贝壳找房关系图谱在贝壳的构建和应用
分享嘉宾:周玉驰 贝壳 资深算法工程师
文章整理:许继瑞
内容来源:贝壳找房知识图谱技术大会
出品平台:DataFun
导读: 贝壳找房积累了大量房、客、人的行为关系数据,我们通过关系图谱的相关技术对这些行为关系进行挖掘,并在实际应用中取得了不错的效果。本次分享将主要介绍关系图谱在贝壳找房的构建历程和落地应用探索。
主要包括:
- 关系图谱的基础建设,包括:关系图谱的基础数据建设,关系强度量化,子图抽取的方法(异质网络和同质网络)
- 关系图谱的能力,包括:节点影响力和 Graph Embedding
- 关系图谱的应用探索
▌为什么做关系图谱
首先来看贝壳找房一些基础节点的数据:

从第一行可以看出,贝壳的客户、房数量较大,每日新增也很大,经纪人增长也很快,小区相对稳定,增量不大。第二行是 2019 年贝壳找房房产行为数据。如何从如此庞大的数据中得到有用于决策的信息,是我们现在要做的工作。用什么方法挖掘数据背后的价值?我们想到了关系图谱。
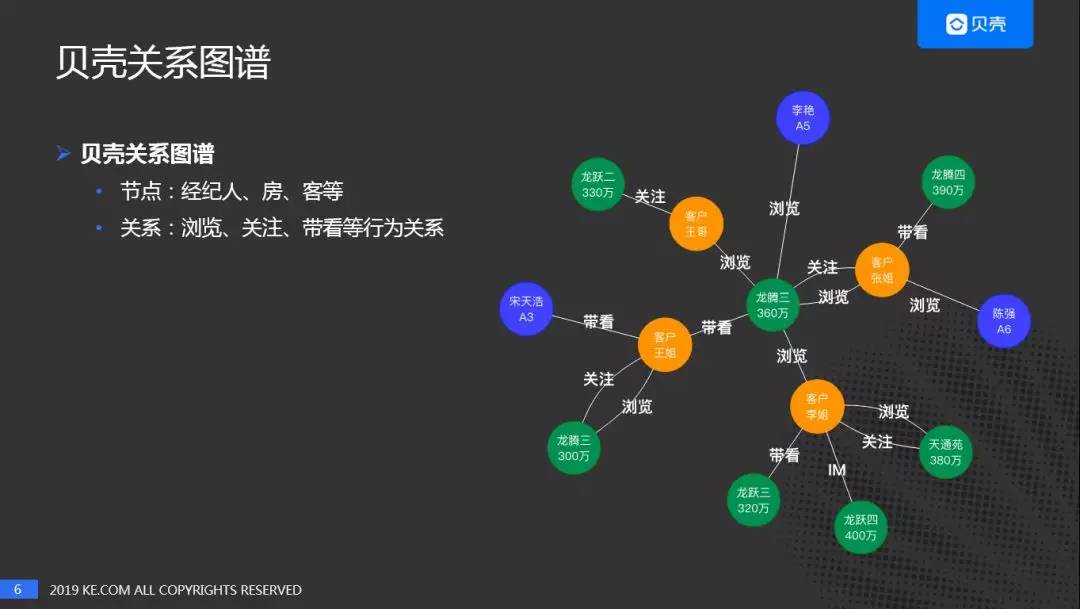
“关系图谱"在业内通常也叫"网络图谱”,上图展示了贝壳关系图谱的实例。实例中,节点是:经纪人、房、客人等。关系:浏览、关注、带看等行为关系。有些是常见的行为,有些是贝壳找房独有的行为,如:带看,等。
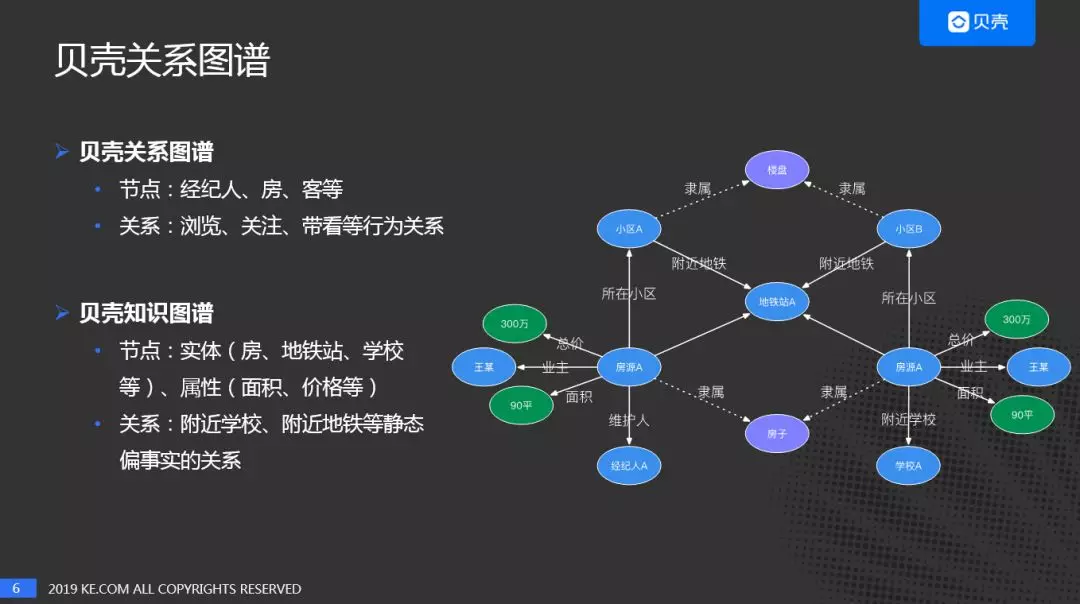
关系图谱与知识图谱的差异,首先看下贝壳知识图谱的示例,节点是:房、地铁站、学校等,关系是附近学校、附近地铁等静态的关系。关系图谱更偏向动态的行为网络而知识图谱更多的是偏实时的静态的知识网络。

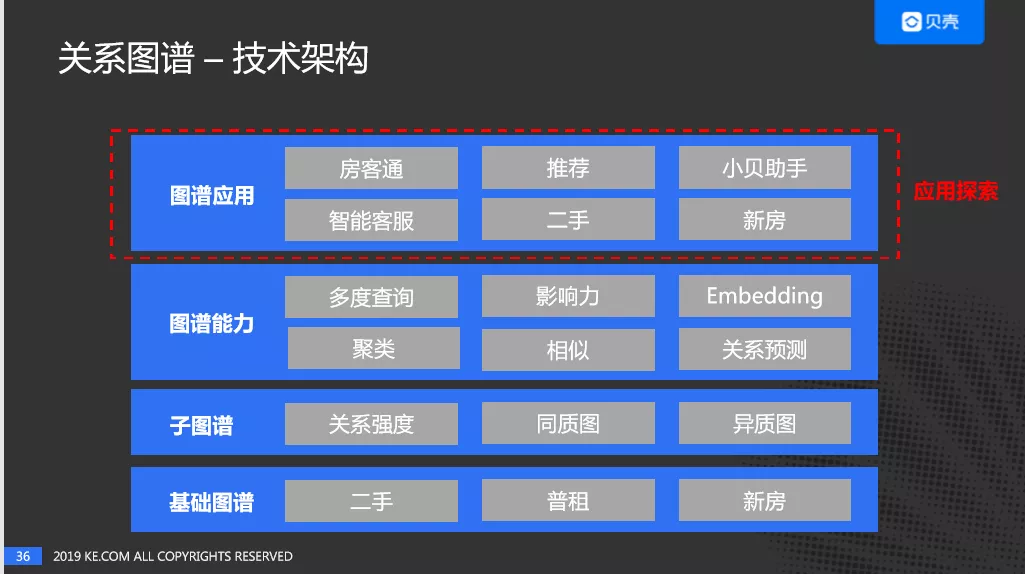
介绍完基本的关系与节点,下面来讨论一下,如何从 0 到 1 搭建关系图谱。在这个过程中离不开三个核心:关系图谱能做什么?如何设计?如何应用?下面以贝壳关系图谱的整体技术架构为切入口,为大家详细介绍下:

贝壳关系图谱的技术架构,自下而上分为: 基础图谱、子图谱、图谱能力、图谱应用。
基础图谱: 基础图谱定义了各种行为的关系。基于基础图谱构建了子图谱。
子图谱: 基于基础图谱构建了子图谱,分为同质图和异质图以及关系强度。同质图是节点、实体和关系,是同一种类型的。在构建子图谱中,有一个非常重要的过程就是关系强度的量化。
