腾讯基于预训练模型的文本内容理解实践

分享嘉宾:赵哲博士 腾讯 高级研究员
编辑整理:张书源 爱丁堡大学
出品平台:DataFunTalk
导读: 预训练已经成为自然语言处理任务的重要组成部分,为大量自然语言处理任务带来了显著提升。本文将围绕预训练模型,介绍相关技术在文本内容理解方面的应用。更具体的,本文会首先对已有的经典预训练工作进行回顾,帮助大家理解预训练模型以及不同模型之间的差异;然后介绍我们在训练算法、框架开发、上线推理方面进一步的探索,以及相关工作在业务上的应用。最后,对当前我们面临的挑战进行总结,并对未来工作进行展望。
本文涉及的预训练框架UER-py项目地址:
https://github.com/dbiir/UER-py
01 预训练背景介绍
1. 预训练模型背景
如果大家关注NLP领域,在过去两三年的时间中应该经常被类似的标题刷屏。比如某某预训练模型超越人类,取得历史突破。这些标题有一定标题党的成分,但是也反映了预训练模型在NLP领域的热度以及对NLP领域的意义。
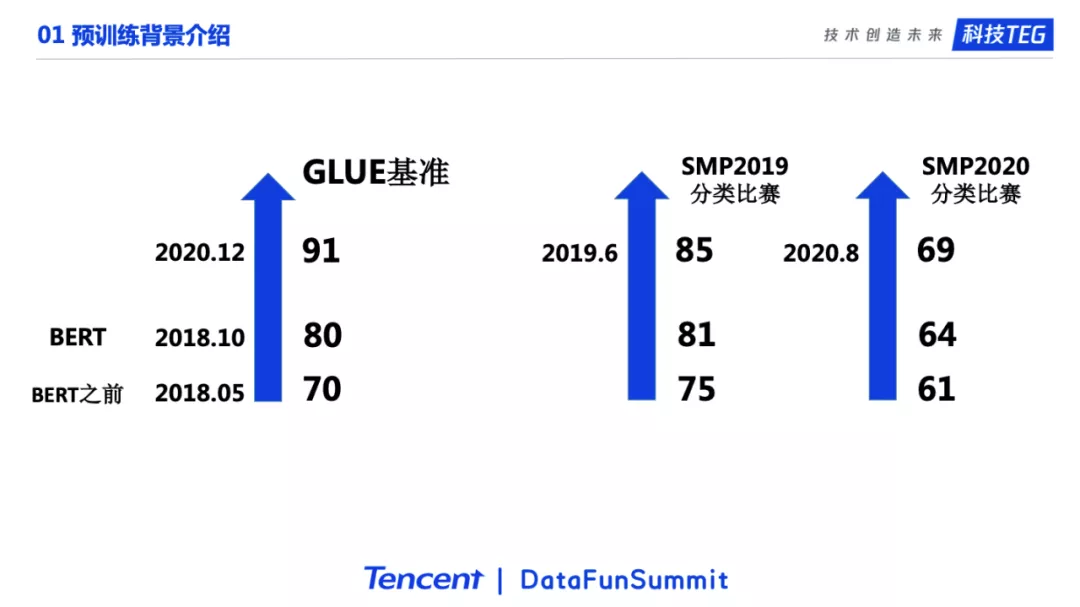
预训练模型的出现确实为NLP领域的任务带来了显著的提升。左边这个图展示了不同时间段当时最好的模型在GLUE榜单上的效果。GLUE是一个英文榜单,包括了9个分类任务。在BERT之前最好的结果是70左右。BERT将结果提升到了80。随着预训练模型继续的发展,主要是更大的模型和更多的语料。20年底GLUE上最佳的表现已经到了90以上。右边的图展示了SMP2019和2020举办的两个情感分析比赛的情况。19年比赛BERT的结果达到了81,BERT之前的非Transformer结构的模型最好的结果也只有75左右,可以看到BERT优势很明显。在2020年的比赛中,BERT在新冠track上的结果是64,通过围绕着预训练模型进行各种改进,冠军能达到69左右的结果。可以看到预训练领域的发展确实为NLP任务带来了显著提升。
2. 预训练模型的基本流程
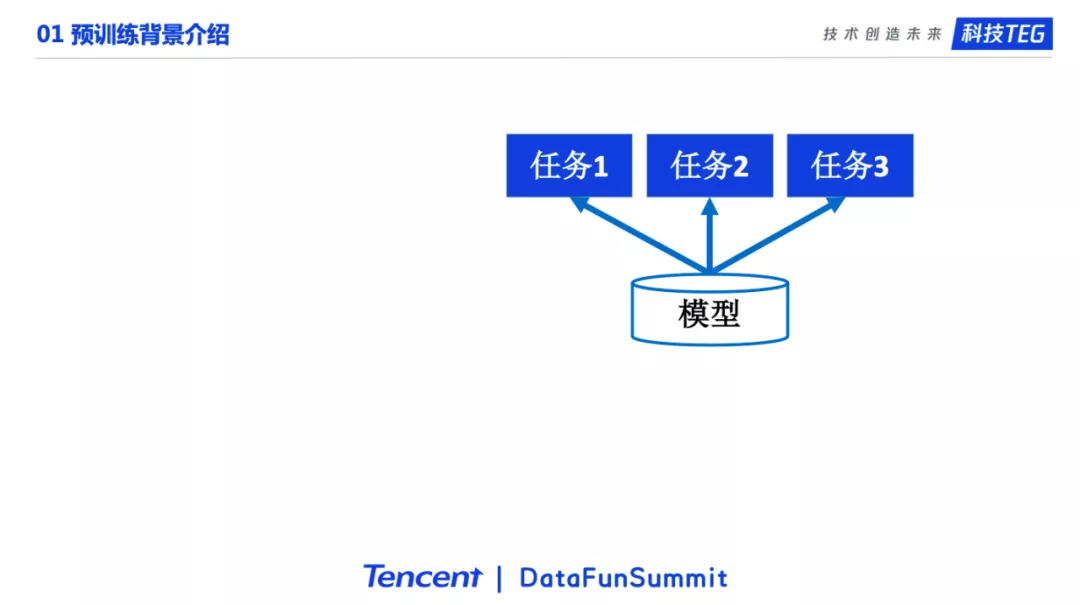
下面介绍预训练模型的基本流程。如果没有预训练,流程如这个图所示。模型参数随机初始化,然后在具体的任务上进行训练。
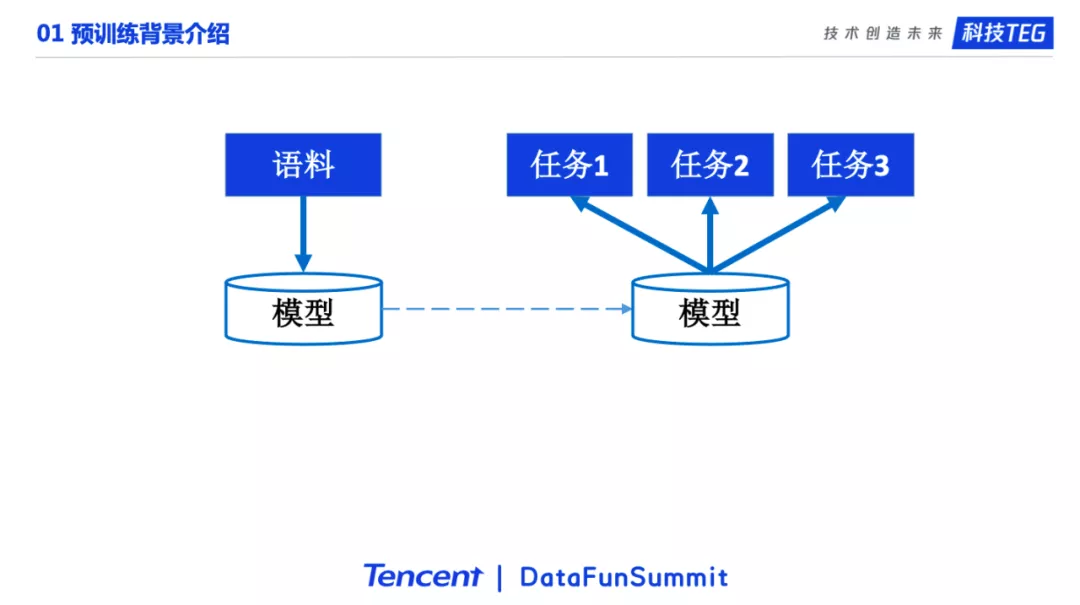
当我们加上预训练以后。模型首先在大规模语料上进行预训练,学习到通用的知识。然后将学习到通用知识的模型迁移到下游任务上进行微调。在预训练阶段学习到的知识对很多下游任务会有很好的帮助。
更具体的说,原来进行下游任务训练的时候,模型是在随机初始化的参数上训练,现在会加载经过预训练的参数,然后在具体任务上微调。目前主流的NLP解决方案一般都是这种两阶段的策略,先预训练再微调。
