腾讯音乐全民歌内容挖掘与召回
分享嘉宾:timmyqiu 腾讯音乐 应用研究
编辑整理:郭真继
出品平台:DataFunTalk
系列文章: 腾讯音乐:全民 K 歌推荐系统架构及粗排设计
导读: 推荐系统一般分为两部分,召回阶段和排序阶段。召回阶段是从全量数据中挑选出用户可能感兴趣的一部分数据,供后面的排序阶段使用。全民K歌作为一个拥有大量用户上传作品的平台,如何挖掘用户上传的内容作为推荐的候选集,也需要精心设计。
今天的介绍会围绕下面四点展开:
- 内容挖掘
- 召回模型
- 召回模型实践
- 总结和展望
01 内容挖掘
首先和大家分享下全民K歌进行内容挖掘在业务上的必要性。
1. 内容挖掘–重要性
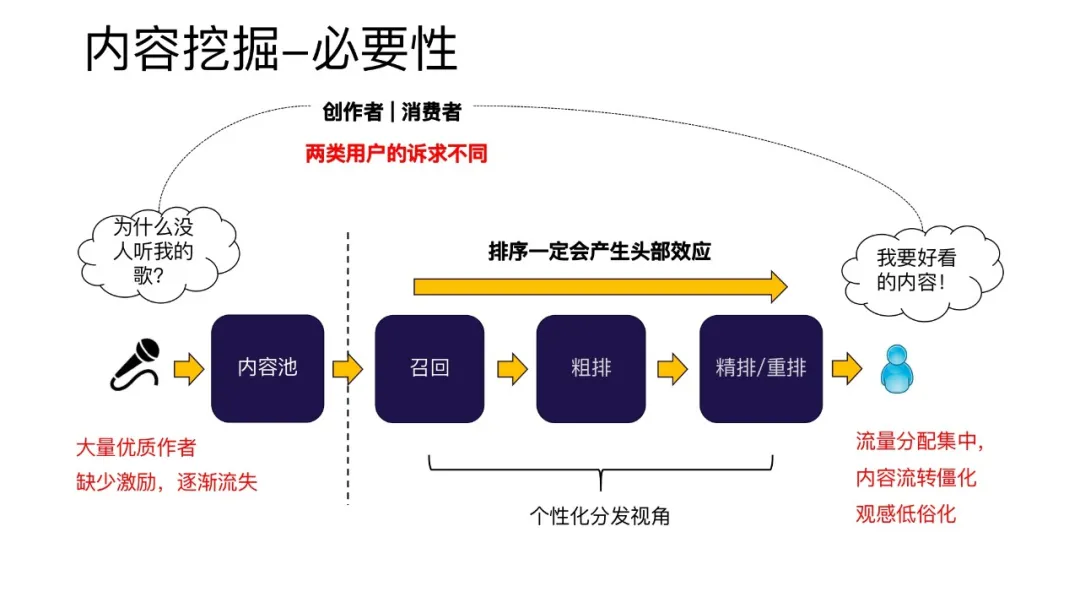 跟普通的召回相比,全民K歌作为一个UGC(User Generated Content,也就是用户生成内容,即用户原创内容),存在着两种用户:内容创作者和内容消费者。两者对于平台的诉求是不一样的:内容消费者和其他平台的用户一样,希望看到好的内容,获得好的用户体验。而内容创作者更看重自己发布的作品被更多的人去看到,去喜欢。所以如果单纯从个性化分发的角度去看待问题,推荐的目标是为了满足内容消费者短期的需求,在短期内可能对于消费规模上会有一个增益。但是长期来看,这种方式会导致推荐流量分配越来越集中到少数作者。大量作者因为得不到推荐流量,缺少创作激励,会导致平台创作者的流失。这样对于平台的生态来说是不理的。所以除了个性化分发的视角以外,还有一个从内容生态视角进行考虑的,从内容生态视角触发的一个机制。这个机制就是内容挖掘机制。
