贝壳找房深度语义匹配模型原理篇一表示型
深度语义匹配模型系列文章会向大家介绍几种经典的表示型和交互型模型原理及其优缺点,同时后续的实践篇将会介绍匹配模型在智能客服中的实践应用。
一、背景
工业界的很多应用都有在语义上衡量本文相似度的需求,直接目标就是判断两句话是否表达了相同或相似意思,我们将这类需求统称为“语义匹配”,nlp 中的许多任务都可以抽象为语义匹配任务。语义匹配的相关应用场景主要有搜索引擎、问答系统、推荐系统、文本去重等,主要是为了找到与目标文本最相关的文本,比如在问答系统中找到和问题最相关的答案,在搜索引擎中找到与搜索框中关键词最相关的网页等。
传统的文本匹配技术有 BoW、TF-IDF、BM25、Jaccard、SimHash 等算法,主要能够解决词汇层面的匹配问题,但基于词汇重合度的匹配算法有很大的局限性:
- 词义局限:例如“苹果”在不同的语境下表示不同的含义,既可以表示一种水果,也能表示苹果公司。
- 结构局限:“深度学习”和“学习深度”虽然词汇完全重合,但表达的意思不同。
二、表示型深度语义匹配模型
随着深度学习在计算机视觉、语音识别等领域的成功运用,近年来有很多研究致力于将深度神经网络模型应用于自然语言匹配任务,以降低特征工程的成本。
从匹配模型的发展来看,可以将模型分为:
- 单语义模型:对两个句子编码后计算相似度,不考虑句子中短语的局部特征。
- 多语义模型:从多个粒度对待匹配的句子进行解读,考虑字、短语等局部特征。
- 匹配矩阵模型:考虑待匹配句子的两两交互,交互之后用深度网络提取特征,能获得更深层次的句子之间的联系。
而换个角度,从模型的本质来看可以分为两种类型: 表示型和交互型。表示型的模型会在最后一层对待匹配的两个句子进行相似度计算,交互型模型会尽早的让两个句子交互,充分应用交互特征。本次为大家介绍几种表示型的匹配算法。
表示型的模型更侧重于对表示层的构建,其基本模型结构如下图所示:
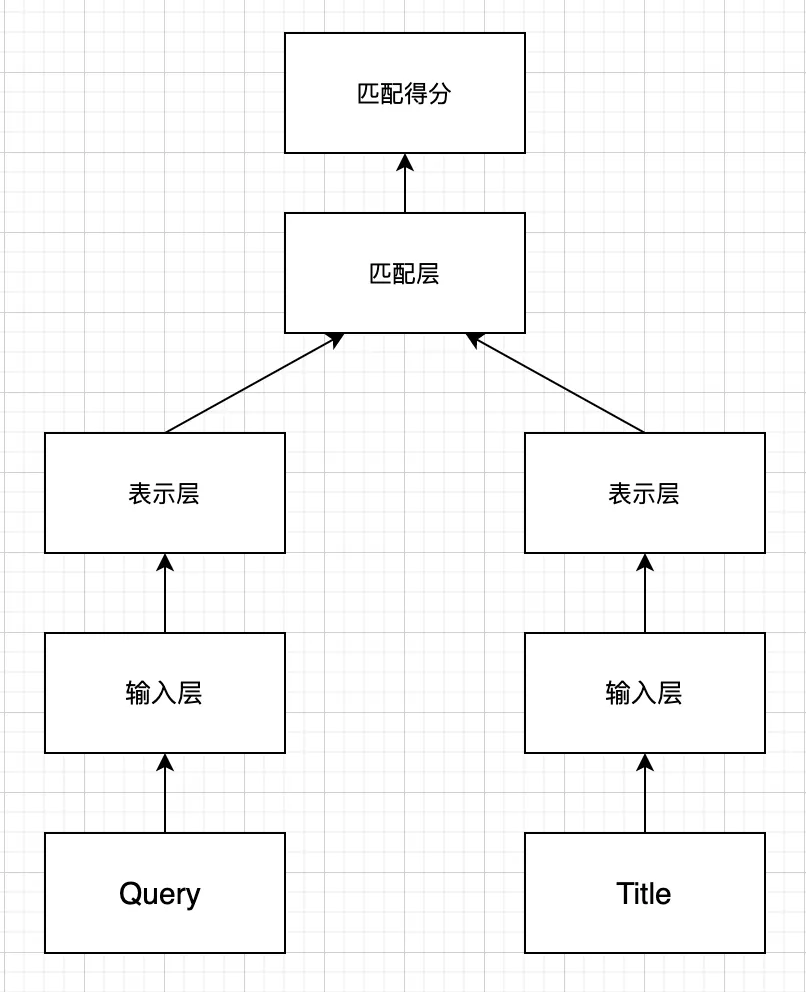
表示型匹配模型的特点是:
- 采用 Siamese 结构,共享网络参数。
- 对表示层进行编码,使用 CNN, RNN, Self-attention 均可。