图谱能力: 基于子图谱,贝壳进行了图谱能力的建设。包括:
- 基于图数据库的多度查询;
- 节点的影响力,反映了节点影响力的强度;
- Embedding;
- 聚类,有社群发现的算法也有基于 Embedding 的聚类;
- 相似,比如相似房源等,也是基于 Embedding 来计算的相似;
- 关系预测,也就是关系推导。
图谱应用: 基于关系图谱的能力,进行了关系图谱应用的探索,这个部分会在后面介绍。
▌基础建设
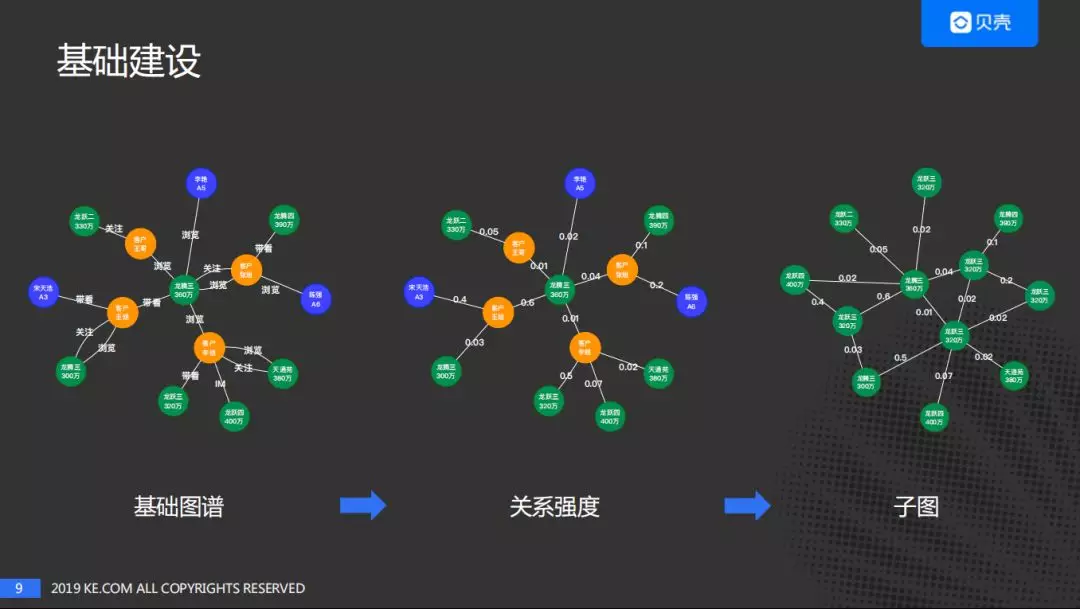
先探讨一下基础建设部分,包括:基础图谱及子图谱。我们首先建设基础图谱,然后量化关系强度。在量化关系强度之后,两个边之间的内容由关系变为数值,值越大表示两个节点直接的关系变的越紧密。关系强度可以做一些直接的应用,如客户偏好的计算,也可以用来做子图的抽取,基于子图做一些应用。
上图中的子图是一个房子关系图谱的示例,节点全部都是房子,房子之间的强度被量化成数值。
- 基础图谱
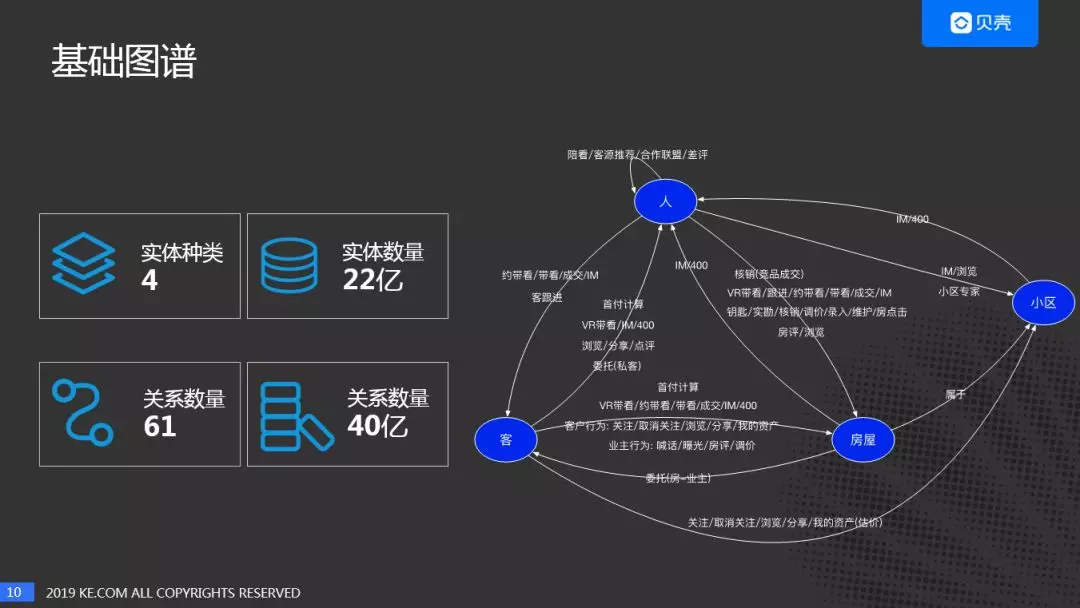
贝壳二手房关系图谱,如下图所示。有四个实体,人:经纪人,客:客户/业主,房,小区。实体数量 22 亿,关系数量有 61 种,40 亿。
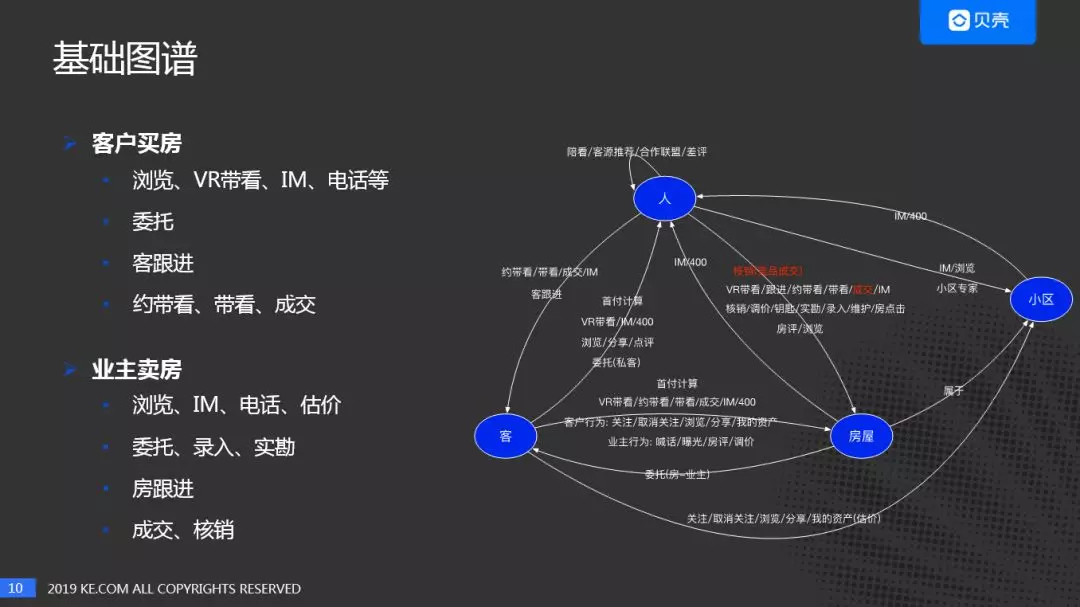
下面通过两个流程,了解关系图谱中实体之间的行为关系。
客户买房:
客户首先到贝壳 App 上浏览房源,可以通过 App 体验贝壳 VR 带看,如果想进一步了解房源可以通过 IM、电话聊天等方式咨询经纪人。如果客户对经纪人比较满意,可以进一步合作,成为该经纪人的私人客户(其他经纪人无法看到此客户信息)。经纪人负责后续跟进,带看,成交等活动。
业主卖房:
业主通过贝壳 App 浏览房源了解市场行情,通过 IM、电话联系经纪人,也可以通过贝壳估价评估业主房子的大致价格。在业主确定房子出售时,可以把房子委托给贝壳,有专门的经纪人对房源进行录入及实勘。房源维护人会经常和业主联系,了解目前业主对房屋出售的意愿,判断业主是否愿意降价等。如果通过贝壳出售了该房子则达成成交,如果被其他中介出售房子,也需要及时的核销。
- 关系强度
