腾讯音乐音乐命名实体识别技术

分享嘉宾:Kevin 腾讯音乐 算法工程师
编辑整理:韦国迎 天虹
出品平台:DataFunTalk
导读: 命名实体识别(Named Entity Recognition,简称NER)是自然语言处理中的热点研究方向之一,目的是识别文本中的命名实体,并将其归纳到相应的实体类型中。命名实体识别也是NLP最重要的底层任务之一,在学术界和工业界一直都是重点研究的问题。今天主要和大家分享音乐领域的命名实体识别技术,包括以下几方面内容:
- 背景介绍
- 候选生成与训练数据构建
- 用户Query NER模型
- 音乐文本NER模型
- 未来展望
01 背景介绍
1. NER的定义与应用
NER就是识别文本中具有特定意义的实体,在音乐领域中实体主要包括歌曲名、歌手名、影视、综艺、版本、音乐流派等,例如:
Block B在一周的偶像中挑战二倍速的Her,rap部分感觉Zico的舌头都要打结了
给我来一个东方红谢谢
这里有歌曲名(Her、东方红)、歌手名(Block B、Zico)、综艺(一周的偶像)。在音乐领域中,NER在多种类型的文本上都有着广泛的应用,这里我们主要分为两大类:用户query理解和音乐文本结构化。
① 用户query理解
用户的query理解,包括了搜索框内的文本搜索以及语音场景下的搜索。比如说这里用户在搜索框内输入的query是 “周杰伦的七里香”,由于我们库内没有同名的资源,因此这里我们就需要NER模块从中来提取出歌手名=周杰伦、歌曲名=七里香,这样我们才知道用户想要的其实是周杰伦唱的七里香这首歌。
② 音乐文本结构化
音乐文本的结构化,主要是从我们库内的视频标题、歌单标题、评论等非结构化文本数据中抽取出一些音乐领域的实体,便于在搜索推荐等任务中应用。
2. NER的发展历程
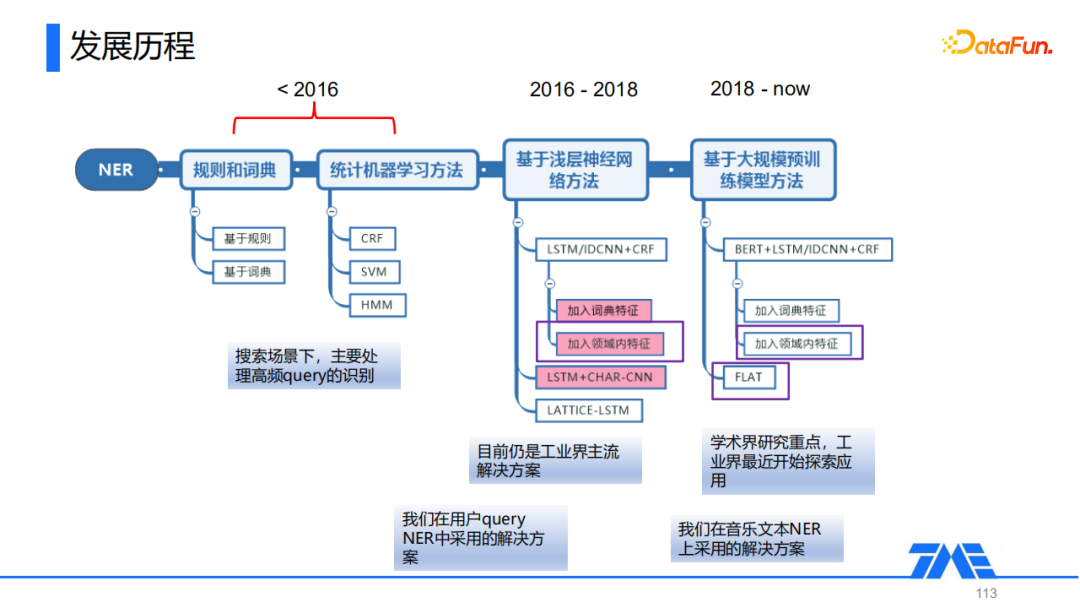
NER在早期的时候主要是基于规则和词典,还有统计机器学习的方法(HMM、CRF、SVM等),这类方法主要的优点是速度比较快,精确率比较高,但是召回率通常比较低。目前工业界主要是在搜索的场景下,采用这类方法来处理一些高频query,以实现线上大多数请求的快速响应。
2016~2018年之间随着深度学习的发展,相关从业者也在NER领域做了比较多的研究工作,提出了基于浅层神经网络的方法。它的基础结构是通过LSTM或者IDCN这样的浅层神经网络去抽取文本的特征,然后通过CRF进行解码,得到对应的实体序列,在这样的模型基础上,融入外部词典特征和领域内信息等外部知识进行模型优化。此外还有其他一些研究工作,考虑如何融入多粒度信息,比如LSTM+CHAR-CNN增加一个字符级的CNN融入,LATTICE-LSTM通过对LSTM的结构进行修改实现词以及短语等不同粒度信息的融入。根据我们的调研,这类目前依然是工业界主流的解决方案,我们在用户query NER中就采用了这一类的方法。