跟普通的召回相比,全民K歌作为一个UGC(User Generated Content,也就是用户生成内容,即用户原创内容),存在着两种用户:内容创作者和内容消费者。两者对于平台的诉求是不一样的:内容消费者和其他平台的用户一样,希望看到好的内容,获得好的用户体验。而内容创作者更看重自己发布的作品被更多的人去看到,去喜欢。所以如果单纯从个性化分发的角度去看待问题,推荐的目标是为了满足内容消费者短期的需求,在短期内可能对于消费规模上会有一个增益。但是长期来看,这种方式会导致推荐流量分配越来越集中到少数作者。大量作者因为得不到推荐流量,缺少创作激励,会导致平台创作者的流失。这样对于平台的生态来说是不理的。所以除了个性化分发的视角以外,还有一个从内容生态视角进行考虑的,从内容生态视角触发的一个机制。这个机制就是内容挖掘机制。
2. 内容挖掘—目标
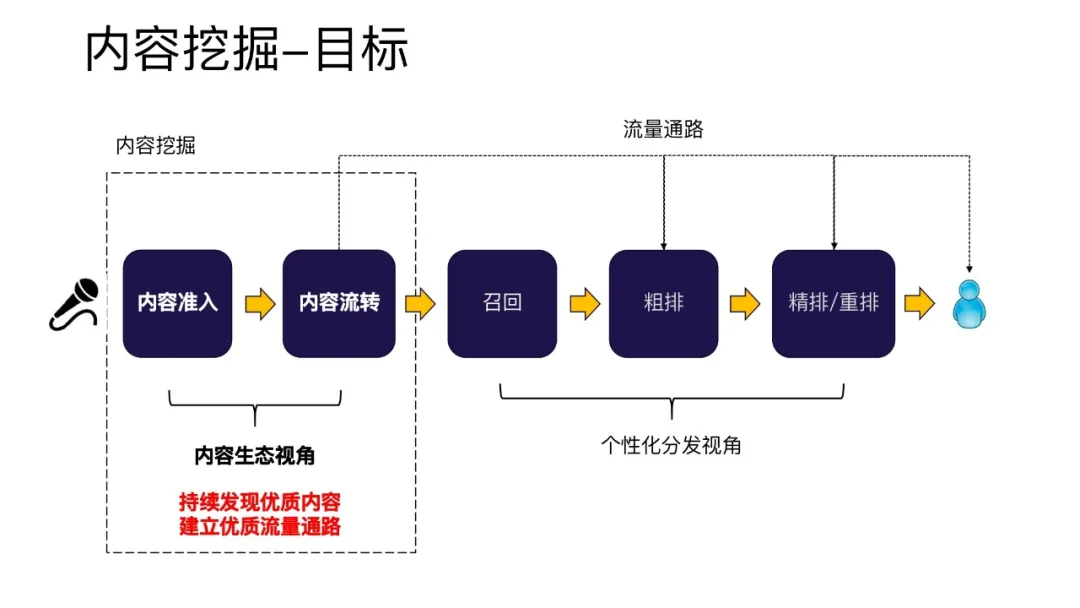 内容挖掘的目标是持续发现优质内容,建立优质流量通路。为了实现这个目标,内容挖掘主要分为两个模块
内容挖掘的目标是持续发现优质内容,建立优质流量通路。为了实现这个目标,内容挖掘主要分为两个模块
- 内容准入机制:从内容创造者上传的内容中筛选出优质作品,进入到推荐系统链路
- 分发通路:内容创作者上传内容中筛选出优质作品之后,需要一个稳定的分发通路,保证这些优质资源能够让用户看到。
这两个模块也是经历了一系列的迭代和优化过程,下面将详细介绍迭代过程。
3. 内容挖掘—迭代
