腾讯音乐全民歌推荐后台架构
分享嘉宾:davidwwang 腾讯音乐 | 基础开发组副组长
编辑整理:梁尔舒
出品平台:DataFunTalk
系列文章 : 腾讯音乐:全民 K 歌内容挖掘与召回
导读: 首先介绍一下我们业务背景,腾讯音乐集团,于2018年是从腾讯拆分独立上市,目前涵盖了四大移动音乐产品,像包括QQ音乐,酷狗,酷我音乐以及全民K歌四大产品,现在总的月活用户量已经超过了八亿,其中全民K歌和其他三款APP有显著的不同,我们是以唱为核心,在唱歌的功能上不断衍生出了一些音乐娱乐的功能以及玩法,当前的月活规模也在1.5个亿以上,我们团队在全民K歌APP中负责各个场景的推荐。
本篇文章将会给大家介绍一下全民K歌推荐系统在工程上的一些实践,整篇分享分为3个部分: 首先介绍下K歌推荐后台架构;其次根据推荐的整体流程,从召回、排序、推荐去重三个方面分别介绍下K歌的相关实践; 最后介绍下推荐相关的Debug系统。
01 K歌推荐后台架构
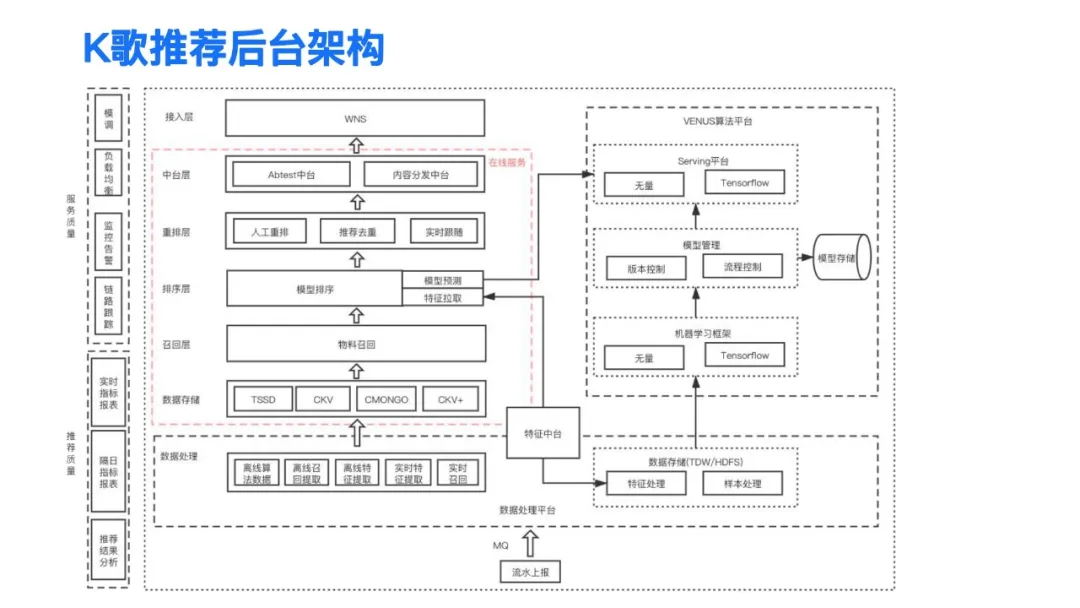
K歌推荐的后台架构整体可以分为在线和离线两个部分,离线的部分主要依赖两个平台:数据处理平台和VENUS算法平台。
- 数据处理平台:这里主要是依赖于腾讯内部的太极,还有t等一系列的用于大数据处理的平台组件,使用这些组件来进行离线的数据处理、样本处理、特征处理,算法训练等一系列算法相关的工作。
- VENUS算法平台,主要是针对那些需要进行线上提供服务的算法,提供了一个从离线训练到在线服务的一站式的管理工具,同时它实现了一个基于类似tensorflow的参数服务器的功能,可以支持大规模模型的在线训练和线上预测的功能。
位于我们数据存储层之上的是在线的部分,包括召回层、排序层和重排层,排序层根据业务复杂度的不同,又可以进一步分为精排层和粗排层,在这三层之上是我们的中台层,它包括了我们整个内部的abtest平台,内容分发平台等相应的一系列的平台组件。除此之外还有我们的服务质量监控,以及我们的推荐质量监控,推荐Debug的一些辅助工具等一些支持系统。
接下来主要会对整个推荐的在线服务相关的模块做一些介绍。
02 召回
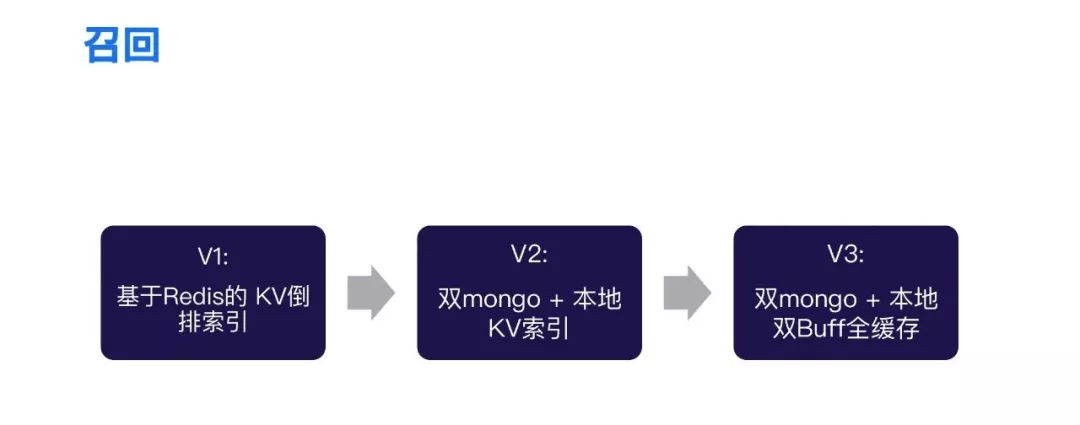
首先,要介绍的是我们的召回部分,在整个K歌的实践中,其实大概经历了三个阶段的演进,在业务的初期流量比较小的情况下,为了支持业务的快速上线,我们主要采用的是一个基于Redis的KV倒排索引的方案,后期随着整个业务的逐渐放量,还有我们整个的召回的路径也越来越多,所以V1版的方案,它暴露出来了两个问题,首先第一个就是说召回越来越多,对于频繁修改,导致整个开发效率是比较低的,对于人力的成本投入也是比较高。第二个就是线上采用了对远程分布式Redis直接拉取的方案,那么对于Redis存储压力是比较大的。为了解决上面两个问题,我们后来演化到了V2版本的方案,是一个基于双mongo和本地KV缓存的方案,通过本地索引解决了性能问题,但它还会存在另外一个问题,因为我们采用的是一个懒加载的本地Cache方案,所以说它会存在首次不命中的一个问题。为了解决这个问题,我们在V2版的方案上要进一步迭代到V3版的方案。V3版方案是基于双mongo和本地双buffer全缓存的一个方案。下面来对这三个方案来做一一的介绍。
1. 召回V1:基于Redis的KV倒排索引