3. 理解预训练模型
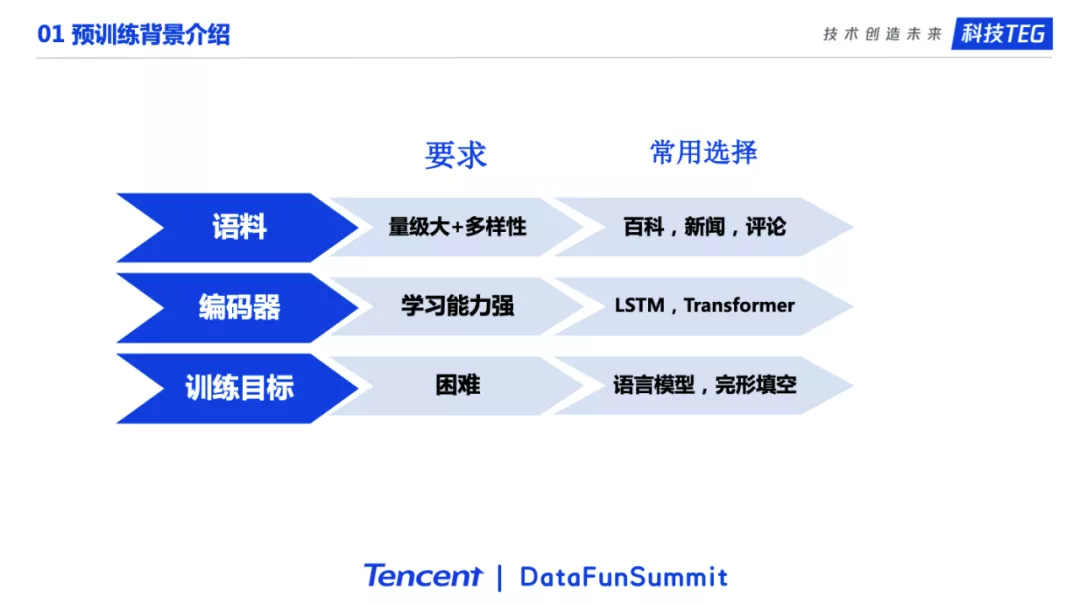
我们可以有很多的角度去理解预训练模型。在这次分享中,我们从三个角度去理解一个预训练模型。这三个角度分别是语料、编码器、训练目标。事实上,我们可以这么说,一个预训练模型主要就是由这三个部分组成的。我们选择一份语料,一个编码器,一个预训练目标,就构成了一个预训练模型。关于预训练模型的语料,我们一般希望量极大并且有一定的多样性,包含很多的知识。常见的语料包括百科,新闻,评论等等。关于编码器,我们希望编码器足够的强大,常用的选择是深度学习中能力很强的编码器,像LSTM,Transformer。最后是训练目标。我们希望训练目标有一定的挑战性。强大的编码器加上困难的目标任务,才能让模型从语料中充分学习到语言的知识。
02 经典预训练模型
介绍完预训练模型的背景,下面我们介绍10个左右的经典预训练模型。由于时间有限,我们会从上面说的语料,编码器,预训练目标三个角度对预训练模型进行介绍,一些细节我们就不多叙述了。其实给定一个预训练模型,我们把它的这三方面说清楚了,也就对这个预训练模型有了一个基本的认识。
1. Skip-thoughts

第一个是Skip-thoughts,是一个15年的模型。它的选择的是大规模的图书语料。图书语料其实是一个很合适的选择,因为图书的题材可以很多,比如历史、爱情、科幻,以及图书包含了很多人类的知识。在编码器方面。选择了当时比较流行的GRU。它的目标是很经典的语言模型单词预测任务,通过一个句子的前n-1个单词的信息来预测第n个单词。如果在预训练阶段模型能把单词预测的任务做好,那么我们认为它充分学习到了人类语言的知识,对下游任务会有很大的帮助。
Skip-thoughts这个模型还有一个额外的贡献点,那就是它用了相邻句子的信息来预测第n个单词。如图所示,灰色、红色和绿色代表不同的句子。我们对红色的句子进行单词预测的时候,不仅使用红色句子中前n-1个单词的信息预测第n个单词,还会使用相邻句子的信息,也就是灰色的句子。最终,模型会将相邻的句子进行编码之后和前面的n-1个单词一起预测第n个单词。
2. Quick-thoughts

然后介绍Quick-thoughts。我们可以从名字看出来,它其实是Skip-thoughts模型的近亲。在语料方面,它用了和Skip-thoughts一样的大规模图书语料,同时它还增加了更多的互联网的语料。在编码器方面,它跟Skip-thoughts一样,用的也是GRU模型。这篇论文的贡献,也就是和Skip-thoughts主要的不同点在于它的预训练目标:它使用了句子级别的预测模型,即用中心句子预测周围的句子。如图所示,第一句话“春天来了”的下面有三句候选,我们要从这三句候选句子中挑选出哪一句话是真正的下一句话。所以我们会对这三个候选的句子,通过GRU编码器进行编码,最后通过一个分类器进行预测。第二个候选句子“但是谷物还没有生长”是正确的答案。这个预训练任务的目标就是通过预测句子之间的关系来让模型学习到高质量的句子表示。
