袁腾飞阿里飞猪信息流内容推荐探索

分享嘉宾:袁腾飞 阿里巴巴 算法专家
编辑整理:赵二白
出品平台:DataFunSummit
导读: 飞猪信息流的业务场景是架设在飞猪首页里面的猜你喜欢模块,其本质是一个多物料混排场景,包括内容和商品,本次的分享主要是介绍内容推荐在旅行场景的一些探索及实践。
主要有如下三部分:
- 飞猪信息流业务简介
- 飞猪内容推荐探索
- 内容流量机制设计
01 飞猪信息流业务简介
1. 飞猪信息流简介
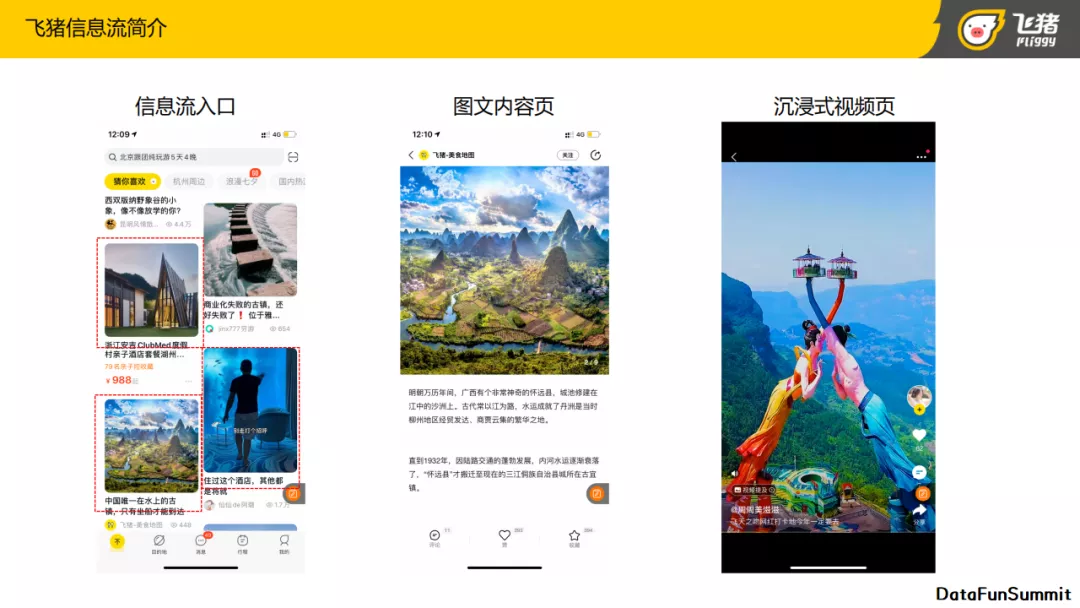
首先来看一下飞猪的信息流业务简介。
由上图所示,飞猪信息流的入口位于飞猪首页里的猜你喜欢模块,里面涵盖了很多种类的物料,如视频内容、图文内容、商品、广告、POI主题等。上图展示了比较常见的内容种类:图文内容,以及视频沉浸页。
2. 飞猪信息流技术框架
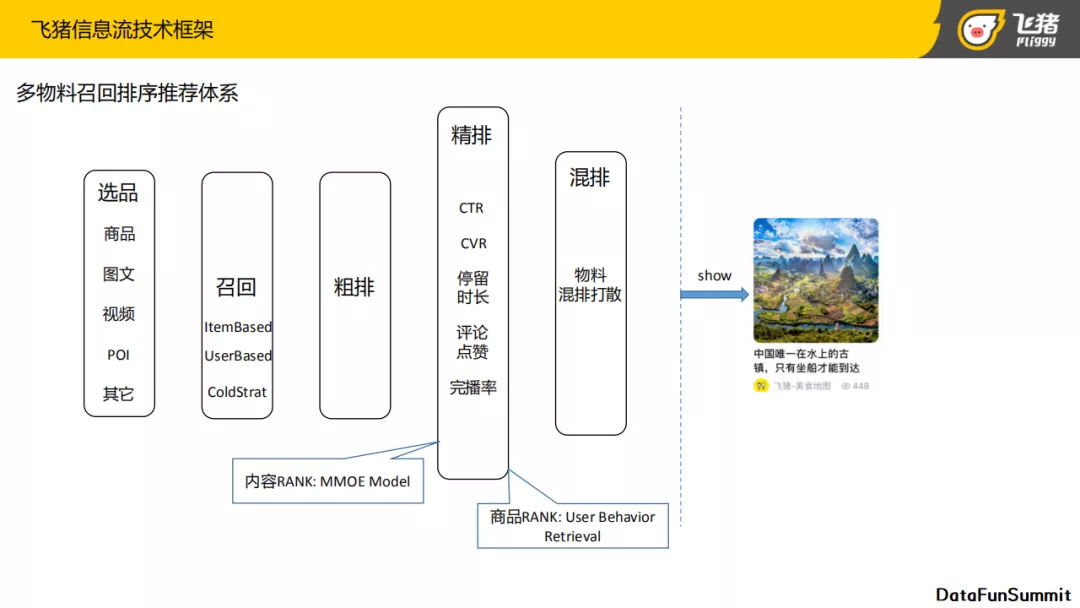
上图为目前信息流使用的技术框架,从左到右有如下几个重要模块:
- 选品: 因为线上的物料类型丰富,不同类型的物料会设定不同的准入门槛,所以选品模块会添加选优判断等逻辑。
- 召回: 主要分成三个部分,Item-base的召回,User-base的召回,还有今天主要会讲的冷启动的召回。
- 粗排: 因为召回物料的量比较大,所以在精排前还要加上粗排做第一轮的初筛。在今天介绍的内容推荐的粗排里,会介绍一些粗排中的特殊的策略,比如:时效截断,粗排中冷启动的策略等。
- 精排: 应用了多目标建模。不同的物料,其侧重点也会不一样。比如商品和内容,在商品的精排里,主要对CTR与CVR进行多目标建模。而对内容的话,主要会去考虑CTR,停留时长,点赞,完播率等目标。接下来也会详细介绍一下内容推荐的排序模型,目前应用了 MMoE 模型。而商品推荐的排序模型使用了用户行为序列建模。
- 混排: 主要目的是将多物料进行打散,因为整个选品池里物料类型比较多,在最终展现给用户时,需要有一些业务逻辑来控制。比如不同物料的流量比例,不同物料之间的互斥规则,打散规则等。因为我们使用了精排的预估结果作为特征去构建混排模型,所以混排模型是一个比较轻量级的模型。接下来也会详细介绍一下关于混排的设计。
