蘑菇街首页推荐多目标优化之实践一把双刃剑
作者:美丽联合集团 算法工程师 琦琦 ,
公众号关注:诗品算法
0、引言
我曾经也秉承着“技术至上”的信条,但随着工作年限的日益增长,在我变成一个老白兔后,观点慢慢发生了转变。作为一个算(调)法(参)工程师,理解业务才是最重要的。有些技术看起来很高大上,但它不可能适用于所有场景。算法工程师的核心竞争力,是为公司创造价值,这正是建立在深刻理解业务的基础上的。 不同场景在不同阶段的优化目标不同,可能需要不同的特征 & 不同的模型来承接。有些“小而美”的算法,上线成本低,为何不优先尝试呢?本文介绍的正是通过改变样本权重进行多目标优化的方案,简单易上手。
1、多目标学习的必要性
在工业界推荐系统中,推荐结果可能会呈现不同的形态(商品、视频、图片、文章等等),用户在不同平台不同场景对推荐结果的满意度通常也依赖于多种多样不同的指标。具体细分到每个场景,比如在电商场景,我们的优化目标是点击率和GMV;在信息流场景中,我们的优化目标是用户的停留时长、点赞、评论、关注等互动指标。当然,在不同的场景、不同的产品形态下,不同目标的重要程度也会有所不同。推荐系统到后期,必然会向多目标演化,甚至可以在模型的loss function中引入更多业务目标。
多目标排序通常是指有两个或两个以上的目标函数,目的是寻求一种排序使得所有的目标函数都达到最优。
工业界大都基于隐式反馈进行推荐,因此在评估用户满意度的时候会有不同程度的偏差。
1、不同目标的权重不同
比如在电商场景,购买所表达的偏好远远高于点击、浏览所表达的偏好程度;而在信息流社区,停留时长、关注、分享、评论等表达的偏好远远高于点击和浏览。
2、单目标预测不全面
在今日头条、知乎、小红书等以内容生产为主营的app,若仅仅以点击率为目标排序,可能存在质量极差的标题党内容排序靠前。
在抖音/快手等短视频app,若仅以视频完播率为目标,可能会存在设置悬念而后需要转发关注才能观看的视频,用户看完后一声唏嘘,大大降低用户体验;若仅以点击率为目标,可能会将封面内容极佳、实质内容极差的视频排上去;若仅以停留时长为目标,可能排名靠前的就偏向于长视频了。
在微博,如果仅以转发分享为目标,排名靠前的可能是满屏的转发保平安或者类似拼多多之类的社群裂变营销。
3、用户表达满意度的方式不同
比如在社区,用户表达喜欢的方式可能从点赞、分享、评论到关注不等,毕竟世上没有完全相同的两片叶子。若仅使用点击和点赞目标建模,就错失了那部分倾向于以关注表达喜爱的用户信息。
4、单目标模型无法巧妙融合业务目标
