腾讯知识图谱补全技术

分享嘉宾:陈立玮 博士 腾讯 高级研究员
编辑整理:王吉东
出品平台:DataFunTalk
导读: 当前知识图谱已经被广泛应用在自然语言处理的各项任务中,但知识图谱中实体间关系的缺失也给其实际的应用带来了很多问题。因此,目前学术界围绕知识图谱的补全进行了大量的研究工作。本文主要对知识图谱补全相关的研究进展进行了归纳与分享。
01 背景介绍
首先和大家分享下知识图谱的背景。
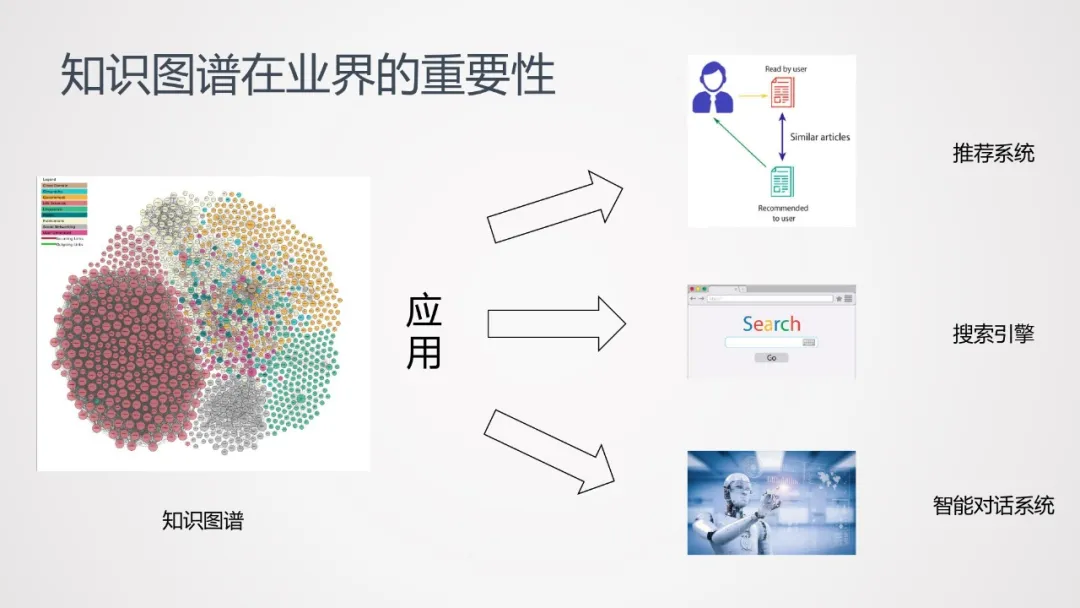
知识图谱,在互联网行业已经被广泛应用于多种不同的领域,如推荐系统、搜索引擎、智能对话系统等。在AI时代,知识图谱是一项非常重要的技术。
1. 知识图谱主要研究方向
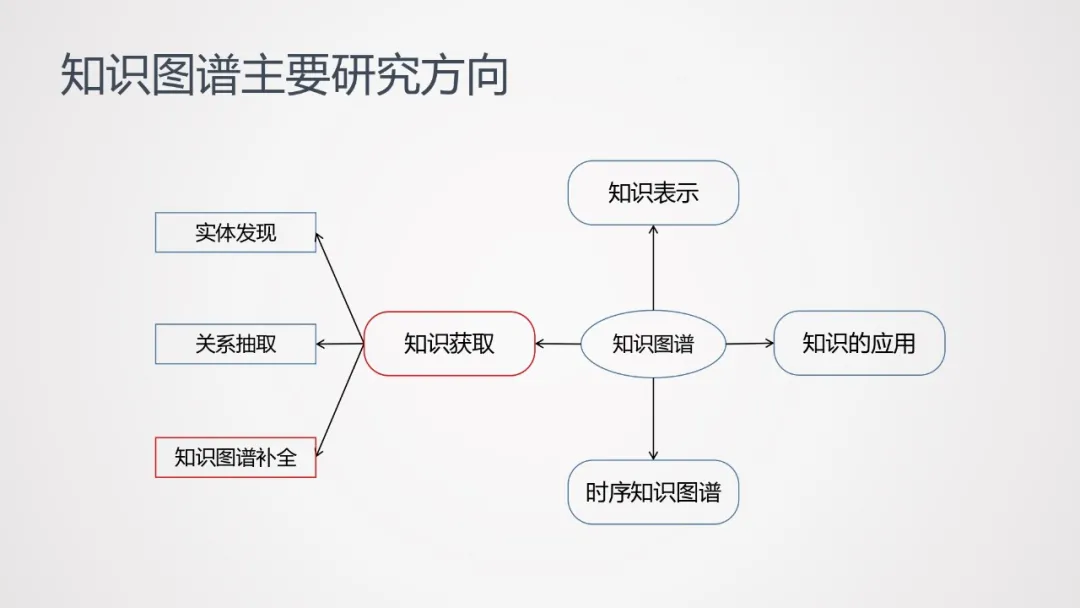
知识图谱的主要研究方向包括知识获取、知识表示、时序知识图谱、知识应用等方向。本次分享,主要聚焦于知识获取中的一个子任务——知识图谱补全。
2. 为什么要做知识图谱的补全
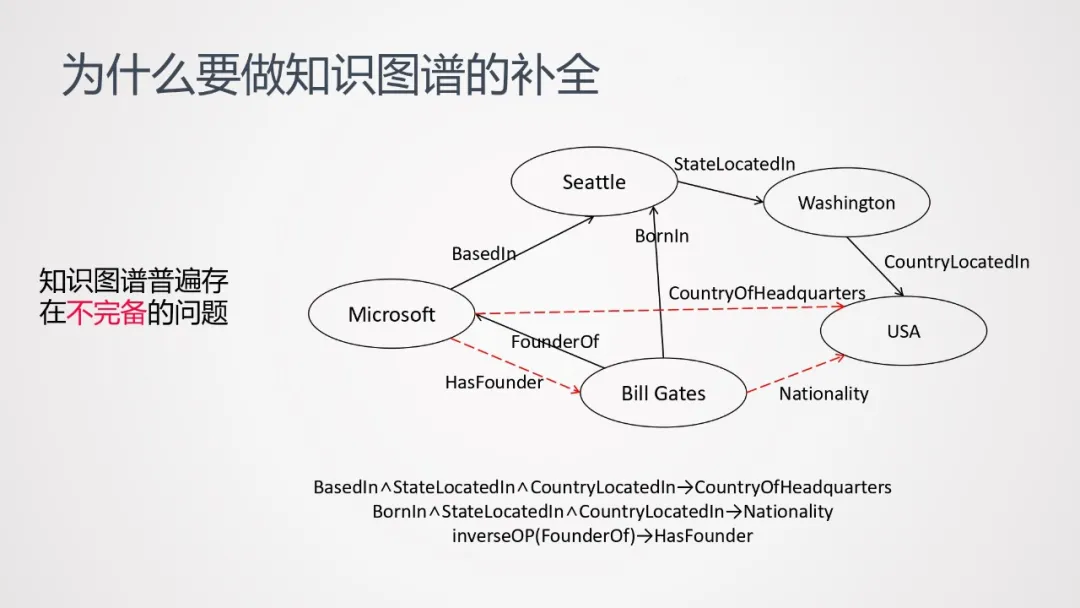
知识图谱普遍存在不完备的问题。以上图为例,黑色的箭头表示已经存在的关系,红色的虚线则是缺失的关系。我们需要做的,是基于图谱里已有的关系,去推理出缺失的关系。
3. 知识图谱补全的难点与挑战