2018年后,随着Bert的兴起,基于大规模预训练语言模型的方法成为了趋势,这类方法主要特点是,将浅层的文本抽取器、特征提取器,改成Bert这样的大规模训练语言模型,从而获取质量更高的embedding去优化下游的任务。此外在这类方法的基础上还会有一些相关的优化,比如说ACL2020的FLAT,基于transformer序列全连接的结构,实现外部词典信息的引入。目前这类方法是学术界的一个研究重点,我们是在音乐文本的命名实体识别上采用了这类的解决方案,并针对场景进行了一些优化。
3. 音乐领域NER的难点

① 领域相关性强
如果没有领域内的相关知识,文本中的实体难以正确地被识别,比如:张碧晨时间有泪忧伤的恰如其分,这句话中《时间有泪》是一首歌曲,如果我们事先不知道它是歌曲名,仅通过文本层面的信息很难正确地切分出它的边界。
② 实体名命名不受限且歧义大
这里的歧义主要有两方面,第一个是实体名与自然语言表述的歧义,比如:天后梅艳芳与歌神张学友同台合唱,薛之谦唱过一首歌《天后》,但是在这个句子中 “天后” 并不是歌曲名,而是对歌手梅艳芳的一个称谓。第二的话是同样一个实体名在不同场景下实体类型可能不同,比如:“安静的歌曲”与“歌曲安静”,前面的 “安静” 指的是一种歌曲类型,而后面的 “安静” 指的是周杰伦唱的歌曲《安静》。
③ 缺乏足够的上下文信息
这一难点主要是针对于用户query,因为用户query通常是一些实体的堆叠,很多都缺乏上下文信息,并且和正规的文本相差比较远,比如:张韶涵夜空中最亮的星邓紫棋。它是由(张韶涵、夜空中最亮的星、邓紫棋)三个实体堆叠而成的,没有任何的上下文信息可以利用。
④ 表述具有多样性
这一难点主要是针对于音乐文本,音乐文本同开放域文本一样,也是具有多样性的。同样的意思可能有多种表达方式,并且表达方式相对于正规文本来说更加的不规范。比如对这样一个视频标题:女歌手弹唱一首恰似你的温柔,真是好听。如果我们把弹唱替换成演唱/带来/创作,甚至其它的表述方式,它都是合理的。
4. 整体解决方案
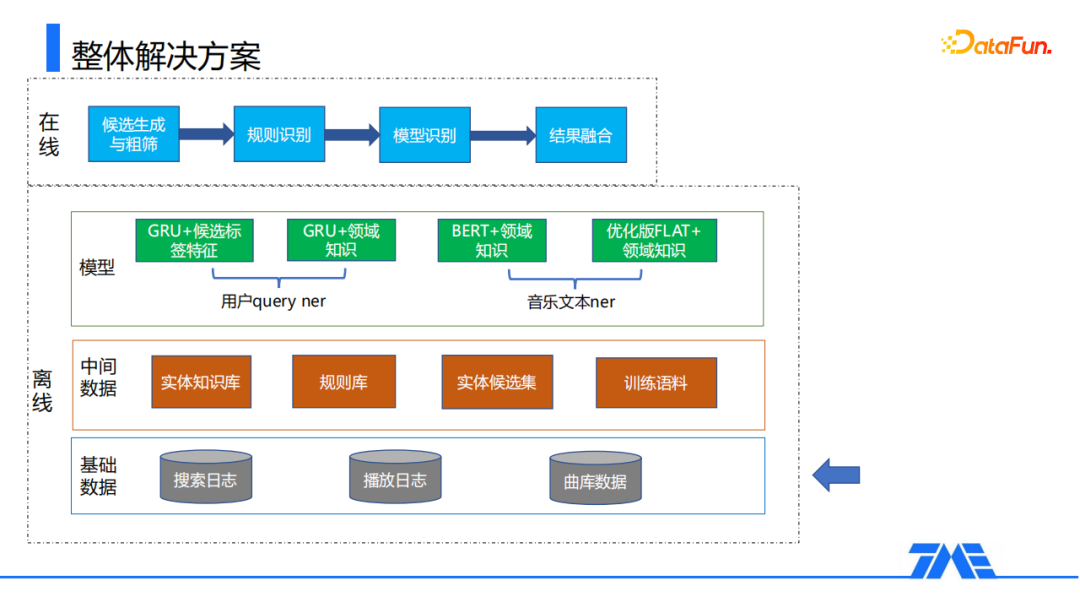
从上述四个难点可以看出,要想正确识别文本中的实体,需要将实体属性的建模以及文本信息的建模相互结合起来。这里介绍一下我们的一个整体解决方案,主要分为离线和在线两个部分。
① 离线模块
离线分为三个子模块:基础数据、中间层数据、模型。
-
基础数据
基础数据包括搜索日志、播放日志、曲库数据等内容,其中搜索日志和播放日志主要是对用户行为上报的存储,曲库数据主要是存储在库中的结构化资源数据。
-
中间层数据
中间层数据主要是基于基础数据进行计算和变换所得到的中间层数据,包括实体知识库、规则库、实体候选集以及训练语料等。
实体知识库是对结构化资源信息和用户行为日志进行一些整合变换得到的key-value集合,其中key表示的实体名,value是这个实体对应的一些属性,通过这样的存储方式,便于下游工作对它的利用。
规则库主要是对于用户query文本,通过Bootstrapping之类的文本挖掘方法,从中挖掘出一些频繁出现的模式,然后存储到规则库中。
实体候选集主要是存储文本中可能是实体的片段,关于实体候选集和训练语料的构建,后面会比较详细阐述我们采用的方法。
-
模型