- 匹配层进行交互计算,采用点积、余弦相似度、高斯距离、相似度矩阵均可。
表示型匹配模型的代表算法有: DSSM、CDSSM, MV-LSTM, ARC-I, CNTN, CA-RNN, MultiGranCNN 等。
2.1 DSSM
DSSM 的全称是 Deep Structured Semantic Models,是匹配模型的鼻祖。原文传送门: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf,这篇 paper2013 年由微软 Redmond 研究院发表,短小但是精炼。下图为 DSSM 的整体网络结构
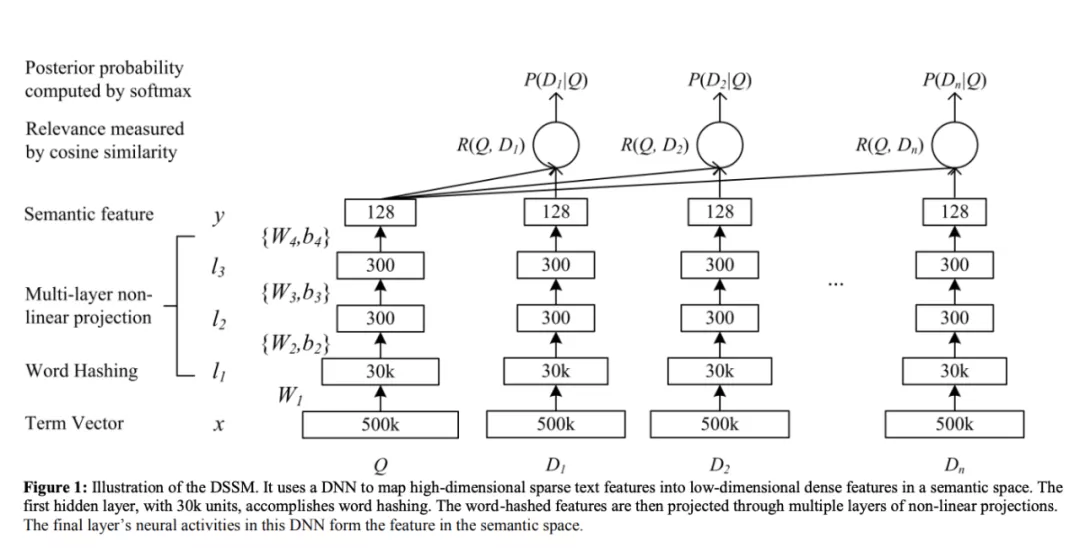
2.1.1 输入层及 word hash
输入层做的事情是把句子映射到一个向量空间里并输入到深度神经网络(Deep Neural Networks,DNN)中,这里英文和中文的处理方式有很大的不同。
(1)英文
英文的输入方式采用了 word-hashing,其主要目的是减少维度,压缩空间,采用 letter-ngrams 对英文单词进行切分,并以“#”作为单词的开头和结尾。本文用的是 letter-trigram,50w 个词的 one-hot 向量空间可以通过 letter-trigram 压缩为一个 3 万维的向量空间,例如单词“good”会被切分成(#go,goo,ood,od#)。
(2)中文
在单纯的 DSSM 模型中,中文是按照“字袋模型”来处理的,因为汉字部首偏旁特征的研究目前还不很成功。因为中文字个数是有限的,常用的字大概有 15K 左右,而常用的双字大约到百万级别,这里采用字向量(one-hot)作为输入,因此这种做法不会有维度过大的问题。
2.1.2 表示层
DSSM 的特征抽取层,其实就是 3 个全连接层串行的连接起来,在 DSSM 中采用 tanh 作为激活函数。
2.1.3 匹配层
通过表示层得到了一些 128 维的特征向量,在匹配层采用 cosine 距离(即余弦相似度) 来表示:
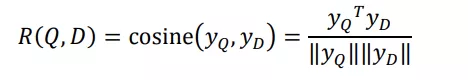
通过 softmax 函数可以把 Query 与正样本 Doc 的语义相似性转化为一个后验概率:
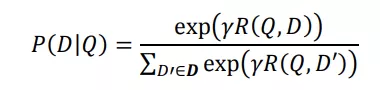
在训练阶段,通过极大似然估计,最小化损失函数为:
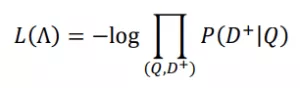
2.1.4 模型优缺点分析
DSSM 的优点在于能够快速的计算多个 query 和 Doc 对之间的语义相似度;相对于词向量的方式,它采用有监督的方法,准确度要高很多,同时单个词或单个字处理不依赖切词的正确与否。缺点是在词向量表示时采用词袋模型,不考虑词语的位置信息,这对语义理解是一个大的损失。此外,DSSM 是弱监督模型,因为引擎的点击曝光日志里 Query 和 Title 的语义信息比较弱,从这种非常弱的信号里提取出语义的相似性或者差别,那就需要有海量的训练样本,因此训练成本会比较高。
2.2 变种 1: CDSSM
针对 DSSM 词袋模型丢失上下文信息的缺点,CDSSM(convolutional latent semantic model)2014 年由微软提出,又叫 CLSM。CNN-DSSM 与 DSSM 的区别主要在于输入层和表示层, 与 DSSM 相比,该算法相比原始 DSSM 将近会有 10% 的效果提升。原文传送门 https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2014_cdssm_final.pdf
2.2.1 输入层
(1)英文: 除了 DSSM 用到的 letter-trigram,CDSSM 也用了滑动窗口策略。word-trigram 其实就是一个包含了上下文信息的滑动窗口,对窗口里的每个词进行 letter-trigram,将三个向量 concat 起来,最终映射到一个 9 万维的向量空间里。
(2)中文: 采用 one-hot 编码时,依然是使用字向量维度更可控,此处与 DSSM 的中文处理方法一致。
2.2.2 表示层
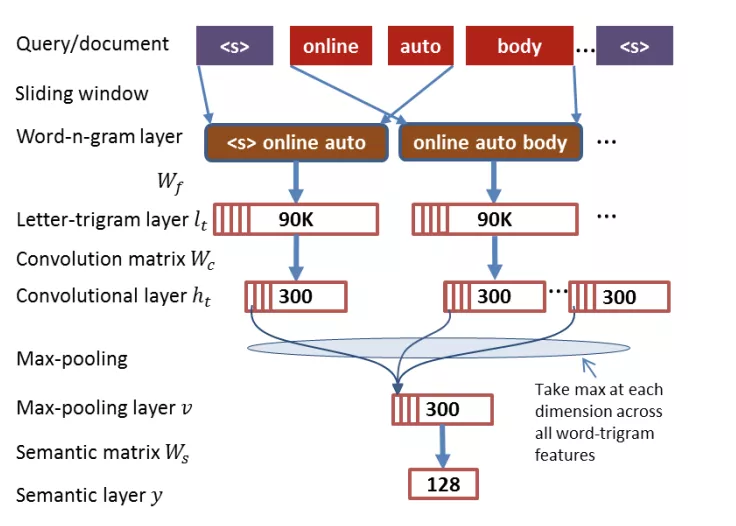