- 如何更好的建模知识的结构和推理规则?如何查找路径?强化学习可用吗?如何建模逻辑规则?
- 如何解决长尾数据问题?few-shot learning?
02 问题定义
知识图谱补全问题定义
给定知识图谱G = {E, R, F},其中E表示所有实体的集合,R表示所有关系的集合,F为所有三元组的集合。
知识图谱补全的任务是预测出当前知识图谱中缺失的三元组F’={(h, r, t) | (h, r, t)∉F, r∈R}
根据补全的实体是否在E中,知识图谱补全可分为两个子任务:
- 封闭域的知识图谱补全,限制要补全的三元组的实体都在E中
- 开放域的知识图谱补全,不限制实体一定在E中
后面分享中除非特别提到,否则主要指封闭域的知识图谱补全。
03 知识图谱补全技术发展
知识图谱补全技术,可归纳为以下几种:基于知识表示的方法、基于路径查找的方法、基于推理规则的方法、基于强化学习的方法、基于元学习的方法。
1. 基于知识表示的方法
基于知识表示的方法,是最直接的一种方式。

- 知识表示学习:对知识图谱中的实体和关系学习其低维度的嵌入式表示。
- 常见的知识表示学习方法:上图涵盖了常见的知识表示学习方法,主要是以TransE法为核心,针对空间映射等场景做的改进。
- 基于实体和关系的表示对缺失三元组进行预测;
- 许多前面提到的知识表示方法都可以用在知识图谱补全中。