这个模型的名字叫做Quick-thoughts,之所以有quick这个名字,是因为它的训练非常的快。我们知道,一般语言模型是比较慢的,因为语言模型对单词的预测需要在整个词典中找出合适的单词。举一个简单的例子,词典大小是两万,那就要从两万个单词中去选择那个合适的单词。另一方面,语言模型需要对每个单词进行预测。但Quick-thoughts针对句子进行预测是可以很快的。直观的说,如果进行负采样,Quick-thoughts只选两个句子作为负样本,到最后就是一个简单的三分类任务,所以这也是为什么它叫Quick-thoughts的原因。
3. CoVe
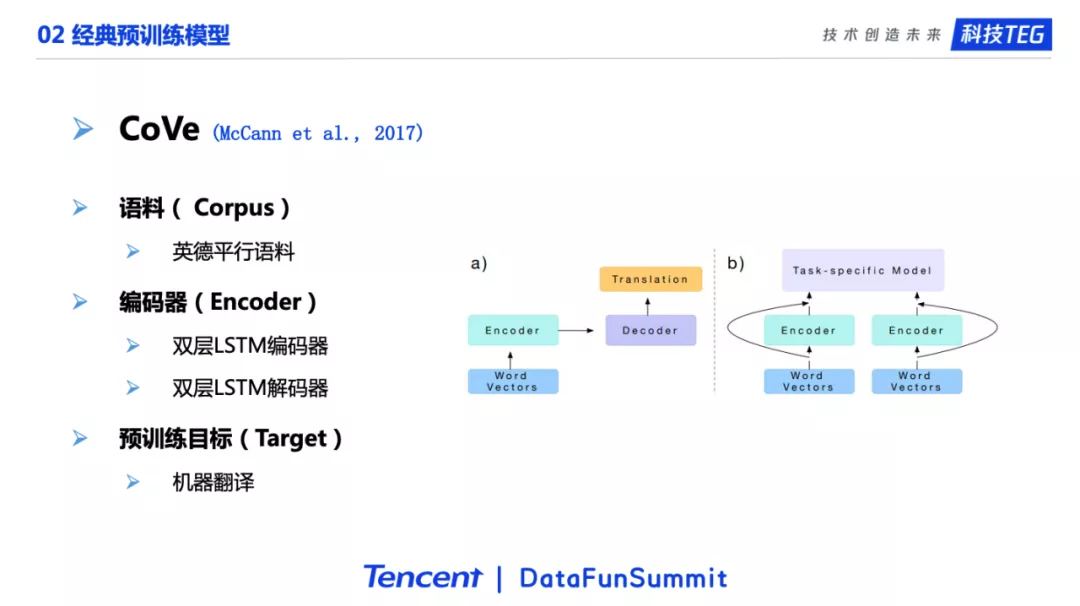
接下来是17年的一个模型,是当时在预训练领域比较有名气的一个工作,叫做CoVe。它最大的贡献是提出了用机器翻译作为训练目标进行预训练。因为机器翻译是一个非常困难的一个任务,被称为人工智能皇冠上的明珠。如果模型把这么难的任务都能做好的话,那它应该能学习到很多的语言知识,这些知识对于其他的下游任务就会有很大的帮助。CoVe的预训练目标选择了机器翻译之后,很自然的就会选择平行语料作为预训练的语料,这里使用了英德平行语料。编码器则选择了当时最为流行的双层LSTM,解码器也是双层LSTM。如图所示,在预训练的过程中,编码器对应的是英语,解码器对应的是德语。由于模型的下游任务都是英语,所以会把编码器学习到的英语的知识迁移到下游任务上,然后利用学习到的权重去更好的提升下游任务上的表现。
4. InferSent
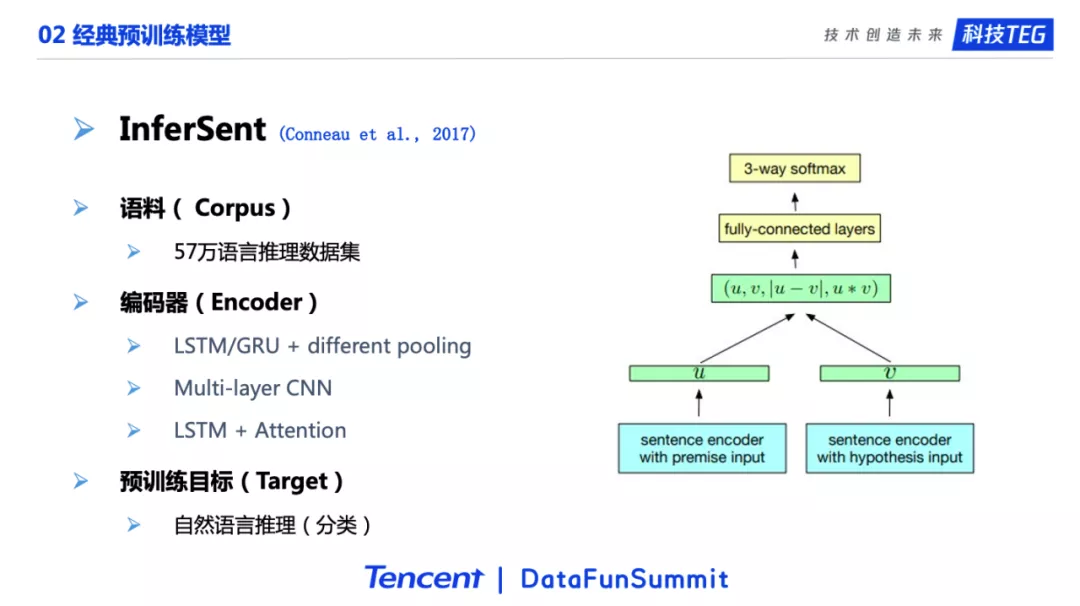
下一个介绍的是InferSent。这个工作的动机和上个介绍的工作是类似的,认为自然语言推理是一个很难的任务。如果把这个任务做好了,那模型也就能学习到有价值的人类语言知识,对于下游任务也会有很大的帮助。自然语言推理是一个文本对三分类任务:给定两个句子,如果第一句能推理出第二句是正确的,这两个句子就是蕴含关系;如果第一句能推出第二句是错误的,这两个句子就是矛盾关系;如果第一句既推不出第二句是正确,也推不出第二句是错误的话,那两者就是中立关系。简单来说这篇文章的核心工作就是使用分类任务作为预训练目标。这个工作的语料是五十七万的语言推理数据集。在编码器方面。用到了在Transformer之前常用的各种编码器,包括LSTM/GRU加上不同的Pooling层、以及多层的CNN、LSTM加上Attention。