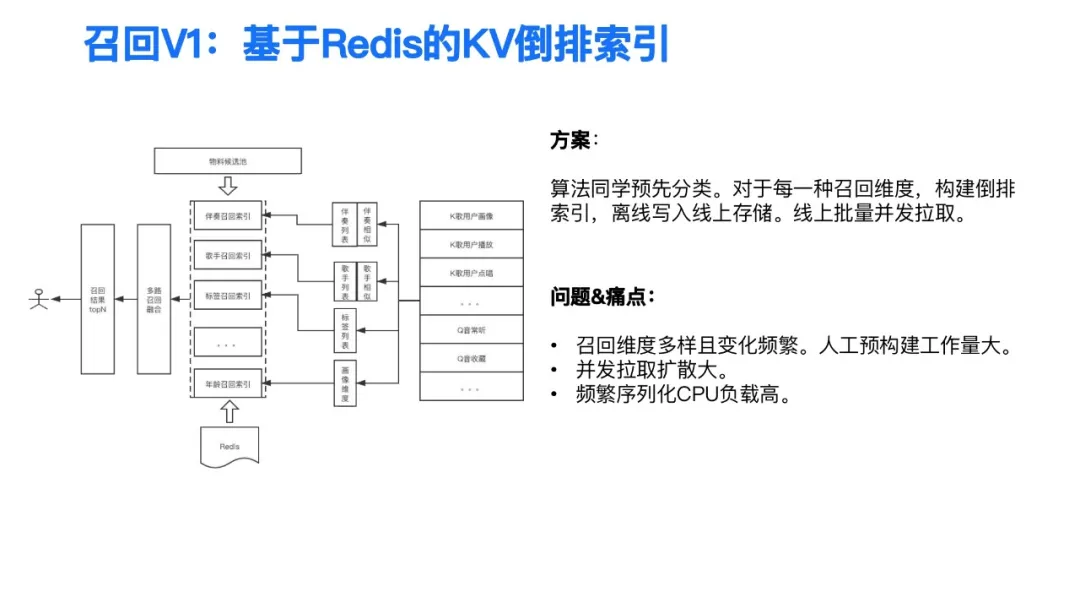 首先是基于Redis的KV倒排索引的方案。这个方案的实现是比较简单的,简单来说就是算法的同学会对每一个召回做一个预先的分类,对于每一个召回维度构建相应的倒排索引,将离线的数据写入到线上,线上服务采用的是一个批量并发拉取远程Redis KV的方式做召回。
首先是基于Redis的KV倒排索引的方案。这个方案的实现是比较简单的,简单来说就是算法的同学会对每一个召回做一个预先的分类,对于每一个召回维度构建相应的倒排索引,将离线的数据写入到线上,线上服务采用的是一个批量并发拉取远程Redis KV的方式做召回。
这个方案它的问题是什么?首先随着业务复杂度的增加,整个召回的维度它是非常多样的,而且我们不断地做abtest的实验,它整个召回的变化也是比较频繁的,这样人工构建的一个方案对于整个的开发工作量是非常大的,而且后续非常难以维护。然后第二个问题是在线是采用了直接拉取,并没有增加一些缓存的一些逻辑在里面,在召回这个阶段,用户的请求大概可以达到1比100以上的一个请求放大,对于整个Redis后端的存储压力以及存储成本是相对比较高的。另外在线上的存储采用了一个序列化的存储协议,对于序列化的数据,我们在拉取回来之后,必然要涉及到一个反序列化,那么频繁的反序列化也会导致我们整个CPU的负载会偏高。那么针对这三个问题,进行了第二版的方案优化。
2. 召回V2: 双mongo + 本地KV索引
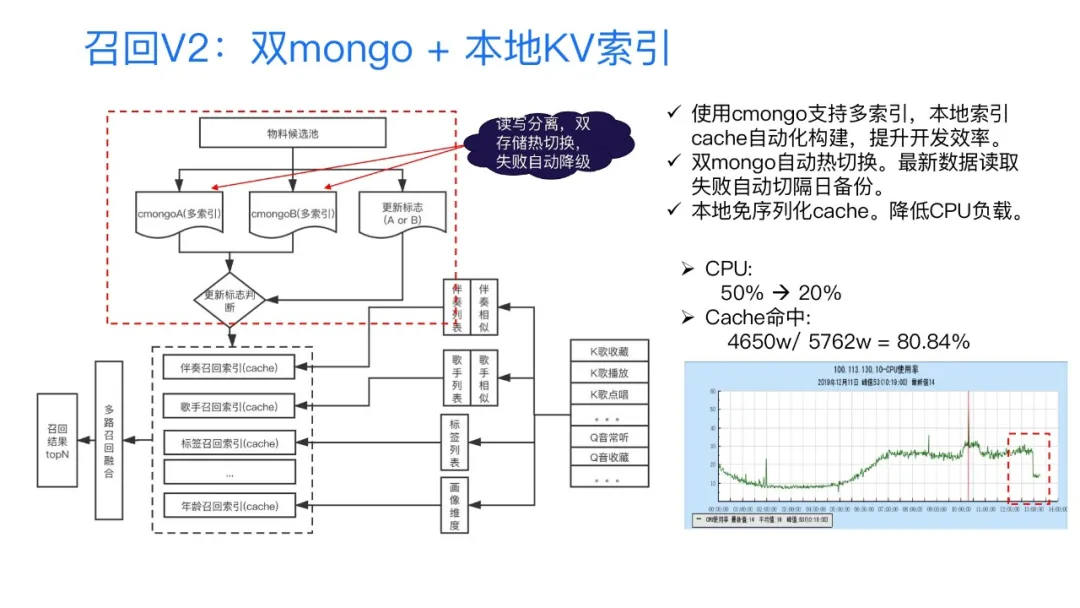 第二版的方案利用cmongo的多索引特性和本地索引Cache的自动化构建,提供了自动化的索引构建和自动化的拉取的能力,解决了前面所说的整个索引构建开发复杂度比较高的问题。另外对于双mongo,实现了自动热切换的功能,这两个mongo之间如果最新的数据出现失败的情况下,它会自动去切换到一个隔日的备份,本质上是一个降级的逻辑。另外采用双buffer,也是对于当日和隔天数据的一个解耦。第三个问题就是前面说的CPU的问题,我们解决的一个方案是在Cache组件的选取里面,选取了一个本地的免序列化的一个Cache组件,来降低我们的CPU的一个负担。那么整个V2版的方案在上线之后,我们在CPU的性能上提高了一倍,在Cache命中率上达到80%。当然这个地方还有一个可以改进的点,我们在个别场景有使用,就是说如果能搭配到前端的一个一致性Hash请求的话,那么整个Cache的命中率可以达到90%以上。
第二版的方案利用cmongo的多索引特性和本地索引Cache的自动化构建,提供了自动化的索引构建和自动化的拉取的能力,解决了前面所说的整个索引构建开发复杂度比较高的问题。另外对于双mongo,实现了自动热切换的功能,这两个mongo之间如果最新的数据出现失败的情况下,它会自动去切换到一个隔日的备份,本质上是一个降级的逻辑。另外采用双buffer,也是对于当日和隔天数据的一个解耦。第三个问题就是前面说的CPU的问题,我们解决的一个方案是在Cache组件的选取里面,选取了一个本地的免序列化的一个Cache组件,来降低我们的CPU的一个负担。那么整个V2版的方案在上线之后,我们在CPU的性能上提高了一倍,在Cache命中率上达到80%。当然这个地方还有一个可以改进的点,我们在个别场景有使用,就是说如果能搭配到前端的一个一致性Hash请求的话,那么整个Cache的命中率可以达到90%以上。
V2版的方案中,在本地Cache里其实采用了一个懒加载的方案,就会导致首次不命中的问题,不过在一般的情况下不会有太大的问题,但是在业务的高峰期它就可能有问题,在业务的高峰期可能会有零星的线上的报警,还可能会出现一些请求的毛刺。