CDSSM 的表示层是将全连接层替换为一个卷积神经网络。
(1)卷积层: 每个英文单词经过 word hash 之后由一个 30K 大小的向量表示,窗口大小为 3,即将待卷积部分三个单词拼接成一个 90K 的向量,而卷积核为一个 90K * 300 的矩阵,每次卷积输出一个 1*300 的向量。
(2)池化层: 池化层也是经常和卷积一起配合使用的操作了,它的作用是为句子找到全局的上下文特征,这里之所以选择 max-pooling 是因为,语义匹配的目的是为了找到 query 和 doc 之间的相似度,那么就需要去找到两者相似的点,max-pooling 则可以找到整个 Feature map 中最重要的点。最终池化层的输出为各个 Feature Map 的最大值,即一个 300*1 的向量。
(3)全连接层: 最后通过全连接层把一个 300 维的向量转化为一个 128 维的低维语义向量。全连接层采用 tanh 函数。
CDSSM 的最后的损失函数,相似度度量等和 DSSM 一致,这里省略。
2.2.3 模型优缺点分析
CDSSM 通过输入层提取了滑动窗口下的上下文信息,又通过卷积层和池化层提取了全局的上下文信息,上下文信息得到较为有效的保留。但因为滑动窗口大小的限制,仍无法获得较长距离的上下文依赖关系。
2.3 变种 2 : LSTM-DSSM
针对 CDSSM 无法捕获较远距离上下文特征的缺点,有人提出了用 LSTM-DSSM(Long-Short-Term Memory)来解决该问题。原文传送门 https://arxiv.org/pdf/1412.6629.pdf。这篇文章是对 DSSM 模型的修改,相比于 CDSSM 更简单,毕竟全连接网络是最简单的神经网络,替换一下模型就能提升效果。
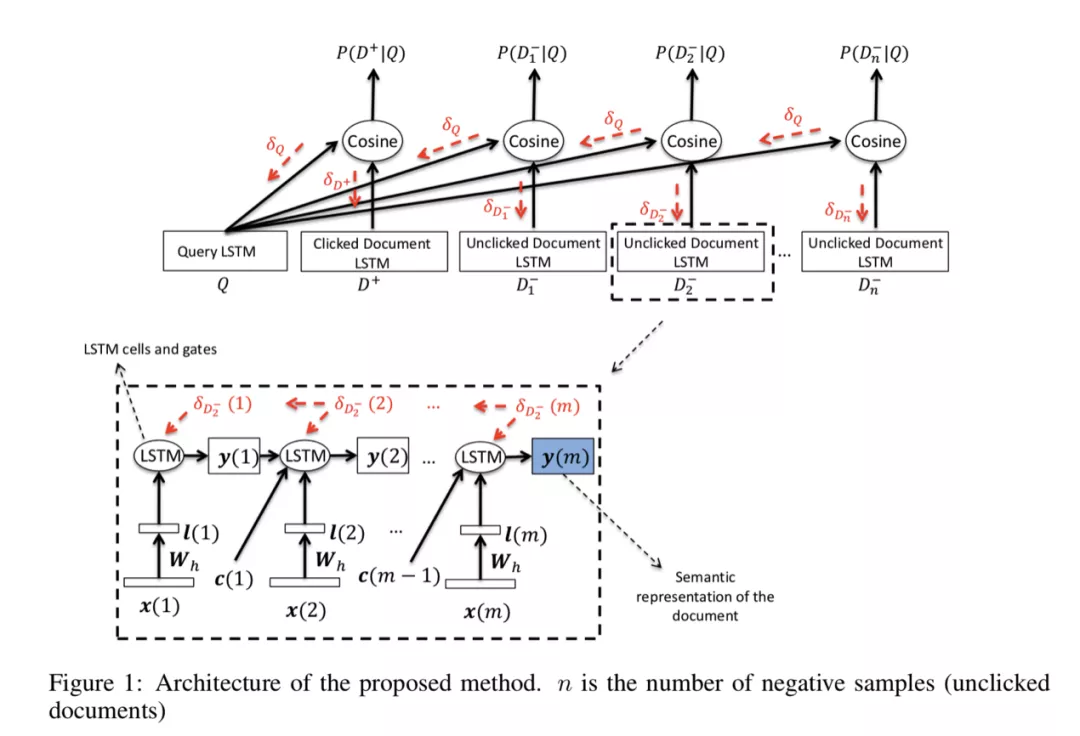
该模型与 DSSM 的本质区别其实就是把 DSSM 里的全连接改成 LSTM。这里的输入层个人感觉也不需要做 word hashing,直接把每个单词映射到一个 word representation,就是 embedding,然后把整个句子送入 LSTM 并训练,拿出最后输出的状态作为隐语义向量,有了这个最后的语义向量后就和 DSSM 模型一样,进行相似度度量,softmax 计算概率等等。