若希望将业务目标融合到loss function中,比较优雅的方式自然是引入多目标建模。比如,在电商场景,需要尽量避免推荐的结果集中在同一个店铺/同一个类目,此时,除了引入业务层硬性“hard”打散,也可以在模型的loss function中引入打散目标,更加soft。
笔者分别在蘑菇街首页推荐信息流以及首页推荐直播切片视频两个场景中实践并落地了reweight策略。前者由笔者亲自实践,后者由笔者带着组内小伙伴操作。线下调整和线上实践的过程中,有很多有趣的现象和奇思妙想跟大家分享。相信我,这是网上关于reweight实践最详细的一篇文章了,读完你定会有所收获。
2、理论篇——sample weight原理介绍
网上的资料有很多,这里简单提一下。这个方法也属于多目标范畴,但涉及较多的trick和目标的人工调整。这里以信息流场景为例,主目标是点击率,但当ctr优化到一定程度后,其他的行为(在feed的停留时长、点赞、分享等互动事件)的指标是下降的,因为用户接收到了他认为不实用的东西。
以同时优化点击率和停留时长为例,点击和有停留时长的样本均为正样本,我们可以根据用户在不同feed中的停留时间,对不同停留时长的样本设置不同的sample weight。模型训练在计算梯度更新参数时,梯度要乘以权重,对sample weight大的样本给予更大的权重,导致对这类样本预测错误会带来更大的损失。上线后,这种方法会以点击率持平或者略跌的代价,换取停留时长的增长。
这种方案的优缺点很明显。
优点:模型简单,基于排序主模型进行微调,仅在训练时通过梯度上乘样本权重实现对某些目标的放大或者减弱。
缺点:本质上不是多目标建模,而是将不同目标折算为同一个目标。这种折算能否带来线上指标的提升,完全取决于工程师的调参经验和运气。同时,这种方案会将正样本中的噪声放大n倍,其影响难以预估,比如对随机成交的正样本赋予很高的权重。该策略无法达到最优,多目标问题本质上是一个帕累托寻找有效解的过程。
3、理论篇——loss function的变化
我们有
 组样本(
组样本(
 ),
),
 表示第
表示第
 组数据及其对应的label。其中,
组数据及其对应的label。其中,
 为
为
 维向量(考虑bias),
维向量(考虑bias),
 则为表示label的一个数。
则为表示label的一个数。
 取0或者1。模型的参数为
取0或者1。模型的参数为
 。
。
先给出通常意义上的交叉熵损失函数:

其中,



如果我们对上述损失函数稍加改动,使用一个变量来平衡positive error(第一项)和negative error(第二项),通过更改这个变量的大小,来改变两项的相对权重,那么,我们就可以在召回率(recall)和精确率(precision)之间寻求tradeoff。