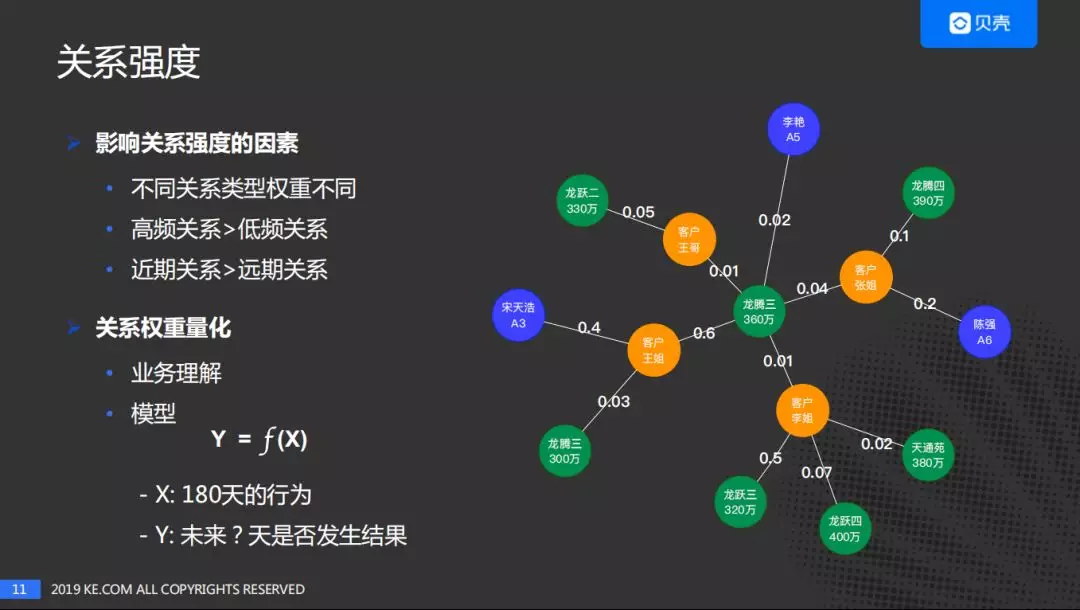
在基础图谱的基础上,量化各节点的关系强度。最主要的影响因素有:
- 不同关系类型的权重不同:如带看的强度大于浏览的关系强度;
- 高频关系 >低频关系:当一个行为发生的频率越高其对应的关系强度值越大;
- 近期关系 >远期关系,离当前时间越近强度就越大,会做一些时间维度的强度衰减。
关系强度的量化:
- 基于业务理解,结合数据生产的漏斗,定义了不同关系类型的权重。
- 采用模型化的方法进行计算,以成交为目标,已导致成交的因素为特征来进行预估。但是这种方法只能对部分关系进行量化,如有的行为,行为量比较少,不足以成为影响成交的行为,且有些关系和成交没有直接关系。模型化的方法主要是对用户行为及业务理解进行交叉验证。
- 同质图
同质图的应用在业内比较成熟,分为两类:
- 面向用户的社交关系图谱(微博、知乎等)
- 基于商品的同质图图谱(贝壳的房子)
下面介绍下房子的关系图谱是如何进行构建的,有两种方法:
① 基于用户的行为序列
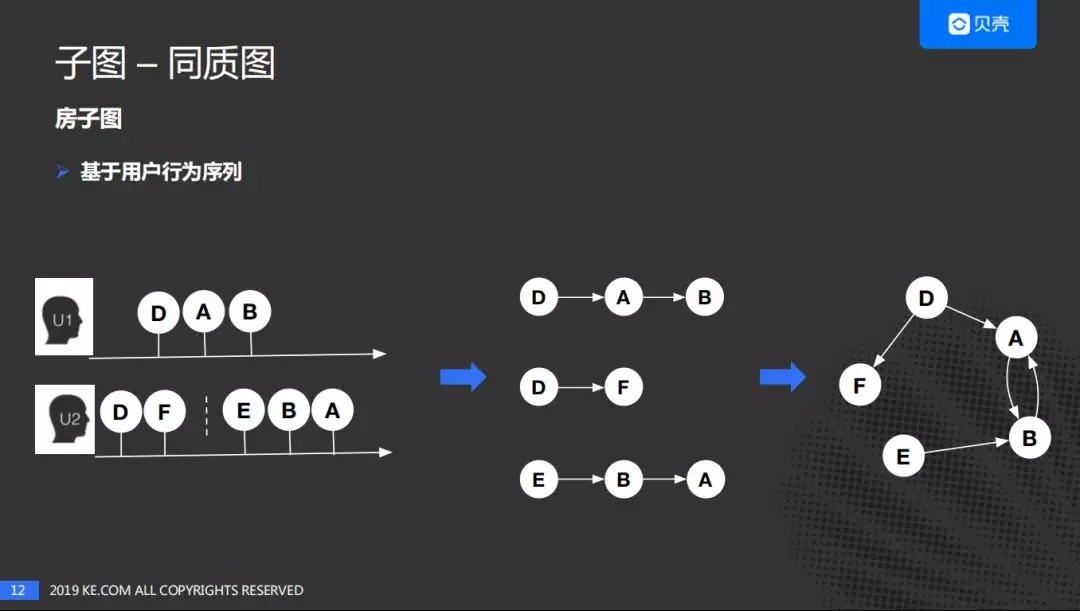
假定一段时间窗口内,用户先后浏览了一些房子,依次可以建立关系。主要考虑两点,一是用户的兴趣短时间内不会发生偏离,二是考虑计算资源的成本。
接下来分析两个用户的行为:
用户 1 先后看了 DAB 三个房子,用户 2 分两个时间段分别看了,DF 及 EBA 房子;我们由此推断,对于用户 1 可以由 D 到 A,A 到 B 建立联系;对于用户 2,第一个时间窗口 D 到 F 及 E 到 B,B 到 A 可以建立联系;最后进行聚合可以得到第三个图,就是房子的关系图谱。
② 基于用户行为传播
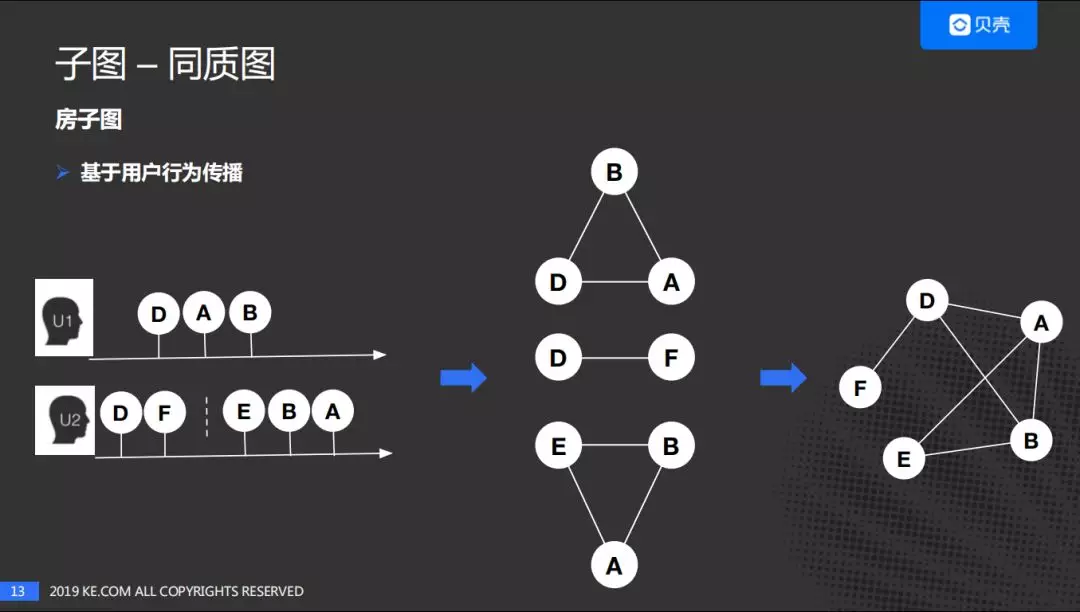
进一步,假定在这个事件窗口期内用户的兴趣不变,我们认为用户的行为可以进行传播,即在事件窗口期内用户浏览的房子可以在两两之间建立联系。最后进行聚合得到最后的图谱。类似于协同过滤的思路。
- 异质图
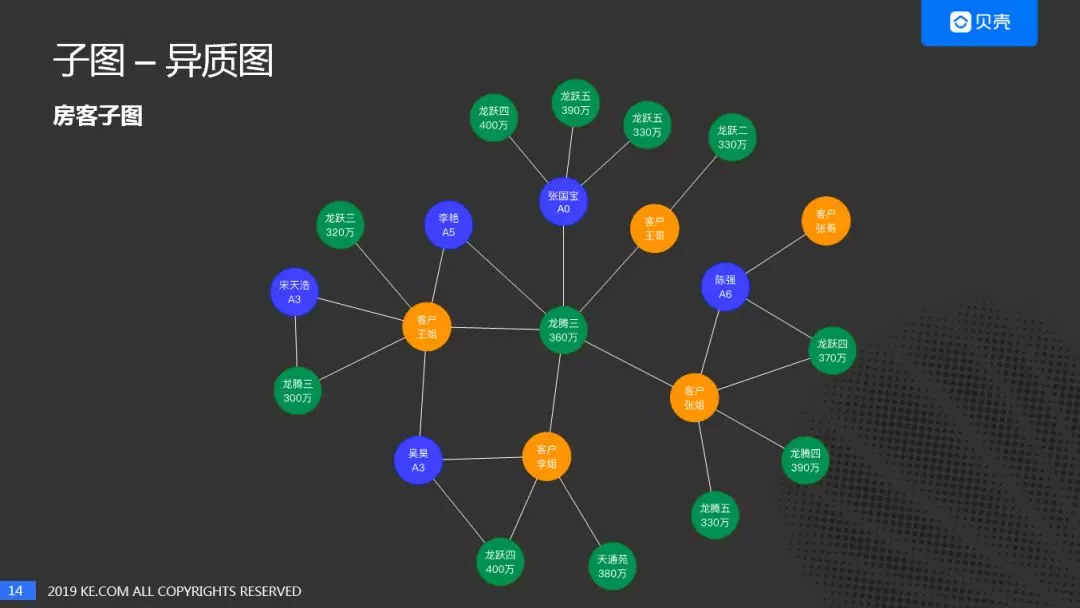
我们社会中的网络,大部分都是异质图。在我们这边首先研究的是房客子图,为什么选择房客子图?主要因为我们的图谱中是有经纪人的,考虑到房和客的特征和偏好存在倾向性。一个想要买房子的客户对目标房子的面积和价格是有预期的,同理房子的特征也是确定的。对于经济人来说,对房子的价格和面积是不介意的,可以卖任何价位和任何面积的房子。