2.4 变种 3: MV-DSSM
MV 为 Multi-View,一般可以理解为多视角的 DSSM,原文传送门 https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/frp1159-songA.pdf,该文章 2016 年由微软发表,并将其用于用户推荐。这个工作同样是对 DSSM 的改进,与 CDSSM 和 LSTM-DSSM 不同的是,它没有改变网络结构,而是从信息源入手解决这个问题。
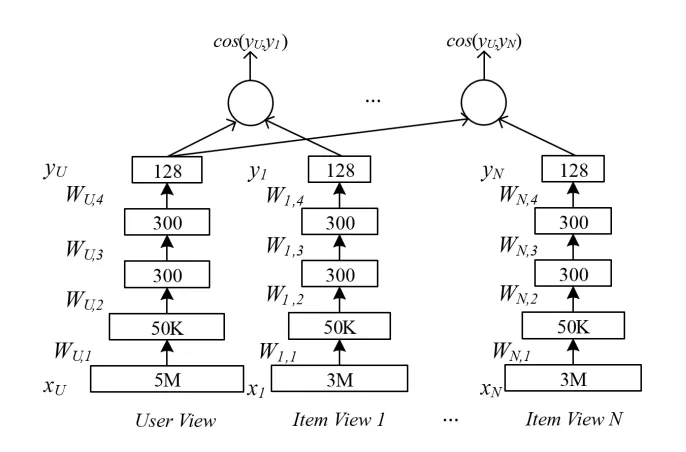
放在我们的场景可以这样理解 multi-view: 比如我们的经纪人,可能在 app 上产生了带看信息,也可能在 link 上问了房源修改的问题。不同的信息源都对同一个经纪人进行了一些刻画,所以综合各种信息源可以描述出经纪人画像,然后进行推荐。MV-LSTM 的核心思想是把经纪人的特征与不同的信息源统一到一个相同的语义空间,通过 Cosine 距离表征相关性。这里的每一个信息源与经纪人的匹配都是一个独立的 DSSM 模型,但是共享一个 user 模型。
那么问题来了
DSSM 系列的模型看起来在真实文本场景下可行性很高,但不一定适合所有的业务。
- DSSM 是端到端的模型,对于一些要保证较高准确率的场景,最好先用人工标注的有监督的数据,再结合无监督的 w2v 等方法进行语义特征的向量化,效果会更加可控。
- DSSM 是弱监督模型。dssm 的训练样本都是点击曝光日志里的 Query 与 Tiltle,但点击的 title 不一定与 query 是语义匹配的,因此想要从这种非常弱的信号里提取出语义相似性就需要有海量的训练样本。
- DSSM 均使用 cosine 相似度作为匹配的结果,而余弦相似度是无参匹配公式,个人感觉加一层 MLP 会更好一点。
接下来介绍两个 DSSM 系列之外的匹配模型。
2.5 ARC-I