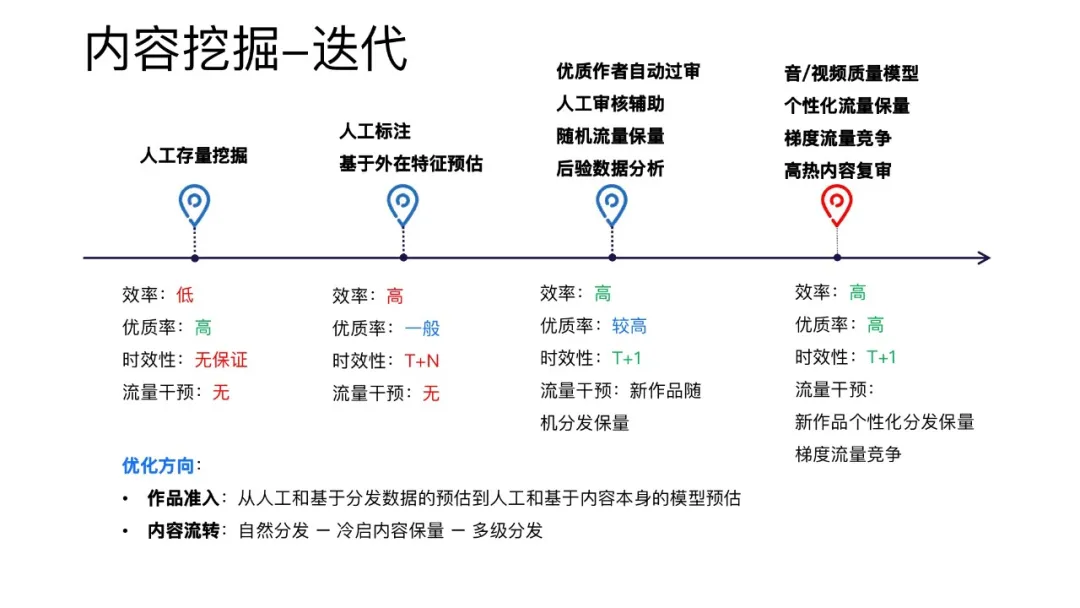 在内容准入方面,一开始用的是人工存量挖掘。靠人工对上传的资源进行打分。这样做可以获取到高质量的资源,但是人工操作费时费力,效率很差,时效性也无法获得保证。后面为了提高效率尝试用一些人工标注的特征进行模型预估来识别优质内容,但是这些模型都存在一些问题。现在用的方案是基于视频音频本身的特征来做优质内容的识别,然后用人工的一些辅助审核来帮助实现的内容准入。
在内容准入方面,一开始用的是人工存量挖掘。靠人工对上传的资源进行打分。这样做可以获取到高质量的资源,但是人工操作费时费力,效率很差,时效性也无法获得保证。后面为了提高效率尝试用一些人工标注的特征进行模型预估来识别优质内容,但是这些模型都存在一些问题。现在用的方案是基于视频音频本身的特征来做优质内容的识别,然后用人工的一些辅助审核来帮助实现的内容准入。
在内容分发方面,一开始完全是基于推荐系统的自然分发,然后在此基础上,为了更好的激励内容创作者,增加了冷启动内容保量机制。现在采用的是多级分发,针对不同的反馈效果去给一个作品做多流量的分发机制。
4. 内容挖掘—方案
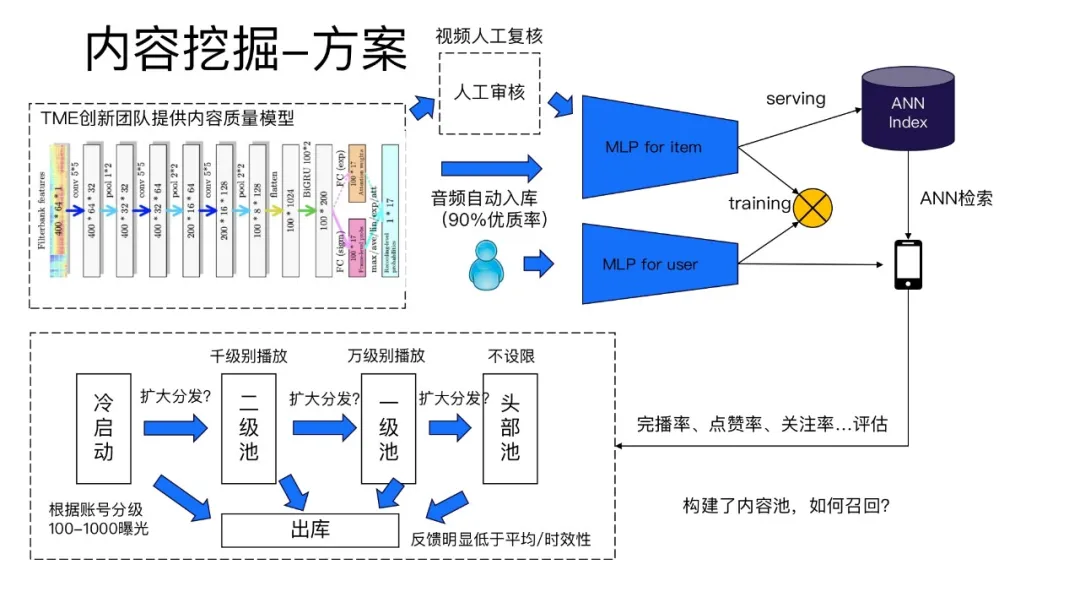 从整体上看,内容挖掘一共有三部分组成:
从整体上看,内容挖掘一共有三部分组成:
① 内容准入:内容准入部分是由TME创新团队提供的深度神经网络模型,将一些普通内容和优质内容进行人工标注之后训练模型。对于新发的音频和视频资源,模型会根据他的唱功、视频质量等一系列特征来判断内容好坏。对于音频资源通过模型打分之后直接进入到推荐候选池中,对于音频资源还需要通过人工审核才能入库。通过这样的流程就可以很高效的从每日发布的500w资源中挖掘出可以推荐的资源。