在前面的难点中提到了,我们这里主要有两大类的文本,一类是纯UGC的文本,比如用户的query,另外一类就是相对而言中长一些的文本,比如标题、评论等。针对这两类不同的文本,我们采用两类不同的模型,因为用户query的上下文信息比较缺乏,我们采用了GRU对文本进行编码,对于其他的一些中长类的文本,我们采用BERT来提取更丰富的上下文信息。在两类baseline模型的基础上,我们针对如何去融入领域内的知识进行了一些探索,在下文都会进行详细阐述。
② 在线模块
线上预测分为四个部分:首先经过一个候选生成与初筛模块,得到文本中存在的候选片段,然后依次通过规则和模型识别得到识别结果,最后再通过融合模块进行融合,得到最终的识别结果。通过这样的方式,我们可以将规则的高精确以及模型的高召回结合起来,得到质量比较高的识别结果。
02 候选生成与训练数据构建
1. 候选生成
候选提取就是从文本中提取出尽可能不重叠的高置信候选实体。

在上图例子中,针对用户query“陈小春的歌乱世巨星”,通过与知识库匹配,可以得到“陈小春”、“小春”、“小春的歌”等候选实体。如果直接将这些信息加入到模型中,会给模型带来很大的噪声,因为这些候选在这个片段中位置上是高度重叠的,因此我们需要通过一个筛选模块,从中筛选出一些尽可能不重叠的候选,比如最终我们选择了陈小春,乱世巨星两个候选,然后把他们加入到模型中,就可以提供一个比较好的外部信息。前面我们提到了音乐领域的NER是有强领域相关性的,因此候选的效果对最终的效果有很大的影响。
针对候选的提取业界常见的解决方案主要有最大匹配和最小匹配方法:
- 最大匹配算法 贪心地去选择一个最长的候选,它的主要缺点是对于词典的质量要求比较高,比如对于这个句子:请为我播放陈慧琳记事本。由于我们库内有“陈慧琳记事本”这样一个同名实体,因此通过最大匹配我们就会切出“陈慧琳记事本”这样一个候选,显然这是一个错误的候选。
- 最小匹配算法 近似于利用实体词典来进行切词,它虽然说解决最大匹配带来的问题,但是它切分力度太细,很容易将一个正确的实体切散,比如对于这个句子:郑中基演唱的晴天阴天雨天。最小匹配可能得到的结果就是“晴天”、“阴天”、“雨天”三个候选,本来“晴天阴天雨天”是郑中基演唱的一首歌,在这里就被切散了。
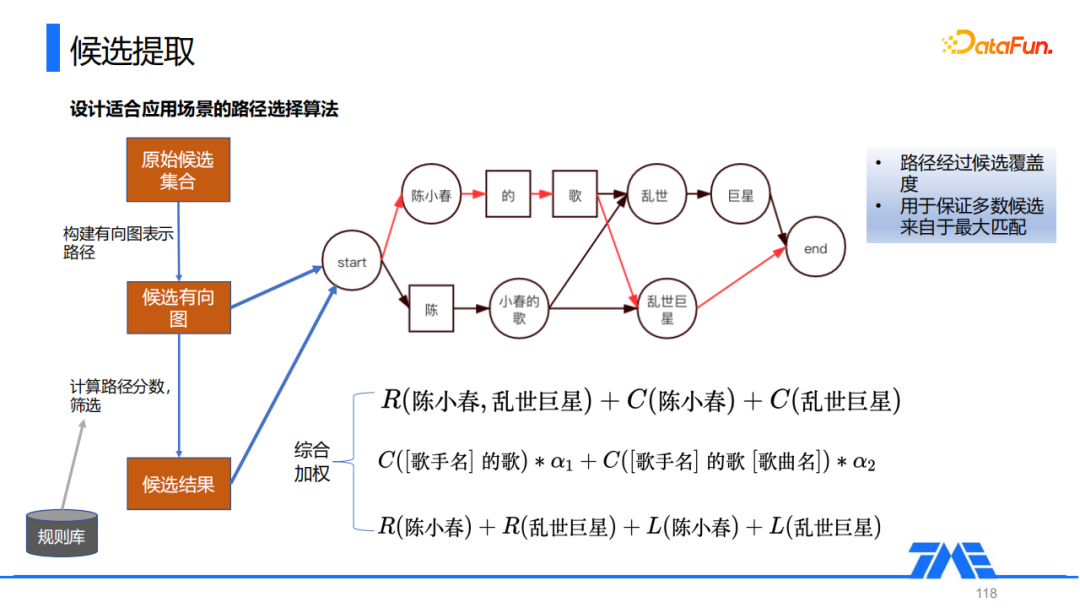
针对最大和最小匹配存在的问题,我们综合最大和最小匹配的优势,设计了一个适合我们应用场景的路径选择方法。首先针对原始的候选实体,我们抽取出所有可能的候选,然后构建出候选的有向图,比如对于上面这个例子:陈小春的歌乱世巨星。我们用一个有向图来表示所有可能的候选的路径,接下来去计算每一条路径的分数,然后根据路径的分数筛选出红色标红的路径就是分数最高的路径,根据这条路径选择最终的候选集合。这里的关键在于如何计算每条路径的分数,我们从三个角度来计算分数,首先是候选实体的置信度,它主要评估候选本身的置信度,或者说它的热度;然后是路径命中规则情况计算得到的分数,其实也就是实体级别的一个语言模型分数,主要评估路径的流畅性;最后我们引入了一个Root-Link考察候选被其它候选的覆盖情况,这是音乐领域的一个特性,如果一个候选是所有重叠候选中最长的实体部分,通常情况下,我们更倾向于认为它是一个正确的实体,最终将这三类分数综合加权得到了每一条路径的分数。

