详解支撑亿用户搜索的百度图片处理收录中台
内容来源:百度Geek说 作者: imazon

导读: 在百度搜索中,主要由“搜索在线”和“搜索离线”两部分构成,“在线”服务主要用于响应用户请求,“离线”服务则将各种来源的数据转换处理后送入“在线”服务中。“搜索离线”的数据处理是一个典型的海量数据批次/实时计算结合的场景。
一、多模态检索背后的”离线“与“在线”
在百度搜索中,主要由“搜索在线”和“搜索离线”部分构成,“在线”服务主要用于响应用户请求,“离线”服务则将各种来源的数据转换处理后送入“在线”服务中。“搜索离线”的数据处理是一个典型的海量数据批次/实时计算结合的场景。
2015年起,百度App上线了多模态检索能力,将智能化搜索直观体现在用户面前。多模态检索是在传统文本检索之上,增加了视觉检索和语音检索的能力。

其中,“视觉检索”和“文本检索图片”这两类业务的离线、在线技术上,有很多地方是共通的。以视觉检索为例,产品形态包括:猜词、更多尺寸图片、图片来源、垂类图片(短视频、商品、等)、相似推荐等,其背后依托的核心技术有分类(GPU在线模型预估)与ann检索。

在ann检索方面,目前主要采用的检索方法有基于聚类的gno-imi、基于图的hnsw,以及局部敏感hash方法,选型的主要考虑是技术方案成本与特征的适用性,比如gno-imi是百度内开源的,内存占用比较小的方案,应用到百亿规模的ann检索上成本可接受;局部敏感hash的方法,应用到SIFT这类局部特征上,可以加强手机拍照识别场景下召回效果。
这些在线技术的背后,依赖的特征有百余种,离线要收录全网图片,并对图片计算特征,其算力开销是非常庞大的;另外,图片在互联网上依附于网页,还需要维护“图片-图片链接-网页链接”的关系(离线数据处理、在线应用都离不开数据关系,比如为了溯源,需要提供图片的来源网页url等)。
此种情况下,搜索架构部与内容技术架构部依据自身业务与技术特点,联合设计与开发了“图片处理收录中台”,以期达到以下目的:
- 统一的数据获取与处理能力,可整合图片类业务的数据获取、处理、存储逻辑,提升人效,降低存储&计算成本。
- 百亿~千亿级别的图片应用,可实现快速调研、数据采集、全网数据更新能力。
- 建设图片实时筛选与定制下发数据通路,提升图片资源引入的时效性。
该项目在内部名为Imazon项目。Imazon来自于Image + Amazon,其中amazon代表中台能力的吞吐能力、DAG处理能力、图片容量。
目前,图片处理收录中台,提供复杂业务场景下单日处理数十亿级图片数据,秒级实时收录百gps,全网收录万级别gps。平台目前支持多个业务线的图片处理与收录需求,大幅提高了业务执行效率。
二、图片处理收 录中台的架构与关键技术
搜索效果的持续优化,离不开数据与算力,主要以收录,存储,计算为核心。图片处理收录中台,希望通过中台提供的通用能力包括:从时效、全网图片收录通路中筛选数据、提供大吞吐的流式处理机制、图片-网页关系刻画能力、原图&缩图存储、在线处理机制等。
2.1 图片处理收录中台解决什么问题?
图片处理收录中台的主体流程,经历6个阶段:网页spider(获取网页内容),图片内容提取,图片spider(爬取图片),特征计算(百余种特征),内容关系存储,建库。如下图所示:

2.2 图片处理收录中台的技术指标
中台的技术指标定义,从架构指标、效果、研发效率3方面来描述。
架构指标包括吞吐、扩展性、稳定性:
- 吞吐,即在成本限制内,提高吞吐,具体指标为:单数据大小:百K bytes(图片+特征);实时收录 百qps;全网收录万级别qps
- 扩展性,即云原生部署、算力资源弹性调度,有资源时快点算,没资源时慢点算。
- 稳定性,即不丢数据,自动重试,自动回放;时效性数据分钟级处理成功率;全网数据天级处理成功率
效果指标主要关注数据关系:
- 真实的图片-网页链接关系(e.g. 网页/图片退场了,关系更新)
研发效率指标包括业务通用性和语言灵活性:
- 业务通用性:支撑依赖全网图片的业务获取数据;特征迭代
- 语言灵活性:C++&go&php
2.3 图片处理收录中台的架构设计
图片处理收录是一个无界数据的流式处理过程,因此整体架构设计以流式实时处理系统为主,兼支持批处理输入。同时,为了解决大吞吐需求、业务研发效率等问题,设计中采用了弹性计算&事件驱动、业务逻辑与DAG框架解耦部署等思想。具体如下图所示,后文会详细讲解。
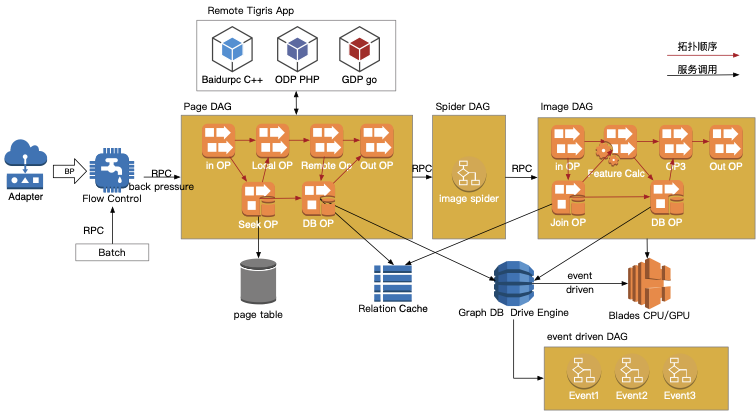
2.4 图片处理收录中台的基础设施
百度基础设施:
- 存储:table、bdrp(redis)、undb、bos
- 消息队列:bigpipe
- 服务框架:baidurpc、GDP(go)、ODP(php)
依托&构建的业务基础设施
- Pipeline调度:odyssey,支撑架构全景中的各DAG
- 流控系统:在核心入口层,提供均衡流量、调节流量的能力
- 千仞:托管/调度/路由 百~千类上万实例的cpu/gpu算子
- 内容关系引擎:刻画图-网页关系,基于事件驱动计算,与blades联动弹性调度
- 离线微服务组件:Tigris,DAG节点的具体业务逻辑放到远程RPC中执行
三、优化实践
下面简单介绍在面向大吞吐高算力场景下,中台的一些优化实践。
3.1 大吞吐流式处理架构的实践
成本(算力、存储)是有限的,面对大吞吐需求,在如下方向做了针对性优化:
- 消息队列成本高
- 流量毛刺、波峰波谷带来的资源利用率不足
- 算力不够带来的数据堆积
3.1.1 消息队列成本优化
在离线流式数据处理中,通过消息队列在DAG/pipeline中传输数据是比较常规的方案,该方案可以借助消息队列的持久化来保证业务对数据的不丢的要求(at least once)。业务特点:
- Pipeline/DAG中的传输的是图片及其特征,百K bytes,消息队列的成本比较高昂
- 下游算子,不一定需要所有数据,通过message queue透传所有字段性价比低
具体优化思路如下:
- DAG中message queue传引用(trigger msg),DAG中算子的输出存储到旁路cache
- 旁路cache的高吞吐低成本优化,利用DAG中数据的生命周期,主动删除&脏写优化
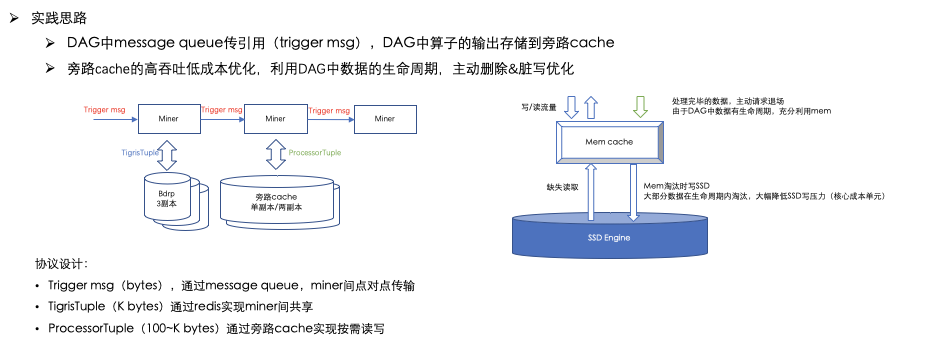
具体协议设计为:
- Trigger msg(bytes),通过message queue,miner间点对点传输
- TigrisTuple(100K~ bytes)通过redis实现miner间共享
- ProcessorTuple(M~ bytes)通过旁路cache实现按需读写
3.1.2 流量均衡与波峰滞后计算
入口流量的波峰波谷或毛刺,使得全系统必须按照峰值容量部署,但是低峰期资源利用率又不够。如下图:

具体优化思路如下:
通过反压/流控机制,在资源恒定的前提下,将系统的总吞吐最大化
- 流控系统平滑流量,减少均值与峰值的gap,使得全系统各模块的“容量利用率”稳定维持在高位
- DAG/pipeline具备反压能力,当局部模块容量不足,反压到流控模块,流控模块自适应调节,波峰数据滞后到波谷计算
- 为解决业务上不可接受的数据滞后,区分数据优先级,保证高优数据优先分发(全系统的吞吐设计至少cover高优数据的吞吐)
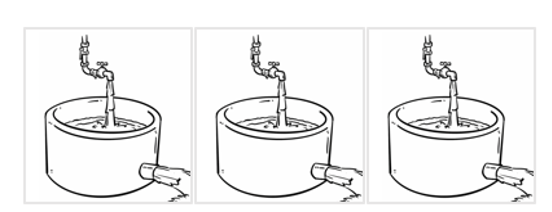
△图3 3个优先级的流控
3.1.3 解决大吞吐场景下算力临时不够带来的数据堆积
全网数据收录场景下,特征计算存在GPU资源瓶颈,这些特征消耗的GPU卡非常巨大,可以通过“错峰”与“离在线混布、临时资源使用”等思路可以解决该问题,但是引入了新问题:离线pipeline中无法buffer这么多的数据,且不希望反压影响上游DAG处理吞吐
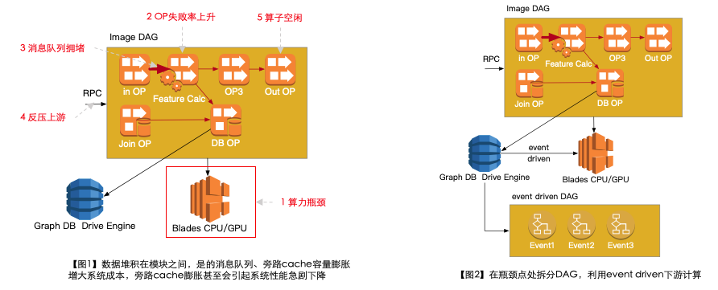
具体优化思路:
- 分析瓶颈点, 拆分DAG;利用存储DB作为“天然的流控”系统,事件驱动(弹性调度计算特征、特征就位触发调度下游DAG)。
3.2 内容关系引擎
互联网的图片内容关系,可以用一个三部图来刻画。采用下面的概念定义进行描述:
- f:fromurl,代表网页,f下有多个o。f纬度的特征:title、page type等
- o:objurl,代表图片链接,一个o只能指向一张图片。o纬度的特征:死链
- c:图片content sign,图片内容的签名,代表图片。c纬度的特征:图片内容、ocr、清晰度、人物,等
- fo:网页与图片链接的边。边的特征:图片上下文、alt
- oc:图片链接与图片的边。边的特征:图片爬取时间
内容关系引擎,需要能够刻画如下行为:
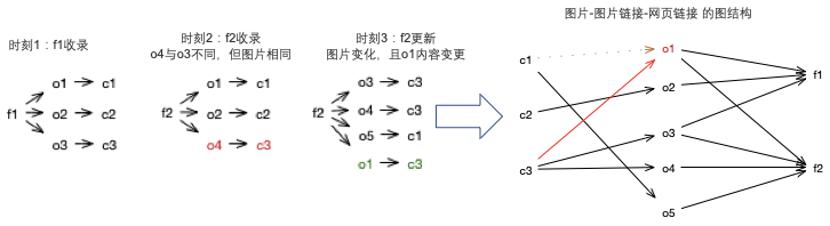
为刻画互联网中各元素完整关系描述,这是一个千亿节点规模,P级别存储的图数据库,需要达成的系统指标如下:
- 写性能:
- vertex:万级别qps,单节点属性(100~K bytes)
- edge:十万级别qps
- 读性能(全量筛选、特征迭代):
- 导出的点、边属性信息(scan吞吐需求:G bytes/s)
为了解决读写性能问题,基于table设计了COF三部图内容关系引擎,核心设计思路如下:
- C表采用前缀hash做数据划分,保证scan的顺序性,并读到完整关系(c来源于哪些o,o来源于哪些f),P级存储
- O表采用SSD机制,支持查O对应的C
- F表采用SSD介质,提高随机读性能;保存反向映射关系,支持通过F查找O与C

为减少随机写带来的IO瓶颈、降低系统事务复杂性,采用了“基于版本的校验方法,读时校验,异步退场”来保证关系的正确性。
3.3 其他实践
为提升业务研发迭代效率、提升系统自身维护性,系统解决了一些问题,但是在提升“研发幸福感”的路上,才刚刚上路。我们着重解决研发效率和维护成本的问题。
比如在业务接入效率方面:
数据源复用
- Problem:10个业务的数据,有10种格式,proto嵌入太多,看不懂
- Try:从异构schema=>标准schema;OP的input/output管理
DAG 产出复用
- Problem:不能影响上游的DAG处理吞吐和速度。
- Try:DAG rpc串联,解决级联阻塞;DAG原生衔接,数据生存周期问题, copy on write&erase
资源存储复用:
- Problem:我用了他产生缩图,但是这个缩图现在打不开了!什么,原图也被删了?
- Try:多租户机制,引用计数退场,cdn统一接入、在线统一智能裁剪与压缩
在多语言支持方面:
- Problem:
- 想用C++/Python/PHP/go,框架兼容复杂!速度慢了,谁的问题?
- 我只实现一个业务逻辑就行了,不想关心DAG的太多细节
- Try:
- DAG框架语言统一,通过远程rpc隔离业务实现
- Rpc Echo(trigger msg[in], t
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%AF%A6%E8%A7%A3%E6%94%AF%E6%92%91%E4%BA%BF%E7%94%A8%E6%88%B7%E6%90%9C%E7%B4%A2%E7%9A%84%E7%99%BE%E5%BA%A6%E5%9B%BE%E7%89%87%E5%A4%84%E7%90%86%E6%94%B6%E5%BD%95%E4%B8%AD%E5%8F%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