3. 召回V3: 双mongo+ 本地双buff全缓存
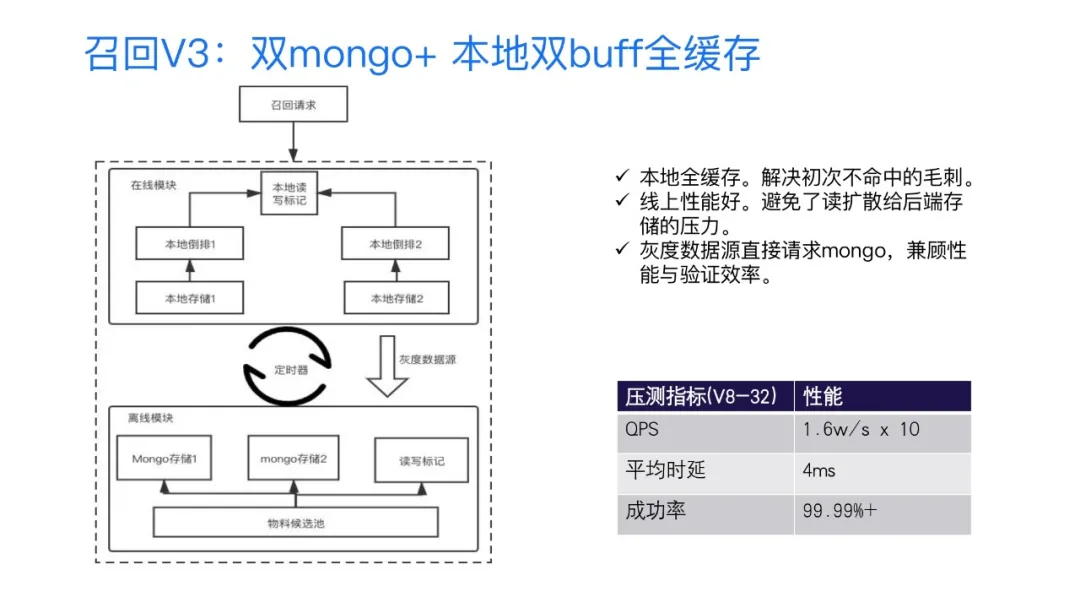 为了解决这样的一个问题,我们V2版方案的基础上,我们又构建了V3版的方案——双buffer+本地全缓存的一个方案,和V2版相比只有在线模块有一些变动,在线模块的变动的主要的变动,就是说将mongo存储的拉取采用了一个定时器来自动化定时更新的一个方案,更新的周期是大概是分钟级。OK。另外的话就是在本地全缓存的Cache,也是采用了一个buffer和自动热切换的一个方法,这样做核心要解决的一个问题,首先是能够读写分离,因为整个Cache组件它本身是有锁的,读写分离的话就可以对线上请求来说只有读而没有加锁的问题,可以达到更高的一个性能。另外的话就是整个数据存储之间的一个解耦。可以在整个图的左边看到,除了定时器的更新,其实还保留了一个灰度数据源的一个通路,这个通路会直接使线上请求从远程mongo数据源召回,因为对于我们做搜索推荐的来说,肯定都会有这样的一个场景,就是说我们做了一堆的ABtest的实验,其实我们真正能够推到线上的可能也就不到50%,如果我要对每一个相应的一个实验都要做一个全缓存的定时器的,从开发工作量上来说会变得很大。而且像ABtest这种一般都是基于小流量的实验,只有在最终验证成功之后,才会去进一步的放量这种小流量的实验。对于小流量的实验直接请求mongo源,其实性能上是完全可以支持的,因为如果只是读的话,经过测试,其实是可以支持到至少十几万的TPS的一个访问量,所以说没有任何问题。整个的方案在上线之后,我们进行了一个压测,对于一个八核32G的机器,我们大概亚特的一个新的数据是这样的,就是说如果我们以10台一组去请求后端的话,我们大概的QPS在单台机器上可能达到一个1.6万,而整个的平均时延从V2版方案的十几毫秒,大概能降低到四毫秒左右,整个成功率达到4个9以上了,完全满足我们整个服务的性能要求。
为了解决这样的一个问题,我们V2版方案的基础上,我们又构建了V3版的方案——双buffer+本地全缓存的一个方案,和V2版相比只有在线模块有一些变动,在线模块的变动的主要的变动,就是说将mongo存储的拉取采用了一个定时器来自动化定时更新的一个方案,更新的周期是大概是分钟级。OK。另外的话就是在本地全缓存的Cache,也是采用了一个buffer和自动热切换的一个方法,这样做核心要解决的一个问题,首先是能够读写分离,因为整个Cache组件它本身是有锁的,读写分离的话就可以对线上请求来说只有读而没有加锁的问题,可以达到更高的一个性能。另外的话就是整个数据存储之间的一个解耦。可以在整个图的左边看到,除了定时器的更新,其实还保留了一个灰度数据源的一个通路,这个通路会直接使线上请求从远程mongo数据源召回,因为对于我们做搜索推荐的来说,肯定都会有这样的一个场景,就是说我们做了一堆的ABtest的实验,其实我们真正能够推到线上的可能也就不到50%,如果我要对每一个相应的一个实验都要做一个全缓存的定时器的,从开发工作量上来说会变得很大。而且像ABtest这种一般都是基于小流量的实验,只有在最终验证成功之后,才会去进一步的放量这种小流量的实验。对于小流量的实验直接请求mongo源,其实性能上是完全可以支持的,因为如果只是读的话,经过测试,其实是可以支持到至少十几万的TPS的一个访问量,所以说没有任何问题。整个的方案在上线之后,我们进行了一个压测,对于一个八核32G的机器,我们大概亚特的一个新的数据是这样的,就是说如果我们以10台一组去请求后端的话,我们大概的QPS在单台机器上可能达到一个1.6万,而整个的平均时延从V2版方案的十几毫秒,大概能降低到四毫秒左右,整个成功率达到4个9以上了,完全满足我们整个服务的性能要求。