在具体计算的过程中,我们做了一个优化,当文本比较长时,遍历所有路径依次计算分数的开销过大。因此我们采用了 beam_search的方式,对于每一个token只保留以它为结尾的N条路径,把整个有向图分为多个部分分开计算。比如对于上面的例子,我们对于"乱"这个token,就保留以它为结尾的两条路径。当我们对这个token后面进行路径选择时,就与前面的路径无关了,这样就可以减少整体的计算量。
2. 训练数据构建
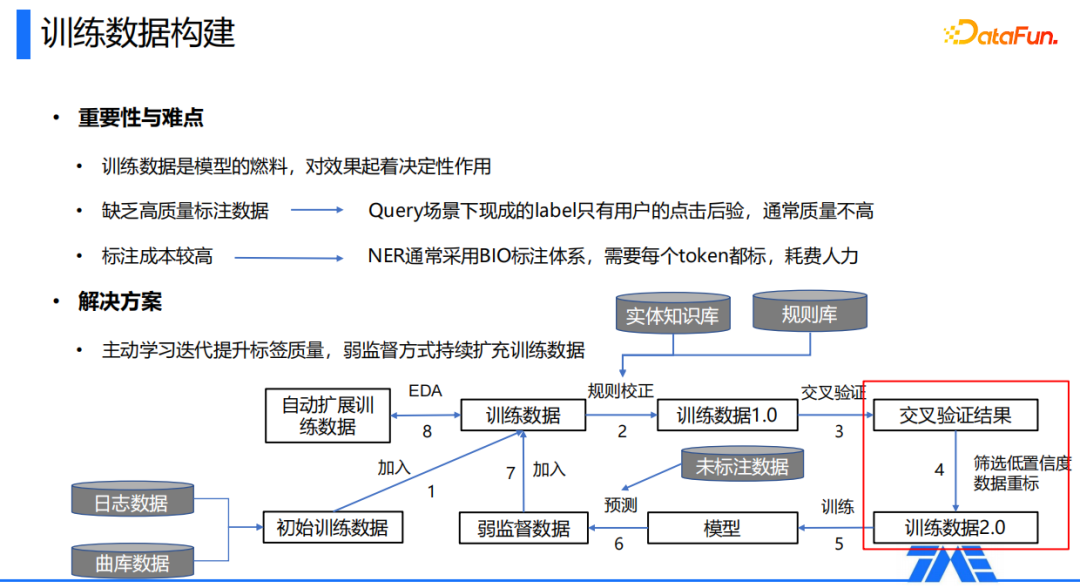
① 重要性与难点
训练数据是模型的燃料,对模型效果起着决定性的作用。在我们的应用场景中,训练数据构建主要有以下两个难点,第一个是缺乏高质量的标注数据,在query的场景下,只有用户query点击这样的label,且质量通常不是很高;第二个是人工标注的成本高,因为NER通常采用BIO这样的标注体系,每个token都需要打上标记,这种方式逐个去标非常耗费人力。
② 解决方案
我们通过主动学习迭代提升标签质量,同时构造弱监督数据去扩充训练数据量。首先我们根据用户的点击后验来构建一份质量不是很高的训练数据,再通过我们预制的一些规则模板对它进行校正,以及对一些明显有问题的label进行校正,得到一份可以用于训练模型的数据1.0。然后通过训练数据1.0,我们做一个交叉验证,从中来筛选出一些低置信度、模型不是很确定的数据,对这些数据进行重标。通过这样的方式,我们使用模型自动筛选出可能有问题的数据,减少人力标注的数量,得到一份经过清洗后的训练数据2.0。我们再去用训练数据2.0训练模型,利用这版模型去预测一些未标注数据,把这些外边数据作为一个弱监督的数据,将其加入到原始的实验数据中,从而构建了一个闭环的迭代过程,经过迭代后,模型训练数据的数量和质量上都有提升。
在迭代之外,我们还引入了EDA自动扩展训练数据,主要策略有实体替换、非实体片段替换、实体名扰动等。比如我们把一首片段中的歌曲名替换成另一首歌曲:来一首七里香→来一首吻别;把非实体片段替换:来一首七里香→播放七里香;实体名扰动:来一首七里香→来一首七七里香,因为我们NER在语音场景下也会有应用,而语音场景下有很多用户可能会说错歌曲名,通过实体名扰动构建类似数据,可以增加模型整体的鲁棒性。
03 用户Query NER模型
1. V1版
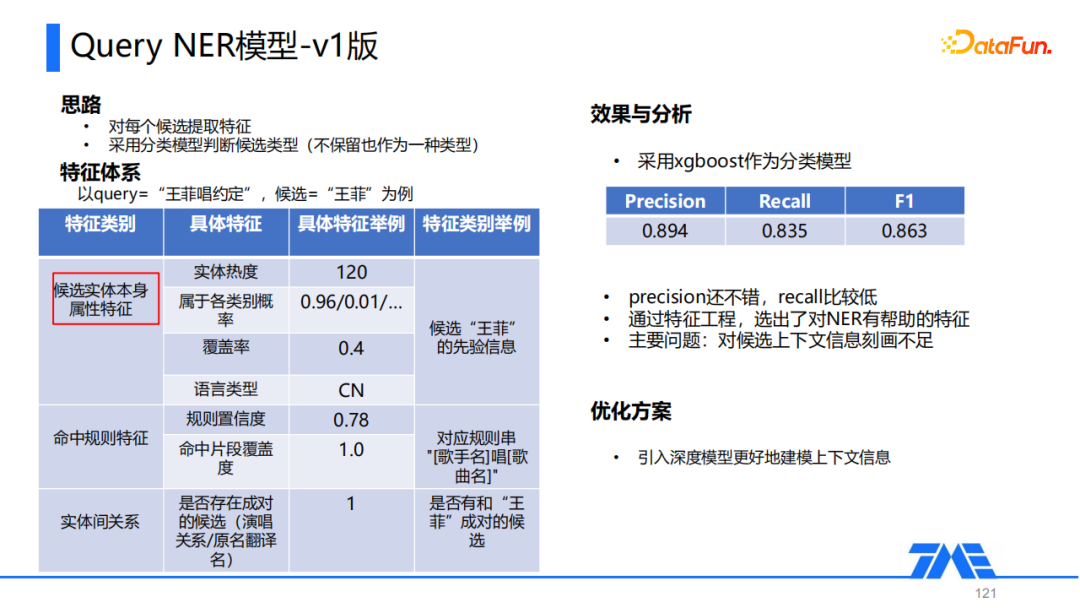
① 思路
前面提到了用户Query通常比较简短、信息比较少,因此我们第一版模型考虑对每一个候选去抽取出一些特征,然后采用传统的分类模型去判断每一个候选的类型,因为不是所有的候选都在最终正确结果中保留,因此不保留也作为一种类型。
② 特征体系
特征体系方面,以Query为例,主要提出以下三类特征,第一类是候选实体本身的属性,包括些热度、覆盖度、语言类型等;第二类是命中规则的特征,主要作用是通过人为统计的方式,给模型提供一些可能存在的上下文层面信息,因为Query没有显式引入上下文的信息;第三类是实体间的关系,主要包括一些成对的关系,因为在音乐领域经常有一些演唱,可以从中生成一些成对关系,比如王菲演唱过约定,我们就将(王菲,约定)这样的信息也加入到特征中。