以上图中的三元组为例,已知头实体以及头实体间的关系,预测其尾实体。可将头实体的embedding组合到一起,在尾实体的candidate列表中计算score(可自定义score计算方法,例如相似度);从candidate中选择一个分数最高的尾实体作为补全。
基于这种方法可以做进一步的改进——引入实体描述信息,构建神经网络:
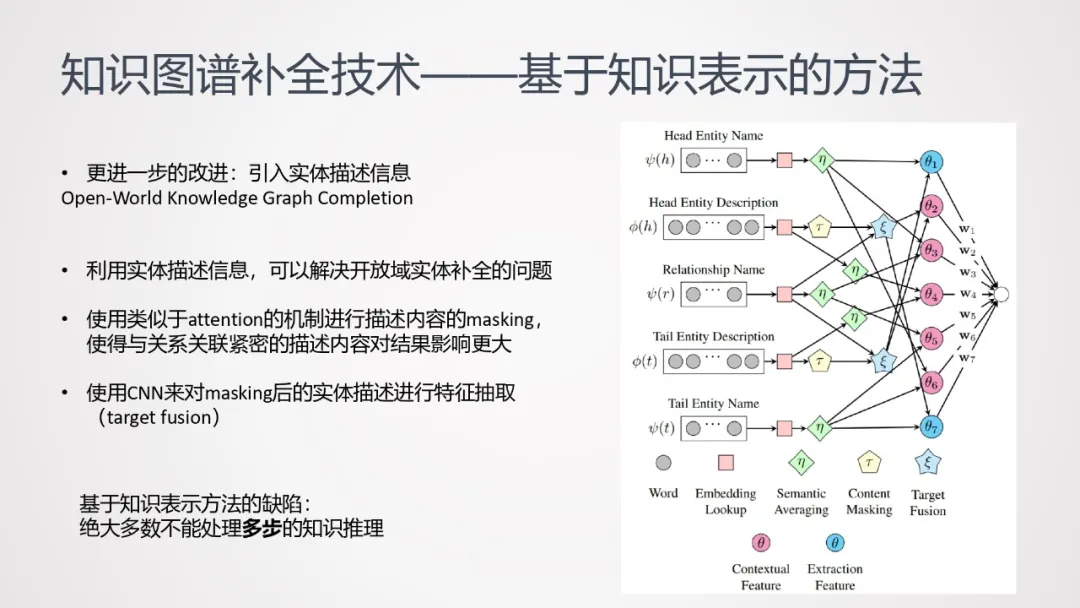
- 利用实体描述信息,可以解决开放域实体补全的问题;
- 使用类似于attention的机制进行描述内容的masking,使得与关系关联紧密的描述内容对结果影响更大;
- 使用CNN来对masking后的实体描述进行特征抽取(target fusion)。
通过以上步骤,将文本提取成两种特征:一种是含有三元组(即头实体、尾实体和关系名)上下文信息的特征,一种是偏向利用实体描述信息抽取新实体相关知识的特征。将两类特征输入到全连接网络中,做最终补全结果的预测。
2. 基于路径查找的方法
基于知识表示方法,一般不能处理下图这种多步知识推理。(图中从微软到美国,需要经过4步推理才能获得)
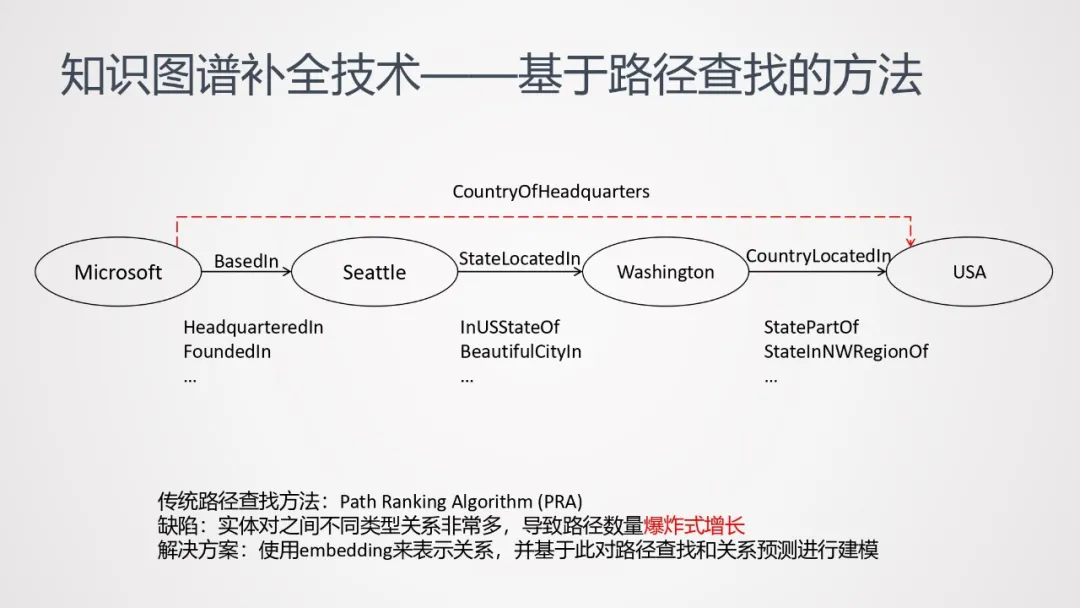
可使用基于路径查找的方法来处理这类多步推理问题。
传统的路径查找方法主要是PRA方法(Path Ranking Algorithm);但是这种方法对于包含较大规模的知识图谱来说,会由于路径数量爆炸式增长,导致特征空间急剧膨胀。
