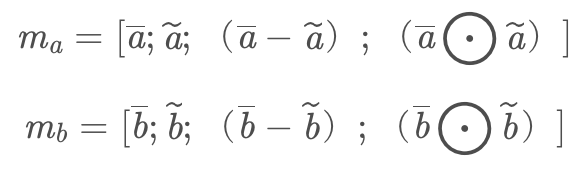
2.5.3 聚合层
在综合所有信息之后进行一个全局分析,使用一个组合层来合成增强的局部推断信息。此处再用BiLSTM进行一次编码,将新序列信息内容在内部进行一个融合,使用relu函数降低模型复杂度。
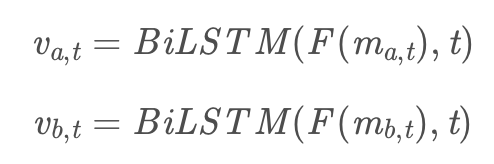
2.5.4 预测层
对聚合层输出进行一个pooling操作,并将pooling后的结果简单拼接为最后进入分类器的向量。
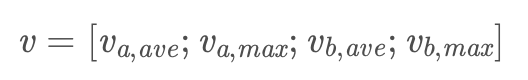
将向量V放入一个多层感知器进行分类,输出层使用softmax,得到最后的预测结果。
2.6 Bimpm
Bimpm(Bilateral Multi-perspective Matching) 即 双向多角度匹配,2017年由IBM提出,原文传送门: https://arxiv.org/pdf/1702.03814.pdf。 相信在阅读了ESIM之后对“双向”有了一定的理解,该模型的亮点在于如何“多角度”进行匹配。
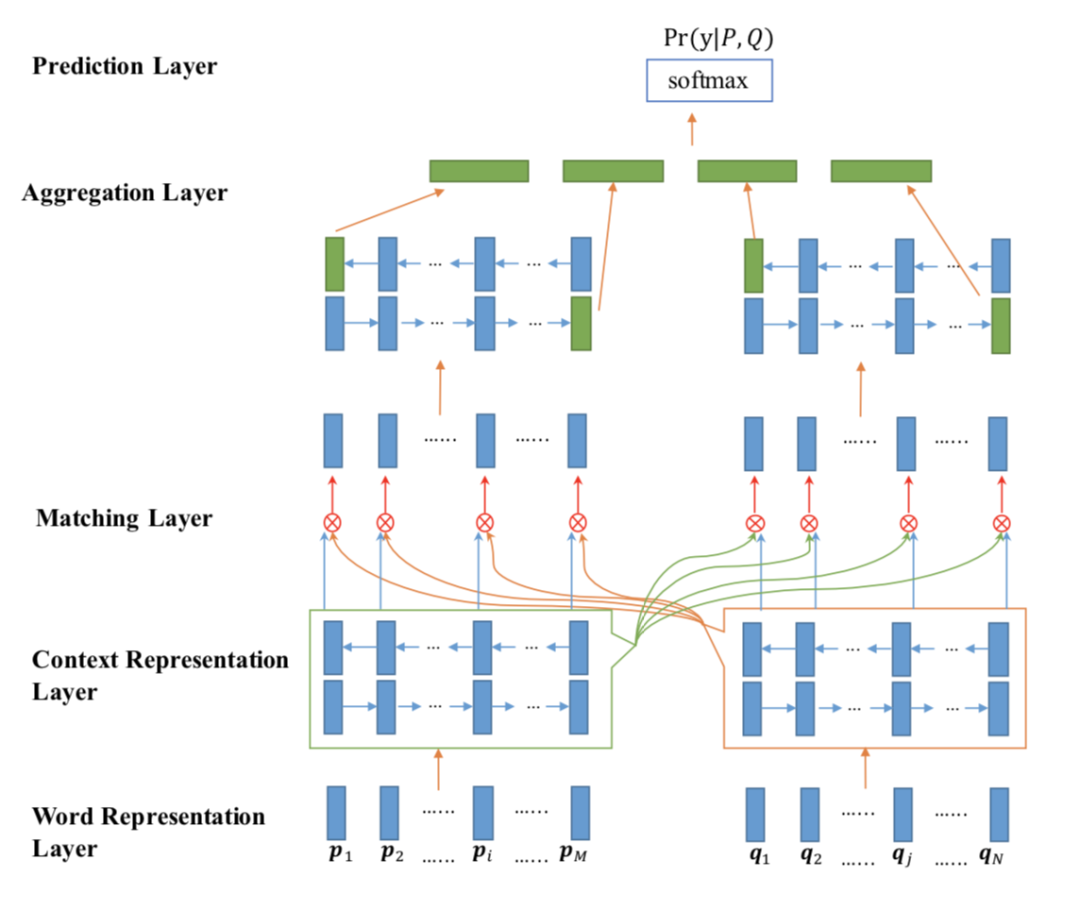
2.6.1 输入层
该模型的输入层与ESIM略有差别:字向量经过一层LSTM,取最后一个time作为char embedding ,然后与预训练好的词向量进行拼接,拼接之后经过BiLSTM,保存两个query(P,Q)的每个time-step值。
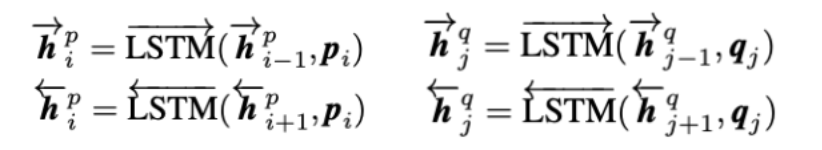
2.6.2 匹配层
在匹配层,模型采用了4种方法进行匹配BiLSTM输出的上下文向量,每种都是双向的,下面仅从一个方向P->Q解释匹配算法,另一方向与其相同。
1. full-matching:在这种匹配策略中,用P中每一个time step的上下文向量(包含前向和后向)分别与句子Q中最后一个time step的上下文向量(包含前向和后向)计算匹配值,即
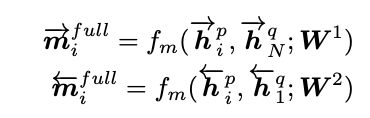
2. maxpooling-matching:在第一种匹配方法中选取最大的匹配值,即
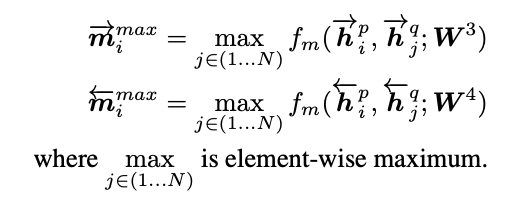
3. attentive-matching:先对P和Q中每一个time step的上下文向量(包含前向和后向)计算余弦相似度,得到相似度矩阵
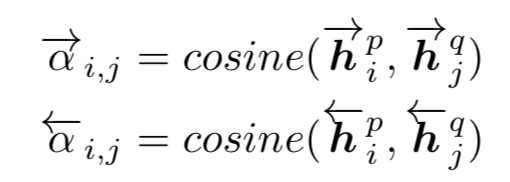
然后将相似度矩阵作为Q中每一个time step权重,通过对Q的所有上下文向量(包含前向和后向)加权求和,计算出整个句子Q的注意力向量
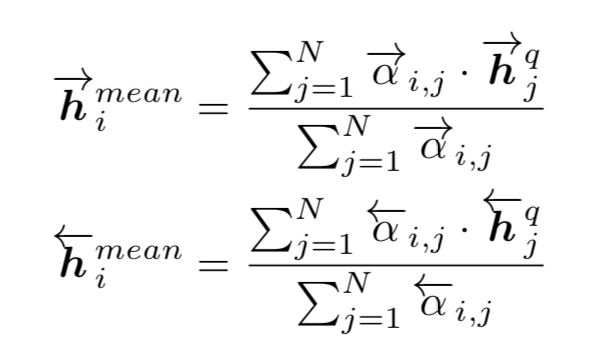