3. 内容投放链路
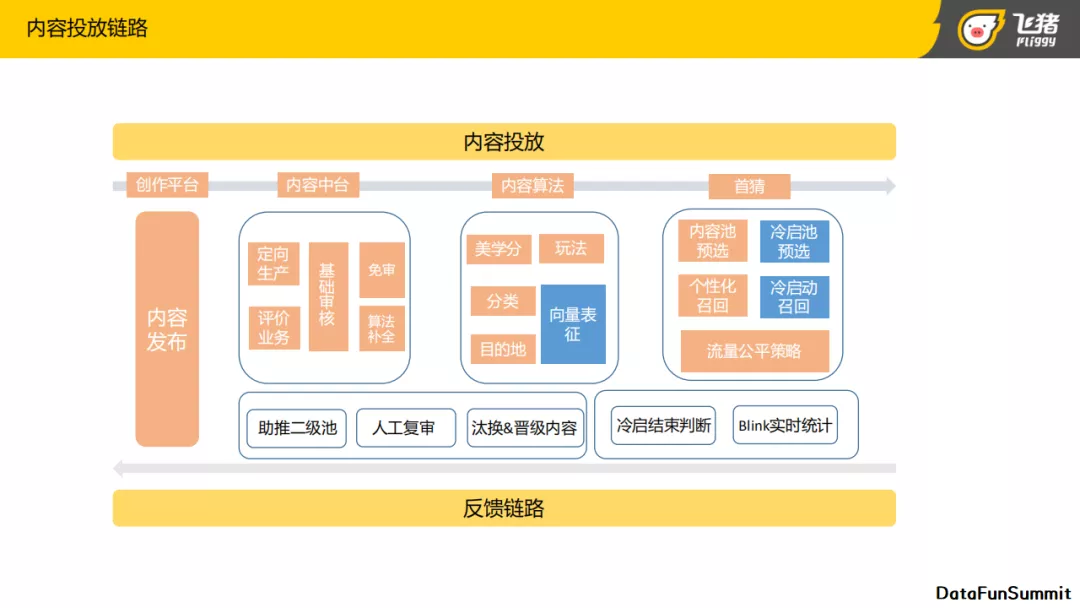
上面介绍的信息流推荐的框架是包含商品和内容的,现在我们来看下内容投放链路,分为内容投放以及反馈链路,内容投放所涉及到的模块从左到右依次是:
- 创作平台: 进行内容发布。
- 内容中台: 内容中台主要负责从相应渠道取得相应的内容,内容的审核以及内容标签的补全等工作。内容中台里有两个重点渠道:一个是基于大号达人做的不同城市玩法的内容定向生产,一个是基于飞猪域内和阿里域内的评价业务。由于目前创作发布平台不是很完善,整个内容平台里的内容属性会有缺失,所以在内容中台里有一个审核模块,其会结合内容中台算法会去做一些联动,算法会对审核模块提供补全数据,使审核的效率得到提高。
- 内容算法: 内容算法主要负责搭建内容分类体系,内容质量的筛选以及构建内容向量表征。
- 首猜分发池: 包含内容的预选,召回,流量公平策略,排序等模块。整个内容预选和召回单独拆成了两条路,一个是冷启动内容池的预选和召回,另一个是全量内容池的预选和召回。因为内容对时效性要求很高,旅行类的内容线上更替和生存期都会比较短,所以新内容需要快速曝光,快速启动,内容需要面临更多的冷启动的问题。
在反馈链路中制定了一套针对冷启动的策略,在对新内容进行筛选之后进行EE探索以及设置探索结束条件。在探索结束之后,会基于线上feedback返回的特征去判断内容是否适合继续在线上存活,或者是否要更多的流量激励。对于一些不合适的内容,进行汰换下线。汰换下线之后,需要接入业务的人工复审模块,再次确定这个内容是否适合线上分发,这就是整个的内容分发链路。
02 飞猪内容推荐探索
下面具体来讲一下飞猪这一年在内容推荐上面做的一些探索及工作。
1. 内容算法要解决的问题

在飞猪的这种旅行场景下,内容算法面临的问题可以分为三类:
- 内容生产不规范,导致内容的结构化分类体系比较弱,如何进行内容理解。从上图可以看到飞猪对内容理解的思路,包括两部分,第一部分是判别图片质量,我们可以容易地看出,上图左侧蓝框里的两张图的图片质量比蓝框外的图要好;第二部分是对优质内容进行图文内容理解(上图左侧蓝框所示),图片描述的信息是不是一致,描述的目的地是否一致。
- 因为内容渠道多,导致内容量大,针对有限的线上流量如何筛选优质内容。
- 基于飞猪的业务场景,内容对时效性要求高,新内容需要及时曝光,如何设置排序策略。
2. 冷启动内容召回及粗排
(1) 面临问题
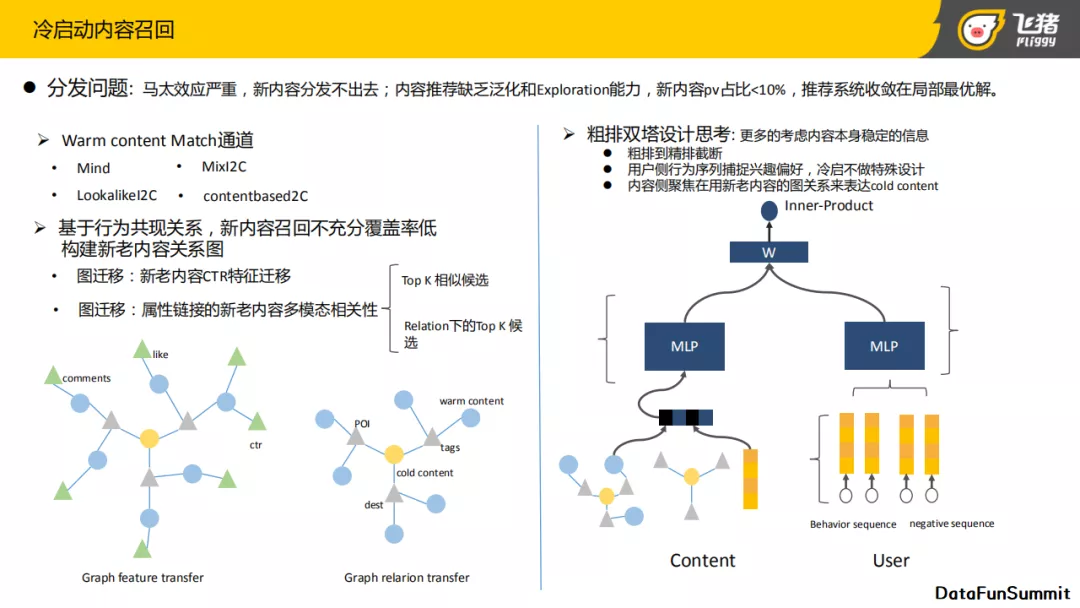
刚才提到由于内容对时效的要求比较高,且图文类的内容的量比较大,供给比较丰富,所以内容的冷启动面临的挑战是比较大的。而且在今年六七月份的时候我们发现,线上的图文的流量分发过于集中,马太效应比较严重,导致新内容分发不出去。整个内容推荐缺乏泛化和探索的能力。
(2) 解决方法及相关设计
缓解线上马太效应的核心思路是提高系统对新内容的探索能力和加大新内容供给。具体分为:
- 如何确保新商品或内容能被线上召回;
- 在排序阶段要考虑召回的内容要分发给什么样的人群。
跟随这个思路,我们讲一下飞猪在召回阶段跟粗排阶段的一些做法,目前整个线上采用两路召回的方法,一个是Warm content的Match方法,它使用了U2I,I2I相关的召回方案,例如Mind, LookalikeI2C,还有MixI2C。这条召回路径是针对已经与用户有行为交集的这些内容。
对于新内容,因为内容和用户是没有行为互动的,所以首先我们会做基于线上content的基础属性的图表达,给新内容找到相似的线上投放过的老内容,然后通过老内容的一些统计类数据来表示新内容。具体分为两部分,一个是新老内容的CTR特征迁移,如上图中左半部分的左图,中心节点是一个新内容,通过它的一些基础属性可以扩展找到线上的一些相似的老内容,使用这些老内容的点赞、CTR、评论等信息来表达新内容的统计类的特征。这样的话,即便新内容没有在线上分发,通过这些属性,可以得到先验特征。