03 排序
排序部分主要介绍三点:特征平台、特征格式的选择、特征聚合与模型预测框架。
1. 特征平台
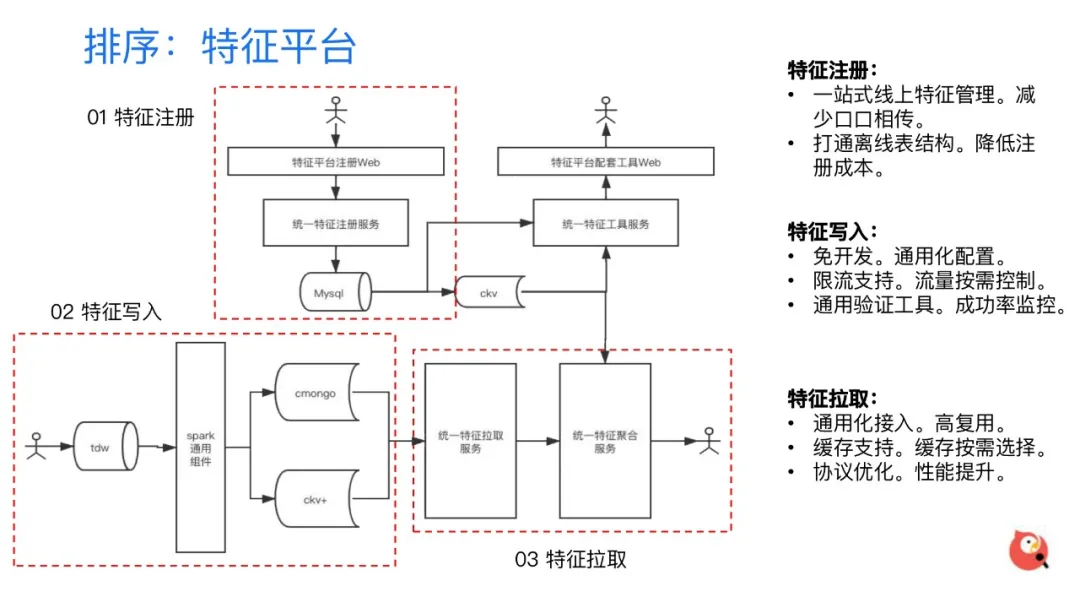
特征平台这边主要解决的是特征管理的问题,在最初的时候大家都是自己去构造特征然后去上线,那会导致特征散落在各个地方,不利于统一维护,特征复用依赖于大家口口相传,管理和维护成本是非常之高的。整个特征平台主要包含三个大的模块:特征注册、特征写入、特征拉取。在特征注册部分主要是提供了一个一站式的特征管理界面,这样就减少了前面所说的口口相传的一个问题,另外就是将离线的数据和在线的存储做了一个打通,减少了相应的特征注册成本,提高注册的效率。在特征写入这个阶段,我们是采用了一个组件化的开发方式,提供一个专用的免代码开发的写入组件,只需要相关的同学完成配置之后,就可以将相应的数据自动导入到线上的存储里,同时导入时支持了相当于限流的一个工具,可以支持的流量的按需控制。同时还开发了一些配套的通用验证工具和一些成功率相关的监控。最后对于在线服务的特征拉取这一块,首先当然是要存储结耦,于是提供了一个通用化的存储协议来进行存储。另外在特征聚合框架内提供一个可配置的缓存支持,可以按需来进行选择。另外就是特征格式协议选择的优化,进一步提升了我们整个特征平台线上特征拉取过程的性能。
2. 特征格式的选择

提到了特征协议,就来到了我们的第二部分,特征格式的选择。为什么单要拎出一页PPT来单独介绍特征格式?原因就是说如果特征格式的选择不合适的话,它对整个线上的性能影响是非常之大的。其实最早我们选取的特征格式,其实是谷歌的Tfrecord的格式,也就是Tensorflow支持的格式,这个格式简单来说,就是通过一个Map和多层的Vector嵌套来实现了一个通用的帧格式。但是我们在线上在实际使用的过程中,发现线上非常消耗CPU,假设我们CPU高负载到90%了,90%里面的80%,它其实都是消耗在Tfrecord的这种格式的打解包以及打解包过程中相应的内存分配上,OK,大家现在可以知道,基本上这个点就是我们的业务一个瓶颈了。
通过我们对于业界的一些相关的平台的调研和我们内部的压测之后,我们选择了右边的特征格式,它的主要改进点有两个,第一个就是取消了Map,因为在我们的压测中会发现它整个Map的打解包和序列化的性能都是非常之差。另外一个就是说我们去掉了string,首先去掉string的原因,是因为我们看到模型训练的特征是可以没有string的。第二个原因其实是还可以减少网络流量的浪费,对于同样一个特征,切换掉string后,新的特征格式与老的特征格式进行对比的话,在线上的存储占用基本上可以减少1/2左右,上面表格中新的特征格式与老的特征对比可以发现,我们在打解包的性能上,我们基本上可以拿到一个十倍的一个收益,在内存的分配大小上,我们基本上可以拿到五倍左右的一个收益,当然了,我们上线后的QPS表现上也基本上能拿到五倍左右的一个最终收益。
3. 特征聚合与预测框架