这篇文章最后给出了一个结论,认为LSTM加上max Pooling是最好的选择。其实我们之前自己的实验也有相似的结论,LSTM确实在很多场景下还是一个非常鲁棒的模型,在和max pooling配合的时候,在很多数据集上都能取得非常好的效果,不一定比Transformer要差。
5. GPT
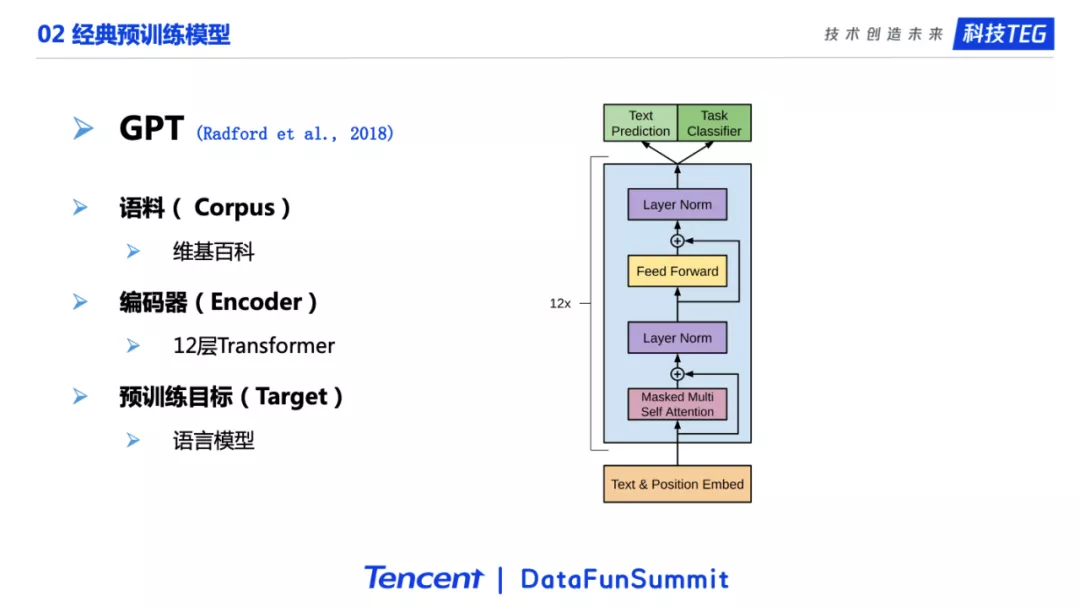
下面是一个有里程碑意义的工作,也就是GPT模型。它的语料是维基百科,预训练目标则是语言模型,这两点很正常。这个工作最重要的一点是首次将Transformer搬到了预训练场景。它使用十二层的Transformer进行预训练。Transformer是多个self-attention网络的堆叠,能力非常强,适合文本序列这样数据的建模,相对于以前经典的LSTM和CNN有了非常大的提升。由于时间的原因,我们这里不过多介绍Transformer的细节。
6. BERT
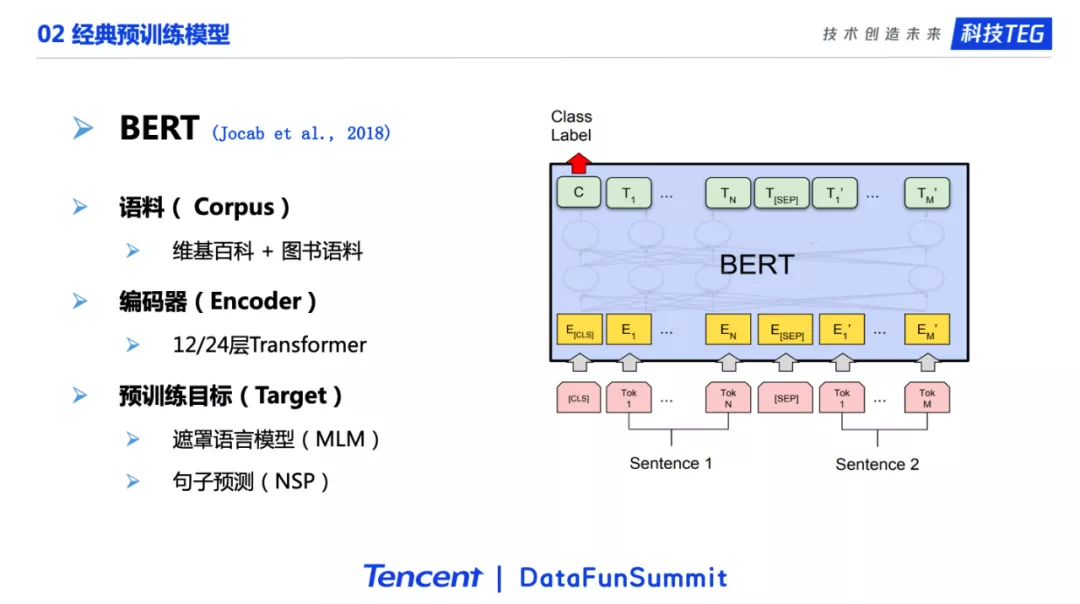
下一个工作是BERT。这个应该可以算是NLP最重要的工作之一。我们还是从语料、编码器、训练目标3方面介绍。它使用的语料是维基百科加图书。这里的图书语料其实就是第一个介绍的模型Skip-thoughts所使用的语料。
在编码器方面,BERT和GPT是一样的,都使用了Transformer。BERT首次使用了24层的Transformer,这是在NLP中第一次使用这么“重”的编码器。在此之前有工作使用30层左右的CNN网络,但是那个CNN比这里的24层Transformer参数量少很多。BERT工作中的一个重要结论是,更重的编码器(24层)相对于较轻的编码器(12层),会在下游任务上有着明显的优势。
在训练目标方面,BERT的一个贡献是它使用了遮罩语言模型,一个双向的语言模型目标任务。GPT中使用的语言模型是单向的,只能通过左边的信息对单词预测,BERT这里使用两侧的信息对中间单词进行预测。其实BRET用的MLM遮罩语言模型就是完形填空。和高中英语完形填空差不多。高中的完形填空是四选一,遮罩语言模型更困难,因为它要在整个词典中选择一个最合适的单词。如果当前的词典有两万个单词,就相当于两万选一。BERT还使用了句子预测NSP作为另一个目标任务。这个目标任务其实跟我们之前介绍的Quick-thoughts基本上是一样的。也就是说BERT实际上是多任务的预训练:一方面要去预测那些被遮住的单词,另一方面要判断两个句子之间的关系。
7. RoBERTa & ALBERT

