论文笔记结合叶节点嵌入的可解释推荐模型
“ 本文主要介绍了发表在 WWW2018 的论文《TEM: Tree-enhanced Embedding Model for Explainable Recommendation》,利用 GBDT 叶子节点进行嵌入表示来获得一个具有解释性的推荐模型”
本文来源:RecLismCat https://zhuanlan.zhihu.com/p/96124874

3 TREE-ENHANCED EMBEDDING METHOD
首先提出 TEM,它结合 MF 用于稀疏数据建模和 GBDTs 用于交叉特征学习的优点。还讨论了可解释性,分析了其复杂性。
3.1 Predictive Model
给定一个 user u ,一个 item i,和他们的特征向量
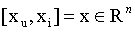
将它们作为输入,TEM 预测 user-Item 偏好:
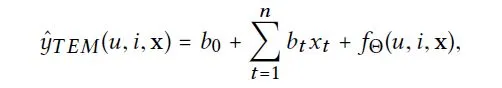
其中,前两项是与 FM 相似的特征偏差,第三项是 TEM 的核心部分。参数Θ用于建模交叉特征影响。
3.1.1 Constructing Cross Features
与在学习过程中不透明地捕捉交叉特征效应的嵌入式方法不同,我们最初的考虑是让交叉特征是显式的并且是可解释的。在工业中广泛使用的一种解决方案是手工制作交叉特性,然后将它们输入一个可解释的方法,该方法可以了解每个交叉特性的重要性,例如逻辑回归。例如,我们可以通过交叉特征变量 age 和 traveler style 的所有值来获得二阶交叉特征。但是,这种方法的难点在于它是不可伸缩的。为了对高阶特征交互进行建模,必须将多个特征变量交叉在一起,从而导致复杂性呈指数级增长。虽然通过谨慎的特征工程,如跨越重要的变量或值,可以在一定程度上控制复杂性,但开发有效的解决方案需要大量的领域知识,不容易适应领域。
为了避免这种劳动密集型的特性工程,我们利用 GBDT(在 2.2 节中简要介绍)来自动识别有用的交叉特性。虽然 GBDT 并不是专门为提取交叉特征而设计的,但是考虑到一个叶节点代表一个交叉特征,并且树是通过优化对历史交互作用的预测来构建的,因此认为叶节点是有用的交叉特征是合理的。
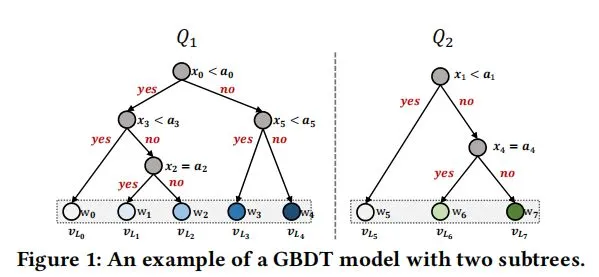
形式上,我们定义 GBDT 为一系列决策树 Q={Q1,Q2,…,Qs},其中,每一棵树将一个特征向量 x 映射到一个叶子节点上(有权重)。我们使用 Ls 定义第 s 棵树的叶子节点的数量。与原始的将激活的叶节点的权值累加作为预测的 GBDT 不同,我们将激活的叶节点作为交叉特征,并将其输入神经注意模型中进行更有效的学习。我们将交叉特征表示为一个多热向量 q,它是多个单热向量(其中一个单热向量编码树的激活叶节点)的串联:
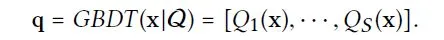
这里 q 是一个稀疏向量,其中值为 1 的元素表示激活的叶节点,q 中的非零元素数量为 S。
设 q 的大小为
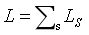
- 。例如,在图一中,有两个子树 Q1(有五个叶子节点)和 Q2(有三个叶子节点)。如果 x 分别以 Q1 和 Q2 的第二和第三叶节点结束,那么得到的多热向量 q 应该是[0,1,0,0,0,0,0,1]。令图 1 中的特征变量(x0
- x5)和值(a0 ~ a5)的语义被列在表 1 中,那么 q 表示从 x 中提取的两个交叉特征。
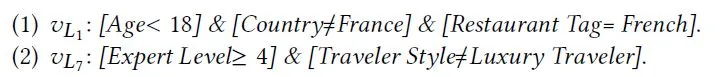
3.1.2 Prediction with Cross Features
利用显式交叉特征,我们利用稀疏线性方法学习各交叉特征的重要性,选择最上面的交叉特征作为预测的解释。Facebook[22]之前的工作已经证明了这种解决方案的有效性,它将 GBDT 的叶节点输入到逻辑回归(logistic regression, LR)模型中。我们把这个解称为 GBDT+LR。虽然 GBDT+LR 能够学习交叉特征的重要性,但它为所有用户- 项目对的预测分配了相同的交叉特征权重,这限制了建模的保真度。在实际应用中,具有相似人口统计特征的用户通常会选择相似的项目,但是它们是由不同的意图或原因驱动的。