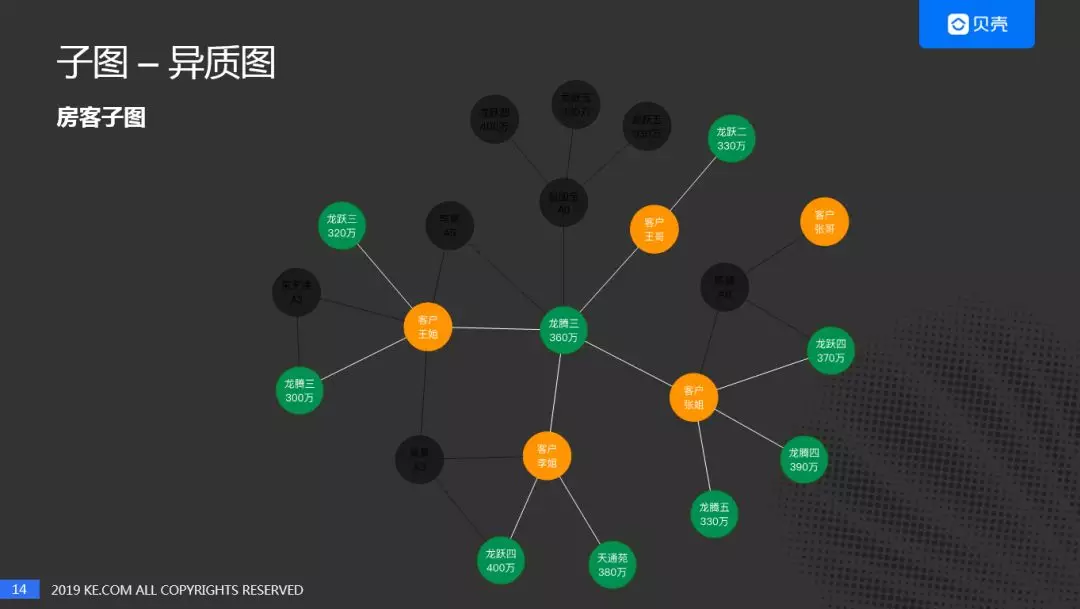
房客子图的抽取方法比较简单,就是我们图谱中的一部分,再加上关系量化的过程。
▌能力建设

基于子图谱的建设,我们进行了图谱能力的建设,主要介绍四种能力: 影响力、Embedding、相似、关系预测。 多度查询就是图数据库的查询,就不做专门介绍了;聚类在实际中暂时没有合适的落地场景,也不做介绍。
- 节点影响力
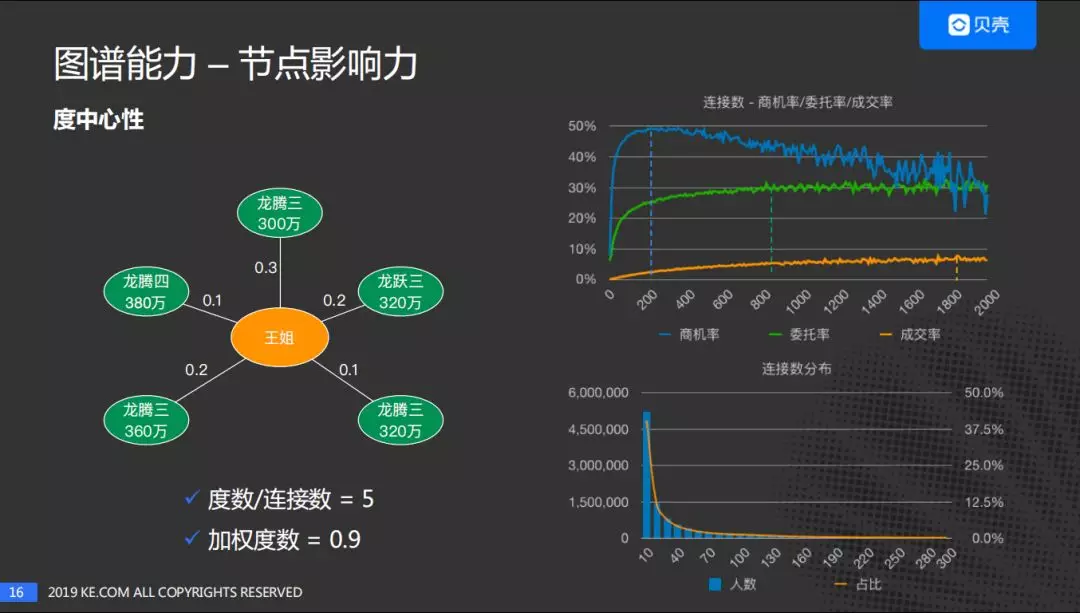
节点的影响力反应了节点的强度,我们采用了度中心性的办法。度中心性就是一个节点的度数/连接数/边数,当然,大家可也以选用 PageRank。我们以图中的"王姐"为例子,周围的边是 5 条,度数就是 5,加权度数就是考虑这些边的强度,对边的强度进行加和。
节点影响力的价值:
- 右上图,是连接数和转化率之间的关系。横坐标是连接数,纵坐标是转化率。可以看到连接数在一定范围内,连接数越大转化率越高。
- 右下图,连接数与客户数量关系分布图。可以看出大部分用户连接数比较低:40% 的用户,与房的连接数小于 10;大约 80% 的用户,与房的连接数小于 140。
从这两个数据可以看出:贝壳平台需要增加用户的连接数。增加连接数,可以增加用户的转化率。这也是贝壳平台需要做的事情,也是我们平台的价值。
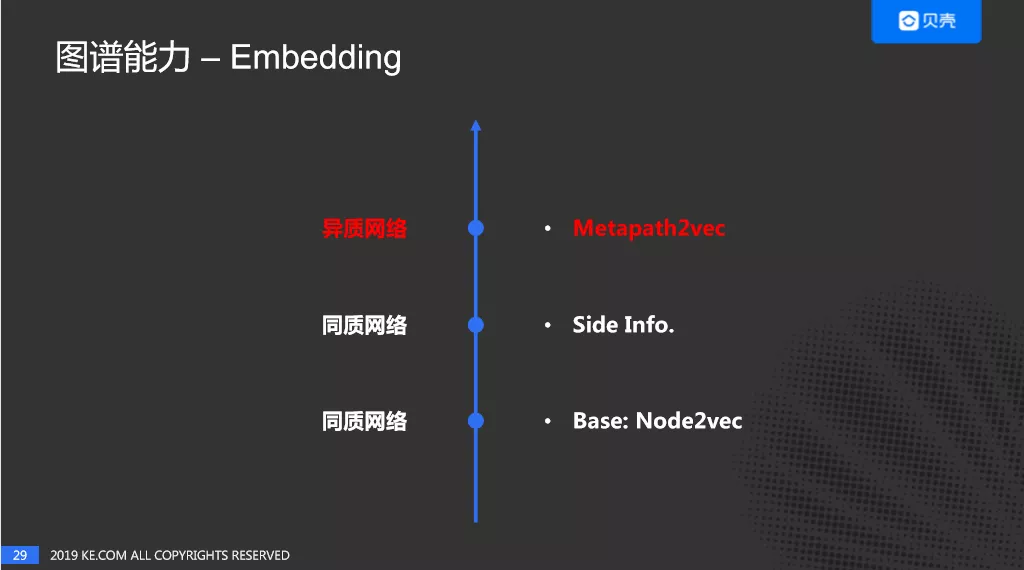
- Embedding
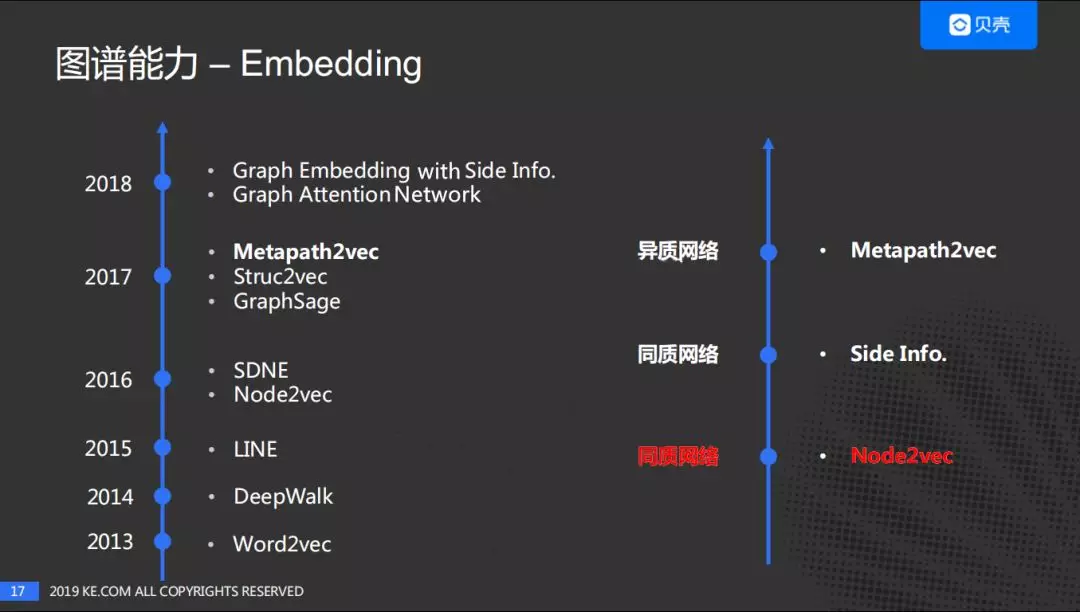
Graph Embedding 近年来发展迅速,在各大公司陆续开始应用,并取得了不错的效果。结合贝壳自身的情况,对于同质图的网络采用的是 Node2vec,并尝试使用 Side Info 来优化 Node2vec;针对异质图网络尝试使用 Metapath2vec。
① Node2vec
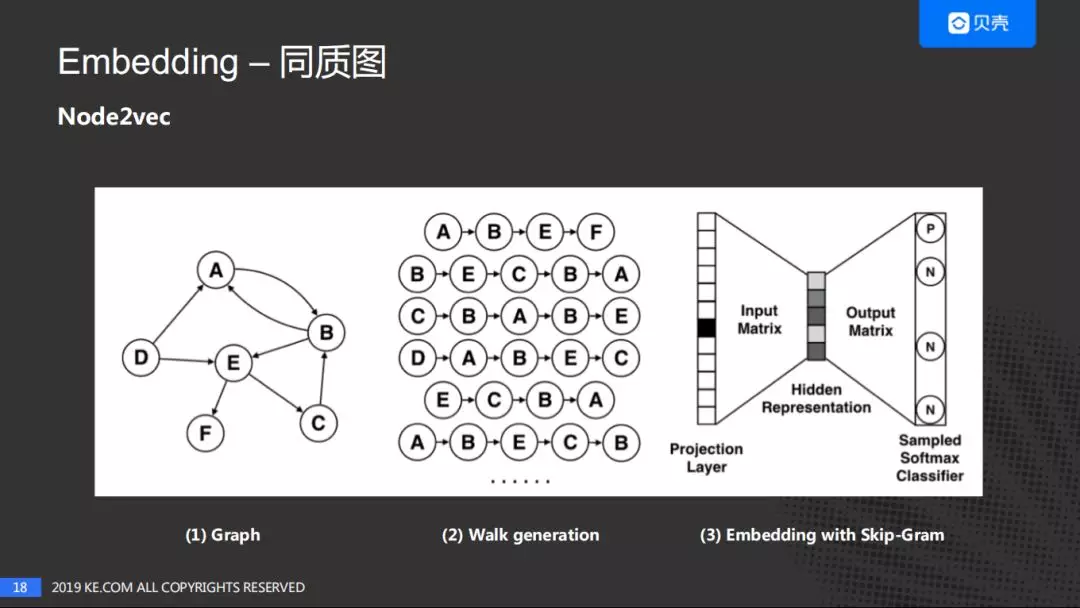
针对同质图网络的 Node2vec。对左边的房子图谱通过随机游走抽取序列,使用 Word2vec 进行量化。