③ 效果与分析
在构建特征后,我们采用了传统分类模型xgboost进行尝试,最终整体的precision为0.894,勉强达到了可用的水平,但是recall仅有0.835,没有达到可用的水平。这一版模型的主要意义就是我们通过传统的特征工程选出了一些对于NER具有帮助的特征,但我们没有显示地去引入候选的上下文信息。虽然Query的上下文信息不多,但还是存在一些的,因此我们后续的优化方案,就是通过深度模型去更好地建模上下文信息。
2. V2版

① 思路
V2版我们采用业界比较常见的思路,首先将NER转化为序列标注问题,将实体按照它所属的token以及位置来对实体的每一部分给出标注,比如说对于上图的Query,我们得到它对应的一个标注。
② 特征与模型
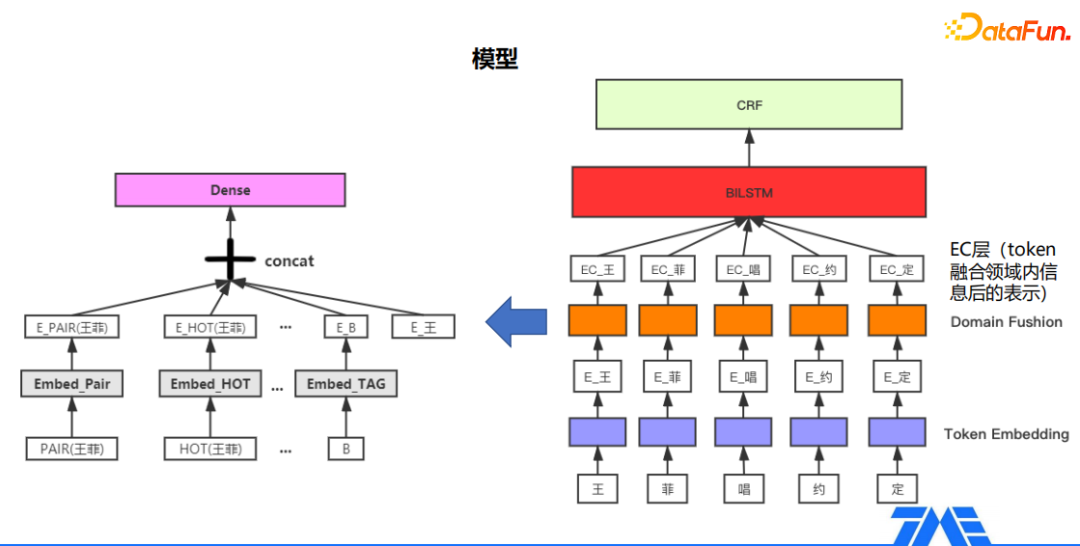
特征层面我们仍然采用了V1版中得到的特征,只不过加入特征的方式相比V1版有一些区别,我们将每一类特征对应到token本身,每一类特征都是一个特定的候选,把每一类特征加到其所属的图层中,最终每一个token会对应到多个类别的特征。
模型层面的话,我们采用了一个比较常用的解决方案,首先得到每个token对应的token embedding,然后经过上图橘黄色标注的Domain Fushion层,将每个token对应的多个特征拼接起来,得到token融合领域知识后的特征,最终经过BiLSTM+CRF编码和解码得到实体序列。
② 效果与分析

V2版的召回率相对V1版有明显的提升,我们去做了一些case分析,发现整体也是符合预期的。good case主要是扩召回一些query干扰信息比较多但上下文特征比较强的实体,比如上图第一个例子,在歌曲名“你的浅笑”前有非常多口语化的表述,V1版由于没有显示的引入文本层面信息,就无法识别出这类实体。对于第二个例子:花千骨主题音乐歌曲,因为V1版中我们通过模板来引入上下文信息,有一个模板是影视剧名+主题曲,这里只把“曲”换成“音乐”,模板就失效了,通过深度模型,我们可以学习到“曲”和“音乐”是近义词,这样就能够正确地识别出“花千骨”是影视剧名。
V2版也存在一些问题,最大的问题就是歧义大的实体识别不准,举两个例子。
来一个恋人主题曲郑颖娟的、帮我找下有没有东方红这首歌。第一个例子模型没有识别出“影视剧名=恋人”,主要原因就是因为“恋人”的影视意图很弱,我们提到恋人,第一反应是认为它应该是一个歌曲而不是影视剧。第二个例子是语音场景下的一个query,模型错误地识别出“歌曲名=有没有”,主要原因是因为“有没有”本身是一个热度比较高的歌曲,模型受到热度特征的干扰导致了误判。
因此我们需要针对问题的特点设计一个定制化的领域内信息融入模块来解决歧义的问题。我们首先需要解决候选实体类型的歧义,然后就是实体与常用表述之间的歧义,针对这两点问题,我们设计了V3版的模型。
3. V3版
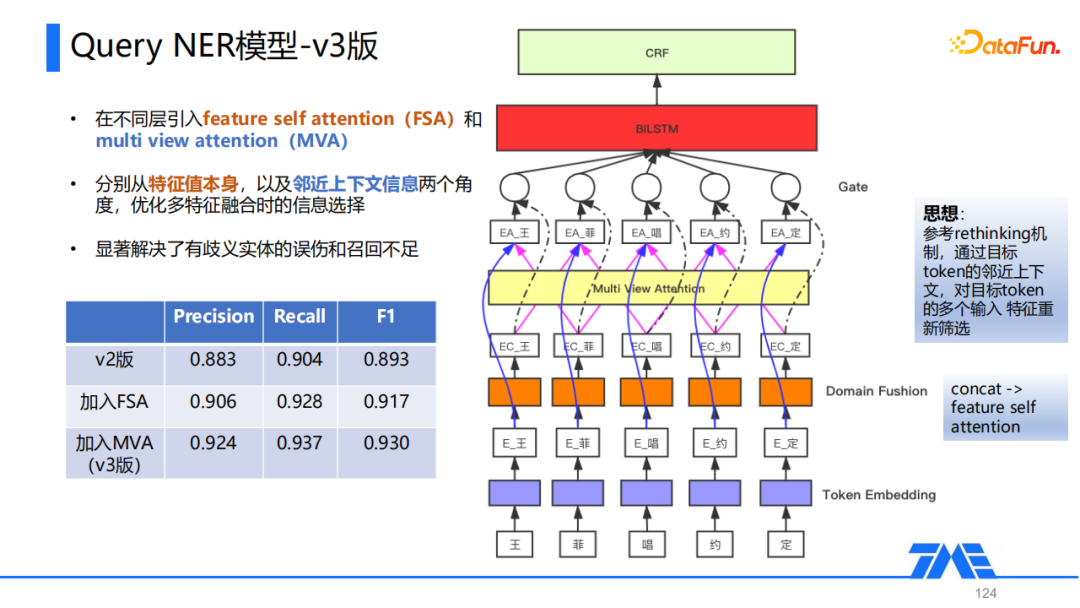