下面介绍的两个模型,RoBERTa和ALBERT都是以BERT为基础进行了改进。RoBERTa工作的主要观点是,在BERT之后对于BERT的各种算法技术上的改进并没有太大的意义,或者说收益并不大。RoBERTa工作仅仅在BERT的基础上运用更大规模的语料进行预训练就能取得更好的结果,在榜单上将BERT的80分提升到了接近90分的水平。RoBERTa在预训练目标那里,去掉了句子预测NSP任务。此外,RoBERTa还在一些点进行了小的改变,比如使用动态的遮罩方式,也就是边训练边决定哪个单词需要被遮罩以及预测。
ALBERT做出的改进是在12/24层Transformer的层之间进行了参数共享,从而节省了显存。另外,ALBERT的编码器变的十分的“矮胖”,隐层维度的宽度大大增加。在预训练目标方面则是将NSP改成了句子顺序预测,判断两个句子的顺序是正常的还是颠倒的,也就是SOP,动机是认为SOP任务更难,但我们在实验中发现这个任务也不算很难,比较容易达到较高的准确率。
8. GPT-2
GPT-2进一步使用了更大的编码器,达到了最多48层,使用了Pre-layernorm机制,将layernorm放在了每一层的Attention和Feed Forward的前面。此外GPT-2在参数随机初始化策略方面也进行了改变。这些调整能够帮助我们训练更深的模型。
9. T5

T5的语料进一步扩大,使用了750G的语料。它最核心的贡献是将NLU和NLG、也就是自然语言理解和自然语言生成统一了。虽然这方面的工作很早就有,但是T5的试验做的非常全面,最终发现encoder/decoder是一个非常好的结构,T5最终的参数数量也是达到了110亿个。右边的图展示了T5的预训练目标,输入inputs是一些单词被遮罩的句子,进入到encoder;在decoder部分,模型需要生成被遮罩的单词。
当T5用于下游任务的时候,文本作为encoder端的输入,decoder负责标签的输出。事实上,不管是NLU还是NLG任务,都可以使用text文本用来表示他们的正确答案。因此不管是分类还是翻译还是回归任务,都可以使用一样的seq2seq模型结构和一样的训练/推理策略。
03 预训练模型框架
刚才介绍了这么多预训练模型。这些预训练模型各有特点,可以适用于不同的场景之中。我们希望能有一个框架去复现这些预训练模型,并在其基础上结合我们的需求,比如业务需求,进行改进。下面介绍我们在预训练框架方面的工作。
1. 模块化设计

首先说一下模块化设计。模块化设计是很多深度学习框架遵循的一个原则,我们希望能像搭积木一样去构建模型,尽可能的减少构建模型的“成本”。这方面很经典的一个工作是Keras。Keras将网络所有的层都抽象为Layer,创建一个神经网络的过程就是把各种Layers进行组装,像搭积木一样搭起来。类似的还有NeuronBlocks、OpenNMT、NeuralClassifier等。比如OpenNMT,会实现很多的encoder和decoder模块。当我们需要创建机器翻译模型时,只需要将一个encoder和一个decoder组合就可以。