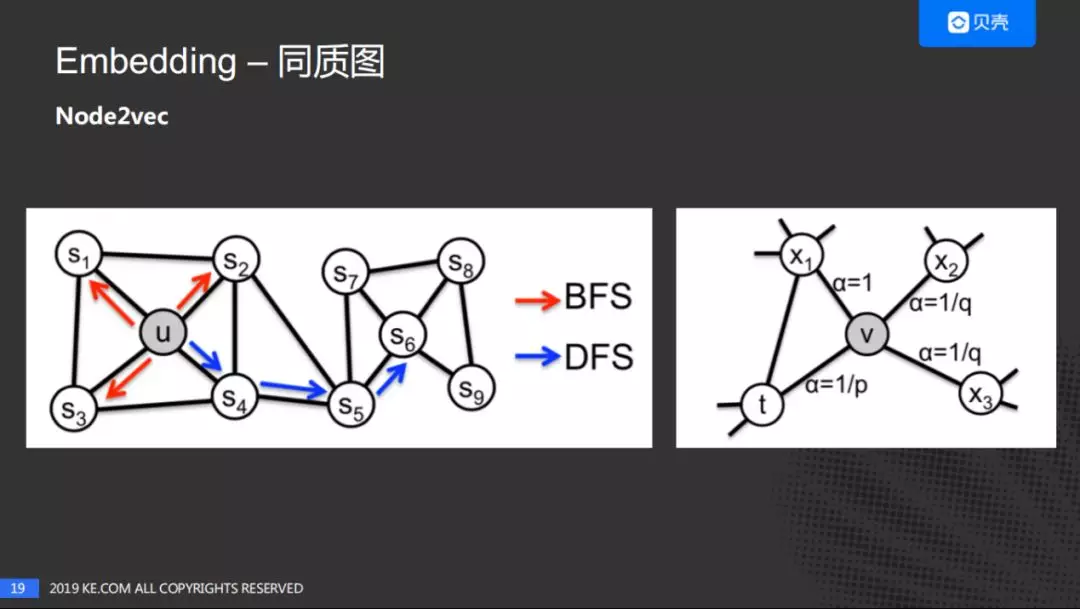
Node2vec 的核心优点是:平衡了深度优先搜索和广度优先搜索,通过 p 和 q 控制了下一跳的跳转概率,进而选择是深度的遍历还是广度的遍历。
如何进行效果的评估:

首先来回忆一下 Word Embedding 评估方法:通过词的语义判断词的相似性。例如:“would”,通过 Embedding 相似性得到 can,could,may,…是它的相似词,通过语义我们可以判断出来这些结果是相似的,这种 Embedding 的计算方法是有效的。
对于 House,如何判断房子是否相似?我们通过房子的特征来判断房源是否相似,可以从定性和定量两个角度进行评估。
从定性角度,采用数据可视化的方法。
从定量角度,采用了三种方法:
- 定义衡量相似度的指标
- 线下人工标注
- 线上 AB 实验
下面详细看下定性和定量的具体过程:

定性:
- 数据可视化分析,Embedding PCA 的降维。
定量:
- 衡量相似度的指标: 定义了一个房源相似度的分数,通过规则打分的方式判断房子是否相似。规则打分的计算逻辑:首先在核心维度上如房价、面积、区域来判断每个维度上的相似度。如距离维度,当两个房子的距离越近即可认为比较相似;当价格越近, 两个房子是相似的;最后,对不同维度进行加权求和,得到房子的相似度分数,分数越高即越相似,当然这也不是绝对的。
- 线下标注: 通过经纪人进行线下标注,标注房源是否相似。
- 线下 AB 实验: 转化为推荐的召回和排序策略。
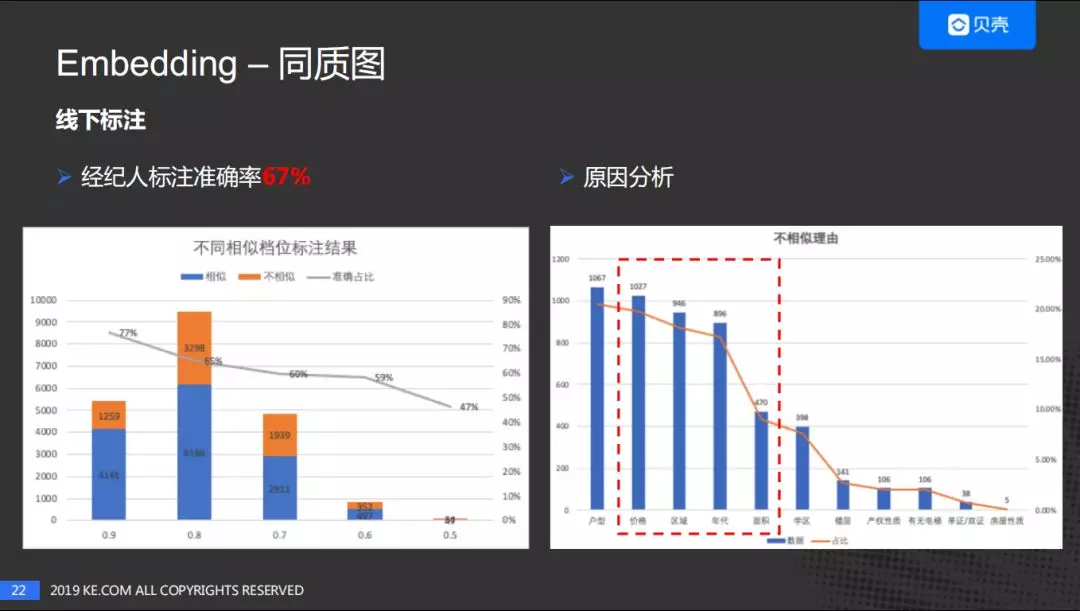
上图展示了 V1 版本经纪人对 Node2vec 线下标注的结果。我们考虑了不同种类的房子,包括高端房源、普通房源,也包括学区及远郊和市中心的房源,最终结果的准确率是 67%。左图是对不同标注挡位的标注结果进行的分析,横坐标是不同相似度的挡位,柱状图蓝色表示相似的数量,橙色表示不相似的数量,折线图表示对应的准确率。我们可以看到余弦相似度越高,房源相似度越高。
同时,我们还分析了经纪人给出的房源不相似的原因,横坐标表示不相符的原因,柱状图表示不相似的数量,折线图表示百分占比。我们可以看出不相似的原因比较集中,第二版使用 Side Info 来做优化,把房源的特征加入到模型当中,但是其中的户型图并没有加进来,因为户型图的覆盖量没有这么高并且户型图是难以量化的。