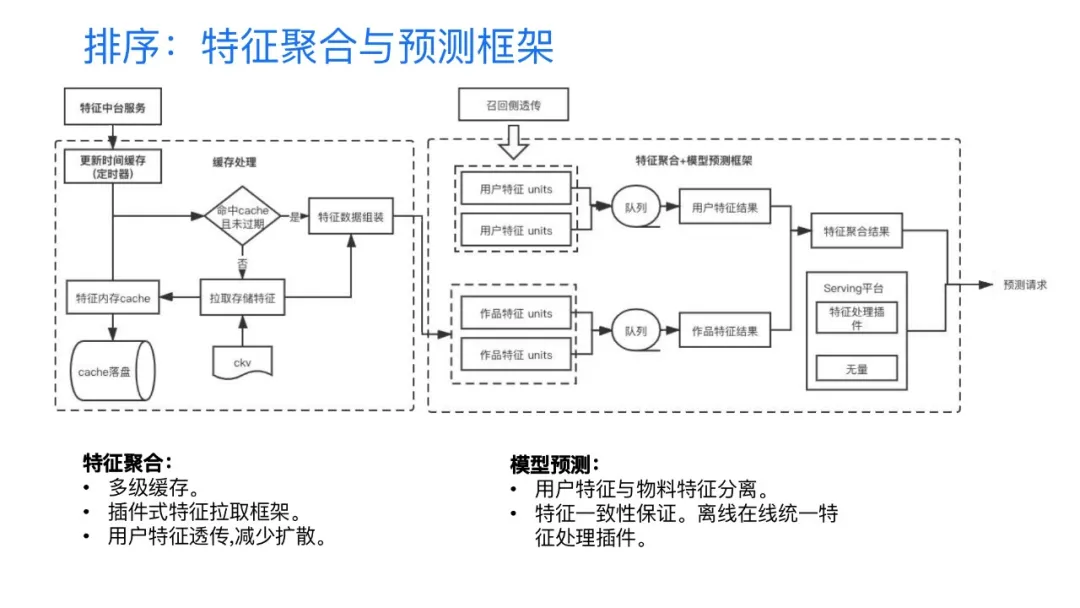 介绍完了特征平台、特征格式的选择接下来就是特征拉取(聚合)和预测框架了,然后这一块主要介绍几个我们的优化点,首先是在特征聚合阶段我们采用了一个周期缓存的方式,因为整个特征拉取的阶段,也是一个扩散量非常大的一个场景,如果直接是拉取存储,会跟召回侧一样,对于整个后端的存储压力和整个的存储成本的要求会非常的高。所以说我们采取了一个多级缓存的方案,简单来说首先就是利用了前面介绍的一个特征平台,它提供了一个支持特征缓存的一个设置,另外在整个特征拉取的框架中,对于特征聚合的过程中也可以提供一个聚合后的特征缓存的配置。另外的话我们在特征聚合框架中采取了插件式的特征拉取开发方式,原因是说我们目前这边后台的开发人力相对来说是比较紧缺的,现在的话,基本上算法同学也会做一些相应的一些开发工作。为了将线上稳定性和性能调优这部分工作与算法同学的模型相关工作解耦出来,我们将这一层(稳定性和性能)在框架里就做了一个透明化的处理,然后相关的同学只需要去实现其中的一两个接口就可以完成整个的功能,进而提高上线效率,规避上线风险。第三个要介绍的是在用户特征这一块,其实跟item的特征做了一个分离处理,用户特征其实是通过上游来透传的,为什么要这样做?主要是为了在rank 特征加载阶段减少一个拉取和扩散的损耗,因为在线上的请求过程中,假设500个要去做预测打分,是不可能给500个单个单个的通过模型预测服务去打分的。OK,如果500个,30个为一批次的话,大概就十几个批次,如果每批次都要在整个特征聚合的框架做拉取的话,大概也要拉取十几次,整个的扩散量是1:10几,对于整个用户特征的扩散量还是相对来说会比较大的。如果通过上游透传过来的话,那就是1:1的一个扩散量,其实相对来说就非常小了,对成本的节省是非常明显的。OK,这是特征聚合的几个大的优化点。
介绍完了特征平台、特征格式的选择接下来就是特征拉取(聚合)和预测框架了,然后这一块主要介绍几个我们的优化点,首先是在特征聚合阶段我们采用了一个周期缓存的方式,因为整个特征拉取的阶段,也是一个扩散量非常大的一个场景,如果直接是拉取存储,会跟召回侧一样,对于整个后端的存储压力和整个的存储成本的要求会非常的高。所以说我们采取了一个多级缓存的方案,简单来说首先就是利用了前面介绍的一个特征平台,它提供了一个支持特征缓存的一个设置,另外在整个特征拉取的框架中,对于特征聚合的过程中也可以提供一个聚合后的特征缓存的配置。另外的话我们在特征聚合框架中采取了插件式的特征拉取开发方式,原因是说我们目前这边后台的开发人力相对来说是比较紧缺的,现在的话,基本上算法同学也会做一些相应的一些开发工作。为了将线上稳定性和性能调优这部分工作与算法同学的模型相关工作解耦出来,我们将这一层(稳定性和性能)在框架里就做了一个透明化的处理,然后相关的同学只需要去实现其中的一两个接口就可以完成整个的功能,进而提高上线效率,规避上线风险。第三个要介绍的是在用户特征这一块,其实跟item的特征做了一个分离处理,用户特征其实是通过上游来透传的,为什么要这样做?主要是为了在rank 特征加载阶段减少一个拉取和扩散的损耗,因为在线上的请求过程中,假设500个要去做预测打分,是不可能给500个单个单个的通过模型预测服务去打分的。OK,如果500个,30个为一批次的话,大概就十几个批次,如果每批次都要在整个特征聚合的框架做拉取的话,大概也要拉取十几次,整个的扩散量是1:10几,对于整个用户特征的扩散量还是相对来说会比较大的。如果通过上游透传过来的话,那就是1:1的一个扩散量,其实相对来说就非常小了,对成本的节省是非常明显的。OK,这是特征聚合的几个大的优化点。