2. UER-py

受到上面工作的启发,我们团队构建了第一个模块化的预训练模型框架, UER-py 。一个预训练工作,从模型的角度,可以分成Embedding层、Encoder编码层、Target目标任务层。当我们需要实现一个预训练模型的时候,我们通过对三个层中不同模块的组合,就可以快速构建一个预训练模型。
UER项目的全称是Universal Encoder Representations,这个项目是完全基于PyTorch开发的,不需要任何其他额外的环境,完全开源。UER最大的特点,刚才也提到过,模块化的设计,支持按需装配。
这个工作被EMNLP2019 System track收录,并且在公司内部被广泛应用。UER这个项目在Github上开源了,地址是 https://github.com/dbiir/UER-py,期待大家的使用、建议、以及对代码或者资源的贡献。
3. 框架结构
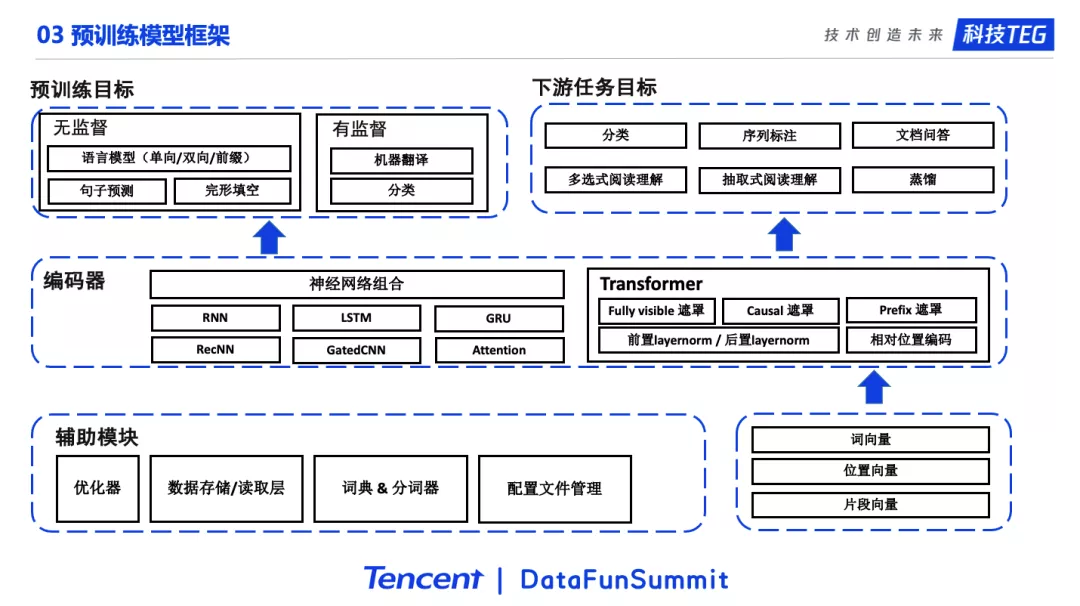
这里给出了这个项目整体的框架结构,由于篇幅原因我们只列出了部分的模块。希望通过这个图能够帮助我们更加清晰的理解UER-py项目的结构。
右下角是Embedding部分,包括了词向量、位置向量、片段向量等模块。Embedding层的输出会进入到中间的编码层。编码层中包含了神经网络的组合和Transformer以及Transformer的各种变种,比如不同的遮罩策略、相对位置编码等。事实上从17年最早Attention is all you need论文到最新的论文,比如T5,Transformer一直有一些微小的变化或者说是改进,这些点UER都是支持的。编码层往上是Target训练目标层。训练目标分为预训练目标和下游任务目标。预训练目标又分为无监督目标和有监督目标。下游任务目标则对应各种各样的下游任务。此外UER包括了预训练所需要的各种辅助模块,这里就不多叙述了。
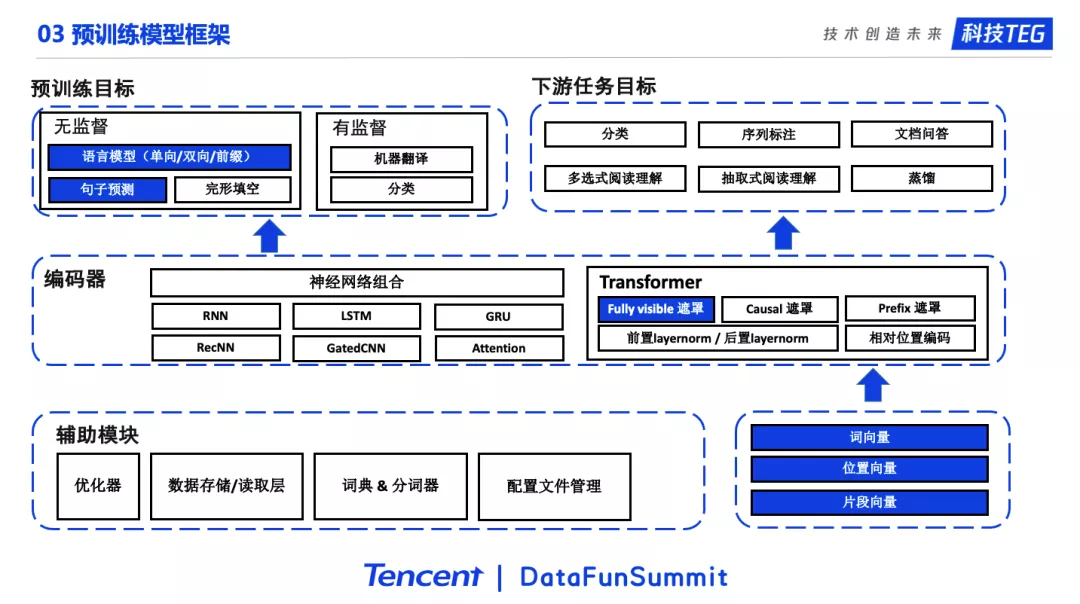
在这个框架下,例如我们想实现BERT的模型,我们只需要从每个部分拿出相应的模块,然后进行组合就行了。如图,蓝色模块组合即是BERT模型。
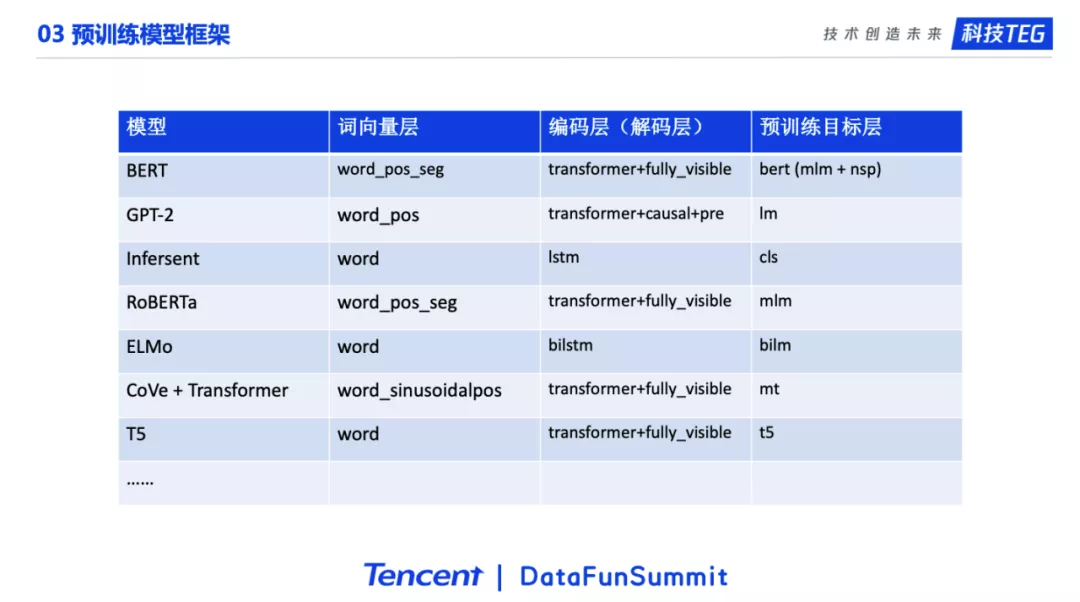
这个表格展示了不同的模型,需要的模块。这里由于篇幅限制,一些细节有缺失。
更多的细节需要参考UER的文档(英文和中文):
https://github.com/dbiir/UER-py/wiki
https://github.com/dbiir/UER-py/wiki/ 主页
可以看到经典的预训练模型,可以通过模块的组合实现。