② 分级分发:从用户创作的内容挖掘出优质资源之后,跟着的就是冷启动阶段。根据用户的账号等级,给资源初始曝光量,在曝光量打到设定的值之后根据反馈的数据与资源的平均数据进行对比,如果反馈效果更好的话就增加曝光量,在扩大曝光几次之后,如果资源的反馈仍然比较好,就用双塔模型对资源进行一个保量。
③ 召回:召回模型采用的是双塔模型,不过和传统的双塔模型相比,这里只用到了作品的源信息,没有用到后续的信息。
在完成保量过程之后优秀的作品会转入到流量流转阶段,这个阶段和分级分发类似,每个推荐周期结束后根据一些指标对内容进行评估。比如看点击率、完播率这些,根据这些表现来确定是不是要把它放到更大一级的流量池里面去分发。
02 召回模型
完成了内容创作者资源的挖掘之后,从每日上传的内容里面可以获取到比较优秀的内容,构建内容池,然后对这个内容池来做个性化召回。
1. 召回模型—总览
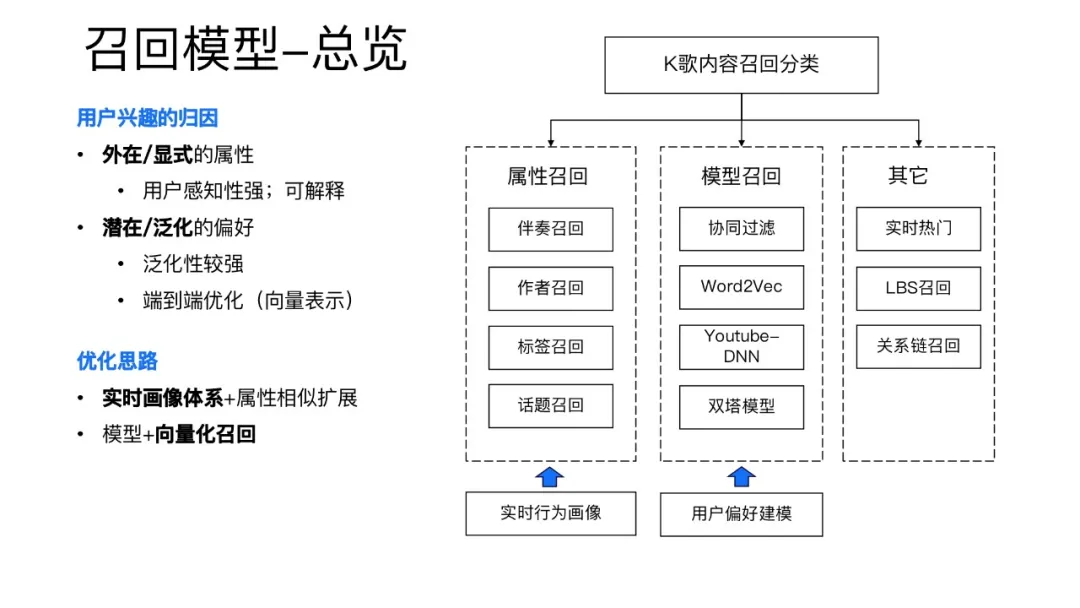 全民K歌的召回主要分为三类:
全民K歌的召回主要分为三类:
- 属性召回:用户在看什么内容,说明用户对于这类属性的物品有一个偏好,然后可以根据这些偏好去做点对点的召回,召回一些带有用户偏好属性的内容;
- 模型召回:从用户和item的建模角度,把用户和item建模到同一个向量空间,之后可以按照相关检索去为用户做一个召回;
- 其他召回:除了上述两种召回以外,基于实时热门内容、LBS(基于位置服务)、关系链召回也可以召回少量数据作为补充。