加入reweight策略后的交叉熵损失函数(reweight权重=pos_weight=p):

当reweight > 1时,对positive样本预测错误将带来更大的损失,因此false negative数量将会减少,
 将会上升;相反的,当reweight < 1时,对负样本预测错误将带来更大的损失,导致false positive数量减少,从而
将会上升;相反的,当reweight < 1时,对负样本预测错误将带来更大的损失,导致false positive数量减少,从而
 将会增加。
将会增加。
损失函数对参数分量的偏导数,大家可以自行推导。梯度下降时,positive样本会在原始梯度的基础上乘以reweight值。
因此我认为,reweight实际上是召回率与精确率之间的tradeoff,增加召回率势必会以牺牲精确率为代价,后面我们会说到,随着reweight的不断增加,模型引入的噪声越来越多,这并不是没有原因的。
4、实战篇1——首页推荐信息流
蘑菇街推荐场景的信息流包含图片和视频,之前的模型训练目标仅仅包含单一的点击率,经过线上模型排序后,展现出来的物料往往都是高点击率,低停留时长的内容,这些内容可能有着极其吸引人、博人眼球的封面,但是真正的内容往往差强人意、甚至让人没有继续在当前界面停留并看完视频的欲望。封面展现和其内核不符,是导致某些内容点击率高、停留时长和互动等核心指标极差的原因之一。电商的核心诉求是提高用户的留存率。如何提高用户留存率?必然要提高用户对平台展现内容的兴趣,让用户有继续看下去并与视频/图片发表者进行互动的动力。若用户观看了一些裹着糖衣的极差视频,用户对于平台的认知就会大打折扣,甚至不再回访。因此,在这样的大环境下,我们的模型优化目标不再仅仅是点击率,而是更内核更重要的停留时长、互动、关注及用户的留存。
停留时长多目标样本加权方式,参照RecSys2016上Youtube提出的时长建模,在模型训练时,通过停留时长对正样本加权,负样本不加权的方式,影响正负样本的权重分布,使停留时长越长的样本,在时长目标下得到充分训练。
技术方案具体实现:
- 首先,我们需要统计平台内的停留时长分布情况。停留时长重要分布指标包含均值、方差、分位数(10分位数、20分位数、30分位数~90分位数、99分位数)。
- 注意:不建议直接取原始停留时长或者将停留时长取默认log函数后加入训练(原因后面解释)。1)根据不同场景,对停留时长做不同的预处理。2)引入分享/评论/点赞/关注等用户在详情页的行为事件,进行预处理。
