腾讯音乐知识图谱搜索实践

分享嘉宾:Elvin 腾讯音乐 高级工程师
编辑整理:李一 中科雨辰
出品平台:DataFunTalk
导读: 近几年来,图数据在计算机领域得到了广泛的应用。互联网数据量指数级增长,大数据技术、图数据方面的应用增长很快,各家互联网大厂都在图数据分析和应用方面大量投入。为了让我们的搜索更加智能化,腾讯音乐也借助了知识图谱。今天和大家分享下腾讯音乐在图谱检索与业务实践方面的探索,主要包括以下几大部分:
- 音乐知识图谱介绍
- 图数据库选型
- 项目架构介绍
- 知识图谱搜索功能应用举例
- 总结与展望
01 音乐知识图谱介绍
首先和大家介绍下音乐知识图谱的相关知识。
1. 音乐数据分类
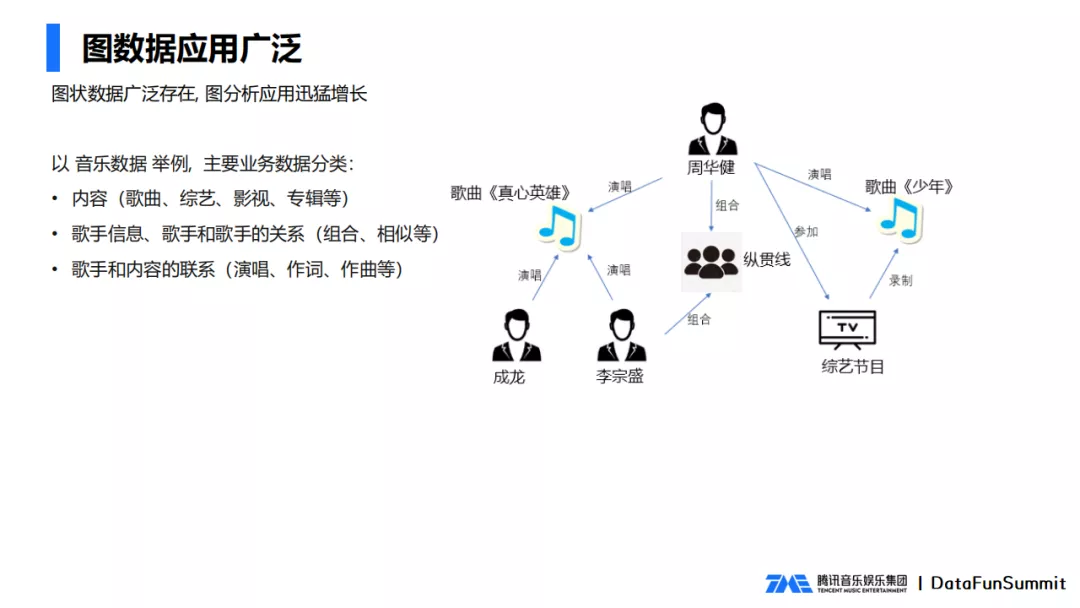
图状数据广泛存在,其中与音乐相关的业务数据主要有以下三类:
- 内容方面有歌曲、综艺、影视、专辑等;
- 歌手方面有歌手信息、歌手之间的关系,包括组合、相似等;
- 歌手和歌手内容之间的关系有演唱、作词、作曲等。
2. 音乐知识图谱的应用场景
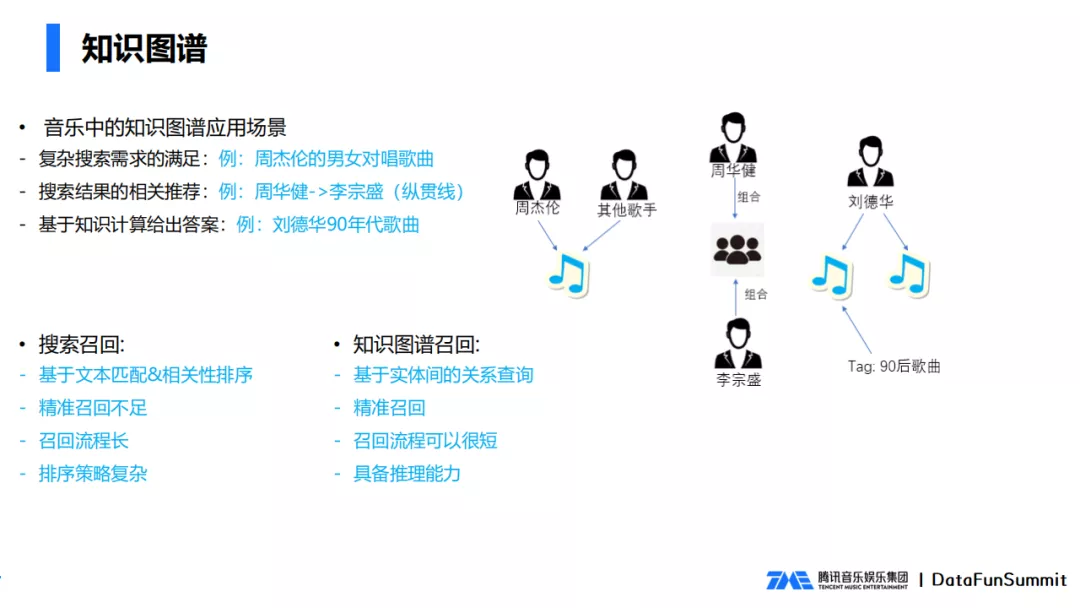
(1) 复杂搜索需求实现
音乐知识图谱不仅可以做简单的搜索,还可以实现复杂搜索需求。例如要查询周杰伦的男女对唱的歌曲有哪些,如果要实现这个查询,需要对周杰伦的歌曲进行一定的过滤,歌手的数量要等于2,另一位歌手的性别是女性,还要考虑基于播放量、歌手权重等等的排序。在传统关系型数据要实现这个功能很复杂。利用知识图谱就比较简单了,先找到歌手周杰伦,查找周杰伦的所有歌曲中满足2人合唱,另一个歌手性别是女性的,只要两跳就可以实现复杂的搜索查询。