ARC-I, ARC-II 模型是 2014 年华为诺亚方舟实验室提出,前者是表示型匹配,后者是交互型匹配(将在下期讲到),原文传送门: https://papers.nips.cc/paper/5550-convolutional-neural-network-architectures-for-matching-natural-language-sentences.pdf.该模型相比于 DSSM,最大特点是通过逐层构图和合并充分表达句子的词序信息,并且匹配计算公式采用了带参数的计算公式。
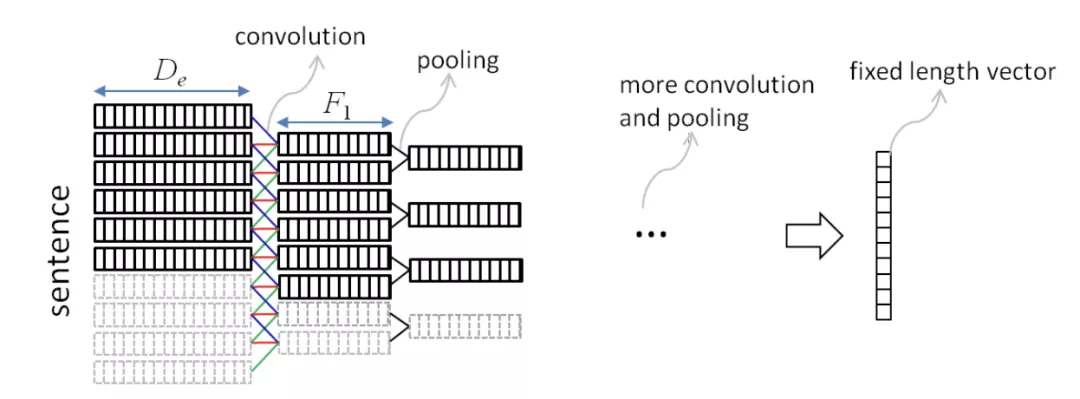
2.5.1 基于 CNN 的句子建模
本文基于 CNN 为句子建模,对于长度较短的句子作补 0 处理,卷积的计算和传统的 CNN 卷积计算无异,可参考上文的 CDSSM。卷积的作用是从句子中提取出局部的语义组合信息,pooling 的作用是对多种语义组合进行选择,找出置信度高的特征组合。
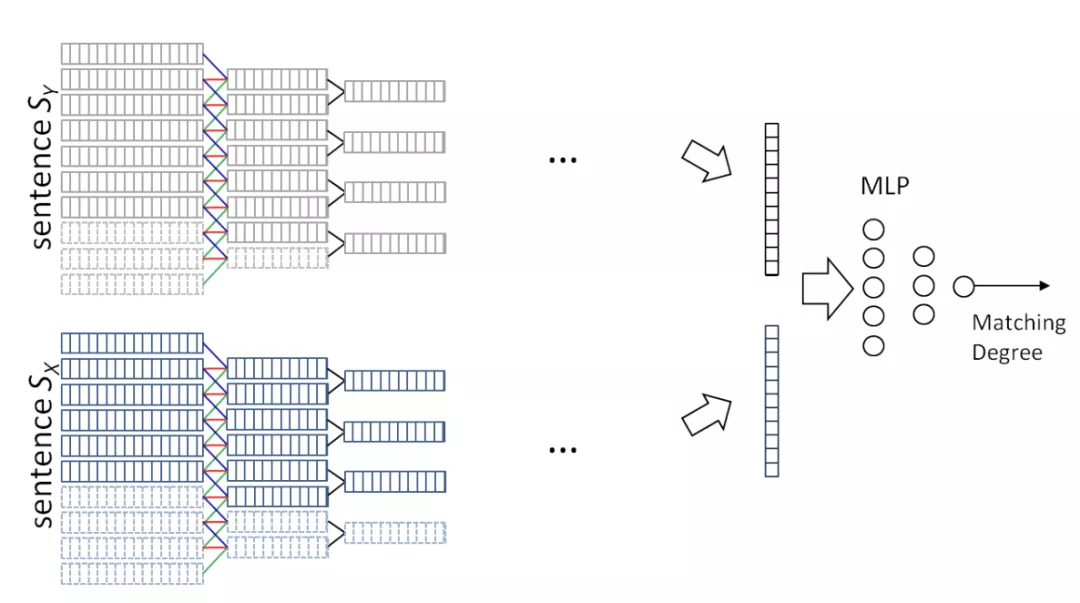
2.5.2 句子匹配
从图中可以看出,两个句子分别进行特征提取,得到两个相同且固定长度的向量,向量为句子经过建模后抽象得来的特征信息,然后将这两个向量作为一个多层感知机(MLP)的输入,最后计算匹配的分数。
这个模型比较简单,但最大的缺点是两个句子在建模过程中完全独立,没有任何交互行为,最后抽象为特征信息后再进行匹配计算,因此过早失去了句子间语义交�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%B4%9D%E5%A3%B3%E6%89%BE%E6%88%BF%E6%B7%B1%E5%BA%A6%E8%AF%AD%E4%B9%89%E5%8C%B9%E9%85%8D%E6%A8%A1%E5%9E%8B%E5%8E%9F%E7%90%86%E7%AF%87%E4%B8%80%E8%A1%A8%E7%A4%BA%E5%9E%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