下面将详细阐述我们在两次线下和线上实验中,分别对停留时长和互动指标进行的处理工作。
实验一**
- 行为事件:1 + log(1.3, event_cnt + 0.1)
- 停留时长:当time <= 50时,线性函数:0.8 * time;当time > 50时,非线性函数:log(1.0775, time-30)
- 两者相加,作为正样本reweight权重,负样本reweight权重默认=1
其中,event_cnt表示用户在内容详情页的行为事件数量,这里的事件数量即点赞、评论、分享等互动指标的简单求和(更优的方案自然是加权求和)。time表示线上真实停留时长。log底数根据上述停留时长分布/行为事件分布情况确定。我们公式的核心点:在停留时长 < 50s时,使用线性函数,使停留时长之间的倍数关系不变,当停留时长 > 50s时,对停留时长进行适当压缩。以50s为分界点的停留时长处理函数如下:
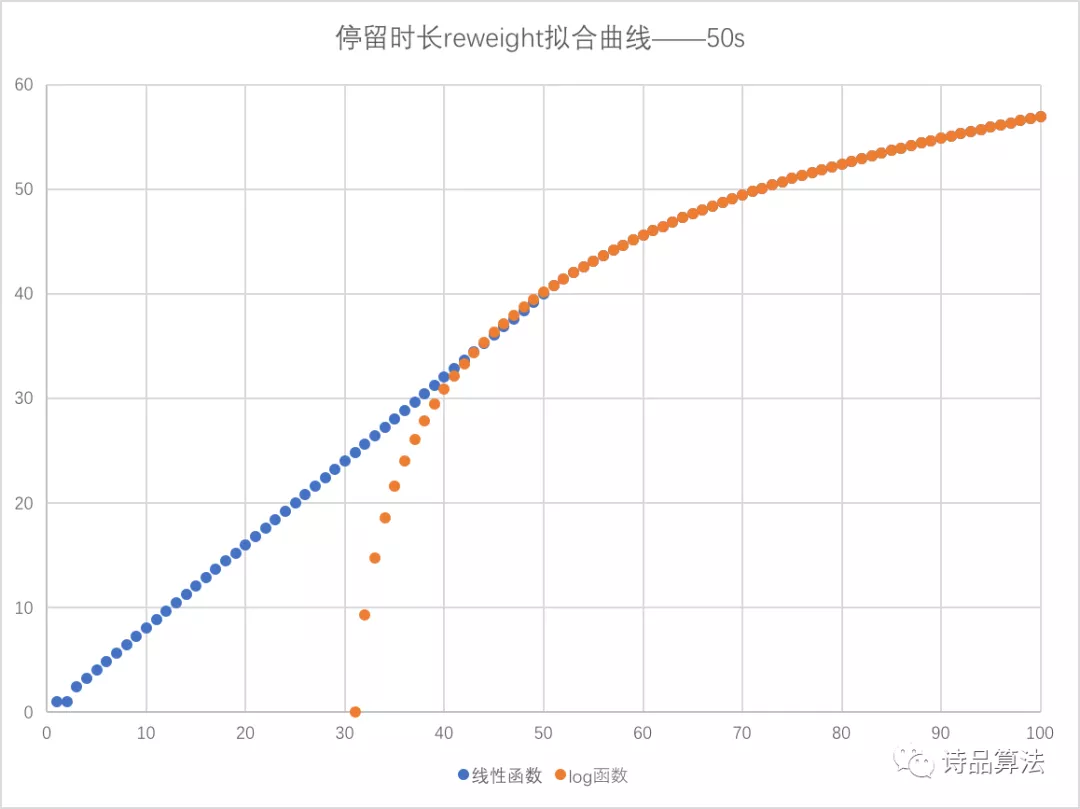
横轴表示原始停留时长,纵轴表示reweight权重,蓝色线表示前50s进行的线性变换,红色线表示50s后进行的非线性变换。在两个函数的相交部分,需要保证两个函数相切,以便实现平滑过渡。
问:为何不直接使用默认的log函数?答:使用默认log函数的处理方式,对停留时长的压缩较为严重,线上的模型目标依然向点击率倾斜。
更直观的,若我们不对log函数进行上述底数变换,而是使用默认的底数,那么,我们得到的停留时长曲线对比如下:
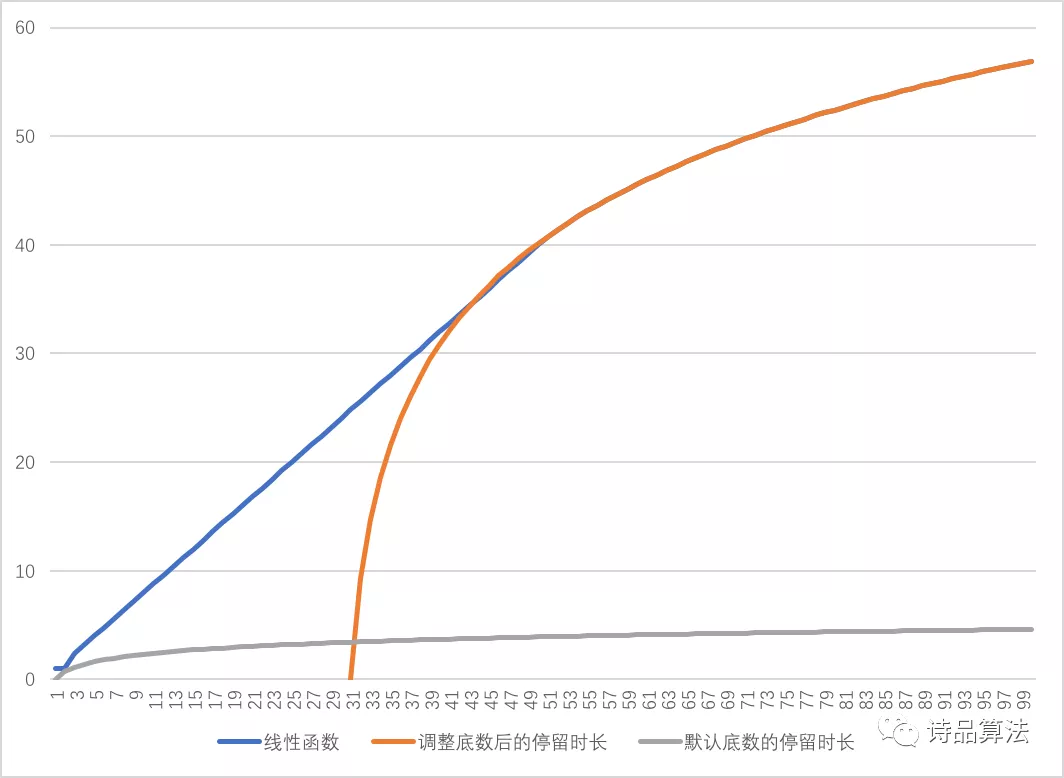
蓝色+红色是调整后的停留时长曲线,灰色的线是对原始停留时长使用默认底数的log函数进行处理的停留时长,可以看出,**若进行默认处理,在处理后,停留时长几乎没有区分度,模型仍然以点击率目标为主,无法体现reweight的优势;但若不进行任何处理,使用停留时长原始值,我们将无法有效过滤样本中的噪声数据。**在大于某个阈值后,停留时长实际上已经完全“失真”了,比如某个样本中的停留时长达到600s,即10分钟,这种数据对模型训练将产生灾难性的影响。有人也许会说,可以对不置信的过长停留时长进行截断。截断在某种程度上是有用的,但截断阈值本身就不容易确定,且在截断阈值点,无法保证相切。我们采用前半段线性,后半段非线性的方案,完美地解决了上述问题。
线上实验效果:曝光PV-3.1%,点击PV-6.29%,点击率-3.29%。总停留时长-6%,停留时长+6.96%,人均停留时长+11.5%,安卓停留时长+6.81%,IOS停留时长+7.53%,小窗停留时长+14.02%。