解决的方式,可以尝试用embedding的方式表示关系,对关系进行泛化,并基于此对知识的补全进行建模,以缓解路径数量过多导致的特征空间膨胀问题。
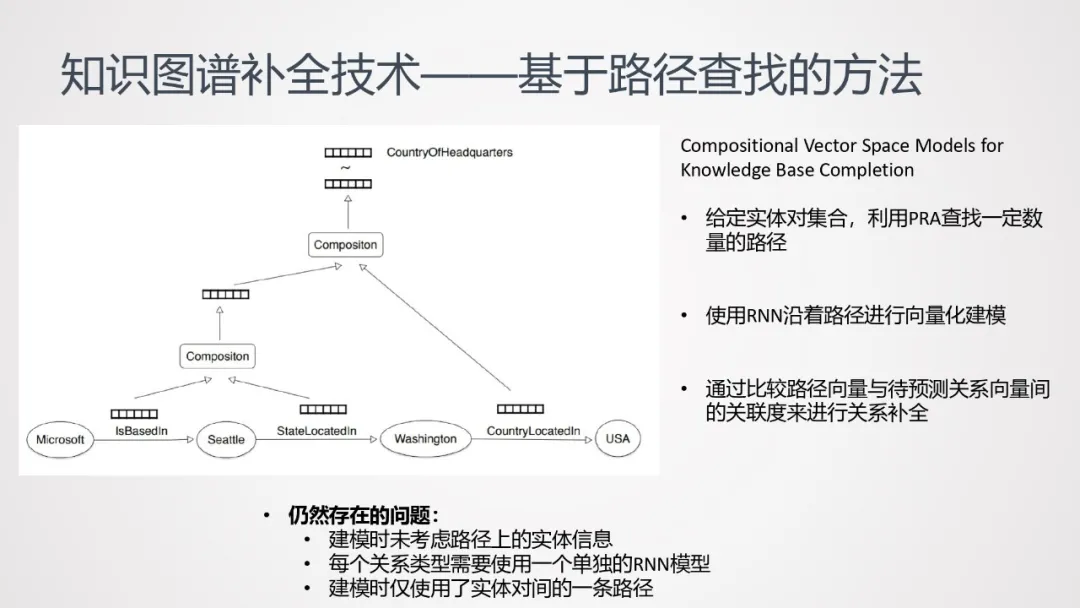
- 给定实体对集合,利用PRA查找一定数量的路径;
- 使用RNN沿着路径进行向量化建模;
- 通过比较路径向量与待预测关系向量间的关联度来进行关系补全。
此方法仍然存在一些问题:
- 建模时未考虑路径上的实体信息;
- 每个关系类型需要使用一个单独的RNN模型;
- 建模时仅使用了实体对间的一条路径。
基于此,后续的工作对以上方法做了如下改进:
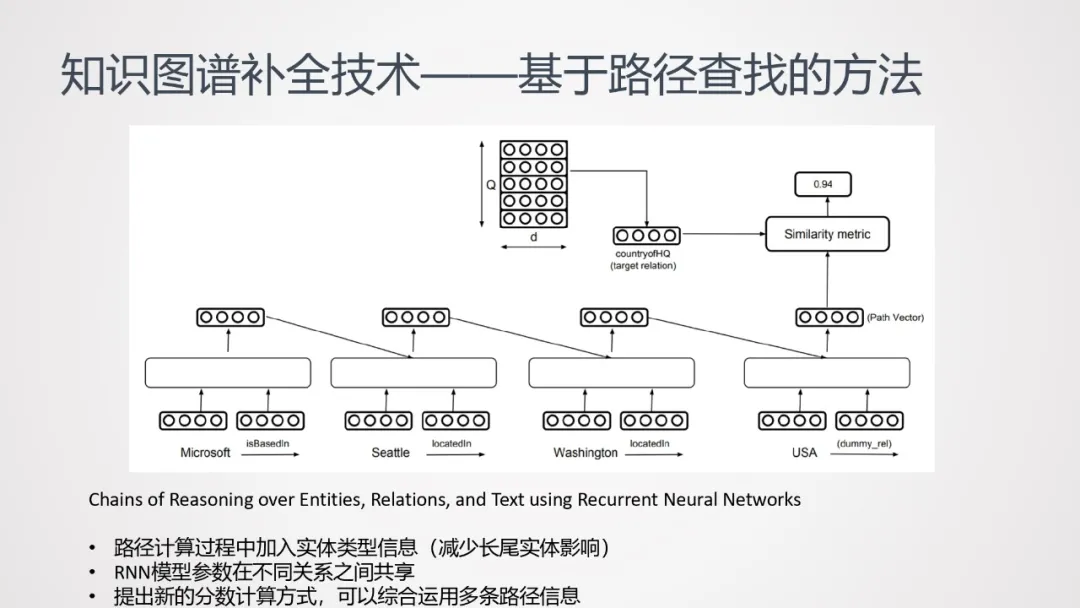
- 路径计算过程中加入实体类型信息(减少长尾实体影响);
- RNN模型参数在不同关系之间共享;
- 提出新的分数计算方式,可以综合运用多条路径信息:
假设{s_1,s_2, …, s_n}为两个实体{e_s,e_t}间所有路径与关系r之间的相似度分数集合,那么该实体对拥有关系r的概率可有以下几种计算方式:

这里特别提到LogSumExp法,将所有相似度分数计算指数和后取对数;这种计算方法,在误差反向传播的过程中,分数高的路径获得的梯度分配更多;类似于根据分数计算贡献的方式。