② Side Info
下面讨论一下 Side Info:
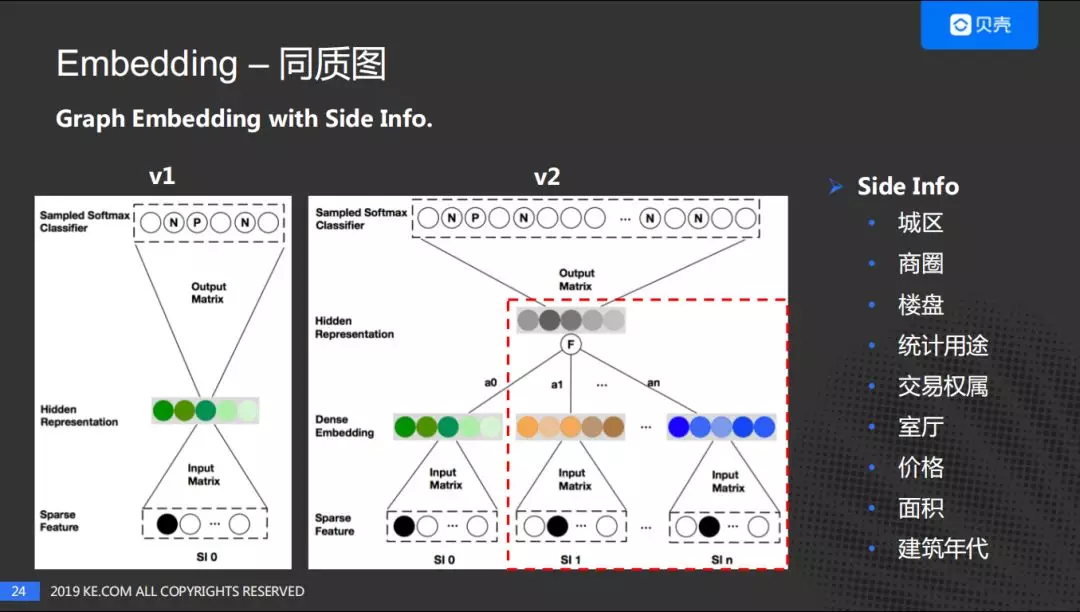
这是 2018 年阿里在 KDD 上的一篇文章,简单比较一下这两个方案:
V1 是 Node2Vec,V2 是 Graph Embedding with Side Info。两个图中的 SI0 是通过随机游走产生的房子序列,右边的 SI1 到 SIn 是房源的特征,进行 Embedding 之后再做一个平均。Side Info,基于经纪人帮助我们评估,我们采用了右边的九大维度。
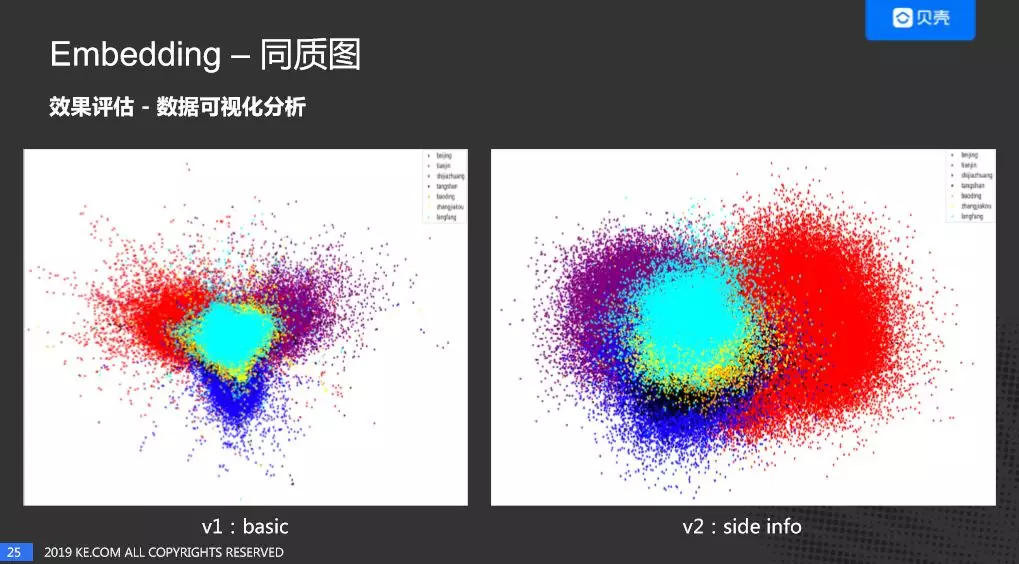
这是两个版本 PCA 降维之后的结果,每个颜色代表一个城市。可以看出来,Embedding 在不同的城市里面是有一定的聚集度的。同时也可以看出加入了房子特征之后的 V2 版本,效果比 V1 版本好很多。
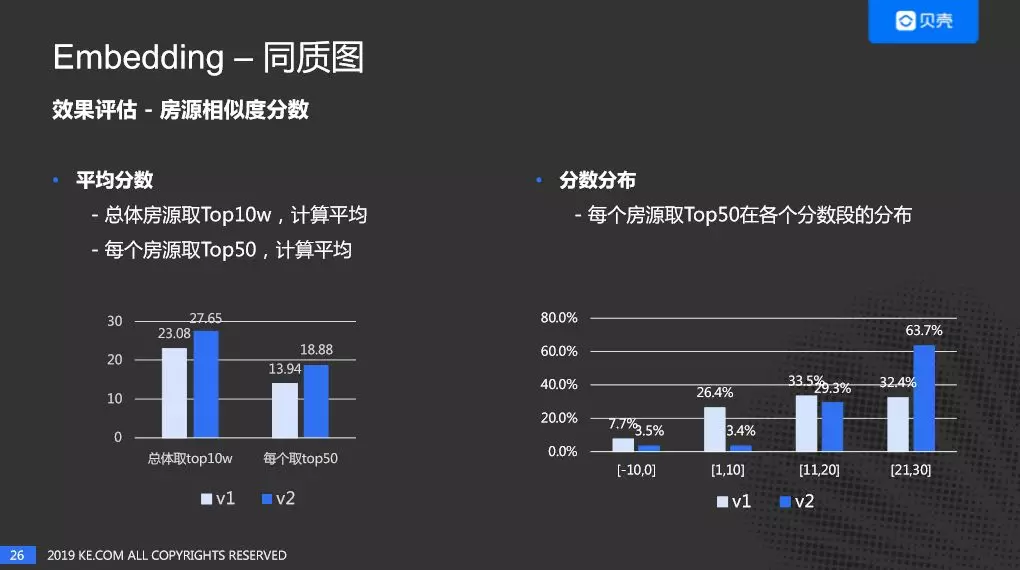
这是评估房源相似度分数的情况,左边是平均分数,从两个维度来考虑,第一个是把所有的房子两两之间计算它们的相似度,然后取 Top 10W,第二个是对每套房源取 Top 50。 通过左边的图表,我们可以看出 V2 的效果要明显好于 V1。右边的图是分数的分布,对每个房源取 Top 50,然后分析相似房源规则打分分数的分布,可以看出 V2 明显是分布在高分段之中。蓝色是 V2 版本,浅色是 V1 版本。
线上实验:
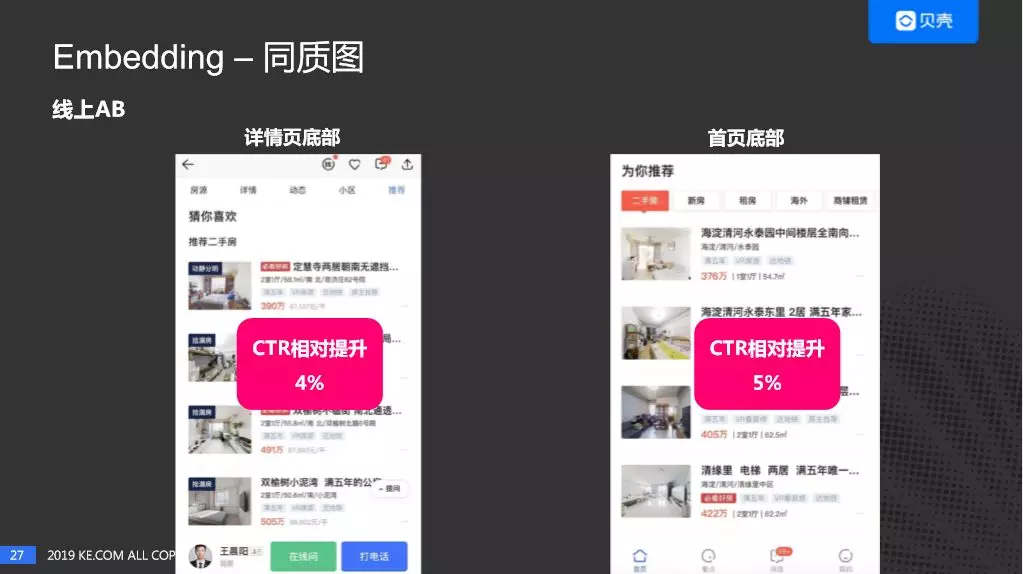
最后,我们进行了线上实验,在贝壳详情页的底部"猜你喜欢",还有首页的底部,“为你推荐"做了 AB 实验,在房源详情页面的底部 CTR 相对提升了 4%,在首页底部,相对提升了 5%。

有了房源 Embedding 之后,我们来计算下用户的 Embedding,有两种方式:第一种是基于用户行为的序列进行加权平均,第二种方式是基于异构网络。
我们通过一个示例,来分析如何通过用户行为序列进行 Embedding 计算:
首先,用户先后浏览了三套房源,然后进行向量化,最后进行加权平均,作为用户的 Embedding。在实际应用时,我们考虑了实时数据和时间衰减两个因素,最后应用在推荐,在贝壳 APP 首页的底部进行了 AB 实验,CTR 相对提升了 3%。
③ Metapath2vec
然后再来看下 Metapath2vec 的尝试:
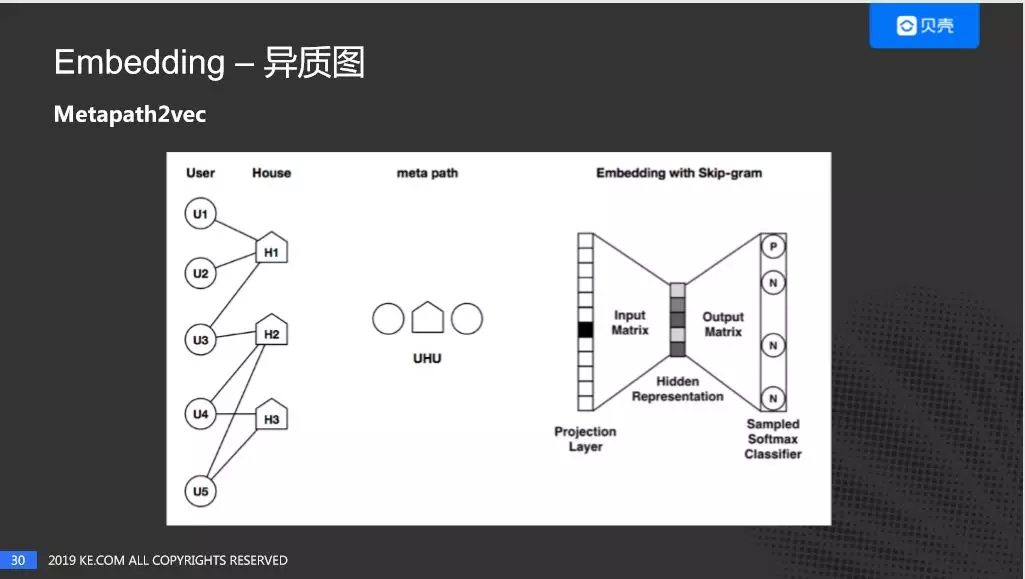
简单回顾一下 Metapath2vec 的原理,最左边是客房子图,中间是 metapath(我们是客房客),基于 metapath,对左边的客房子图进行随机游走,产生一个序列,最后通过 word2vec 对序列进行向量化。在构建房子图时,我们考虑了客户和房子之间的行为可以进行传播,假定用户的兴趣不变,我们取客户 30 天的行为,我们认为客户在这 30 天之内的兴趣是不变的。
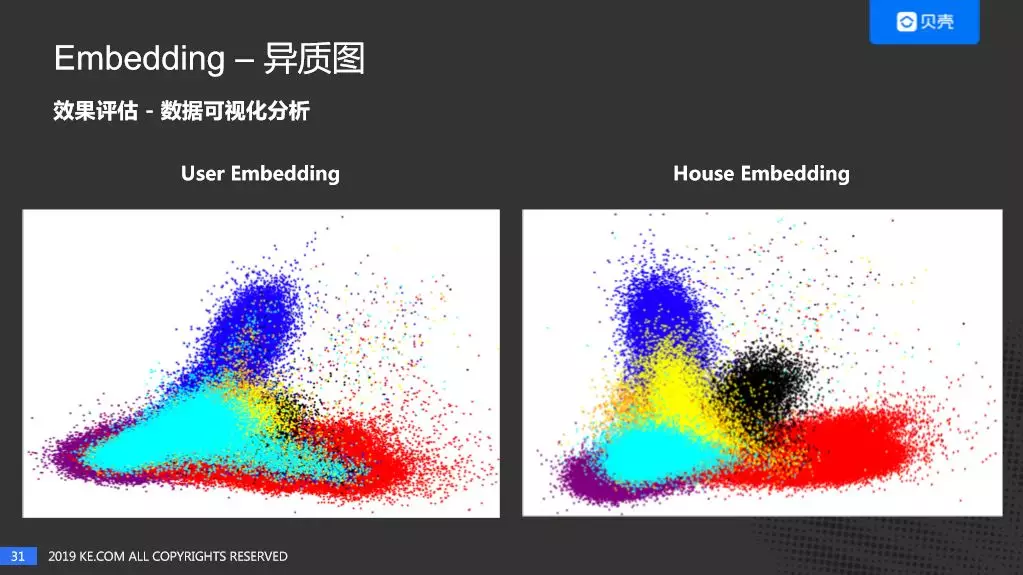
这是异质网络的 User Embedding 及 House Embedding PCA 降维后的结果。不同的颜色也代表不同的城市,我们可以看出来在不同城市也是有一定聚集度的。
- 关系预测
有了 Graph Embedding,我们如何进行关系的预测及推导呢?主要有两种方式:
- 第一种,基于相似房源或者相似用户,再结合关系强度来进行关系预测;
- 第二种,基于异构网络,User embedding 和 House Embedding。
① 基于相似房源 + 关系强度:
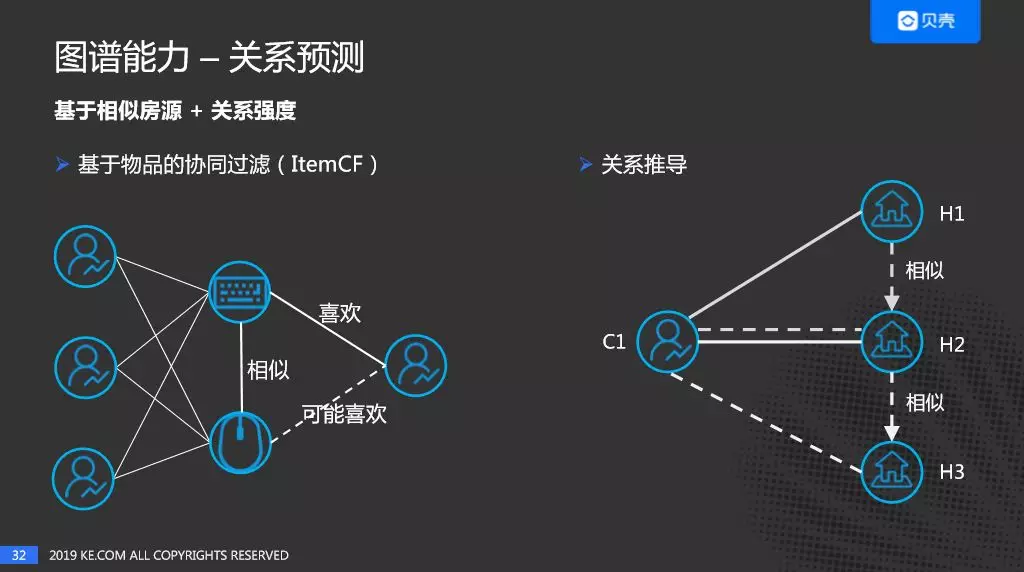
首先看下基于相似房源,首先回顾下基于物品的协同过滤原理:当多个用户同时喜欢两个物品时,我们认为这两个物品是相似的,当某个用户喜欢其中一个商品时,我们认为用户也可能喜欢另一个商品,这是协同过滤。我们来看下如何利用相似房源 + 关系强度进行关系推导:
用户 C1 分别对 H1 和 H2 产生过直接的行为关系,如果 H2 的相似房源是 H3,可以推导出 C1 和 H3 之间可以建立一个关系,关系强度 = 强度(C1 与 H2)* 相似度(H2 与 H3)。同样,如果 H1 的相似房源是 H2,C1 和 H2 之间可以叠加一个关系强度。
② 基于相似用户 + 关系强度:
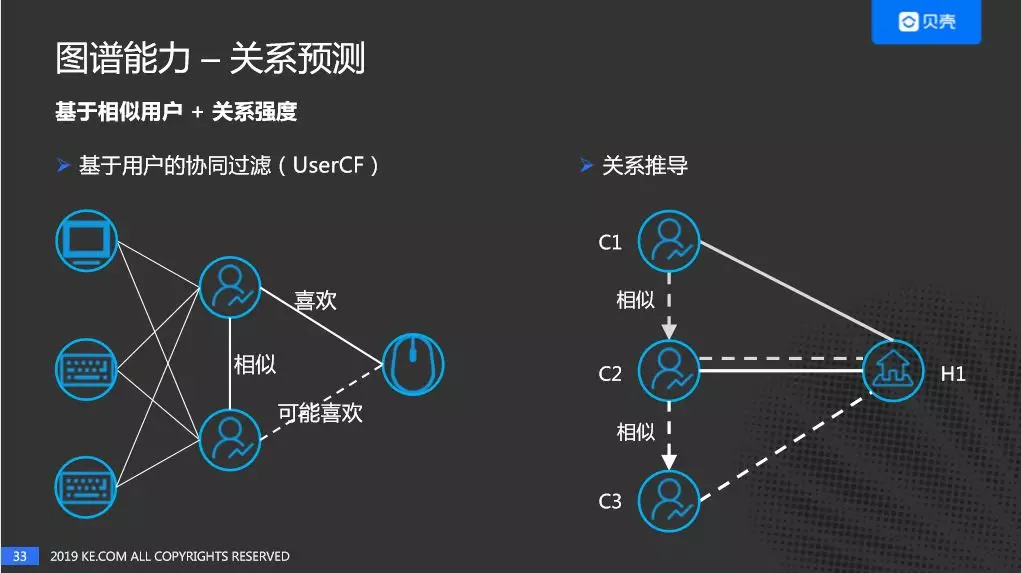