停留时长:用户在单个内容上的停留时长。总停留时长:用户在单个内容上停留,并产生下滑行为的整体停留时长。这里的停留时长涵盖了用户下滑所观看视频的停留时长。
这个实验不是很完美,虽然我们提高了单内容停留时长指标,但是却损害了点击pv指标。所以需要继续调整目标曲线。
实验二**
调整之前的停留时长reweight公式,增大对原始停留时长的压缩力度。
让我们回顾实验一的reweight策略:
- 行为事件:1 + log(1.3, event_cnt + 0.1)
- 停留时长:当time <= 50时,线性函数:0.8 * time;当time > 50时,非线性函数:log(1.0775, time-30)
- 两者相加,作为正样本reweight权重,负样本reweight权重默认=1
实验二的reweight策略:
- 行为事件:log(1.2, event_cnt + 1.0)
- 停留时长:当time <= 4时,1.0;当time > 4时,非线性函数:log(1.4, time - 3)
- 两者相加,作为正样本reweight权重,负样本reweight权重默认=1
其中,与实验一不同,实验二中的event_cnt表示事件加权和,即通过点赞、评论、互动、关注等指标加权求和得到。每个事件对应的权重是不同的,这里的权重可以根据不同平台下,不同指标的重要程度来确定。比如关注的重要性最高,可以赋予最高权重;评论/分享的重要性次高,可以赋予比关注略低的权重。time表示线上真实停留时长。
如下图所示,蓝线表示实验一的停留时长处理曲线,红线对应处理后的停留时长权重,灰色线对应处理后的事件权重。与实验一相比,我们加入了对各类事件的加权,同时适当降低了停留时长的reweight权重。
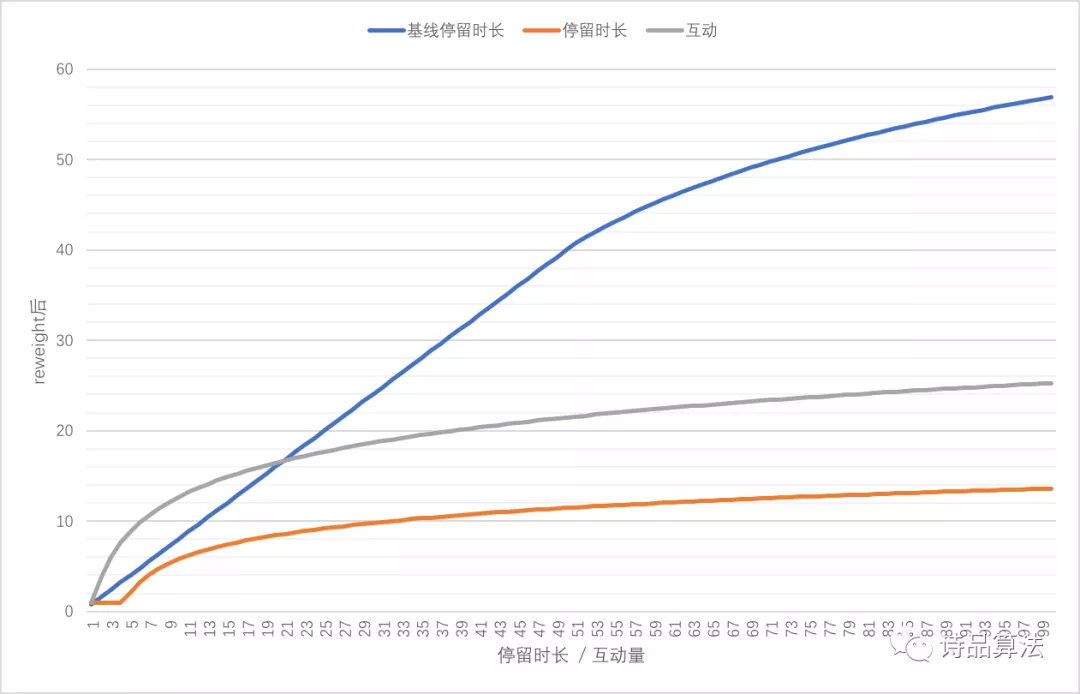
总结:实验一调出的公式远非模型所能达到的最优点,实验二将停留时长重新调整和压缩,使目标在点击率和停留时长之间达到一个平衡点。
线上实验收益:曝光PV+3.73%,点击PV+7.21%,点击率+3.46%,点击UV+2.95%,总停留时长+12%,停留时长-3.8%。已全量。
优于实验一的收益。虽然单个内容的停留时长略降,但是用户在全局的停留时长有明显上涨(12%),且用户的浏览深度和点击PV指标也有明显增长,符合我们的期望。
因此,经过我们的经验调整,模型可以达到一个较优的状态。
5、实战篇2——首页推荐直播切片视频