2. 召回模型—画像属性召回
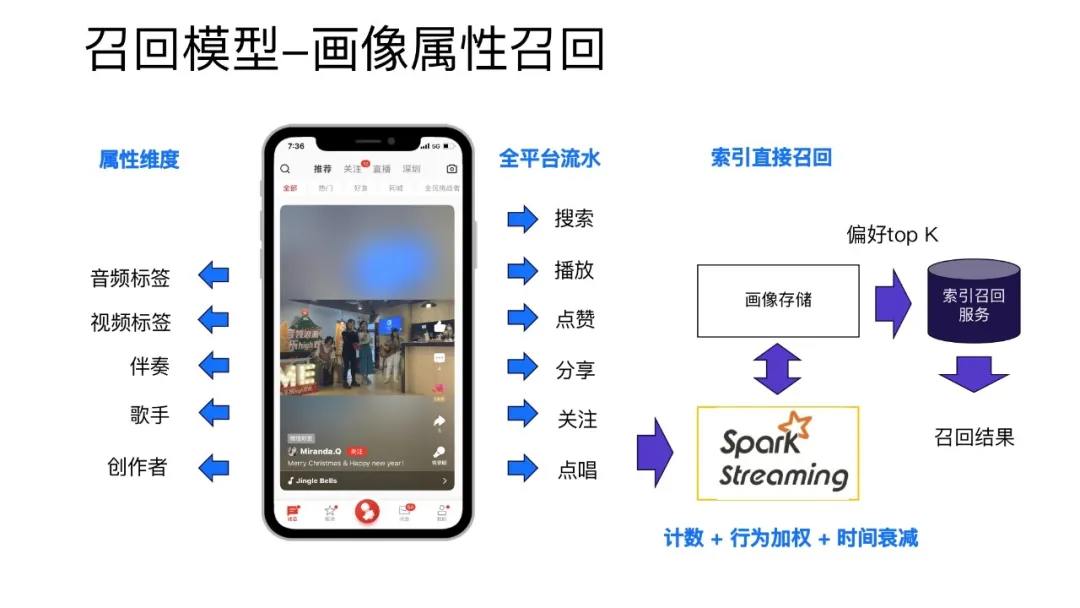 基于用户画像的属性召回的原理比较简单:根据全平台的流水(如搜索、播放、点赞、分享、关注和点唱等用户行为),实时计算用户在我们平台的各个维度(如音频标签、视频标签、伴奏、歌手、创作者)的偏好。最终选取用户比较高的偏好维度的一系列属性来为用户去做召回。这种召回对于用户的感知性很强,因为召回结果和用户的实时行为时有强相关的关系。
基于用户画像的属性召回的原理比较简单:根据全平台的流水(如搜索、播放、点赞、分享、关注和点唱等用户行为),实时计算用户在我们平台的各个维度(如音频标签、视频标签、伴奏、歌手、创作者)的偏好。最终选取用户比较高的偏好维度的一系列属性来为用户去做召回。这种召回对于用户的感知性很强,因为召回结果和用户的实时行为时有强相关的关系。
3. 召回模型—属性向量化
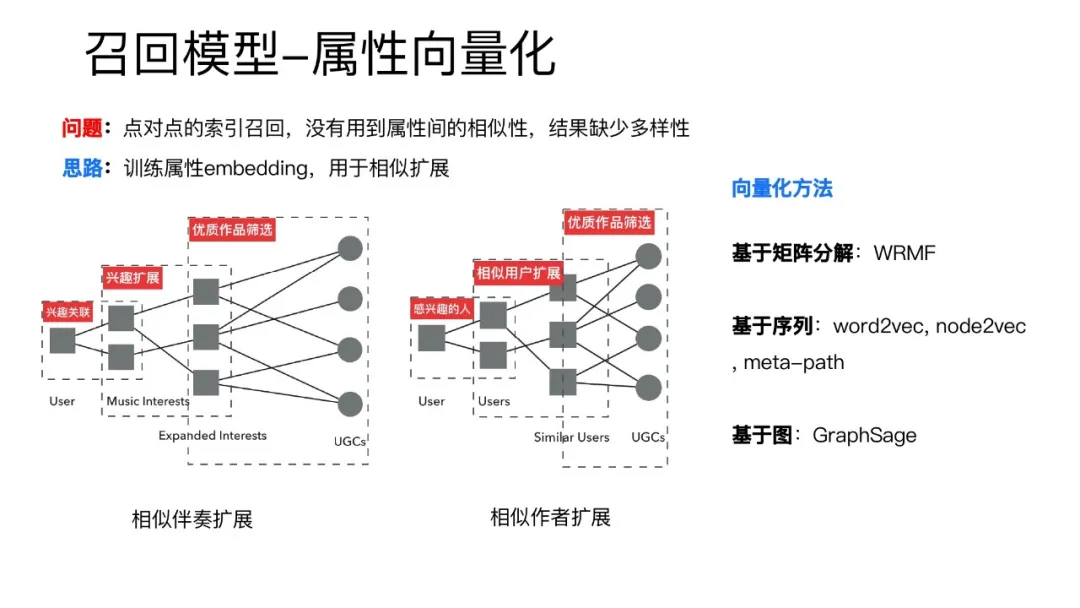 单纯用点对点的属性召回是存在问题的:这样的召回比较死板,没有考虑到属性之间的相似性。为了解决这个问题,这里引进了属性向量化,训练属性的embedding,根据属性直接的相似关系进行相似扩展。比如用户喜欢的伴奏,可以扩展到相似的伴奏然后寻找作品。用户喜欢某个作者,也可以扩展到风格相似的作者。
单纯用点对点的属性召回是存在问题的:这样的召回比较死板,没有考虑到属性之间的相似性。为了解决这个问题,这里引进了属性向量化,训练属性的embedding,根据属性直接的相似关系进行相似扩展。比如用户喜欢的伴奏,可以扩展到相似的伴奏然后寻找作品。用户喜欢某个作者,也可以扩展到风格相似的作者。