(2) 搜索结果的相关推荐
可以根据搜索的关键词,查询图谱中的实体节点,根据实体节点查询出关联的节点,用关联的节点给出推荐的结果。例如用户搜索周华健,可以通过关联信息推荐出李宗盛。如果通过搜索引擎,很难推荐出李宗盛,而用知识图谱,只要两跳,周华健歌手到对应组合(纵贯线),从组合再到另一歌手李宗盛,只要两跳。
(3) 基于知识计算给出答案
可以根据知识图谱的计算来给出一些答案,通过图谱的关联信息,实体上下位信息,实体属性信息,查询出相应的答案。例如用户搜索刘德华90年年代的歌曲,用知识图谱的话,只要歌手刘德华,时间90年代歌曲,两个联合起来就可以得到结果。
3. 搜索召回和知识图谱召回优缺点
搜索召回,是基于文本匹配的,召回之后会涉及相关性排序,相对来说比较复杂,精准度不足,可能过度召回。搜索召回的流程比较复杂,排序策略也相对复杂。
知识图谱召回,是基于实体之间的关系进行查询,可以做到精准召回,也没有过召回,召回的流程可以很短,也就是几条图查询的语句。另外,知识图谱还具备一定的推理能力。
02 图数据库选型
要实现图查询,首先得做图数据库的选型。
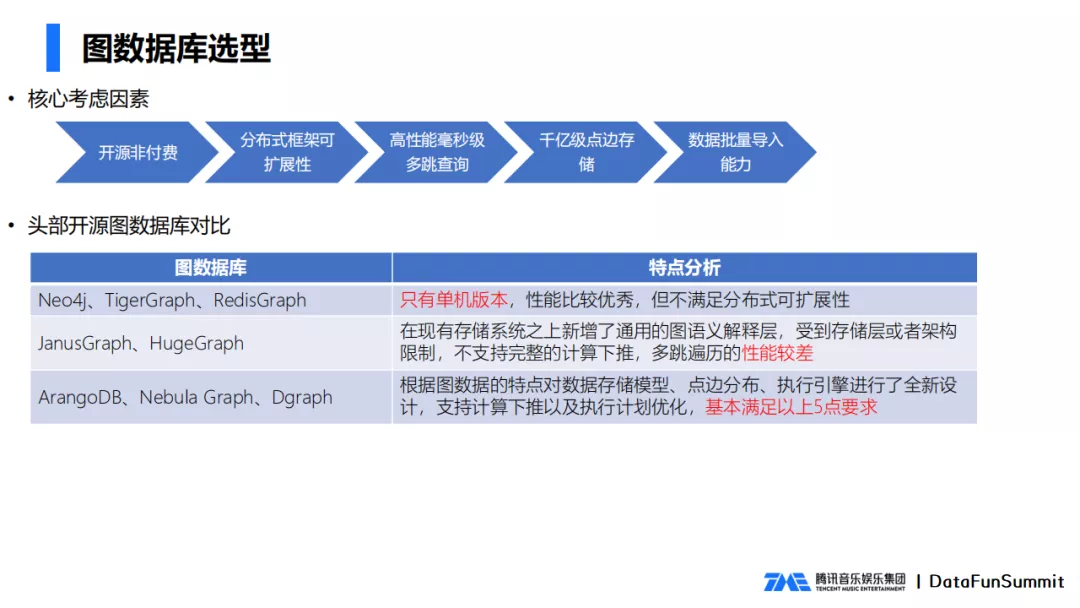
图数据库的选型,需要考虑以下几点因素:
- 开源非付费 ,考虑到成本及源码可控性,选择拥抱开源;