上图左半部分右图展示的是多模态相关性的图迁移,与左边的图不同的是,它是基于模态之间的相关性来构建图结构,其关于相关性的计算会比左侧复杂。对于多模态相关性的计算有两个思路,一个是直接通过新老内容的视觉的多模相似性,第二是通过属性链接计算,这种方法对相关性的要求更高。对新内容召回的核心就是如何给新内容找到相关性高的老内容,然后把老内容的特征迁移过来。
当使用上述方法确保新内容被召回且和用户有相关性后,下面则要考虑在排序模块中如何进行粗排,如图右侧部分所示,粗排部分我们设计了一个双塔结构的MLP的model,为了提升整个粗排泛化性使排序不受历史投放的影响,我们更多的考虑了内容自身的一些信息,换句话说就是跟我们线上的投放数据关系不大的特征。整个网络结构分为两个塔,一个是content塔,一个塔是user塔。User侧与我们的商品排序以及精排相同,主要是基于用户点击行为序列以及其负反馈的行为序列。在左侧的content塔里,我们设计了如何表示内容,因为这次粗排的设计是为了解决冷启动问题,所以content侧的设计没有引入可以显著提升排序精度的统计类特征,更多的考虑了内容本身的side information,也就是图能迁移过来的属性和相关性来表示这个内容本身。改良后的模型对新内容的冷启动问题还是有效果的。
3. 内容多模态理解
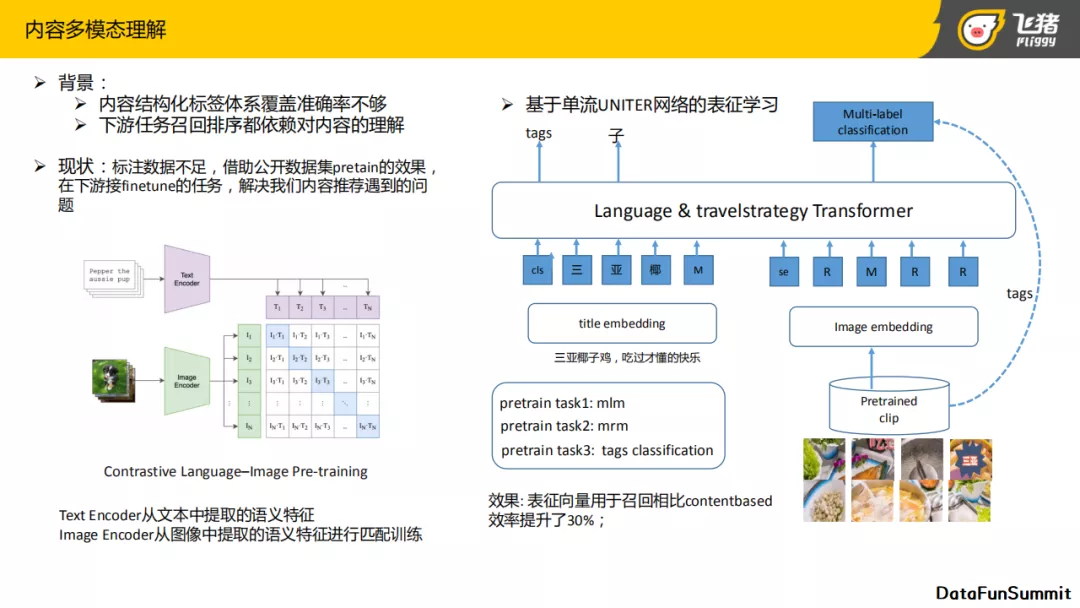
第二部分是我们之前提到的内容理解,刚才在内容冷启动里面我们提到,在召回模块里需要多模的向量表征去表达新老内容之间的相关性。同时因为目前标签的覆盖率和准确率不够,所以下游的整个匹配,包括召回、排序等,也都依赖内容理解。
我们知道模型决定了效果的下限,数据决定了效果上限 ,特别是在做CV的这种领域,训练模型需要大量的样本。基于这样的现状,我们选择了使用公开数据集去做pre-train,然后再利用自身的业务数据进行fine-tune的方案。Pretrain使用的是CLIP模型,大致原理是通过text-image的pair对去做无监督学习。这种类型的数据获取方式比较简单,可以使用句子去搜索引擎里搜图。这个句子就是这个图片的text表达,与图像分类不同,这里面使用了一句话作为图片的标签,而句子里涵盖了multi-label。换句话说是,可以用多个标签来描述一张图。多标签可以让模型的泛化能力变得更好,也可以更好地迁移到下一个的任务里面去。