例如,设(u, i, x)和(u’, i’, x’)是两个正的实例。假设 x 等于 x’,那么这两个实例将具有与 GBDT 相同的交叉特征。由于每个交叉特征都有一个全局权重,与 LR 中的训练实例无关,预测的(u, i)和(u’, i’)将被视为同一顶交特性,不管实际的可能性原因中 u 选择 i,u 选择 i’是不同的。为了确保可表达性,我们认为对不同的用户- 项目对交叉特征进行不同的评分是很重要的。在交叉特征上个性化权重,而不是使用全局加权机制。
神经推荐模型如 Wide&Deep 和 NFM 的最新进展可以允许交叉特征的重要性变得个性化。这是通过将 user ID、item ID 和交叉特征一起嵌入到共享的嵌入空间中,然后对嵌入向量执行非线性转换(例如,通过完全连接的层)来实现的。非线性隐含层强大的表示能力使得 user ID、item ID 和交叉特征之间的复杂交互能够被捕获。因此,当使用不同的用户- 项目对进行预测时,交叉特性的影响是不同的。然而,由于难以解释的非线性隐含层,这些方法无法解释交叉特征的个性化权重。因此,为了便于解释,我们必须放弃使用完全连接的隐藏层,尽管它们在现有方法中有助于模型的性能。
为了开发一种既有效又可解释的方法,我们介绍了 TEM 中的嵌入和注意力的两个基本成分。具体来说,我们首先将每个交叉特征与一个嵌入向量相关联,这样就可以捕获交叉特征之间的相关性。然后,我们设计了一种注意力机制,明确地对交叉特征上的个性化权重进行建模。最后,将用户 ID、项目 ID 和交叉特征的嵌入集成在一起进行最终预测。虽然 TEM 是一种浅层模型,没有完全连通的隐层,但利用嵌入和注意使其具有很强的表示能力和有效性。接下来,我们将阐述 TEM 的两个关键组成部分。
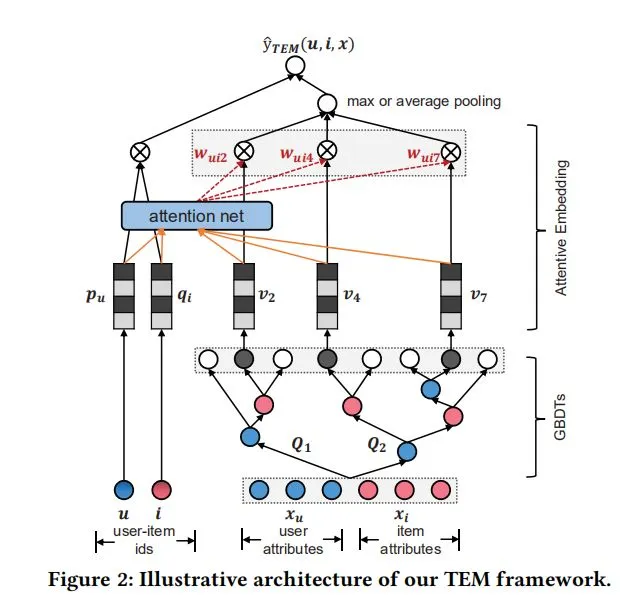
嵌入
给定由 GBDT 生成的交叉特征 q,我们将每一个交叉特征 j 投影都嵌入项链
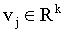
,其中 k 是嵌入尺寸。在这个操作之后,我们获得了一个嵌入向量集合
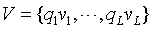
。由于 q 是一个只有少量非零元素的稀疏向量,我们只需要在预测中包含非零特征的嵌入,也就是说
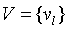
,其中,
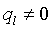
。我们使用 Pu 和 qi 来定义用户嵌入和物品嵌入。
与 LR 使用标量对特征进行加权相比,将交叉特征嵌入到向量空间有两个优点。首先,使用嵌入学习可以捕获特性之间的相关性,例如,经常同时出现的特性可能产生类似的嵌入,这可以缓解数据稀疏性问题。其次,它提供了一种将 GBDT 的输出与基于嵌入式的协同过滤无缝集成的方法,这比模型预测的后期融合更灵活(例如,在[49]中使用 FM 来增强 GBDT)。
注意力
受之前工作的启发[9,46],我们通过为每个交叉特征的嵌入分配一个关注的权重,明确地捕获了交叉特征在预测中的不同重要性。在这里,我们考虑两种方法来聚合交叉特征的嵌入,平均池化和最大池化,以获得一个统一的表示 e(u, i,V)的交叉特征:
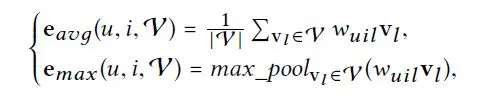
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%AE%BA%E6%96%87%E7%AC%94%E8%AE%B0%E7%BB%93%E5%90%88%E5%8F%B6%E8%8A%82%E7%82%B9%E5%B5%8C%E5%85%A5%E7%9A%84%E5%8F%AF%E8%A7%A3%E9%87%8A%E6%8E%A8%E8%8D%90%E6%A8%A1%E5%9E%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