3. 基于强化学习的方法
前面提到的两种方法,仍然存在若干的问题:
- 需要基于random walk来查找路径;
- 而random walk算法在离散空间中运行,难以评价知识图谱中相似的实体和关系;
- 超级结点可能影响random walk算法运行速度。
基于以上问题,有很多研究者开始尝试强化学习方法:
- 在连续空间中进行路径搜索;
- 通过引入多种奖励函数,使得路径查找更加灵活、可控。
这里介绍DeepPath这种强化学习方法:
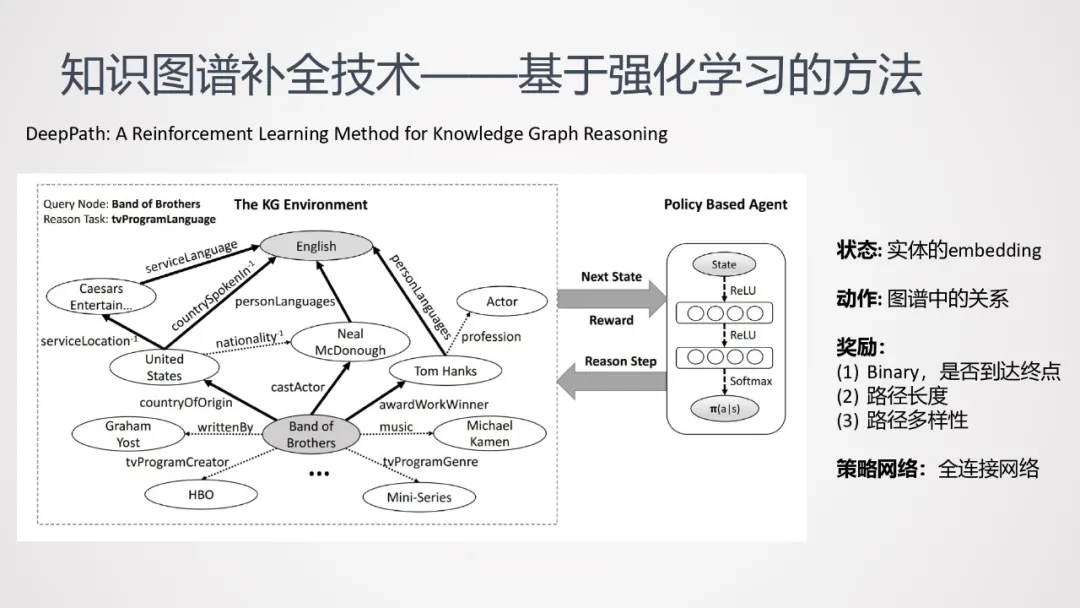
① 任务:查找Band of Brothers和English之间的关系。
② 路径起点:Band of Brothers
③ 状态:实体中的embedding
④ 动作:图谱中的关系;
⑤ 奖励:
- Binary,是否到达终点
- 路径长度
- 路径多样性
⑥ 策略网络:使用全连接网络。
DeepPath方法仍然存在一些缺陷:知识图谱本身的不完善很可能对路径查找造成影响。
基于此,研究者提出了更加开放的知识图谱补全方法,在路径查找过程中,通过抽取关系,将缺失的路径补全。
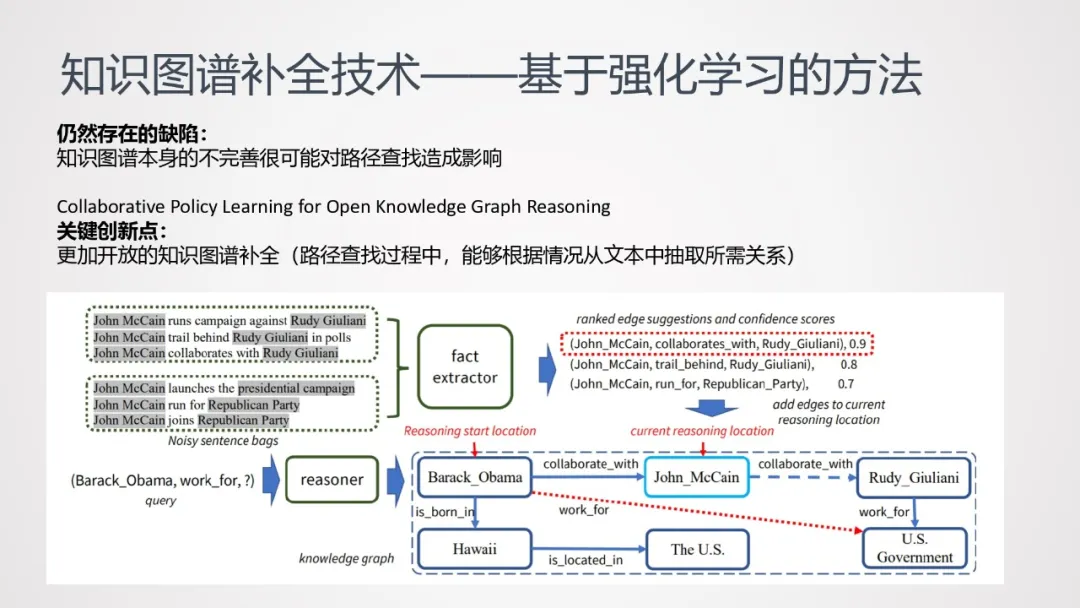