针对V2版的问题,V3版主要做了两个方面的优化。首先在融合外部知识的Domain Fushion层,我们把多个特征concat的方式改成采用feature self attention,通过attention机制去捕捉对于识别当前token更重要的一些特征。第二个优化点,在进入BiLSTM进行序列编码前增加了一个multi view attention层,它主要是基于NLP歧义知识融合中常用的rethinking机制的思想,通过目标token的临近上下文,对目标token的多个输入特征进行重新筛选,这样可以在一定程度上利用query中歧义较小的片段,对歧义较大片段信息融合中的错误进行一些校正。
这里我们通过在不同层引入feature self attention(FSA)和multi view attention(MVA),分别从特征值本身,以及邻近上下文信息两个角度,优化多特征融合时的信息选择,显著解决了有歧义实体的误伤和召回不足的问题。在做了这两个方面的优化后,V3版整体的precision和recall都有明显的提升,达到了一个比较可用的水平。
04 音乐文本NER模型
1. 特征抽取优化
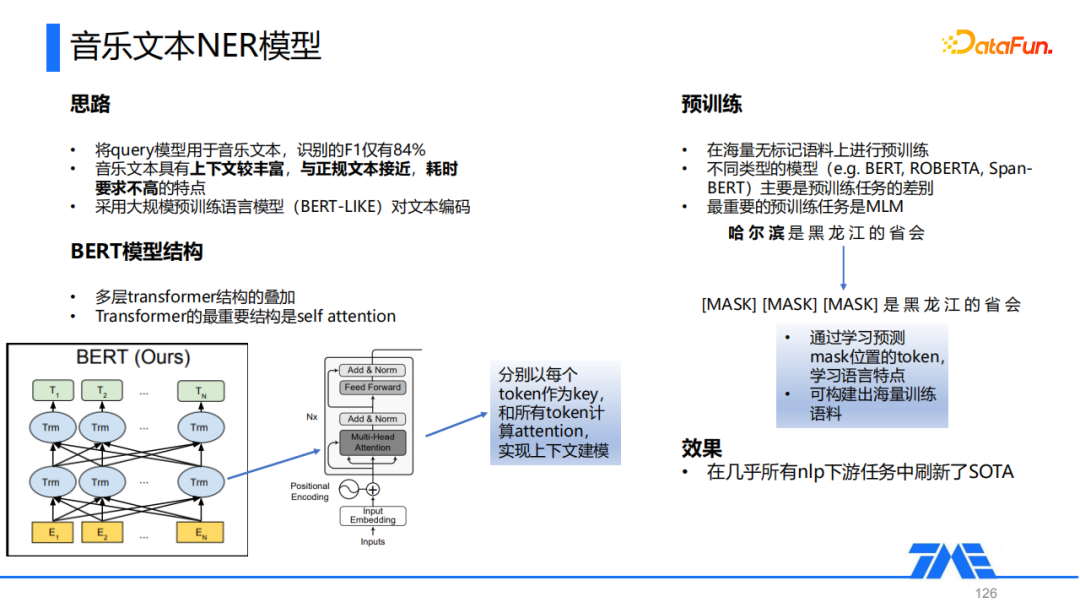
我们直接用从query中探索出的NER模型套用在音乐文本识别任务上,发现F1只有84%,分析发现主要是因为音乐文本的上下文相比query是比较丰富的,和正规文本更加接近。因此我们采用大规模训练语言模型(e.g. Bert)对文本进行编码,Bert是多层transformer结构的叠加,而transformer最重要的结构是self attention,关于bert的模型结构这里就不做赘述了。Bert通过在大规模无标记语料上进行训练,得到一个比较好的语言模型,不同类型的语言模型(e.g. BERT, ROBERTA, SpanBERT)主要是预训练任务的差别,其中最重要的预训练任务是MLM,它其实就是将文本中的一些token改成[MASK]这样的标记,然后通过模型去学习[MASK]位置的token,从而去感知语言的一些表达方式和特性,因此Bert几乎刷新了所有NLP下游任务的SOTA。
① 思路
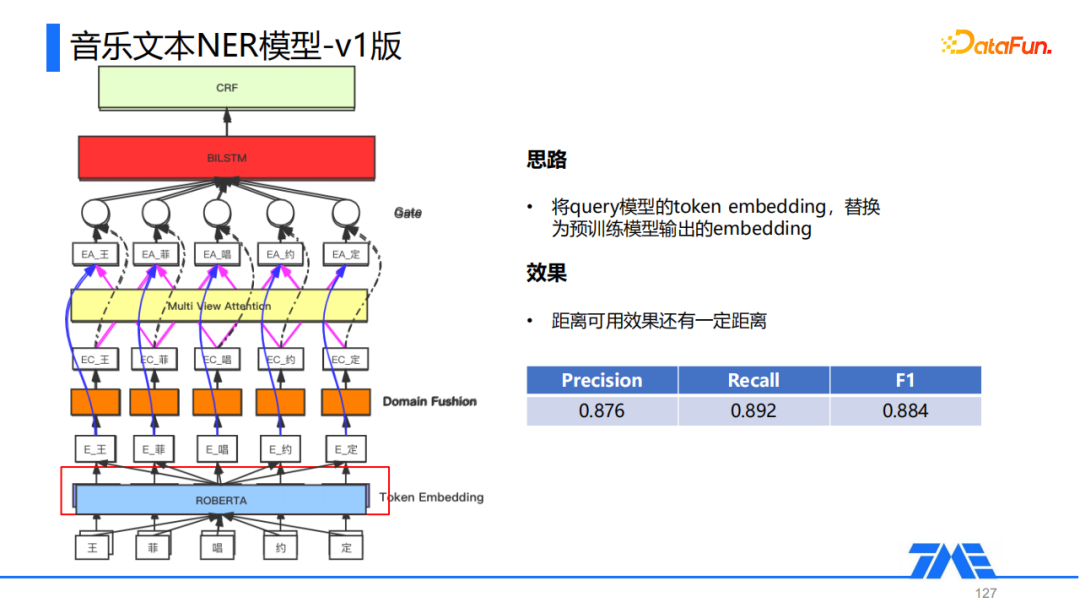
我们V1版的优化其实是比较简单的,就是将我们Query NER中采用的最终模型中的Token Embedding层替换成了ROBERTA,将原本上下文无关的很弱的Embedding表示替换成由ROBERTA得到的上下文相关且质量非常高的Embedding表示,其余后续模型结构不做任何改动,经过优化效果相比直接采用Query NER模型有一些提升,F1 score由84%提高到88.4%,但是整体未达到可用效果的要求。
② 问题分析
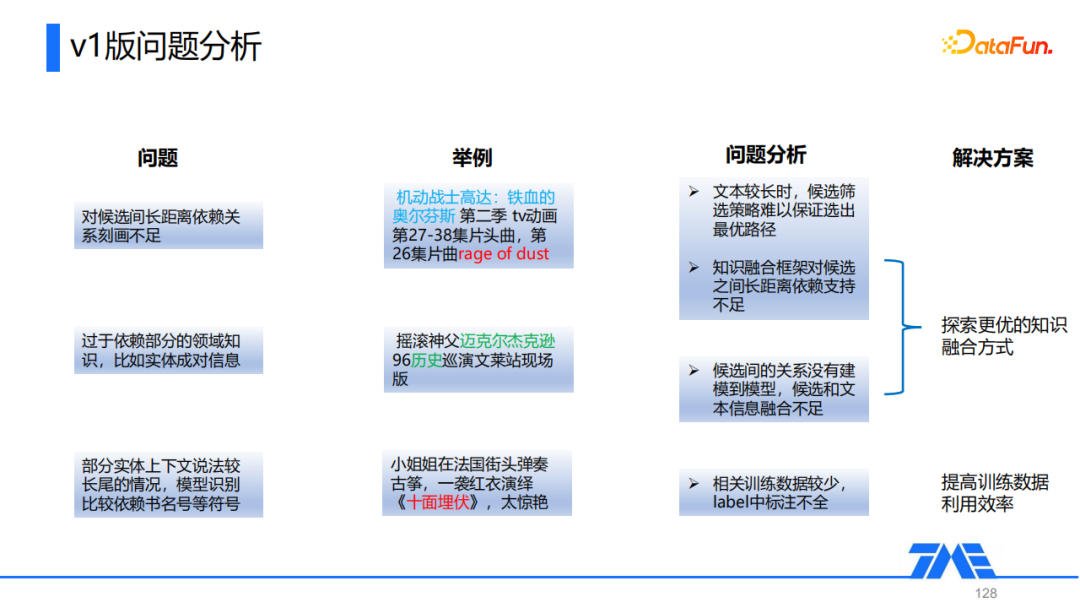
我们对于存在的问题做了一些比较详细的分析。首先第一点问题是对候选间长距离依赖关系刻画不足,比如上图第一个例子,《rage of dust》其实是影视《机动战士高达》的主题曲,但是由于两者在文本中的距离比较远,导致模型对于它们之间的关系没有很好的捕捉,造成这种情况的原因首先是我们的候选筛选策略难以保证选出的路径是最优的,其次就是知识融合框架对候选之间长距离依赖捕捉支持不足。