最后,将P中每一个time step的上下文向量(包含前向和后向)分别与句子Q的注意力向量计算匹配值
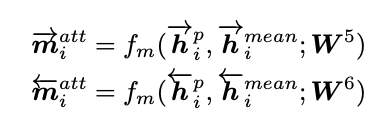
4. max-attentive-matching:与attentive-matching的匹配策略相似,不同之处在于选择句子Q所有上下文向量中余弦相似度最大的向量作为句子Q的注意力向量。
2.6.3 聚合层与输出层
获得16个匹配向量后(P->Q,Q->P各8个),再次使用BiLSTM将两个序列的匹配向量聚合成一个固定长度的匹配向量。经过两层全连接层后,softmax输出最终匹配结果。
三、总结
本文介绍了六种交互型的深度语义匹配模型。交互型匹配模型的共同特点是:不存在单个文本的表达,从模型的输入开始两段文本就进行了交互,得到细粒度的匹配信息。其 优点 是:保持细粒度的匹配信息,避免在一段文本抽象成一个表达时,细节的匹配信息丢失。但 缺点 是:
- 需要大量的有监督的文本匹配的数据训练。
- 网络复杂,模型训练的时候资源消耗较大,每一对文档都得完全通过一遍网络。
因此这类模型一般都是用于类似问答系统、翻译模型、对话系统这种语义匹配程度高、句式变化复杂的任务中。
说了这么多原理,深度语义匹配模型如何在工业界中应用?下期精彩: 【深度语义匹配模型】实践篇:匹配在智能客服中的应用。
四、参考文献
- http://cjc.ict.ac.cn/online/onlinepaper/pl-201745181647.pdf
- https://www.sohu.com/a/140243692_500659
- https://blog.csdn.net/ling620/article/details/95468908
- https://blog.csdn.net/coraline_m/article/details/78796786
- https://zhuanlan.zhihu.com/p/47580077
- https://zhuanlan.zhihu.com/p/72403578
- https://blog.csdn.net/Xwei1226/article/details/82081583
- [htt
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%B4%9D%E5%A3%B3%E6%89%BE%E6%88%BF%E6%B7%B1%E5%BA%A6%E8%AF%AD%E4%B9%89%E5%8C%B9%E9%85%8D%E6%A8%A1%E5%9E%8B%E5%8E%9F%E7%90%86%E7%AF%87%E4%BA%8C%E4%BA%A4%E4%BA%92%E7%AF%87/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