关于模型预测这一块儿,主要介绍两个地方,首先就是说在真正我们喂到模型去进行打分预测的时候,我们用户的特征跟物料的特征其实是做了一个分开去投传的,为什么要分开?之前我们也是说把物料特征和用户才能全部拼在一起,拼成物料的特征。其实分开打分主要是要解决线上的特征拉取流量过大的问题,因为在整个推荐这个场景,打分的时候,我们的特征是非常多的,对于一个用户的打分,基本上你拉取的整个特征量可能是按M来计的,这对于整个线上的网络IO的流量会比较大,我们在之前就达到了整个线上网络IO流量的瓶颈,可能是单机都能达到1G以上,或者是接近对于实际的网卡,我们可能达到8G左右,相当大了。通过这样的一个改进,就可以至少降低1/3的网络IO的流量,对整个网络带宽的成本消耗是非常之明显的。
第二个要介绍的是特征一致性的保障。其实分为两个方面,一个是特征值的一致性,另外一个是特征处理的一致性。特征值的一致性通过将在线的特征做一个离线的上报,这样的话在线和离线所用的特征都是同一份数据源,那就消除了特征穿越导致的不一致。关于特征处理的一致性的解决方案,是说在前面介绍的VENUS的一个数据处理平台上,提供了一个统一的特征处理的插件,离线和在线都是通过同一个插件来做特征的处理,这样的话就可以规避线上线下特征处理不一致的问题。通过以上两个方案,我们完成了整个的特征一致性的一个保障。
04 推荐去重
1. 方案选型
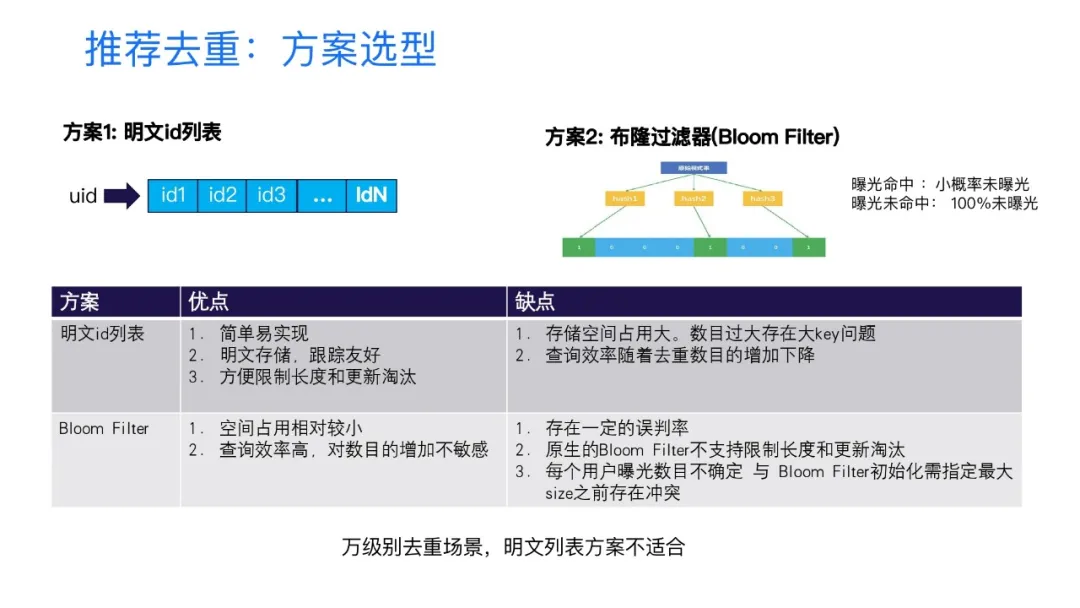
第三部分介绍的是在万级别去重过滤的场景的实践。去重过滤在业界有两种主要方案,一个是明文列表的方案,一个是基于布隆过滤器的方案。那么像K歌之前在千级别以下的去重过滤,采用的是明文列表方案,因为它比较简单,一般来说都是我们第一个想到的一个方案,
明文列表优势:
- 简单易实现
- 明文存储,比较好跟踪调试。方便限制长度和更新淘汰。
劣势:
- 存储空间占用大,假设我们一个itemId 30字节,存5000个,存储占用可能就要到达到150K。150K对于线上的存储来说,基本上就属于大Key了,在线上会产生拉取性能问题,还有QPS的上限的问题。另外随着它整个的数据量的增大,因为会在本地将数据转成一个类似map的结构,查询效率随着整个数目的增加,也会有一个显著的下降,这也是它存在的一个问题。
布隆过滤器它相对的明文列表的方案来说优势:
- 空间占用小,因为它是基于位数组的一个方案,是一个通过hash位来判断它是否命中的方式。
- 另外是查询效率高,对数目的增加并不敏感
劣势:
- 存在一定的误判率
- 原生的布隆过滤器,它不支持限制长度,也不支持更新淘汰。另外就是说在我们的业务场景中
- 用户的曝光数目其实我们是不确定的,我们不知道用户可以看多少个,但是布隆过滤器在初始化时需要指定它能支持的最大的size。这两方面是存在一定的冲突。
通过前面介绍的方案的对比,我们可以知道万级别这种场景下,因为key值太大了,所以使用明文列表的方案不太合适。布隆过滤这种方法也有它的问题,我们通过对原生的布隆过滤器做一些基本的改造,来完成我们线上的业务的一个诉求。
2. K歌实现方案