第二点是模型过于依赖部分的领域知识,比如实体间的成对信息,对于上图第二个例子,因为迈克尔杰克逊曾唱过一首歌《History》,它的翻译名就是历史,导致模型误识别出:歌曲名=历史,主要是因为我们没有显示地将候选词间的关系建模到模型中。
最后一点就是对于部分实体上下文说法较长尾的情况,模型识别比较依赖书名号等符号,比如对于上图第三个例子,如果这里我们将书名号去掉,可能模型就无法正确的识别出歌曲名为“十面埋伏”,主要原因是相关的训练数据比较少,并且label标注不全。
针对前两个问题,我们的优化方案是去探索一个更好的知识融合方式;对于第三个问题,我们主要通过提高训练数据利用效率解决。
2. 知识融合框架
目前工业界和学术界比较常见的知识融合框架主要有三大类,下面主要围绕这三类框架的典型代表,以及在我们任务上的知识融合优化展开阐述。
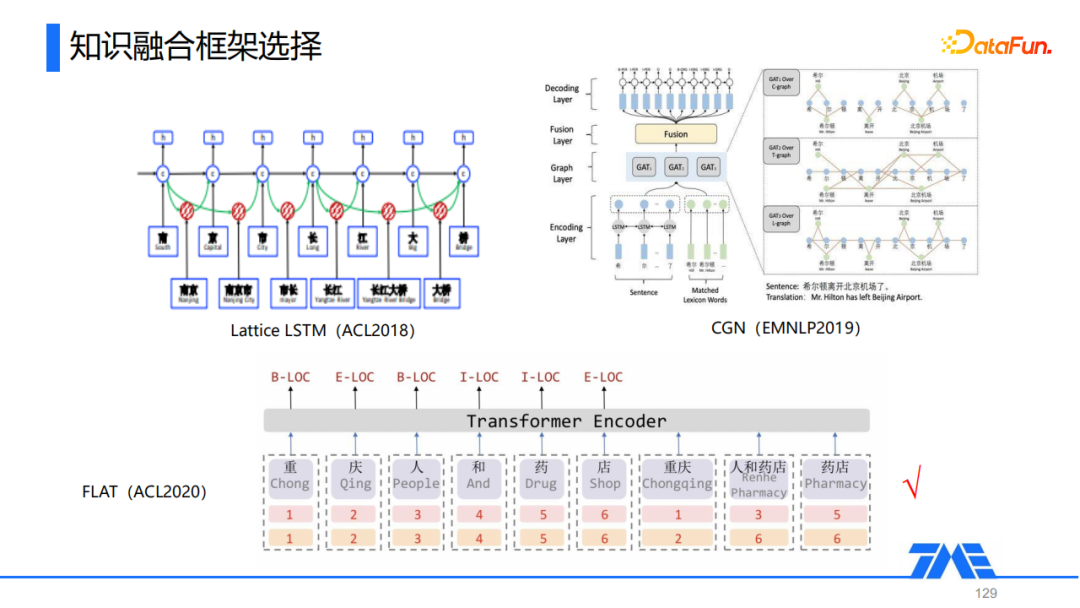
① Lattice LSTM
第一类以Lattice LSTM为代表,它通过对LSTM或GRU模型的结构进行一些修改,实现词/短语级别信息的引入。
② CGN
第二类以CGN为代表,它不修改原本的文本编码方式,在编码层后叠加一些图神经网络,实现引入更多粒度的信息。
③ FLAT
最后一类以FLAT为代表,这也是我们在音乐文本NER任务中最终选用的知识融合框架。
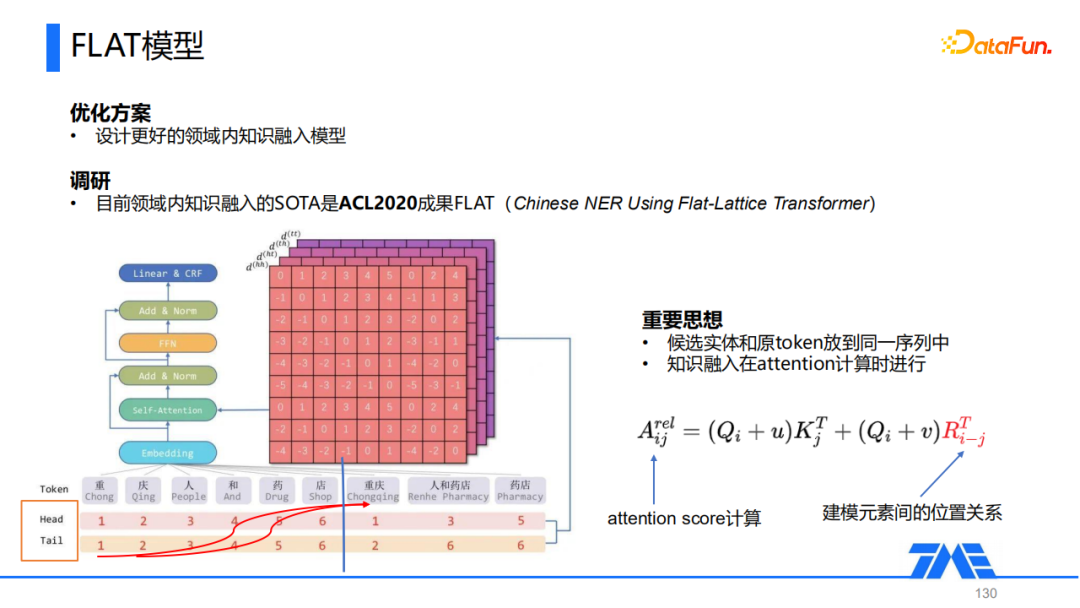
FLAT在transformer模型的基础上,引入多粒度信息(主要是词典信息),将文本中存在的一些词直接拼接到Token后面,得到了一个包含异质信息的序列。通过将词和token放在一个序列中,在Self-Attention计算时,词级别的信息就自然而然地融入到整个模型中,这样就不需要像CGN这样的模型,人为构建图表述候选和token之间的关联再通过GNN去编码,而是对attention score的计算进行修正,实现多粒度信息的引入。
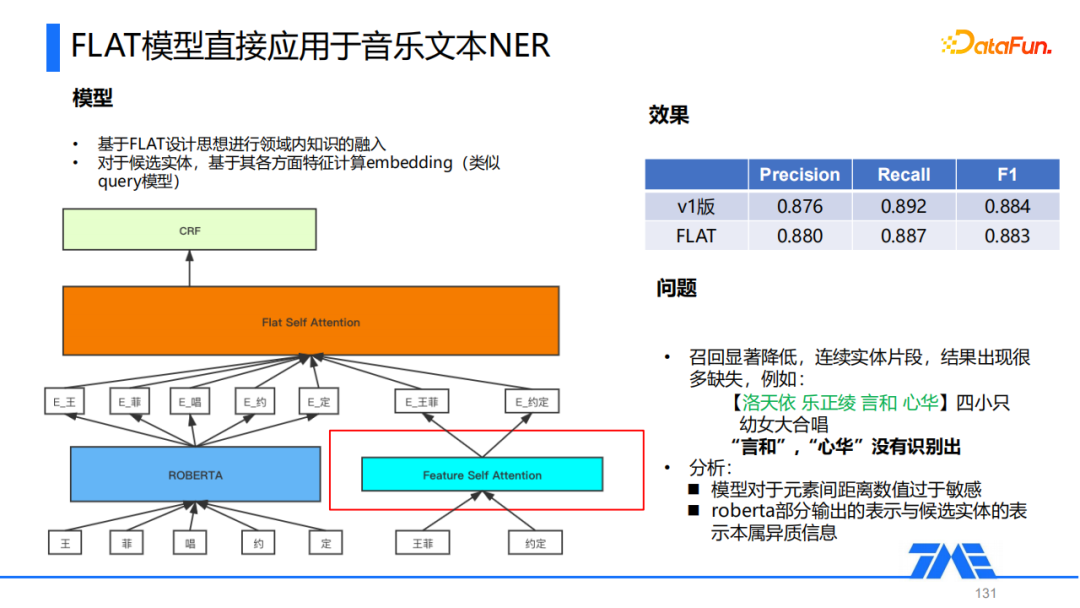
我们尝试直接将FLAT模型应用于音乐文本NER,对文本部分用ROBERTA来进行编码得到它的Token Embedding,对候选词部分采用与Query NER中一样的Feature Self Attention,对每个候选实体多个层面的特征组合,得到每个候选实体的Embedding,然后将Token Embedding和候选实体的Embedding拼接到一个序列中,后面再接一层Flat Self Attention得到融合后的表示,最后通过CRF对Token进行解码。
观察效果我们发现直接应用FLAT进行知识融合并没有明显的提升,F1 Score相比第一版还有一点下降。我们对一些case进行分析,发现召回显著降低,对于一些连续的实体片段,在结果中出现了很多缺失,比如对于这个例子:【洛天依 乐正绫 言和 心华】四小只幼女大合唱,这里其实有四个歌手,但是模型只识别出了其中的两个。我们通过一些实验,发现导致问题的主要原因是模型对于元素间距离的数值过于敏感,另外是由于ROBERTA部分输出的表示与候选实体的表示属于异质信息,因此我们在FLAT模型的基础上,结合这里的几个问题进行了一些优化。