4. UER v.s. Huggingface Transformers
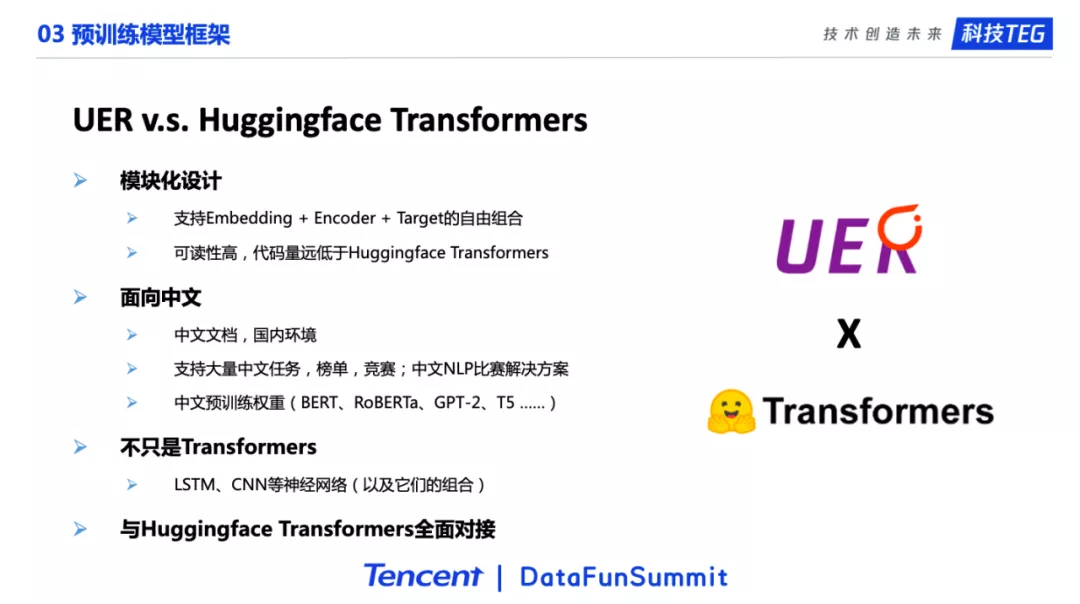
目前预训练领域最火的框架是Huggingface Transformers,这个框架在功能上和UER是类似的,都是预训练模型框架,支持很多模型的预训练以及他们在下游任务上的微调。Huggingface Transformers很受欢迎,但是UER和其相比,在一些点上还是有着明显的区别和优势。首先,UER最大的特点是模块化的设计,预训练模型被拆多个部分,我们可以通过不同模块的组合构成预训练模型。这样做的优点是框架可读性高,代码量少。而Huggingface Transformers也在文档里说明了,这个项目的顶层设计逻辑是,不进行模块化的设计,而专注于严格的模型复现。UER第二个特点是面向中文,支持非常多的中文任务,中文竞赛,以及发布了大量的中文预训练权重(下一页PPT会进行介绍)。此外,Huggingface的一些功能需要翻墙,也不是很方便。第三点是UER不仅支持Transformer相关的工作,也包括LSTM、GatedCNN这样的编码器。
总的来说,UER虽然和Huggingface Transformers在功能上是类似的,但是实际上有很多的不同,也在一些点上有明显的优势。目前,UER和Huggingface Transformers项目是全面对接的,经典的预训练模型,比如BERT、GPT-2、T5、BART、PEGASUS等是可以严格的相互转换的。
5. 预训练权重资源(中文)

下面介绍UER提供的预训练权重资源。UER提供了很多中文预训练资源。刚才提到UER和Huggingface Transformers是可以相互转换的。因此我们又提供了Huggingface Transformers格式的预训练权重,也提供了UER格式的预训练权重。这两个仓库,包括的模型以及模型权重是一样的,只是两种不同的格式,支持两种不同的框架。
我们在Huggingface模型仓库中建立了UER用户。并在这个用户下面上传了大量的预训练模型权重,这些权重的每月下载量接近5万。
地址: https://huggingface.co/uer
我们提供的权重的特点是开源可复现。我们给出了所有的细节,用户只要有计算资源,就可以轻松复现。所有的预训练模型权重都是通过UER进行的训练,然后通过转换脚本转换为Huggingface Transformers格式。我们利用UER预训练了大量的权重,包括BERT、GPT-2、T5、ALBERT、BART等预训练模型权重以及分类、阅读理解等下游任务权重。
我们在UER项目下也提供了预训练模型仓库。里面的模型权重都是UER格式的,也就是UER可以直接加载。它和上面说的Huggingface Transformer UER用户下面的权重是一一对应的。