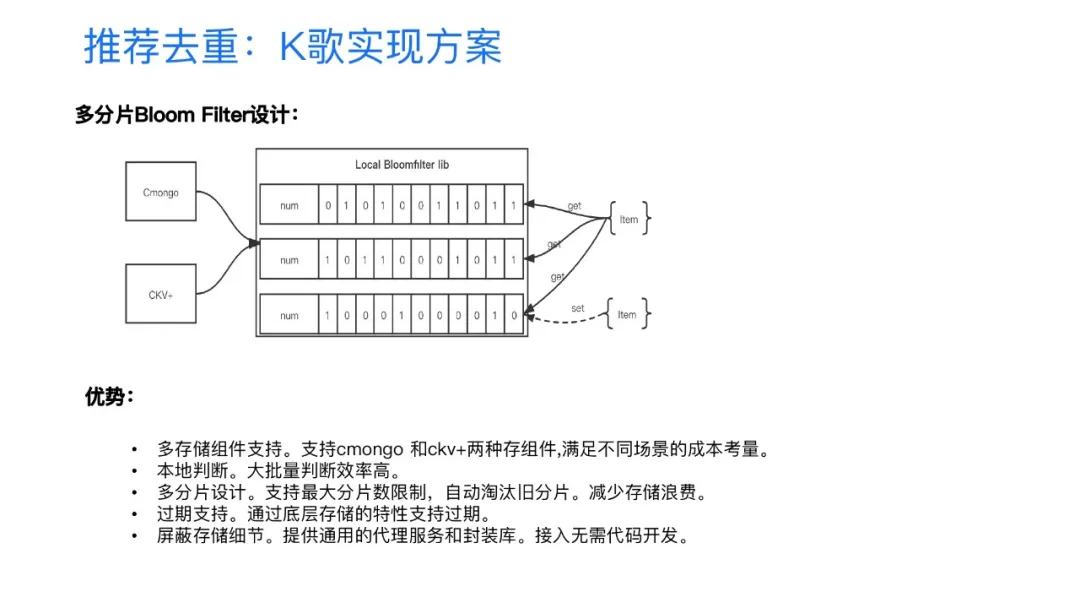 这个是我们改造的方案。简单来说,我们实现了一个基于多分片的和自动淘汰的布隆过滤器的设计。在这个设计中我们介绍三点,第一点就是我们支持了多个存储组件,主要就是支持了Cmongo、CKV+两种,Cmongo就我们腾讯内部的一个mongoDB,它的底层存储是SSD,成本上在我们内部大概估的话应该就是每G每月几块钱的租赁成本。像CKV+这一块,它是一个纯内存的,它的每月每G的租赁成本,由于机房不同,大概是二十或几十不等。为了满足不同场景的成本考量,我们提供了多种存储的支持。另外第二个就是我们线上实施的过程是将整个布隆过滤器数据拉到本地来进行判断,主要的原因是想解决一个网络IO的问题,它不像Redis默认支持布隆过滤器,需要你通过网络IO把你的相应的信息传到远端的Redis里面,通过Redis的API来判断。我们知道整个网络IO的延时跟本地判断延时相比基本上前者是毫秒级别的,后者是纳秒级的,两边差了一到两个数量级。所以说在本地判断的话,对于大批量判断的效率,它会非常之高效。第三个就是多分片的设计了,通过多分片的最大分片数的限制,我们可以自动淘汰旧分片,同时减少存储的浪费。通过存储组件提供的特性,我们还支持过期这样的一个功能,也就是解决了前面我们所说的原生布隆过滤器存在的一些问题。最后我们还提供了一些通用的代理服务和多元的SDK来使业务完成快速接入。
这个是我们改造的方案。简单来说,我们实现了一个基于多分片的和自动淘汰的布隆过滤器的设计。在这个设计中我们介绍三点,第一点就是我们支持了多个存储组件,主要就是支持了Cmongo、CKV+两种,Cmongo就我们腾讯内部的一个mongoDB,它的底层存储是SSD,成本上在我们内部大概估的话应该就是每G每月几块钱的租赁成本。像CKV+这一块,它是一个纯内存的,它的每月每G的租赁成本,由于机房不同,大概是二十或几十不等。为了满足不同场景的成本考量,我们提供了多种存储的支持。另外第二个就是我们线上实施的过程是将整个布隆过滤器数据拉到本地来进行判断,主要的原因是想解决一个网络IO的问题,它不像Redis默认支持布隆过滤器,需要你通过网络IO把你的相应的信息传到远端的Redis里面,通过Redis的API来判断。我们知道整个网络IO的延时跟本地判断延时相比基本上前者是毫秒级别的,后者是纳秒级的,两边差了一到两个数量级。所以说在本地判断的话,对于大批量判断的效率,它会非常之高效。第三个就是多分片的设计了,通过多分片的最大分片数的限制,我们可以自动淘汰旧分片,同时减少存储的浪费。通过存储组件提供的特性,我们还支持过期这样的一个功能,也就是解决了前面我们所说的原生布隆过滤器存在的一些问题。最后我们还提供了一些通用的代理服务和多元的SDK来使业务完成快速接入。
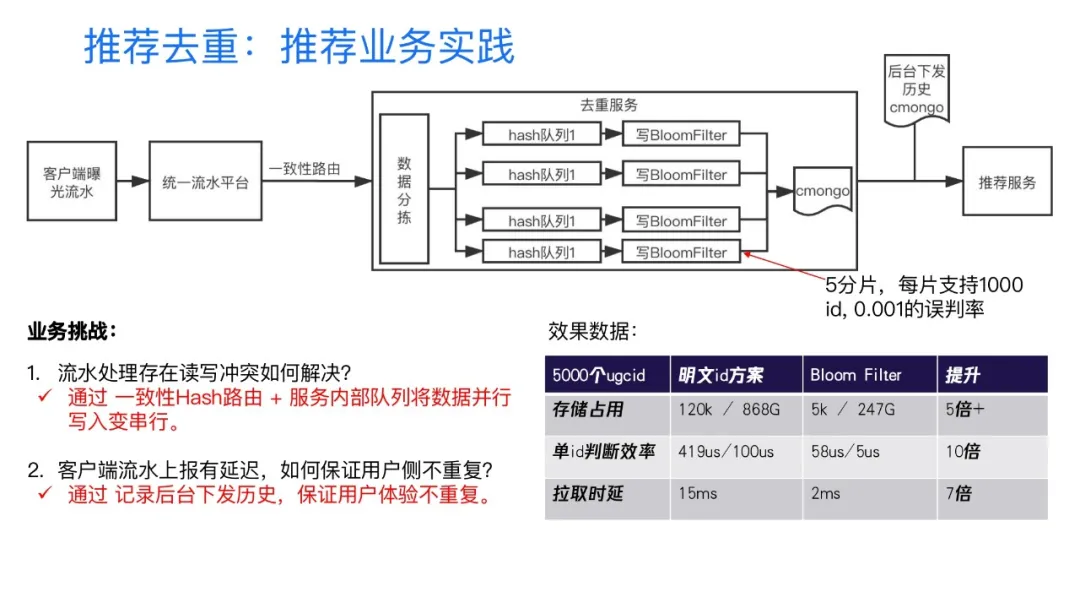 这里介绍一个应用场景,是我们在内部的一个推荐feed的业务实践。在这个业务实践里,我们是采用了五分片,然后每个分片大概支持1000个ID,千分之一误判率的一个配置。实践中有两点还是要介绍一下的,第一个就是说客户端流水,因为是并发上报的,它会存在一个读写冲突的问题,如何解决流水处理作业冲突,我们采用的是一致性hash的负载均衡的路由算法,另外再配合我们服务内部的一个hash队列,将整个数据的并行写入,变成了一个串行写入,来解决这样的一个并发冲突问题。
这里介绍一个应用场景,是我们在内部的一个推荐feed的业务实践。在这个业务实践里,我们是采用了五分片,然后每个分片大概支持1000个ID,千分之一误判率的一个配置。实践中有两点还是要介绍一下的,第一个就是说客户端流水,因为是并发上报的,它会存在一个读写冲突的问题,如何解决流水处理作业冲突,我们采用的是一致性hash的负载均衡的路由算法,另外再配合我们服务内部的一个hash队列,将整个数据的并行写入,变成了一个串行写入,来解决这样的一个并发冲突问题。