03 召回模型实践
在介绍完召回模型的理论部分之后,下面介绍一下召回模型的实践以及实践中的探索优化
1. 召回模型实践—模型化召回
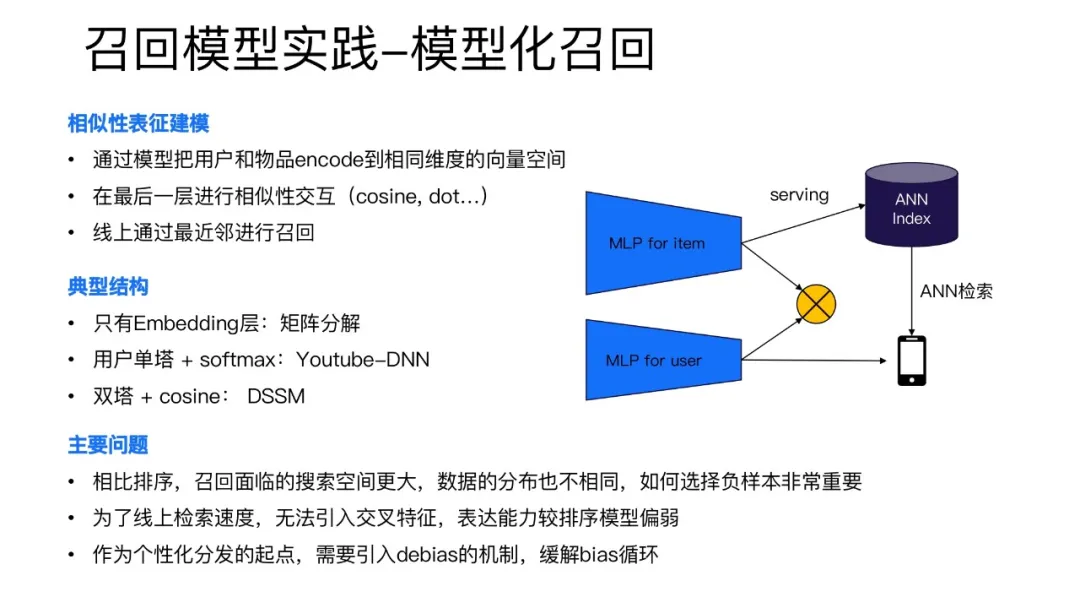 模型化的召回是相似性的表征建模:通过模型把用户和物品encode到相同维度的向量空间,在最后一层进行相似性交互(cosine,dot等相似性计算方法),线上通过最近邻来召回最相似的内容。
模型化的召回是相似性的表征建模:通过模型把用户和物品encode到相同维度的向量空间,在最后一层进行相似性交互(cosine,dot等相似性计算方法),线上通过最近邻来召回最相似的内容。
模型化召回典型结构有三种:
- 只有Embedding层:矩阵分解
- 用户单塔+softmax:Youtube-DNN
- 双塔+cosine:DSSM
全民K歌线上采用的是第三种结构,和排序模型相比有几个需要注意的问题:
- 相比排序,召回面临的搜索空间更大。排序只是把少量内容进行打分然后按照分数从高到低排
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E9%9F%B3%E4%B9%90%E5%85%A8%E6%B0%91%E6%AD%8C%E5%86%85%E5%AE%B9%E6%8C%96%E6%8E%98%E4%B8%8E%E5%8F%AC%E5%9B%9E/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