基于用户的协同过滤(UserCF)当两个用户同时喜欢多个商品时,我们认为这两个用户是相似的。如果某一个用户喜欢某一件商品,我们认为另一个用户可能也喜欢这个商品。
关系推导过程:
两个用户 C1 与 C2 分别和房源 H1 建立了直接的联系,C2 的相似用户是 C3,可以推导 C3 和 H1 之间可以建立一个关系。关系强度的计算方法同上。同样,C1 的相似用户是 C2,C1 与 H1 之间可以叠加一个关系强度。
③ 基于异质图
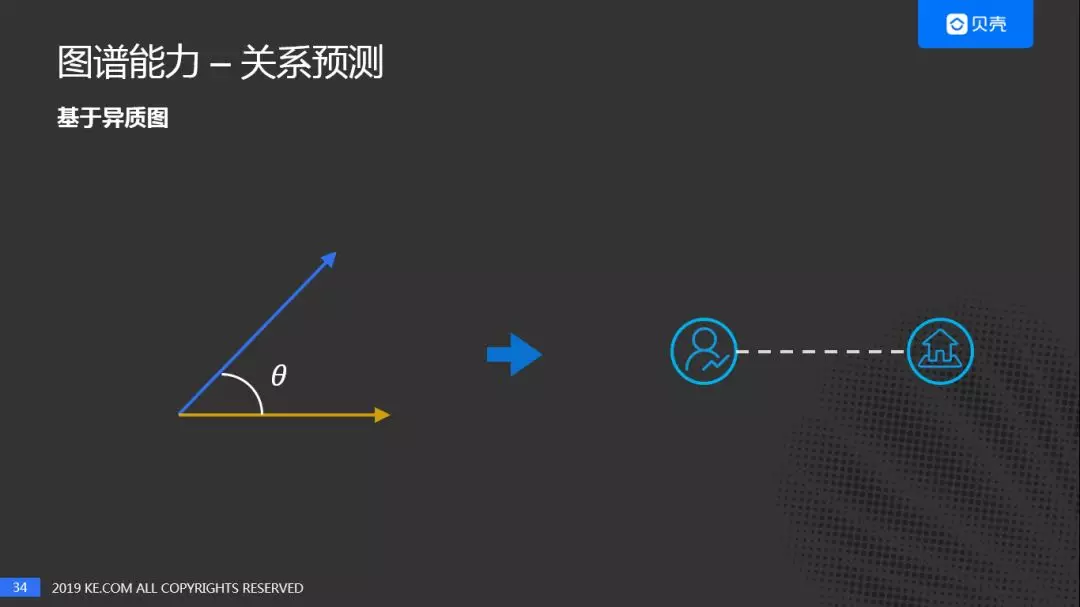
基于异质图的关系预测,直接计算用户和房源的余弦相似度,然后取 Top N,Top N 的房屋和用户就可以建立关系,关系的强度就是他们的余弦相似度。
- 小结
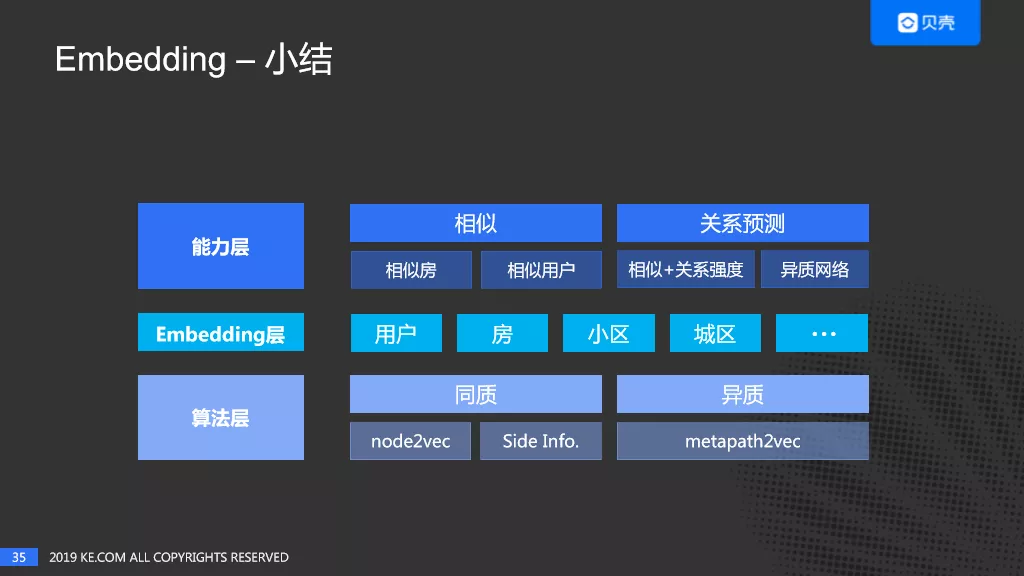
最后,对 Embedding 进行一个小结:
- 在算法层,对于同质图,尝试了 node2vec 及 side info;对于异质网络,我们尝试了 metapath2vec,另外,我们也在尝试一些其它的算法。
- 在 Embedding 层,我们有用户、房子、小区、城区等等的 Embedding。
- 在能力层可以做相似,如相似房,相似用户;同时,可以做关系预测,一个是基于相似 + 关系强度,一个是基于异质网络。
▌基础建设
最后,分享下贝壳在应用方面的探索。

我们主要从多度查询和向量化两个角度介绍:
多度查询:
- 房客通:是内部为经纪人和客户需求进行连接的产品。
- 挖掘图谱:也称为可视化图谱。
向量化:
- 相似
- 推荐
- 智能问答:把用户咨询的问题作为节点,通过用户的行为序列建立图谱。
- 多度查询

以房客通项目为例:当某个用户经常浏览关注或者咨询某�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%B4%9D%E5%A3%B3%E6%89%BE%E6%88%BF%E5%85%B3%E7%B3%BB%E5%9B%BE%E8%B0%B1%E5%9C%A8%E8%B4%9D%E5%A3%B3%E7%9A%84%E6%9E%84%E5%BB%BA%E5%92%8C%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