直播切片指的是主播在直播过程中录制的商品讲解视频,有购买链接。直播切片以视频的方式呈现,每个直播切片必然存在一个商品与之对应,结合了商品和视频的共同特点。与信息流不同的是,直播切片的首要目标是提升gmv,很直观的,我们需要直接建模成交。
废话不多说,直接上公式及其对应的实验结果。以下是直接使用上述reweight策略建模gmv的公式及对应效果。
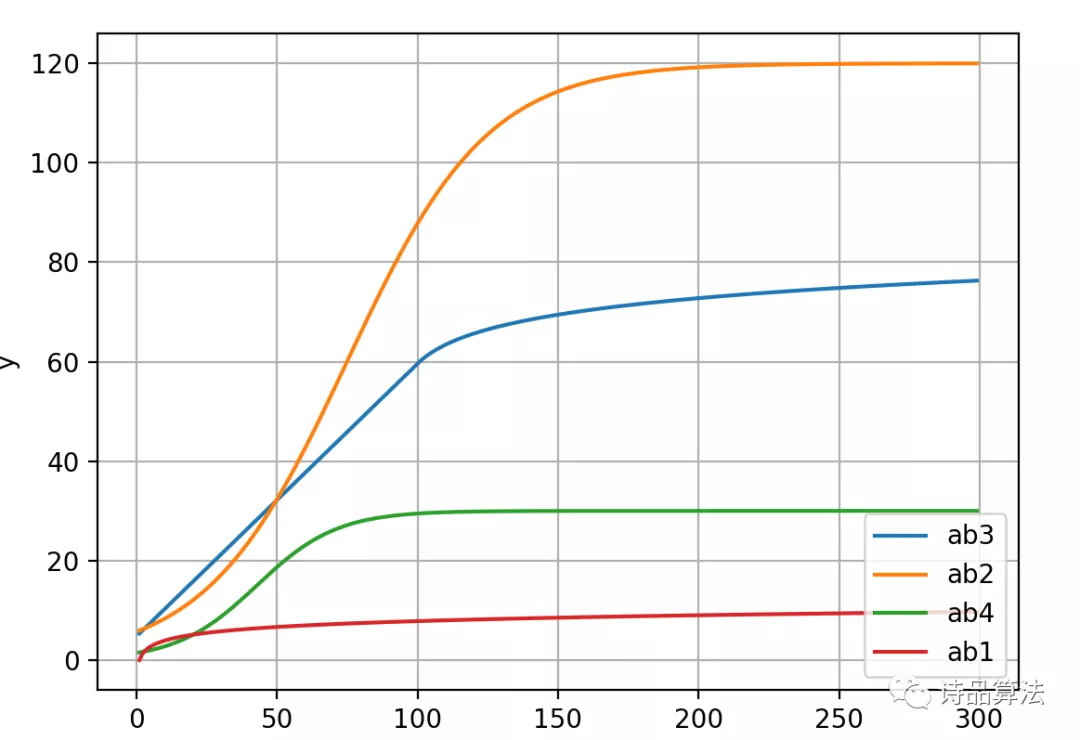
1、reweight公式
(1)实验1:log(x, 1.8)
(2)实验2:6/(0.05 + math.exp(-0.04*x))
(3)实验3:if x <= 100 then 0.5484*x + 4.78 else log(1.2, (x - 90)) + 47
(4)实验4:3.5/(0.05 + exp(-0.03*x))
其中,x为模拟gmv,单位为元,也就是下图的横轴,纵轴为reweight权重。
2、实验结果
(1)实验1: 曝光pv/点击pv/pvctr/uvctr与基线持平,成交订单量+8.74%,成交UV+8.46%,gmv+6.6%,第一天上线时的收益更加明显,成交订单量+23.23%,成交UV+20.92%,gmv+23.37%。已经全量。
(2)实验2:pvctr-4%,uvctr-5%,成交订单量-2%,gmv-4%。
(3)实验3:pvctr-1.8%,uvctr-2.7%,成交订单量-12%,gmv-12%。
(4)实验4:离线auc与基线绝对值差0.1%,线上所有指标与基线持平。细心的读者可以观察到,在gmv<20的区间内,实验4的reweight权重小于ab1,因此对于落于这部分商品的reweight力度小于ab1。
3、实验分析
上述的实验2、3、4均无收益,因此,我们着重分析了这几份实验上,不同类型切片的gmv。
1)reweight的置信度问题。
拿ab1和ab2对比,对于曝光大于一定阈值的切片,ab2上的成交订单量/gmv/cvr均优于ab1,相反的,对于曝光量小于某一阈值的切片,ab2上的成交订单量/gmv等指标则明显差于ab1。
这个结论很有意思,原因也在前面多次提到过。 reweight会将正样本中的噪声放大n倍,其影响难以预估,比如对随机成交的正样本赋予很高的权重。
针对此现象,我们进行了一系列调整实验: 将曝光量/点击量低于一定阈值的商品所对应样本的reweight权重全部置为1,也就是说,不置信商品产生的成交样本权重等同于负样本权重(当然我们也可以用更加soft的方式平滑)。上线后,整体gmv略微正向。曝光量低于一定阈值的商品曝光占全局曝光的比例较少,因而对全局的影响有限。
2)reweight的压缩区域。