详细的网络结构如左图所示,分为两部分,text encoder和image encoder。Text encoder目的为了提取文本embedding的特征。Image encoder用来提取图像的特征。然后通过matrix-learning可以得到一个矩阵,矩阵的斜对角线就是我们需要取的监督信号label。基于这种pre-train,就可以拿到图片的基础向量。
接下来基于pre-train的结果,去做fine-tune。如右图所示,其思路就是现在比较流行的单流UNITER网络表征学习,它将 transformer的思想应用到了视觉领域里。这个网络的整体思路和左图的思路是类似的,其左侧是我们图文里文字的embedding信息,原始信息来源于title或者头部段落的summary信息。在右侧网络里,对图片进行切割,使用图片里的regions和objects生成embedding信息。然后经过transformer网络。最后接了三个任务。
因为这属于一个无监督学习的任务,为了更好的监督整个网络的学习,我们在整个transformer的下游接了三个任务:
- 第一个任务里,会对整个标题做mask,然后让transformer去预测mask的信息。
- 第二个任务里,会对图片做mask,然后预测图片的embedding跟输入的差异。
- 第三个任务里,因为有30%的标签覆盖的数据,所以我们会拿这部分数据去跟整个多模态的类别去做多分类的任务。
通过这三个任务的学习,可以让整个模型自适应的去表达航旅里的内容,但是我们还面临着一个核心的问题,最终预测出来的向量更多的和文字信息相关,因为文字里可提取的信息更为丰富。但是作为一个旅行玩法,也需要图片的视觉表达。为了去解决这个问题,我们在整个任务里尝试了不同的图与文字的模态的权重,然后在做title的mask时,会做一些随机drop逻辑。表征向量最终会拿到线上去做召回进行评估,在召回阶段与基于Content-base图迁移相比大概有30%的效果提升。