另外就是说像这种消息队列的上报,其实它是有一定的延迟的,虽然也很快,一般认为大约是两毫秒左右的一个延迟。如果延迟不管的话,其实对于用户频繁下拉的时候,它就可能会出现一个重复的问题。我如何解决?这一个重复的解决方案是这样的,我们通过配合实时查询后台记录的下发历史的短列表来保证用户的体验上不刷到重复的。
整个线上业务实践的数据结果,大概就像图片里表格内容所示,相比于明文列表的方案,采用布隆过滤器,我们在整个存储的占用上,拿到了五倍以上的收益,那么在整个单ID的判断效率上,我们也可以看到,基本上可以拿到十倍左右的一个收益。我们在拉取时延上,因为整个它的存储key的value变小了,所以说也拿到了接近7倍的一个收益。这个是我们整个在推荐系统部分的业务实践。
05 Debug
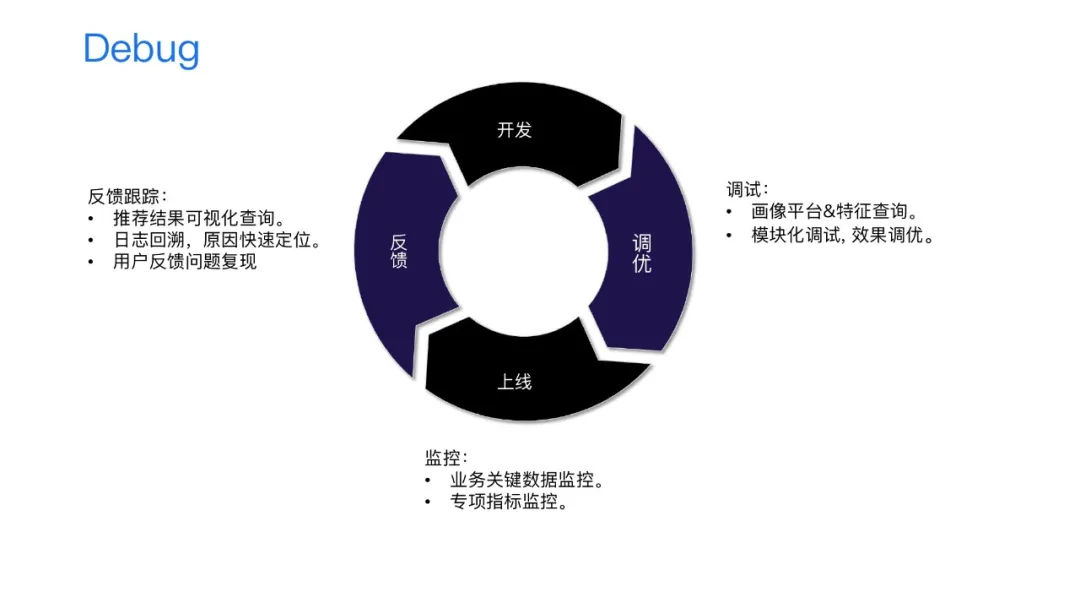
最后一部分我们要介绍的是推荐的一些周边系统。整个推荐的开发流程,可以分为四个部分,先是代码开发,开发完会进行自测和调试,感觉满足需求后上线,上线之后监控用户的反馈。
1. Debug:调试
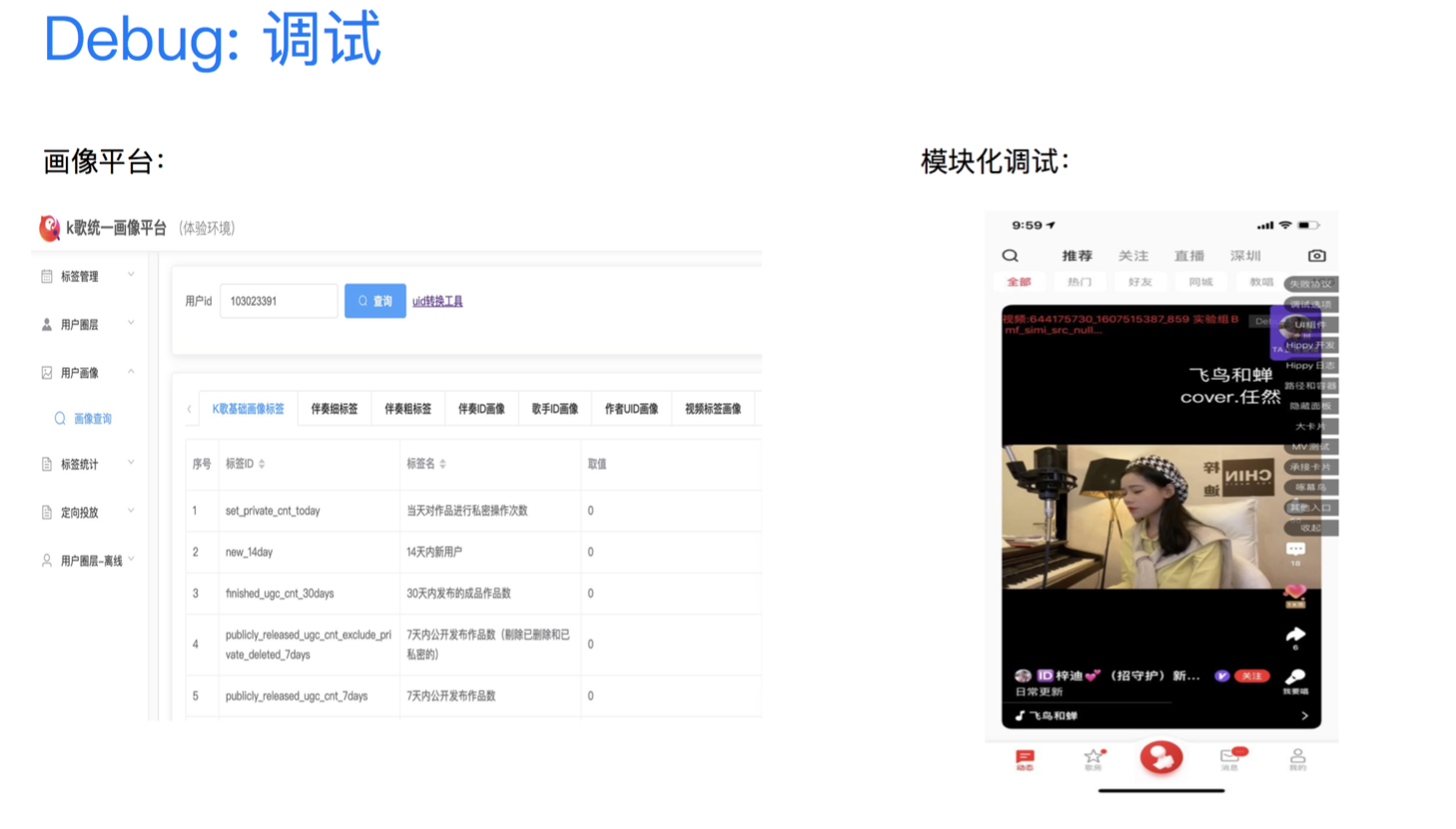
在调试阶段,开发了画像平台&特征查询的平台,方便数据验证。在内部Debug版本的APP中,内嵌了模块化的调试工具,可以实时查看物料对应的推荐相关信息。
2. Debug:监控
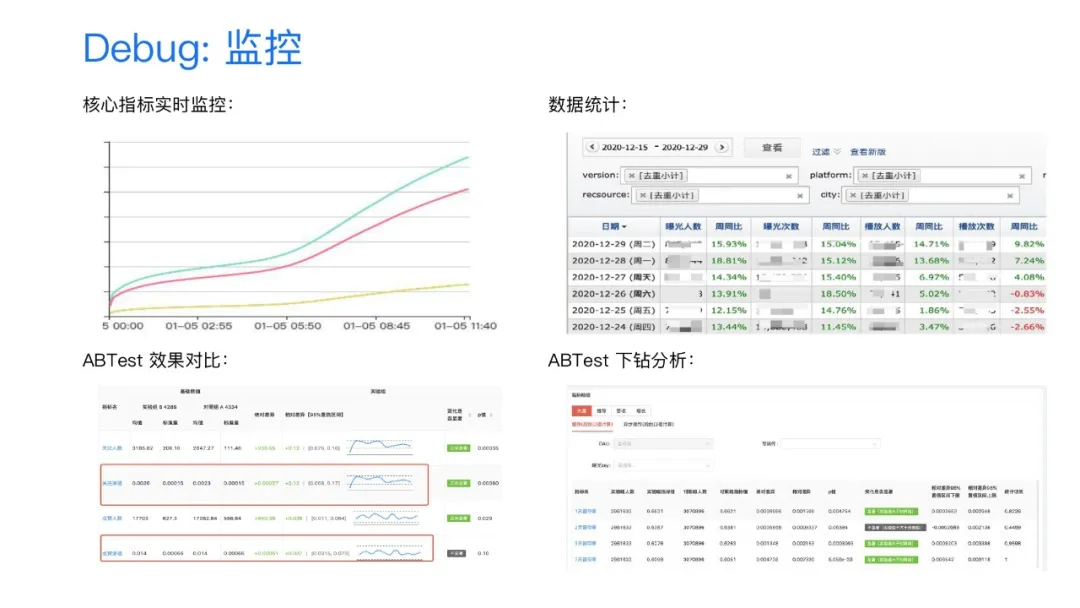
在调试后的上线阶段,我们构建了丰富的监控体系。包括了核心指标的实时监控, 整体效果的统计监控,基于abtest平台的显著性验证和下钻分析等。
3. Debug:日志追溯
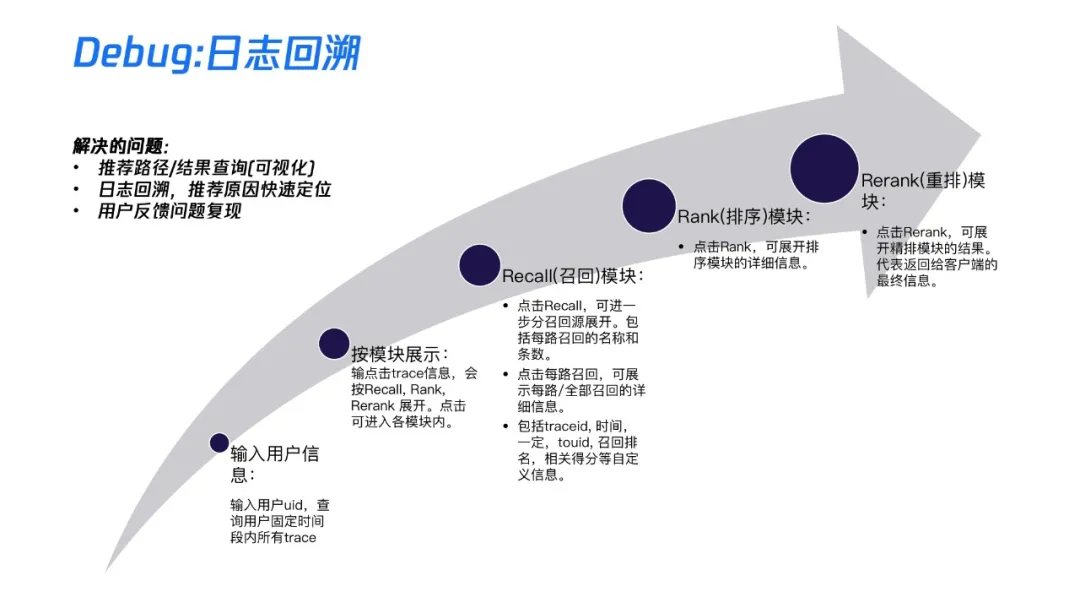
上线之后,不可避免的就是我们会收到各种各样的反馈。对于产品和运营同学来说,整个推荐它其实一个偏黑盒儿的一个东西,它其实并不知道你为什么推给他。为了解决黑盒,我们开发了一个基于日志回溯的Debug系统,通过这个系统,我们可以将整个推荐的路径做一个可视化的展示,然后通过这种可视化的展示,我们可以逐级定位推荐的数据从哪里来,到哪里去,进而可以帮助我们快速定位整个的线上问题。
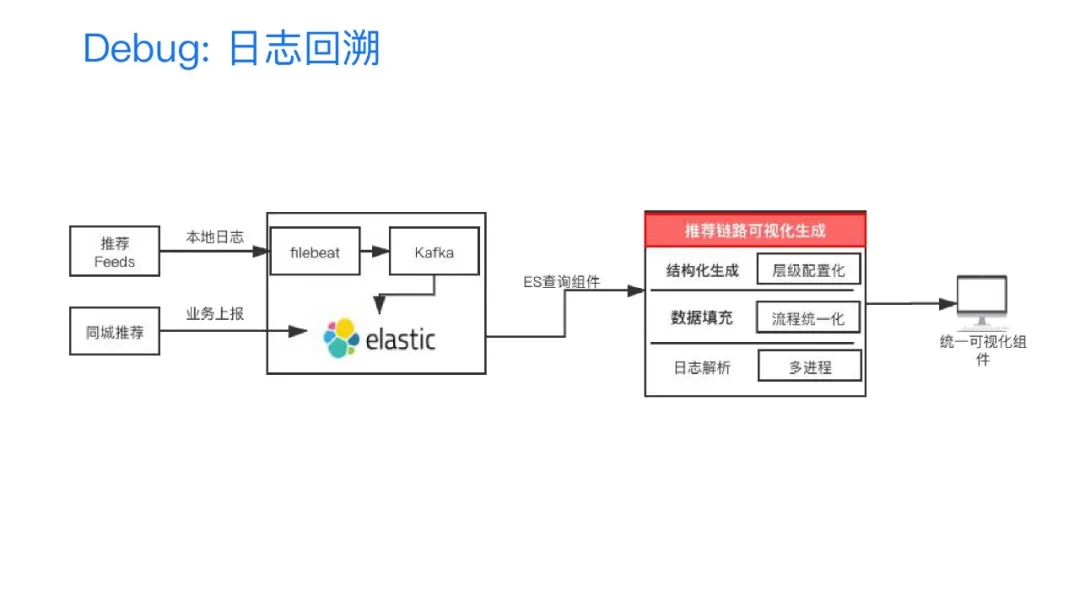
接下来介绍这个平台实现的架构方案,在整个的存储端采用的是将ES作为存储组件,支持服务端采用本地日志写入,或者直接通过ES的API写入,这个就看业务各自的一个选择情况了。在前端的一个展示界面上,我们是采用Django开发框架来搭建,然后这个平台可以将整个推荐路径作逐级的展开。在基于日志回溯的Debug系统里,它其实有一个难点:我们其实知道整个推荐在召回阶段是万级别的,那么等到我们排序打分的时候�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E9%9F%B3%E4%B9%90%E5%85%A8%E6%B0%91%E6%AD%8C%E6%8E%A8%E8%8D%90%E5%90%8E%E5%8F%B0%E6%9E%B6%E6%9E%84/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