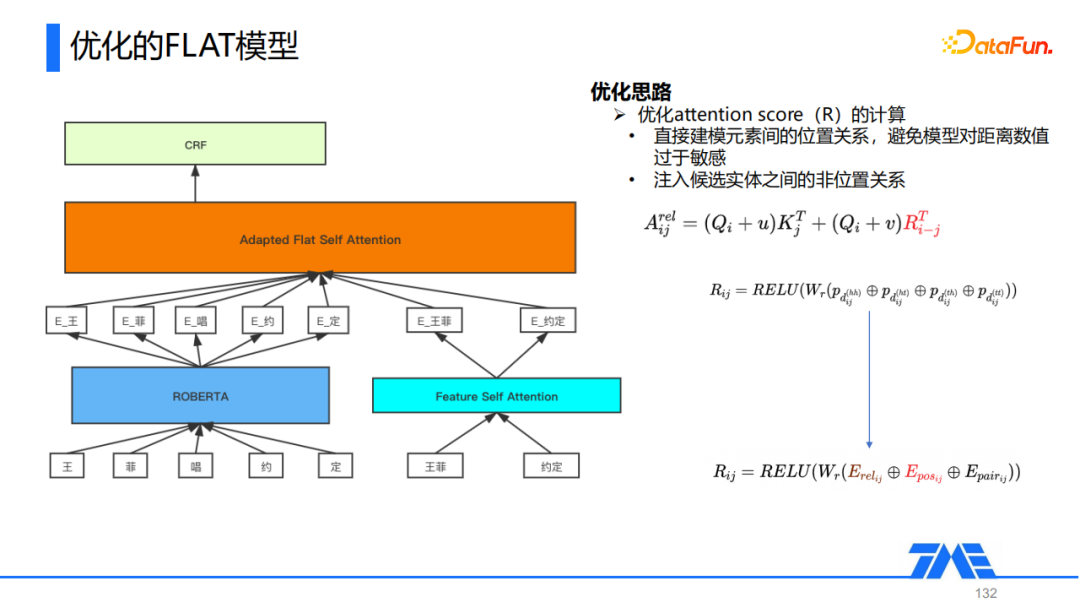
我们主要的优化点在于Attention Score的计算方式。原始的FLAT直接通过元素间的位置关系来建模,一共计算了四种不同的位置信息,分别是lattice的开始减开始,开始减结束,结束减开始,结束减结束。我们通过分析发现,当我们的训练数据质量还有数量都不是很足的时候,这样的设计方式可能会导致模型对于距离本身的一个具体数值产生依赖,因此我们对这种位置关系的计算方式进行了修改。首先我们显示地引入token与候选实体之间关系,比如依赖、包含、相交等关系,然后针对原始的四个位置信息,把它变成了一个position,通过它表示两个token在序列中最短的位置信息,通过它去建模两个元素之间的位置关系。此外我们还引入了一个pair的信息,主要目的是将一些非位置信息,比如候选实体间的成对,包括一些其他的关系引入到模型中,通过这几点优化,模型的效果有了显著的提升。除此之外,我们基于异构图网络的思想,对不同类型的节点先进行节点级别的信息聚合,再对不同类型作语义级别聚合。
3. 提高训练数据利用效率
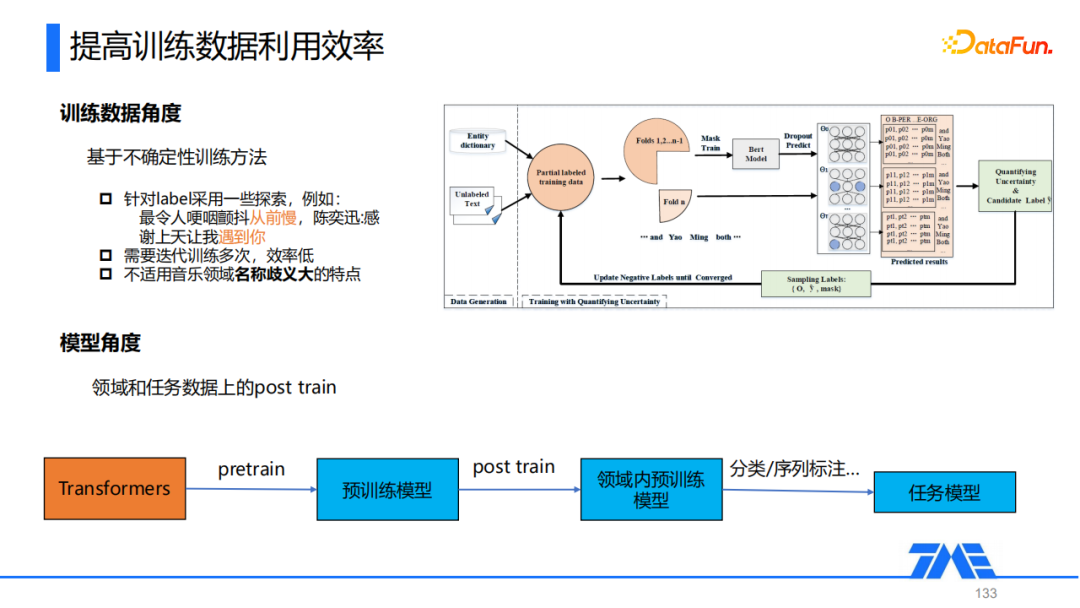
关于如何去提升训练数据的利用效率,业界比较常见的解决方案是从训练数据的角度出发,基于不确定性的方法去训练模型。整体思想是认为label本身存在漏标的可能,通过针对label来进行探索,把没有标注为实体部分改标为实体,然后进行模型的迭代训练。
在我们音乐文本NER的应用中,我们发现基于不确定性训练的方法主要有两个缺点,第一个是它需要进行多次的迭代训练,整体效率会比较低;第二点是因为音乐领域本身名称歧义非常大,这里可能会有一些不太合适的探索,会导致模型整体产生偏差,后面的修正也无法让它回到原来正确的方向上。因此在音乐文本NER任务中我们从模型的角度出发,通过领域和任务数据上post train来实现训练数据的利用效率。在得到预训练模型基础上,对领域和任务相关的一些数据进行一轮post train,得到一个领域内的预训练模型,再去做下游的NER任务,这个流程其实也是目前NLP任务整体的一个范式。
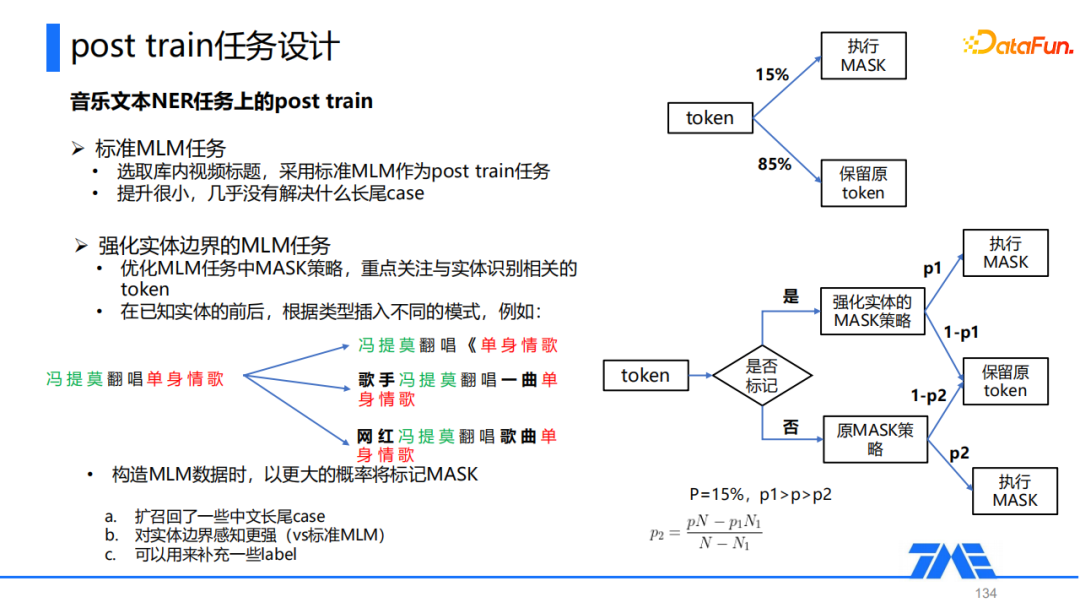
在post train任务设计的探索中,我们首先采用的是标准的MLM,即对于每一个token,以15%的概率把它制成mask,以85%的概率保留原token。我们选取了库内的一些视频
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E9%9F%B3%E4%B9%90%E9%9F%B3%E4%B9%90%E5%91%BD%E5%90%8D%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB%E6%8A%80%E6%9C%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