我们设计的reweight公式,对reweight曲线的前半段来说(大部分样本落在的区域),reweight力度越大,点击率指标会跌得越多;对reweight曲线的后半段来说,则是在处理gmv较大的样本,力度越大,大概率会使实验的gmv指标下跌,因为这部分样本数量过少,存在大量的随机成交,为模型引入了额外噪声。
实践时,可以根据不同平台的gmv分布情况对reweight的区间以及值域范围进行调整。
4、与成交相关的目标挖掘
直接建模成交,无疑是极其稀疏的,无论是简单的reweight还是复杂的ESMM。因此,有必要找到与order正相关的中间变量,建模到reweight公式中。
我们分析了停留时长与gmv的关系。从数据来看,**停留时长与成交订单/gmv呈正相关的线性关系,因此将停留时长设计为从点击到gmv的一个中间变量,可能可以缓解gmv样本的稀疏性问题,同时可以缓解随机成交给模型带来的噪声。**我们来试试吧!
如下图所示,横轴为停留时长所在分桶,纵轴为gmv。设计敏感数据,具体值不pou出,大家看趋势就好。
reweight策略公式:
(1)gmv_reweight公式:log(gmv, 1.8)
(2)停留时长reweight公式:1/(0.2 + exp(-0.03*stay_time)) + 0.6
(3)总reweight:reweight=gmv_reweight + stay_time_reweight
PS:这里的停留时长reweight公式,设计为类sigmoid函数,前段和后段压缩,中段保持线性,这是有理论及实践支撑的,大家也可以想想为什么,欢迎留言讨论。
实验效果: 曝光pv与基线持平,pvctr-3.31%,uvctr-1.7%,成交订单量+9.95%,成交UV+7.89%,gmv+8.51%,总停留时长+4.92%,平均停留时长+8.28%,人均停留时长+8.28%,收益稳定,已全量。
_
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%98%91%E8%8F%87%E8%A1%97%E9%A6%96%E9%A1%B5%E6%8E%A8%E8%8D%90%E5%A4%9A%E7%9B%AE%E6%A0%87%E4%BC%98%E5%8C%96%E4%B9%8B%E5%AE%9E%E8%B7%B5%E4%B8%80%E6%8A%8A%E5%8F%8C%E5%88%83%E5%89%91/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