上图中,任务是查找Barack_Obama为哪个组织工作。在原图谱中,John_McCain和Rudy_Giuliani之间的路径是断的;通过弱监督的方式,从原文本中训练出一个关系抽取器,通过这个关系抽取器将缺失的关键路径补充完整。至于是否有必要做路径补充,以及哪一条路径需要补充,则是强化学习中策略选择的工作。
下面介绍一下该模型中的一些细节:
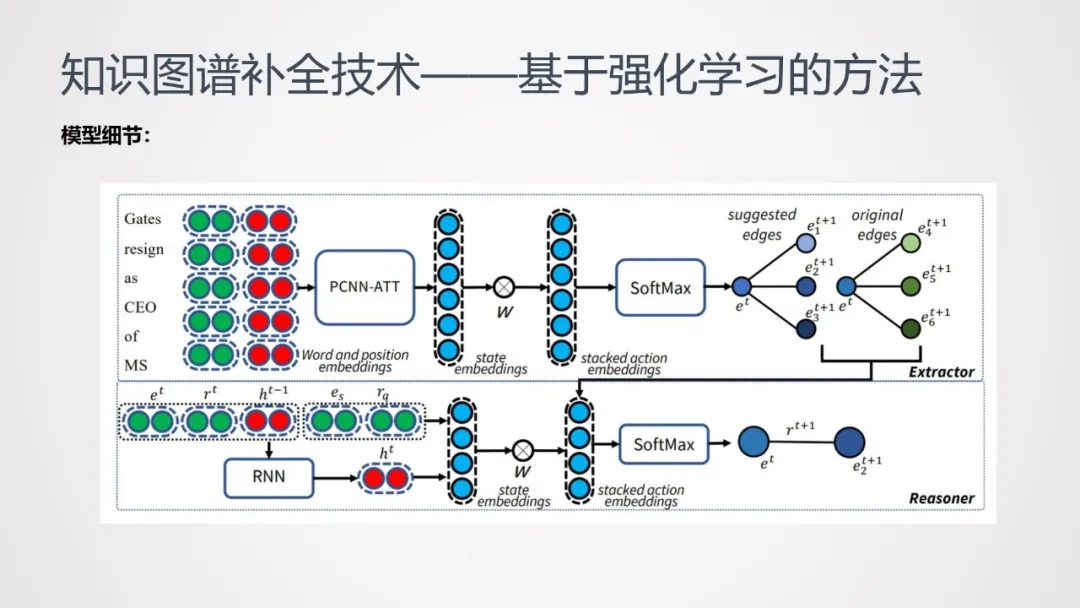
模型包括两个部分:
① 关系抽取(Extractor):使用PCNN-ATT,将文本输入到模型中,可预测出一部分关系;将原图谱中存在的关系和根据预测出来的关系结合,丰富了实体间的关系网络,扩大了当前节点的关系选择范围。
② 关系推理(Reasoner):基于RNN神经网络的推理,将节点当前状态和当前节点可能存在的关系注入到模型中,从而判断推理路径。
4. 基于推理规则的方法
知识推理是针对知识的一项重要应用,很自然的会考虑将其应用在知识补全中;与路径查找不同,知识推理更侧重于对逻辑规则本身建模。
传统的推理规则挖掘方法搜索空间庞大,会导致搜索速度慢。针对这一缺陷,有两类不同的优化方案:
- 推理规则与embedding结合
- 神经网络模型与传统的推理模型结合
首先介绍推理规则与embedding结合的方法:
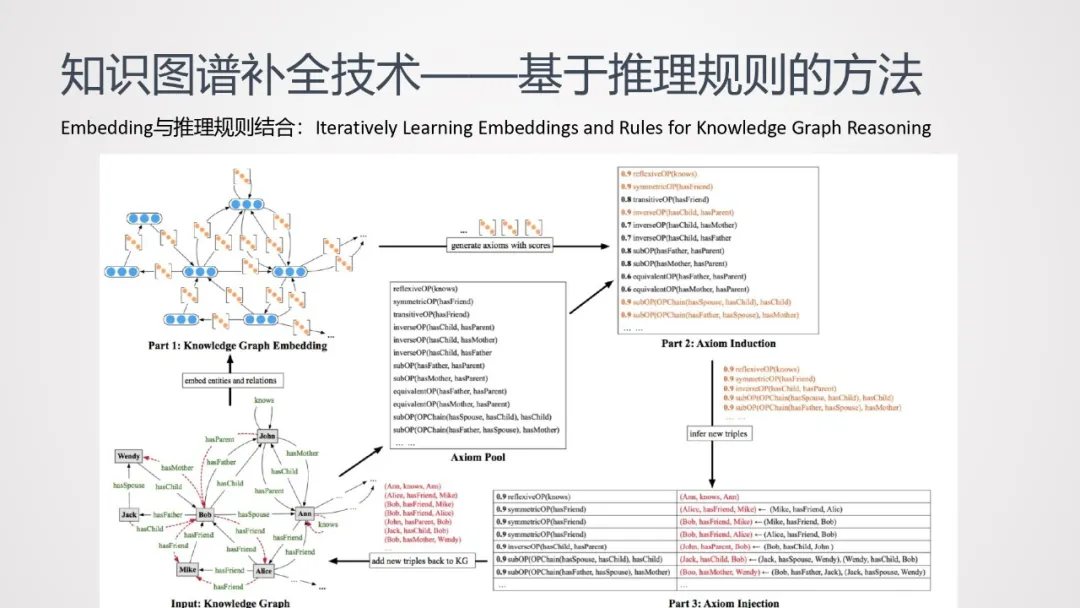