4. 排序-精排
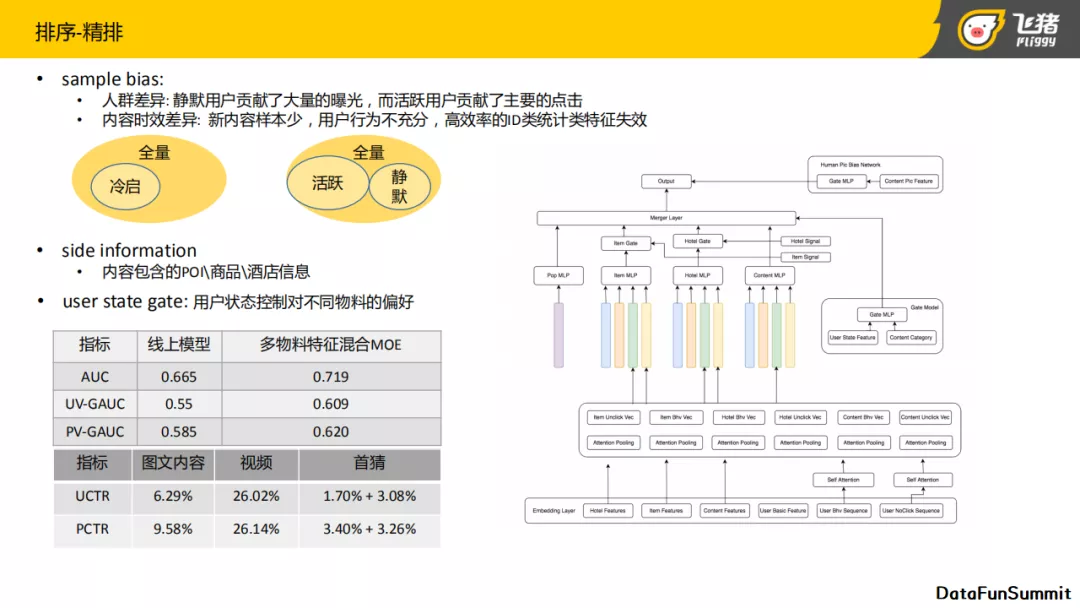
然后是内容排序,内容排序包括两个部分,一个是精排,一个是混排。这部分着重强调一下对内容排序与对其他物料排序的差异点,主要是sample bias,分为两部分:
- 人群的差异: 位于不同阶段的用户其行为表现及商品偏好需求也不同。举个例子,静默无目标用户更想找到自己想去的目的地,其贡献了大量曝光,这个时候推荐旅行玩法应该占比大一些,而活跃有目标用户贡献了主要点击,应该多推荐与目标相关的商品。
- 内容时效性差异: 内容时效性差异导致新内容的样本比较少,它跟用户的交互的样本也比较少。在排序里使用的统计类特征对于新内容是不友好的,而排序使用的样本活跃用户也会比静默用户的占比高。
而且整个猜你喜欢的留存率还是比较高的,所以它的活跃样本量占比较大。但是静默用户是整个产品场景用户增长的一个核心要素,也需要服务好这部分用户。结合上面提到的问题,如上图所示设计了整体精排模型,其思路如下:
- 更多的考虑side information的信息: 在右边这张图架构的最底层,包括三大部分特征,第一是用户的行为序列,包括它的正反馈序列和负反馈行为序列。第二块是内容本身的side information,因为内容本质还是为商品做引流,所以内容下会有对应的商品,酒店等。同时side information也能够进行内容理解。
- 使用user state gate: 在模型结构右侧gate model这部分,则考虑到了不同人群对不同物料的倾向,使用了用户的user state的状态加上样本所属的类目,结合了整个embedding上一层的多个不同类型的MLP网络(商品,hotel,content等),通过用户的不同的状态,会给不同的物料以不同的权重。