- 分布式框架可扩展 ,随着数据的增加和减少,后台必须是可扩展的;
- 高性能毫秒级多跳查询 ,要做到毫秒级的在线响应;
- 支持千亿级规模数据量 ;
- 支持数据批量导入导出 。
我们对比了8个数据库,对优缺点进行了分析,对这些数据库进行了分类:
- 第一类,以Neo4j为代表的,只有单机版本,性能比较优秀,但是不满足分布式可扩展性要求。Neo4j的商业版本支持分布式,但是却是收费的。
- 第二类,JanusGraph、HugeGraph这类数据库,支持分布式可扩展的,他们的共同特点是在现有的图谱上增加了通用的图语义解释层,受到存储层架构的限制,存储层是外部数据库实现,不支持计算下推的功能,导致性能较差。
- 第三类,以NebulaGraph为代表,这一类数据库都实现了自己的存储层,支持计算下推,做了效率上的优化,性能提升很多。
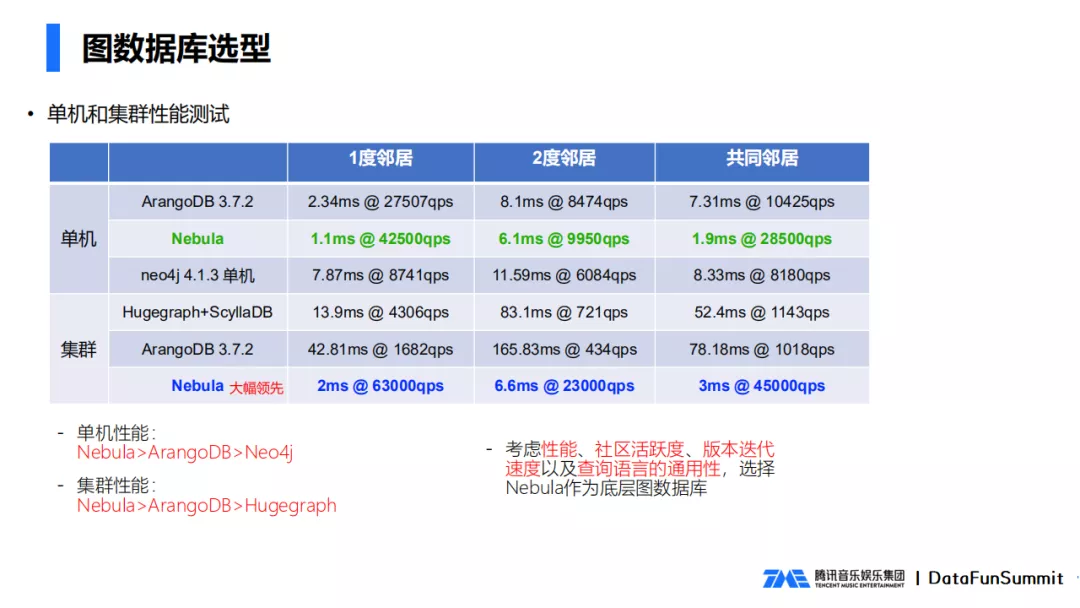
从上图看到综合性能测试数据。我们通过1度邻居(跟点直接相连的点),2度邻居,共同邻居,这三个方面来对数据库性能进行测试,可以看到Nebula不管是单机性能,还是集群性能,都要远超于其他竞品。考虑到性能,社区活跃度,版本迭代速度,语言上的通用性,我们最终选择了Nebula数据库做为我们项目的图数据库。
03 项目架构介绍
1. 在线层
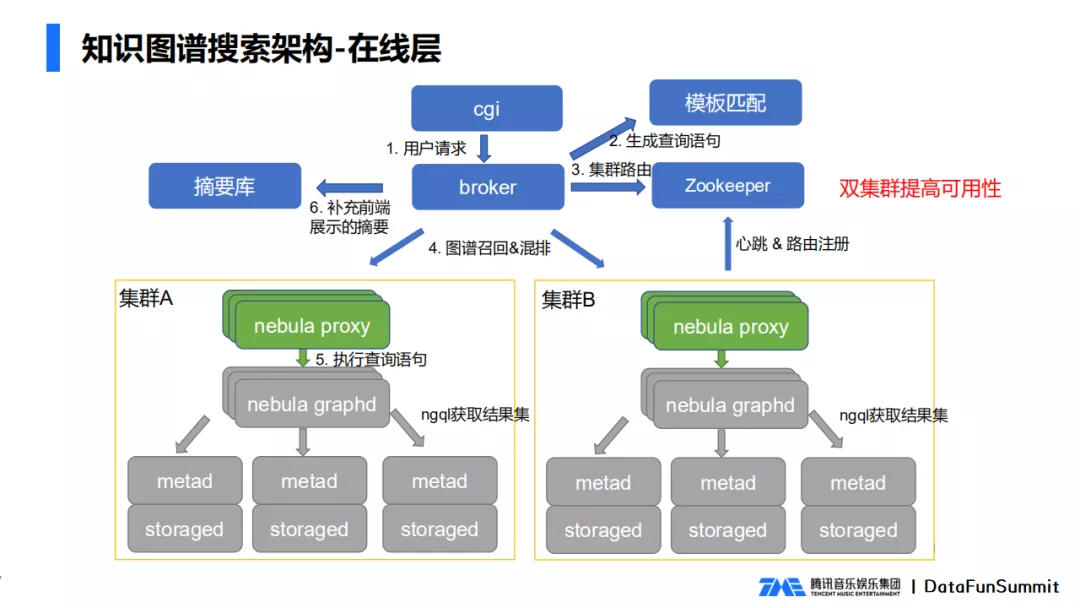
包含以下模块:
- Storaged 负责具体数据的存储,包括点数据、边数据,以及相关的索引;
- Metad 负责存储图数据的meta信息,例如数据库的schema、addition等;
- Nebula graphd 负责数据计算的逻辑层,是无状态的,可以进行平行扩展,内部执行计算引擎来完成查询的整个过程。
- Nebula proxy 是我们新增的模块,作为整个nebula模块的代理层,可以接受外部的命令,并对图数据进行操作,包括图的查询,更新,删除。另外,nebula proxy也负责协议的转换,集群的心跳和路由注册。
由于单集群有重建数据的需求,也为了防止机房故障,我们选择双集群来支撑整个服务的可用性。
在线层请求处理的流程为,cgi在接收到用户请求后,将用户请求传给broker模块,broker请求模版匹配生成相应的图查询语句,从Zookeeper中提取可用的集群,将查询语句发给nebula proxy进行图谱召回,nebula proxy将具体的查询语句传递给nebula graphd, nebula graphd负责执行最终的语句,然后把结果返回给broker层,broker层补充一些前端显示摘要后,将数据返回给前端做展示。
2. 离线层
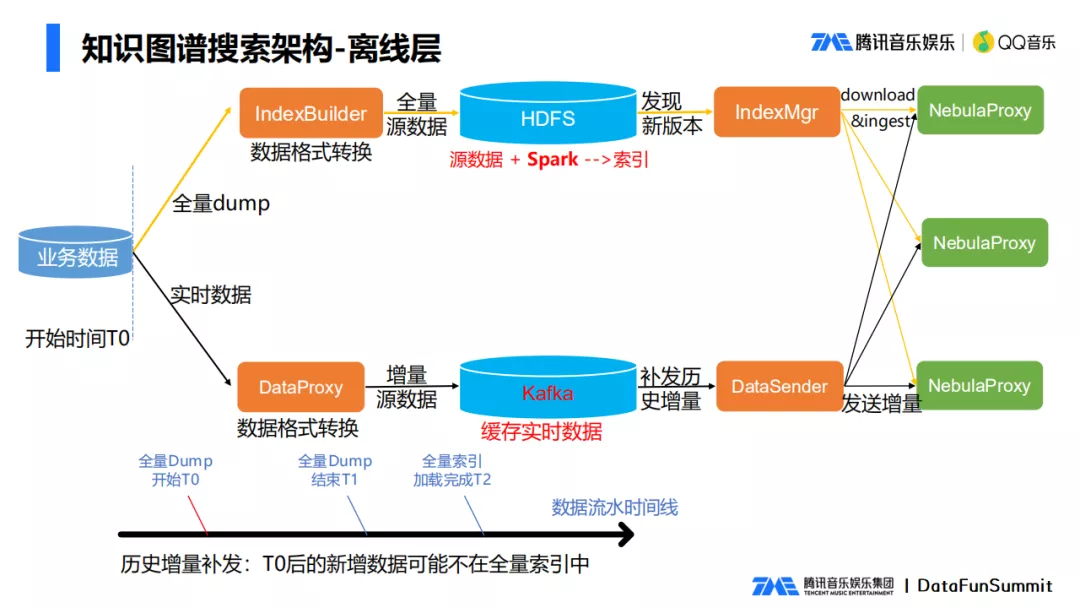
音乐数据有实时的新增数据,例如新增发行的唱片,还有全量数据的更新,所以我们选择了全量加增量的数据层方案。
(1) 全量数据生成方案
音乐很多数据存在数据库中,先将数据从DB中dump出来后,由IndexBuilder模块将数据格式转换为所需的格式后形成一个全量的源数据,将全量的源数据上传到HDFS后,通过运行spark任务,把数据转为Nebula底层所需的数据文件,IndexMgr发现有新的常量数据生成后,将数据文件下载下来,将全量数据加载到NebulaProxy,这样全量数据就生成好了。
(2) 实时数据的生成
每隔一段时间,通常是几分钟,将几分钟之内的业务修改数据dump出来后,转为特定的格式,形成一个增量的源数据,增量的源数据存入到Kafka里面,可以用于数据的重发和恢复,DataSender从Kafka队列里面拉取到最新的数据,通过NebulaProxy发送到集群,这样增量数据就生效了。
这里涉及到了一个增量补发的问题,因为存量过程dump过程中要耗费很长时间,可能要花几个小时,在全量数据dump过程中也有新的增量数据,这期间的增量数据可能并没有进入到全量的数据当中。所以这里需要进行一个历史增量的补发,从T0后(全量同步开始时间)的新增数据,不在全量数据中,需要将T0之后的�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E9%9F%B3%E4%B9%90%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E6%90%9C%E7%B4%A2%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