训练知识图谱的embedding的时候,可能会存在很多长尾的实体或关系,会使模型的训练变得不可靠;而单纯使用规则进行推理,挖掘规则本身是个搜索空间非常大。因此结合以上两项工作,互相弥补各自优缺点。对于长尾的实体或关系,用规则进行扩充;对于搜索空间很大的规则来说,借助embedding转换成向量计算,大大降低计算量
这种方法的input是个Knowledge Graph,通过该Graph训练出一个embedding;选取一些已有规则(如自反规则、传递规则、逆转规则等7种规则,如下表所示),对知识图谱中的已有规则进行扩展,进而生成命题:
- 针对每个关系,利用它周围的实体与关系随机获取具体的命题(随机抽取k个含有该关系的三元组,经证明k有一个可控上界)
- 在整个图谱中查找能够支持命题的实例,如果能够查到则保留。
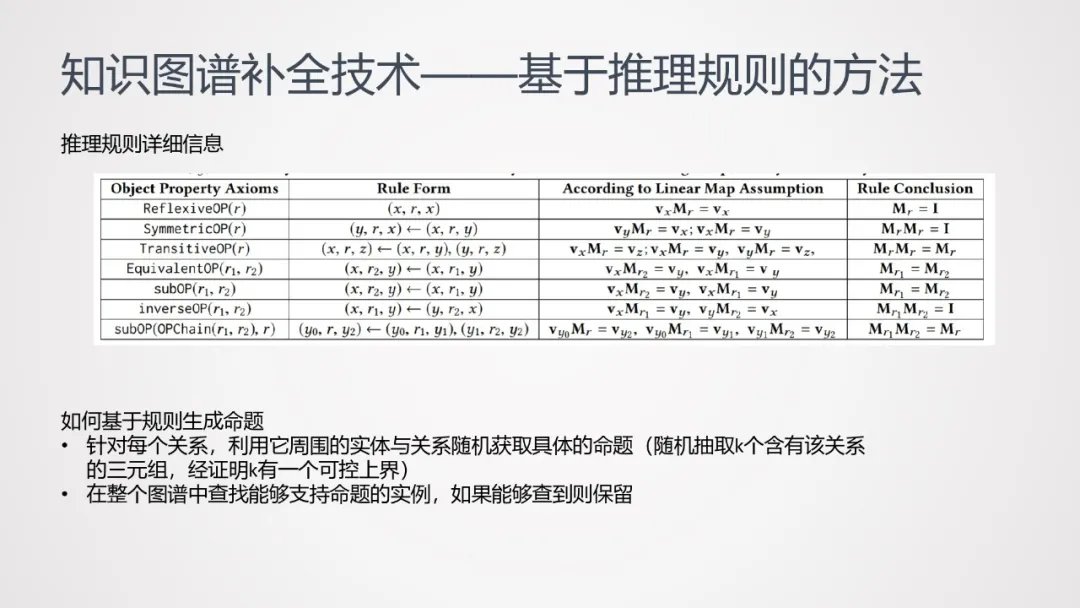
命题形成后,可通过关系表达满足度分数等指标来判断命题是否成立;如命题成立,可将其落地到原知识图谱中,形成可扩充的三元组,并根据命题分数和三元组的分数去计算每个三元组的置信度;将高置信度的三元组扩充回到知识图谱中,训练新的embedding,不断迭代下去。
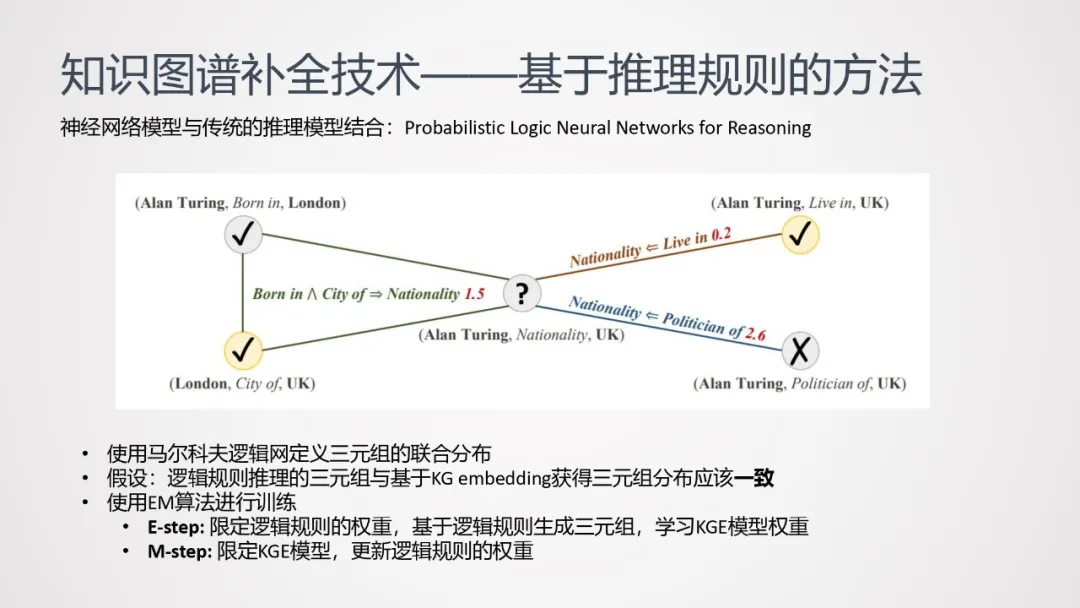
接下来介绍另一种优化方案——神经网络模型与传统的推理模型结合。这里的传统推理模型主要指马尔可夫逻辑网。使用马尔科夫逻辑网定义三元组的联合分布:
①假设:逻辑规则推理得到的三元组,与基于KG embedding获得的三元组,分布一致。
②基于以上假设,使用EM算法进行训练:
- E-step: 限定逻辑规则的权重,基于逻辑规则生成三元组,学习KGE模型权重。
- M-step: 限定KGE模型,更新逻辑规则的权重
5. 基于元学习的方法
前面介绍的几种方法,往往都需要大量的训练数据;而在知识图谱中,大量关系出现频次很低(即长尾数据);而越是低频的关系,越可能需要补全。为了解决这样的矛盾,有人提出了使用元学习方法。
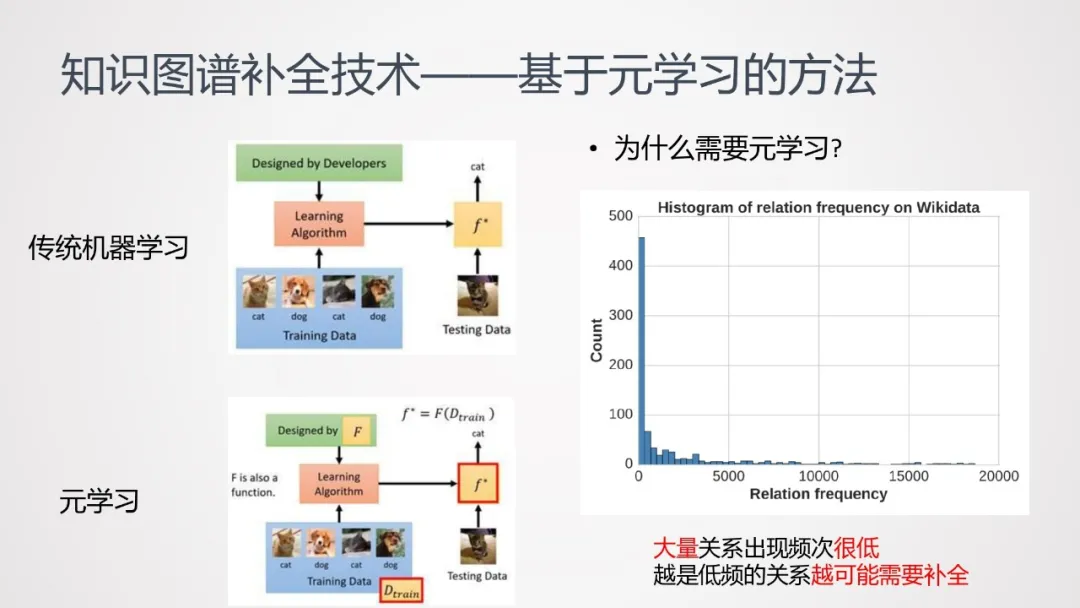
传统的机器学习,通常是基于训练数据去学习一种“从数据到标签的映射”;而元学习,学习的是“一种更高阶的映射”,即从数据到函数的映射。(见上图)
相较于传统机器学习,元学习可以用较少的数据去完成学习任务。
问题定义:基于极少量的已知三元组,对缺失的三元组进行预测

以上表为例,Training过程由几个Task组成,每个Task面向不
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E8%A1%A5%E5%85%A8%E6%8A%80%E6%9C%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