- 线上封面图伪点击处理: 在分析投放数据中发现带人像的封面图,例如:美女图,自带了一些伪点击,导致展现的线上封面图,人像的比例占比会特别高。所以在网络里面我们添加了一个Human pic bias 网络,去还原人像本身的真实点击率。
精排部分使用的是上述的MOE门控网络,最终的效果还是比较明显的,它的CTR和PCTR提升的幅度都比较大。
5. 排序-混排
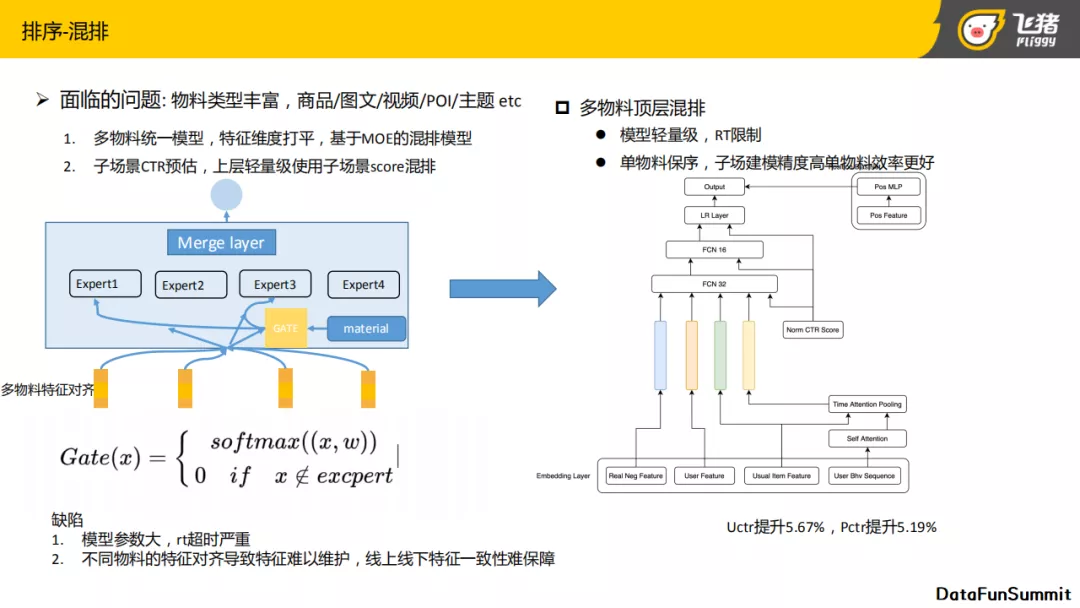
在精排之后,还有一层混排的逻辑,因为首猜是一个多物料场景,它包括商品、图文、视频、POI,还包括一些主题,混排就是将这些物料进行统一的排序。对于混排,我们迭代过两版方案,第一版我们做了一个多物料的统一模型,最底层将所有物料的特征进行特征对齐,放入同一个特征维度空间,上层设计了一个MOE混合的专家网络。
但是特征对齐可能会出现一个问题,不是所有物料都能够在特征里边做对齐的,举例来说,A内容可能包含商品,但是B内容有可能不包括商品。为了减少就是说这种底层特征缺失带来的一个影响,在上层设计了一个expert network的门控。它主要原理是,当底层的特征缺失时,对应的expert权重可以被强制为零,这样的话可以减少这一部分缺失特征带来的影响。
这种方案的缺点也十分明显:
- 因为它是一个同构的expert网络,所以导致模型参数量特别大。当上线时,会导致整个RT超时严重;
- 当对不同物料做特征对齐时,在打平特征之后,特征维度已经超过我们所有以前可用的线上模型,特征线上线下的一致性�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%A2%81%E8%85%BE%E9%A3%9E%E9%98%BF%E9%87%8C%E9%A3%9E%E7%8C%AA%E4%BF%A1%E6%81%AF%E6%B5%81%E5%86%85%E5%AE%B9%E6%8E%A8%E8%8D%90%E6%8E%A2%E7%B4%A2/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