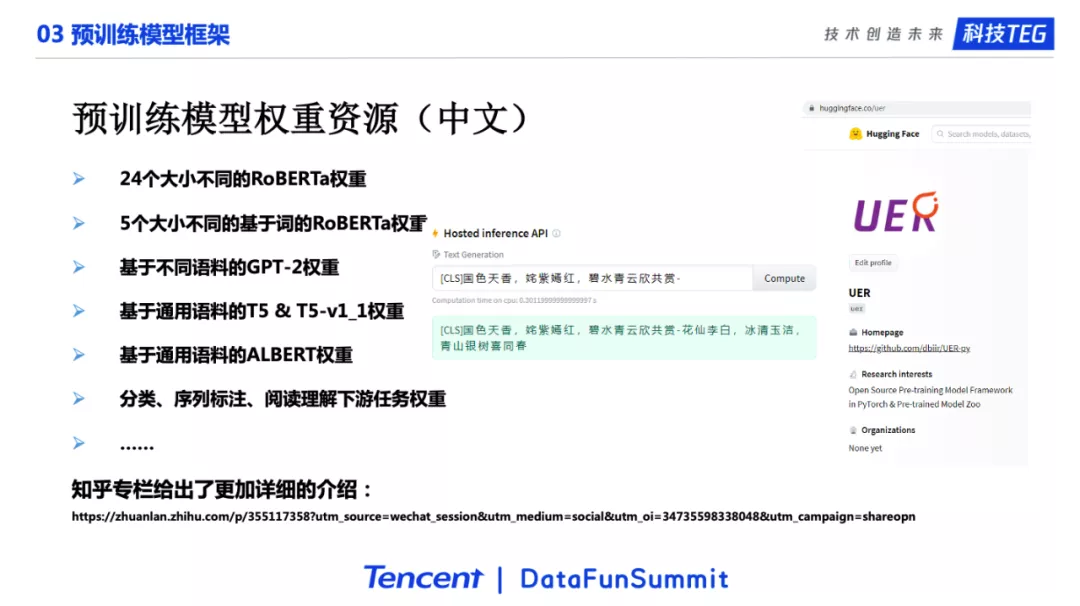
我们提供了非常丰富的预训练模型权重。这里进一步列出了我们提供的各种类型的权重。右图是UER在Huggingface上面的主页。非常欢迎大家能够使用我们提供的预训练权重,可以使用Huggingface Transformers加载使用,也可以使用UER加载使用。
目前我们已经发布了超过50个权重,并且每个权重都给出了详细的训练方式和使用方式,并且支持Huggingface的网页端在线推理。比如中间的图展示用Huggingface的在线推理生成对联。下面快速介绍几类典型的权重。
我们在知乎的这篇文章中给出了这些预训练权重详细的信息,链接为:
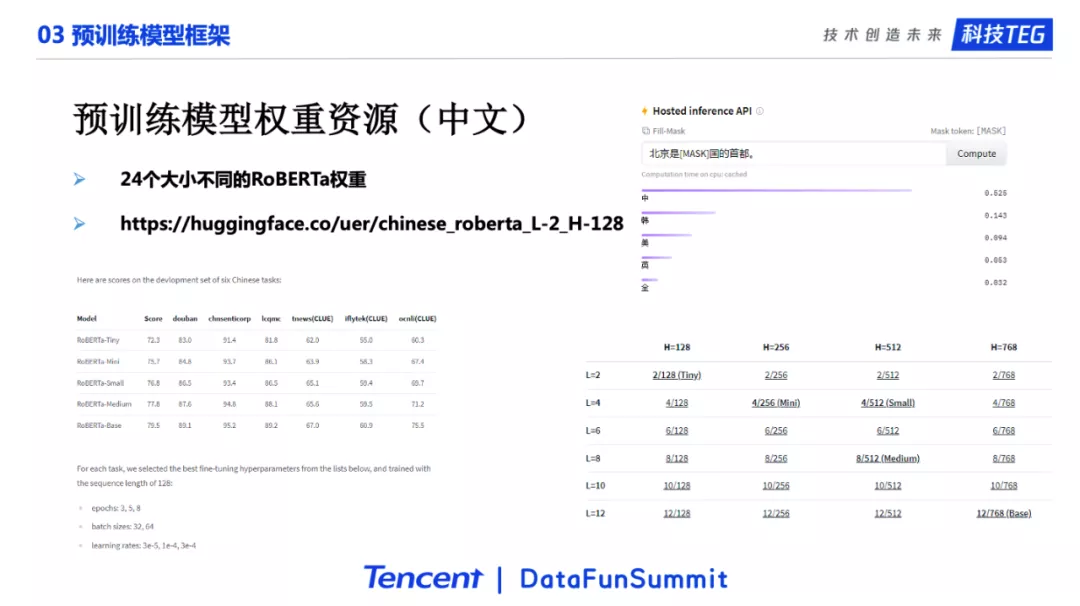
参考BERT作者后续发的文章:Well-Read Students Learn Better: On the Importance of Pre-training Compact Models,预训练对于小模型也有很大的帮助。我们跟着他们的工作,提供了24个不同尺寸的中文RoBERTa模型,并给出了这些模型在经典中文数据集上面的效果。

我们提供了基于不同语料的GPT-2预训练权重。比如右下角这个是生成的古诗。由于Huggingface的在线生成是无法显示结束符号的,所以实际上这个诗只有四句28字。
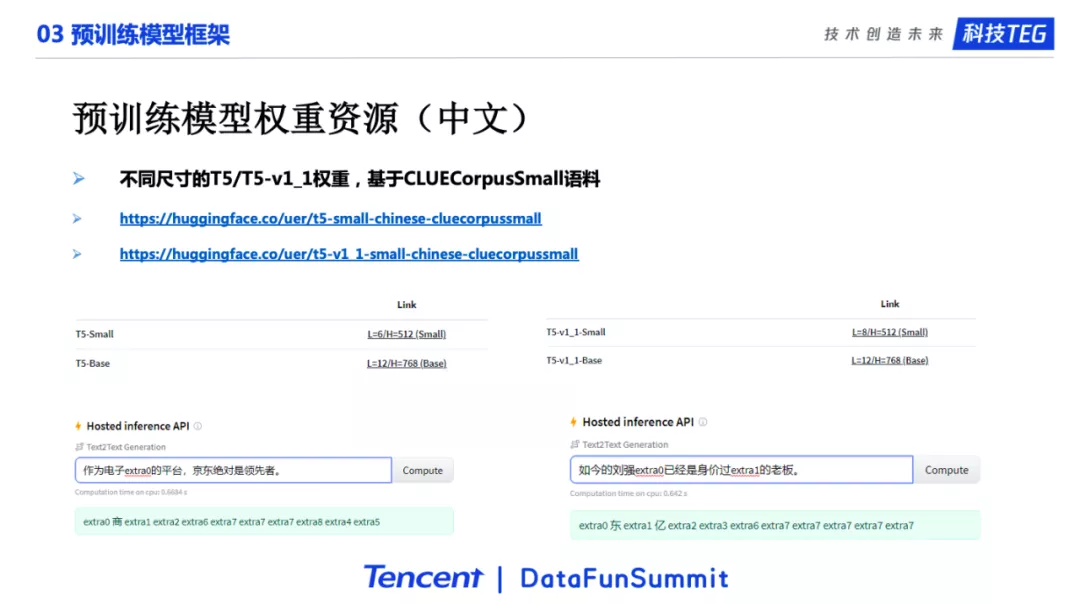
T5预训练权重。我们提供了T5和T51.1,分别提供了Small和Base模型。
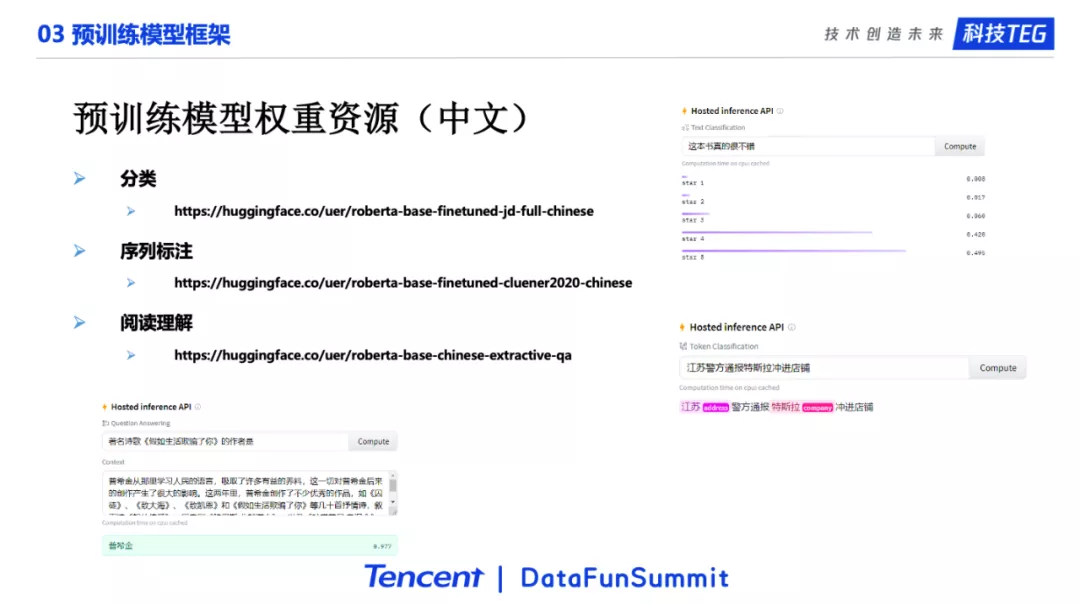
我们也提供了很多下游任务权重,可以进行分类、序列标注、阅读理解等任务。
04 预训练应用实践
通过上面的介绍,我们对预训练模型以及如何通过UER框架去使用预训练模型有了一定的了解。下面介绍我们在业务上的实践。
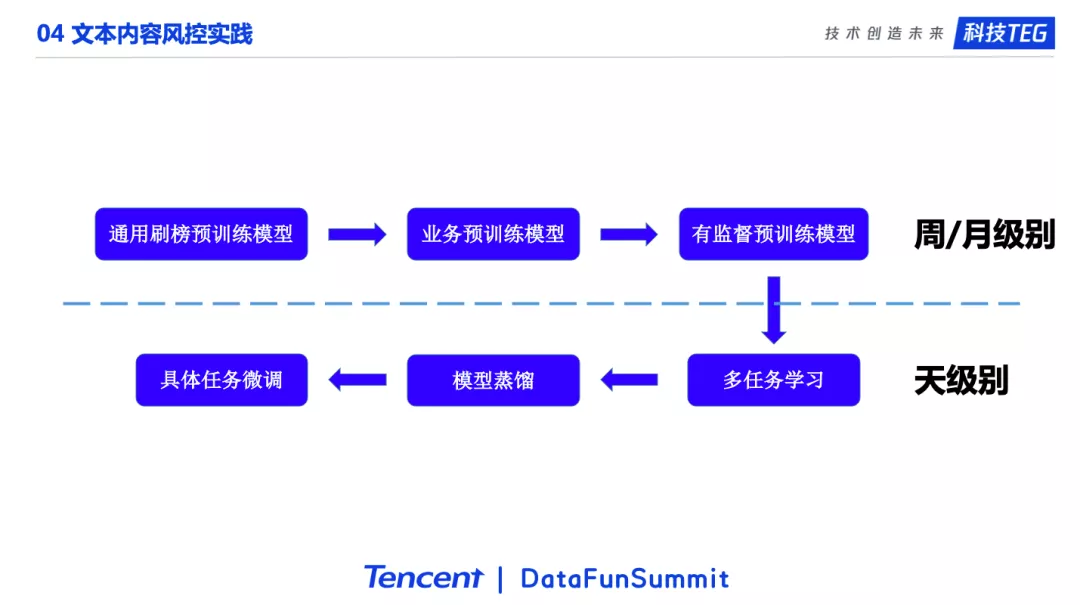
由于时间有限,这里我会比较粗略的介绍我们在公司内部做业务的一个基本的流程。更细节的内容可以后续�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E5%9F%BA%E4%BA%8E%E9%A2%84%E8%AE%AD%E7%BB%83%E6%A8%A1%E5%9E%8B%E7%9A%84%E6%96%87%E6%9C%AC%E5%86%85%E5%AE%B9%E7%90%86%E8%A7%A3%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


